Оптимизация производительности – это такая область, в которой каждый хотел бы стать великим мастером. Если говорить о специалистах в области работы с базами данных, то мы все приходим новичками и в начале карьеры затрачиваем массу времени, изучая основы, стараясь постичь искусство настройки серверов баз данных и приложений для улучшения производительности. Однако, и по мере проникновения в тему глубже, оптимизация производительности не становится легче.
По мере развития технологий, внедрению современных «гибких» подходов, «непрерывной интеграции» в области баз данных необходимость в более быстром отклике на запросы конечных пользователей только усиливается. В нынешних условиях распространения мобильных устройств практически всегда требуется внести изменения в системы обработки данных, чтобы ускорить обмен данными с «нативными» или WEB-приложений пользователей.
Мы наблюдаем постоянное появление и ввод новых технологий. Это здорово! А в это же время имеющиеся «старые» технологии требуют массу внимания и времени для поддержки. «Океан» данных, «море» баз данных, больше распределенных систем. Остается меньше времени на настройку и оптимизацию. Сокращение окон для модификации, поддержки и внесения изменений осложняет задачу увеличить непрерывность работы систем на имеющемся оборудовании.
В области настройки оптимизации баз данных, часто встречаются ситуации, когда трудно выбрать «правильное» решение. В таких случаях приходится полагаться на различные инструменты, которые помогают оценить ситуацию и найти пути ее улучшения. Освоив такие инструменты, часто становится проще найти лучшее решение, если в дальнейшем возникает подобная ситуация.
В подтверждение этой мысли приведу перевод любопытной статьи из блога
bulldba.com/db-optimizer
В новых релизах DB Optimizer компании Embarcadero, начиная с версии 3.0, имеется отличная новая возможность: наложить на диаграмму VST explain plan запроса!
[Примечание переводчика:
Диаграмма визуальной оптимизации Visual SQL Tuning (VST) превращает текстовый SQL-код в графическую SQL-диаграмму, показывает индексы и ограничения в таблицах и представлениях с использованием статистических сведений, а также операции соединения, используемые в инструкции SQL, такие как прямые и подразумеваемые декартовы произведения и отношения «многие ко многим». ]
Возьмем для примера следующий запрос:
SELECT COUNT (*)
FROM a, b, c
WHERE
b.val2 = 100 AND
a.val1 = b.id AND
b.val1 = c.id;
По колонкам b.id и c.id созданы индексы. В окне DB Optimizer этот запрос выглядит так:
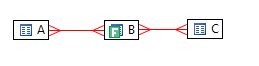
Красные линии связей такого вида в соответствии с определениями говорят, что отношения могут быть типа «многие ко многим».
Вопрос: «какой план выполнения этого запроса является оптимальным?».
Один из возможных оптимальных планов выполнения этого «дерева запроса» может быть таким:
- Начать с наиболее селективного фильтра
- Выполнить JOIN с подчиненными таблицами, если возможно
- Если нет – то выполнить JOIN с таблицей верхнего уровня

 Зная, что антипаттерны не статичны и эволюционируют по мере того, как вы растете как разработчик SQL, и тот факт, что есть много, что нужно учитывать, когда вы задумываетесь об альтернативах, также означает, что избежать антипаттернов и переписывания запросов может быть довольно сложной задачей. Любая помощь может пригодиться, и именно поэтому более структурированный подход к оптимизации запроса с помощью некоторых инструментов может быть наиболее эффективным.
Зная, что антипаттерны не статичны и эволюционируют по мере того, как вы растете как разработчик SQL, и тот факт, что есть много, что нужно учитывать, когда вы задумываетесь об альтернативах, также означает, что избежать антипаттернов и переписывания запросов может быть довольно сложной задачей. Любая помощь может пригодиться, и именно поэтому более структурированный подход к оптимизации запроса с помощью некоторых инструментов может быть наиболее эффективным.