 Пост по мотивам прошедшего в пятницу финала ACM ICPC 2010, о том, как в буквальном смысле слова «на коленке» поднять зеркало умирающей под нагрузкой странички, прикрутить к нему чат с ее обсуждением, и не загнуться от нагрузки самому :)
Пост по мотивам прошедшего в пятницу финала ACM ICPC 2010, о том, как в буквальном смысле слова «на коленке» поднять зеркало умирающей под нагрузкой странички, прикрутить к нему чат с ее обсуждением, и не загнуться от нагрузки самому :)Пост будет интересен скорее веб-программистам, нежели олимпиадникам.
Немного статистики, конфигов nginx, полезные трюки, а также ряд граблей, которые должны быть прекрасно известны людям с опытом, но на которые многие все равно часто наступают…
Предыстория
Пару дней назад состоялось одно из главных событий года в спортивном программировании, о котором уже писали на хабре.
В узких кругах любителей этих соревнований (это несколько тысяч человек по всему миру) есть традиция: во время финала на 5 часов собираться за экранами мониторов и следить за «живой» таблицей результатов. Интерес сродни тому, с которым нормальные люди смотрят трансляции ЧМ по футболу :) (на который Россия, увы, не попала, в отличие от).
К сожалению, официальная страница с заветной табличкой ежегодно падает под хабр-, топкодер- и прочими эффектами, да и не отличается особой удобочитаемостью, поэтому уже в 4-й раз я делал ее неофициальное зеркало, с
Краткая статистика
Всего за 5 с небольшим часов:
— 6000 уникальных IP (в пике за 10-минутный интервал — 2000)
— 1М запросов к статичным файлам
— 500К long-poll запросов
Нагрузка на сервер в пиковое время (9 утра по Москве — начало последнего часа соревнований, время «заморозки» таблицы) — 1.5К подключений к nginx, 50М съеденной им памяти, менее 1% загрузки CPU, исходящий трафик 7 Мбит/сек. То есть, хватило бы VDS в близкой к минимальной конфигурации или даже ноутбука на коленях — главное, чтобы канал позволял.
Немного графиков из cacti (данные за 2 суток, чтобы можно было сравнить с нагрузкой сервера в «мирное» время):

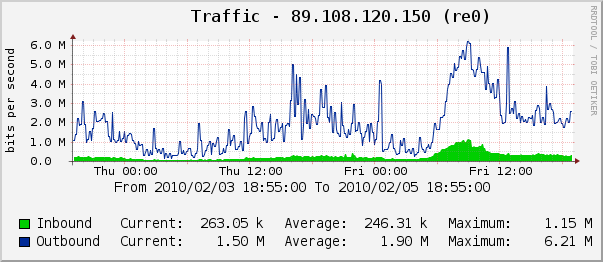
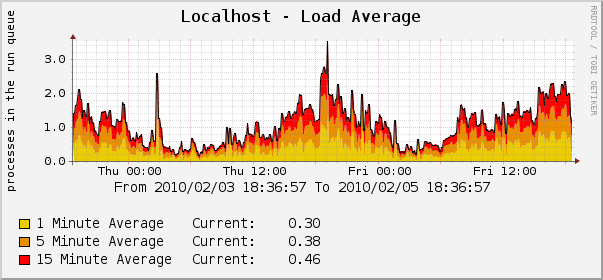
Конфигурация
В прошлые годы вся «морда» — это была несложная страничка, дергающая обновления своей основной части — таблицы, посредством ajax раз в 15-30 секунд (период настраивался пользователем). Со всей нагрузкой на ура справлялась банальная связка apache + php с минимальным кэшированием — официальная таблица скачивалась не чаще 1 раза в 10 секунд, парсилась в json и затем раздавалась всем спрашивающим.
В этом году захотелось попробовать что-то новое, начитавшись на хабре статей про такие вещи, как long-polling, comet и т.п., решил сделать что-то такое у себя. Да и чат давно хотелось прикрутить…
Напомню, что суть long-polling — «подвешивание» клиентских запросов вплоть до прихода новых данных на сервер, в результате клиенты получают ответ сразу же, как эти данные появляются. Для реализации этой функции использовался nginx_http_push_module.
Почему он, а не realplexor, cometd или самописный демон? Потому что он умеет ровно то, что хотелось, а именно:
— полный контроль формата данных — на сервере для обновления данных делается простой POST-запрос, все содержимое которого в точности как есть отдается ожидающим клиентам
— нет необходимости использовать дополнительные библиотеки, на клиенте делается такой же ajax-запрос, просто он доооолго выполняется :)
— поддержка аналога gzip_static (сжатие не в момент выдачи клиенту, а предварительное), благодаря первому пункту
Для подстраховки клиент умел работать и в старом режиме, обычными ajax-запросами по таймеру, а новый режим включался пользователем выбором «real-time» в настройках.
Благорадя гибкости nginx_http_push_module, смена режима заключалась только в смене URL для опроса и таймеров — данные приходили в точности одни и те же.
