Читая Хабр на предмет материалов по нейросетям и вообще по теме искусственного интеллекта я нашел пост о однослойном перцептроне и решил из любопытства начать изучение нейросетей с него, а потом и расширить опыт до многослойного перцептрона. О чем и повествую.
Нейронные сети: практическое применение
15 min

Наталия Ефремова погружает публику в специфику практического использования нейросетей. Это — расшифровка доклада Highload++.
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace. Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
История предсказания переходов с 1 500 000 года до н.э. по 1995 год
18 min
Translation
Это приблизительная расшифровка лекции о предсказании переходов (предсказании ветвлений) на localhost, новом цикле лекций, организованном RC. Выступление состоялось 22 августа 2017 года в Two Sigma Ventures.
Кто из вас использует ветвления в своём коде? Можете поднять руку, если применяете операторы if или сопоставление с образцом?
Сейчас я не буду просить вас подымать руки. Но если я спрошу, сколько из вас думают, что хорошо понимают действия CPU при обработке ветвления и последствия для производительности, и сколько из вас может понять современную научную статью о предсказании ветвлений, то руки подымет меньше людей.
Цель моего выступления — объяснить, как и почему процессоры осуществляют предсказание переходов, а затем вкратце объяснить классические алгоритмы предсказания переходов, о которых вы можете прочитать в современных статьях, чтобы у вас появилось общее понимание темы.
Кто из вас использует ветвления в своём коде? Можете поднять руку, если применяете операторы if или сопоставление с образцом?
Большинство присутствующих в аудитории поднимают руки Сейчас я не буду просить вас подымать руки. Но если я спрошу, сколько из вас думают, что хорошо понимают действия CPU при обработке ветвления и последствия для производительности, и сколько из вас может понять современную научную статью о предсказании ветвлений, то руки подымет меньше людей.
Цель моего выступления — объяснить, как и почему процессоры осуществляют предсказание переходов, а затем вкратце объяснить классические алгоритмы предсказания переходов, о которых вы можете прочитать в современных статьях, чтобы у вас появилось общее понимание темы.
Введение в нейросети
9 min
Translation

Искусственные нейронные сети сейчас находятся на пике популярности. Можно задаться вопросом, сыграло ли громкое название свою роль в маркетинге и применении этой модели. Я знаю некоторых бизнес-менеджеров, радостно упоминающих об использовании в их продуктах «искусственных нейронных сетей» и «глубокого обучения». Так ли рады были бы они, если бы их продукты использовали «модели с соединёнными кругами» или «машины „совершишь ошибку — будешь наказан“»? Но, вне всяких сомнений, искусственные нейросети — стоящая вещь, и это очевидно благодаря их успеху во множестве областей применения: распознавание изображений, обработка естественных языков, автоматизированный трейдинг и автономные автомобили. Я специалист по обработке и анализу данных, но раньше не понимал их, поэтому чувствовал себя мастером, не освоившим свой инструмент. Но наконец я выполнил своё «домашнее задание» и написал эту статью, чтобы помочь другим преодолеть те же самые препятствия, которые встретились мне в процессе моего (всё ещё продолжающегося) обучения.
Код на R для примеров, представленных в этой статье, можно найти здесь в Библии задач машинного обучения. Кроме того, после прочтения этой статьи стоит изучить часть 2, Neural Networks – A Worked Example, в которой приведены подробности создания и программирования нейросети с нуля.
Изобретаем велосипед или пишем персептрон на С++. Часть 1 и 2
7 min
Tutorial
Изобретаем велосипед или пишем персептрон на C++. Часть 1
Напишем простую библиотеку для реализации персептрона на C++

