Писать на C++ расширения для PHP приходится не так чтобы очень часто, но когда приходится — обнаруживается, что публикаций и документации на эту тему не так уж и много. Особенно, если копнуть поглубже. Опишу несколько интересных моментов, которые мне пришлось выяснять «на своей шкуре».
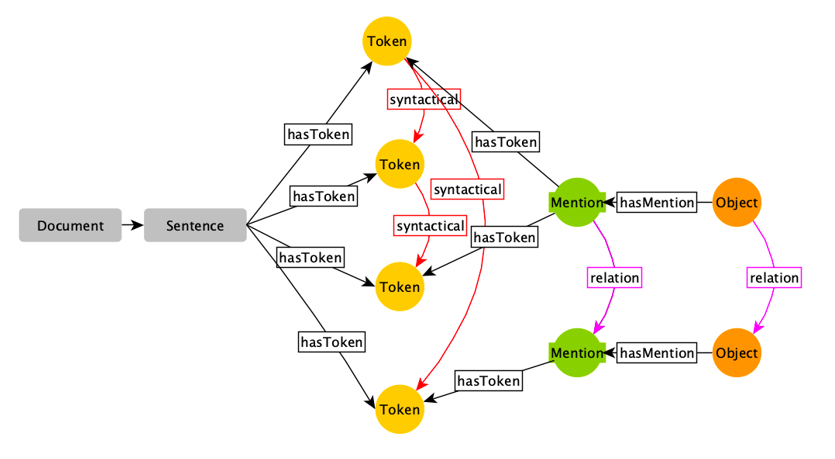
Неожиданные сложности подстерегают нас при вызове из кода расширения (которое, напомню, мы пишем на C++) PHP-функций. Для этого предусмотрена функция call_user_function_ex,
пример использования которой найти не так уж сложно; проблемы возникают, если вынести ее вызов из C++'ной функции, которая вызывается из PHP. Объявляются такие функции следующим образом:
ZEND_FUNCTION(MyFunction) { … }
После вынесения вызова call_user_function_ex за ее пределы, наше расширение перестает компилироваться.
Разгадка (и решение проблемы) кроются, конечно же, в определении макроса ZEND_FUNCTION, который добавляет к определению функции пару параметров. Нам ничего не остается, кроме как передать их той функции, откуда мы хотим обратиться к PHP. Выглядеть это будет так: