В продолжение статей про устройство таблицы маршрутизации и про реализацию протокола BGP в Quagga, в настоящей статье я разберу как работает протокол OSPF. Я ограничусь случаем для одной OSPF зоны без редистрибъюции маршрутов из других протоколов маршрутизации.

User
Виртуальное приватное облако: работа с CoreOS и RancherOS
15 min
Tutorial

Недавно мы добавили в сервис «Виртуальное приватное облако» новый образ с операционной системой RancherOS и обновили образ CoreOS.
Эти операционные системы будут интересны пользователям, которым необходим инструмент для простого управления большим количеством приложений в контейнерах и использования различных систем кластеризации контейнеров — Kubernetes, Docker Swarm, Apache Mesos и других.
Парсинг JSON — это минное поле
25 min
Translation

JSON — это стандарт де-факто, когда заходит речь о (де)сериализации, обмене данными в сети и мобильной разработке. Но насколько хорошо вы знакомы с JSON? Все мы читаем спецификации и пишем тесты, испытываем популярные JSON-библиотеки для своих нужд. Я покажу вам, что JSON — это идеализированный формат, а не идеальный, каким его многие считают. Я не нашёл и двух библиотек, ведущих себя одинаково. Более того, я обнаружил, что крайние случаи и зловредная полезная нагрузка могут привести к багам, падениями и DoS, в основном потому, что JSON-библиотеки основаны на спецификациях, которые со временем развиваются, что оставляет многие вещи плохо или вообще не задокументированными.
Содержание
1. Спецификации JSON
2. Тестирование парсинга
2.1. Структура
2.2. Числа (Numbers)
2.3. Массивы
2.4. Объекты
2.5. Строки
2.6. Двойственные значения RFC 7159
3. Архитектура тестирования
4. Результаты тестирования
4.1. Полные результаты
4.2. C-парсеры
4.3. Objective-C-парсеры
4.4. Apple (NS)JSONSerialization
4.5. Freddy (Swift)
4.6. Bash JSON.sh
4.7. Другие парсеры
4.8. JSON Checker
4.9. Регулярные выражения
5. Контент парсинга
6. STJSON
7. Заключение
8. Приложение
2. Тестирование парсинга
2.1. Структура
2.2. Числа (Numbers)
2.3. Массивы
2.4. Объекты
2.5. Строки
2.6. Двойственные значения RFC 7159
3. Архитектура тестирования
4. Результаты тестирования
4.1. Полные результаты
4.2. C-парсеры
4.3. Objective-C-парсеры
4.4. Apple (NS)JSONSerialization
4.5. Freddy (Swift)
4.6. Bash JSON.sh
4.7. Другие парсеры
4.8. JSON Checker
4.9. Регулярные выражения
5. Контент парсинга
6. STJSON
7. Заключение
8. Приложение
Mesos. Container Cluster Management System
25 min
Tutorial

