Несколько позже, чем хотелось, но продолжаем наш разговор о получении текста из разных форматов данных. Мы с вами уже познакомились с тем, как работать с изначально XML-base файлами (docx и odt), прочитали текст из pdf, преобразовали содержимое rtf в plain-text. Теперь перейдём в вкусненькому да сладенькому — формату DOC.

Василий @nvv
User
Курс «PostgreSQL для начинающих»: #1 — Основы SQL
Easy
13 min
Opinion

Этим постом я запускаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В программе: рассказ об основах SQL, возможностях простых и сложных SELECT, анализ производительности запросов, разбор [не]эффективного применения индексов и особенностей работы транзакций и блокировок в этой СУБД.
Курс не претендует на лавры "войти в айти", поэтому подразумевает наличие у слушателя опыта программирования или работы с другими СУБД, и, главное, желания самостоятельно изучать тему работы с PostgreSQL глубже.
Для тех, кому комфортнее смотреть и слушать, а не читать - доступна видеозапись.
GPT-4: Чему научилась новая нейросеть, и почему это немного жутковато
Easy
23 min
Review

В этой статье мы разберем новые удивительные способности последней языковой модели из семейства GPT (от понимания мемов до программирования), немного покопаемся у нее под капотом, а также попробуем понять – насколько близко искусственный интеллект подошел к черте его безопасного применения?
Как работает ChatGPT: объясняем на простом русском эволюцию языковых моделей с T9 до чуда
Easy
30 min
Review

В последнее время нам почти каждый день рассказывают в новостях, какие очередные вершины покорили языковые нейросетки, и почему они уже через месяц совершенно точно оставят лично вас без работы. При этом мало кто понимает — а как вообще нейросети вроде ChatGPT работают внутри? Так вот, устраивайтесь поудобнее: в этой статье мы наконец объясним всё так, чтобы понял даже шестилетний гуманитарий!
Плагин для анализа планов PostgreSQL в IDE JetBrains и его разработка
Medium
11 min
Tutorial

Для пользователей explain.tensor.ru - нашего сервиса визуализации PostgreSQL-планов, мы создали плагин "Explain PostgreSQL" для всех IDE от JetBrains, теперь есть возможность форматировать запросы и анализировать планы непосредственно в IDE.
Как использовать плагин и детали о его разработке читайте ниже.
Четыре метрики, изменившие мой проект
9 min
Case
Привет, Хабр! Я Федор Щудло, team lead и fullstack-разработчик. Всего я в разработке 15 лет, из них 11 в роли team lead.
Три года назад я сменил работу и занялся проектом, состояние которого можно описать кратко: ему 25 лет.
За этот долгий срок проект пережил несколько слияний и разделений компании, означающих серьезные потери людей, знаний, и даже исходников от некоторых сервисов по юридическим соображениям.
На проекте были благополучные периоды, когда были созданы очень крутые и амбициозные вещи. Но были также периоды, когда команды еле хватало на выполнение самых срочных задач. И в это время многие сделанные или не доделанные большие штуки изрядно обветшали.
Как результат, разработка шла с большими накладными расходами (все делали долго), и с высокими рисками (выкатили и разломали прод). А команда при этом работала на износ.
Но за три прошедших года мы с командой кардинально изменили ситуацию. В этой статье я расскажу про самую значимую перемену — простую, но кратно снизившую и накладные расходы, и риски. А это уже открыло дорогу сотням маленьких изменений, в итоге преобразивших проект.
Процесс разработки приложения Python по дедупликации файлов с использованием контрольных сумм
Easy
16 min