Изобретаем велосипед или пишем персептрон на С++. Часть 3
5 min
Tutorial
Изобретаем велосипед или пишем персептрон на C++. Часть 3
Реализуем обучение многослойного персептрона на C++ при помощи метода обратного распространения ошибки.
Перцептрон Розенблатта — что забыто и придумано историей?
4 min
На хабре — уже есть несколько статей про искусственные нейронные сети. Но чаще говорят о т.н. многослойном перцептроне и алгоритме обратного распространения ошибки. А знаете те ли Вы что эта вариация ничем не лучше элементарного перцептрона Розенблатта?
Например, вот в этом переводе Что такое искусственные нейронные сети? мы можем увидеть, что о перцептроне Розенблатта пишут такое:
Причем это встречается на разный лад в различных статьях, книгах и даже учебниках.
Но это, наверно, самая великая реклама в области ИИ. А в науке это называется фальсификация.
Например, вот в этом переводе Что такое искусственные нейронные сети? мы можем увидеть, что о перцептроне Розенблатта пишут такое:
Демонстрация персептона Розенблатта показала, что простые сети из таких нейронов могут обучаться на примерах, известных в определенных областях. Позже, Минский и Паперт доказали, что простые пресептоны могут решать только очень узкий класс линейно сепарабельных задач, после чего активность изучения ИНС уменьшилась. Тем не менее, метод обратного распространения ошибки обучения, который может облегчить задачу обучения сложных нейронных сетей на примерах, показал, что эти проблемы могут быть и не сепарабельными.
Причем это встречается на разный лад в различных статьях, книгах и даже учебниках.
Но это, наверно, самая великая реклама в области ИИ. А в науке это называется фальсификация.
Какова роль первого «случайного» слоя в перцептроне Розенблатта
6 min
Итак в статье Перцептрон Розенблатта — что забыто и придумано историей? в принципе как и ожидалось всплыло некоторая не осведомленность о сути перцептрона Розенблатта (у кого-то больше, у кого-то меньше). Но честно говоря я думал будет хуже. Поэтому для тех кто умеет и хочет слушать я обещал написать как так получается, что случайные связи в первом слое выполняют такую сложную задачу отображения не сепарабельного (линейно не разделимого) представления задачи в сепарабельное (линейно разделимое).
Честно говоря, я мог сослаться просто на теорему сходимости Розенблатта, но так как сам не люблю когда меня «посылают в гугл», то давайте разбираться. Но я исхожу из-то, что Вы знаете по подлинникам, что такое перцептрон Розенблатта (хотя проблемы в понимании всплыли, но я все же надеюсь что только у отдельных людей).
Честно говоря, я мог сослаться просто на теорему сходимости Розенблатта, но так как сам не люблю когда меня «посылают в гугл», то давайте разбираться. Но я исхожу из-то, что Вы знаете по подлинникам, что такое перцептрон Розенблатта (хотя проблемы в понимании всплыли, но я все же надеюсь что только у отдельных людей).
Запрограммируем перцептрон Розенблатта?
17 min
После одной провокационной статьи Перцептрон Розенблатта — что забыто и придумано историей? и одной полностью доказывающей отсутствие проблем в перцептроне Розенблатта, и даже наоборот показывающей некоторые интересные стороны и возможности Какова роль первого «случайного» слоя в перцептроне Розенблатта, я так думаю у некоторых хабражителей появилось желание разобраться, что же это за зверь такой — перцептрон Розенблатта. И действительно, достоверную информацию о нем, кроме как в оригинале, найти не возможно. Но и там достаточно сложно описано как этот перцептрон запрограммировать. Полный код я выкладывать не буду. Но попробуем вместе пройти ряд основ.
Начнем… ах да, предупреждаю, я буду рассказывать не классически, а несколько осовременено…
Начнем… ах да, предупреждаю, я буду рассказывать не классически, а несколько осовременено…
«Жидкий перцептрон» или гипотеза как реализовать реальную парралельность
5 min
В комментариях к статье Алгоритмическая неразрешимость – это не препятствие для алгоритмического ИИ я высказался, в свете того, что
и намекнул, что проблемы построения ИИ заключаются скорее в принципиальной (непреодолимой) медленности компьютеров построенных по принципу машин Тьюринга.
В статье же говорилось о теоретической проблеме алгоритмической неразрешимости на примере задачи останова.
и вот тут кажется недооценен «алгоритм» работы человека с нахождением частных случаев. Не под силу это компьютеру, ему не хватает устройства, благодаря которому он мог бы выделять частные случаи. Конечно, в комментариях в этой статье — многие сразу закодировали эти частные случаи, но речь же идет о том, чтобы компьютер сам это осуществил бы при решении. Представляется, что нахождение частных случаев как минимум принципиально снижает сложность расчетов. Человек упрощая и идеализируя затем переходит к формулированию законов, тем самым переходя на качественно другой уровень. И вот это компьютеру не доступно.
Но все по порядку.
Почему-то все зациклились на задачах NP. Но никто почему то не ставит задачи БЫСТРЕЕ решать задачи класса P (вплоть до мгновенного ответа)
и намекнул, что проблемы построения ИИ заключаются скорее в принципиальной (непреодолимой) медленности компьютеров построенных по принципу машин Тьюринга.
В статье же говорилось о теоретической проблеме алгоритмической неразрешимости на примере задачи останова.
Человек решает задачу останова, но делает это с ошибками, вероятность которых повышается с усложнением программ. Способность человека решать алгоритмически неразрешимые проблемы (как массовые проблемы) является крайне сомнительной. Его способность находить решения для отдельных частных случаев ничего не доказывает, ведь это под силу и компьютеру.
и вот тут кажется недооценен «алгоритм» работы человека с нахождением частных случаев. Не под силу это компьютеру, ему не хватает устройства, благодаря которому он мог бы выделять частные случаи. Конечно, в комментариях в этой статье — многие сразу закодировали эти частные случаи, но речь же идет о том, чтобы компьютер сам это осуществил бы при решении. Представляется, что нахождение частных случаев как минимум принципиально снижает сложность расчетов. Человек упрощая и идеализируя затем переходит к формулированию законов, тем самым переходя на качественно другой уровень. И вот это компьютеру не доступно.
Но все по порядку.
Как устроена нейросеть
3 min
Всем привет! Меня зовут Константин Берлинский, я фуллстек-разработчик в компании БКС. Недавно я самостоятельно изучал нейросети и по итогам написал книгу. Ниже я расскажу как устроена простейшая нейросеть.

