Comments 118
'lengthMin' => [ [ 'password', '8'] ],
'lengthMin' => [ [ 'password_wrong', '8'] ],Это не сработает. Ключи массива должны быть уникальны.
Что-то примеры какие-то странные. Где-то написаны регулярки, а где-то нет. Вероятно, вынесены в отдельные валидаторы (функции, классы). Основное мясо во всех примерах занимает карта соответствия поле-валидатор. И почему же код на чистом пхп получился менее красивым? Видимо, потому что там половину места занимают сообщения об ошибках, которых нет в остальных примерах. А если вытащить валидаторы в классы, то тут уже, библиотекой запахнет. Пусть и тривиальной. Вобщем, единственное обоснование тут — готовые наборы валидаторов для типичных данных. А сама карта соответствия — пофиг.
Кстати, сами валидаторы передавать строками, пожалуй, тоже не самая красивая идея. Мне больше по душе, когда я могу в IDE в один клик попасть на код валидатора, вместо того чтобы каждый раз проходить через парсер строк.
В ларавеле так не валидируют, в ларавеле используют FormRequest-ы (хотя под капотом там, конечно, оно самое).
Yii:
class RegistrationForm
{
public $name;
public $name_wrong;
public $login;
public $login_wrong;
...
public function rules()
{
return [
[['name', 'name_wrong'], 'match', 'pattern' => '/^[A-Za-z]+\s[A-Za-z]+$/u'],
[['login', 'login_wrong'], 'match', 'pattern' => '/^[a-zA-Z0-9]-_+$/'],
[['email', 'email_wrong'], 'email'],
[['email', 'email_wrong', 'password', 'password_wrong'], 'required'],
[['password', 'password_wrong'], 'string', 'length' => [8, 64]],
[['agreed'], 'boolean'],
[['date', 'date_wrong'], 'datetime', 'format' => 'php:Y-m-d H:i:s'],
[['ipv4', 'ipv4_wrong'], 'ip', 'ipv6' => false],
[['guid', 'guid_wrong'], 'match', 'pattern' => '/^[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$/i'],
];
}
}
$form = new RegistrationForm();
$data = Yii::$app->request->post();
$form->load($data);
if ($form->validate()) {
...
} else {
$errors = $model->errors;
foreach ($errors as $field => $fieldErrors) {
echo $field . ': ' . implode("\n", $fieldErrors) . "\n";
}
}Ну в том что написано особой разницы нигде почти нет. Но рассмотрены очень базовые вещи. Не рассмотрен очень важный аспект валидации массивов данных в форме. Где придется делать цикл и валидировать каждый элемент отдельно, а где есть для этого специальные возможности. Ну и всякие условные валидации, а так же расширяемость. Вот там либы будут отличаться уже сильнее
А не надо мешать валидацию пользовательского ввода с инфраструктурной.
Бессмысленно проверять уникальность на этапе валидации пользовательского ввода: между валидацией и инсертом в базу данных (или что там у вас) вечность. Один фиг ловить какой-нибудь UniqueConstraintViolation придется (или городить транзакции и блокировки непонятно зачем).
github.com/asmgit/query2validation-exception
Но так как остальные проверки все равно нужны, то в приложении появляется зоопарк решений.
Передаем по сети, нагружаем и так нагруженную базу, заставляем ее генерировать ошибку, возвращать обратно по сети, генерируем эксепшн в приложении, ловим эксепшен в приложении, проверяем регэкспом текст ошибки, чтобы достатать и сконкатенировать значения, которые изначально и так были в приложении в удобном для обработки виде. Куча затратных операций на ровном месте. У вас одной валидацией можно DOS-атаку устроить)
Не всю. Если данные валидные, будут только первые два пункта. Можно сказать даже полтора, так как если данные невалидные, на базу будет 2 запроса, с неправильными данными и с исправленными, а в случае проверки в приложении 1.
который сложно поддерживать
['email', 'required'] — да, очень сложно поддерживать.
Причем из указанных в статье правил в базе можно проверить только половину — required, string, boolean, datetime. И это мы еще не рассматривали такой распространенный сценарий, когда при создании объекта некоторые данные могут быть пустые, а при переводе в некоторый статус должны быть заполнены.
