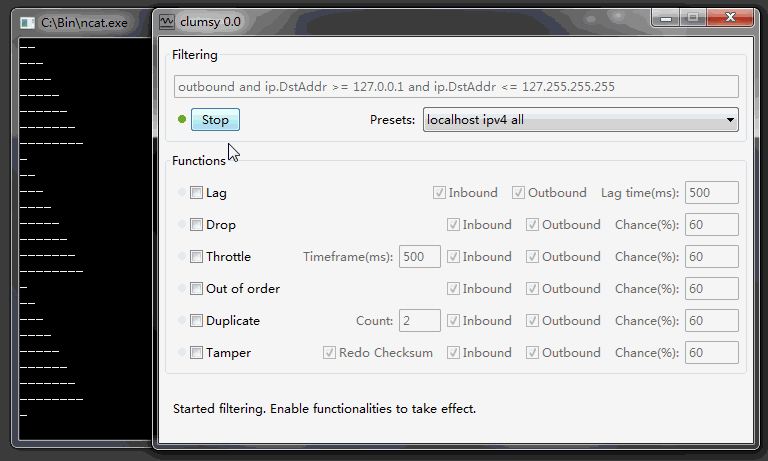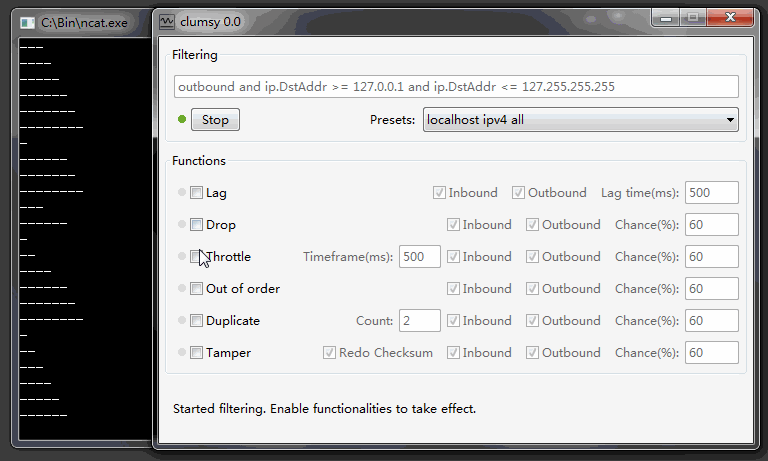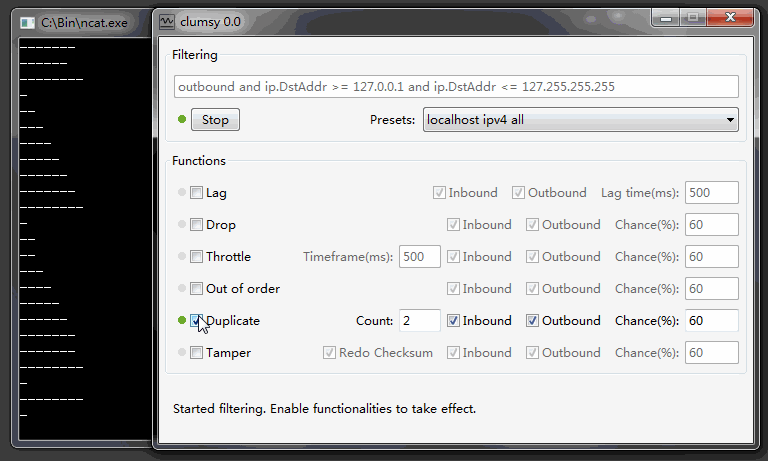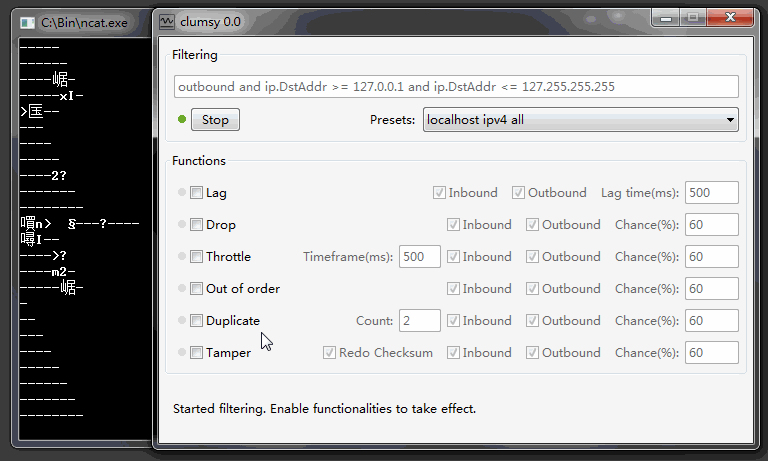
Статья для тех, кто боится слова template в C++. Вводная информация с примерами и их подробным разбором.

