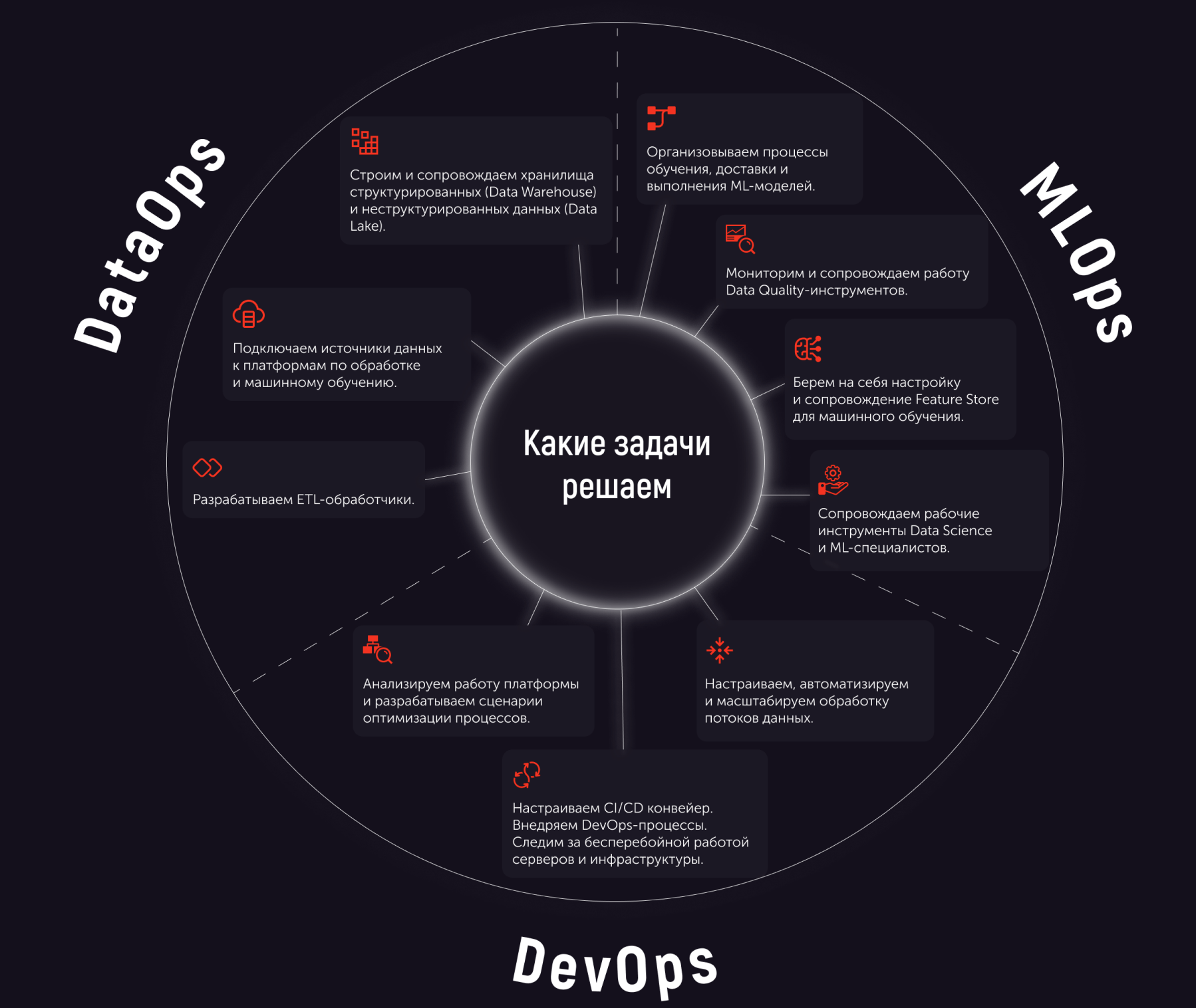
Документация нужна. Точка. На этом всё, расходимся.
На самом деле, если без шуток, что такое техническая документация? Зачем она нужна? Вопросы интересные. Если отвечать на них бюрократическим языком, то получится длинно, важно и непонятно. Поэтому мы попробуем ответить по-простому.
Документация — это про знания. Знания о продукте, системе, процессах. Важно, где и как хранятся эти знания, кто может получить к ним доступ, легко ли их найти, доступны ли они для понимания.
А еще документация — это про деньги. Как и многое в этом мире. Например, если наличие документации уменьшает количество обращений пользователей в службу поддержки, то, вероятно, это сокращает расходы на сотрудников поддержки. А значит, документация решает определенную бизнесовую задачу.
И наконец, документация — это про коммуникацию. Про передачу информации между людьми, отделами, компаниями и т.д. Например, документация API позволяет заменить коммуникацию между группами разработчиков, пользовательская документация — это способ коммуникации между компанией-разработчиком и ее клиентами, инструкции для новых сотрудников — это замена общения наставника и новичка.