Нет дублирования и избыточности.
Ну как же это нет, а на остальные проверки, которые база не проверяет? Получается есть 2 системы, которые валидируют данные, база и приложение, а могло бы быть только приложение. Избыточность.
И это мы еще не рассматривали такой распространенный сценарий, когда при создании объекта некоторые данные могут быть пустые, а при переводе в некоторый статус должны быть заполнены.Это не настолько распространённый сценарий.
Ну и в любом случае это легко реализуется.
ALTER TABLE organizations
ADD CONSTRAINT `organizations|type,first_name,last_name|first name and last name required for user.` CHECK (type = 'user' AND last_name IS NOT NULL AND first_name IS NOT NULL OR type != 'user');У Вас в любом случае получается 2 системы валидации, т.к. часть проверок практически нереально сделать на уровне приложения, но легко реализуются на уровне БД, та же проверка на уникальность.
Т.е. в Вашем случае:
— 80% проверок дублируется в 3х местах: в базе в виде схемы CREATE TABLE, в RULE_CREATE и в RULE_UPDATE
Остальные 20%:
— часть прописана только в апп
— часть прописана в БД: уникальность, внешние ключи и т.д., то что нереально отслеживать на уровне апп. Притом эту часть ещё, зачастую, наивно дублируют в апп.
В моём случае:
— 95% проверок реализуется на уровне схемы БД в CREATE TABLE: типы данных, уникальность, внешние ключи
Остальные 5%:
— часть декларативно CHECK CONSTRAINT в схеме БД
— часть императивно в BEFORE TRIGGER
— часть в приложении, то что база делать не умеет, например, пингануть домен мыла, что такой существует или проверить EXIF картинки.
Пример на Ларавеле:
Схема данных:
CREATE TABLE materials (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(191) NOT NULL
, organization_id_manufacturer INT UNSIGNED NOT NULL
, UNIQUE KEY (name)
, CONSTRAINT materials_organization_id_manufacturer FOREIGN KEY (organization_id_manufacturer) REFERENCES organizations (id)
);Валидейшены в апп:
$rules_create = [
'name' => 'required|max:191|unique:materials,name',
'organization_id_manufacturer' => "required|integer|exists:organizations,id",
];
...
$rules_update = [
'name' => 'required|max:191|unique:materials,name,'.$id,
'organization_id_manufacturer' => "required|integer|exists:organizations,id",
];
Валидейшены в sql:
Далее поддержка.
Мы захотели изменить длину поля name до 500 символов. В обоих случаях в БД будет миграция:
ALTER TABLE materials
MODIFY name VARCHAR(500) NOT NULLНо у меня то на этом всё и закончится, а Вам надо ещё в 2х местах эту дублированную информацию поправить, не забыть, не ошибиться.
Далее производительность.
Апп:
— SELECT 1 FROM materials WHERE name = :name
— SELECT 1 FROM organizations WHERE id = :organization_id_manufacturer
— INSERT/UPDATE materials + БД перед DML оператором ещё раз сама проверит соответствие типов данных, проверку полей на NULL, проверки на уникальность, проверки внешних ключей, если что-то не валидно, то даст отбой
Т.е. в вашем случае:
— апп выполняет проверки перед отправкой в БД
— 2 лишних SELECT'а
— 1 DML включая все проверки в БД
SQL:
— INSERT/UPDATE materials, БД сделает все проверки, в случае возникновения ошибки, передаём управление апп для интерпретации
т.к. часть проверок практически нереально сделать на уровне приложения, но легко реализуются на уровне БД, та же проверка на уникальность
Это не валидация введенных данных, это уже проверки, связанные с бизнес-логикой. Валидация данных это то, что можно проверить имея только сами данные, без запроса каких-то других данных.
Они не "легко реализуются на уровне БД", а реализуются на уровне БД потому что бизнес-логика хранит эти данные в БД. Если она их будет в другом хранилище хранить, БД тут никак не поможет, независимо от того, насколько легко они там реализуются.