История начинается с несложной задачи и небольшого Python приложения.
Несложная задача это периодическое удаление дубликатов файлов из указанных каталогов. Изначально она возникла из следующих условий. Есть домашнее хранилище фотографии и видео, в котором определен порядок хранения файлов по тематике, датам и т. д. И есть источники для пополнения этого хранилища: смартфоны, фотоаппараты, контент из сети, электронной почты и т. д. Синхронизации источников контента и хранилища нет. Периодически со смартфонов и фотоаппаратов скидываются все хранящиеся там файлы на жесткий диск компьютера, и получается набор каталогов, в которых оказываются как те файлы, что уже есть в хранилище, так и новые файлы. И чтобы поместить в хранилище новые файлы, их нужно каким‑то образом отделить их от тех, что уже сохранены. Самый простой способ, который пришел в голову, это удалить дубликаты из каталогов «пополнения», а с остатком уже работать.
С источников файлы не удаляются пока в этом не появится острая необходимость, в первую очередь потому, что это «естественная» резервная копия. Ну и бывает удобно иметь какие‑то фотографии и видео у себя под рукой.
В процессе своего повествования, постараюсь пояснить принятые мной решения, некоторые из которых прямо напрашиваются на решение иным способом.
Долгоиграющие приложения на PHP
Medium
15 min
Review

Мы часто сталкиваемся с задачами, которые требуют работы нашего кода дольше, чем длится простой HTTP-запрос. Это могут быть как выгрузки данных для интеграции с партнёрами, так и просто приложения, которые должны реагировать на события в системе в момент их появления. Конечно, можно использовать другие языки программирования, но это увеличит стек и усложнит систему.
Меня зовут Александр Пряхин, я TechUnit Lead в Авито. В IT работаю уже 14 лет. Из них 8 лет руковожу командами. Параллельно с этим преподаю и менторю. Сегодня разберём, как готовить демонов на PHP — от А до Я, и почему это актуально.
SQL миграции в Postgres. Часть 2
Medium
17 min
FAQ
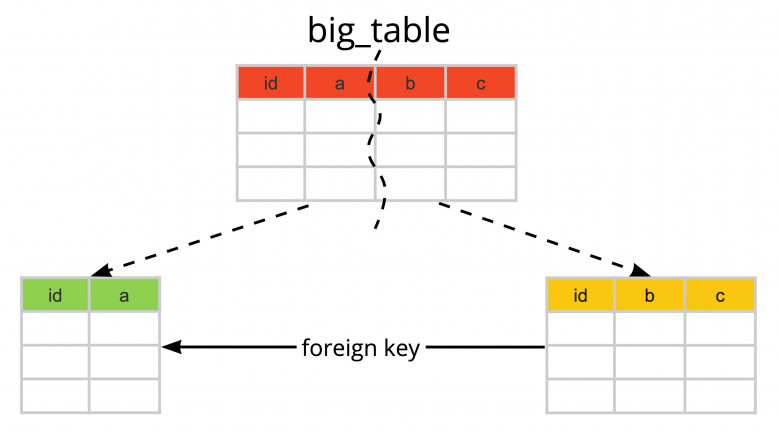
В первой части мы рассмотрели базовые операции, такие как добавление новых атрибутов, создание индексов и ограничений и т.д.
Эта статья посвящена двум более сложным миграциям:
- обновление большой таблицы
- разделение таблицы на две
Рассмотрим подходы, которые позволяют провести миграции с минимальным простоем для приложения.
Пайплайн для создания классификации текстовой информации
10 min