Apache Mesos — это централизованная отказоустойчивая система управления кластером. Она разработана для распределенных компьютерных сред c целью обеспечения изоляции ресурсов и удобного управления кластерами подчиненных узлов (mesos slaves). Это новый эффективный способ управления серверной инфраструктурой, но и, как любое техническое решение, не "серебряная пуля".
В некотором смысле суть его работы противоположная уже традиционной виртуализации — вместо деления физической машины на кучу виртуальных, Mesos предлагает их объединять в одно целое, в единый виртуальный ресурс.
Mesos распределяет ресурсы CPU и памяти в кластере для задач в похожей манере, как ядро Linux выделяет ресурсы железа между локальными процессами.
Представим себе, что есть необходимость выполнить различные типы задач. Для этого можно выделить отдельные виртуальные машины (отдельный кластер) для каждого типа. Эти виртуальные машины, вероятно, не будут полностью загруженными и некоторое время будут простаивать, то есть не будут работать с максимальной эффективностью. Если же все виртуальные машины для всех задач объединить в единый кластер, мы можем повысить эффективность использования ресурсов и параллельно с тем повысить скорость их выполнения (в случае если задачи краткосрочные или виртуальные машины не загружены полностью все время). Следующий рисунок, надеюсь, прояснит сказанное:
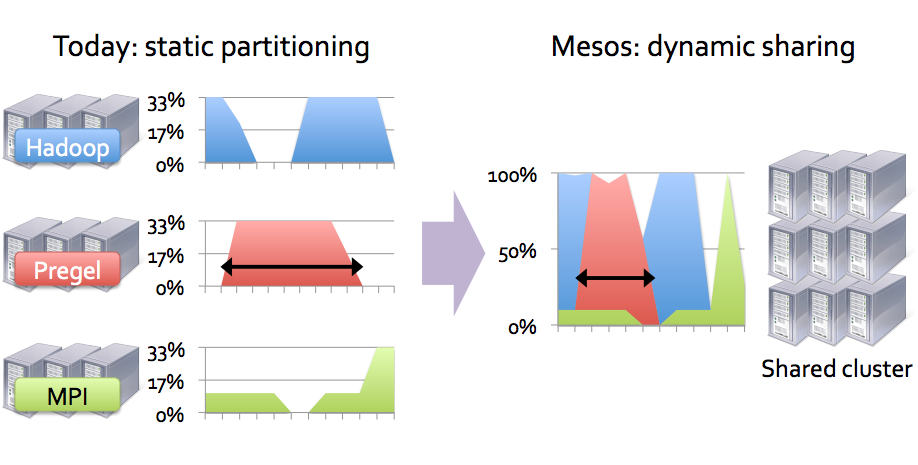
Но это далеко не все. Кластер Mesos (с фреймворком к нему) способен пересоздавать отдельные ресурсы, в случае их падения, масштабировать ресурсы вручную или автоматически при определенных условиях и т.п.
Пройдемся по компонентам Mesos-кластера.
Таблица маршрутизации в Quagga
7 min
По роду своей деятельности я занимаюсь проектированием сетей и настройкой сетевого оборудования. В какой-то момент времени мне захотелось узнать как-же устроены сетевые устройства, которые всегда представляли для меня черные ящики, магически реализующие сетевые протоколы. Поскольку устройства от вендоров типа Cisco или Juniper закрыты и не доступны для какого-либо изучения, то мой выбор пал на программу Quagga – маршрутизатор с открытыми исходными кодами, который достаточно широко используется в реальной жизни и довольно успешно справляется с протоколами OSPF и BGP. Вооружившись исходниками Quagga я приступил к исследованию. В данной статье я хочу рассказать как устроена таблица маршрутизации в Quagga, какие структуры и алгоритмы используются для ее реализации.
Механизмы контейнеризации: cgroups
11 min
Tutorial

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Ищем уязвимости с помощью google
8 min
Любой поиск уязвимостей на веб-ресурсах начинается с разведки и сбора информации.
Разведка может быть как активной — брутфорс файлов и директорий сайта, запуск сканеров уязвимостей, ручной просмотр сайта, так и пассивной — поиск информации в разных поисковых системах. Иногда бывает так, что уязвимость становится известна еще до открытия первой страницы сайта.
Разведка может быть как активной — брутфорс файлов и директорий сайта, запуск сканеров уязвимостей, ручной просмотр сайта, так и пассивной — поиск информации в разных поисковых системах. Иногда бывает так, что уязвимость становится известна еще до открытия первой страницы сайта.
Более чем 80 средств мониторинга системы Linux
12 min
Ниже будет приведен список инструментов мониторинга. Есть как минимум 80 способов, с помощью которых ваша машинка будет под контролем.

1. первый инструмент — top
Консольная команда top- удобный системный монитор, простой в использовании, с помощью которой выводится список работающих в системе процессов, информации о этих процессах. Данная команда в реальном времени сортирует их по нагрузке на процессор, инструмент предустановлен во многих системах UNIX.
1. первый инструмент — top
Консольная команда top- удобный системный монитор, простой в использовании, с помощью которой выводится список работающих в системе процессов, информации о этих процессах. Данная команда в реальном времени сортирует их по нагрузке на процессор, инструмент предустановлен во многих системах UNIX.
Виртуальная машина KLEE для символьного выполнения кода
6 min
Translation
В этом посте мы попробуем применить технику символьного выполнения на примере символьной ВМ KLEE для решения простого ASCII-лабиринта. Как вы думаете, сколько верных решений мы сможем найти?