Т.е. в Вашем случае:
— 80% проверок дублируется в 3х местах: в базе в виде схемы CREATE TABLE, в RULE_CREATE и в RULE_UPDATE
Что такое RULE_CREATE и RULE_UPDATE? У меня ничего такого нет. Есть список полей для бизнес-действия и правила проверки данных в этих полях. Правила проверки привязаны к бизнес-действию, а не к сущности.
80% проверок как раз имеются только в приложении. Формат телефона или то, что логин должен состоять из букв, база не проверяет. В приведенном примере 50% проверок нет в базе, и это самые сложные проверки.
Остальные 20%
часть прописана в БД: уникальность, внешние ключи
Это часть модели данных, они и должны быть там прописаны.
В моём случае:
часть в приложении, то что база делать не умеет
Вот я и говорю, у вас есть 2 механизма проверки вместо одного, и оба надо поддерживать.
Кстати, как у вас задать текст сообщения об ошибке? А никак, база этого делать не умеет. Таким образом, для всех правил валидации нужен какой-то код в приложении. Особенно если надо сделать перевод на разные языки.
У Вас в любом случае получается 2 системы валидации,
В моем случае правила валидации надо поддерживать только в одной системе. В базе меняется только схема данных.
Далее поддержка.
Мы захотели изменить длину поля name до 500 символов. В обоих случаях в БД будет миграция:
Да, а теперь покажите изменения для случая, когда решили задать еще и минимальную длину? В приложении добавится только min:2, а что у вас? ALTER TABLE и новый CONSTRAINT. Логически изменений мало, а у вас много.
А потом решили, что 2 это мало, пусть будет 3, что у вас будет? Опять миграция с ALTER TABLE, причем надо копипастить весь CONSTRAINT. А в приложении только 1 символ поменять.
Вот это и есть поддержка.
Т.е. в вашем случае:
апп выполняет проверки перед отправкой в БД
И это снижает нагрузку на БД. В этом и есть цель. БД одна, а процессов приложения много.
1 DML включая все проверки в БД
Нет, в вашем случае в БД есть куча CONSTRAINT-ов, а в моем их там нет. Поэтому дублируются только самые простые проверки, поэтому и особой нагрузки от них нет.
SQL:
INSERT/UPDATE materials, БД сделает все проверки, в случае возникновения ошибки, передаём управление апп для интерпретации
Да, это и создает лишнюю нагрузку, и на базу и на приложение. Пользователь просто ошибся при вводе, а у вас все системы вовлечены в обработку этой ситуации. Даже автоинкремент увеличится и запишется на диск.
Это не валидация введенных данных, это уже проверки, связанные с бизнес-логикой. Валидация данных это то, что можно проверить имея только сами данные, без запроса каких-то других данных.Именно поэтому и возникает этот оверхэд, в подавляющем большинстве случаев введённые данные необходимо сохранить. Исключительные случаи когда их сохранять не надо, например, password_confirm. А т.к. данные всё равно сохранять, то самое простое их проверить в БД.
А Вы т.е. не делайте проверку на уникальность в приложении? Просто в Ларавеле это прописано на уровне документации, что надо делать именно так. А как Вы это делайте? Как потом ошибки обрабатываете? Пример скиньте.
Про мин длину, да напишу алтер, а потом ещё раз, зато данные в БД будут валидные, в Вашем случае, данные будут не консистентны.
Нагрузка в моём случае не лишняя, а необходимая для консистентности данных. В Вашем случае нагрузка сначала на апп + селекты для проверки уникальности и ключей, потом доп нагрузка на БД, т.к. БД всё равно валидирует типы, нулы.
т.к. БД всё равно валидирует типы, нулы
Да, но она не генерирует ошибку, не отправляет ее в приложение, а приложение не создает исключения, так как данные валидны. А главное, это делается только 1 раз, а не 2 или более, как в вашем случае при неправильном вводе пользователя.
А Вы т.е. не делайте проверку на уникальность в приложении? Просто в Ларавеле это прописано на уровне документации, что надо делать именно так.
