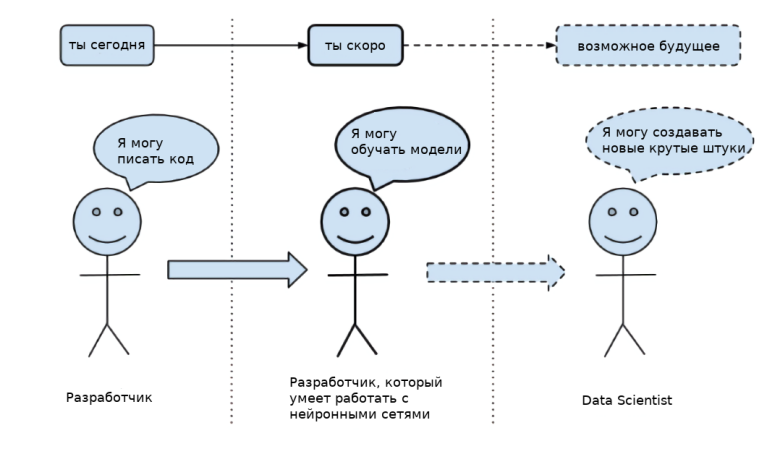
«Цель этого курса — подготовить вас к вашему техническому будущему.»

Привет, Хабр. Помните офигенную статью
«Вы и ваша работа» (+219, 2372 в закладки, 375k прочтений)?
Так вот у Хэмминга (да, да, самоконтролирующиеся и самокорректирующиеся
коды Хэмминга) есть целая
книга, написанная по мотивам его лекций. Мы ее переводи, ведь мужик дело говорит.
Это книга не просто про ИТ, это книга про стиль мышления невероятно крутых людей.
«Это не просто заряд положительного мышления; в ней описаны условия, которые увеличивают шансы сделать великую работу.»
Мы уже перевели 16 (из 30) глав.
Глава 14. Цифровые фильтры — 1
(За перевод спасибо Максиму Лавриненко и Пахомову Андрею, которые откликнулись на мой призыв в «предыдущей главе».) Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Теперь, когда мы изучили компьютеры и разобрались в том, как они представляют информацию, давайте обратимся к тому, как компьютеры обрабатывают информацию. Разумеется, мы сможем изучить лишь некоторые способы их применения, поэтому сосредоточимся на основных принципах.
Большая часть того, что компьютеры обрабатывают, — это сигналы из разных источников, и мы уже обсуждали, почему они часто бывают в виде потока чисел, полученного из системы дискретизации. Линейная обработка, единственная, на которую у меня хватает времени в рамках этой книги, подразумевает наличие цифровых фильтров. Чтобы продемонстрировать, как всё происходит в реальной жизни, сначала я расскажу вам о том, как я стал работать с ними, и далее о том, чем я занимался.








 В августе на Intel Developer Forum в Сан-Франциско
В августе на Intel Developer Forum в Сан-Франциско 