Comments 31
UFO just landed and posted this here
Рулит JSONP, т.к. работает везде быстро. :-)
О том, что нативные парсеры — это хорошо я пишу в выводах. Проблема в другом: вы их никак не скрестите с JSONP. Ясное дело, что если речь идет именно о парсинге JSON, а не о выполнении полной задачи «запросил-получил-обработал», то лучше всего использовать враппер, в котором первым делом пробуется нативный парсер, а уж если он отсутствует — что-нибудь другое в порядке предпочтений…
О том, что нативные парсеры — это хорошо я пишу в выводах. Проблема в другом: вы их никак не скрестите с JSONP. Ясное дело, что если речь идет именно о парсинге JSON, а не о выполнении полной задачи «запросил-получил-обработал», то лучше всего использовать враппер, в котором первым делом пробуется нативный парсер, а уж если он отсутствует — что-нибудь другое в порядке предпочтений…
А вы уверены, что работа с JS сводится к парсингу JSON?
opera 10?
А уже есть релиз? ;-) Мне казалось, что буквально только что на хабре анонсили какую-то очередную ее бета-сборку…
Я не знаю кому как, а лично мне не нужны «технологии ради технологий» и, соответственно — тестирование ради тестирования. Пусть этим техногики занимаются. :-) Меня интересует то, что используется в production.
Я не знаю кому как, а лично мне не нужны «технологии ради технологий» и, соответственно — тестирование ради тестирования. Пусть этим техногики занимаются. :-) Меня интересует то, что используется в production.
Релиза нету, но все фаны давно на неё пересели :)
И её упомянули, не чтобы оправдать Оперу, а просто реально интересно, как там она, может она даже хуже 9й…
И её упомянули, не чтобы оправдать Оперу, а просто реально интересно, как там она, может она даже хуже 9й…
клева… после строчки о удаленном сервере, тесты можно не смотреть.
Если в момент теста, например оперы просто была немного больше загружена сеть… то отсюда возможны такие вот результаты.
Если в момент теста, например оперы просто была немного больше загружена сеть… то отсюда возможны такие вот результаты.
Полностью согласен! О чем я, собственно, несколько раз упомянул в статье… Но, что же поделать — се ля ви… Я уже говорил — скачивать статику с локалхоста было бы намного проще и приятнее, но тогда результаты получаются еще хуже — тот же Хром первый же запрос кэширует, а последующие результаты получаются в районе нескольких мс… Каждый тест проводился по 50 раз, так что результаты худо-бедно, но усредняются…
А, извините, зачем вы вообще брали какой-то сервер?
Сделали бы локальную страницу с javascript и на ней бы все протестировали…
Сделали бы локальную страницу с javascript и на ней бы все протестировали…
Затем что некоторые браузеры отлично кэшируют как страницы, так и отдельные js-объекты. Например, у того же Chrome'а кэширование не менее (а может даже и более) агрессивное, чем у Оперы: он в приведенном примере только первый запрос делал реально, а остальное все брал из кэша.
Собственно, в другом тестировании обработки JSON, ссылка на которое была в топике, как раз некоторые комментаторы объяснили еще более скоростные результаты Хрома именно кэшированием. Поэтому и было решено от этого отказаться… Пусть даже итоговые результаты менее репрезентативны.
Собственно, в другом тестировании обработки JSON, ссылка на которое была в топике, как раз некоторые комментаторы объяснили еще более скоростные результаты Хрома именно кэшированием. Поэтому и было решено от этого отказаться… Пусть даже итоговые результаты менее репрезентативны.
Графики бы, графики… а так за на наглядность неуд.
Да не вопрос. Тоже хотел графики, но не придумал — между чем и чем. Что сравнивать: один и тот же браузер с разными методами обработки JSON, или разные браузеры с одинаковым методом? Опять же — результаты недостаточно репрезентативны, а цифры не настолько радикально отличаются, чтобы можно было сделать красивые графики… :-( Наглядность была бы неплохой, если бы можно было строкам таблицы назначить фоновой цвет и тем самым выделить — что и с чем сравнивать. Но хабр этого не позволяет…
Обожаю топики, начинающиеся со слова «Сравнение», в них обычно очень много интересного. Автор, огромное спасибо, было интересно прочитать.