User
Статья для тех, кто боится слова template в C++. Вводная информация с примерами и их подробным разбором.
После недавней статьи о шаблонах С++ для начинающих осталось жгучее желание показать что-нибудь похожее, но на практическом примере, да так, чтобы и порог входа был не высоким, и чтобы скучно не было. А так как в голове крутится задача перевода чего бы то ни было в строку, то этим и предлагаю заняться всем, кто хочет потрогать компилятор за шаблоны.


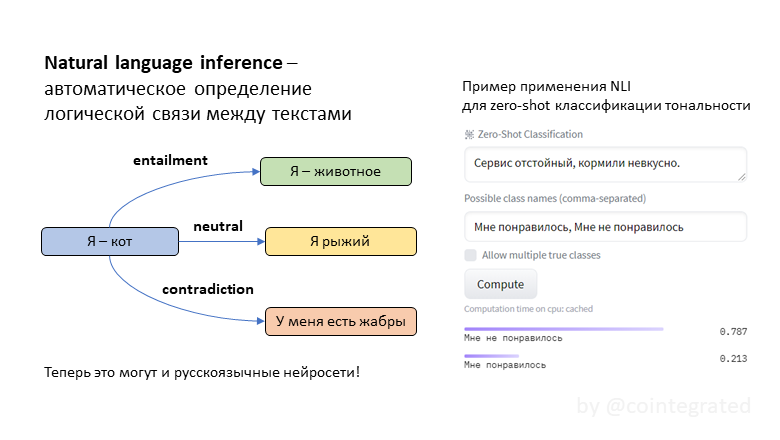
NLI (natural language inference) – это задача автоматического определения логической связи между текстами. Обычно она формулируется так: для двух утверждений A и B надо выяснить, следует ли B из A. Эта задача сложная, потому что она требует хорошо понимать смысл текстов. Эта задача полезная, потому что "понимательную" способность модели можно эксплуатировать для прикладных задач типа классификации текстов. Иногда такая классификация неплохо работает даже без обучающей выборки!
До сих пор в открытом доступе не было нейросетей, специализированных на задаче NLI для русского языка, но теперь я обучил целых три: tiny, twoway и threeway. Зачем эти модели нужны, как они обучались, и в чём между ними разница – под катом.
Не так давно Сбер, а затем и Яндекс объявили о создании сверхбольших русских языковых моделей, похожих на GPT-3. Они не только генерируют правдоподобный текст (статьи, песни, блоги и т. п.), но и решают много разнообразных задач, причем эти задачи зачастую можно ставить на русском языке без программирования и дополнительного обучения — нечто очень близкое к «универсальному» искусственному интеллекту. Но, как пишут авторы Сбера у себя в блоге, «подобные эксперименты доступны только компаниям, обладающим значительными вычислительными ресурсами». Обучение моделей с миллиардами параметров обходится в несколько десятков, а то сотен миллионов рублей. Получается, что индивидуальные разработчики и маленькие компании теперь исключены из процесса и могут теперь только использовать обученные кем-то модели. В статье я попробую оспорить этот тезис, рассказав о результатах попытки обучить модель с 30 миллиардами параметров на двух картах RTX 2080Ti.
 Эдвард Мэтью Ворд. Пузырь Компании Южных морей. 1847 г. Галерея Тейт, Лондон.
Эдвард Мэтью Ворд. Пузырь Компании Южных морей. 1847 г. Галерея Тейт, Лондон.



Привет, Хабр! Представляю вашему вниманию перевод статьи "Web2Text: Deep Structured Boilerplate Removal" коллектива авторов Thijs Vogels, Octavian-Eugen Ganea и Carsten Eickhof.
Веб-страницы являются ценным источником информации для многих задач обработки естественного языка и поиска информации. Эффективное извлечение основного содержимого из этих документов имеет важное значение для производительности производных приложений. Чтобы решить эту проблему, мы представляем новую модель, которая выполняет классификацию и маркировку текстовых блоков на странице HTML как шаблонных блоков, или блоков содержащих основной контент. Наш метод использует Скрытую Марковскую модель поверх потенциалов, полученных из признаков объектной модели HTML-документа (Document Object Model, DOM) с использованием сверточных нейронных сетей (Convolutional Neural Network, CNN). Предложенный метод качественно повышает производительность для извлечения текстовых данных из веб-страниц.

{kind=link}