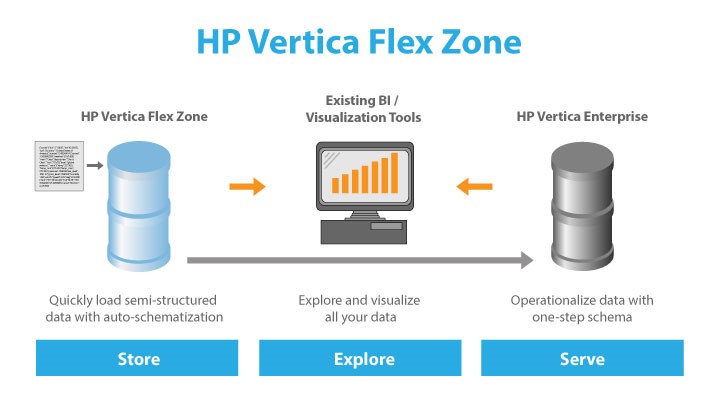
8 августа 2014 года вышла новая версия HP Vertica 7.1. Команда Майкла Стоунбрейкера продолжает утверждать, что работа с большими данными сродни БАМу и продолжает новым версиям выдавать названия с строительной тематикой. Итак, Бульдозером (6 версия) по таблицам данные разровняли, сверху неструктурированными данными во Flex зону приложили (версия 7.0), пришла пора большого Экскаватора повернуть реки вспять. Встречаем версию Dragline 7.1! В этой статье я опишу, что же изменилось в новой версии.
Расширения функциональности проекций
Напомню для тех, кто в курсе и расскажу для тех, кто не знает: проекцией в Vertica называется материализация данных таблицы. Таблица в Vertica это описание структуры таблицы (столбцов), constraints и партиций. А непосредственно данные хранятся в проекциях, которые создаются на таблицы. Проекции чем-то похожи на индексы, они хранят данные по всем или не всем столбцам таблицы. Может быть более одной проекции на таблицу, проекции могут хранить отсегментированные и отсортированные данные по разным правилам. Данные во всех проекциях автоматически обновляются при обновлении записей таблицы. Фактически проекции содержат данные таблицы полностью всех колонок или частично определенных колонок. Жертвуется дисковое место серверов кластера, но значительно ускоряются выборки для разных групп запросов.
Выражения в проекциях
До новой версии в проекциях можно был указать исключительно только колонки таблицы. Это накладывало определенные ограничения на использование проекций. Например, если в запросах часто в фильтрации использовалось выражение по колонкам таблицы, поиск по этому фильтру не был максимально эффективным за счет того, что в проекции не было возможности указать сортировать хранимые данные по выражению. Сортировка же по столбцам выражения вряд ли помогла повысить производительность. Это могло вылиться в достаточно серьезную проблему. В качестве решения потребовалось бы добавить в таблицу новую колонку, в которую можно сохранять результат вычисления. Так же потребовалось изменить алгоритм загрузки в эту таблицу данных первоисточников, чтобы во время загрузки заполнять вычисляемый столбец. Так же пришлось бы перегружать всю таблицу, чтобы заполнить добавленное поле. Если в таблице десятки и сотни миллиардов записей и в нее идет постоянная загрузка, такое решение физически было бы невыполнимо.
В новой версии для проекций введена возможность указать как столбцы, так и выражения:
CREATE PROJECTION sales_proj (sale_id, sale_count, sale_price, sale_value) AS
SELECT sale_id, sale_count, sale_price, sale_count * sale_price
FROM sales
ORDER BY sale_count * sale_price
SEGMENTED BY HASH(sale_id) ALL NODES KSAFE 1;
Следующий запрос к созданной проекции таблицы:
SELECT *
FROM sales_proj_b0
WHERE value > 1000000
ORDER BY value;
при выполнении фактически моментально отдаст результат, используя сортировку выражения.
На такие проекции накладываются следующие ограничения:
- Нельзя использовать функции, которые могут изменить результат (например функцию TO_CHAR, так как она вернет разный результат в зависимости от выставленной кодировки клиента)
- Нельзя использовать служебные мета функции
- Нельзя обновлять записи таблицы оператором MERGE (UPDATE и DELETE разрешены)
Проекции такого типа можно создать и перестраивать на таблицу в любой момент времени, без остановки работы с ней пользователей и загрузки данных. Таким образом, проблема включения вычисляемого столбца в сортировку для повышения производительности запросов более не актуальна.