
На хабре было несколько статей по преобразованию Фурье и о всяких красивостях типа Цифровой Обработки Сигналов (ЦОС), но неискушённому пользователю совершенно не понятно, зачем всё это нужно и где, а главное как это применить.
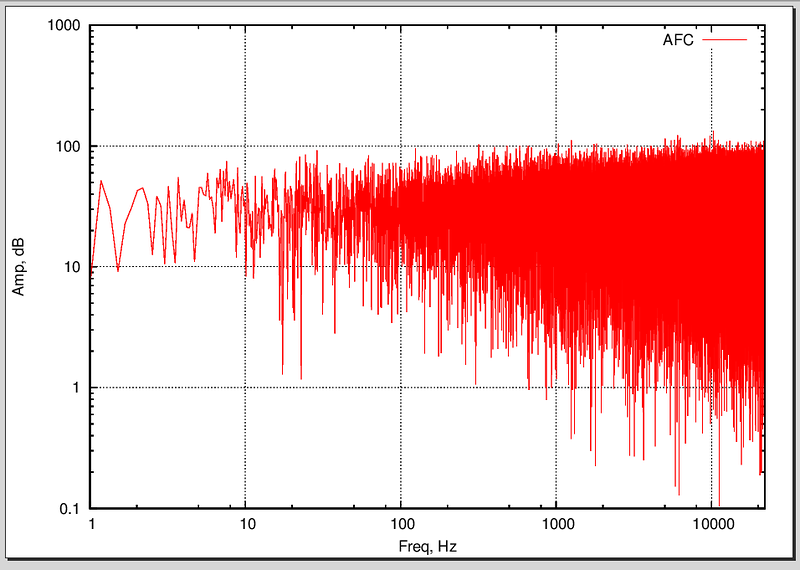
АЧХ шума.
Лично мне после прочтения этих статей (например, этой ) не стало понятно, что это и зачем оно нужно в реальной жизни, хотя было интересно и красиво.
Хочется не просто поглядеть красивые картинки, а так сказать, ощутить нутром, что и как работает. И я приведу конкретный пример с генерацией и обработкой звуковых файлов. Можно будет и послушать звук, и поглядеть его спектр, и понять, почему это так.
Статья не будет интересна тем, кто владеет теорией функций комплексной переменной, ЦОС и прочими страшными темами. Она скорее для любопытствующих, школьников, студентов и им сочувствующих :).
АЧХ шума.
Лично мне после прочтения этих статей (например, этой ) не стало понятно, что это и зачем оно нужно в реальной жизни, хотя было интересно и красиво.
Хочется не просто поглядеть красивые картинки, а так сказать, ощутить нутром, что и как работает. И я приведу конкретный пример с генерацией и обработкой звуковых файлов. Можно будет и послушать звук, и поглядеть его спектр, и понять, почему это так.
Статья не будет интересна тем, кто владеет теорией функций комплексной переменной, ЦОС и прочими страшными темами. Она скорее для любопытствующих, школьников, студентов и им сочувствующих :).


