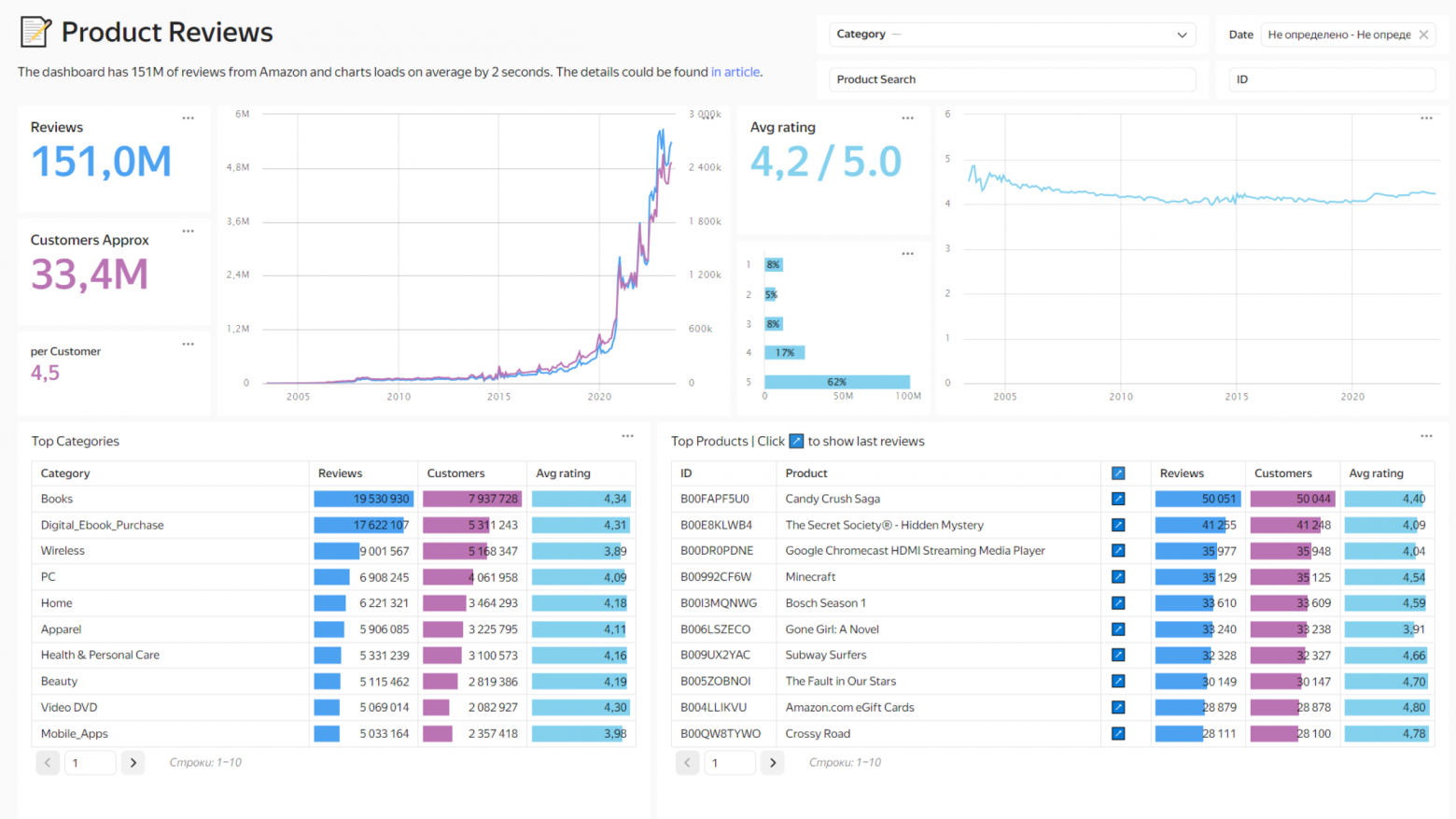
Рассказывать айтишникам про психологию то еще дело, некоторые читатели скажут: «Bullshit!», и вообще не поверят, потому что психологию, даже прикладную, нельзя назвать точной наукой. Тем не менее, задача этой статьи — показать и доказать вам, что некоторые модели действительно работают. В основе доклад
Сергея Котырева из UMI на РИТ++ 2017, от его лица дальше и пойдет повествование.

Я — IT-предприниматель с 20 летним стажем. Так получилось, что с самого начала карьеры мне пришлось управлять людьми. Как выпускник технического вуза и айтишник, я изначально понял, что люди сложно поддаются алгоритмизации, и вообще осознанию, пониманию и прогнозированию.
Позже я пришел к мысли, что
люди — это вообще самое сложное, с чем приходится работать. Сейчас я думаю, что люди вообще, наверное, самое сложное, что есть во Вселенной.
Мне кажется, о поведении и предсказании поведения спиральных галактик мы знаем больше, чем о том, как поведет себя человек, например, моя жена, сотрудник, или особенно сотрудница моего отдела маркетинга, не говоря уже о пиарщицах. О том, что ближайшая к нам Галактика летит, и через сколько-то миллиардов лет столкнется с нашей, мы уже знаем точно.