Это вторая часть статьи о том, как правильно общаться и избежать ошибок в процессе код-ревью. Здесь мы поговорим о том, как довести ревью до конца и избежать неприятных конфликтов.
Основы изложены в первой части, так что рекомендую начать с неё. Но если не терпится, вот её краткое содержание: хороший рецензент не только ищет баги, но и обеспечивает добросовестную обратную связь, чтобы помочь коллеге повысить свой уровень.
Моё худшее код-ревью
Худшее код-ревью в моей жизни было для бывшей коллеги, назовём её Мэллори. Она начала работать в компании за несколько лет до меня, но только недавно перешла в мой отдел.
Каждый изучающий английский язык наверняка слышал хрестоматийные шутки про разговоры о погоде. В нашей культуре пустые разговоры, которыми, по сути, является small talk, не очень приняты. Вот светская беседа – другое дело. Но прежде чем дойдет до полноценной беседы, разговор все-таки нужно завязать. А если вам предстоит путешествие за границу, то нужно быть морально готовыми к тому, что там без small talk не обойдется даже поход в магазин. Если вам трудно говорить ни о чем и на отвлеченные темы, то эта статья для вас.
Многие взрослые студенты начинают подтягивать свой английский в первую очередь для работы. Английский уже давно является языком международного бизнеса: где бы вы ни находились, с какими бы компаниями ни вели дела, чаще всего все переговоры и сделки по продаже ведутся на английском языке. Курсы бизнес-английского обычно знакомят вас с самой ходовой лексикой, например, названием должностей, структурой компаний и навыками бизнес-переписки. Но чаще всего вам придется вести переговоры, будь то переговоры по телефону или лично. С чего начать планирование переговоров и нужно ли их вообще планировать? Какая лексика потребуется в самом начале? Уместен ли small talk в бизнес-переговорах? Разбираемся с основами.
В последнее время я читал статьи о лучших практиках code review и заметил, что эти статьи фокусируются на поиске багов, практически игнорируя другие компоненты ревью. Конструктивное и профессиональное обсуждение обнаруженных проблем? Неважно! Просто найди все баги, а дальше само сложится.
Так что у меня случилось откровение: если это работает для кода, то почему не будет работать в романтичных отношениях? Итак, встречайте новую электронную книгу, которая поможет программистам в отношениях со своими возлюбленными (обложка на иллюстрации слева).
Моя революционная книга обучит вас проверенным техникам по выявлению максимального количества недостатков в своём партнёре. Книга не затрагивает следующие области:
• Обсуждение проблем с сочувствием и пониманием.
• Помощь партнёру в устранении недостатков.
Насколько я могу понять из чтения литературы по code review, эти части отношений настолько очевидны, что вообще не стоят обсуждения.
Как вам нравится такая книжка? Предполагаю, что она вам не очень по душе.
Является продолжением предыдущих публикаций. Не секрет, что при упоминании R в числе используемых инструментов вторым по популярности является вопрос о возможности его применения в «промышленной разработке». Пальму первенства в России неизменно держит вопрос «А что такое R?»
Попробуем разобраться в аспектах и возможности применения R в «промышленной» разработке.
Ранее мы говорили о разработке системы квантовой связи и о том, как из простых студентов готовят продвинутых программистов. Сегодня мы решилие еще раз (1, 2) взглянуть в сторону темы машинного обучения и привести адаптированную (источник) подборку полезных материалов, обсуждавшихся на Stack Overflow и Stack Exchange.
Всю рутину, которую можно отдать роботам, нужно отдать роботам. Большие системы без этого невозможны. В разработке и тестировании очень много похожих задач, которые не требуют высокой квалификации, но отнимают много времени. Человек, который умеет обеспечить разработку, тестирование и деплой – это редкий специалист и его на количество страничек никак не масштабируешь.
В Яндексе тестировщику невозможно без автоматизации. Мы даже развиваем экспериментального робота, который способен брать на себя функциональное тестирование. В какой-то момент мы поняли, что не так много людей осознают, сколько сейчас есть возможностей работать не 12 часов, а головой. Собрав весь свой опыт в тестировании и деплое, мы открыли в питерском офисе Яндекса Школу автоматизации процессов разработки. У нас получилась школа, где каждый, кто пишет код, может получить базовый набор знаний о том, как собрать, запустить и поддерживать сервис в продакшене так, чтобы это стоило недорого.
