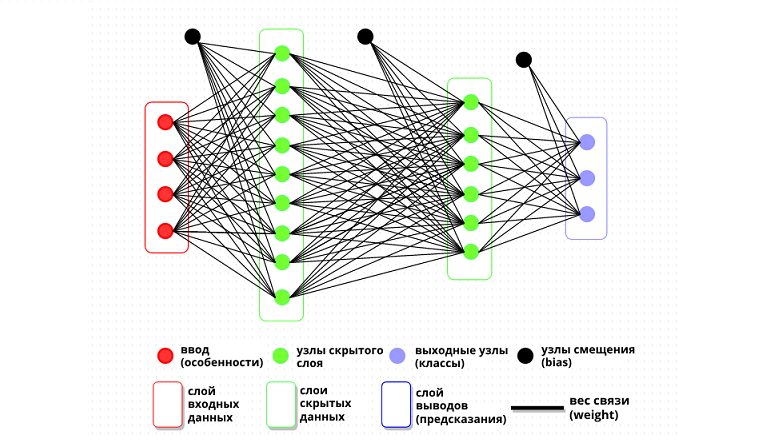
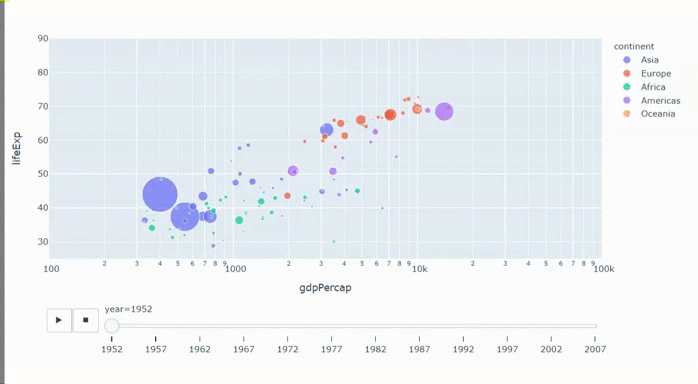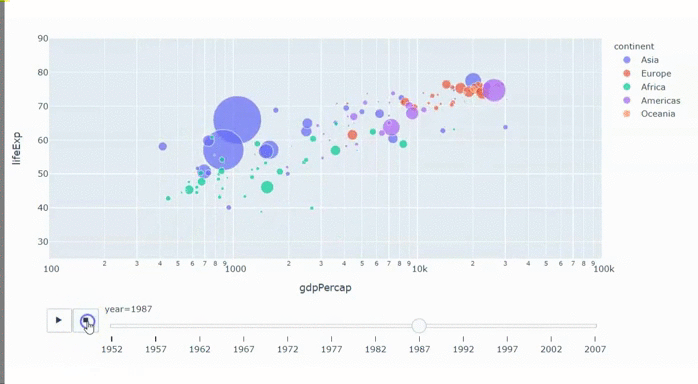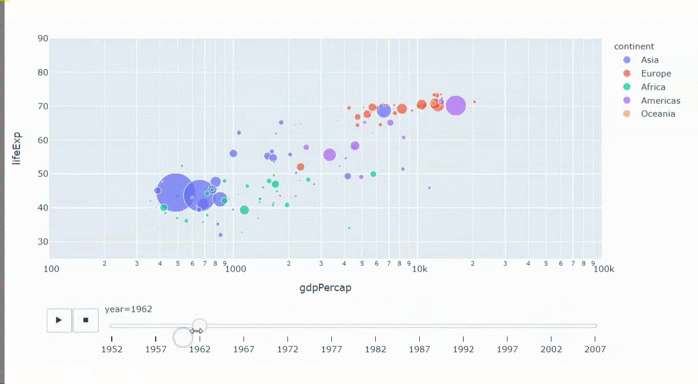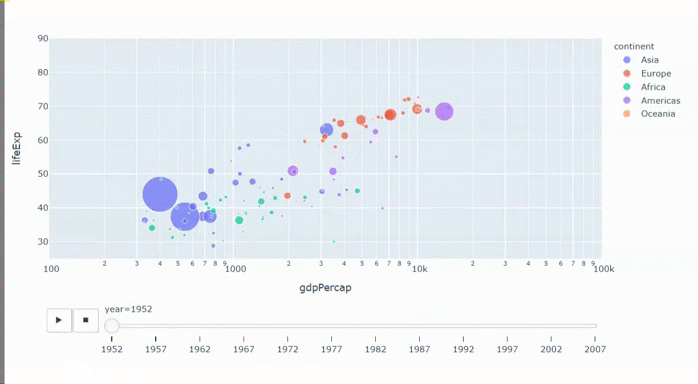
Синий кит — отличный пример того, как проектирование сложного проекта пошло не по плану. Кит внешне похож на рыбу, но он млекопитающее: кормит детенышей молоком, у него есть шерсть, а в плавниках до сих пор сохранились кости предплечья и кистей с пальцами, как у сухопутных. Он живет в океанах, но не может дышать под водой, поэтому регулярно поднимается на поверхность глотнуть воздуха, даже когда спит. Кит самое большое животное в мире, длиной с девятиэтажный дом, а массой как 75 автомобилей Volkswagen Touareg, но при этом не хищник, а питается планктоном.
Когда разработчики работали над китом, то не стали писать все с нуля, а использовали наработки из старых проектов. Он словно слеплен из несовместимых частей кода, которые не тестировались, а все проектирование сводилось к выбору фреймворка и к срочному «велосипедированию» уже в продакшне. В итоге получился проект красивый внешне, но с кусками дремучего легаси и костылей под капотом.

Для создания проектов, которые помогают бизнесу зарабатывать, а не похожих на морское животное, которое не может дышать под водой, есть DDD. Это подход, который фокусируется не на инструментах или коде, а на изучении предметной области, отдельных бизнес-процессов и на том, как код или инструменты работают для бизнес-логики.
Что такое DDD и какие инструменты в нем есть, мы расскажем в статье на основе доклада
Артема Малышева. Подход DDD в Python, инструменты, подводные камни, контрактное программирование и проектирование продукта вокруг решаемой проблемы, а не используемого фреймворка — все это под катом.