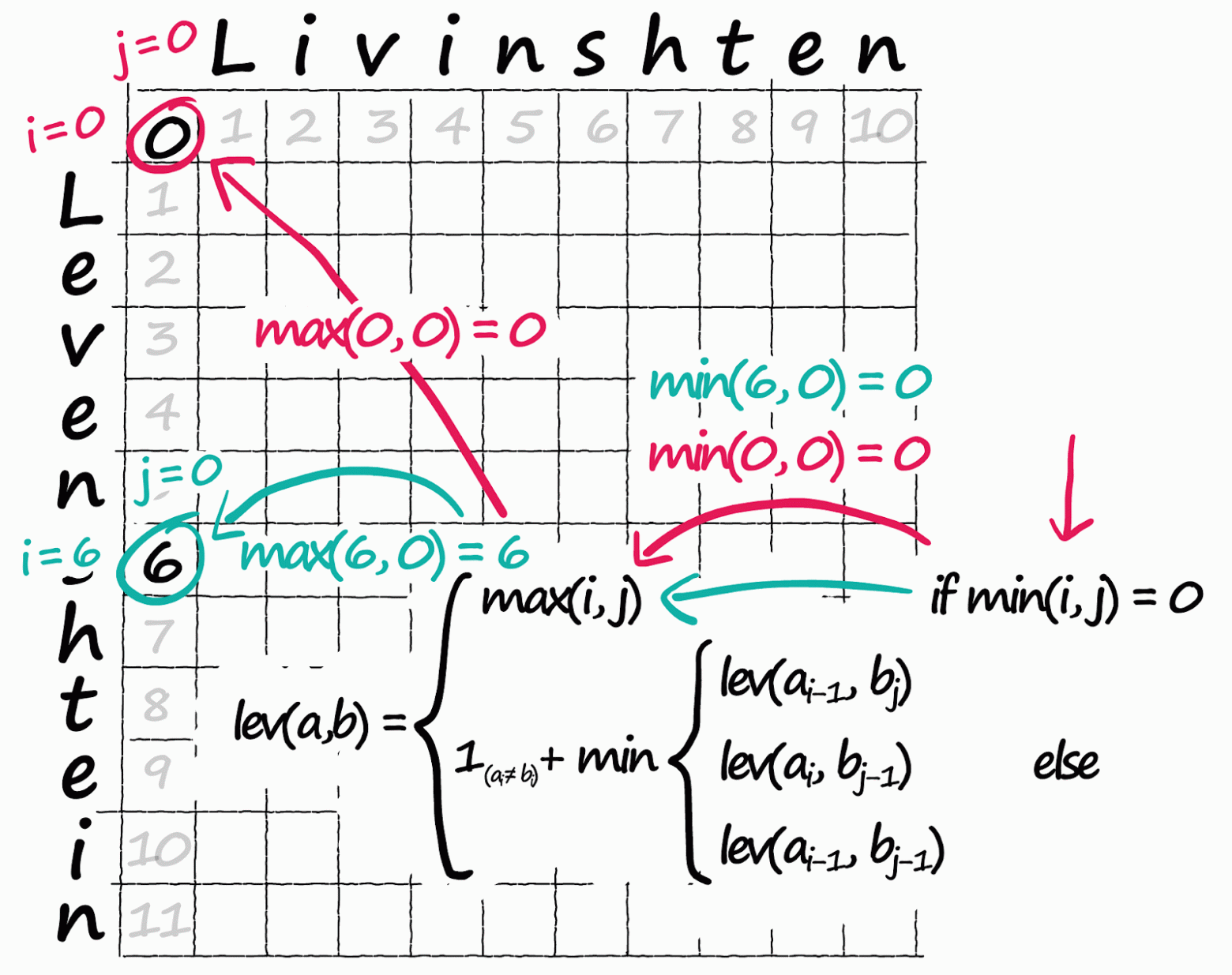
В материале, переводом которого мы решили поделиться к старту курса о машинном и глубоком обучении, простым языком рассказывается о семантическом поиске, статья охватывает шесть его методов; начиная с простых сходства по Жаккару, алгоритма шинглов и расстояния Левенштейна, автор переходит к поиску с разреженными векторами — TF-IDF и BM25 и заканчивает современными представлениями плотных векторов и Sentence-BERT. Простые примеры сопровождаются кодом и иллюстрациями, а в конце вы найдёте ссылки на соответствующие блокноты Jupyter.