Курс открывает моя лекция о том, зачем вообще автоматизировать процесс разработки. Из нее вы получите представление о то, что будут рассказывать мои коллеги.
Сейчас занятия закончились, и мы, как и обещали, выкладываем записи лекций, которые перемежаются с мастер-классами, для всех желающих. Понятно, что наш опыт и знания – не 42, но мы надеемся, что они принесут вам пользу.
В докладе рассказывается о том, как мы извлекаем сущности (например, имена людей и географические названия) из текстов и запросов. А также об извлечении фактов, т.е. связей между объектами. Мы рассмотрим несколько подходов к решению этих задач: формулирование правил, составление словарей всевозможных объектов, машинное обучение.
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
Мечта о том, чтобы машина понимала человеческий язык, завладела умами еще когда компьютеры были большими, а их производительность – маленькой. Главная проблема на пути к этому заключается в том, что грамматика и семантика естественных языков слабо поддаются формализации. Кроме того, от языков программирования их отличает присутствие многозначности.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Привет, меня зовут Наталья, я работаю в Яндексе разработчиком в группе извлечения фактов. Весной мы рассказали о том, что такое Томита-парсер и для чего он используется в Яндексе. А уже этой осенью исходники парсера будут выложены в открытый доступ.
В предыдущем посте мы пообещали рассказать, как пользоваться парсером и о синтаксисе его внутреннего языка. Именно этому и посвящен мой сегодняшний рассказ.
Прочитав этот пост, вы узнаете, как составляются словари и грамматики для Томиты, а также, как извлекать с их помощью факты из текстов на естественном языке. Та же информация доступна в формате небольшого видеокурса.
(Части 1, 2, 3) В четвёртой части мы поговорим о проверке грамматики за пределами токенизированных передложений.
Как уже упоминалось, разбиение предложения на токены и POS-разметка уже позволяют создать простой инструмент проверки грамматической корректности текста. По крайней мере, LanguageTool плагин к Open Office работает именно так. Очевидно, что массу ошибок можно выловить на уровне размеченных токенов. Однако также очевидно, что не менее обширные классы ошибок остаются за пределами возможностей нашего модуля. Взять хотя бы такую простую вещь как согласование подлежащего и сказуемого: «дама любил собак», «любил собак дама», «собак дама любил»… как составить паттерн для правила «сказуемое должно иметь тот же род, что и подлежащее?» Даже для английского языка с более-менее чётким порядком слов это трудно, говорить о русском и вовсе не приходится.
(Часть 1, Часть 2) В прошлый раз я преждевременно упомянул токенизацию; теперь можно поговорить и о ней, а заодно и о маркировке частей речи (POS tagging).
Предположим, мы уже выловили все ошибки (какие догадались выловить) на уровне анализа текста регулярными выражениями. Стало быть, пора переходить на следующий уровень, на котором мы будем работать с отдельными словами предложения. Разбиением на слова занимается модуль токенизации. Даже в столь простой задаче есть свои подводные камни. Я даже не говорю о языках вроде китайского и японского, где даже вычленение отдельных слов текста нетривиально (иероглифы пишут без пробелов); в английском или в русском тоже есть над чем подумать. Например, входит ли точка в слово-сокращение или представляет собой отдельный токен? («др.» — это один токен или два?) А имя человека? «J. S. Smith» — сколько здесь токенов? Конечно, по каждому пункту можно принять волевое решение, но в дальнейшем оно может привести к различным последствиям, и это надо иметь в виду.
Примерно так я рассуждал на начальных этапах нашего проекта, теперь же склоняюсь к тому, что в задачах обработки текстов частенько приходится подчиняться решениям других людей. Это будет уже ясно на примере маркировки частей речи.
(Часть 1) Сегодня мы поговорим об уровнях понимания текстов нашей системой, о том, какие ошибки правописания отловить просто, какие не очень просто, а какие запредельно сложно.
Начнём с того, что текст можно рассматривать с двух точек зрения: либо как простую последовательность слов, пробелов и знаков препинания, либо как сеть связанных между собой синтактико-семантическими зависимостями понятий. Скажем, в предложении «я люблю больших собак» можно расставить слова в любом порядке, при этом структура связей между словами будет одна и та же:
Читавшие мои предыдущие публикации знают, что пишу я достаточно редко, но обычно сериями. Хочется собраться с мыслями на заданную тему и разложить их по полочкам, не втискивая себя в прокрустово ложе одной короткой статейки.