Привет, Хабр!
Меня зовут Дарморезов Вадим, я Data Scientist и участник профессионального сообщества NTA. Актуальность работы с большими объемами текстовой информации ещё долгое время (а может быть и всегда) будет неоспорима. При этом спектр задач весьма вариативен – от задач по поиску именованных сущностей, до классификации и кластеризации текстов обрабатываемых документов.
Представим ситуацию. Перед вами важная задача – классифицировать огромный поток входящих обращений сотрудников/клиентов для дальнейшего анализа профильными сотрудниками на предмет отклонений и для построения интересующих статистик. Первое решение, приходящее в голову – в ручном режиме просматривать обращения и проводить их классификацию. Спустя пару часов, приходит осознание того, что решение было не самым правильным и так задачу не выполнить в срок. Как же тогда поступить? Именно об этом будет следующий пост.
Установка сервера 1С, Postgresql и терминального сервера для клиентских приложений 1С на ОС Fedora Linux
36 min
На настоящий момент фирма 1С предоставляет возможность установки своего основного программного продукта на ОС Windows, Linux и MacOS (только клиентского приложения).
На официальном портале 1С зарегистрированный пользователь может скачать установочные наборы программ для этих операционных систем. С системами из семейства ОС Windows в данном случае есть достаточно большая ясность, они поддерживаются хорошо, так как имеют наибольшее распространение среди пользователей.
Однако, сама фирма 1С в своей документации и справочных материалах довольно прозрачно намекает, что ОС Windows далеко не единственный вариант установки ПО, в особенности серверной части и что ОС Linux гораздо более предпочтительна в качестве серверной ОС.
На портале 1С мы можем найти разные наборы установочных пакетов для 64-битных и 32-битных систем, для систем из семейства Linux, основанных на deb-пакетах (для системы Debian и её производных — Ubuntu, Mint и других) и основанных на rpm-пакетах (для ОС RedHat и её производных — CentOS, Suse, Fedora и других).