Если надо делать, то так и делаю. Только вот какое дело. Если меня устраивает проверка базой и генерация исключения, как в вашем случае, то я так делать и не буду. База сама проверит и выкинет ошибку. А если не устраивает, то я делаю SELECT потому что не устраивает, не соответствует требованиям, а не потому что по-другому нельзя.
В любом случае SELECT по уникальному полю создает нагрузку меньше, чем INSERT. Если пользователь 3 раза отправляет неправильные данные, будет 3 SELECT-а, а у вас 3 неуспешных INSERT-а.
зато данные в БД будут валидные, в Вашем случае, данные будут не консистентны
Какой вы шустрый однако) Вот так вот взяли и поменяли исторические бизнес-данные, которые участвуют во всех документах. Можно еще удалить то что нельзя исправить, а что, у нас же правило валидации. Подумаешь, у бизнеса отчет за прошлый год не сходится, и названия позиций поменялись.
Если нужно исправить предыдущие данные, пишется отдельная процедура исправления, согласованная со всеми заинтересованными.
Т.е. при валидной работе у вас двойная нагрузка на БД (это если только 1 поле уникальное, даже без проверки ключей), при невалидных данных одинарная.
Я как раз не менял исторические данные, я всего лишь констрейнт накинул, а Вы по сути сломали схему данных. Т.е. в валидейшене написали что мин длина стала 3, хотя данные этому не соответствуют, а дальше на основе этого валидейшна, другой программист может начать писать какие-то отчёты и всё поплывёт.
Притом 50 инсертов с вываленной ошибкой уникальности для БДшки проще чем 50 селектов на проверку уникальности.
Нет. Я не знаю, почему вы так решили, но запись сложнее чтения по уникальному полю, а генерация ошибки выполнения сложнее простого if перед выполнением. Я же говорю, у вас как минимум автоинкремент изменится и запишется на диск, даже при ошибке.
Причем в случае валидных данных у нас никаких данных эти селекты не вернут. Поэтому вполне может оказаться, что 1000 лишних пустых селектов занимает время, сравнимое с 50 ошибочных инсертов. То есть может и больше, но незначительно. Но это опять же надо проверять на практике.
Я как раз не менял исторические данные, я всего лишь констрейнт накинул.
У вас в таблице были данные длиной 2. Мы сделали правило, что минимальная длина должна быть 3. Что с вашими данными произойдет? Если ничего, то я тоже просто констрейнт накинул, никаких отличий от проверки в приложении нет.
Если вам их надо предварительно поменять, чтобы они соответствовали ограничению, то это как раз то, о чем я говорю.
а Вы по сути сломали схему данных
Нет, я вам как раз и объясняю, что до момента X данные длиной 2 валидные, то есть соответствуют схеме на момент их внесения, и менять просто так по своему желанию их нельзя. Мы не сломали схему данных, она изменилась в соответствии с новыми требованиями. Новые данные должны ей соответствовать, а должны ли соответствовать старые, это вопрос, который требует отдельного обсуждения.
У Вас в какой-то момент времени схема данных просто поменялась, а данные им перестали соответствовать
У Вас в какой-то момент времени схема данных просто поменялась, а данные им перестали соответствовать
Еще раз, у нас договор назывался "№2". Он должен продолжать называться "№2" независимо от того, какие правила мы решили сделать для новых договоров.
Да, только они не должны применяться к данным, которые были созданы когда этих правил еще не было и не предвиделось. Это как если цена на товар изменилась, цена в оплаченных заказах меняться не должна. Тут то же самое.
В том и проблема, математика и теория баз данных вместе с ней не рассматривают создание и изменение объектов. У нас они как бы есть, и мы их моделируем. Развитие системы не рассматривается.
Кто меняется, данные? Так они и у вас меняются. И правила меняются.
Не, обычно да, когда появляются новые правила, решают что делать со старыми данными и меняют их соответственно. Но это делается после обсуждения и при необходимости делается специальная процедура, а не просто сделали ALTER TABLE и оно само там чего-то поменяло. Я этот пример привел к тому, что вы представили это как преимущество базы, а это не так. А с процедурой изменения данных данные будут консистентны в обоих случаях.
Вы почему-то игнорируете то, что я пишу. Оно не преимущество потому что при применении меняет существующие данные по своему усмотрению.