Компоненты системы:
— главная страница — оболочка со всем клиентским кодом, загружаемая в идеале один раз
— динамические данные в виде двух файлов — standings.js (таблица) и chat.js (последние 30 сообщений чата) — их клиент и тянет, либо по таймеру, либо long-poll запросами
— постоянно запущенный независимо от апача демон на php, скачивающий и парсящий официальную таблицу каждые 3 секунды и сохраняющий ее в standings.js
— скрипт на php, принимающий (тоже аяксом) сообщения в чат, пересобирающий chat.js
— nginx_http_push_module, в который два предыдущих скрипта также кидали обновления (содержимое соответствующих файлов, сжатое в gzip), и к которому подцеплялись клиенты, использующие «real-time» режим.
Конфигурация nginx, реализующая упомянутую логику:
location ~ ^/fairy/post/([a-z0-9._-]+)$ {
access_log /var/log/nginx-fairy.log main;
push_publisher;
set $push_channel_id $1; # чтобы каналы назывались по именам файлов
push_message_timeout 2h; # время хранения побольше
push_min_message_recipients 0;
push_message_buffer_length 1; # продвинутая логика с очередью сообщений не нужна, хватит последнего
}
location ~ ^/fairy/([a-z0-9._-]+)$ {
access_log /var/log/nginx-fairy.log main;
push_subscriber;
push_authorized_channels_only on; # запрещаем читать из несуществующих каналов
push_subscriber_concurrency broadcast; # каналы не персонализированы, а общие
set $push_channel_id $1;
default_type text/plain;
add_header Content-Encoding gzip; # эмуляция gzip_static
expires epoch; # см. ниже про кэширование
}
(почему /fairy? да потому что раздражает название comet :) )
Получилось, что «каналы» эмулировали обычные js файлы, по адресу /fairy/standings.js отдавалось то же самое, что и по адресу /standings.js (статичный файл), но с «подвисанием» до его обновления, а обновление делалось через POST /fairy/post/standings.js, вот такая простая и понятная схема URL-ов.
Некоторые мысли на тему добра и зла
1. gzip — добро
У официальной таблицы (html весом 50К, обновляющийся через meta refresh раз в 30 сек) не было ВООБЩЕ никакого gzip-а, и в итоге умирал канал.
(к чести организаторов, позже они сделали ее зеркало, где gzip таки появился)
2. gzip_static — добро
Зачем сжимать все эти мегабиты исходящего трафика на лету и тратить на это CPU, если можно вместе с обновляемым файлом создать рядом файл.gz и сказать nginx отдавать его, если клиент поддерживает?
3. обновление файла записью поверх (вместо записи рядом + rename) — зло
Если в этот момент его качать (а его БУДУТ качать) — начинаются неприятности.
Официальная таблица так и обновлялась, из-за чего пользователи иногда видели «порванную» таблицу, а уж если ее в таком виде тянул мой скрипт… все бы ничего, но он считал разницу новой и предыдущей версий таблиц и кидал информацию о новых «плюсиках» в чат. В итоге чат периодически заваливало волной ложных срабатываний, что вызывало шок у неподготовленных зрителей :)
(кое-как удалось починить прямо на ходу добавлением дополнительных проверок)
4. оптимизация времени загрузки — добро
Весь клиентский код весит менее 15к в gzip — по этой причине я не использовал свой любимый jquery и прочие фреймворки — мне не нравится, когда фреймворк весит вдвое больше, чем все остальное вместе взятое :)
Также, чтобы избежать надписей «loading...» при первом заходе, файлы с данными добавлялись на страницу через <script src="..."> и грузились, не дожидаясь onload/documentready.
Результат — готовая собранная таблица + последние сообщения чата у меня грузились с нуля за 0.2-0.3сек, включая пинг до сервера (по показаниям firebug), вышло быстрее чем главная страница гугла :)
5. правильно настроенное клиентское кэширование — добро
До сих пор очень часто вижу костыли с добавлением чего-нибудь вроде &random=74925 в запрос…
Между тем, достаточно поставить заголовок Expires в прошедшее время, чтобы браузер всегда делал запрос (в nginx это делается одной строкой — expires epoch), и научить клиентский скрипт обрабатывать ответ 304.
Также надо следить за тем, чтобы при ajax-запросах передавался правильный If-Modified-Since, тот же nginx_http_push_module его активно использует.
Я туда подставлял содержимое заголовка Last-Modified от последнего полученного ответа на тот же URL (вообще, браузер сам так и делает, но если у пользователя выключено кэширование, это не так).
6. отсутствие OpenID — зло
У участников чата была возможность подписываться своими никами на TopCoder (для выделения их имен соответствующим цветом), и мне очень не хватало возможности проверять их подлинность без специальной регистрации (которая в условиях скрипта «на одну ночь» невозможна). Впрочем, большинство участников вели себя на удивление культурно, но наиболее зарвавшихся личностей пришлось лечить баном IP :)
К сожалению, из-за их наличия я был вынужден отключить чат в конце, когда решил наконец немного поспать — оставлять все без модерации я просто не рискнул.
7. отказ от поддержки IE6 — добро
Обнаружив незадолго до начала, что чат не работает во всеми нами «любимом» браузере (кажется, из-за чуть несовместимого в деталях XMLHTTPRequest), я с чистой совестью повесил табличку в духе «извините, в IE6 что-то может не работать, обновитесь уже наконец» и занялся более полезными для остальных пользователей вещами.
Считаю, что так и надо делать, т.к. главная функция — показ таблицы результатов — продолжала работать даже там.
Кажется, получилось чрезмерно много букв. Но надеюсь, кому-нибудь мой опыт окажется полезен.
И да, ППНХ :)
