Comments 36
UFO just landed and posted this here
Под рукой нет таких процессоров, но могу послать на e-mail исполняемые файлы. А вы опубликуете результаты.
Могу попробовать на ноуте =) Sempron SI-42 2,1 GHz; 2 Gb озу; Win7
gsirrxz[известный знак]жмэйл.com
gsirrxz[известный знак]жмэйл.com
Результаты таковы:
Intel — 280 ms
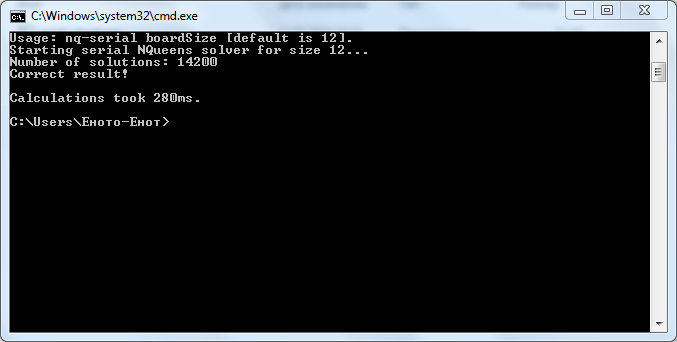
Visual — 555 ms (Да, красивое число ^^)

Intel — 280 ms

Visual — 555 ms (Да, красивое число ^^)
Прирост в итоге меньше. 98%, против 104% на процессоре Intel (что-то при расчете 107% я не получил).
Прирост зависит от многих факторов. Если прокрутить тысячу раз, то может получить среднее значение адекватное. А при прогоне 1 раз вполне может быть что то не объяснимое. Есть традиционное объяснение, мол антивирус решил запуститься во время счета.
А разница в 3-4% при одноразовом запуске — абсолютно привычное явление. Вот вот 20-30% это другой разговор. А 3-4 статистическая погрешность на измерения, работу планировщика потоков и наборы команд процессора.
А разница в 3-4% при одноразовом запуске — абсолютно привычное явление. Вот вот 20-30% это другой разговор. А 3-4 статистическая погрешность на измерения, работу планировщика потоков и наборы команд процессора.

