Комментарий автора: Основная цель доклада — рассказать про методы построения инфраструктуры (Configuration Synchronization/Immutable infra) и сравнить их. Ansible используется как пример одного из инструментов синхронизации конфигурации. С точки зрения автора мир движется в сторону immutable infrastructure и в докладе приводятся аргументы разъясняющие позицию автора. И так как мир движется в сторону immutable infrastructure, то учить инструменты использующие подход синхронизации конфигураций может быть не самым лучшим использованием времени. Повторю еще раз — доклад не про инструменты, а про подходы и принятие решения “от-проблемы”, а не “от-инструмента”
Disclaimer: Этот доклад сложен тем, что готовится под российскую аудиторию, которая работает в несколько специфических условиях. Мы потрогаем все эти вещи во время презентации. В России специфичное использование инфраструктуры, потому что народ в основном живет не на Amazon. Есть компании, которые и там живут, но их мало. И это является ограничением. Это стоит учитывать во всех докладах, связанных с раскаткой инфраструктуры, чтобы не говорить: «Ребята, поехали в облако, в AWS все будет отлично» и тут сидит толпа людей, которые туда поехать не могут. Российская аудитория кажется очень специфичной. И те доклады, которые заходят в Европе, в России не всегда заходят. Возможно, это связано с особым восприятием данной аудитории.

Всем привет! Спасибо, что пришли послушать! Сегодня мы обсудить, почему я не рекомендую людям изучать Ansible. Давайте разбираться.

Что же все-таки не так с Ansible? Давайте разбираться.

Еще несколько дисклеймеров.
Первый дисклеймер – это то, что в этой презентации нет цели сравнивать какие-то инструменты. Т. е. это не Ansible vs Terraform, Ansible против CloudFormation, Ansible против Chef и т. д.

Тогда вы сейчас, возможно, думаете: «А о чем тогда это может быть?»

Еще один дисклеймер:
- Это презентация построена на нашем опыте консалтингового агентства FivexL.
- Это именно то, что мы рекомендуем заказчикам на сегодняшний день.
- Все, что рассказывается в этой презентации, это мое субъективное мнение, а также мнение моих коллег. И оно достаточно прагматичное.
- Также нет серебряной пули, т. е. то, что я рассказываю здесь, не нужно воспринимать идеалистически. Нужно, как говорят англичане, воспринимать это с щепоткой соли.

И снова рассказываю не про Ansible?

Давайте поговорим про Ansible. Мы пойдем на страницу Ansible. Этот снапшот я сделал с нее 2 дня назад, так что он достаточно свежий. Мы можем попытаться разобраться, что же за инструмент такой Ansible и зачем его используют.
Мы видим из этой страницы, что его можно использовать для application deployment, менеджмента конфигурации, чтобы оркестровать таски. И это все работает либо через OpenSSH, либо WinRM.
Но это не отвечает на вопрос: «Зачем нам его использовать, какую проблему он решает?».

Поэтому мы можем пойти на страницу use-cases. Те ссылки, которые я привожу, вы увидите в левом нижнем углу экрана.
Мы видим, что его рекомендуют использовать для provisioning серверов, менеджмента их конфигурации, а также для того, чтобы раскидывать там приложения. И можно что-то делать для безопасности и оркестрации.

Наши заказчики часто к нам приходят с различными желаниями. Они говорят: «Давайте мы будем вот этот инструмент использовать».
А мы им говорим, что давайте пойдем от проблемы, поймем контекст.
Далее поймем методы, которые в этом контексте будут уместны.
И потом уже подберем инструмент, т. е. давайте не будем исходить из инструмента.

И если мы переварим все то, что сейчас увидели на слайдах касательно Ansible, то мы можем понять, что проблема – это автоматизация изменений IT.
Соответственно, контекст, который они подразумевают, это либо железные сервера, либо виртуальные машины.
Метод, который предполагается использовать, это инфраструктура как код и синхронизация конфигурации.
И предлагают использовать инструмент Ansible.

Многие из вас думают, что с Ansible можно делать многое другое.
Можно еще AWS настроить.
Можно и Kubernetes.
Можно и HashiCorp Vault настроить.
Можно все сделать с помощью Ansible при желании.

Но тогда стоит задуматься – будет ли Ansible решением той проблемы и в том контексте, которую вы решаете. Т. е. нужно идти от проблемы.

Иначе можно оказаться в ситуации, когда мы применяем инструмент как молоток, которым мы стучим везде и все нам кажется гвоздем.

Мы не хотим быть в этой ситуации. Плюс каждый раз, когда вы немножко выходите из mainstream, нужно подумать о последствиях. Vendor, который предлагает вам инструмент, говорит, как его можно использовать. Вы можете пойти попробовать вправо-влево и сделать что-то по-другому. Но вам нужно всегда думать: «Я это сделаю сейчас так, но тогда я начну что-то терять. Если я иду в другую сторону по сравнению с community, то я потеряю именно те вещи, которым community научится, т. е. какие-то инсайты я потеряю».
Дальше подумать: «То, что я делаю, это немного на стороне, какие здесь перспективы продолжительного саппорта? Могу ли я найти кого-то, кто захочет потом с этим работать в дальнейшем?».
Плюс, возможно, ваш начальник будет более рад, если вы будете фокусироваться на чем-то, что полезно бизнесу, вместо того, чтобы на стороне что-то такое делать, когда можно воспользоваться другим инструментом, который для этого больше подходит. Это такие вещи, которые стоит продумать.

Именно поэтому Ansible в рамках этой конфигурации мы будем рассматривать, как инструмент менеджмента конфигурации, который используется для provisioning серверов, чтобы раскидать applications, приложения по этим серверам. Плюс можно запускать таски, он это умеет делать.

Мы часто будем возвращаться к этому слайду и разговаривать про проблему, которая остается неизменной, т. к. также хотим автоматизировать изменения в IT.
Но в этой презентации я заявляю, что у нас меняется контекст, у нас меняются методы. И поэтому выбор инструмента может быть другим. Давайте разбираться.

Меня зовут Андрей Девяткин.
Называю себя cloud engineering-специалистом.
Я занимаюсь в частности AWS и инструментами компании HashiCorp. Выступал на HashiConf этим летом, потому что было очень классно.
Также являюсь основателем консалтинг-бренда FivexL.
Часто выступаю на конференциях. И еще у нас есть англоязычный podcast DevSecOps, где я и два моих друга рассуждаем о том, что сейчас происходит и пытаемся разобраться во всем. Мы пытаемся разобраться, что работает, что не работает. Это честный разговор, который мы записываем.

В этой презентации у нас будет очень много материала, который нам понадобится. Я эту презентацию разбил на 5 этапов, через которые мы сейчас пройдем.
На первом этапе мы будем говорить о том, что единственная константа – это изменения.
На втором этапе мы поговорим, что синхронизация конфигурации – это необходимое зло.
На третьем этапе мы поговорим про immutable-инфраструктуру и о том, что это, скорее всего, наиболее подходящая практика, которая у нас есть сегодня.
Поговорим о том, что появляются новые способы, новые контексты и новые методы.
Плюс поговорим о том, что будущее уже здесь. Оно просто неравномерно распределено.
Поехали, начнем с первого.

