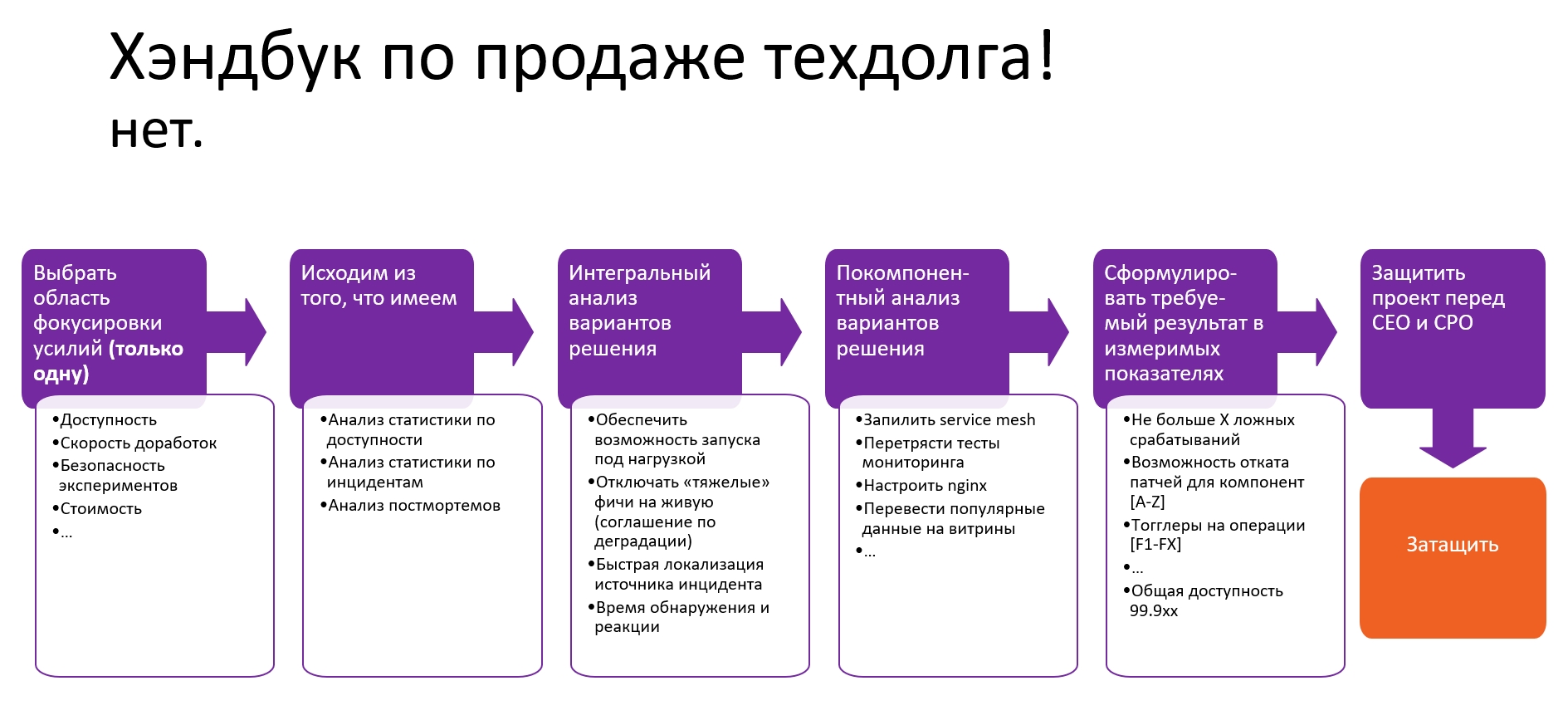
Это экспериментальная статья про Research&Development, технологии для создания новой ценности для клиента — потому не будет ни слова про техническую часть. Будет немного про историю и культуру DevOps , а также про процессы, культурные особенности, взаимодействие внутри инженерных команд и, конечно, особенности появления R&D внутри них.
Сразу скажу, что это немного идеалистичная картина для нашего российского IT. У нас еще мало компаний, которые дейсвительно используют R&D в качестве основного зарабатывающего бизнес-юнита. В основном лишь частично внедряются практики, взаимодействие и культуру DevOps. Но это не значит, что туда не надо идти. Если у вас это вызовет отторжение: «Такого не бывает, это не работает», то предлагаю превратить это в вопрос: «Такого не бывает? Это не работает?»
Меня зовут Александр Титов, первые DevOps-практики я начал использовать еще до того, как появилось само слово DevOps. Сейчас я управляющий партнер в компании Экспресс 42, которая помогает ставить DevOps в компаниях.