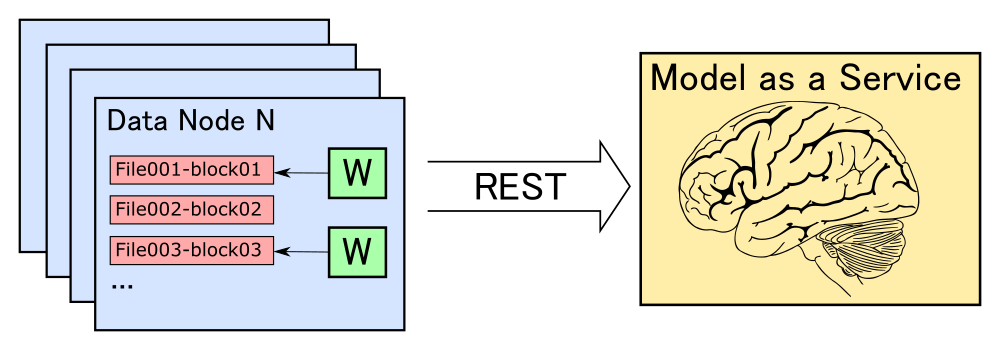
Рано или поздно каждый продакт становится достаточно матёрым, чтобы грамотно автоматизировать любую ручную работу:
• Финотдел тратит время на отчет? Вот вам кнопка, жмите, отчет сформируется автоматически!
• Аналитики делают ручные выгрузки? Вжух, и у нас теперь красивый автоматический дашборд!
• Сэйлзы заполняют данные о клиенте вручную? Хоп, и данные уже парсятся автоматом!
Тогда продакт начинает чувствовать себя этакой Белоснежкой, которая улучшает всё, к чему прикоснется. Да и коллеги его хвалят — ведь всем нравится, когда что-то делалось руками, а теперь работает «само по себе». Пусть вкалывают роботы, а не человек!
Но это ошибка. На длинной дистанции автоматизация часто бесполезна и даже вредна для бизнеса. А продакт – как раз тот человек, который должен предостеречь окружающих.
Сегодня расскажу, как вовремя распознать зловредную автоматизацию.









 В первых двух абзацах оригинального текста автор описывает как он пил пиво с друзьями. Я заменил их пятничной картинкой о гимнастике из детства.
В первых двух абзацах оригинального текста автор описывает как он пил пиво с друзьями. Я заменил их пятничной картинкой о гимнастике из детства. Это перевод
Это перевод