Мы посмотрим на большую картинку и попытаемся понять, почему происходят эти изменения в IT, которые нам надо автоматизировать.
Представьте ситуацию, что у потребителя, есть какое-то желание, которое ему нужно утолить.
И есть предприниматель. Предприниматель видит, что у потребителя есть какая-то потребность, которую он может утолить и получить за это деньги. Он тестирует какую-то бизнес-модель и предлагает продукт или услугу потребителю.
Теоретически в идеальных условиях мы можем сказать, что он построил машину по производству денег, если ничего не меняется.
Но это не так. Потому у нас есть competition, т. е. есть люди, которые приходят на рынок, видят, что сделал предприниматель и делают примерно то же самое, а, может быть, даже лучше. И они пытаются занять рынок. Например, мы начали с AWS в облаках, потом пришел Google, потом пришел Amazon, Alibaba, Яндекс, Сбер и т. д. Если бы другие игроки не пришли, то у Amazon была бы полная монополия, он бы просто делал денег. Но этого не происходит.
Коментарий автора: пришел Google, потом пришел Amazon, Alibaba — под Amazon имелся ввиду Azure
Поэтому постоянно приходится меняться, постоянно приходится соревноваться с другими. Плюс меняется сам рынок. Рынок может насыщаться. Могут происходить коренные изменения в рынке, например, как в этом году во время пандемии было тяжело всем перевозчикам и тем, кто зарабатывал на туризме. Для них рынок коренным образом изменился.
Поэтому бизнесу постоянно приходится меняться. И изменения постоянно будут продолжаться.

И каждое изменение приносит собой энтропию. Вы не можете просто изменить, у вас всегда будет элемент хаоса приходить вместе с изменением.

И если мы посмотрим словарь, то энтропия – это мера хаоса, это процесс разрушения, процесс деградации, когда материя во Вселенной станет в ultimate state, т. е. когда все совсем уйдет в хаос.

Вы можете сейчас сидеть и думать: «Как это все связано с Ansible?».

И тут нам надо задать вопрос: «Как же мы позволим бизнесу меняться быстро, но при этом минимизируем энтропию?».
И тут мы можем подумать: «DevOps!».
«Infrastructure as code!»
«Ansible!», наконец.
Но что мы сейчас делаем? Мы просто выкрикиваем термины, которые всплывают в нашей голове.
А должны мы идти по этому фреймворку. Мы должны идти от проблемы. Проблему мы сформулировали – мы хотим минимизировать энтропию, потому что она нам будет мешать по дороге, но при этом нам нужно стараться как можно больше автоматизировать все, что мы можем.

Поэтому мы немножко обсудим конфигурацию синхронизации и энтропию.
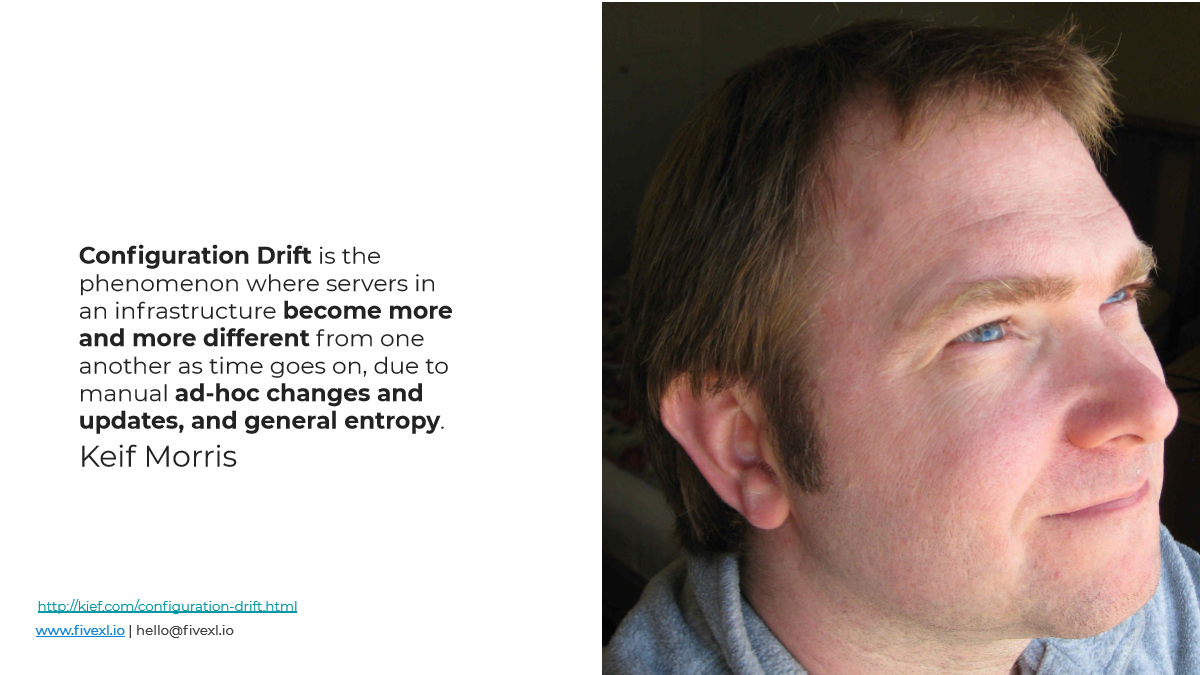
В нашей области энтропию называют – configuration drift. И первый раз я нашел это определение, когда читал книжку Keif Morris «Инфраструктура как код». Он не является тем человеком, который придумал это определение. Первыми этот термин использовали PuppetLabs поэтому атрибутика идет им.
Идея в том, что конфигурационный дрифт накапливается и потихоньку сервера отклоняются-отклоняются-отклоняются от изначальной конфигурации за счет того, что люди делают там что-то руками, делают апдейты, обкатывают новые приложения, приложения могут за собой что-то оставлять.

Потом за счет энтропии, за счет конфигурационного дрифта сервер может в какой-то момент прийти в состояние сервера-снежинки. Это что-то такое, что придумал Martin Fowler в свое время.
Сервер-снежинка – это сервер, который прошел точку невозврата. Он уже настолько свой, что уже никто не знает, как его так сконфигурировали, т. к. там уже столько всего накопилось. И трогать каждый раз его страшно. Он уникальный и очень хрупкий. Я думаю, что у многих были такие моменты, когда они сталкивались с такими серверами-снежинками.

Почему это проблема? Это проблема, потому что нарушается стабильность системы, т. е. мы не можем устанавливать приложения на эти сервера и иметь 100%-ную гарантию, что все пройдет гладко, потому что всегда есть доля неизвестности.
Плюс каждый раз, когда эта доля неизвестности срабатывает и что-то идет не так, мы свои ресурсы отвлекаем от продуктивной работы: от работы над новой функциональностью, от работы над улучшениями инфраструктуры, которая служила бы заказчику и позволяла бы бизнесу двигаться вперед. И, как я уже сказал, это влияет на нашу способность доставлять новые версии приложения. Смотрите на это, как на технический долг в инфраструктуре.
Также это влияет на наш MTTR (mean time to recovery), т. е. насколько быстро мы можем восстановиться после инцидента.

Приведу вам несколько примеров. Например, вам могло прийти письмо счастья от AWS о том, что железо, на котором лежит ваш EC2 instance, деградировало, и они собираются его прибить. И если у вас там такой сервер-снежинка, то день может стать намного интересней, чем он был.
В Amazon это все не так плохо. Вы можете взять снапшот, попробовать его пересоздать и с большой вероятностью это получится. А если у вас резко слетает жесткий диск на железном сервере, то это менее смешно.
Например, у вас случился второй shellshock и вам нужно все резко пропатчить. И тут могут навалиться различные инциденты, потому что патчи не проходят, т. е. вам сложно это сделать.
У моего коллеги Артема была ситуация со серверами-снежинками, у которых были GPU-драйвера. Эти сервера как-то руками наконфигурировали, но как это сделали никто не знает. Нужно было обновить GPU-драйвера. И это было большим приключением. На это ушло гораздо больше времени, чем должно уходить.
Например, в вашей сети находится нарушитель. И вам нужно произвести расследование и понять, что происходило на этом сервере. Эти файлы должны быть здесь или это Вася их поставил? Они должны быть в таком состоянии и в такой директории или им свойства поменяли? Должно ли быть все так?

