
Приведу несколько распространённых стратегий развертывания приложений/сервисов, а также разберу пять популярных стратегий «жонглирования» данными между системами кеширования и базами данных.
Приведу несколько распространённых стратегий развертывания приложений/сервисов, а также разберу пять популярных стратегий «жонглирования» данными между системами кеширования и базами данных.

Команда Trendyol Platform разработала решение проблемы межмикросервисного кэширования в Kubernetes. Приводим перевод статьи, где она делится опытом и рассказывает о создании приложения Sidecache.
Допустим, мы хотим создать чат и хранить сообщения для него. Вполне возможно, мы можем добавить для этого простую базу данных (БД), такую как MySQL или даже NoSQL БД.
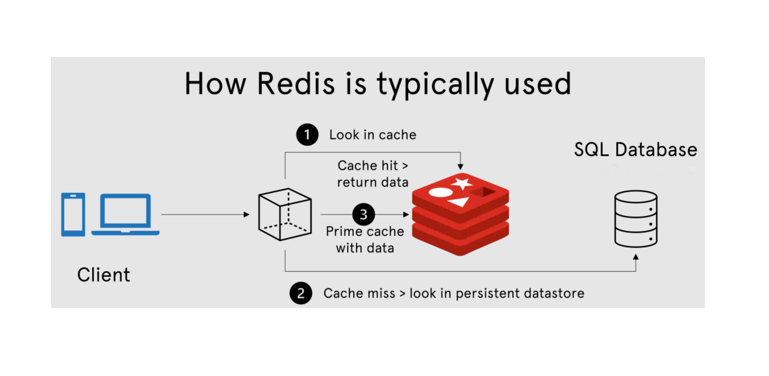
Обычно многие используют Redis как key‑value (dictionary) хранилище. Тем не менее, Redis — это несколько большее, чем key‑value, как многие привыкли думать.
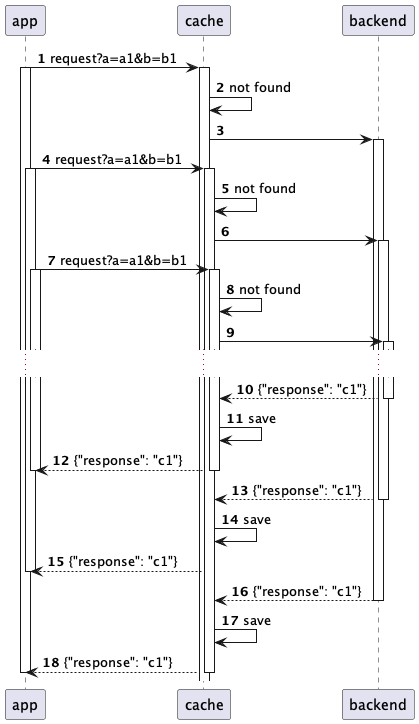
Способность обрабатывать большой объем запросов и данных в реальном времени является ключевым аспектом надежности и производительности современных информационных систем. Одним из способов повышения надежности, снижения нагрузки и, как следствие, расходов на сервера, является применение системы эффективного кэширования на уровне приложения. В этой статье я расскажу о возможных подводных камнях и эффективных стратегиях построения такой системы.
")

NSURLCache — это комплексное решение для кеширования сетевых запросов в оперативной памяти или на диске. В соответствии с документацией Apple, любой запрос с использованием NSURLConnection будет «пропущен» через NSURLCache.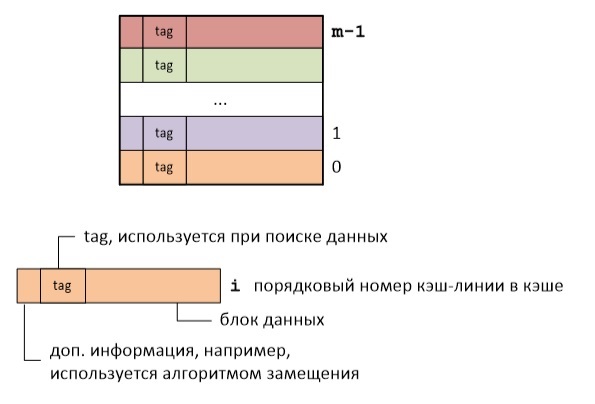
Примечание переводчика.
Есть интересная технология в мире БД — MUMPS. Этот язык программирования и доступа к данным известен уже несколько десятилетий, отлажен и является взрослой проверенной технологией.
Приведу аналогию: если SQL можно сравнить с Бейсиком, то MUMPS больше похож на Си — даёт высочайшую производительность, гибкость и универсальность, позволяя создавать наисложнейшие структуры данных.
Перед вами перевод первой части статьи «Extreme Database programming with MUMPS Globals». Если сообществу он покажется интересным, то последует перевод второй части.
Каждое пересечение строки и столбца содержит ровно одно значение из соответствующего домена (и больше ничего).
Одно и то же значение может быть атомарным или неатомарным в зависимости от смысла этого значения. Например, значение «4286» является
- атомарным, если его смысл — «пин-код кредитной карты» (при разбиении на части или переупорядочивании смысл теряется)
- неатомарным, если его смысл — «набор цифр» (при разбиении на части или переупорядочивании смысл не теряется)