На сей раз появился новый повод поговорить об обработке текстов (natural language processing то бишь). Я разрабатываю модуль проверки правописания для одной конторы. На выходе должна получиться функциональность, аналогичная встроенной в MS Word, только лучше :) Не могу пока назвать себя крупным специалистом в этой области, но стараюсь учиться. В заметках постараюсь рассказать о том, куда движется наш проект, как устроен тот или иной этап обработки текста. Может, в комментариях услышу что-нибудь новое/интересное и для себя. Если проекту с этого будет польза — прекрасно. Как минимум, устаканю данные у себя в голове, а это тоже неплохо.
Задача извлечения информации из текста сама по себе не нова: в этом направлении проделано довольно много работы как со стороны крупных компаний aka Яndex и Google, так и со стороны независимых разработчиков. Однако, говорить о том, что данная задача окончательно решена, увы, не приходится. В этой статье я хочу немного упорядочить свои знания по данному вопросу, поверхностно разобрав наработки, с которыми мне недавно пришлось столкнуться.
(Первые части: 123456789). Как говорилось в известной рекламе, «вы не ждали, а мы пришли» :)
За время, прошедшее после публикации девятой части, я прочитал одну хорошую книжку по теме (в to-read списке ещё парочка), множество статей, а также пообщался с несколькими специалистами. Соответственно, накопился новый объём материала, заслуживающий отдельной заметки. Как обычно, знакомлю других, параллельно структурирую знания для себя.
Сразу прошу прощения: эта часть для чтения и понимания достаточно трудна. Ну да, как говорится, не всё коту масленица. Сложным задачам соответствуют сложные тексты :)
Предлагается справочная информация по основным архитектурным стилям веб-приложений с основными терминами по мотивам диссертации Роя Т. Филдинга (автора REST). В первой части предлагается список архитектурных стилей и таблица их сравнения. Во второй планируется описание самих стилей.
(Первые части: 12345678). Да возрадуются минусующие, сегодня представляю вниманию читателей последнюю, по всей видимости, часть «Заметок». Как и предполагалось, мы поговорим о дальнейшем семантическом анализе; также я порассуждаюю немного о том, чем в принципе можно заняться в нашей области и какие есть трудности «научно-политического» характера.
(Первые части: 1234567). В этой части я расскажу о синтактико-семантическом анализаторе — как я его вижу. Обратите, кстати, внимание на часть 7 — она до главной страницы не добралась, так что не уверен, что все интересующиеся её видели.
(Первые части: 123456). Как и обещал вчера, продолжаем обсуждать XDG и движемся к следующим темам. Возможно, мы двигаемся слишком быстро, и действительно имело бы смысл публиковать одну статью раз в два-три дня, чтобы оставалось время всё обсудить. Но, наверно, пока «бензин есть», я буду продолжать писать. А потом можно будет вернуться и обговорить ранее освещённые вопросы. Мне кажется, что в компьютерной лингвистике разные темы настолько тесно связаны друг с другом, что разговор об одной из них без связи с другими малопродуктивен. А мы ещё не обо всём беседовали, так что лучше охватить взглядом как можно больше аспектов компьютерного анализа текста, а потом уже рассуждать о конкретике в рамках общей картины происходящего.








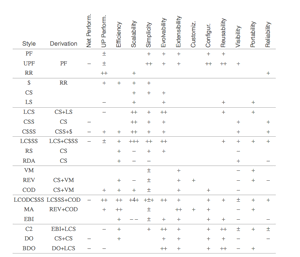 Предлагается справочная информация по основным архитектурным стилям веб-приложений с основными терминами по мотивам диссертации Роя Т. Филдинга (автора REST). В первой части предлагается список архитектурных стилей и таблица их сравнения. Во второй планируется описание самих стилей.
Предлагается справочная информация по основным архитектурным стилям веб-приложений с основными терминами по мотивам диссертации Роя Т. Филдинга (автора REST). В первой части предлагается список архитектурных стилей и таблица их сравнения. Во второй планируется описание самих стилей.