
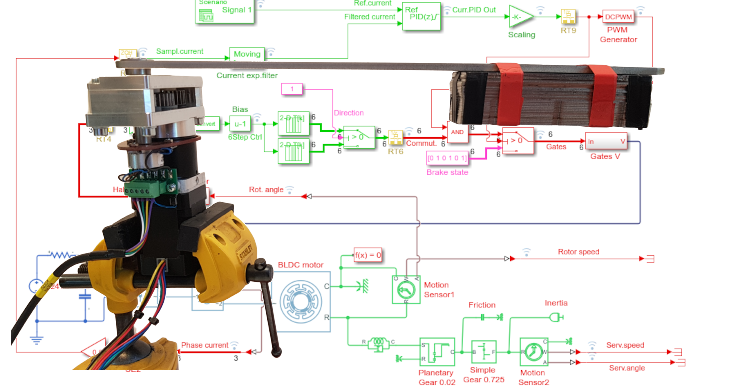
Продолжаем открытый проект сервоконтроллера MC50.
В предыдущей статье была разработана архитектура управления и написана программа сервопривода. Но регулятор был вручную настроен на определенный тип нагрузки. А что делать если тип и динамика нагрузки неизвестны?


 В начале 2016 года CEO Coinbase Брайан Армстронг поставил себе цель читать хотя бы по одной книге в месяц. Исходя из информации в его блоге, ему удалось выполнить и даже перевыполнить свой «план», в основном слушая аудиокниги во время тренировок и поездок за рулем.
В начале 2016 года CEO Coinbase Брайан Армстронг поставил себе цель читать хотя бы по одной книге в месяц. Исходя из информации в его блоге, ему удалось выполнить и даже перевыполнить свой «план», в основном слушая аудиокниги во время тренировок и поездок за рулем.