Изучаем Q#. Обучаем перцептрон
Medium
16 min
Tutorial

Базовым элементом построения нейросетей, как мы знаем, является модель нейрона, а, соответственно, простейшей моделью нейрона, является перцептрон.
С математической точки зрения, перцептрон решает задачу разделения пространства признаков гиперплоскостью, на две части. То есть является простейшим линейным классификатором.
Обобщенная схема нейрона представляет собой функцию f(SUM Wi*xi - W0)
Здесь:
• x1,...,xn – компоненты вектора признаков x=(x1,x2,...,xn);
• SUM – сумматор;
• W1,W2,...,Wn – синоптические веса;
• f – функция активации; f(v)= { 0 при v < 0 и 1 при v>0 }
• W0 – порог.
Таким образом, нейрон представляет собой линейный классификатор с дискриминантной функцией g(X)=f(SUM Wi*Xi - W0).
И задача построения линейного классификатора для заданного множества прецедентов (Xk,Yk) сводится к задаче обучения нейрона, т.е. подбора соответствующих весов W1,W2,...,Wn и порога W0.
Классический подход обучения перцептрона хорошо известен
• Инициализируем W0,W1,W2,...Wn (обычно случайными значениями)
• Для обучающей выборки (Xk,Yk) пока для всех значений не будет выполняться f(SUM Wi*Xki - W0)==Yi повторяем последовательно для всех элементов
• W = W + r(Yk - f(SUM Wi*Xki - W0)) * Xk*, где 0 < r < 1 - коэффициент обучения
Для доказательства сходимости алгоритма применяется теорема Новикова, которая говорит, что если существует разделяющая гиперплоскость, то она может быть найдена указанным алгоритмом.
Что же нам может предложить модель квантовых вычислений для решения задачи обучения перцептрона - то есть для нахождения синоптических весов по заданной обучающей выборке?
Ответ - мы можем сразу опробовать все возможные значения весов и выбрать из них тот - который удовлетворяет нашим требованиям - то есть правильно разделяет обучающую выборку.
Для понимания данного туториала вам потребуются базовые знания по
• нейросетям
• квантовым вычислениям (кубиты и трансформации)
• программированию на Q-sharp
Треугольник Паскаля vs цепочек типа «000…/111…» в бинарных рядах и нейронных сетях
6 min
Серия «Белый шум рисует черный квадрат»
История цикла этих публикаций начинается с того, что в книге Г.Секей «Парадоксы в теории вероятностей и математической статистике» (стр.43), было обнаружено следующее утверждение:

