Comments 125
gettext более предназначен для перевода переменных внутри кода, а не самого наполнения.
Я понимаю о чем вы, я изучал этот инструмент, но интересует именно не локализация текста шаблона (имеется в виду всяческие текстовые переменные такие, как сообщения об ошибках) это уже реализовано.
Интересует комплексный подход к интернационализации, когда у нас есть именно контент, который нужно перевести и который хранится в базе.
Интересует комплексный подход к интернационализации, когда у нас есть именно контент, который нужно перевести и который хранится в базе.
Ты совершенно не понял о чем статья — gettext используется для другого!
Лично я пришел к четвертому варианту по вашей классификации в последнем проекте. Лучше бы не приходил :-) Плюсом является только действительно понятный и четкий интерфейс для перевода. В остальном сплошные неудобства. Использовал самопальный наворот над ActiveRecord фреймворка Yii.
В следующий раз, наверное, хочу пробовать второй вариант. Только к каждой странице добавить alias (кусок адреса url) и по нему связать страницы. Т.е. страницы с одинаковыми url являются переводами друг друга. А в адресной строке такие адреса отличаются первым сегментом — языком.
Заинтересовал и последний вариант, надо обдумать. Спасибо за идею.
В следующий раз, наверное, хочу пробовать второй вариант. Только к каждой странице добавить alias (кусок адреса url) и по нему связать страницы. Т.е. страницы с одинаковыми url являются переводами друг друга. А в адресной строке такие адреса отличаются первым сегментом — языком.
Заинтересовал и последний вариант, надо обдумать. Спасибо за идею.
Ну второй вариант правильней связывать по странице оригинала текста и админить так же. Это будет более универсальным решением, когда речь идет о создании любой структуры. Хотя и ваш вариант тоже является выходом из положения.
Ну а для своего фреймворка, я считаю нужным вшить возможность интернационализации. Думаю только над выбором варианта.
Интересно есть ли другие механизмы.
Ну а для своего фреймворка, я считаю нужным вшить возможность интернационализации. Думаю только над выбором варианта.
Интересно есть ли другие механизмы.
Варианты 1 и 4, наиболее удобны, каждый при своих условиях.
Я использую модификацию варианта 4, но только с одной таблицей.
У меня составной примари ключ из строк:
code — некоторый код страницы (например «main» или «about»), который используется только внутри кода.
language — двубуквенный код языка
и далее поля типа заголовка, текста, даты модификации, логина переводчика, и т.п.
Этот подход имеет недостаток — строковый составной примари ключ, конечно, тормознутее целочисленных id.
Плюс этого подхода — я в базе всегда вижу по коду что это за текст и на каком языке. Например, я делал сайт в котором было 14 языком, в том числе арабский и фарси, там я не то чтоб не понимал, я вообще не знал где кончается одна буква и начинается другая, и какой именно это из языков. Код страницы и код языка сразу говорят что содержится в остальных полях, это очень помогает если нужно найти запись без помощи переводчика.
И еще плюс для внутреннего устройства кода довольно удобно делать выборки с ЧПУ, например www.example.com/ru/about, где ru и about сразу дают нужный ключ.
Я использую модификацию варианта 4, но только с одной таблицей.
У меня составной примари ключ из строк:
code — некоторый код страницы (например «main» или «about»), который используется только внутри кода.
language — двубуквенный код языка
и далее поля типа заголовка, текста, даты модификации, логина переводчика, и т.п.
Этот подход имеет недостаток — строковый составной примари ключ, конечно, тормознутее целочисленных id.
Плюс этого подхода — я в базе всегда вижу по коду что это за текст и на каком языке. Например, я делал сайт в котором было 14 языком, в том числе арабский и фарси, там я не то чтоб не понимал, я вообще не знал где кончается одна буква и начинается другая, и какой именно это из языков. Код страницы и код языка сразу говорят что содержится в остальных полях, это очень помогает если нужно найти запись без помощи переводчика.
И еще плюс для внутреннего устройства кода довольно удобно делать выборки с ЧПУ, например www.example.com/ru/about, где ru и about сразу дают нужный ключ.
>>Я использую модификацию варианта 4, но только с одной таблицей.
Это уже вариант номер 2, а не 4…
Это уже вариант номер 2, а не 4…
Представим случай интернациональным интернет-магазином, где есть, ну очень много товаров. И у нас наивная цель сделать возможным перевод на любой язык с любого языка.
Тогда имеет право на жизнь 3-й вариант. И то, непонятно, как реализовать правильный интерфейс перевода.
У вас есть какие-нибудь примеры реализации?
Тогда имеет право на жизнь 3-й вариант. И то, непонятно, как реализовать правильный интерфейс перевода.
У вас есть какие-нибудь примеры реализации?
>>Этот подход имеет недостаток — строковый составной примари ключ, конечно, тормознутее целочисленных id.
Тут можно попробовать primary сделать int, а соответствие lang:code-id вынести в какой-нить быстрый кэш.
Тут можно попробовать primary сделать int, а соответствие lang:code-id вынести в какой-нить быстрый кэш.
Насчет первого варианта — не согласен, что он плохой. Ваша аргументация:
Это зависит от инструментов/абстракций, которые под это дело написаны. Например, для django есть приложение django-modeltranslation, которое реализует этот подход, и все удобно. Да и вообще, в чем неудобство — не очень понятно.
А тут смешан вопрос о структуре БД и вопрос о том, как ваша конкретная cms/cmf с ней работает. Абсолютно ничего не мешает сделать нормальный интерфейс для администрирования. Да и в любом случае, если нужно несколько вариантов перевода, то нужно заполнить несколько полей с переводами. Связь того, кто куда попадает, со структурой БД — это тоже, видимо, какая-то особенность вашей cms/cmf.
У первого подхода есть ряд плюсов: он простой, вместо join'ов или нескольких запросов данные выбираются из 1 таблицы, очень просто реализуется откат на «язык по умолчанию», если нужного перевода нет. В случае, если переводы лежат в отдельных таблицах, нужно или все переводы сразу для этого выбирать, или делать 2 запроса в случае, если перевода нет. Его минус — чтобы добавить язык, нужно менять структуру БД (что, впрочем, решается очень просто с помощью какого-нибудь инструмента для миграций), ну и разбухание одной таблицы.
Вы верно заметили, первый способ лучше использовать, когда языков немного, и они заранее известны. Но подавляющее большинство сайтов, где требуется i18n контента в базе — именно такие и есть ведь: 2, максимум 3 языка. Равноправный контент > чем на 3 языках — большая редкость, только википедия и приходит на ум сейчас. Обычно ведь перевод контента не требуется (или на это нет ресурсов — 2 языка-то поддерживать уже накладная задача), а нужен только перевод интерфейса, что решается совсем другими методами (gettext).
Когда их становиться больше, то эта структура будет ну очень не удобная. А если еще и переводимых полей больше…
Это зависит от инструментов/абстракций, которые под это дело написаны. Например, для django есть приложение django-modeltranslation, которое реализует этот подход, и все удобно. Да и вообще, в чем неудобство — не очень понятно.
Плюс в том, что находясь на определенной страницы в одном языке, мы попадаем на ту же страницу на другом языке. Администрирование большого количества языков неудобное, из-за количества редактируемых полей.
А тут смешан вопрос о структуре БД и вопрос о том, как ваша конкретная cms/cmf с ней работает. Абсолютно ничего не мешает сделать нормальный интерфейс для администрирования. Да и в любом случае, если нужно несколько вариантов перевода, то нужно заполнить несколько полей с переводами. Связь того, кто куда попадает, со структурой БД — это тоже, видимо, какая-то особенность вашей cms/cmf.
У первого подхода есть ряд плюсов: он простой, вместо join'ов или нескольких запросов данные выбираются из 1 таблицы, очень просто реализуется откат на «язык по умолчанию», если нужного перевода нет. В случае, если переводы лежат в отдельных таблицах, нужно или все переводы сразу для этого выбирать, или делать 2 запроса в случае, если перевода нет. Его минус — чтобы добавить язык, нужно менять структуру БД (что, впрочем, решается очень просто с помощью какого-нибудь инструмента для миграций), ну и разбухание одной таблицы.