Мы говорим сейчас в контексте именно серверов и виртуальных машин. И джентльмены, про которых мы говорили до этого, в начале 2010-ых говорили в терминологии серверов и виртуальных машин.

И что мы с этим делаем?

Обычный способ – это инфраструктура как код. И есть 4 принципа, сформулированные в книге «Инфраструктура как код»:
- Все элементы в инфраструктуре должны быть воспроизводимыми, т. е. у нас должна быть возможность их воспроизвести.
- За счет того, что мы можем их воспроизвести, у нас должна быть возможность их выкинуть. Они должны быть disposable.
- И за счет того, что мы конфигурируем как код, наша инфраструктура будет консистентной.
- Плюс у нее нет конечного состояния. Когда мы проектируем нашу инфраструктуру, мы понимаем, что то, что мы знаем сегодня ограниченно и завтра может измениться. Может измениться бизнес-контекст, могут измениться бизнес-нужды, поэтому то, что мы выстраиваем сегодня, это не что-то такое, что вырублено на камне. Это то, что будет меняться, поэтому нужно продумать, как мы это будем менять завтра. И нужно быть готовым это изменить.
Это 4 принципа, на которых держится инфраструктура как код.

И если мы посмотрим определение из Википедии, то там написано, что инфраструктура как код – это когда мы описываем всю нашу инфраструктуру в файликах. Эти файлики – machine-readable, т. е. какие-то инструменты могут эти файлики прочитать и потом перевести все, что в этих файликах написано, а потом пойти и сконфигурировать системы так, как мы это описали.

Технически мы применяем методы разработки software – одна конфигурация. Все те же методики, т. е. так же, как мы разрабатывали код, как мы разрабатывали продукт, тоже самое мы делаем с инфраструктурой, применяя те же методики. Можем делать code review, можем запускать CI и так далее

И наш шаблон потихоньку заполняется, т. е. мы говорим в контексте железных серверов и виртуальных машин. Применяем infra as code.

И я обещал поговорить про синхронизацию конфигурации и давайте про нее поговорим.

Было несколько поколений инструментов для работы с конфигурациями.
Я не буду называть номер этого поколения, но было конкретно выделенное поколение: Puppet, Chef. Ansible и SaltStack пришли чуть попозже. Это именно те инструменты, которые работали с синхронизацией конфигурации. Мы сейчас увидим, что это значит.
Специфика этих инструментов в том, что они автоматизируют provisioning. И чаще всего им нужна небольшая дополнительная конфигурация. В случае некоторых инструментов нужно установить агента на сервер, в случаях других нужно открыть firewall для того, чтобы он туда мог пойти, например, по SSH-порту и сделать то, что он хочет сделать.
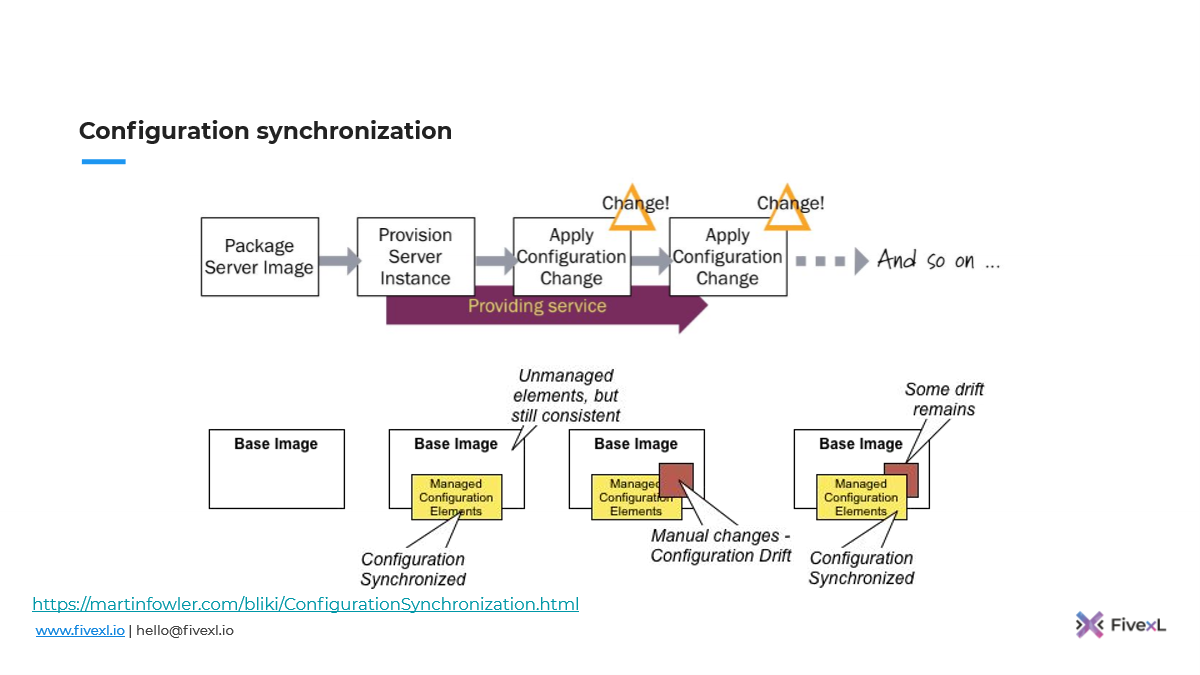
Вот эту картинку я взял из статей Martin Fowler. Это отличные картинки, ссылки внизу, если вы захотите всю статью прочитать. Это именно то, как работает конфигурация синхронизации.
У нас есть образ сервера. Мы накатываем его на сервер. Сервер у нас поднялся. И потом мы используем инструмент синхронизации конфигурации, чтобы применять изменения. Он поэтому так и называется. У нас лежит конфигурация в нашем репозитории, и мы ее запускаем, чтобы синхронизировать на сервере. И каждый раз, когда нам нужно что-то новое сделать, мы меняем это в репозитории, запускаем инструмент. И он это синхронизирует на сервере. Если мы не уверены, как он там встал, мы запускаем еще раз и делаем еще одну синхронизацию.
Опасность здесь в том, что мы не следим за всеми файлами на сервере. У вас всегда есть вероятность, что кто-то пошел и руками поправил и это вне ответственности инструмента. Это все накапливается-накапливается.