Рис. 1.
По анализу комментарий к первым публикациям (часть 1, часть 2) и последующими рассуждениями созрела идея представить эту теорему в более наглядном виде.
Большинству из участников сообщества знаком треугольник Паскаля, как следствие биноминального распределения вероятностей и многие сопутствующие законы. Для понимания механизма образования треугольника Паскаля развернем его детальнее, с развертыванием потоков его образования. В треугольнике Паскаля узлы формируются по соотношению 0 и 1, рисунок ниже.
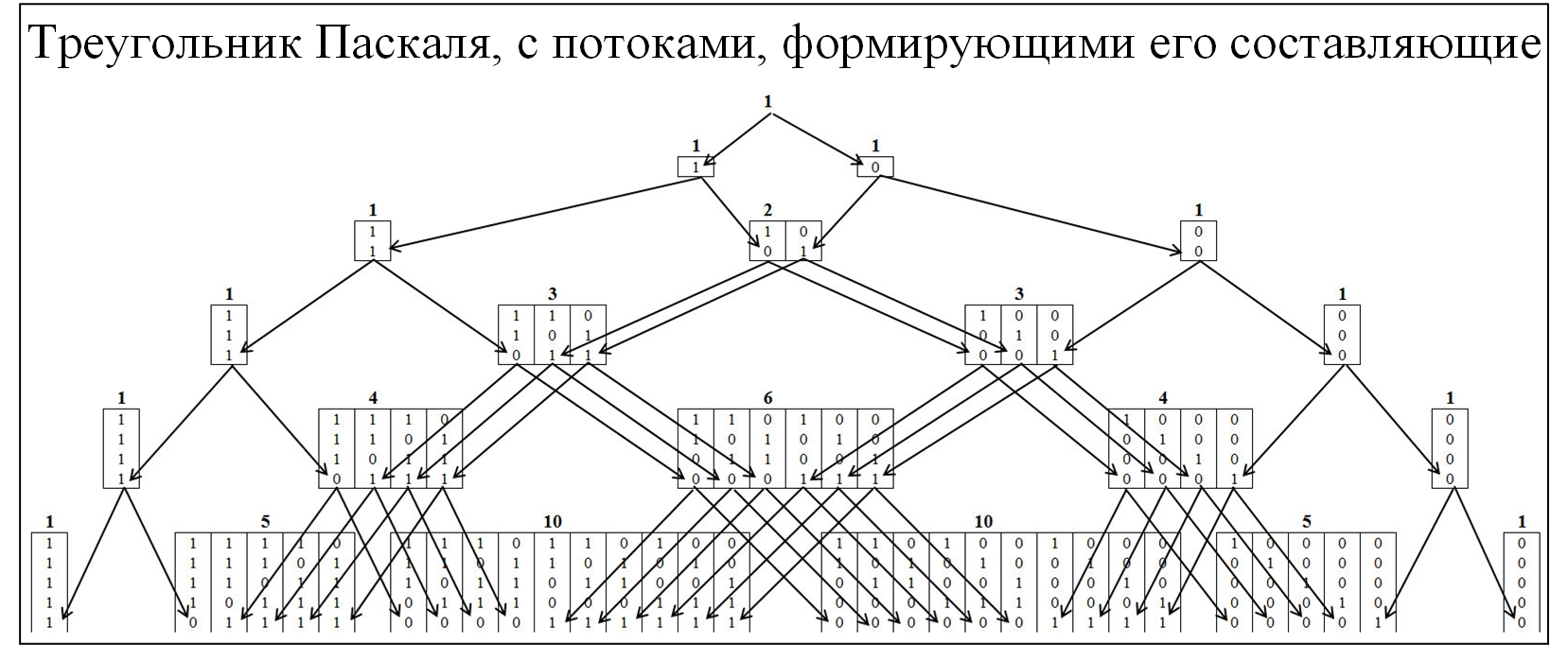
Рис. 2.
Для понимания теоремы Эрдёша-Реньи составим аналогичную модель, но узлы будут формироваться из значений, в которых присутствуют наибольшие цепочки, состоящие последовательно из одинаковых значений. Кластеризации будет проводиться по следующему правилу: цепочки 01/10, к кластеру «1»; цепочки 00/11, к кластеру «2»; цепочки 000/111, к кластеру «3» и т.д. При этом разобьём пирамиду на две симметричные составляющие рисунок 3.

Рис. 3.
Первое что бросается в глаза это то, что все перемещения происходят из более низкого кластера в более высокий и наоборот быть не может. Это естественно, так как если цепочка размера j сложилась, то она уже не может исчезнуть.
Julia и нейронные сети: Flux
11 min
Tutorial
Прошло чуть больше года, с тех пор как MIT объявил о релизе высокопроизводительного языка общего назначения Julia. С тех пор язык набирает популярность: он используется в более чем 1500 университетах (в некоторых преподается в качестве первого ЯП), а области применения охватывают от медицинской диагностики и планирования космических миссий до таких насущных проблем, как оптимизация трафика школьных автобусов.
Одним из ключевым полей деятельности многих проектов, как не трудно догадаться, является машинное обучение, для которого на Julia есть множество мощных инструментов, а недавно вышел в свет довольно интересный проект — Система вероятностного программирования общего назначения "GEN".
Сегодня же мы обратим внимание на, как понятно из названия, пакет Flux, предоставляющий всю мощь нейронных сетей. Постараемся пройти путь от обработки и исследования наборов изображений до обученной нейронной сети, чтобы получить полноценный классификатор!
Двоичный алгоритм машинного обучения с динамической структурой
3 min
Recovery Mode