Механизмы контейнеризации: namespaces
11 min

Последние несколько лет отмечены ростом популярности «контейнерных» решений для ОС Linux. О том, как и для каких целей можно использовать контейнеры, сегодня много говорят и пишут. А вот механизмам, лежащим в основе контейнеризации, уделяется гораздо меньше внимания.
Все инструменты контейнеризации — будь то Docker, LXC или systemd-nspawn,— основываются на двух подсистемах ядра Linux: namespaces и cgroups. Механизм namespaces (пространств имён) мы хотели бы подробно рассмотреть в этой статье.
Начнём несколько издалека. Идеи, лежащие в основе механизма пространств имён, не новы. Ещё в 1979 году в UNIX был добавлен системный вызов chroot() — как раз с целью обеспечить изоляцию и предоставить разработчикам отдельную от основной системы площадку для тестирования. Нелишним будет вспомнить, как он работает. Затем мы рассмотрим особенности функционирования механизма пространств имён в современных Linux-системах.
Справочник по синхронизаторам java.util.concurrent.*
14 min
Tutorial
Целью данной публикации не является полный анализ синхронизаторов из пакета java.util.concurrent. Пишу её, прежде всего, как справочник, который облегчит вхождение в тему и покажет возможности практического применения классов для синхронизации потоков (далее поток = thread).
В java.util.concurrent много различных классов, которые по функционалу можно поделить на группы: Concurrent Collections, Executors, Atomics и т.д. Одной из этих групп будет Synchronizers (синхронизаторы).
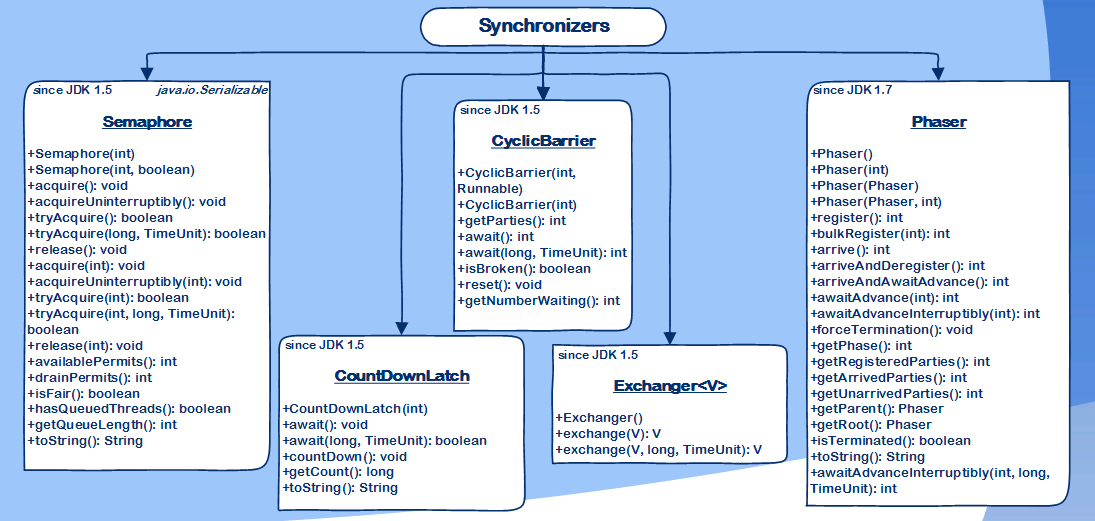
Синхронизаторы – вспомогательные утилиты для синхронизации потоков, которые дают возможность разработчику регулировать и/или ограничивать работу потоков и предоставляют более высокий уровень абстракции, чем основные примитивы языка (мониторы).
В java.util.concurrent много различных классов, которые по функционалу можно поделить на группы: Concurrent Collections, Executors, Atomics и т.д. Одной из этих групп будет Synchronizers (синхронизаторы).
Синхронизаторы – вспомогательные утилиты для синхронизации потоков, которые дают возможность разработчику регулировать и/или ограничивать работу потоков и предоставляют более высокий уровень абстракции, чем основные примитивы языка (мониторы).
[ В закладки ] Алгоритмы и структуры данных в ядре Linux, Chromium и не только
9 min
Translation
Многие студенты, впервые сталкиваясь с описанием какой-нибудь хитроумной штуки, вроде алгоритма Кнута – Морриса – Пратта или красно-чёрных деревьев, тут же задаются вопросами: «К чему такие сложности? И это, кроме авторов учебников, кому-нибудь нужно?». Лучший способ доказать пользу алгоритмов – это примеры из жизни. Причём, в идеале – конкретные примеры применения широко известных алгоритмов в современных, повсеместно используемых, программных продуктах.