Вы верно заметили, первый способ лучше использовать, когда языков немного, и они заранее известны. Но подавляющее большинство сайтов, где требуется i18n контента в базе — именно такие и есть ведь: 2, максимум 3 языка. Равноправный контент > чем на 3 языках — большая редкость, только википедия и приходит на ум сейчас. Обычно ведь перевод контента не требуется (или на это нет ресурсов — 2 языка-то поддерживать уже накладная задача), а нужен только перевод интерфейса, что решается совсем другими методами (gettext).
Я охарактеризовал их субъективно.
Ну а если нам необходима языковая расширяемость? Приходится при добавлении нового языка дублировать все поля и дописывать им новые префиксы. И чем больше у нас языков, тем больше у нас столбцов в таблице и тем корявей это начинает выглядеть.
И задача стоит конкретно переводить не интерфейс а контент.
Ну а если нам необходима языковая расширяемость? Приходится при добавлении нового языка дублировать все поля и дописывать им новые префиксы. И чем больше у нас языков, тем больше у нас столбцов в таблице и тем корявей это начинает выглядеть.
И задача стоит конкретно переводить не интерфейс а контент.
Да и плохой он только в случае, когда требуется универсализация, во всех остальных он чаще всего верен.
Удобство — вопрос инструментов и уровня абстракции. Например, как это в django-modeltranslation сделано: в ORM мы по-прежнему указываем 1 поле, без всяких префиксов и тд, как будто переводы на другие языки нас не интересуют. В таблице при этом создаются также поля под все необходимые языки, но с таблицей-то мы работаем через ORM, и у нас там по-прежнему 1 поле. При доступе к полю правильный язык выбирается автомагически по языку текущего пользователя. При необходимости можно выбрать данные для нужного языка вручную. Если перевод не заполнен, идет откат на язык по умолчанию.
Если нужно добавить новый язык, то указываем его в настройках (1 строка), запускаем south (инструмент для миграций), он сам определяет, какие колонки нужно добавить/убрать и генерирует миграцию (+1 команда в консоли), смотрим, что там все в порядке, запускаем ее на локальной машине (+1 команда в консоли) и на сервере (еще +1 команда в консоли) — структура таблиц поменялась. Не вижу тут абсолютно ничего корявого, наоборот, очень удобно и минимум действий.
Другое дело, что язык нельзя добавить из интерфейса администратора. Если языков 30, то это может быть не удобно (хотя вполне приемлемо, разве что 30 раз придется «пнуть» программиста, чтобы он дописал строку в настройки и выполнил 3 команды в консоли). И еще это может быть плохо с точки зрения БД (если контент большой — весь в одной таблице).
Но в реальности-то эти 30 языков нигде не требуется. Для разных ситуаций хороши разные решения, это точно. Просто мне кажется, так оказалось, что гораздо более распространена ситуация, когда лучшим является ваше первое решение, а не универсальный огород с таблицами.
Если нужно добавить новый язык, то указываем его в настройках (1 строка), запускаем south (инструмент для миграций), он сам определяет, какие колонки нужно добавить/убрать и генерирует миграцию (+1 команда в консоли), смотрим, что там все в порядке, запускаем ее на локальной машине (+1 команда в консоли) и на сервере (еще +1 команда в консоли) — структура таблиц поменялась. Не вижу тут абсолютно ничего корявого, наоборот, очень удобно и минимум действий.
Другое дело, что язык нельзя добавить из интерфейса администратора. Если языков 30, то это может быть не удобно (хотя вполне приемлемо, разве что 30 раз придется «пнуть» программиста, чтобы он дописал строку в настройки и выполнил 3 команды в консоли). И еще это может быть плохо с точки зрения БД (если контент большой — весь в одной таблице).
Но в реальности-то эти 30 языков нигде не требуется. Для разных ситуаций хороши разные решения, это точно. Просто мне кажется, так оказалось, что гораздо более распространена ситуация, когда лучшим является ваше первое решение, а не универсальный огород с таблицами.
Согласен. В данном случае, когда генератор делает все за тебя любой из описанных методов является рабочим. Но, увы, не всегда верным.
Я же руководствуюсь принципом 7 раз отмерь 1 отрежь. Хочу добиться правильного соотношения понятность/эффективность/универсальность.
И согласно моему выбору, в котором, надеюсь, мне помогут ваши комментарии я разработаю соответствующий генератор для своего фреймворка. И соответственно убрать рутину из разработки, хотя всю рутину не уберешь никогда, наверное :).
Простите за слово «корявость», это было выражением двух последних абзацев в вашем комментарии. :)
Я же руководствуюсь принципом 7 раз отмерь 1 отрежь. Хочу добиться правильного соотношения понятность/эффективность/универсальность.
И согласно моему выбору, в котором, надеюсь, мне помогут ваши комментарии я разработаю соответствующий генератор для своего фреймворка. И соответственно убрать рутину из разработки, хотя всю рутину не уберешь никогда, наверное :).
Простите за слово «корявость», это было выражением двух последних абзацев в вашем комментарии. :)
Самый простой вариант — переходите на Django, и забудете о подобных проблемах. Забудь о «глобальной» универсальности подхода — универсальность нужна только в контексте выбранной платформы для разработки.
«Хочу добиться правильного соотношения понятность/эффективность/универсальность» — тем более Django для вас. Я около года разрабатывал подобные «универсальные» вещи (я о реализациях велосипедов на PHP, да), вместо того чтобы заниматься реально интересными задачами, и сейчас, в принципе жалею о потраченном времени.)
«Хочу добиться правильного соотношения понятность/эффективность/универсальность» — тем более Django для вас. Я около года разрабатывал подобные «универсальные» вещи (я о реализациях велосипедов на PHP, да), вместо того чтобы заниматься реально интересными задачами, и сейчас, в принципе жалею о потраченном времени.)
Согласен, просто индивидуальность поставленных передо мной задач не позволяет мне сделать такой шаг. Тут есть четкая необходимость реализовать это в контексте своего фреймворка и реализовать «сразу», приняв правильное решение.
Я имел опыт работы с Symfony и CodeIgniter. Там тоже решены эти задачи. Но все-же хочется решить их правильно индивидуально, предварительно обсудив с вами.
Я работал с многими программистами, но ни один так четко и не сказал как правильно решить задачу с переводом контента. У всех свое мнение, которое они пытаются навязать. Это не плохо, наверное… Но в итоге, перестаешь понимать, что такое хорошо, а что такое плохо.
Я имел опыт работы с Symfony и CodeIgniter. Там тоже решены эти задачи. Но все-же хочется решить их правильно индивидуально, предварительно обсудив с вами.
Я работал с многими программистами, но ни один так четко и не сказал как правильно решить задачу с переводом контента. У всех свое мнение, которое они пытаются навязать. Это не плохо, наверное… Но в итоге, перестаешь понимать, что такое хорошо, а что такое плохо.
мм… Реализация в Symphony мне когда нравилась больше, и она похожа на ваш вариант.) *если не ошибаюсь*. Хотя для работы я предпочитал CI.
*PM mode on*
Хорошо — это быстро, и в срок, а лучше чуть раньше.
Хорошо — это производительно, легко поддерживаемое и кэшируемое.
Хорошо — это второй вариант, скорее всего.
*PM mode off*
У вас условие — это наличие странного CRUD'а о котором вы говорите. Поэтому четвертый вариант правильней в вашей ситуации — проще интерфейс для переводов. А вообще — что вам мешает перегрузить свой CRUD для конкретного случая кастомным интерфейсом?
*PM mode on*
Хорошо — это быстро, и в срок, а лучше чуть раньше.
Хорошо — это производительно, легко поддерживаемое и кэшируемое.
