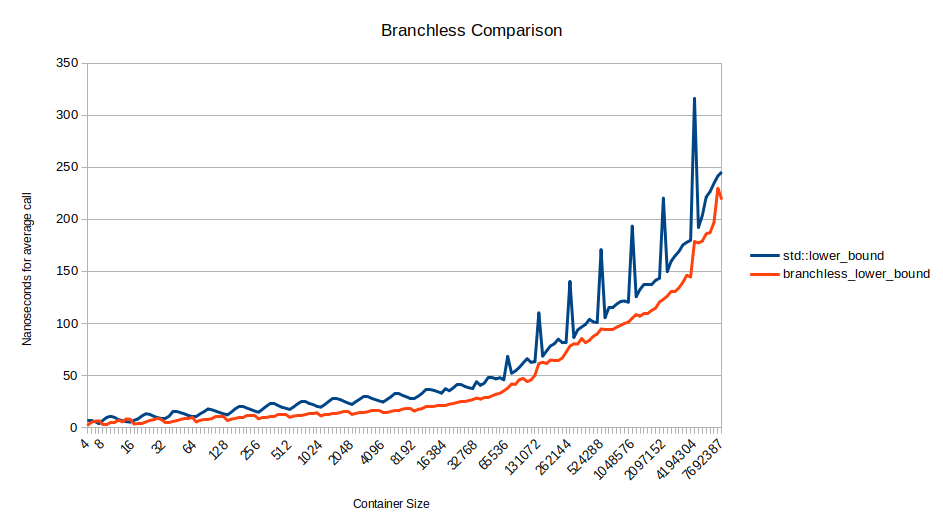
Недавно я прочитал пост Алекса Мускара Beautiful Binary Search in D. В нём описывается алгоритм двоичного поиска под названием «алгоритм Шора». Я никогда не слышал о нём и его невозможно загуглить, но увидев алгоритм, я думал только об одном: «он без ветвления». Кто знал, что может существовать двоичный поиск без ветвления? Поэтому я занялся его трансляцией в алгоритм для итераторов C++, не требующий индексации на основе единицы или массивов фиксированного размера.
В GCC он более чем в два раза быстрее, чем std::lower_bound, который сам по себе — очень высококачественный двоичный поиск. Цикл поиска прост, а генерируемый ассемблерный код красив. Меня потрясло, что он существует, но им, похоже, никто не пользуется.