Привет, хабр.
Очень рад, что тема Data Mining интересна сообществу.
В данном топике (а если понравится, — в серии топиков) расскажу, какие примеры использования Data Mining есть в Российском и не только бизнесе. Почему я пишу об этом? Я работаю в компании, которая тесно связана с ВЦ РАН (Вычислительный центр Российской академии наук), что позволяет нам иметь отличный научно-исследовательский отдел и разрабатывать новые проекты, применяя отечественные достижения в математике. В данном топике будет больше бизнеса, чем науки, но если последняя все же вас интересует, тогда вам сюда: mmro.ru или сюда: www.machinelearning.ru
Итак, поехали:
Сегодня почти в любом большом бизнесе есть огромная туча данных, которые собираются и хранятся на протяжении многих лет. Основная задача Data Mining — нахождение в сырых данных нетривиальных зависимостей, которые позволят решить конкретную бизнес-задачу.
Большая торговая сеть, например Копейка, Перкресток, Пятерочка, Ашан, имеет сотни магазинов по всей РФ, десятки тысяч активных товаров. Данные о продажах каждого товара (SKU) в каждом конкретном магазине в каждый момент времени (день или час) хранится в учетной системе компании.
Торговая сеть ежедневно должна заказывать товары в свои магазины. Т.е. ежедневно в матрице, например [5000 Х 10 000] должно стоять значение — сколько везти этого товара?
Если торговая сеть закажет меньше, чем будет реальный спрос, то получит УБЫТКИ из-за дефицита (и потеряет наценочную стоимость), если сеть закажет больше товаров, чем будет реальный спрос, то получит УБЫТКИ из-за стоимости хранения товароов на складе, замороженных средств, порчи товара после истечения срока годности. Эти два типа убытков называются соответственно out-of-stock и over-stock.
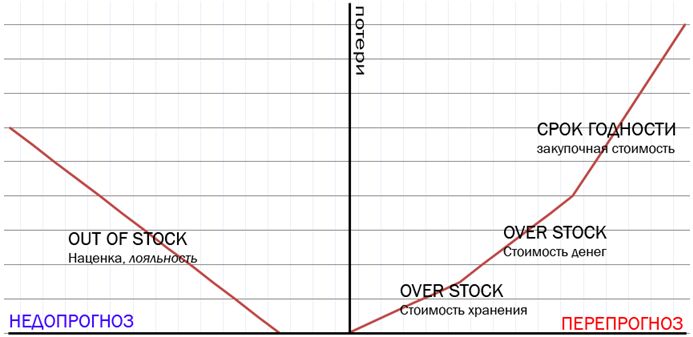
Что же делать? На основе накопленной истории по товародвижениям в каждом магазине и каждому товару можно научиться на прецедентах и построить прогнозирующую модель, которая будет учитывать:
1. Недельную сезонность (например, водка продается начиная с четверга, энергетики продаются больше по пятницам)
2. Годовая сезонность (например, пиво покупают летом больше)
3. Праздники (например, Советское шампанское продается в 100 раз больше чем в среднем на 8 марта, 31 декабря, 23 февраля)
4. Промо-акции (например, всплеск продаж песиколы в сентябре — это не годовая сезонность, а эффект от проведения промо-акции с Бритни :))
В любой data-mining задаче важно грамотно очистить данные перед работой и построением моделей. Поэтому в случае с продажами, важно обучаться не на реальных продажах, а на «восстановленном спросе». Что это?
Допустим конфеты у вас продавались в течении месяца равномерно, а в последнюю неделю их не завезли и продажи были равны 0. Это ведь не означает, что не было спроса (и в последней неделе следующего месяца спроса тоже не будет :)). Поэтому в данной ситуации важно восстановить спрос в местах отсутствия продаж.
А что делать, если у вас появляется новый товар (по которому еще нет истории)? В данном случае важно смотреть на историю по товарной группе. Например появления чая «icetea lipton персиковый» можно прогнозировать по товарной группе «холодные чаи», при этом не забыть учесть фактор «как появление нового товара в истории отражалось на продажах в целом по группе».
Тоже самое происходит с новыми магазинами — сколько товаров заказывать во вновь открывшийся магазин? Нужно найти «похожий» магазин и первое время прогнозировать на основе его истории, а потом плавно переключиться на историю нового магазина.
Все это задачи работы с данными в data minnig.
Ежедневно системы прогнозирования в ритейле обрабатывают гигабайты (а где-то терабайты) данных, что сделать прогноз и ответить на вопрос: Сколько каждого конкретного товара заказать в каждый конкретный магазин, чтобы сократить финансовые издержки и максимально учесть (спрогнозировать) спрос.
Если у вас 1-2 магазина и несколько тысяч позиций — человек вам спрогнозирует лучше любой машины, но когда у вас WallMart и сотни тысяч товаров на полках — никакая армия аналитиков и товароведов не справятся с решениям такой задачи, именно поэтому в торговых сетях так пристально обращают внимание на автоматизация бизнес-процессов.
ФАКТ: улучшение прогнозирующей модели способно снизить издержки торговой сети на 1-2 процента от оборота. А теперь подумайте, какие это деньги, учитывая тот факт, что оборот крупнейших российских сетей — от 1 миллиарда долларов.
Я думаю, что на этом пример1 про торговые сети я закончу. Если интересно — пишите вопросы, комментарии — я ответу. Если в целом понравится — в следующий раз расскажу про телеком, и как они решают задачу «повышения лояльности абонента», учитывая объемы в десятки и сотни миллионов абонентов.