Хорошо — это второй вариант, скорее всего.
*PM mode off*
У вас условие — это наличие странного CRUD'а о котором вы говорите. Поэтому четвертый вариант правильней в вашей ситуации — проще интерфейс для переводов. А вообще — что вам мешает перегрузить свой CRUD для конкретного случая кастомным интерфейсом?
Вот imho самое достойное мнение в этом топике: habrahabr.ru/blogs/webdev/99480/#comment_3074020
Разные задачи, наилучшие решения — тоже разные. У всех решений тут есть плюсы и минусы, идеального и подходящего для всех случаев решения нет (по крайней мере, мне оно неизвестно).
Разные задачи, наилучшие решения — тоже разные. У всех решений тут есть плюсы и минусы, идеального и подходящего для всех случаев решения нет (по крайней мере, мне оно неизвестно).
И все-таки, есть ли какие-то реальные мысли или скриншоты админок где реализована интернационализация?
UFO just landed and posted this here
При желании за красивым интерфейсом можно скрыть и «плохую» структуру таблицы №1.
В интерфейсе на мой взгляд главное:
1) все языковые версии страниц редактируются отдельно;
2) можно легко добавить новую языковую версию страницы с помощью копирования.
Но есть пример сложнее — к примеру у нас есть таблица с объектами недвижимости.
Каждый объект недвижимости содержит 10 свойств, из которых необходим перевод для различных языковых версий только для 3 свойств (к примеру название, адрес).
В таком случае, удобнее делать правку сразу всех языковых версий объекта на одной странице — с точки зрения интерфейса.
В интерфейсе на мой взгляд главное:
1) все языковые версии страниц редактируются отдельно;
2) можно легко добавить новую языковую версию страницы с помощью копирования.
Но есть пример сложнее — к примеру у нас есть таблица с объектами недвижимости.
Каждый объект недвижимости содержит 10 свойств, из которых необходим перевод для различных языковых версий только для 3 свойств (к примеру название, адрес).
В таком случае, удобнее делать правку сразу всех языковых версий объекта на одной странице — с точки зрения интерфейса.
На своих проектах админку локализаций делал по принципу описанному в этой презентации www.slideshare.net/ingvar/symfony-presentation-i18n-2, там описано именно работа с отдельными сообщениями, на последних слайдах есть скриншот админки, делал локализацию объектов по тому же принципу, все поля подлежащие переводу клал в отдельную таблицу, минус что приходилось join`ить таблицы, но в плане удобства очень приятное решение. Список всех языков выделен в отдельные сущности, т.е. таблицы с переводами имеют внешние ключи. Так же в таблицах с переводами определен язык по умолчанию. Пока проблем в данном механизме не возникало. Если у кого проблемы были буду рад о них узнать.
Сам использую 1-ый вариант. Изначально была разработка по типу общая таблица для переводов где формировался уникальный ид из полей таблица + поле + id
например countries_name_ru, имя извлекалось при помощи join, но когда эта таблица разрослась то давала неимоверные тормоза. На данный момент как говорил используется 1-ый вариант, структура задается в xml файле, т.е. просто указывается таблица и список полей, при добавлении языка или таблицы считывается настройки и формируются новые столбцы. Выборка производится IF(name_ru!='', name_ru, name) AS name. Проблем с добавлением той или иной версии языка нет, так как были разработаны все нужные инструменты. Также не приходилось делать сайты с огромным кол-вом языков (максимум 3). Также отмечу что все что касается статей, новостей или страниц контента имеет привязку к конкретному языку сайта и в переводе не нуждаются (тут уж все зависит от конкретной реализации). Как правило в переводимости нуждаются к примеру товары (заголовок, описание и т.д.). Это частный случай, и тут я использую нечто похожее на 4-ю схему.
Наблюдение из практики — часто сам набор страниц для разных языков бывает разный
UFO just landed and posted this here
UFO just landed and posted this here
Спасибо. Вот пользователь, немного позже описал ваш метод habrahabr.ru/blogs/webdev/99480/#comment_3073862
В Symfony встроен ваш 4 вариант. Весьма себе удобно работает:)
на довольно нагруженном сайте (~20K хитов в день) используем четвертый вариант, слегка усложненный:
оригинальная таблица article сделана для английского языка, содержит все поля:
id
title
description
short_description
к ней джойнится таблица переводов article_langspec:
language_id
article_id
title
description
short_description
если язык английский (а основная нагрузка как раз на этот раздел) вторая таблица не джойнится, все работает максимально быстро.
Если язык русский происходит джоин, к сожалению лефт — на случай если перевода страницы нет надо вытащить оригинальный контент, что делается простым ифом мускуля.
Сейчас весь интерфейс работы с таблицами обернули в единый класс, который сам в зависимости от локали подключает нужные таблицы и строит выборки. Результаты жестко кешируем.
Итого: в плюсах имеем ускорение в получении оригинального контента.
В минусах чуть более сложную структуру.
Было желание перенести английскую версию тоже в ледспек (как в вашем 4м примере). Подозреваю это дало бы ускорение за счет того что результаты выборки стали бы помещаться в кеш мускуля.
Еще хотелось поиграться с ленивой загрузкой переводов — грузить только по мере использования и жестко кешировать.
Сейчас на сайте 8, кажется, языков. Система работает.
оригинальная таблица article сделана для английского языка, содержит все поля:
id
title
description
short_description
к ней джойнится таблица переводов article_langspec:
language_id
article_id
title
description
short_description
если язык английский (а основная нагрузка как раз на этот раздел) вторая таблица не джойнится, все работает максимально быстро.
Если язык русский происходит джоин, к сожалению лефт — на случай если перевода страницы нет надо вытащить оригинальный контент, что делается простым ифом мускуля.
Сейчас весь интерфейс работы с таблицами обернули в единый класс, который сам в зависимости от локали подключает нужные таблицы и строит выборки. Результаты жестко кешируем.
Итого: в плюсах имеем ускорение в получении оригинального контента.
В минусах чуть более сложную структуру.
Было желание перенести английскую версию тоже в ледспек (как в вашем 4м примере). Подозреваю это дало бы ускорение за счет того что результаты выборки стали бы помещаться в кеш мускуля.
Еще хотелось поиграться с ленивой загрузкой переводов — грузить только по мере использования и жестко кешировать.
Сейчас на сайте 8, кажется, языков. Система работает.
Вот как раз с кешированием, я думаю над пятым вариантом, т.е. дублируется структура основной таблицы и еще одно поле, идентификатор языка, как во втором варианте. Т.е. получаем комбинированную структуру и широкие возможности администрирования.
В итоге все работает без джоинов, а простой выборкой. Спасибо за живой пример.
к сожалению в основной таблице не только id уникален. У нас там хранятся такие вещи как code для найс урлов (одинаков для всех), картинки к статьям, иконки, файлы и т.д. и т.п.
Кроме того, из-за пожелания заказчика «показывать переведенные выше чем все остальное» пришлось реализовать кеширование флага о наличии перевода в SET поле основной таблицы. Без этого сайт напрочь ложился.
Если это все дублировать по разным таблицам получится очень тяжело. К тому же любой программист будет тыкать в вашу структуру БД и громко смеяться о ее нормализации.
Кроме того, из-за пожелания заказчика «показывать переведенные выше чем все остальное» пришлось реализовать кеширование флага о наличии перевода в SET поле основной таблицы. Без этого сайт напрочь ложился.
Если это все дублировать по разным таблицам получится очень тяжело. К тому же любой программист будет тыкать в вашу структуру БД и громко смеяться о ее нормализации.
Я бы сделал на каждый перевод свою базу данных…
Поля не нуждающиеся в переводе просто дублируются.
Места тратится больше, зато все остальное проще (вывод очень простой получается по-моему)
Поля не нуждающиеся в переводе просто дублируются.
Места тратится больше, зато все остальное проще (вывод очень простой получается по-моему)
А готовое решение MODx + YAMS не смотрели?