И это может привести к спирали страха автоматизации.
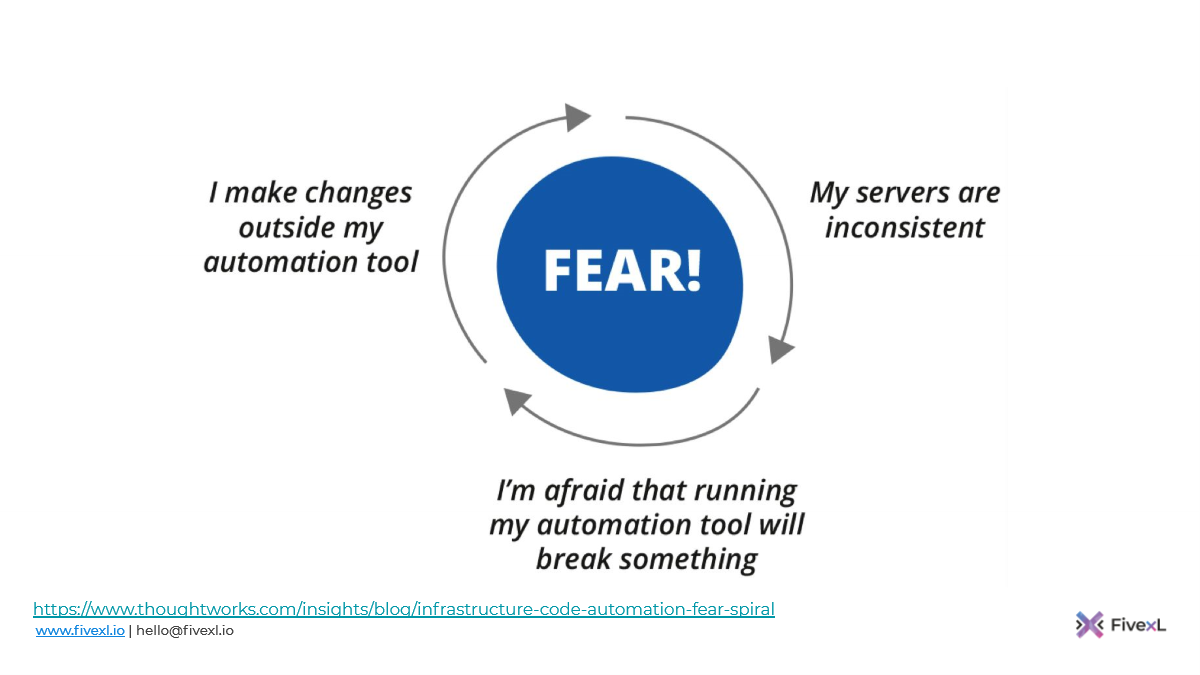
Как это работает? Вы делаете изменения вне вашего инструмента, которым вы синхронизируете конфигурацию. Ваши сервера становятся немного не консистентными. И потом вам становится страшно запускать ваш инструмент, потому что что-то может пойти не так: что-то может сломаться, если вы его запустите. Поэтому в следующий раз, когда вам нужно сделать изменения, вы снова их делаете руками, сервера становятся еще более не консистентными, и вам еще более страшней запустить ваш инструмент. И таким образом ваш сервер по спирали уходит вниз к состоянию сервера-снежинки.

Давайте посмотрим, как эволюционировала человеческая мысль дальше.

Потом те же ребята из ThoughtWorks пришли с идеей о Phoenix server,
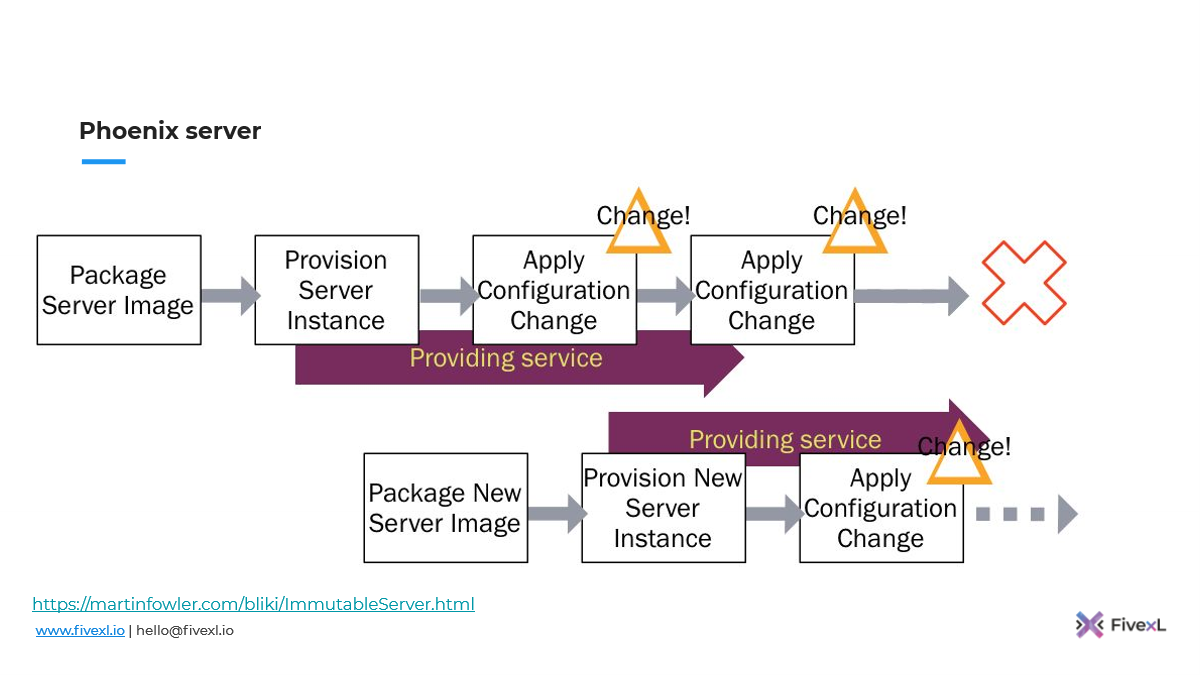
Идея такая же: мы делаем все то же, что конфигурация синхронизации, но в какой-то момент на периодической основе мы этот сервер прибивает, полностью все с него удаляем, заново накатываем образ сервера и потом запускаем наш инструмент. Таким образом мы обнуляем конфигурационный дрифт, который накопился.

Мы можем сделать еще один шаг.

Мы можем все изменения, все конфигурации, которые у нас есть, поместить в образ сервера и уже накатывать это сразу на сервер. И после этого не делаем никаких изменений, и просто раз в какой-то промежуток времени его удаляем. Если нам нужно сделать какие-то новые изменения, мы делаем новый образ сервера, накатываем его на сервер. Т. е. мы не делаем синхронизацию конфигурации, мы либо поднимаем новую виртуалку из нового образа или вайпаем (wipe, стереть) сервер и накатываем новый образ. И поэтому требуется несколько серверов, чтобы вы могли переключать трафик. Но за счет этого вы минимизируете количество конфигурационного дрифта.
И другой бенефит, который вы получаете от этого, у людей пропадает желание ходить на сервер по SSH, потому что они знают, что сервер будет уничтожен в какой-то момент и все изменения, которые они делают, пропадут. И вместо про то чтобы спрашивать вас о том где лежит SSH ключ они уже спрашивают вас о том, где лежит спека из которого будет собран образ для этого сервера. И это уже новый уровень диалога.

Если говорить еще о бенефитах, то, как мы уже говорили, у нас стремится к нулю конфигурационный дрифт.
У нас есть возможность масштабироваться быстро. Например, в рамках AWS у нас есть auto scaling группа. Вам нужно поднимать новые виртуалки. И вы не будете руками их запускать-запускать, а потом инструментом синхронизации конфигурации их настраивать, а потом только вводить в строй. Если у вас почти все заключено в ami (шаблон виртуальной машины), то тогда у вас auto scaling group может автоматически вам новые сервера легко поднимать, а также убивать. Вы ничего не теряете, потому что они всегда все одинаковые. Ничего нового здесь я не рассказываю. Это backing vs. frying, cattle vs pets. Все то что много раз рассказывалось на конференциях.
И у вас повышается уровень безопасности. Представьте, что в вашу сеть пробрался нарушитель. И вы это не заметили. А вы каждую неделю перекатываете все свои сервера. И таким образом все, что он установил, вы стираете. И ему придется каждую неделю повторять все те же мероприятия, чтобы хоть как-то закрепиться в вашей инфраструктуре.
Плюс, что делают те, кто нападают? Они нападают и сидят очень тихо. И они делают нумерацию всего того, что у вас есть: «Ага, веб-сервер на том IP-адресе, это на том IP-адресе». А у вас все меняется постоянно. У вас постоянно происходит ротация этих серверов, ротация IP-адресов, если вы в облаке. И им намного сложнее заниматься теми делами, которыми они пришли заниматься. Например, незаметные латеральные движения в вашей сети становится намного сложнее.
Плюс, за счет того, что вам минимальное время нужно на provisioning сервера, потому что все уже в образе находится, вы можете воспользоваться, если вы в облаке такими опциями, как EC2 spot instance. Если даже из-под вас spot instance выдернут, то ничего страшного. В другой зоне поднимется, потому что там осталось все по-прежнему, т. е. вы ничего не теряете. У вас будет 2 минуты для того, чтобы переключить трафик, чтобы убрать этот instance из ротации.