Если рассматривать сегодняшние алгоритмы машинного обучения с движением от невежества (низ) к осознанию (верх) то текущие алгоритмы похожи на прыжок. После прыжка происходит замедление скорости развития (обучающая способность) и неминуемый разворот и падение (переобучение). Все усилия сводятся к попыткам приложить как можно больше сил к прыжку, что увеличивает высоту прыжка но кардинально не меняет результатов. Прокачивая прыжки мы увеличиваем высоту, но не учимся летать. Для освоения техники «контролируемого полета» потребуется переосмыслить некоторые базовые принципы.
Почему инициализировать веса нейронной сети одинаковыми значениями (например, нулями) – это плохая идея
11 min

В популярных фреймворках машинного обучения TensorFlow и PyTorch при инициализации весов нейросети используются случайные числа. В этой статье мы попытаемся разобраться, почему для этих целей не используют ноль или какую-нибудь константу.
Кто хочет быстрый и короткий ответ на этот вопрос, вот он: если инициализировать веса нулями, то нейросеть может не обучаться совсем или обучаться плохо.
Кто хочет более развёрнуто узнать, что значит «плохо», может просто перемотать к заключению в конце статьи.
А тем, кто хочет в деталях разобраться с основами обучения нейронных сетей, добро пожаловать в мир математических формул. Мы детально разберём, из-за чего в механизме обучения может произойти «сбой».
Анализ финансовых ботов, можно ли заработать?
10 min

Разбираю разные подходы к созданию ботов и смотрю на их эффективность
Заработает ли бот достаточно денег?
Будет ли стабильный заработок?
Достигнет ли он когда-нибудь годового дохода в $100,000?
В этом посте я отвечу на эти вопросы и дам вам несколько советов, как двигаться дальше.
Коллапсирующие CNN: аппроксимация, имитация и щепотка спектральной магии
14 min

Можно ли ускорить обученную сверточную нейросеть? Можно ли заметно сократить ее веса, не снижая точности? Можно ли найти и «обезвредить» узкие места в модели, препятствующие достижению максимальной точности? Можно ли радикально изменить архитектуру готовой сетки, не прибегая к обучению с нуля?
Простейшая нейросеть: еще раз и подробнее
10 min
Review

Машинное обучение это незаменимый инструмент для решения задач, которые легко решаются людьми, но не классическими программами. Ребенок легко поймет, что перед ним буква А, а не Д, однако программы без помощи машинного обучения справляются с этим весьма средне. И едва ли вообще справляются при минимальных помехах. Нейросети же уже сейчас решают многие задачи (включая эту) намного лучше людей. Их способность обучаться на примерах и выдавать верный результат поистине очаровывает, однако за ней лежит простая математика. Рассмотрим это на примере простого перцептрона.
Данная статья представляет собой пересказ-конспект первой части книги Тарика Рашида "Создай свою нейросеть" для тех, кто начал изучать тему, не понял отдельные детали или с трудом охватывает общую картину.
Откуда есть пошла аналитика и что отличает DS, DA, BA и SA
Easy
18 min

Каждому из нас приходится принимать решения и иметь дело с их последствиями. Если речь идёт о бизнесе, то верный выбор может принести кругленькую сумму денег, а неверный — стоить целого состояния. Неудивительно, что сейчас в моде data-driven-подход, при котором каждое бизнес-решение принимается на основе объективных данных. Преобразованием данных в решения занимаются аналитики: финансовые, инвестиционные, продуктовые, аналитики рисков — им нет числа, как и строкам в их таблицах.
Разновидностей аналитиков стало уже так много, что в них немудрено и запутаться. Под катом мы разберём, кто такие аналитики данных, системные аналитики, бизнес-аналитики и дата-сайентисты: чем они отличаются, что у них общего, какие навыки нужны, чтобы стать одним из них. А заодно — вспомним первопроходцев, выдающихся аналитиков прошлого и над какими задачами они работали.