Вот уже 2 года в нескольких проектах использовал 3-й вариант, в узких местах кешировал мемкешем, ни разу не пожалел, сбоев не было.
Так как языки с разным направлением письма (ltr/rtl), переводы делать на одной и той же страницы было не удобно, сделал переключение всего интерфейса админки. Не переведенный контент для удобства в админке отображается на дефолтном языке, контент которого вносится первым.
yfrog.com/n8i18np
На самом сайте если для статьи (к примеру) нет перевода, то она легко отфильтровывается и не отображается.
Так как языки с разным направлением письма (ltr/rtl), переводы делать на одной и той же страницы было не удобно, сделал переключение всего интерфейса админки. Не переведенный контент для удобства в админке отображается на дефолтном языке, контент которого вносится первым.
yfrog.com/n8i18np
На самом сайте если для статьи (к примеру) нет перевода, то она легко отфильтровывается и не отображается.
Спасибо, а можно по-подробней об узких местах?
Единственным узким местом был джоин двух таблиц (возможно с условием) при выводе списка позиций (например статей).
Сорри! Только что обратил внимание, что не верно указал номер варианта — 3. Мой вариант 4.
У меня так
articles
— id (PK)
— alias
— created
— is_show
articles_i18n
— id (PK) — равен articles.id
— lang_id (PK)
— title
— description
Есть еще отдельная таблица лога, где указано кто и что редактировал и прочие действия юзеров в админке.
Работа с такими таблицами реализована в одной модели (делал на Codeigniter). Такой механизм легко работает и с иерархическими структурами, такими как категории с Nested Sets.
Сорри! Только что обратил внимание, что не верно указал номер варианта — 3. Мой вариант 4.
У меня так
articles
— id (PK)
— alias
— created
— is_show
articles_i18n
— id (PK) — равен articles.id
— lang_id (PK)
— title
— description
Есть еще отдельная таблица лога, где указано кто и что редактировал и прочие действия юзеров в админке.
Работа с такими таблицами реализована в одной модели (делал на Codeigniter). Такой механизм легко работает и с иерархическими структурами, такими как категории с Nested Sets.
Попробуйте интернационализацию CodeIgniter — там в url добавляется язык, который через CI файл routes.php скрывается (ru|en). Мы так делали один сайт — пользователь нажимает на иконку языка — и вуаля — в урл добавляется язык, который после еще одного перехода скрывается. Можно оставлять.
Универсального решения я думаю нет. Все зависит от задачи. Когда клиент хочет интернационализацию на сайте, я всегда спрашиваю, что вам конкретно нужно товарищ? Сколько языков требуется?
— каждая страница сайта с оригинальным контентом имеет страницу-перевод. Фиксированное количество языков. При этом лучше чем вариант №1 ничего нет. Минимум запросов к БД, простое редактирование. Все модели данных имеющие контентные поля, имеют их дубликаты. Соответственно правка объектов такой модели состоит в написании оригинала и перевода/ов друг под другом.
— локализации сайта имеют разное количество страниц/асинхронное наполнение контентом языковых версий сайта. Лучше чем дубликат всего сайта с управлением из одной админки, да еще с многопользовательским доступом к разноязыковым моделям иногда сложно что-то придумать, каждая версия развивается как ей угодно. В данной статье это варианты №2,3 (но применительно ко всем контентным моделям сайта)
— если количество языков еще не определено, тогда, из моделей данных все контентные поля выносятся в отдельные модели имеющие метки языка. В данной статье это вариант №4,5. К примеру — новости: id,name,date,source — поля остаются в модели news, а контент набивается в объекты модели news_i18n связанную как hasMany в news, тоже самое с другими контентными моделями.
— каждая страница сайта с оригинальным контентом имеет страницу-перевод. Фиксированное количество языков. При этом лучше чем вариант №1 ничего нет. Минимум запросов к БД, простое редактирование. Все модели данных имеющие контентные поля, имеют их дубликаты. Соответственно правка объектов такой модели состоит в написании оригинала и перевода/ов друг под другом.
— локализации сайта имеют разное количество страниц/асинхронное наполнение контентом языковых версий сайта. Лучше чем дубликат всего сайта с управлением из одной админки, да еще с многопользовательским доступом к разноязыковым моделям иногда сложно что-то придумать, каждая версия развивается как ей угодно. В данной статье это варианты №2,3 (но применительно ко всем контентным моделям сайта)
