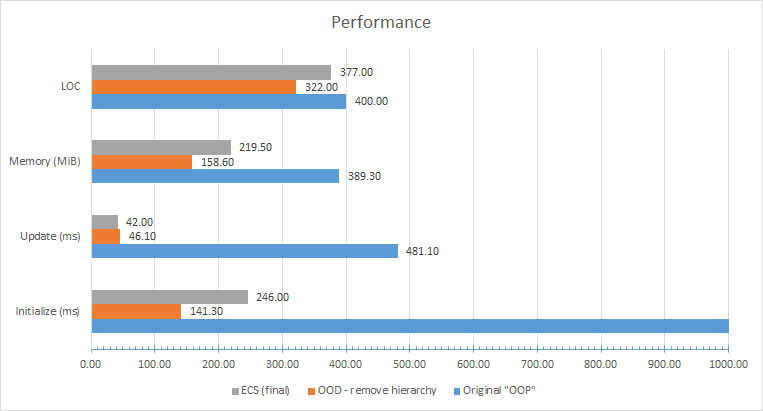
Я собрал худшее из худшего! Оказалось, что хороших практик — море, и разбираться в них долго, а вот плохих, реально плохих, — считаные единицы.
Понятно, что плохие практики не отвечают на вопрос: «А как делать-то?» — но они помогают быстро разобраться в том, как не делать.
Мы часто спорим про архитектуру и хотим друг от друга знания разных правильных практик проектирования, лучшего мирового опыта и вот этого всего. Понятно, что в реальном мире это совсем-совсем не так. И худших практик часто достаточно, чтобы начать договариваться, как не надо.
Итак, мой любимый антишаблон — поток лавы. Начинается всё просто: в новый проект можно добавить код из старого проекта копипастой. Он там делал что-то полезное, пускай делает почти то же самое полезное в новом проекте. Вот только нужно закомментить один кусок, а в другом месте — чуть дописать. Примерно через три переноса без рефакторинга образуются большие закомментированные участки, функции, которые работают только с частью параметров, сложные обходы вроде «выльем воду из чайника, выключим газ, и это приведёт нас к уже известной задаче кипячения чайника» и так далее.
Это если команда одна. А если разработчики на пятом проекте новые, то начинается самое весёлое — этот сталактит надо ещё прочитать.
Очень часто я вижу лава-код в проектах аутсорсинговых компаний, потому что они используют свою кодовую базу по разным заказчикам как такой своеобразный иннерсорс. А «междисциплинарный» код как раз хорошо обрастает отключаемыми участками и переопределяемыми функциями.