Но при более тщательном изучении документации, можно столкнуться со следующим интересным моментом.
Для того, чтобы установить систему 1С в клиент-серверном варианте, требуется установка не только самого сервера 1С, но и сервера СУБД. Начнём установку именно с этого, так как без работоспособной базы данных устанавливать сервер 1С не имеет смысла.
Вариантов для выбора СУБД весьма немного. Система 1С может работать всего лишь с 4-мя различными СУБД: Microsoft SQL Server, PostgreSQL, IBM DB2 и Oracle Database. Все эти СУБД могут быть установлены на Linux, однако в полноценном варианте Microsoft SQL Server, IBM DB2 и Oracle Database являются платными коммерческими продуктами с немалой стоимостью. А на настоящий момент все эти три корпорации с РФ не работают (Microsoft, IBM, Oracle). У PostgreSQL тоже есть платная версия, но той версии, которая распространяется как свободный и открытый программный продукт, вполне достаточно для работы с сервером 1С. Поэтому при использовании свободной ОС Linux выбор в первую очередь, конечно, падает на PostgreSQL.
Запросы в PostgreSQL: 2. Статистика
19 min
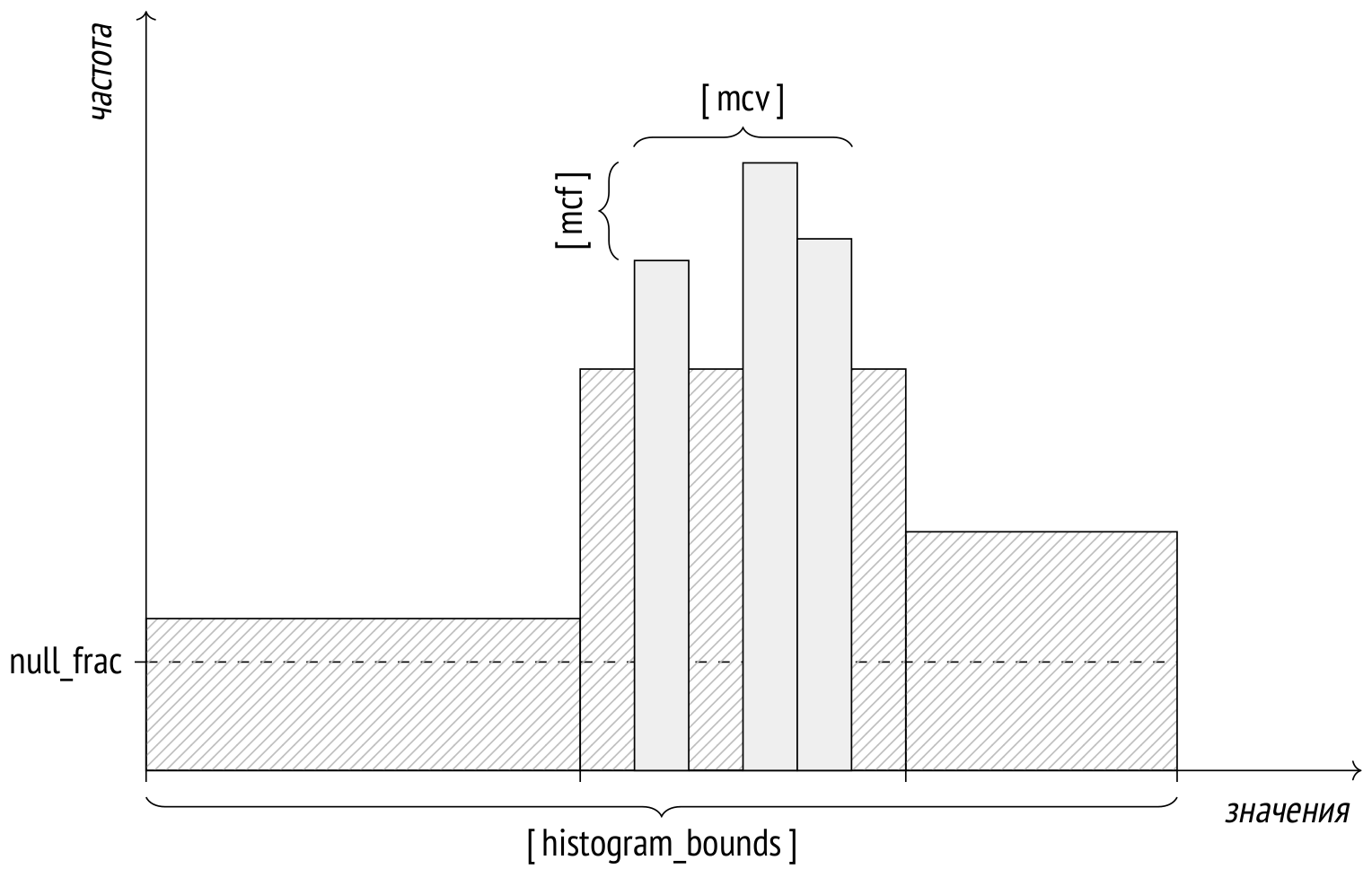
В прошлый раз я рассказал об этапах выполнения запросов. Прежде чем переходить к тому, как работают различные узлы плана (способы доступа к данным и методы соединения), надо разобраться с той основой, на которую опирается стоимостной оптимизатор — со статистикой.
Как обычно, я буду приводить примеры из демобазы. В этой статье будет довольно много планов выполнения, но про их составные части я буду рассказывать только в следующих статьях. Здесь же нас в первую очередь будут интересовать оценки количества строк (кардинальности), то есть числа, указанные в верхней строке плана в позиции rows.
Алгоритмы быстрого умножения чисел: от столбика до Шенхаге-Штрассена
Medium
26 min