— если количество языков еще не определено, тогда, из моделей данных все контентные поля выносятся в отдельные модели имеющие метки языка. В данной статье это вариант №4,5. К примеру — новости: id,name,date,source — поля остаются в модели news, а контент набивается в объекты модели news_i18n связанную как hasMany в news, тоже самое с другими контентными моделями.
Объективно, спасибо.
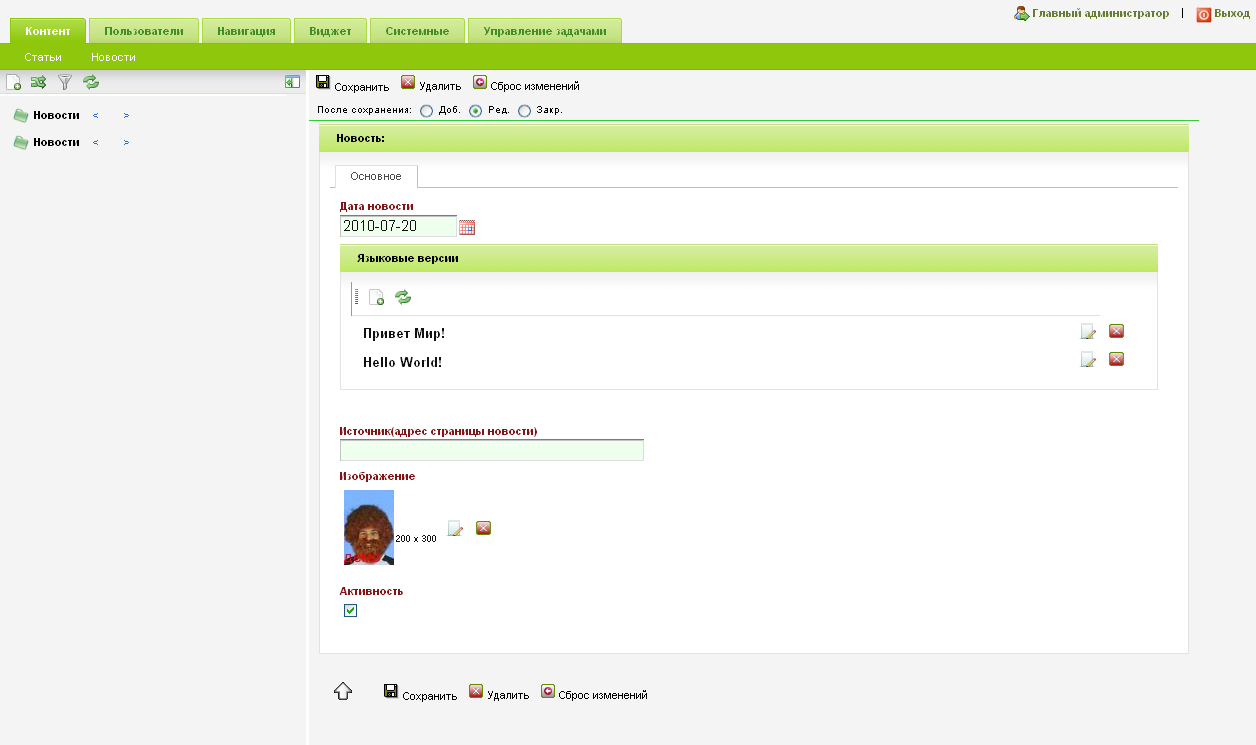
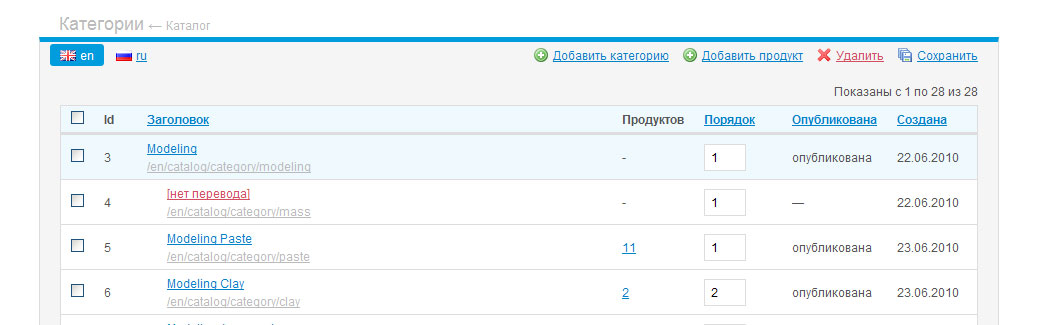
Еще просили скрины. За полчаса сделал решение к каждому из трех вариантов на базе моего фреймворка:
habreffect.ru/files/263/ea7b01c67/first.png
habreffect.ru/files/43b/2de358f7b/second.png
habreffect.ru/files/60b/bca785a20/third.png
habreffect.ru/files/263/ea7b01c67/first.png
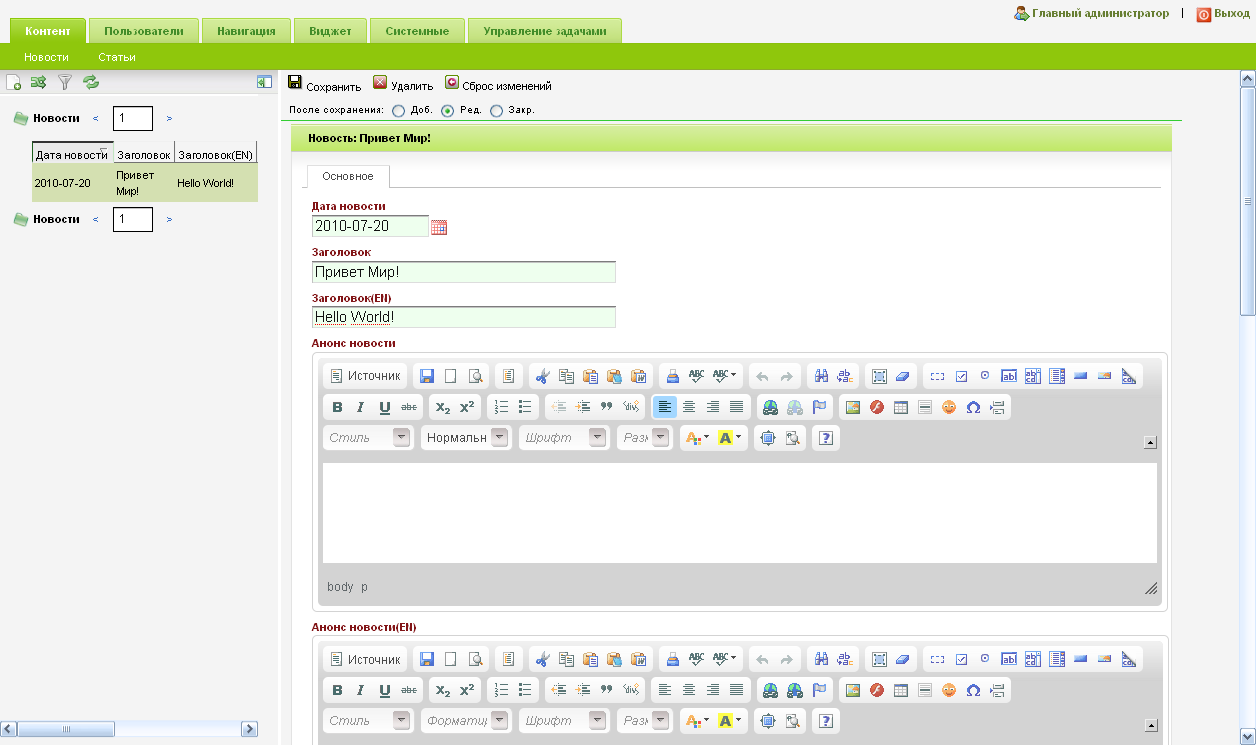{kind=link}
habreffect.ru/files/43b/2de358f7b/second.png
{kind=link}
habreffect.ru/files/60b/bca785a20/third.png
{kind=link}
Как-то Ваш фреймворк очень похож на MODx. Можете подробнее рассказать, что Вы такое с ним сделали, чтобы превратить в то, что получилось на скриншотах? И насколько это стало удобнее, чем исходный фреймворк?
Да, каюсь. Я позаимствовал стилевое оформление и иконки, а вся начинка моя. Т.к. не далеко не дизайнер, то просто портировал десяток тем от modx. Сам modx не используется вообще. Фреймворк больше всего похож на cakephp(model(своя ORM), практически такие же layout, view, добавлены несколько типов связей, реализация контроллеров совершенно другая) и codeigniter(но без хуков), сделан свой скаффолдинг(виден на скринах), прегенерация таблиц и связей в develop mode на основе описания моделей. В принципе все идеи лежат на поверхности, просто все сделано для себя с целью максимально увеличить скорость разработки.
Спасибо, так уже интересней.
У нас 3 таблицы:
Таблица с языками используется для вывода «флажков» — переключателей языка.
В админке просто для каждой страницы сделаны как вкладки — на первой вкладке редактируем общие поля (url, родителя и т.д.) и для каждого языка по вкладке.
Достаточно удобно.
id страницы все поля которые не нуждаются в переводе (url, parent и т.д.)
id языа двубуквенный индекс языка
id страницы id языка поля, которые нуждаются в переводе
Таблица с языками используется для вывода «флажков» — переключателей языка.
В админке просто для каждой страницы сделаны как вкладки — на первой вкладке редактируем общие поля (url, родителя и т.д.) и для каждого языка по вкладке.
Достаточно удобно.
Есть распаралелливание (несколько непохожих структурой ресурсов, каждый под свой язык), клонирование (механизм описанный выше, фиксированная структура сайта, можно переключаться с одного языка на другой на любой статье) и «языковые версии». Последний гибче и работают так:
— есть «сущность» или статья
— есть языковые версии этой сущности
Сущность — единая в системе и не несет в себе текста и прочих аттрибутов, кроме «привязки» к конкретному разделу (разделам) сайта.
«Языковая версия» — полностью локализировання статья (включая имя автора, метаданные и т.д.) на определенном языке, привязанная к сущности. Языковых версий может быть сколько угодно у каждой сущности.
В базе это хранится как:
— Табл. 1 — сущности
— Табл. 2 — языковые версии (одно из полей language — язык) связанные с Табл. 1
Выборка идет по таблице сущностей и по language (Табл. 2)
Например, сущность a [languages: en, fr, de], b [languages: en, fr].
Посетитель заходит на сайт в некий раздел и получает список материалов на английском (скажем, это язык по умолчанию) — a и b, связанных с этим разделом. Язык предположим берется из первого сегмента URL.
Посетитель открывает страницу с материалом «a», CMS просматривает языковые версии материала и предлагает ему выбор языка [fr, de]. Человек может перейти на ту языковую версию, которая ему удобна (1).
Если он переходит на de и возвращается в раздел, CMS делает выборку материалов, как «статьи подвязанные к этому разделу с языковой локалью de» и покажет ему только материал «а», спрятав «b», не поддерживает этот язык (2).
— есть «сущность» или статья
— есть языковые версии этой сущности
Сущность — единая в системе и не несет в себе текста и прочих аттрибутов, кроме «привязки» к конкретному разделу (разделам) сайта.
«Языковая версия» — полностью локализировання статья (включая имя автора, метаданные и т.д.) на определенном языке, привязанная к сущности. Языковых версий может быть сколько угодно у каждой сущности.