И тут вы можете подумать: «Если я использую Ansible, но при этом достаточно часто убиваю свои сервера, то, может быть, этого достаточно?».

Может быть. Как я вам сказал, эта презентация очень практичная. И мы не идеалисты, мы практики. Умные книжки вам всегда рисуют красивую картинку, но жизнь всегда сложнее. Ты приходишь иногда к заказчику и думаешь: «Боже мой, что же вы наворотили! Какой ужас!».
Конечно, этого нельзя людям в лицо говорить. Нужно пообщаться и понять, почему они так сделали. Скорее всего, у них были причины. Если бы у нас у всех были идеальные условия, то мы бы строили идеальные системы. Но условия не идеальные и часто приходится подстраиваться. И как хмурый котик нам сказал о том, что, может быть, это даст вам 80 % бенефитов за 20 % усилий.
Каждый для себя выбирает свою дорогу, основываясь на том фреймворке, о котором мы сейчас говорили.

Мы понимаем, свою проблему, свой контекст, свои ограничения. И сейчас мы уже видим, что есть новые методы, из которых мы можем выбрать. И когда мы работаем в контексте серверов и виртуальных машин, мы можем выбрать синхронизацию конфигураций или можем выбрать immutable-инфраструктуру.
И мы рекомендуем нашим заказчикам, что immutable-инфраструктура – это более лучший подход.

Как ее имплементировать? Давайте поговорим про это.

В идеале перед тем, как вы начнете, вам надо посмотреть на ваши приложения. И будет очень хорошо, если ваши приложения будут соответствовать 12 факторам app.
Там очень полезные вещи написаны. И очень смешно, когда системные инженеры, которые занимаются инфраструктурой, выстраивают системы, приходят к девелоперам и говорят: «Вы про 12 factor app слышали? Давайте так делать». И очень часто на них люди удивленно смотрят.
И если вы следуете этим рекомендациям и если ваше приложение сегодня не запускается в контейнерах, то переезд контейнера будет намного проще. Плюс вам будет намного проще имплементировать immutable-инфраструктуру.
На этом слайде я привожу несколько примеров этих принципов, чтобы вы поняли, о чем это.

Давайте подумаем о тех вещах, которые стоит учесть.
У нас есть 3 большие области, про которые стоит подумать:
- У вас всегда будет какая-то динамическая конфигурация, которую вы не знаете наперед. И, может быть, эту часть вы решаете сегодня с Ansible.
- У вас могут быть какие-то секреты, которые вы не хотите запихивать в образ. И нужно подумать, как это решить.
- И нужно подумать, как сделать так, чтобы люди туда не ходили, чтобы этот конфигурационный дрифт не накапливался. И как им все-таки туда пойти, если очень нужно.

Давайте разбираться с секретами сначала.

Нам нужно решить проблему нулевого секрета. И в зависимости от той среды, которую мы используем, применяются разные вещи. Например, если это AWS, то мы можем использовать instance-профайлы, которые нам дадут credentials, которые мы потом можем в дальнейшем использовать.
Если это Bare Metal, то там много разных систем.
SPIFFE все больше набирает популярность, чтобы давать серверам identity. И потом, чтобы они могли через identity аутентифицироваться в других системах.
Другой вариант – вы можете запечь зашифрованные секреты в образ с учетом того, что ключ шифрования будет доступен, когда образ будет подниматься. Например, в AWS вы можете использовать KMS ключ, который доступен только в вашем аккаунте. Если ваш AMI утек, то его нельзя будет расшифровать, потому что нет доступа к ключу. В вашем дата-центре может быть HSM (hardware security module), в котором вы можете хранить ключи шифрования, которые будете использовать для того, чтобы расшифровывать секреты. Если у вас утечет образ, то ничего страшного, потому что ключи только там.
Также сейчас есть системы, которые позволяют затаскивать секреты вовнутрь, т. е. у вас приложение может подняться и прочитать все необходимые секреты, например, с HashiCorp Vault. Если вы бежите в AWS, то мы можете Secrets Manager использовать.
Также все больше и больше возможностей генерировать динамические credentials. Это не сильно относится к immutable-инфраструктуре, но это то, что мы всегда рекомендуем.
Плюс есть возможность пулить (pull) не только секреты, но и конфигурацию, например, используя Consul.

Что делать с людьми?

Нам нужно оставить возможность попасть на сервер, либо на виртуальную машину. Но сделать это так, чтобы люди наследили, когда они это делают. Грубо говоря, не надо гасить SSH-сервер, но SSH-порт стоит закрыть на firewall. И чтобы людям туда пойти, им сначала нужно открыть firewall. И у вас получится из этого какой-то event. Это зависит от того, как ваша инфраструктура выстроена. И на этот event вы потом можете настроить автоматическое убийство машин, потому что неизвестно, что человек там наделал.
И многие компании так делают. Если там кто-то что-то наделал ручками, то автоматически эта машина через 12 часов будет убрана из ротации и полностью очищена.

Как нам поступать с debug?

- В первую очередь нужно вытаскивать все, что мы можем вытащить. Стримить логи наружу, а также все метрики, т. е. все то, что можно вытащить, нужно вытаскивать.
- Дальше нам нужно подумать про безопасность немножко. Наши сервера умирают достаточно часто. И может быть так, что нам понадобиться пойти назад в историю. Может быть, у нас несколько месяцев сидит злоумышленник в нашей сети, и нам нужно провести исследование, что он делал и где он был. А если вы каждую неделю вращаете свои сервера и полностью их затираете, то вы можете потерять важные улики. Поэтому системные вызовы тоже стоит стримить с серверов. И, скорее всего, ваша служба безопасности этим занимается. Либо нужно делать какие-то снапшоты перед тем, как вы сервер убиваете. И потом эти снапшоты вы храните несколько месяцев. Это полезно.
- Если людям нужно что-то протестировать, то у вас есть образ, который такой же, как и тот. Поднимите на стороне еще одну виртуалку, например, либо еще один сервер. Пустите немножко трафика и протестируйте там. Не ходите на те машины, которые на данный момент обслуживают production.
- А если очень нужно, то ходите, а потом прибейте.

- Лучшие практики. Если вы делаете continuous integration, то ничего нового. Все зависимости сохраняйте под системой контроля версий.
- Автоматизируйте построение образов ваших виртуальных машин или серверов. Постарайтесь, чтобы люди вам их не собирали, чтобы это был повторяемый процесс, который у вас происходит на сервере.
- Автоматизируйте тестирование, т. е. пробуйте автоматически все раскатывать.
- Старайтесь промоутить вместо того, чтобы пересобирать. Эта важно. Старайтесь, чтобы это был тот же образ, просто, чтобы он был конфигурируемый между окружениями вместе того, чтобы пересобрать в каждом окружении свой. Иначе будет вероятность, что что-то пойдет не так или у вас будет тестирование отличное от условий production.
- Часто деплойте. Как можно меньшую дельту накапливайте перед тем, как раскатываете. В идеале раскатываете на каждый commit, если у вас есть такая возможность. Особенно, если у вас система построена так, что вы без потери трафика можете переключать виртуальные машины. Это требует определенной работы, но вполне достижимо. И сейчас есть много инструментов, которые могут с этим помочь. В идеале каждый commit. Потому что, если что-то пошло не так, у вас дельта – один commit, вы знаете, что пошло не так. Проблема в этом commit. Вы его откатили, вернули зеленое состояние. И человека, который сделал этот commit, есть время, чтобы разобраться и узнать, что пошло не так. На него нет давления, что он сломал что-то в CI. Т. е. просто откатили и человек спокойно разбирается.
- Плюс я рекомендую перекатывать по расписанию. У вас может быть так, что commit’ов нет. Т. е. у вас какая-то такая система, в которой не так часто происходят изменения. Поэтому я рекомендую по таймеру перекатывать, т. е. делать каждую неделю перекатку. Можно делать это в выходные, либо в понедельник с утра.