Вот такой результат на стареньком атлоне
У компилятора Intel проблема в том, что он не все доступные инструкции AMD задействует (например, SSE5, если не ошибаюсь), в то время как на процессорах Intel он те же наборы использует полноценно.
Поэтому не у каждого приложения можно заметить падения производительности. Как правило, страдают расчетные/научные задачи.
Поэтому не у каждого приложения можно заметить падения производительности. Как правило, страдают расчетные/научные задачи.
И правильно не поддерживает, ибо SSE5 еще не поддержаны в железе и будут поддерживаться только AМД. Почему об этом должна заботиться Интел?
Я привел SSE5 как пример.
Не поддерживается вообще вся линейка команд SSE. Пруф.
Не поддерживается вообще вся линейка команд SSE. Пруф.
Кто мешает AMD или VIA написать свой компилятор?
А почему AMD/VIA должны писать свой компилятор? Всего лишь из-за того, что конкурент — нехорошая компания?
Если бы Intel декларировала свой компилятор как совместимый только с процессорами Intel, то никаких жалоб, скорее всего, не было бы. Проблема в том, что они пытаются скрыть то, что они делают. Многие программисты считают, что компилятор Intel совместим с процессорами AMD. Это так, но в тайне от программиста он включает в программу предвзятый диспетчер процессора, который выбирает худший вариант кода при работе на процессорах всех компаний, кроме Intel.
Когда я начал тестирование компилятора Intel несколько лет назад, я вскоре выяснил, что его диспетчер процессора предвзят. Ещё в январе 2007 года я пожаловался Intel на несправедливый диспетчер процессора. Я долго переписывался с инженерами Intel по этому вопросу. Они постоянно отрицали проблему, а я приводил всё больше доказательств.проблема не в том, что Intel производит предвзятый компилятор. Проблема в том, что они отказываются это признать.
В тестах четко видно, что первая задача работала около 2.5 секунд, вторая — около 1.5, а значит выдаваемые значения были в милисекундах, а не в микросекундах. Странно немного смотреть обзоры производительности от человека, не видящего разницу между милисекундами и микросекундами.
Делать обзор, так уж до конца.
Добавить в сравнение компилятор g++, собирать под разные ОС (Windows, Linux, FreeBSD, MacOSX) и разные процессорные архитектуры (x86, x86-64).
Добавить в сравнение компилятор g++, собирать под разные ОС (Windows, Linux, FreeBSD, MacOSX) и разные процессорные архитектуры (x86, x86-64).
Имхо обзор какой-то неинформативный — да, подменили компилятор, получили прирост. Это как я сейчас заменю LINQ на PLINQ и покажу что вот вам производительность.
Я не очень силен в LINQ и в PLINQ, но думаю Гуглу можно верить. PLINQ ~ LINQ для многоядерных систем. В моем примере о параллельности и слова нет. Меняется только компилятор, для сборки проекта, никаких дополнительных опций компиляции (e.g. /Qparallel) не добавляется. Таким образом считаю, что это замечание не уместно.
Да не суть. Просто вы как бы ничего не продемонстрировали. Ну да, другой компилятор, задачи не видно, непонятен смысл. Вот если бы вы показали как например TBB использовать чтобы выжать максимум из алгоритма — это да.
Впрочем, мне не надо продавать Интелевский компилятор и библиотеки, я уже давно подсел.
Впрочем, мне не надо продавать Интелевский компилятор и библиотеки, я уже давно подсел.
мда х))) хотите я сделаю такую же презенташку с ровно противоположным результатом?
Не прошло и двух минут, а ключевые слова «Интел» и «Интел Паралел Студио» прозвучали 6 раз каждый.
Зомбируете?
Зомбируете?
Укажите опции компилятора для каждого случая. Без них не совсем ясно, как интерпретировать результаты.
Я уже писал тут, никаких дополнительных ключей не добавлялось. Использовались все ключи, которые выстовляются по умолчанию.
Тем не менее, вот команд лайны
для Visual C++: /Oi /GL /D «WIN32» /D «NDEBUG» /D "_CONSOLE" /D "_UNICODE" /D «UNICODE» /FD /EHsc /MD /Fo«Release\\» /Fd«Release\vc90.pdb» /W3 /nologo /c /Wp64 /Zi /TP /errorReport:prompt.
И для Intel С++: /c /Oi /Qipo /D «WIN32» /D «NDEBUG» /D "_CONSOLE" /D "_UNICODE" /D «UNICODE» /EHsc /MD /GS /fp:fast /Fo«Release/» /W3 /nologo /Wp64 /Zi
Тем не менее, вот команд лайны
для Visual C++: /Oi /GL /D «WIN32» /D «NDEBUG» /D "_CONSOLE" /D "_UNICODE" /D «UNICODE» /FD /EHsc /MD /Fo«Release\\» /Fd«Release\vc90.pdb» /W3 /nologo /c /Wp64 /Zi /TP /errorReport:prompt.
И для Intel С++: /c /Oi /Qipo /D «WIN32» /D «NDEBUG» /D "_CONSOLE" /D "_UNICODE" /D «UNICODE» /EHsc /MD /GS /fp:fast /Fo«Release/» /W3 /nologo /Wp64 /Zi
А что насчет размеров полученных исполняемых файлов?
В данном примере размеры исполняемых файлов следующие:
Visual С++: 112664 байт.
Intel С++: 15360 байт.
Архив с исполняемыми файлами можно скачать тут. Пароль к архиву intelamd. По умолчанию трудоемкость задачи определяется числом 12 (размерность шахматной доски). Можно передать что-то по серьезнее 13 или 14 (как параметр)для увеличения общей трудоемкости.
З.Ы. надо еще добавить расширение к файлам .exe
Visual С++: 112664 байт.
Intel С++: 15360 байт.
Архив с исполняемыми файлами можно скачать тут. Пароль к архиву intelamd. По умолчанию трудоемкость задачи определяется числом 12 (размерность шахматной доски). Можно передать что-то по серьезнее 13 или 14 (как параметр)для увеличения общей трудоемкости.
З.Ы. надо еще добавить расширение к файлам .exe
Если кому интересно, то вот результаты, полученные с испльзованием компилятра vc++2010 со следующими параметрами командной строки
Размер полученного исполняемого файла: 10 240 байт
Среднее время исполнения для параметра 12: 266ms
Результаты для приведенного по ссылке интеловского варианта программы.
Размер полученного исполняемого файла: 15 360 байт
Среднее время исполнения для параметра 12: 260ms
Параметры компа: C2D T7300, Win7eng x86.
/Zi /nologo /Wall /WX- /MP /FAu /Ox /Ob2 /Oi /Ot /Oy /GL /D «WIN32» /D «NDEBUG» /D "_CONSOLE" /D "_UNICODE" /D «UNICODE» /Gm- /EHsc /MD /GS- /fp:precise /Zc:wchar_t /Zc:forScope /GR- /openmp- /Fp«Release\Step1-Serial-Hotspot.pch» /Fa«Release\» /Fo«Release\» /Fd«Release\vc100.pdb» /Gd /analyze- /errorReport:queue
Размер полученного исполняемого файла: 10 240 байт
Среднее время исполнения для параметра 12: 266ms
Результаты для приведенного по ссылке интеловского варианта программы.
Размер полученного исполняемого файла: 15 360 байт
Среднее время исполнения для параметра 12: 260ms
Параметры компа: C2D T7300, Win7eng x86.
Какой-то сферический конь в вакууме. Я собирал icc боевые проги и понял, что этот прирост не стоит того, во первых на глаз заметного прироста нет: все эти оптимизации работают хорошо только в пределах кода, хорошо поддающегося этой самой оптимизации, а большая часть таким кодом не является. Да и мне показалось, что, в сравнении с gcc, у кода собранного icc багов больше.
Sign up to leave a comment.
Пример увеличения производительности. Intel C++ vs. Visual C++