В базе это хранится как:
— Табл. 1 — сущности
— Табл. 2 — языковые версии (одно из полей language — язык) связанные с Табл. 1
Выборка идет по таблице сущностей и по language (Табл. 2)
Например, сущность a [languages: en, fr, de], b [languages: en, fr].
Посетитель заходит на сайт в некий раздел и получает список материалов на английском (скажем, это язык по умолчанию) — a и b, связанных с этим разделом. Язык предположим берется из первого сегмента URL.
Посетитель открывает страницу с материалом «a», CMS просматривает языковые версии материала и предлагает ему выбор языка [fr, de]. Человек может перейти на ту языковую версию, которая ему удобна (1).
Если он переходит на de и возвращается в раздел, CMS делает выборку материалов, как «статьи подвязанные к этому разделу с языковой локалью de» и покажет ему только материал «а», спрятав «b», не поддерживает этот язык (2).
Я так понимаю что таблица сущностей такая же как в 3-м варианте?
А не лучше ли сделать все в одном поле?
[lang=ru]Привет, Мир![/lang]
[lang=en]Hello, World![/lang]
Помоему с этим вариантом все становится легко и просто, как считаете?
[lang=ru]Привет, Мир![/lang]
[lang=en]Hello, World![/lang]
Помоему с этим вариантом все становится легко и просто, как считаете?
Нарушается принцип атомарности. В результате: как составить запрос на выборку, например, 10 последних статей, в которых есть английский язык?
WHERE article.text like '%[lang=en]%'
Т.е. Вы имеете в виду почти такой же вариант как habrahabr.ru/blogs/webdev/99480/?reply_to=3073862#comment_3074312
Это ужасно.
Ваш пример касается перевода интерфейса, а не перевода контента.
Вот, что я на этот счет думал. Поля для примера, естественно. id — идентификатор primary key, publish — опубликован объект или нет, order — сортировка.
table_object
id, publish, order
object_id — id объекта, system — тип поля (чтобы отличить заголовок от текста), data — собственно само наполнение поля, lang — язык.
table_data
object_id, system, data, lang
Ну, и как пример:
table_object:
1, 1, 1
table_data
1, «title», «Приветствую вас на моей страничке!», «ru»;
1, «title», «Welcome!», «en»;
2, «introtext», «Как же я рад вас видеть!», «ru»;
2, «introtext», «I hate you all!», «en»;
И так далее…
table_object
id, publish, order
object_id — id объекта, system — тип поля (чтобы отличить заголовок от текста), data — собственно само наполнение поля, lang — язык.
table_data
object_id, system, data, lang
Ну, и как пример:
table_object:
1, 1, 1
table_data
1, «title», «Приветствую вас на моей страничке!», «ru»;
1, «title», «Welcome!», «en»;
2, «introtext», «Как же я рад вас видеть!», «ru»;
2, «introtext», «I hate you all!», «en»;
И так далее…
Чтобы получить контроль версий перевода, можно добавить поле «time» в таблицу «table_data», содержащее timestamp добавления перевода.
Собственно, мне пока не удалось найти явные недостатки такого подхода. Но версионность я сейчас на ходу придумал, она в 99% случаев не нужна, хотя всякое может быть.
Собственно, мне пока не удалось найти явные недостатки такого подхода. Но версионность я сейчас на ходу придумал, она в 99% случаев не нужна, хотя всякое может быть.
А с контролем версий лучше использовать 5 вариант. Он масштабируемый.
Может я чего-то не понимаю, но версия — это состояние на конкретный момент времени. С полем timestamp мы это и получаем. Т.е. не вижу смысла усложнять.
да, но если делать контроль версий, то зачем лишними версиями захламлять таблицу, нужно делать, своего рода «ветку» — таблицу последних версий.
А как они могут быть «лишними»? Кроме того, при наличии индексов (а они есть), запрос будет обрабатываться за сотые доли секунды, даже если там миллиард записей. В таблице базы данных хлама быть не может :)
Бесспорно, но посмотрите на 5-й вариант.
Выходит, что у нас есть таблица версий и таблица конечных, опубликованных версий, из которых мы выбираем по конкретным ключам, ид страницы, и ид языка.
А в случае с одной таблицей, нам нужно кроме этих двух ключей сделать еще и выборку по дате, что на практике может уменьшить производительность.
Выходит, что у нас есть таблица версий и таблица конечных, опубликованных версий, из которых мы выбираем по конкретным ключам, ид страницы, и ид языка.
А в случае с одной таблицей, нам нужно кроме этих двух ключей сделать еще и выборку по дате, что на практике может уменьшить производительность.
выборка по дате может уменьшить производительность
Дата, в нашем случае, — обычное число, а не порнография вида «dd-mm-yyyy». Сервер баз данных прекрасно обработает этот запрос с разницей, разве что, в одну миллионную секунды (хотя, я уверен, разницы не будет вообще).
На счет публикации версионности:
Если нужна возможность публикации версий, то просто добавляем поле «publish» типа «double» и в запросе используем «WHERE `lang`= 'en' AND `publish` = '1' ORDER BY `timestamp` DESC LIMIT 1». Таким образом получаем последнюю опубликованную версию контента для заданного языка.
Дата, в нашем случае, — обычное число, а не порнография вида «dd-mm-yyyy». Сервер баз данных прекрасно обработает этот запрос с разницей, разве что, в одну миллионную секунды (хотя, я уверен, разницы не будет вообще).
На счет публикации версионности:
Если нужна возможность публикации версий, то просто добавляем поле «publish» типа «double» и в запросе используем «WHERE `lang`= 'en' AND `publish` = '1' ORDER BY `timestamp` DESC LIMIT 1». Таким образом получаем последнюю опубликованную версию контента для заданного языка.
Согласен. Имеет право на жизнь.
В теории все, скорее всего, именно так. А вот на практике — зачастую денормализуют схему БД для улучшения производительности.
С точки зрения производительности _имеет смысл_ вынести версии даже и в отдельную таблицу с той же структурой, ибо к ним будут применяться разные условия. К таблице версий будут обращаться намного реже, что накладывает свои условия на формирование индексов, на кэширование результатов и на время жизни кэша.
Более того, в таблице версий будет и последняя созданная запись. А в «текущей» таблице (назовем ее «быстрая таблица») будет та запись, которая на данный момент опубликована (даже если она — не последняя созданная). Именно данные из быстрой таблицы будут выбираться чаще всего, и постоянно кэшироваться, поэтому этот подход очень даже имеет право на жизнь.
С точки зрения производительности _имеет смысл_ вынести версии даже и в отдельную таблицу с той же структурой, ибо к ним будут применяться разные условия. К таблице версий будут обращаться намного реже, что накладывает свои условия на формирование индексов, на кэширование результатов и на время жизни кэша.
Более того, в таблице версий будет и последняя созданная запись. А в «текущей» таблице (назовем ее «быстрая таблица») будет та запись, которая на данный момент опубликована (даже если она — не последняя созданная). Именно данные из быстрой таблицы будут выбираться чаще всего, и постоянно кэшироваться, поэтому этот подход очень даже имеет право на жизнь.
Вы сейчас описали идею номер 4. Но спасибо, за более детализированное объяснение.
Для мультиязычных страниц использую ваиант 4.
Вполне вменяемо
Вполне вменяемо
Я хранил содержимое полей в БД в формате XML. То есть, запрашивая, скажем, название чего-либо из БД получал ответ в виде XML-документа, элементы которого содержали аттрибут с кодом языка по ISO и переводом в теле. XPath помогал быстро добраться до нужного языка, а кэшированный результат запроса позволял быстро получать перевод на другой язык.
Из плюсов — легкость добавления новой локали, причем абсолютно любой без изменения структуры БД, моделей и прочего. Также легко наращивать функционал системы: хотит добавить ID переводчика, местные наречия, склонения — чуть изменить XML Schema и добавить новый аттрибут.