CREATE TABLE test (name VARCHAR(8)) ENGINE=INNODB;
INSERT INTO test (`name`) VALUES ('12345678');
ALTER TABLE test CHANGE name name VARCHAR(4);оно не меняет, а валидирует и при ошибке, уходит в ошибку
Тогда это противопоставление неверно:
"зато данные в БД будут валидные, в Вашем случае, данные будут не консистентны"
Я-то из него исходил. Если оно просто выдает ошибку, то согласен, я неправильно написал, но ваши аргументы все равно неверны. В вашем случае и данные будут невалидные, и новые правила нельзя задать, пока старые данные им не соответствуют.
Мой вариант отличается только тем, что новые правила можно задать, не меняя старые данные, если нас это устраивает.
Вы презентуете в качестве лучшего варианта, то что ломает данные
Как оно может ломать данные, если данные не меняются?)
я говорю, что Ваш вариант плох этим, Вы всё равно настаиваете
Что плохого в том, что 2 года назад название договора могло быть 2 символа, и мы хотим эту информацию сохранить? Зачем надо переименовывать старые договора, чтобы задать ограничение на новые договора? Это вообще звучит как нонсенс.
Т.е. другой программист будет смотреть на такую схему валидации и ошибочно предполагать что все данные 3 символа и будет абсолютно прав.
А если валидировать в БД, то возможны следующие варианты:
1. если с данныим всё хорошо, то так:
ALTER TABLE documents
ADD CONSTRAINT doc_num_min_length CHECK (CHAR_LENGTH(doc_num) >= 3)
2. если с данныим не всё хорошо, то UPDATE старых данных + п.1
3. если с данныим не всё хорошо и нас это устраивает:
ALTER TABLE documents
ADD CONSTRAINT doc_num_min_length CHECK (created_at < '2020-10-04' OR created_at >= '2020-10-04' AND CHAR_LENGTH(doc_num) >= 3)
Видите насколько хорош 3й пункт, информация о том, что у нас есть данные которые не соответствуют новым требованиям фиксируется прямо в схеме данных! На основе этого другой программист может принять правильные решения.
А Вы представляете быструю и лёгкую возможность выстрелить себе в ногу на php как преимущество.
Но информация у Вас потерялась, когда договоры были из 2х символов, а когда стали 3 и даже информации нет что они когда-то были 2.
Никуда она не потерялась. Можно либо в системе контроля версий посмотреть, либо вообще в самом правиле написать "до такой-то даты создания разрешенная длина 2 символа, после такой-то 3".
Т.е. другой программист будет смотреть на такую схему валидации и ошибочно предполагать что все данные 3 символа и будет абсолютно прав.
Нет. Если он так делает, значит это плохой программист. Если это почему-то важно для алгоритма, который он пишет, он должен взять и проверить, все ли данные соответствуют нужным критериям. Независимо от того, заданы эти критерии в валидации или нет.
А если валидировать в БД, то возможны следующие варианты
Ага, и в приложении возможны точно такие же варианты.
Видите насколько хорош 3й пункт, информация о том, что у нас есть данные которые не соответствуют новым требованиям фиксируется прямо в схеме данных!
Да-да, и 3й пункт тоже можно написать в приложении, если требуется.
А вот то, что вы путаете схему данных и бизнес-логику и смешиваете их в коде, это неправильно.
А Вы представляете быструю и лёгкую возможность выстрелить себе в ногу на php как преимущество.
Нет, я представляю гибкость как преимущество.
Давайте еще раз конкретно, в чем заключается "выстрел в ногу"?
— программист №1 меняет правила валидации: мин длина стала 3 символа вместо 2х
— программист №2 смотрит на схему валидации и пишет новый код с учётом того что длина номера мин 3 символа
А если он смотрит на форму входа по email, где email обязательный, то пишет код с учетом что все email заполнены, а входа по логину, телефону или соцсетям нет. Так получается? Ну так это плохой программист тогда.
Правила валидации должны быть привязаны к бизнес-действиям, а не к сущностям.