Предположим, есть задача посмотреть на практике, какие инструменты могут быть нам полезны.
HashiCorp Packer, я думаю, всем знаком. Это достаточно универсальный инструмент, который много где используется. Вы можете под облака собирать Packer’ом, можете под локальные виртуалки тоже. Есть много разных вариантов.
Если вы деплоите в cloud или вам предоставлен API, то Terraform – классный инструмент. Это дело вкуса, конечно. Может быть, вам vendor предоставляет какой-то более хороший инструмент, т. е. я не пытаюсь вам говорить, что Terraform – самый лучший инструмент в мире. PXE очень полезен для раскатки baremetal, если вам именно baremetal нужен.
У нас сейчас тоже был проект, где мы Packer’ом старались собирать образа и через PXE их раскатывать. Но не было возможности, к сожалению, довести его до конца, потому что началась пандемия и потерялась возможность попасть в то место, где сервера стоят, потому что нет возможности путешествовать.
Безопасность – Audibeat, WAZUH и другие инструменты. Vault – очень популярный инструмент. Если вы в облаке, то используйте облачные сервисы, потому что вам их не нужно будет настраивать самому.
И с debug я тоже привожу здесь какие-то инструменты, но все очень сильно зависит от вашего контекста. Это может быть Prometheus, Logstash. Если вы в облаке, то это может быть CloudWatch, Datadog.

И теперь давайте посмотрим, как у нас изменился контекст.
Ansible занимается менеджментом конфигурации. Если мы делаем immutable-инфраструктуру, то Ansible больше не нужно этим заниматься, потому что это часть построения образа. Теоретически вы можете через Packer Ansible запустить. Но важно то, что вы запекаете конфигурацию в образ. И теперь именно вот этот инструмент за это отвечает.
Server provisioning. Вы уже используете другие инструменты для накатки образа сервера. Вы не пытаетесь настраивать сервер после того, как он поднялся, потому что он уже настроен.
Приложение, скорее всего, вы доставляете как часть образа, т. е. его не надо раздавать.
СI task? Почему бы не нет, если вам очень нравится Ansible.

Поговорим про другие пути и о том, что происходит сейчас.

Понятное дело, что сервера и виртуальные машины уже потихоньку уходят в прошлое. И появляется новый контекст – это контейнеры.

До этого у нас поменялся метод, а сейчас мы смотрим, что проблема остается той же, но изменился контекст. Давайте разбираться, что будет происходить в этом контексте.

Контейнеры сами по себе immutable изначально, т. е. docker-образ, docker images он immutable. Docker container – mutable. Технически вы следуете принципам 12 factors app, когда вы строите docker container. И он (образ) будет immutable изначально. Вся ваша конфигурация туда будет приходить снаружи как переменное окружение. State вы будете монтировать снаружи, базы данных доступны по сети. Здесь у нас все хорошо. Мы используем лучшие практики, которые мы в предыдущем контексте наработали.
Есть еще одна классная штука с контейнерами. Они позволяют вам скрыть энтропию. Вы, когда уничтожаете контейнер и восстанавливаете, то все то, что вы в нем поменяли, остается в этом контейнере. Если вы его удалили, то удалили весь конфигурационный дрифт. При этом host, на котором бежит контейнер, остается намного чище. На нем почти не остается конфигурационного дрифта, если только там нет таких локальных volume.
Плюс контейнеры изначально были stateless. Изначальная идея в том, что они stateless и в том, что вы можете их выкидывать. Я на какой-то конференции слышал такую цифру, что средняя жизнь контейнера – несколько секунд, потому что очень часто используют контейнеры для того, чтобы запустить короткую задачу и потом убить. Достаточно редко контейнеры бегут долго.

Если вы используете оркестратор, то ваш контейнер часто будет переезжать между хостами, потому что что-то изменяется. У нас есть Kubernetes. У AWS есть ECS для тех, для кого Kubernetes слишком сложный. Если вы хотите соединять публичные clouds, prime clouds, hybrid clouds, то можно посмотреть в Nomad, хотя 2 дня тому назад на Reinvent Amazon сказал, что EKS и ECS теперь anywhere. Я не знаю, сколько это будет стоить. Но технически похоже, что EKS и ECS можно будет on-premises запускать и завязывать как-то с Amazon. Посмотрим, что будет.
Но Nomad – это тоже солидное решение, которое используется большим количеством компаний (Cloudflare/CircleCI/Roblox), чтобы серьезное количество нагрузок запускать.
Плюс у нас есть целая аллея мертвецов. В 2015-ом году у нас была война оркестраторов. И победителем вышел Kubernetes, потому что CNCF вкачали в него максимальное количество маркетинговых денег. У нас есть Docker Swarm, который купил в итоге Mitrantis. И который теперь намекает всем своим заказчикам, что пора бы ехать на Kubernetes. OpenShift переделал все на Kubernetes.

Плюс у нас есть не только оркестратор, но и container OS, т. е. операционные системы, которые нацелены на то, чтобы работать с контейнерами. И зачастую эти операционные системы требуют минимальные настройки. Зачастую там уже все есть. Не надо ничего доставлять после.
Плюс многие из этих систем умеют самообновляться, т. е. вы ее подняли и забыли, там ничего не нужно делать после.

Таким образом, нам нужно расширить наш контекст. Мы не можем просто сказать «контейнер», потому что это будет слишком широко. Потому что контейнеры ECS как оркестратор – это совершенное другое. Поэтому давайте остановимся пока на Kubernetes, т. е. контейнеры и Kubernetes.
Метод у нас – инфраструктура как код, чтобы взять Terraform и раскатать все, что вокруг kubernetes-кластера. Доставка в kubernetes-кластер приложений. Похоже, что community движется в сторону GitOps. У меня есть свои персональные вопросы к GitOps, но не хочу идти против течения. Как говорится, если ты не можешь остановить сумасшествие – возглавь его. И сейчас у меня происходит некий нырок в GitOps.
И еще сейчас пошел новый хайповый тренд – Infra as data, т. е. инфраструктура как дата. Это, по сути, тот же самый GitOps, только инфраструктура yaml написана, а не кодом.
Инструменты – ArgoCD, про который на этой конференции достаточно много рассказывали. Helm, которым можно темплейтить kubernetes’кие чарты и потом складывать в репозиторий. Terraform, чтобы поднимать все вокруг. Плюс есть операторы в AWS, которые позволяют Terraform запускать как часть, используя CRD в Kubernetes.
Достаточно много вопросов, как все это будет. Проблема – все та же, контекст более-менее устоялся. Методология как будто бы сейчас начинает устанавливаться. Инструменты – посмотрим, это зависит от методологии.

Если мы рассматриваем Ansible в контексте контейнеров, то менеджмент конфигурации происходит как часть build контейнера.
Server provisioning нам, в принципе, не нужен, потому что мы используем containers OS, которые настраивать не надо. Приложение приезжает само в контейнере и его притаскивает оркестратор. Зачастую наша операционная система будет все необходимое для оркестратора иметь. Нужно будет только сказать, где оркестратор и как к нему подключиться.

Не будем говорить про Serverless. Хотелось бы поговорить, но и так уже много информации. Это еще один контекст. Kubernetes – это один контекст. Serverless – это другой контекст. И в нем будут свои инструменты, свои подходы. Serverless я предлагаю пока оставить за пределами этой презентации. Может быть, у нас контекст контейнеров и Kubernetes немножко устаканится и в следующем году мы поговорим про Serverless, а сегодня пропустим.