Из браузеров лучше всего себя показали Chrome и Safari. Учитывая, что ноги у обоих растут из одного места — WebKit однозначно рулит. :-)
А разве webkit каким-то боком относится к парсингу json? о_О
А разве webkit каким-то боком относится к парсингу json? о_О
JSONP
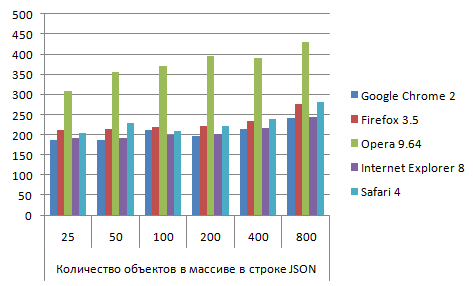
JSON_json2
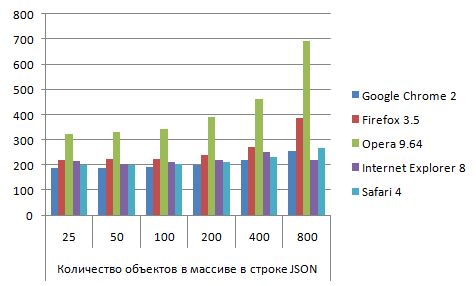
JSON_json_parse
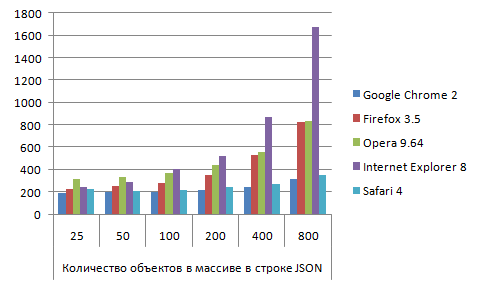
JSON_json_sans_eval
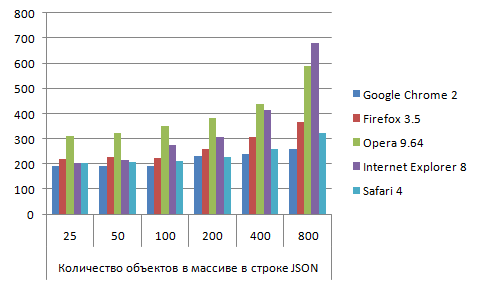
JSON_native

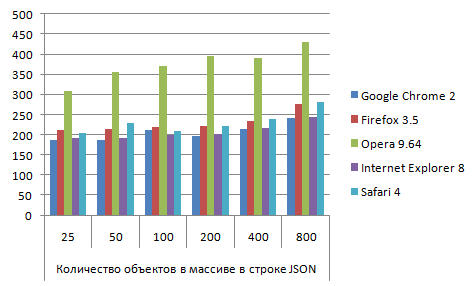
JSON_json2
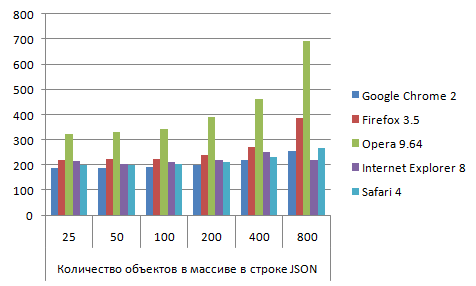
JSON_json_parse
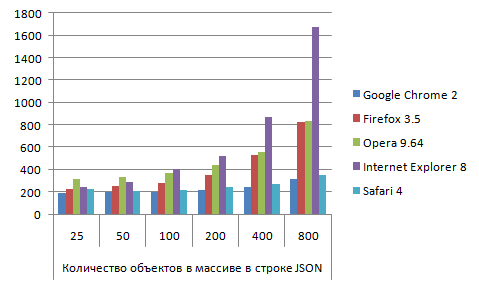
JSON_json_sans_eval

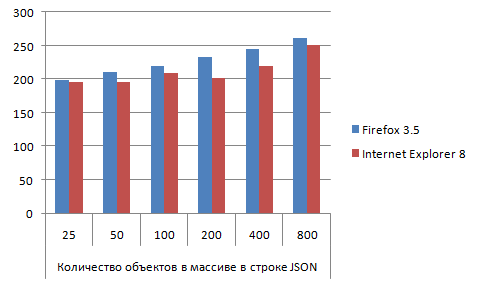
JSON_native
чаще всего слово «безопасность» употребляют люди, которые ничерта в ней не понимают…
не моя тема, но захотелось почитать и автор статью так оформил, что не понятно для непосвященных. цифры даны, а в чем измеряются, не описано. не написано что лучше «меньше — лучше» или «больше — лучше»
а так нормально! «афффтар пишы исчо»
а так нормально! «афффтар пишы исчо»
А почему не тестировался чистый eval?
Чистый eval есть в другом тестировании — ссылка на него есть в начале статьи. А смысл тестировать чистый eval? Парсер json2 с json.org — это и есть eval, строчка для которого перед этим через regexp проходит, очищающий ее от всего лишнего.
Кстати говоря, eval'ом не вполне корректно обрабатывать json по идеологическим соображениям, т.к. eval «схавает» нормально то, что не будет являться синтаксически правильным json'ом. Например, eval'у плевать на то, какие используются кавычки — двойные или одинарные, а в стандарте json определены только двойные. Могут потом несостыковки возникнуть, если не думать об этом… С другой стороны, в JSONP та же проблема. :-)
Кстати говоря, eval'ом не вполне корректно обрабатывать json по идеологическим соображениям, т.к. eval «схавает» нормально то, что не будет являться синтаксически правильным json'ом. Например, eval'у плевать на то, какие используются кавычки — двойные или одинарные, а в стандарте json определены только двойные. Могут потом несостыковки возникнуть, если не думать об этом… С другой стороны, в JSONP та же проблема. :-)
Приставка случайно не Dlink DIB-120?
А хотя бы теоретически рассматривается парсинг на сервере?
Или совсем большие объемы получаются?
Или совсем большие объемы получаются?
Sign up to leave a comment.
Сравнение скорости обработки JSON разными парсерами и браузерами