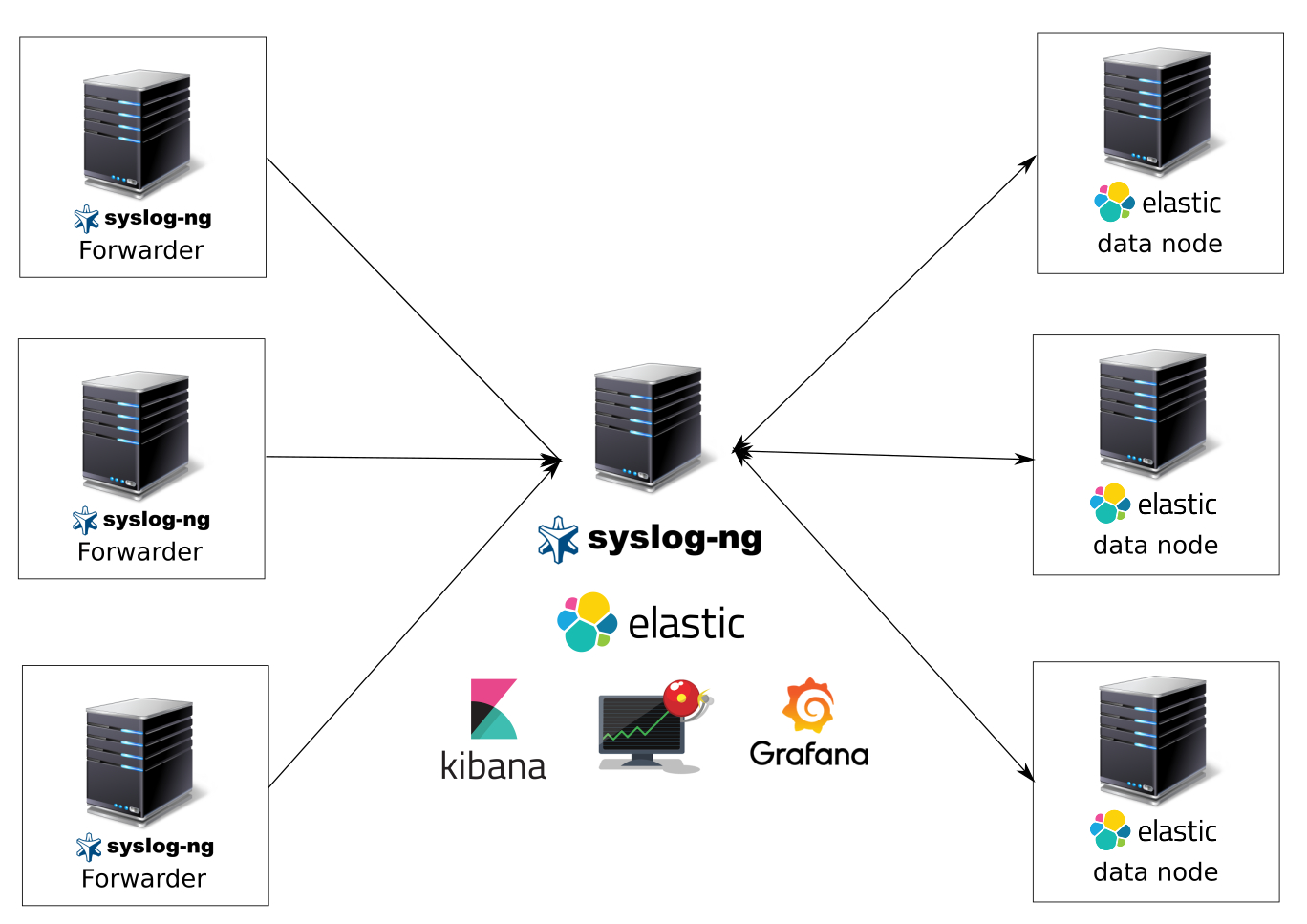
Что мы получим после этой статьи:
Систему сбора и анализа логов на syslog-ng, elasticsearch в качестве хранилища данных, kibana и grafana в качестве систем визуализации данных, kibana для удобного поиска по логам, elasticalert для отправки уведомлений по событиям. Приготовьтесь, туториал объемный.
Какие логи будем собирать:
- все системные логи разложенные по индексам в зависимости от их facility(auth,syslog,messages и т.д.);
- логи nginx — access и error;
- логи pm2;
- и др.
Обоснование выбора системы
Почему я выбрал связку с syslog-ng в качестве отправителя, парсера и приемщика логов? Да потому что он очень быстрый, надежный, не требовательный к ресурсам(да да — logstash в качестве агентов на серверах и виртуальных машинах просто убожество в плане пожирания ресурсов и требованием java), с внятным синтаксисом конфигов(вы видели rsyslog? — это тихий ужас), с широкими возможностями — парсинг, фильтрация, большое количество хранилищ данных(postgresql,mysql,elasticsearch,files и т.д.), буферизация(upd не поддерживает буферизацию), сторонние модули и другие фишки.
Требования:
- Ubuntu 16.04 или debian 8-9;
- vm для развертывания;
- Прямые руки.
Приступим или добро пожаловать под кат

 Как то раз появилась следующая задача: создать локального пользователя в ОС Linux, с ограниченным доступом к папкам и файлам, включая не только редактирование, но и просмотр, а также возможность использовать только разрешенные утилиты. Предусматривается только локальный доступ, сетевого доступа нет.
Как то раз появилась следующая задача: создать локального пользователя в ОС Linux, с ограниченным доступом к папкам и файлам, включая не только редактирование, но и просмотр, а также возможность использовать только разрешенные утилиты. Предусматривается только локальный доступ, сетевого доступа нет.