И новый фронтир. Хотя он не совсем новый, люди это уже делают около 8 лет, но еще пока он не прошел ту точку, когда все про это говорят. Это MicroVM.
Вы, скорее всего, слышали про AWS Firecracker, который используется для запуска лямбды.
И Unikernels – это когда ваша операционная система компилится вместе с вашим приложением. И вы запускаете то, что вы построили сразу на hypervisor, если у вас есть к нему доступ.
Это что-то такое, что может быть как контекст, интересный людям, которые живут в своих дата-центрах. Потому что у вас зачастую есть доступ напрямую к hypervisor. Тем людям, которые живут в облаках, сложнее. Потому что Amazon не даст доступ напрямую к своему Nitro. Может быть, он когда-нибудь придумает свою ручку, чтобы вы смогли там свои Unikernel запускать, но до этого еще нужно дожить.
И здесь много неизвестных. Контекст, в принципе, немного устоялся, но методология совсем непонятная. Не понятно, как мы их будем доставлять, не понятно, как мы будем их оркестрировать, не понятно, как мы ими будем управлять. Очень много вопросов еще, поэтому мы эту тему упомянем, но пропустим.

Чему мы можем научиться от Kubernetes? Давайте задумаемся. Kubernetes принес достаточно интересную концепцию как reconciliation loop, т. к. когда вы ему скармливаете свои yaml, он их принимает, персистит etcd и потом пытается сделать так, чтобы было так, как описано. Он постоянно идет по кругу и проверяет – а оно так, а оно так? Например, pod убили, pod нет. И он поднимает новый, чтобы было так, как описано.
И, может быть, через 2-3-5 лет, провайдеры могут подумать: «А почему бы нам не сделать такую же штуку? Т. е. сейчас мы постоянно запускаем Terraform, по сути вещей делаем что-то близкое к синхронизации конфигурации». И очень может быть, что cloud-провайдеры приготовят что-то такое для нас. Мы будем просто отдавать YAML, cloud будет сам это настраивать для нас так, как оно должно быть. Нам не нужно будет это постоянно запускать. Cloud сможет подстраивать свои ресурсы, сможет сам бороться с конфигурационным дрифтом. Таким образом, он автоматизирует большую часть нашей работы.

Есть еще другая идея, над которой вы можете после подумать – а не идем ли мы назад? Не является ли GitOps новым Chef? Я предлагаю подумать в рамках такой метафоры: часто говорят, что Kubernetes – новый Linux. Теперь Linux – это такая платформа, поверх которой бежит Kubernetes. И Kubernetes – это наш новый user space, где мы запускаем новые приложения. И с GitOps мы, по сути, делаем синхронизацию конфигурации. Т. е. у нас ArgoCD пуллит все то, что написано в наших репозиториях и apply на Kubernetes. По сути, делает все то же самое, что делал Chef в свое время.
Такое ощущение, что мы идем назад. И, принципе, мы уже знаем, что immutable-инфраструктура – это то, что работает хорошо. Это то, что позволяет избежать конфигурационного дрифта. Это то, что позволяет увеличить безопасность. И у меня есть теория, что мы делаем этот необходимый шаг назад так же, как в свое время синхронизация конфигурации была необходимым шагом, чтобы мы могли добраться до immutable-инфраструктуры.
Мы сначала должны были пройти через синхронизацию конфигурации, чтобы добраться до immutable-инфраструктуры. Так что здесь, нам, скорее всего, тоже нужно проделать похожий путь.

История постоянно себя повторяет. И теоретически в какой-то момент мы придем к тому, что нам нужно будет придумать, как мы будем делать immutable-инфраструктуру для Kubernetes.
Может быть, пора уже убивать свои kubernetes-кластеры и полностью их пересоздавать с нуля? Хотя, в принципе, это рекомендовано. Когда Kubernetes выкатывает новую версию и если мы апгрейдим in-place, то очень часто новые security-фичи выключены, чтобы сохранить обратную совместимость. Поэтому рекомендуется свои кластера перекатывать (пересоздавать), таким образом вы убиваете весь тот мусор, который там накопился.

Мы подходим к последнему пункту о том, что будущее уже здесь и оно неравномерно распределено.

Вы можете сейчас подумать: «Как же быть? Я уже потратил столько лет, работая с Ansible. Я так его хорошо знаю. Что делать?». Очень легко принести новые инструменты в организацию, но удалить их оттуда очень сложно.
Например, я вел 10 лет назад миграции с ClearCase на Git. И в больших организациях это мероприятие занимало года полтора, потому что очень много было построено вокруг него.
Если вы хороший специалист, даже используя этот инструмент, вы всегда сможете найти работу, потому что инерция очень большая и специалистов не хватает.
Плюс выбирать какую-то новую технологию – это тяжело, это опасно. Например, в 2015-ом году все новые компании, которые стартовали, выбирали, как они будут строить свою внутреннюю платформу. Был Kubernetes, Nomad, Docker Swarm. Много всего было. И нужно было что-то выбрать. Прошло 2 года и те, кто выбрал Docker Swarm, возможно, начинают покусывать локти.
Technology bets – сложные, их приходится делать. Но если вы их не сделаете, кто-то другой за вас сделает, потому что облако уже за вами идет. Даже сегодня, если есть большое желание, вы можете работать с железными серверами, вы можете продолжать с ними работать. Для вас всегда будет работа. Так что вы сами выбираете, что вам делать.

Вот, что я хочу вам показать. Я вчера сравнил Chef, Ansible и Terraform в Google Trends. Я понимаю, что когда я сравниваю Chef, Ansible и Puppet с Terraform, то я сравниваю яблоки и груши. Я не пытаюсь показать, что один инструмент лучше другого. Я хочу показать вам картинку немного в другом контексте.
Ansible лидирует. Terraform внизу. И это показывает адопцию cloud в России. Потому что в России только сейчас появляются более-менее серьезные игроки, на которые уже можно начинать полагаться.
Плюс некоторые могут пользоваться заграничными облачными решениями. И зеленую полоску поднятия Terraform я истолковываю, как показатель адопции cloud.

Я попробовал воспользоваться Yandex keyword-статистикой, что было не самым приятным опытом. И, как вы видите, Ansible – 29 000.

Terraform – около 6 000. Цифры примерно похожие с Google Trends.

А вот, что происходит в Штатах. Посмотрите, какой прыжок у Terraform. Ansible тоже был очень популярным, но адопция cloud в Штатах началась лет 5-6 назад. В начале 2010-ых это были только самые смелые, типа Netflix. Сейчас уже большие банки там. Если вы смотрите Reinvent, то приходит человек из большого банка и начинает рассказывать о том, как им хорошо жить в облаке. И сейчас там начинает подтягиваться длинный хвост. И именно это показывает график. Я не сравниваю инструменты. Я показываю вам график именно с точки зрения адопции cloud. Я думаю, что в ближайшие 3-5 лет – это то, что мы увидим в России, даже если вы этого не хотите.

Давайте повторим о том, что мы обсудили.
Всегда нужно начинать с проблемы. Потом переходить к контексту. Из контекста понимать, какие доступны методологии. И потом выбирать подходящий инструмент.

В прошлом проблема была такой же, что и в настоящем, т. е. это автоматизация изменения в IT в контексте железных серверов и виртуальных машин.
И раньше мы использовали инфраструктуру как код и синхронизацию конфигурации.
Для этого хорошо подходили Ansible, Puppet, Chef и им подобные.

