
В интернете полно статей на тему основанных на N-граммах языковых моделей. При этом, готовых для работы библиотек довольно мало.
Есть KenLM, SriLM и IRSTLM. Они популярны и используются во многих крупных проектах. Но есть проблемы:
- Библиотеки старые, не развиваются.
- Плохо поддерживают русский язык.
- Работают только с чистым, специально подготовленным, текстом
- Плохо поддерживают UTF-8. Например, SriLM с флагом tolower ломает кодировку.
Из списка немного выделяется KenLM. Регулярно поддерживается и не имеет проблем с UTF-8, но она также требовательна к качеству текста.
Когда-то мне потребовалась библиотека для сборки языковой модели. После многих проб и ошибок пришёл к выводу, что подготовка датасета для обучения языковой модели — слишком сложный и долгий процесс. Особенно, если это русский язык! А ведь хотелось как-то всё автоматизировать.
В своих исследованиях отталкивался от библиотеки SriLM. Сразу отмечу, что это не заимствование кода и не fork SriLM. Весь код написан полностью с нуля.

 Многим разработчикам и тестеровщикам, использующим Visual Studio, известен Брайан Келлер (
Многим разработчикам и тестеровщикам, использующим Visual Studio, известен Брайан Келлер (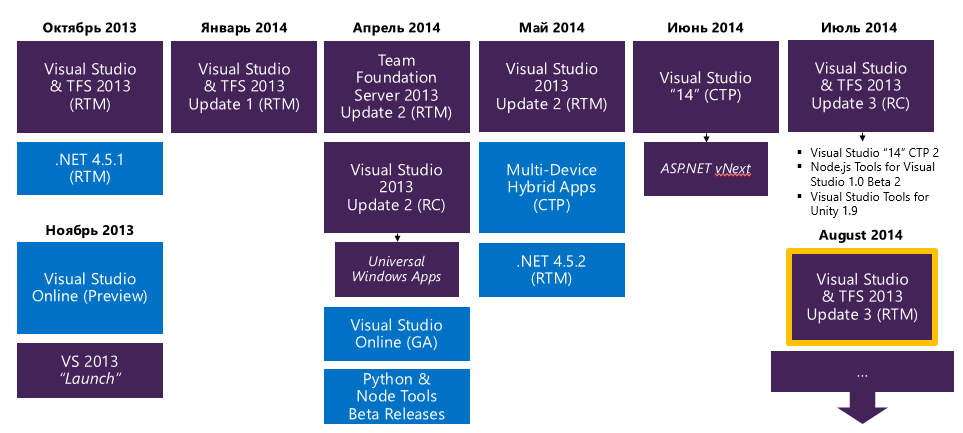


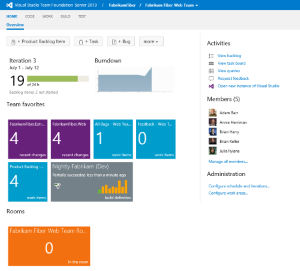
 Наверное многие из вас уже видели скриншоты нового Team Explorer в посте рассказывающем об улучшениях в области контроля исходного кода. В этом топике хотелось бы сосредоточиться на общих новинках Team Explorer.
Наверное многие из вас уже видели скриншоты нового Team Explorer в посте рассказывающем об улучшениях в области контроля исходного кода. В этом топике хотелось бы сосредоточиться на общих новинках Team Explorer. Уважаемые коллеги, разработчики и просто интересующиеся! Приглашаю вас посетить
Уважаемые коллеги, разработчики и просто интересующиеся! Приглашаю вас посетить 

 Управление жизненным циклом приложений это очень важный подход который позволяет создавать качественные системы. Но полноценное создание ALM среды и настройка инструментов может требовать создания сложной инфраструктуры. Вот почему год назад, в рамках первой конференции //Build/ в тестовую эксплуатацию был запущен сервис tfspreviev.com. По сути это облачный вариант Team Foundation Server, который готов к эксплуатации сразу. Вчера состоялся долгожданный RTM этого сервиса. Приятным сюрпризом оказалось то что он бесплатен для команд до 5 человек.
Управление жизненным циклом приложений это очень важный подход который позволяет создавать качественные системы. Но полноценное создание ALM среды и настройка инструментов может требовать создания сложной инфраструктуры. Вот почему год назад, в рамках первой конференции //Build/ в тестовую эксплуатацию был запущен сервис tfspreviev.com. По сути это облачный вариант Team Foundation Server, который готов к эксплуатации сразу. Вчера состоялся долгожданный RTM этого сервиса. Приятным сюрпризом оказалось то что он бесплатен для команд до 5 человек.