При написании высокоуровневого кода мы редко задумываемся о том, как реализованы те или иные инструменты, которые мы используем. Ради этого и строится каскад абстракций: находясь на одном его уровне, мы можем уместить задачу в голове целиком и сконцентрироваться на её решении.
И уж конечно, никогда при написании a * b мы не задумываемся о том, как реализовано умножение чисел a и b в нашем языке. Какие вообще есть алгоритмы умножения? Это какая-то нетривиальная задача?
В этой статье я разберу с нуля несколько основных алгоритмов быстрого умножения целых чисел вместе с математическими приёмами, делающими их возможными.
Как мы сокращаем время простоя при установке обновлений схемы базы данных. Советы разработчикам
Medium
30 min
Review

Привет! Я работаю в компании Bercut, которая более 20 лет занимается разработкой и поддержкой ПО для операторов сотовой и фиксированной связи. Сегодня я хочу рассказать о наших подходах к сокращению времени простоя продуктивного комплекса при установке обновлений схемы данных на СУБД Oracle. Целевая аудитория — начинающие и продолжающие разработчики, которым интересно узнать о различных вариантах распараллеливания и ускорения работы DDL, DML и прочих штуках, облегчающих процесс отладки и установки.
Как поместить весь мир в обычный ноутбук: PostgreSQL и OpenStreetMap
29 min
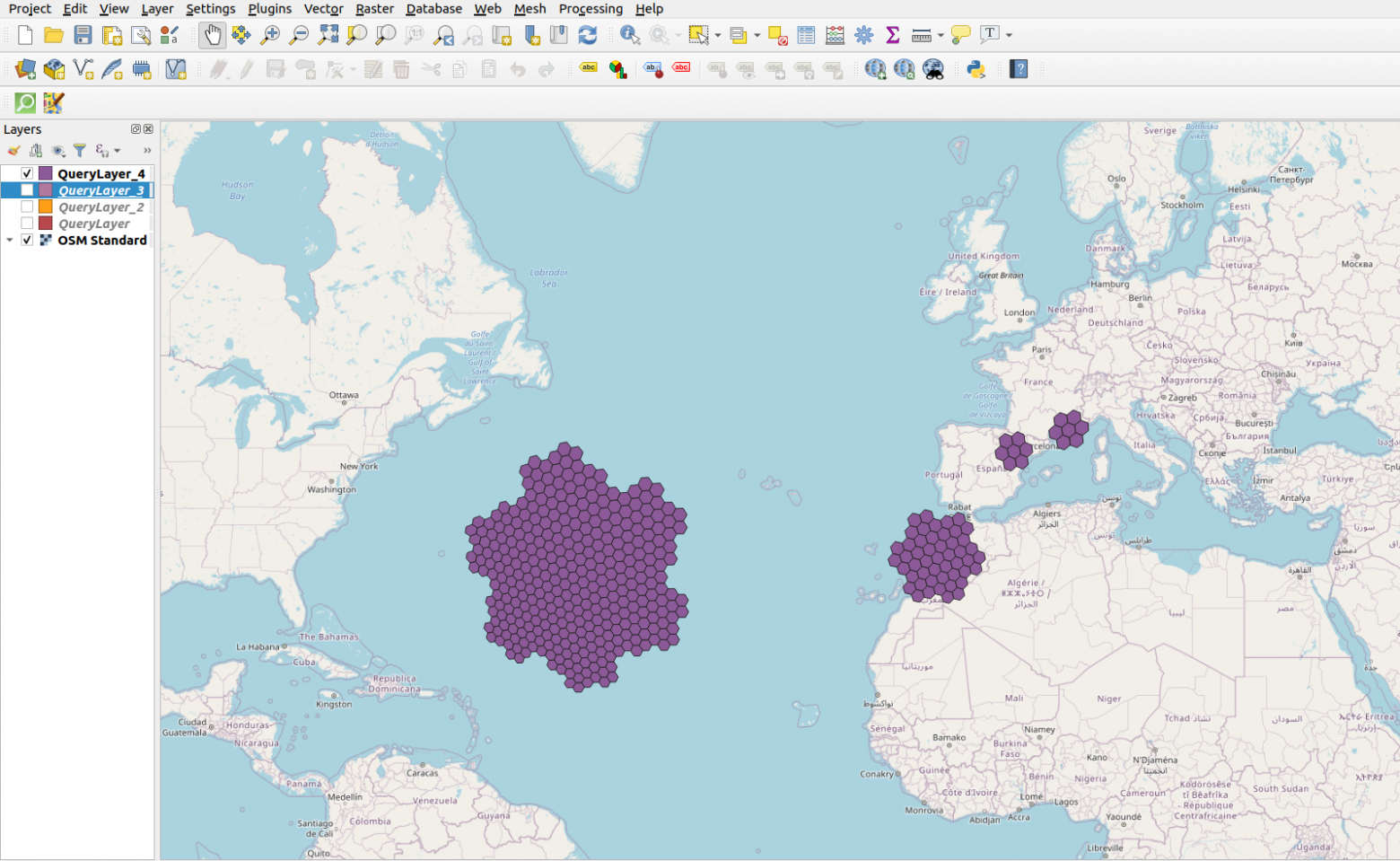
Когда человек раньше говорил что он контролирует весь мир, то его обычно помещали в соседнюю палату с Бонапартом Наполеоном. Надеюсь, что эти времена остались в прошлом и каждый желающий может анализировать геоданные всей земли и получать ответы на свои глобальные вопросы за минуты и секунды. Я опубликовал Openstreetmap_h3 — свой проект, который позволяет производить геоаналитику над данными из OpenStreetMap в PostGIS или в движке запросов, способном работать с Apache Arrow/Parquet.
Первым делом передаю привет хейтерам и скептикам. То что я разработал — действительно уникально и решает проблему преобразования и анализа геоданных используя обычные и привычные инструменты доступные каждому аналитику и датасаенс специалисту без бигдат, GPGPU, FPGA. То что выглядит сейчас простым в использовании и в коде — это мой личный проект в который я инвестировал свои отпуска, выходные, бессонные ночи и уйму личного времени за последние 3 года. Может быть я поделюсь и предысторией проекта и граблями по которым ходил, но сначала я все же опишу конечный результат.
Первый пост не претендует на монографию, начну с краткого обзора...
Парсим ГАР БД ФИАС в удобный формат в питоне. Бесплатно, без регистрации и СМС
8 min
Tutorial