CONSTRAINT email_phone_required CHECK (email IS NOT NULL OR phone IS NOT NULL)
и тогда всё становится на свои места
А мы говорим про правила валидации вводимых пользователем данных, а не про схему их хранения. Как кстати в вашем подходе сделать email required при логине? А никак, надо писать специальный код. А с валидацией в приложении валидация любых полей задается универсальным способом. Это к слову о простоте поддержки.
до такой-то даты создания разрешенная длина 2 символа, после такой-то 3
Программирование в комментариях. Браво!
Если он так делает, значит это плохой программист.
Он хороший программист. Если я вижу колонку id INT — я знаю что тут лежат числа и строки никогда я не получу из этой колонки. Или Вы предлагаете ещё дополнительно проверять что строк нет в INT'овом поле?
он должен взять и проверить, все ли данные соответствуют нужным критериям. Независимо от того, заданы эти критерии в валидации или нет.
Накой чёрт тогда мне такая валидация которая не гарантирует что данные будут соответствовать этой валидации? Выкинуть смело на помойку.
Ну и по Вашей же логике, не только программист должен проверять что данные корректны, а везде в коде где только они используются, надо в момент извлечения проверять что они соответствуют.
Кстати, программист зачастую и не имеет доступа к продовским данным, он проверить на 100% ничего не сможет.
Ага, и в приложении возможны точно такие же варианты.
Только приложение ничего не гарантирует. А БДшка даёт некоторые гарантии.
А вот то, что вы путаете схему данных и бизнес-логику и смешиваете их в коде, это неправильно.
Я как раз ничего не путаю.
Нет, я представляю гибкость как преимущество.
Это не гибкость, а легчайшая возможность стрелять себе в ноги.
Программирование в комментариях. Браво!
Там нет ни слова про комментарии.
Вы писали:
ADD CONSTRAINT doc_num_min_length CHECK (created_at < '2020-10-04' OR created_at >= '2020-10-04' AND CHAR_LENGTH(doc_num) >= 3)Как бы вы объяснили на русском языке логику его работы? Вот моя фраза в кавычках это она и есть. И относится она тоже к коду, а не к комментариям.
Если я вижу колонку id INT — я знаю что тут лежат числа.
А если вы видите в какой-то форме ввода email required, то знаете, что в БД оно NOT NULL и заполнено во всех строках?
Накой чёрт тогда мне такая валидация которая не гарантирует что данные будут соответствовать этой валидации?
Потому что валидация должна быть привязана в к бизнес-действиям, а не к данным. В одном бизнес-действии такие данные валидные, в другом нет. Как email required в форме входа. Или дата в формате DD-MM-YYYY.
Только приложение ничего не гарантирует.
Гарантирует. Вводим данные длиной 2, получаем ошибку, что длина должна быть 3. Значит новые данные неправильной длины введены быть не могут. Это и есть гарантия, которую должны обеспечивать правила валидации ввода пользователя.
Если нам надо проверить валидацию заполненности мыла в форме ввода, то конечно мы это сделаем валидацией на уровне приложения. А вот если мы хотим проверить заполненность мыла в форме регистрации, то тут проверку можно не писать, а воспользоваться моей либой, которая выдаст ошибку валидации в формате Ларавеля. Валидация в любом случае делается в 2х местах, т.к. некоторые вещи можно сделать только на БД (уникальность, ключи и т.д.), а некоторые проще в приложении. Только в моём случае нет дублирования валидаций.
Гарантирует. Вводим данные длиной 2, получаем ошибку, что длина должна быть 3. Значит новые данные неправильной длины введены быть не могут. Это и есть гарантия, которую должны обеспечивать правила валидации ввода пользователя.
Это и называется выстрелить себе в ногу. Т.к. валидацией пользовательского ввода подменяют понятие валидации данных
Вы читали начало ветки?
Если нам надо проверить валидацию заполненности мыла в форме ввода, то конечно мы это сделаем валидацией на уровне приложения.
Вот в начале ветки я как раз и написал, что это зоопарк, который надо поддерживать. Какие-то правила там задавать, какие-то здесь.
