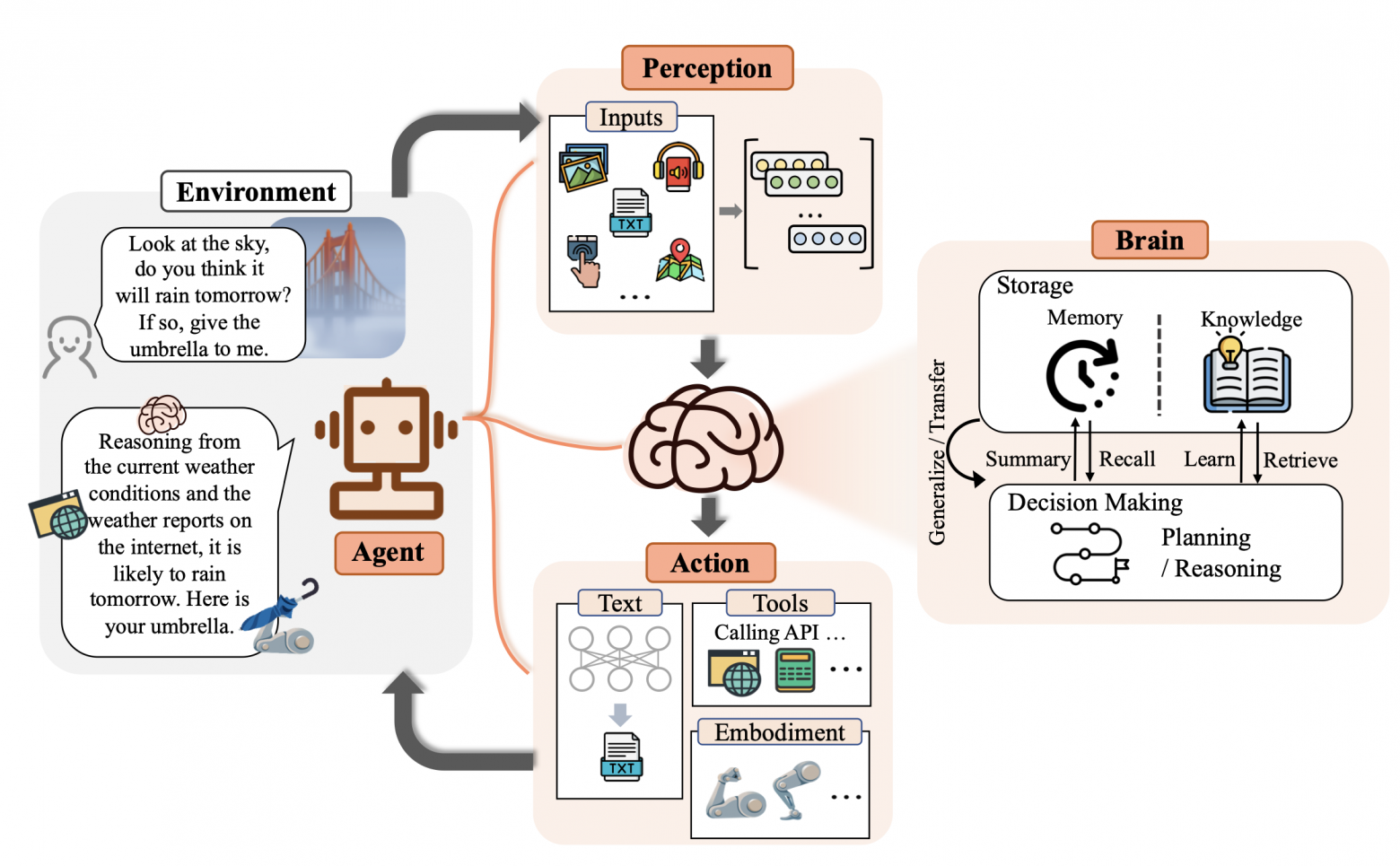
Этот материал посвящён тому, как добавлять собственные данные в предварительно обученные LLM (Large Language Model, большая языковая модель) с применением подхода, основанного на промптах, который называется RAG (Retrieval‑Augmented Generation, генерация ответа с использованием результатов поиска).
Большие языковые модели знают о мире многое, но не всё. Так как обучение таких моделей занимает много времени, данные, использованные в последнем сеансе их обучения, могут оказаться достаточно старыми. И хотя LLM знакомы с общеизвестными фактами, сведения о которых имеются в интернете, они ничего не знают о ваших собственных данных. А это — часто именно те данные, которые нужны в вашем приложении, основанном на технологиях искусственного интеллекта. Поэтому неудивительно то, что уже довольно давно и учёные, и разработчики ИИ‑систем уделяют серьёзное внимание вопросу расширения LLM новыми данными.
До наступления эры LLM модели часто дополняли новыми данными, просто проводя их дообучение. Но теперь, когда используемые модели стали гораздо масштабнее, когда обучать их стали на гораздо больших объёмах данных, дообучение моделей подходит лишь для совсем немногих сценариев их использования. Дообучение особенно хорошо подходит для тех случаев, когда нужно сделать так, чтобы модель взаимодействовала бы с пользователем, используя стиль и тональность высказываний, отличающиеся от изначальных. Один из отличных примеров успешного применения дообучения — это когда компания OpenAI доработала свои старые модели GPT-3.5, превратив их в модели GPT-3.5-turbo (ChatGPT). Первая группа моделей была нацелена на завершение предложений, а вторая — на общение с пользователем в чате. Если модели, завершающей предложения, передавали промпт наподобие «Можешь рассказать мне о палатках для холодной погоды», она могла выдать ответ, расширяющий этот промпт: «и о любом другом походном снаряжении для холодной погоды?». А модель, ориентированная на общение в чате, отреагировала бы на подобный промпт чем‑то вроде такого ответа: «Конечно! Они придуманы так, чтобы выдерживать низкие температуры, сильный ветер и снег благодаря…». В данном случае цель компании OpenAI была не в том, чтобы расширить информацию, доступную модели, а в том, чтобы изменить способ её общения с пользователями. В таких случаях дообучение способно буквально творить чудеса!