Из минусов — этот способ годится лишь для небольших текстов, большой объем данных существенно снизит скорость обработки. Объем данных, скорость выборки в этом случае также отходят на второй план.
Из плюсов — легкость добавления новой локали, причем абсолютно любой без изменения структуры БД, моделей и прочего. Также легко наращивать функционал системы: хотит добавить ID переводчика, местные наречия, склонения — чуть изменить XML Schema и добавить новый аттрибут.
Из минусов — этот способ годится лишь для небольших текстов, большой объем данных существенно снизит скорость обработки. Объем данных, скорость выборки в этом случае также отходят на второй план.
Вот и еще одинн вариант нарисовался. Он имеет право на жизнь. Но как вы сказали этот способ для небольших текстов.
По сути, я так понял, что вы в одно поле таблицы записываете все переводы по данному тексту, и компонуете их с помощью xml. Если бы я так делал, то делал используя сериализацию массива.
По сути, я так понял, что вы в одно поле таблицы записываете все переводы по данному тексту, и компонуете их с помощью xml. Если бы я так делал, то делал используя сериализацию массива.
первый вариант работает быстрее всех и он проще всех => я за первый вариант
Вы представляете себе таблицу, в которой по 7-8 полей на каждый язык и штук 6 языков?
56 нужных столбцов… :)
Максимальное число колонок в MySQL таблице, кажется, 2599. Так в чём проблема? Если 6 языков, то у вас будет возожность сделать для этой сущности 433 атрибута на всех языках…
Ну, и разумеется, делать SELECT * из таблицы не надо. Впрочем, * и так использовать не надо — зачем дёргать лишнее…
В принципе, ещё один вариант проще в некотором смысле, но помедленнее — хранить как обычно, упаковывать данные в xml. То есть в каждом поле таблицы, нуждающемся в переводе, храним xml, содержащий различные варианты перевода этого поля. Получаем поле как обычно, потом парсим. Если языков на сайте много, а хранимой в каждом поле информации много, то такой вариант, конечно, не очень эффективный… Однако если надо добавить поддержку многоязычности в существующую систему — это будет сделать довольно просто, ведь не придётся менять структуру базы.
Ну, и разумеется, делать SELECT * из таблицы не надо. Впрочем, * и так использовать не надо — зачем дёргать лишнее…
В принципе, ещё один вариант проще в некотором смысле, но помедленнее — хранить как обычно, упаковывать данные в xml. То есть в каждом поле таблицы, нуждающемся в переводе, храним xml, содержащий различные варианты перевода этого поля. Получаем поле как обычно, потом парсим. Если языков на сайте много, а хранимой в каждом поле информации много, то такой вариант, конечно, не очень эффективный… Однако если надо добавить поддержку многоязычности в существующую систему — это будет сделать довольно просто, ведь не придётся менять структуру базы.
Я так понимаю, основные концепции баз данных вы не изучали?
Имел дело только в первой реализацией.
На 4 языка мне этого варианта хватило, ну и с четом того, что все это работало на MODx CMS, других вариантов особо и не было. Все поля редактируются на одной странице.
Выглядит это примерно так:

На 4 языка мне этого варианта хватило, ну и с четом того, что все это работало на MODx CMS, других вариантов особо и не было. Все поля редактируются на одной странице.
Выглядит это примерно так:

У меня это выглядит примерно так. На каждой странице есть такие флажки, а так как у меня 4й вариант переключиться на соседний язык очень просто.

Основной минус 4го варианта в том, что необходимо назначить язык по умолчанию, в котором должны быть все страницы и в случае отсутствия перевода откатывать на него. Я же попытался сделать более универсально и в результате намаялся с проверками «а есть ли перевод».
Так что теперь я склоняюсь все-таки к 3-ему варианту.
+ полная свобода, что хочешь, то и переводи на любые языки
+ скорость работы
+ простота (KISS!)
Одинаковые поля при редактировании придется дублировать ручками. тут можно придумать что-нибудь с копированием.
Для перевода таких вещей как статьи, новости и т.п. подходит хорошо, а вот для каталогов, каких-нибудь списков характеристик продуктов может и не подойти.
В общем одним решением не накрыть все возможные варианты.
Основной минус 4го варианта в том, что необходимо назначить язык по умолчанию, в котором должны быть все страницы и в случае отсутствия перевода откатывать на него. Я же попытался сделать более универсально и в результате намаялся с проверками «а есть ли перевод».
Так что теперь я склоняюсь все-таки к 3-ему варианту.
+ полная свобода, что хочешь, то и переводи на любые языки
+ скорость работы
+ простота (KISS!)
Одинаковые поля при редактировании придется дублировать ручками. тут можно придумать что-нибудь с копированием.
Для перевода таких вещей как статьи, новости и т.п. подходит хорошо, а вот для каталогов, каких-нибудь списков характеристик продуктов может и не подойти.
В общем одним решением не накрыть все возможные варианты.
хм, а мне нравится комбинированный подход в симфонии:
www.symfony-project.org/jobeet/1_4/Doctrine/ru/19
там есть специальный оператор $__ для шаблонов, который позволяет получать подстановку значений из xml, а так же мультиязычные поля в таблице реализованы связью id ->таблица значений для поля(значение, язык). Кеширование тоже прикручивается на ура.
www.symfony-project.org/jobeet/1_4/Doctrine/ru/19
там есть специальный оператор $__ для шаблонов, который позволяет получать подстановку значений из xml, а так же мультиязычные поля в таблице реализованы связью id ->таблица значений для поля(значение, язык). Кеширование тоже прикручивается на ура.
Я конечно понимаю, что в этом посте рассматривается back-end реализация универсального механизма перевода контента сайта, но вот есть ленивое решение на js — translateth.is
UFO just landed and posted this here
В моем самопальном CMF (кстати, очень похожем на описанный в статье) я сделал сначала вариант без мультиязычности, затем переписал на мультиязыковой (2 таблицы по версии 4).
Потом понял, что универсальность — не всегда удобно, а мультиязычность в таком виде требуется очень редко. Поэтому временно отвлекся от CMF/CMS и занялся более решением более практичных задач.
Потом понял, что универсальность — не всегда удобно, а мультиязычность в таком виде требуется очень редко. Поэтому временно отвлекся от CMF/CMS и занялся более решением более практичных задач.
По-хорошему, фреймфорк должен позволить быстро сделать любую модель мультиязычной без изменения ее API. А в «базовой» поставке модели должны быть не мультиязычны — именно потому, что чаще мультиязычность не нужна.
Ну у меня на данном этапе базовая поставка так и организована без мультиязычности. Сейчас я хочу, чтоб когда я описываю параметры поля модели что-то вроде «i18n=true» у меня автоматически генерировался CRUD и структура базы для данной таблицы.
myModel:
ActAs:
I18N:
fields: [title, description]
:) Попробуйте symfony. У меня есть подозрение, что вы хотите написать тоже самое:)
Структура таблиц у меня и генерируется автоматически.
Проставил при создании класса объектов галочку «нужна мультиязычность», отобрал нужные поля (они описаны в отдельной таблице) для основной таблицы и для языковой — обе таблицы созданы.
Что касается базовой поставки — то интерфейс лучше сразу делать на нескольких языках. Ну и из моделей какую-нибудь сделать мультиязычной, для примера использования.
Проставил при создании класса объектов галочку «нужна мультиязычность», отобрал нужные поля (они описаны в отдельной таблице) для основной таблицы и для языковой — обе таблицы созданы.
Что касается базовой поставки — то интерфейс лучше сразу делать на нескольких языках. Ну и из моделей какую-нибудь сделать мультиязычной, для примера использования.
У себя в движке я тоже столкнулся в проблемой переводов. Реализовал ее так.
Можно использовать любое количество языков сколько только захочется. В момент запроса Get(), GetList(), GetRows() все прозрачно само вынимается из базы, если же например страница на французском, но перевода нет — вставляется что будет первым.
У меня таких типов языка 2, строчный и Визивиг редактор.