Через какое-то время мы поняли, что в этом контексте можно делать immutable-инфраструктуру. И это более подходящий инструмент, потому что он нам позволяет меньше накапливать конфигурационного дрифта и строить более динамическую инфраструктуру, а также более устойчивую. И это что-то такое, что мы рекомендуем сегодня.
А что будет завтра? Это еще нужно понять, поэтому мы пока смотрим. Но проблема остается прежней, контекст меняется. Пока мы вырабатываем методологию и смотрим, какие есть инструменты. Но это что-то такое, что будет завтра.
И, как я уже сказал, вам самим выбирать, где вы хотите быть: в прошлом, в настоящем или в будущем.

На этом у меня все. В нижнем левом углу мои контакты. И я думаю, что мы сейчас еще немножко поговорим с Максимом и обсудим ваши вопросы.
Вопросы и ответы:
Вопрос: В твоем докладе сначала было больше про инфраструктуру, а потом немного промелькнуло про установку приложения на сервер. Это достаточно два крупных блока. И вопрос от Дмитрия: «Для Ansible место где-то сохраняется?». Например, в infra или для деплоя приложений. Ты про деплой приложений упоминал. Ты говорил, что деплой приложений в Kubernetes может быть через Helm. А если облаков нет, не используется Kubernetes, для деплоя приложения Ansible – это нормальное решение или тоже проблемы будут?
Ответ: Мы про это говорили. Надо исходить из контекста. Если в нашем контексте фигурирует оркестратор контейнеров, то он будет отвечать за доставку. Т. е. чтобы приложение оказалось на сервере, за это будет отвечать оркестратор. Когда мы делаем immutable-инфраструктуру, то у нас есть выбор. То есть мы можем положить приложение в образ и доставлять именно готовый образ с приложением. Каждая новая версия приложения – это новый образ сервера или новый образ виртуалки. И мы таким образом перекатываем. Если у вас не такой возможности, то по старинке через Ansible. Это все зависит от контекста. Я не пытаюсь быть идеалистом. Исходите из того контекста, который у вас есть.
Плюс помните, что будущее наступит, хотите вы этого или нет. Возможно, у вас есть вариант остаться в этой организации и пользоваться теми инструментами, которые есть. Вы можете начать изменения в вашей организации. Если ваша организация никак не хочет меняться, то просто можете уйти из этой организации. Те организации, которые не хотят меняться, их через какое-то время уберут с рынка и вы останетесь без работы. Вам решать, куда идти. Здесь нужно думать и немножко смотреть вперед.
Вопрос: Я правильно понимаю, что для того, чтобы пойти в immutable-инфраструктуру, нужно преодолеть достаточно высокий порог входа? Т. е. эта история примерно повторяется, как было с микросервисами. Было так, что для того, чтобы пойти в микросервисы, тебе нужно было адекватно подготовить инфраструктуру, иначе ты рехнешься все это мониторить и за всем следить. И с immutable-инфраструктурой примерно та же история, потому что желательно, чтобы были облака, а также хорошо настроенный мониторинг, чтобы не было никакой необходимости ходить на сервера вручную и что-то там смотреть, а ты мог взять и порезать всем доступ. И без этого в immutable-инфраструктуру даже соваться не стоит?
Ответ: Я бы так не сказал. Хороший мониторинг тебе нужен всегда. Хороший мониторинг нужно всегда иметь, не важно, как ты инфраструктуру раскатываешь. Я могу примерно так же ответить на другие возражения. Если хочется получить максимум бенефита с минимум усилий, то можно идти по слайдам презентации, т. е. так, как это делали раньше люди. Просто убивайте свои сервера иногда. Сейчас вы Ansible запускаете на своем сервере, но когда был тот последний раз, что вы его запускали с нуля? Это хороший вопрос. И какая гарантия, что с нуля это сработает?
Т. е. если вы просто начнете перекатывать свои сервера изредка, хотя бы раз в месяц или раз в неделю, то ваш Ansible от этого улучшится, потому что вы будете раньше находить эти проблемы. И если у вас долгобегущие сервера, на которых накапливается конфигурационный дрифт, то ваш Ansible playbook начнет потихоньку подстраиваться под то, что у вас там есть, хотите ли вы этого или нет, потому что люди всегда режут углы. Поэтому не давайте людям резать углы, перекатывайте свои сервера с нуля. И таким образом вы тестируете свои playbooks всегда. Они становятся только лучше от этого.
И если вы это делаете регулярно, то в какой-то момент вы часть того, что сейчас накапливаете Ansible, т. е. то, что неизменно, можете перенести в сборку виртуалки. Т. е. вместо того, чтобы запускать vamilla виртуалку, просто запустите сначала Packer и немножко подсоберите ее. И у вас потихоньку будет уменьшаться количество конфигураций, которое вам нужно доставить. В конечном итоге вы будете доставлять самую маленькую долю динамической конфигурации, какие-то секреты.
Мы всегда советуем то, что имеет смысл в бизнес-контексте. Нет смысла в вакууме добиваться какой-то победы. Если вы уже получили 95 % бенефитов и вам нет смысла дальше это делать, потому что это будет дороже, и вы ничего не выиграете, то нет смысла этого делать. Вам нужно понять, где вы находитесь и понять, как это поможет вашему бизнесу.
Вопрос: Остается ли где-нибудь место для Ansible? В некоторых ситуациях оно, действительно, где-то остается. И при этом можно immutable-инфраструктуру создать вполне себе вменяемую.
Ответ: Да. Вы можете запускать Packer, взять свой playbook и просто в Packer запустить свой playbook, чтобы построить образ. И вот у вас есть образ со всем тем, что вам нужно. Некоторые люди еще делают золотой образ, что я не советую. Они берут сервер, делают с него снапшот. И потом настраивают его руками, делают еще один снапшот. Я не советую так делать.
Вопрос: У меня хитрый вопрос остался. Как быть с серверами баз данных? Т. е. с любой инфраструктурой, которая хранит состояния? Там бывает такая ситуация, когда ты обновляешь версию базы данных, а там какое-то мажорное обновление и в этих скриптах обновлений уже заложена конвертация данных. Например, появились транзакции в MySQL базе данных и это как-то повлияло на структуру хранения, и должны эти скрипты отработать. Как в этом случае с immutable быть?
Ответ: Ты же не будешь менять базу одновременно со схемой. Я не уверен, что понимаю вопрос.
Вопрос: Я не про пользовательские изменения. Т. е. не тогда, когда ты сам схемы меняешь. Предположим, у Mongo мажорная версия обновилась так, что у нее поменялась структура хранения данных. Например, они ввели файл и раньше они unlock хранили одним образом, а потом начали хранить другим. Такое бывает редко, но в некоторых инфраструктурах это бывает. И у них в скрипты обновлений встроены скрипты для обновления самих данных, т. е. то, как они их хранят.
Ответ: Т. е. здесь ты говоришь, что у тебя нет возможности пойти обратно? Т. е. если ты уже поднял новую Mongo, то возможности пойти обратно у тебя уже нет?
Вопрос: И ты не можешь просто убить сервер, перенести данные на новую версию Mongo, где она их подхватит. Надо, чтобы они все равно конвертнулись.
Ответ: Зачастую данный volume, на котором у тебя базы данные хранятся, не хранится на том же сервере, что и база данных, т. е. есть какое-то сетевое хранилище. А сама по себе база данных – immutable. И когда ты будешь делать апгрейд на какую-то мажорную версию, ты сделаешь бэкап своих данных и, скорее всего, будешь делать это очень аккуратно, потому что мало ли, что там пойдет не так. Я не вижу здесь большой разницы в процессе.
Мажорные релизы базы данных всегда нервные. Они всегда с большим количеством бэкапов и правильными запусками. Сначала делаешь бэкап, запустишь на стороне без трафика. Смотришь, чтобы все нормально поднялось. Потом запускаешь свои интеграционные тесты поверх этих данных. Проверяешь, что все работает так же. Потом уже начинаешь планировать миграцию.
Немного рекламы: На платформе https://rotoro.cloud/ вы можете найти курсы с практическими занятиями:
