Откровенно говоря, ранее я ни разу не занимался в серьезной мере методами тестирования программного обеспечения. Однако, понимаю, что для полной уверенности в том, что программа будет работать, нужно перепробовать всевозможные варианты её использования. Также очевиден для меня и тот факт, что сделать это не всегда возможно. Если имеются конкретные варианты использования, но невозможно проверить их всех в силу их количества, стараются построить набор, который покроет все самые используемые варианты. Но что делать, если использование всех вариантов равновероятно? Как за минимальное число времени обнаружить все ошибки, на которые есть большая вероятность наткнуться? Данная задача действительно известна, и с ней нередко сталкиваются, ну хотя бы, в
Яндексе.
Чтобы стало понятно о чем идет речь, представим, что нам необходимо протестировать какую-либо программу или сайт. Очень хорош пример с тестированием веб-формы, скажем, для регистрации или для поиска. Возникает вопрос, с какими ошибками в ней скорее всего встретится пользователь? Пускай у нас в форме имеется 6 вопросов, для каждого из которых возможны 10 вариантов ответа. Допустим, на страницу зашел целый миллион пользователей, и каждый из них ответил уникально. Теперь представим, что в форме для заполнения ответами скрывается ошибка. Если ошибка обнаруживается только при определенной комбинации ответов на все 6 вопросов, то на неё наткнется лишь один человек. Если же ошибка вылетает при наборе определенных ответов на какие-то 3 вопроса, то количество людей, обнаруживших ошибку возрастет до тысячи. Очевидно, что чем меньше элементов в комбинации, требуемой для ошибки, тем больше людей с ней встретится. Соответственно, перед нами теперь стоит задача: если мы не можем обнаружить все ошибки, то давайте хотя бы найдем самые критичные, то есть те, на которые наткнется больше всего пользователей.
Таким образом, мы должны сформировать тест-кейсы (и чем меньше, тем лучше), при переборе которых мы наткнемся на самые легкодоступные ошибки. Допустим, у нас имеется множество вопросов
A, которое мы задаем количеством вариантов ответа на каждый из них: А = {2, 3, 5, 2, ...}. Пусть
n — количество вопросов, а 1≤
m≤n — степень критичности ошибок, она же степень покрытия или глубина покрывающего набора. Чем меньше значение m, тем критичнее ошибка. Задавая степень покрытия мы строим тестовый набор, который позволит обнаружить все ошибки, степень критичности которых меньше данного m. Если m = n, то поиск ошибок сводится к перебору всех вариантов. Чем меньше задаем степень, тем меньше тест-кейсов будет сформировано и тем меньше ошибок мы найдем.



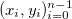 и соответствующий им набор положительных весов
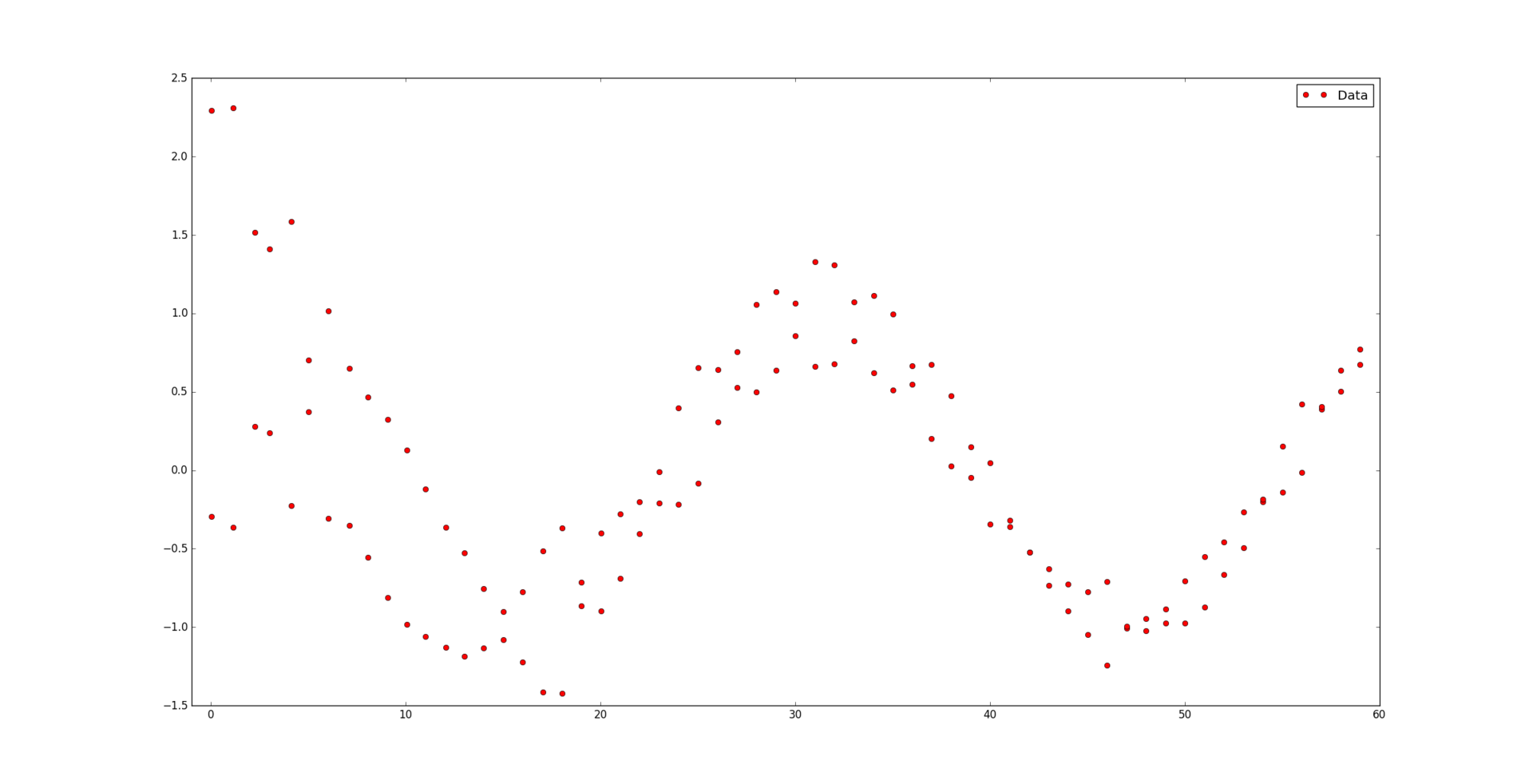
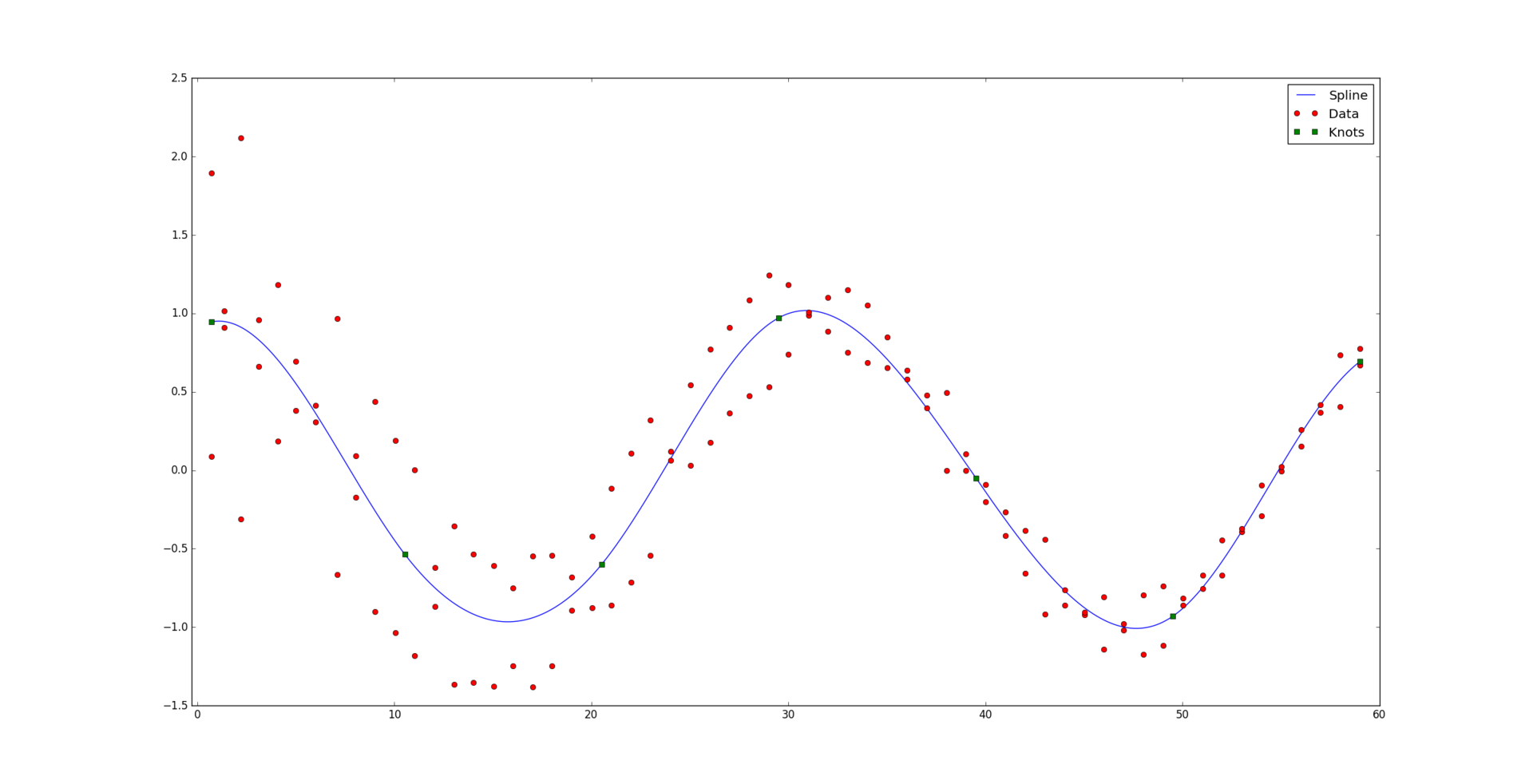
и соответствующий им набор положительных весов 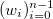 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.