Если вам зачем-то понадобилась полная адресная база России, то самый простой и дешевый способ ее заполучить — это скачать на сайте налоговой. Да, вот так вот просто все. Ну почти.
Да, это полная официальная адресная база России, просто в открытом доступе, никто ничего не спрашивает, просто раздают. Сделали на наши налоги, и честно всем, как скамейку в парке, отдают в пользование. Прекрасно? Да!
"В чем же подвох?", — спросите вы, прищурившись.
Кратко: формат ужасен, документация очень плоха и должного единообразия данных не наблюдается, чем успешно пользуются коммерческие компании, перепродающие бесплатные данные (иногда пылесосят имейлы). Но такую несправедливость можно исправить.
Топ полезных SQL-запросов для PostgreSQL
7 min

Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.
Типы таблиц в PostgreSQL: logged, unlogged и temporary tables
11 min

В PostgreSQL существует большое количество разных типов таблиц. Каждая из них предназначена для решения конкретных задач. Самая распространённая и известная — heap table или стандартная таблица. Про её структуру я рассказывал в прошлой статье. Стандартная таблица позволяет хранить строки, обновлять данные, делать OLAP и OLTP-запросы.
Тем не менее, существует ещё целый ряд таблиц, про которые просто забывают. На мой взгляд, интересные таблицы сейчас — это нежурналируемые и временные таблицы. В этой статье мы поговорим именно про них и сравним их с журналируемыми таблицами.
Блокчейн мало где применим
7 min
Translation

Любители криптовалют часто говорят, что «реальная инновация — это не биткойн, а блокчейн». Популярность блокчейнов постоянно растёт. В какой-то момент используемые блокчейны перестали называть просто «технологией блокчейна», они превратились в «web3». Подразумевается, что блокчейны имеют столь широкую сферу применений, что они заменят современный веб в том виде, в котором мы его знаем.
Однако блокчейны — это не технология общего назначения: они имеют очень ограниченные и специфические способы применения. И использование их в децентрализованных валютах не первый пример из множества, он вполне может оказаться и одним из немногих.
Не очень большие данные
21 min
В статье будут рассмотрены возможности, предоставляемые встроенным или декларативным секционированием в 12 версии PostgreSQL. Демонстрация подготовлена для одноименного доклада на конференции HighLoad++Siberia 2019 (upd: появилось видео с докладом).
Все примеры выполнены на недавно появившейся бета-версии:
Все примеры выполнены на недавно появившейся бета-версии:
=> SELECT version();
version
------------------------------------------------------------------------------------------------------------------
PostgreSQL 12beta1 on i686-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.10) 5.4.0 20160609, 32-bit
(1 row)