Можно использовать любое количество языков сколько только захочется. В момент запроса Get(), GetList(), GetRows() все прозрачно само вынимается из базы, если же например страница на французском, но перевода нет — вставляется что будет первым.
У меня таких типов языка 2, строчный и Визивиг редактор.
Что-то картинка не вставилась, извините: fotky.com.ua/pfiles/23900.jpg
{kind=link}
Итак, сразу отметим, что 5-й вариант — это «навороченный» 4-й.
Если хотите универсальности (2 -> 20 -> 50 -> N языков), то 4-й — ваша отправная точка.
Кроме прочего, нужно обратить внимание на несколько общих моментов, связанных с многоязычностью (если еще не столкнулись — то столкнетесь):
— Действительно ли нужен «оригинальный язык»? Это очень сильно зависит от того, что за сервис работает на движке. Если это вики или сервис коллективных переводов, то это одно, а если просто наборы страничек (тем более зачастую не связанных) — совсем другое. В последнем случае, это могут быть разные/частично пересекающиеся сайты в зависимости от языковой версии (американцы видят одно, украинцы — другое). Здесь также важны конкретные сценарии работы с проектом — к примеру, если это интернет-магазин, то показывать все товары всем или это не так важно? Личное мнение — видеть контент на чужом языке (кроме, может быть, английского) носителям другого языка в большинстве случаев не имеет смысла.
— Существуют точки связи переведенного контента и ресурсов (встроенных текстов и картинок). Здесь в самой архитектуре фреймворка хорошо бы предусмотреть «форматтеры», позволяющие отдельные элементы контента и ресурсов представлять в разном виде на разных языках. Например, дата в разных странах отмечается по-разному, или в некоторой фразе могут быть переставлены местами слова, или просто иметь разную форму («1 Page, 2 Pages, ..., N Pages» и «1 Страница, 2 Страницы, ..., 5 Страниц»), и так далее. Немаловажно, что форматирование может требоваться элементам, которые не являются переводимыми (Дата).
— Нужно учитывать отличия элементов пунктуации и орфографии. (Для всего этого можно хранить в некотором смысле «профайлы» языков).
— Если проекту требуется большое количество языков, при такой универсальности это неизбежно (и очень сильно) сказывается на производительности, так что минимизируйте обращения к БД. Тема многоязычности (а особенно — много-много-многоязычности) неразрывно связана с memcached (всего и вся, на всех уровнях).
— Существует ряд сценариев, когда не нужна одновременная поддержка многих языков в рамках одного приложения, а нужна только возможность выбрать язык на этапе развертывания. Это отдельная большая тема, как это можно сделать (например, реальный сценарий таков, что в разных странах в интернет-магазине продаются товары, некоторые из них доступны везде, а многие — уникальны для отдельной страны. Возможно технически хранить данные о товарах магазинов на разных языках вообще в разных базах данных, даже распределенных географически, но в рамках одной компании, и иметь определенный механизм ассоциаций, специальную БД сверки, либо вообще поддерживать независимо, либо как то еще — миллион вариантов).
— В качестве резюме предыдущего пункта, хочу отметить крайне важное — стопроцентно универсального решения на все случаи жизни, скорее всего нет, у всего есть свои недостатки. Так что, исходите из задачи, не пытайтесь совсем все заранее продумать, пробуйте, экспериментируйте и оценивайте недостатки с практической точки зрения. There is no Silver Bullet!
Если хотите универсальности (2 -> 20 -> 50 -> N языков), то 4-й — ваша отправная точка.
Кроме прочего, нужно обратить внимание на несколько общих моментов, связанных с многоязычностью (если еще не столкнулись — то столкнетесь):
— Действительно ли нужен «оригинальный язык»? Это очень сильно зависит от того, что за сервис работает на движке. Если это вики или сервис коллективных переводов, то это одно, а если просто наборы страничек (тем более зачастую не связанных) — совсем другое. В последнем случае, это могут быть разные/частично пересекающиеся сайты в зависимости от языковой версии (американцы видят одно, украинцы — другое). Здесь также важны конкретные сценарии работы с проектом — к примеру, если это интернет-магазин, то показывать все товары всем или это не так важно? Личное мнение — видеть контент на чужом языке (кроме, может быть, английского) носителям другого языка в большинстве случаев не имеет смысла.
— Существуют точки связи переведенного контента и ресурсов (встроенных текстов и картинок). Здесь в самой архитектуре фреймворка хорошо бы предусмотреть «форматтеры», позволяющие отдельные элементы контента и ресурсов представлять в разном виде на разных языках. Например, дата в разных странах отмечается по-разному, или в некоторой фразе могут быть переставлены местами слова, или просто иметь разную форму («1 Page, 2 Pages, ..., N Pages» и «1 Страница, 2 Страницы, ..., 5 Страниц»), и так далее. Немаловажно, что форматирование может требоваться элементам, которые не являются переводимыми (Дата).
— Нужно учитывать отличия элементов пунктуации и орфографии. (Для всего этого можно хранить в некотором смысле «профайлы» языков).
— Если проекту требуется большое количество языков, при такой универсальности это неизбежно (и очень сильно) сказывается на производительности, так что минимизируйте обращения к БД. Тема многоязычности (а особенно — много-много-многоязычности) неразрывно связана с memcached (всего и вся, на всех уровнях).
— Существует ряд сценариев, когда не нужна одновременная поддержка многих языков в рамках одного приложения, а нужна только возможность выбрать язык на этапе развертывания. Это отдельная большая тема, как это можно сделать (например, реальный сценарий таков, что в разных странах в интернет-магазине продаются товары, некоторые из них доступны везде, а многие — уникальны для отдельной страны. Возможно технически хранить данные о товарах магазинов на разных языках вообще в разных базах данных, даже распределенных географически, но в рамках одной компании, и иметь определенный механизм ассоциаций, специальную БД сверки, либо вообще поддерживать независимо, либо как то еще — миллион вариантов).
— В качестве резюме предыдущего пункта, хочу отметить крайне важное — стопроцентно универсального решения на все случаи жизни, скорее всего нет, у всего есть свои недостатки. Так что, исходите из задачи, не пытайтесь совсем все заранее продумать, пробуйте, экспериментируйте и оценивайте недостатки с практической точки зрения. There is no Silver Bullet!
Отдельная добавка про «форматтеры» даты.
Не вздумайте использовать средства форматирования СУБД на основании языка, присущего записи.
Должен выбираться максимально простой, по возможности однородный и однообразный Result-Set, и кэшироваться, после чего обрабатываться и кэшироваться в отформатированном виде/в виде готовой страницы/готовой части страницы.
Не вздумайте использовать средства форматирования СУБД на основании языка, присущего записи.
Должен выбираться максимально простой, по возможности однородный и однообразный Result-Set, и кэшироваться, после чего обрабатываться и кэшироваться в отформатированном виде/в виде готовой страницы/готовой части страницы.
Делали CRM, у заказчика — рекламного агенства — там хранились описания площадок.
Базовая табличка — русская.
table_name (id, title, descr, ...)
Все остальные идут как table_name_en, table_name_de и т.п.
Главная штука — следить, чтобы id совпадали у карточки площадки и ее же карточек на других языках.
Количество языков всегда конечно, хранить в таблице, которая и так для одного языка одна, еще и id языка — не нужно.
В этом случае, кстати, оптимальным по быстродействию вариантом будет вывести массив языков в настройки — а не читать из базы.
Базовая табличка — русская.
table_name (id, title, descr, ...)
Все остальные идут как table_name_en, table_name_de и т.п.
Главная штука — следить, чтобы id совпадали у карточки площадки и ее же карточек на других языках.
Количество языков всегда конечно, хранить в таблице, которая и так для одного языка одна, еще и id языка — не нужно.
В этом случае, кстати, оптимальным по быстродействию вариантом будет вывести массив языков в настройки — а не читать из базы.
Sign up to leave a comment.
Реализация и универсализация i18n в CMS/CMF