Очень рад, что тема Data Mining интересна сообществу.
В данном топике (а если понравится, — в серии топиков) расскажу, какие примеры использования Data Mining есть в Российском и не только бизнесе. Почему я пишу об этом? Я работаю в компании, которая тесно связана с ВЦ РАН (Вычислительный центр Российской академии наук), что позволяет нам иметь отличный научно-исследовательский отдел и разрабатывать новые проекты, применяя отечественные достижения в математике. В данном топике будет больше бизнеса, чем науки, но если последняя все же вас интересует, тогда вам сюда: mmro.ru или сюда: www.machinelearning.ru
Итак, поехали:
Сегодня почти в любом большом бизнесе есть огромная туча данных, которые собираются и хранятся на протяжении многих лет. Основная задача Data Mining — нахождение в сырых данных нетривиальных зависимостей, которые позволят решить конкретную бизнес-задачу.
Пример1. Ритейл (торговые сети).
Большая торговая сеть, например Копейка, Перкресток, Пятерочка, Ашан, имеет сотни магазинов по всей РФ, десятки тысяч активных товаров. Данные о продажах каждого товара (SKU) в каждом конкретном магазине в каждый момент времени (день или час) хранится в учетной системе компании.
Торговая сеть ежедневно должна заказывать товары в свои магазины. Т.е. ежедневно в матрице, например [5000 Х 10 000] должно стоять значение — сколько везти этого товара?
Если торговая сеть закажет меньше, чем будет реальный спрос, то получит УБЫТКИ из-за дефицита (и потеряет наценочную стоимость), если сеть закажет больше товаров, чем будет реальный спрос, то получит УБЫТКИ из-за стоимости хранения товароов на складе, замороженных средств, порчи товара после истечения срока годности. Эти два типа убытков называются соответственно out-of-stock и over-stock.
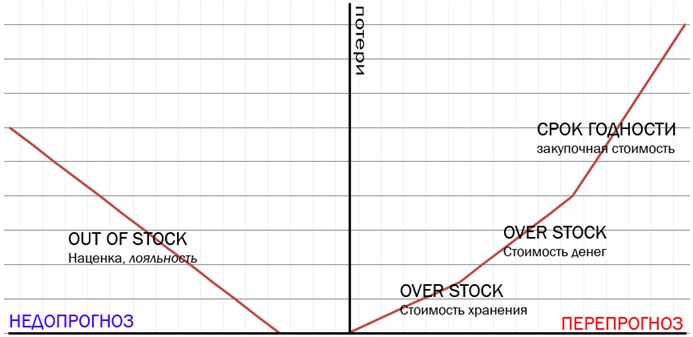
Что же делать? На основе накопленной истории по товародвижениям в каждом магазине и каждому товару можно научиться на прецедентах и построить прогнозирующую модель, которая будет учитывать:
1. Недельную сезонность (например, водка продается начиная с четверга, энергетики продаются больше по пятницам)
2. Годовая сезонность (например, пиво покупают летом больше)
3. Праздники (например, Советское шампанское продается в 100 раз больше чем в среднем на 8 марта, 31 декабря, 23 февраля)
4. Промо-акции (например, всплеск продаж песиколы в сентябре — это не годовая сезонность, а эффект от проведения промо-акции с Бритни :))
В любой data-mining задаче важно грамотно очистить данные перед работой и построением моделей. Поэтому в случае с продажами, важно обучаться не на реальных продажах, а на «восстановленном спросе». Что это?
Допустим конфеты у вас продавались в течении месяца равномерно, а в последнюю неделю их не завезли и продажи были равны 0. Это ведь не означает, что не было спроса (и в последней неделе следующего месяца спроса тоже не будет :)). Поэтому в данной ситуации важно восстановить спрос в местах отсутствия продаж.
А что делать, если у вас появляется новый товар (по которому еще нет истории)? В данном случае важно смотреть на историю по товарной группе. Например появления чая «icetea lipton персиковый» можно прогнозировать по товарной группе «холодные чаи», при этом не забыть учесть фактор «как появление нового товара в истории отражалось на продажах в целом по группе».
Тоже самое происходит с новыми магазинами — сколько товаров заказывать во вновь открывшийся магазин? Нужно найти «похожий» магазин и первое время прогнозировать на основе его истории, а потом плавно переключиться на историю нового магазина.
Все это задачи работы с данными в data minnig.
Ежедневно системы прогнозирования в ритейле обрабатывают гигабайты (а где-то терабайты) данных, что сделать прогноз и ответить на вопрос: Сколько каждого конкретного товара заказать в каждый конкретный магазин, чтобы сократить финансовые издержки и максимально учесть (спрогнозировать) спрос.
Если у вас 1-2 магазина и несколько тысяч позиций — человек вам спрогнозирует лучше любой машины, но когда у вас WallMart и сотни тысяч товаров на полках — никакая армия аналитиков и товароведов не справятся с решениям такой задачи, именно поэтому в торговых сетях так пристально обращают внимание на автоматизация бизнес-процессов.
ФАКТ: улучшение прогнозирующей модели способно снизить издержки торговой сети на 1-2 процента от оборота. А теперь подумайте, какие это деньги, учитывая тот факт, что оборот крупнейших российских сетей — от 1 миллиарда долларов.
Я думаю, что на этом пример1 про торговые сети я закончу. Если интересно — пишите вопросы, комментарии — я ответу. Если в целом понравится — в следующий раз расскажу про телеком, и как они решают задачу «повышения лояльности абонента», учитывая объемы в десятки и сотни миллионов абонентов.