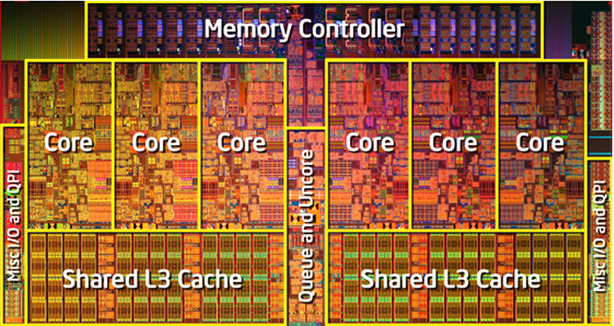
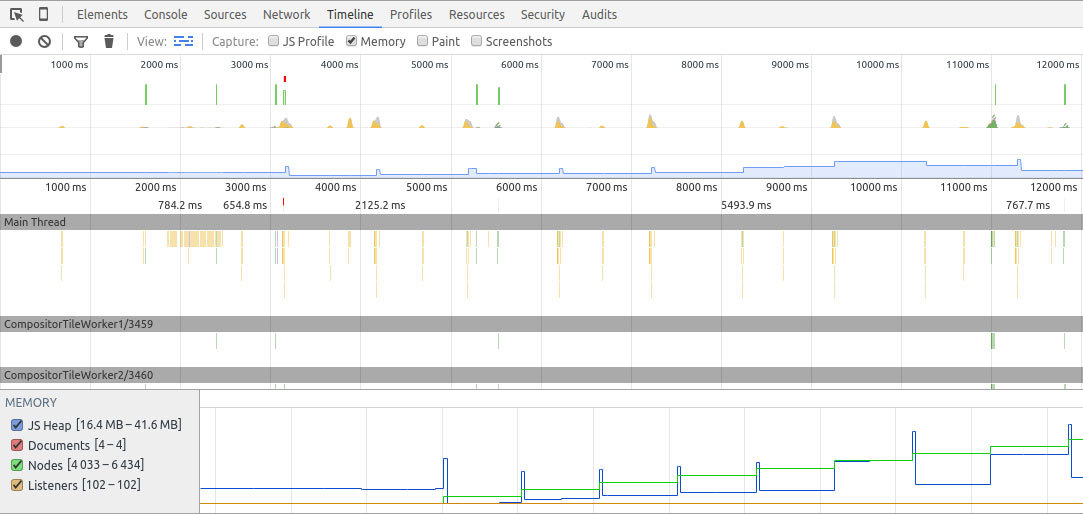




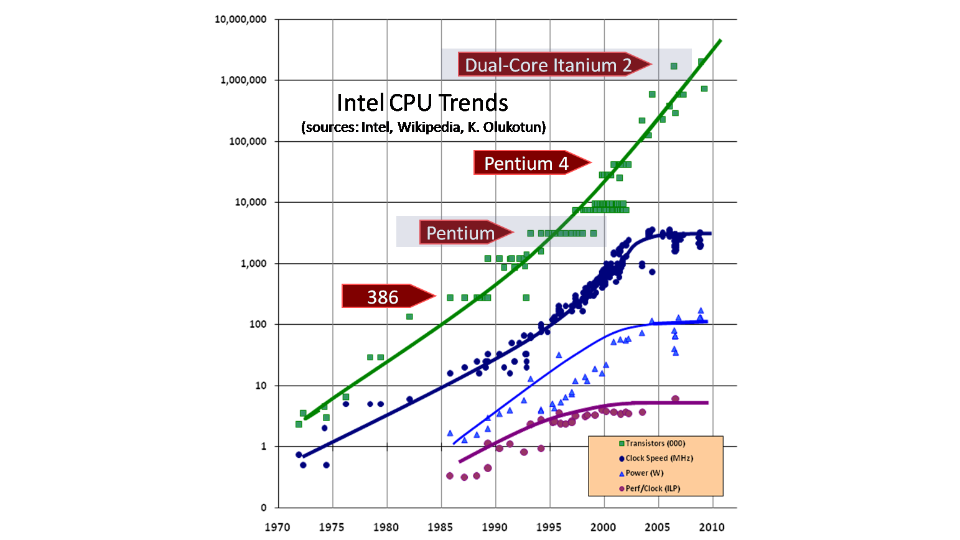


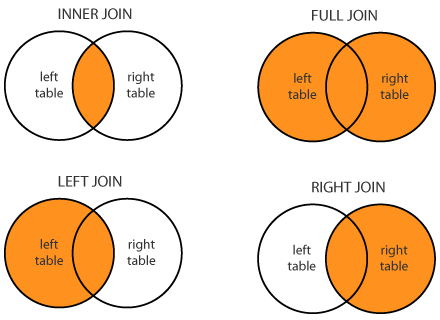
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.