Посмотрим, что можно обнаружить в коде ядра Linux, браузера Chromium и ещё в некоторых проектах.
Посмотрим, что можно обнаружить в коде ядра Linux, браузера Chromium и ещё в некоторых проектах.
Тонкости анализа исходного кода C/C++ с помощью cppcheck
27 min
Tutorial
В предыдущем посте были рассмотрены основные возможности статического анализатора с открытым исходным кодом cppcheck. Он показывает себя не с худшей стороны даже при базовых настройках, но сегодня речь пойдёт о том, как выжать из этого анализатора максимум полезного.
В этой статье будут рассмотрены возможности cppcheck по вылавливанию утечек памяти, полезные параметры для улучшения анализа, а также экспериментальная возможность по созданию собственных правил. Сегодня никаких сравнений анализаторов «кто лучше», статья полностью посвящена работе с cppcheck.
В этой статье будут рассмотрены возможности cppcheck по вылавливанию утечек памяти, полезные параметры для улучшения анализа, а также экспериментальная возможность по созданию собственных правил. Сегодня никаких сравнений анализаторов «кто лучше», статья полностью посвящена работе с cppcheck.
Не зная брода, не лезь в воду. Часть вторая
8 min

В этот раз я хочу поговорить о функции printf. Все наслышаны об уязвимостях в программах, и что функции наподобие printf объявлены вне закона. Но одно дело знать, что лучше не использовать эти функции. А совсем другое — понять почему. В этой статье я опишу две классических уязвимости программ, связанных с printf. Хакером после этого вы не станете, но, возможно, по-новому взгляните на свой код. Вдруг, вы реализуете аналогичные уязвимые функции, даже не подозревая об этом.
СТОП. Подожди читатель, не проходи мимо. Я знаю, что ты увидел слово printf. И уверен, что автор статьи сейчас расскажет банальную историю о том, что функция не контролирует типы передаваемых аргументов. Нет! Статья будет не про это, а именно про уязвимости. Заходи почитать.
Парсинг формул в 50 строк на Python
4 min
Вдохновение — задача с собеседования Яндекса и статья «Парсинг формул в 40 строк».
Моей целью было посмотреть, как будет выглядеть «pythonic» решение этой задачи. Хотелось, чтобы решение было простым, код читаемым и разделённым. В итоге ещё получился и пример применения цепочки генераторов (generators pipeline).
Моей целью было посмотреть, как будет выглядеть «pythonic» решение этой задачи. Хотелось, чтобы решение было простым, код читаемым и разделённым. В итоге ещё получился и пример применения цепочки генераторов (generators pipeline).
Образы и контейнеры Docker в картинках
6 min
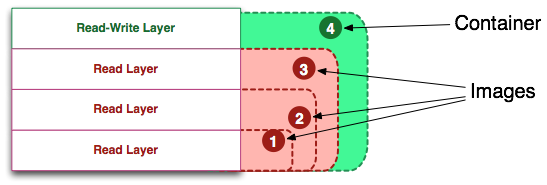
Перевод поста Visualizing Docker Containers and Images, от новичка к новичкам, автор на простых примерах объясняет базовые сущности и процессы в использовании docker.
Если вы не знаете, что такое Docker или не понимаете, как он соотносится с виртуальными машинами или с инструментами configuration management, то этот пост может показаться немного сложным.
Пост предназначен для тех, кто пытается освоить docker cli, понять, чем отличается контейнер и образ. В частности, будет объяснена разница между просто контейнером и запущенным контейнером.
Как устроены дыры в безопасности: переполнение буфера
29 min
Translation
Прим. переводчика: Это перевод статьи Питера Брайта (Peter Bright) «How security flaws work: The buffer overflow» о том, как работает переполнение буфера и как развивались уязвимости и методы защиты.
Беря своё начало с Червя Морриса (Morris Worm) 1988 года, эта проблема поразила всех, и Linux, и Windows.

