

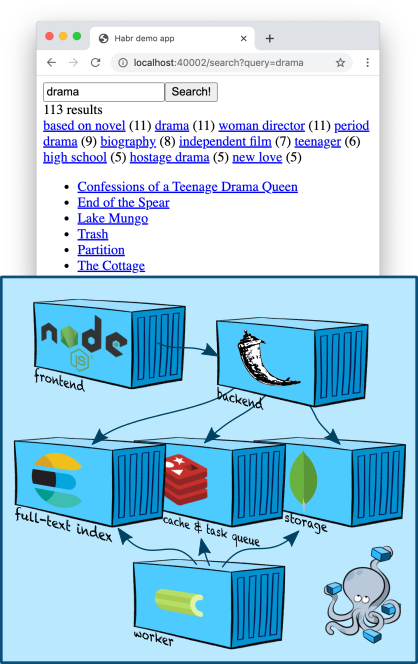
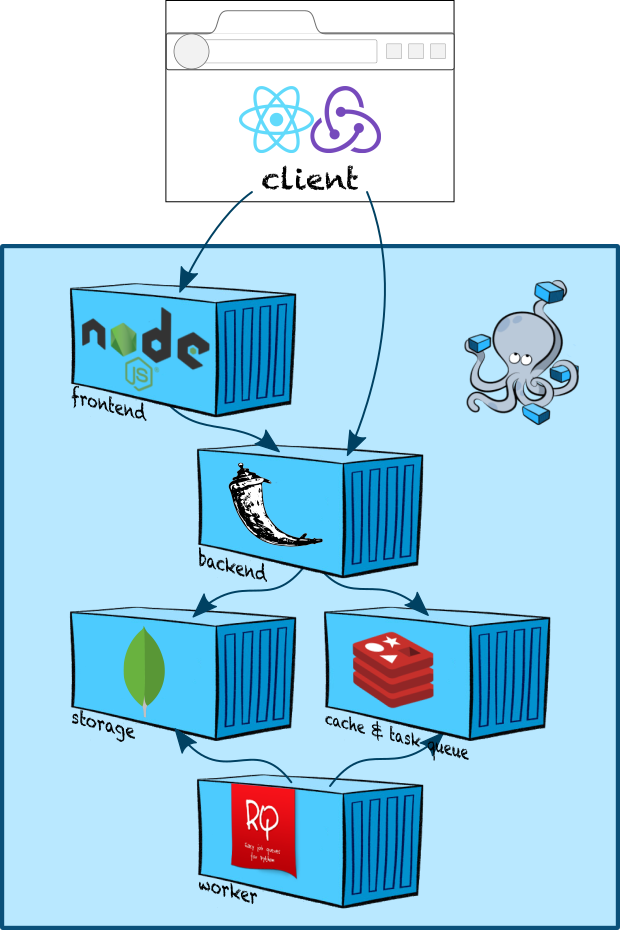
Современные веб-приложения, даже простые на вид, часто подразумевают нетривиальную архитектуру, состоящую из многих компонент. В статье «Делаем современное веб-приложение с нуля» я рассказал, как она может выглядеть, и собрал для демонстрации простейшую реализацию на стеке из нескольких популярных технологий. В неё вошёл бэкенд, фронтенд, воркер для асинхронных задач и аж два хранилища данных — MongoDB как основная база и Redis как очередь задач. В «Делаем поиск в веб-приложении с нуля» я показал, как можно добавить полнотекстовый поиск, и подключил третье хранилище — Elasticsearch.
Всё это время для простоты разработки и отладки компоненты приложения запускались локально через Docker Compose. Но как развернуть такое приложение в настоящем продакшн-окружении? Как обеспечить горизонтальное масштабирование? Как раскатывать новые релизы без простоя?
В этой статье мы разберёмся, как разворачивать многокомпонентное веб-приложение в кластере Kubernetes на примере его локальной реализации — minikube. Мы поднимем виртуальный кластер прямо на рабочем ноутбуке, разберёмся с основными сущностями Kubernetes, запустим и соединим между собой компоненты демо-приложения и обсудим, какие ещё возможности Kubernetes пригодятся нам в суровом энтерпрайзе. Если вы занимаетесь разработкой и слышали о Kubernetes, но ещё не имели возможности пощупать его руками — добро пожаловать под кат!





 Написать этот пост меня вдохновила замечательная
Написать этот пост меня вдохновила замечательная