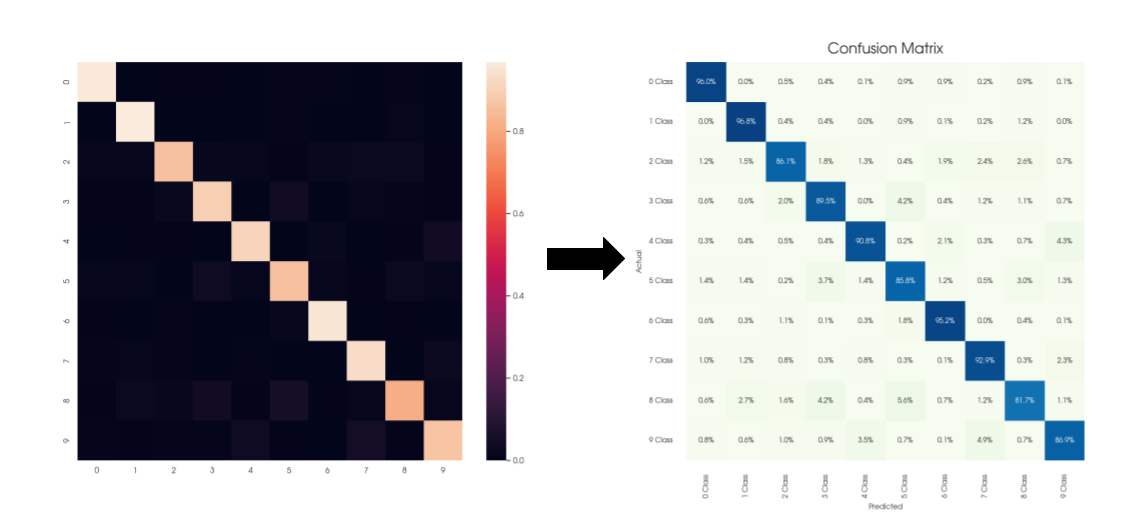
Простой и красивый синтаксис, множество библиотек под самые разные задачи и большое комьюнити делают Python одним из самых популярных языков программирования на сегодняшний день, который активно используется в data science и машинном обучении, веб-разработке и других областях программирования.
Когда я начал изучать питон, у меня возникло несколько вопросов.