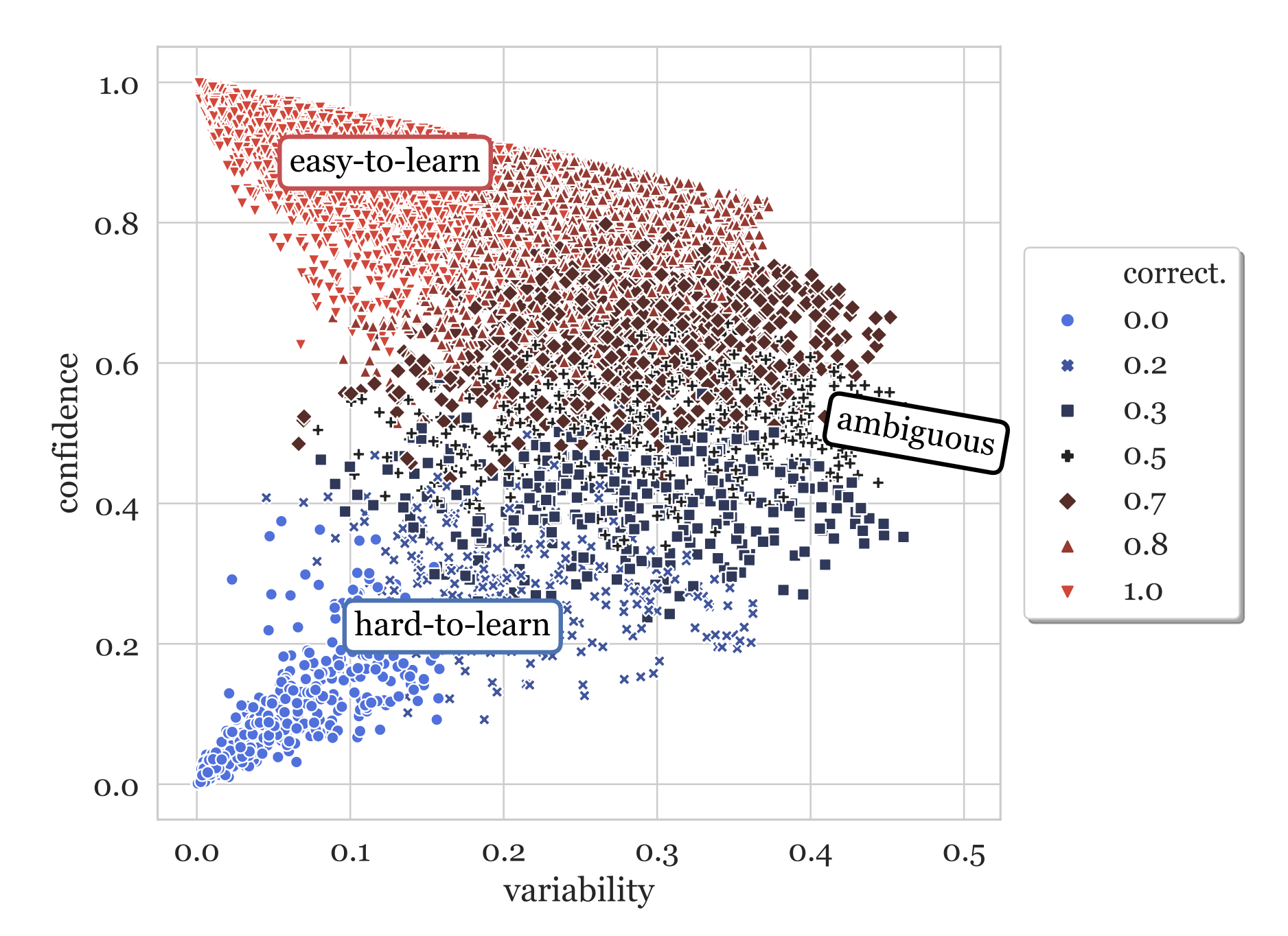
Высококачественные данные — это «топливо» для современных моделей глубокого обучения. Большая часть данных, размеченных под конкретные задачи, создается живыми людьми — аннотаторами, которые занимаются классификацией или проводят RLHF-разметку для LLM alignment. Многие из представленных в этой публикации методов машинного обучения могут помочь улучшить качество данных, но главным остается внимание к деталям и скрупулёзность.
Сообщество разработчиков машинного обучения осознает ценность высококачественных данных, но почему-то складывается впечатление, что «все хотят работать над моделями, а не над данными» (Sambasivan et al. 2021).
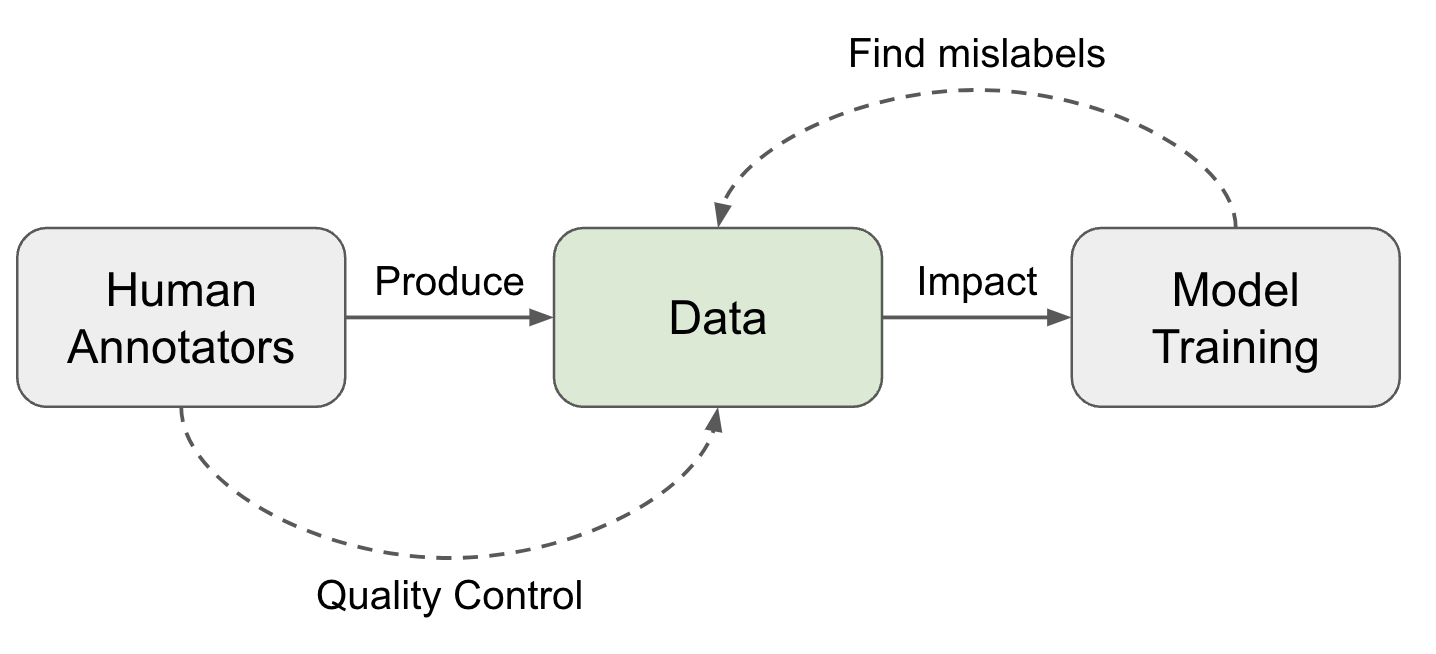
Рисунок 1. Два направления обеспечения высокого качества данных.