

Здравствуйте дорогие хабровчане, в этом посте я хочу показать, как написать свой агрегатор новостей. Конечно, сразу становится очевидно, что это очередное изобретение велосипеда, однако анализируя существующие решения я всё время натыкался на камни преткновения. То они слишком медленно обновлялись, то не было нужных мне источников или часто бывало, что вообще ничего не работало без возможности починить. В итоге я написал своё решение.
Автор статьи приторговывает на бирже, и главной мотивацией было собрать все новости по интересующей теме в одном месте, чтобы не мониторить десяток различных источников вручную.
Текст под катом по большей части технический и будет, скорее всего, интересен читателям, которые сами торгуют на бирже и при этом в IT теме, либо тем, кто сам давно хотел написать агрегатор чего-нибудь.





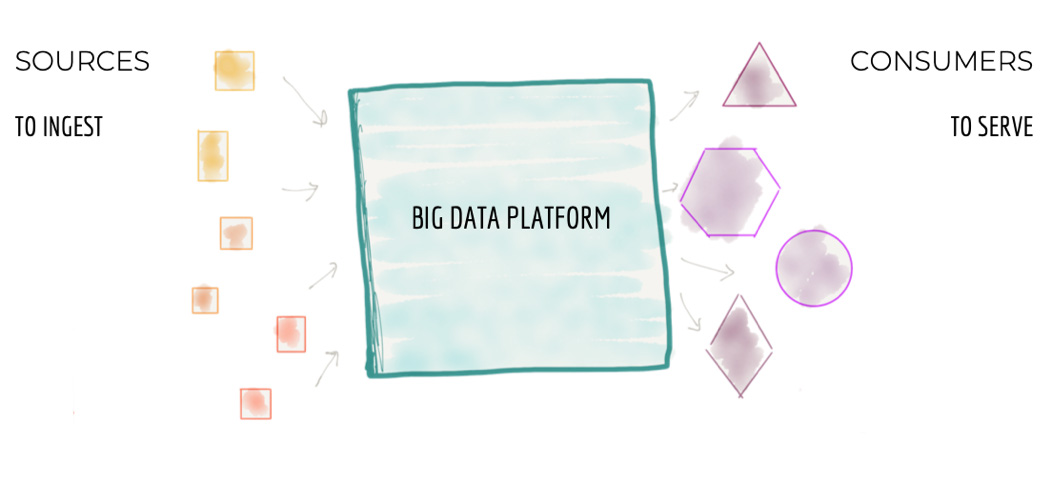

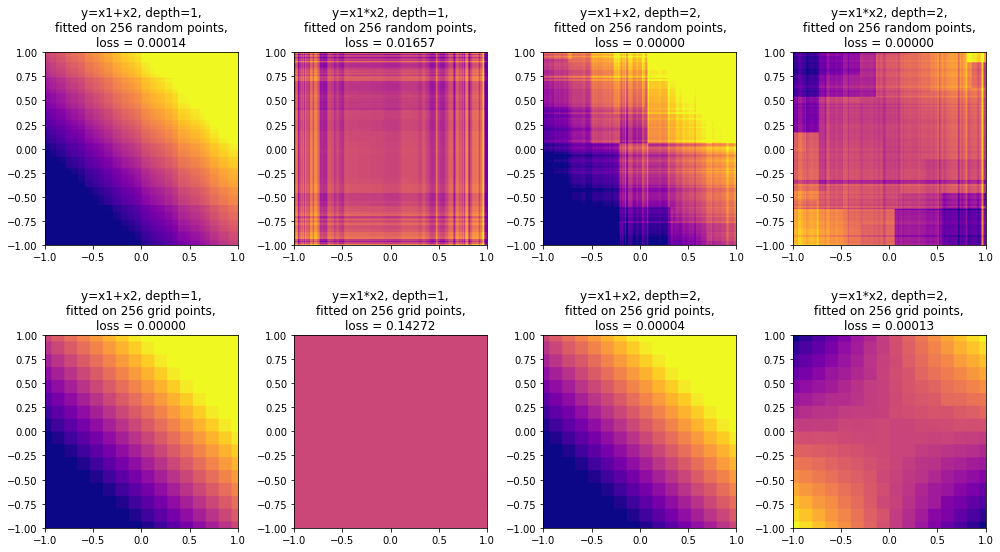
 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.