Переполнение буфера (buffer overflow) давно известно в области компьютерной безопасности. Даже первый само-распространяющийся Интернет-червь — Червь Морриса 1988 года — использовал переполнение буфера в Unix-демоне finger для распространения между машинами. Двадцать семь лет спустя, переполнение буфера остаётся источником проблем. Разработчики Windows изменили свой подход к безопасности после двух основанных на переполнении буфера эксплойтов в начале двухтысячных. А обнаруженное в мае сего года переполнение буфера в Linux драйвере (потенциально) подставляет под удар миллионы домашних и SMB маршрутизаторов.
По своей сути, переполнение буфера является невероятно простым багом, происходящим из распространённой практики. Компьютерные программы часто работают с блоками данных, читаемых с диска, из сети, или даже с клавиатуры. Для размещения этих данных, программы выделяют блоки памяти конечного размера — буферы. Переполнение буфера происходит, когда происходит запись или чтение объёма данных большего, чем вмещает буфер.
На поверхности, это выглядит как весьма глупая ошибка. В конце концов, программа знает размер буфера, а значит, должно быть несложно удостоверится, что программа никогда не попытается положить в буфер больше, чем известный размер. И вы были бы правы, рассуждая таким образом. Однако переполнения буфера продолжают происходить, а результаты часто представляют собой катастрофу для безопасности.
Покрытие графов в тестировании ПО, часть 1
4 min
Translation
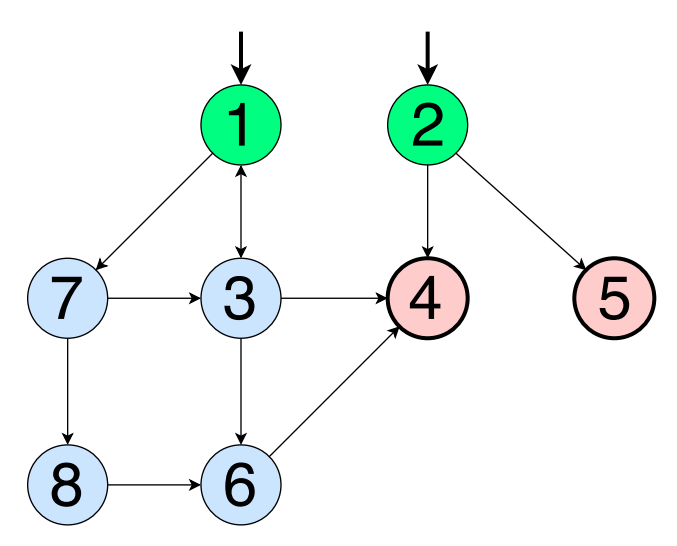
Большинство программ и алгоритмов можно представить в виде графа, состоящего из набора вершин (N) и ребер (Е). Покрытие графов в тестировании полезно тем, что можно проектировать тесты, используя разные критерии покрытия, и выявить ошибки. Что касается тестирования черного ящика, то покрытие графов здесь тоже может иметь большое значение, если приходится работать с состояниями и переходами, графами состояний сущности и т.д. Если граф достаточно сложен, разные критерии покрытия позволят оценить достаточность тестового набора.
Еще раз про приведение типов в языке С++ или расстановка всех точек над cast
8 min

Этот пост попытка кратко оформить все, что я читал или слышал из разных источников про операторы приведения типов в языке C++. Информация ориентирована в основном на тех, кто изучает C++ относительно недолго и, как мне кажется, должна помочь понять cпецифику применения данных операторов. Старожилы и гуру С++ возможно помогут дополнить или скорректировать описанную мной картину. Всех интересующихся приглашаю под кат.
Тестирование в Яндексе. Как сделать отказоустойчивый грид из тысячи браузеров
7 min
Любой специалист, причастный к тестированию веб-приложений, знает, что большинство рутинных действий на сервисах умеет делать фреймворк Selenium. В Яндексе в день выполняются миллионы автотестов, использующих Selenium для работы с браузерами, поэтому нам нужны тысячи различных браузеров, доступных одновременно и 24/7. И вот тут начинается самое интересное.

Selenium с большим количеством браузеров имеет много проблем с масштабированием и отказоустойчивостью. После нескольких попыток у нас получилось элегантное и простое в обслуживании решение, и мы хотим поделиться им с вами. Наш проект gridrouter позволяет организовать отказоустойчивый Selenium-грид из любого количества браузеров. Код выложен в open-source и доступен на Github. Под катом я расскажу, на какие недостатки Selenium мы обращали внимание, как пришли к нашему решению, и объясню, как его настроить.
Selenium с большим количеством браузеров имеет много проблем с масштабированием и отказоустойчивостью. После нескольких попыток у нас получилось элегантное и простое в обслуживании решение, и мы хотим поделиться им с вами. Наш проект gridrouter позволяет организовать отказоустойчивый Selenium-грид из любого количества браузеров. Код выложен в open-source и доступен на Github. Под катом я расскажу, на какие недостатки Selenium мы обращали внимание, как пришли к нашему решению, и объясню, как его настроить.