

Масштабируемость — ключевое требование для облачных приложений. С Kubernetes масштабировать приложение так же просто, как и увеличить количество реплик для соответствующего развертывания или
ReplicaSet — но это ручной процесс. Команда Kubernetes aaS от Mail.ru реализовала в своем сервисе автоматическое машстабирование на уровне кластеров. Ну а если вы хотите оптимизироваться на уровне подов — то следуйте рекомендациям этого перевода.Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или
ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler. По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.Это статья о том, как использовать внешние метрики для автоматического масштабирования приложения Kubernetes. Чтобы показать, как все работает, автор использует метрики запросов HTTP-доступа, они собираются с помощью Prometheus.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.




 Хабр, это снова я, Алексей Рак (фото не мое). В прошлом году, помимо основной работы, мне довелось стать одним из авторов задач для кандидатов в Яндекс. Сегодня наша команда впервые за долгое время публикует на Хабре реальные задачи для разработчиков, которые устраиваются в компанию. Эти задачи использовались до февраля 2020 года при отборе на стажировку для бэкендеров. Решения проверял компьютер. Сейчас кандидатам достаются похожие задания.
Хабр, это снова я, Алексей Рак (фото не мое). В прошлом году, помимо основной работы, мне довелось стать одним из авторов задач для кандидатов в Яндекс. Сегодня наша команда впервые за долгое время публикует на Хабре реальные задачи для разработчиков, которые устраиваются в компанию. Эти задачи использовались до февраля 2020 года при отборе на стажировку для бэкендеров. Решения проверял компьютер. Сейчас кандидатам достаются похожие задания. Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
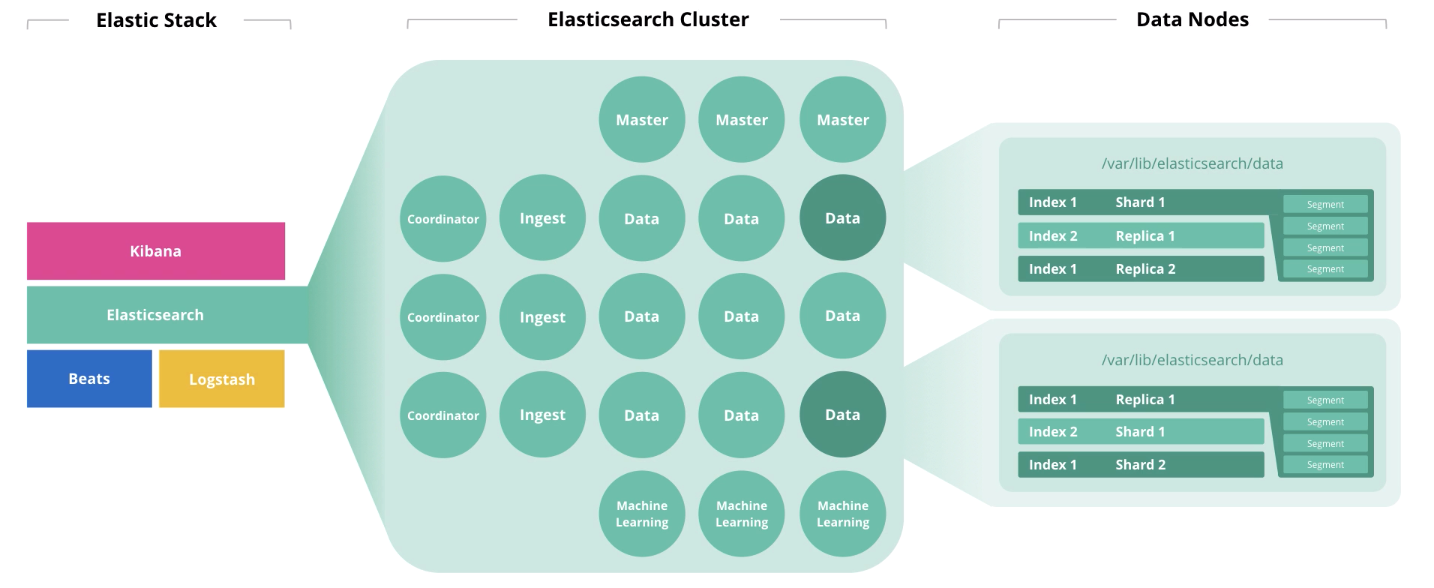
Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.




{kind=link}