
В этой статье я расскажу об API агрегатора финансовых данных Yahoo! Finance. В рассказе есть один нюанс — официальное API Яху Финанс было закрыто три года назад, однако практически сразу же появилась его недокументированная работоспособная версия, которая жива до сих пор. Хочу в исследовательских целях рассказать об использовании этой работоспособной версии подробнее.
Тем более, что список рынков, данные с которых можно получать через Яху Финанс огромен. На текущий момент в нем 79 стран, включая и Россию.
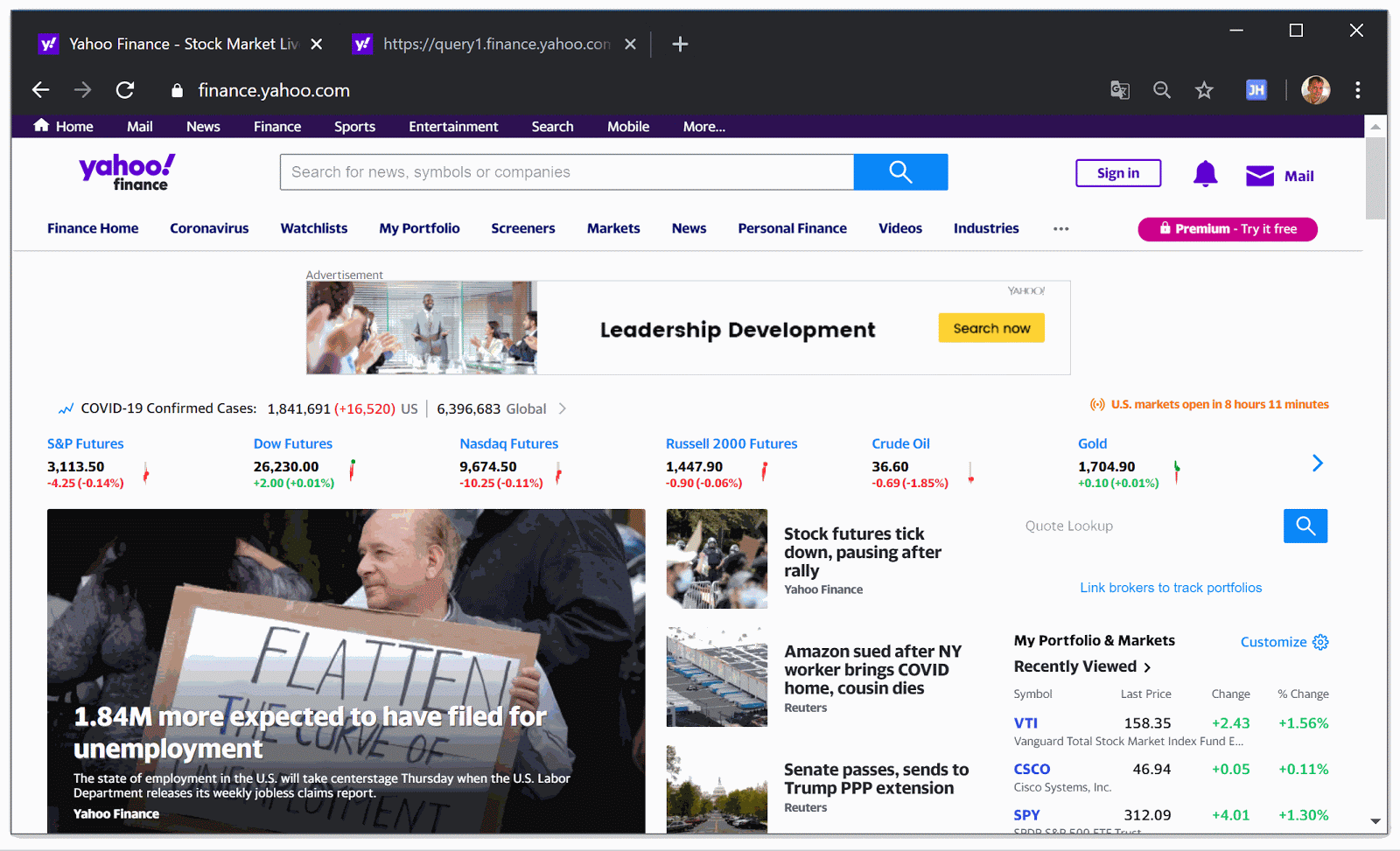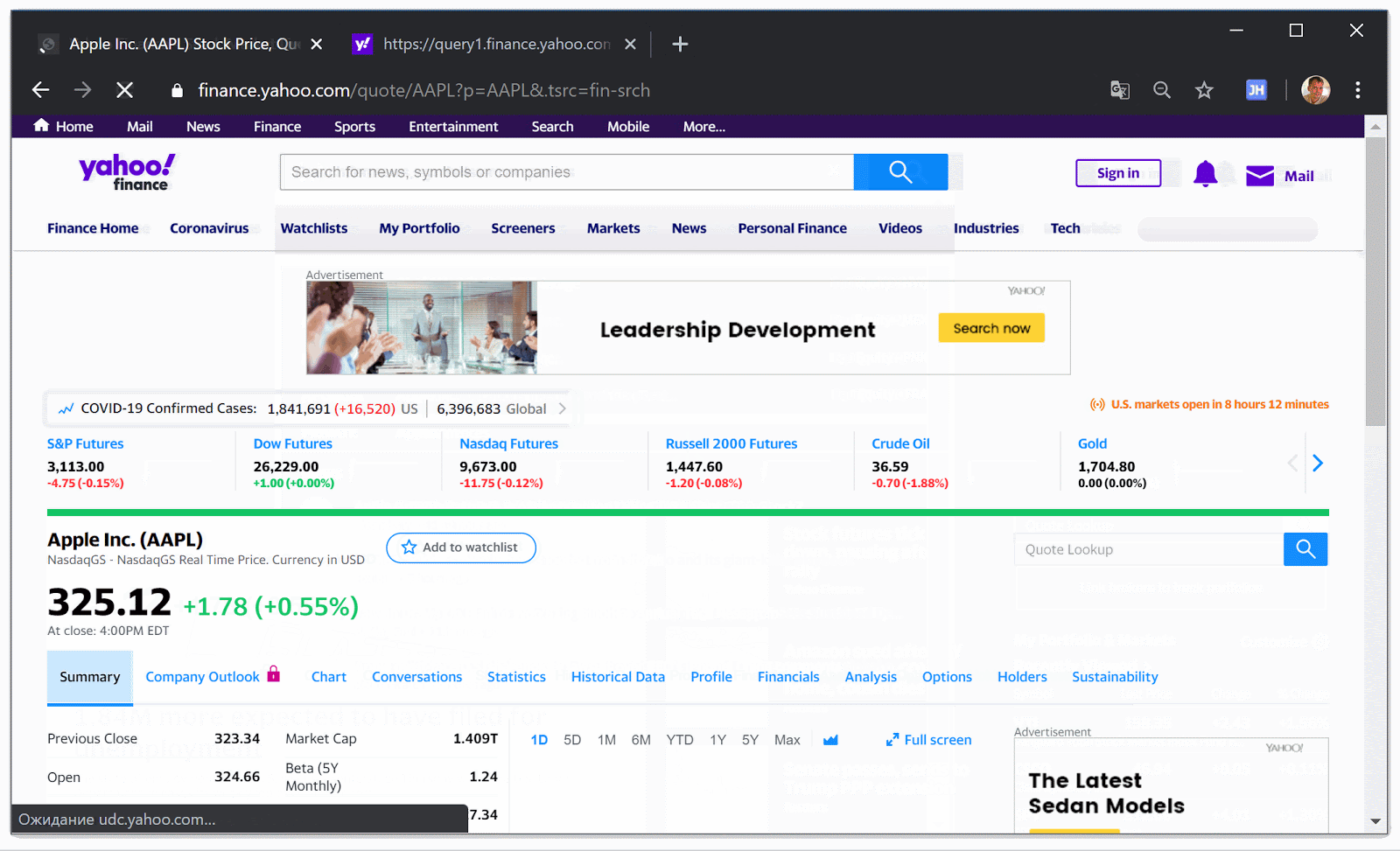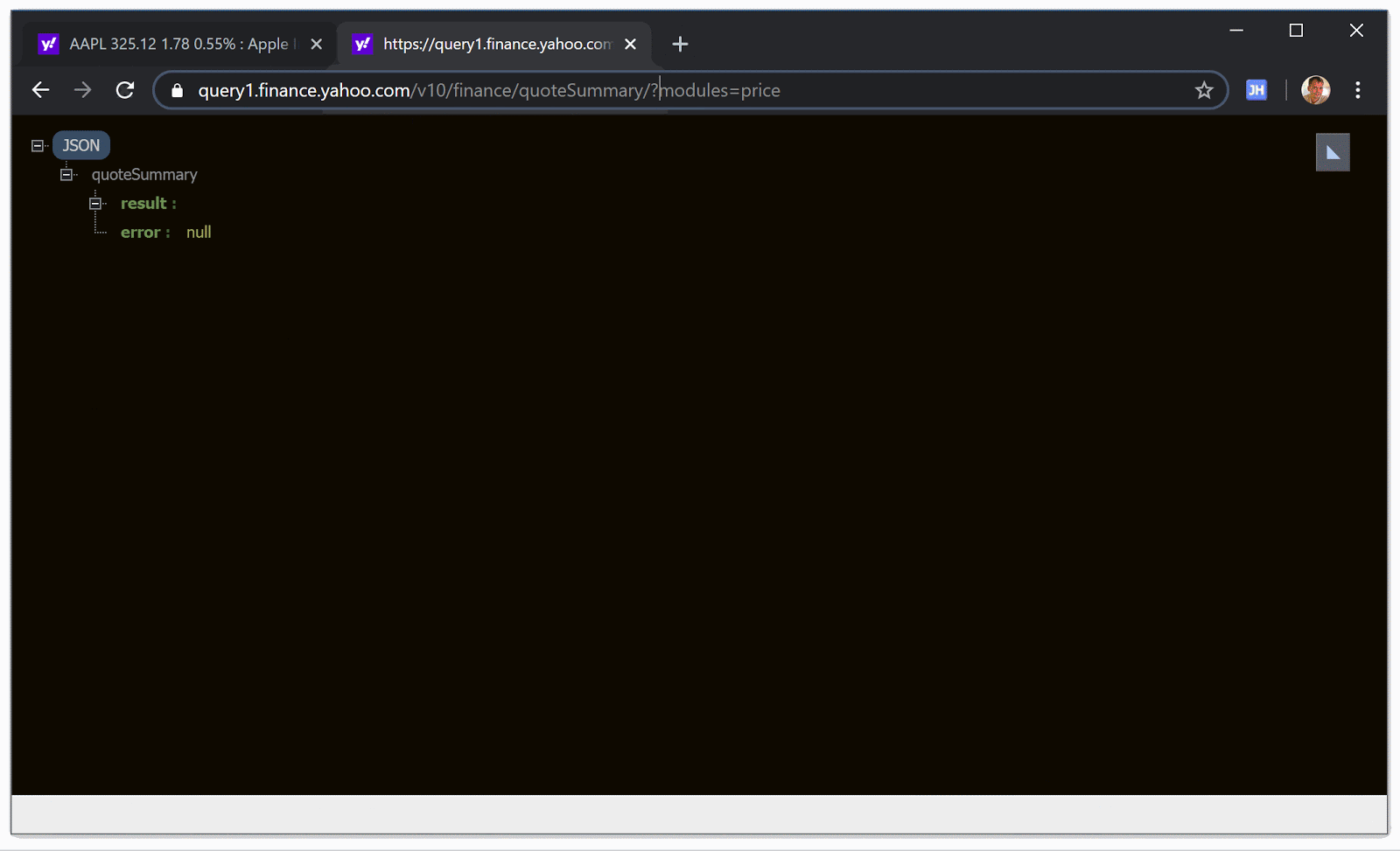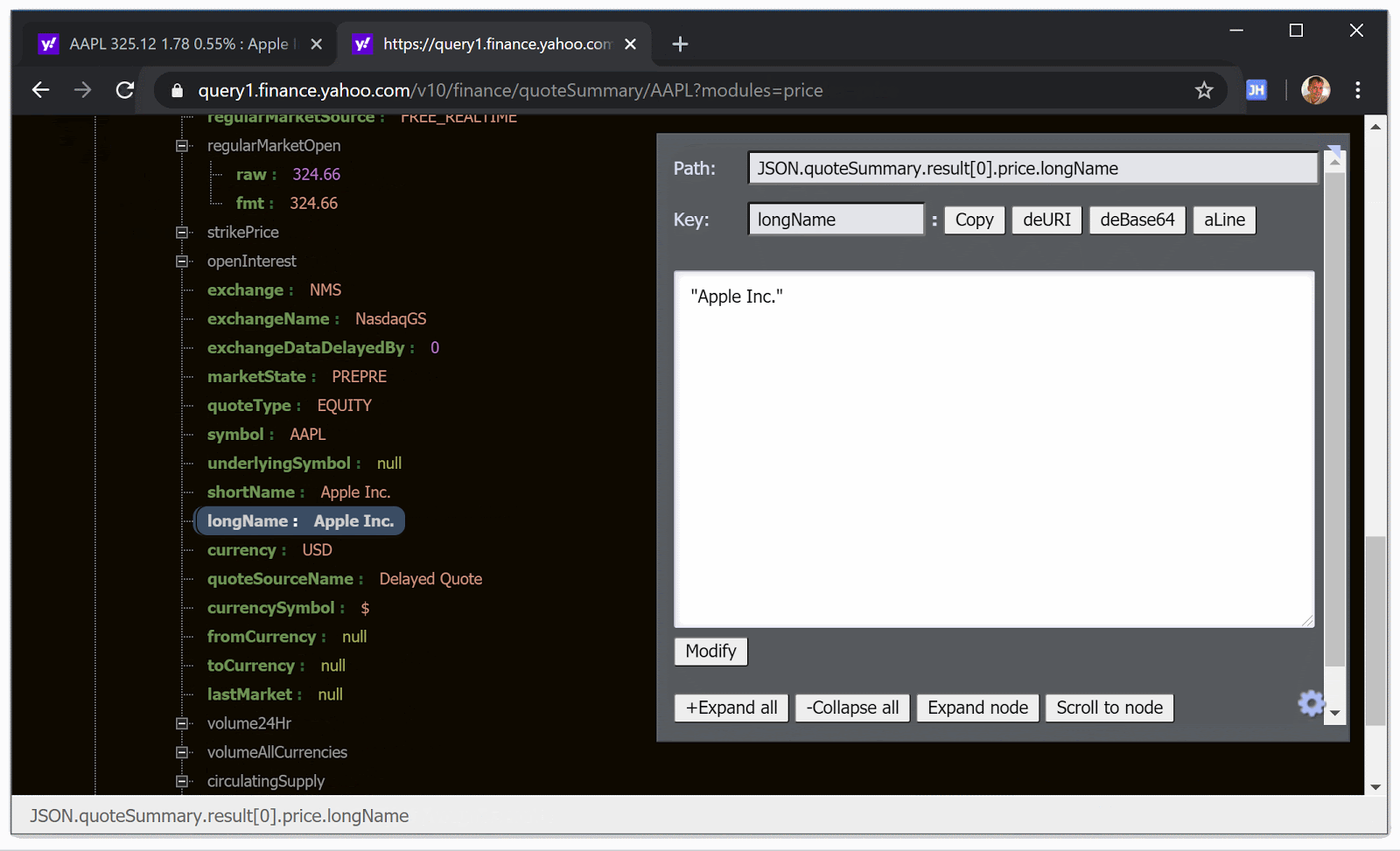
Apple Inc. (AAPL) на сайте и в API Яху Финанс
Тем более, что список рынков, данные с которых можно получать через Яху Финанс огромен. На текущий момент в нем 79 стран, включая и Россию.
Apple Inc. (AAPL) на сайте и в API Яху Финанс