А вот если мы хотим проверить заполненность мыла в форме регистрации, то тут проверку можно не писать, а воспользоваться моей либой
А вот если в форме входа есть возможность войти через логин или номер телефона, то и в регистрации заполненность мыла тоже проверяется только в одном из сценариев — с регистрацией по email, а с регистрацией через соцсети email не нужен.
Т.к. валидацией пользовательского ввода подменяют понятие валидации данных
Никто его не подменяет. У нас бизнес-задача такая, валидировать ввод пользователя. Даже если мы его никуда не сохраняем. Ее надо не подменять, а решать. Это вы как раз пытаетесь отождествить валидацию введенных данных с их хранением.
Кстати про персистентность, это мы еще про юнит-тесты не говорили. В приложении их можно хоть в 1000 потоков запустить, а вот насколько быстро база будет с такой нагрузкой справляться, это вопрос. А это тоже сложность поддержки.
github.com/michael-vostrikov/stocks/blob/master/app/migrations/m200909_221603_init.php
Сколько лишних строк кода Вы напишите для валидации вот этих данных?
Насчёт юнит тестов, Вам религия не позволяет несколько инстансов БДшки развернуть для прогона юнит тестов? Только я так и не понял какие опять юнит тесты взялись, вроде речь совсем о другом… Лучше примеры приводите, а не абстрактные вещи.
Сколько лишних строк кода Вы напишите для валидации вот этих данных?
Лишних — нисколько. Все строки кода для валидации в приложении достигают некоторой цели, которую в БД не достичь или достичь, но это будет сложнее в поддержке.
Вам религия не позволяет несколько инстансов БДшки развернуть для прогона юнит тестов?
Время их работы не позволяет. И лишняя сложность их поддержки.
Только я так и не понял какие опять юнит тесты взялись, вроде речь совсем о другом…
Речь о написании логики, в данном случае логики проверки введенных данных. Которую надо тестировать. Писать заведомо нетестируемый или сложно тестируемый код выглядит нелогично.
Все строки кода для валидации в приложении достигают некоторой цели, которую в БД не достичь или достичь, но это будет сложнее в поддержке.
Вот и я про то же! А у меня будет в 7 раз меньше кода (мб даже больше чем в 7 раз, не догадываюсь как пишется проверка уникальности в Yii), выполнять ту же самую задачу. Самый лучший код это ненаписанный код. + Вам ещё надо будет синхронизировать Ваш дублированный код, не забывать его менять в случае миграций. Принципы кисс и драй рулят.
1. Убедиться, что валидация не менялась по гиту
2. Убедиться, что данные не были вставлены до валидации
3. Убедиться, данные не были вставлены в обход валидации
4. Запросить данные с прода и убедиться что они соответствуют заявленным схемам валидации
Нет, он просто должен учитывать, что если в форме email required, то совсем необязательно он required в БД.
О а ещё Ваш код, как Вы сами сказали, не гарантирует прошлые данные
Гарантировать прошлые данные должен прошлый код. Почему прошлые данные должны удовлетворять будущим ограничениям?
Нет, он просто должен учитывать, что если в форме email required, то совсем необязательно он required в БД.
Я же писал выше, что совсем не против валидации пользовательского ввода, я против дублирования в приложении, если эта валидация и так есть в БД.
Не будущим, а текущим. Валидация в апп не гарантирует консистентность текущих данных, это очень сильно усложняет разработку, я Вам выше привёл пример того, что должен сделать разработчик.
Не будущим, а текущим
Будущим по отношению к дате внесения данных.
я Вам выше привёл пример того, что должен сделать разработчик
Ну так вы неправильный пример привели. Он не должен этого делать. Не должен убеждаться, что данные не были вставлены в обход валидации и т.д. С логикой в приложении все данные вносятся только через приложение, руками в базу никто не лазит. Все что он должен делать — не ориентироваться на правила, заданные в конкретной форме ввода. Потому что в других формах правила могут быть другие.
А у меня будет в 7 раз меньше кода выполнять ту же самую задачу.
Задача — прогонять тесты всех правил валидации, чем быстрее тем лучше. Приложение это сделает и быстрее, и с меньшим количеством кода и действий программистов и сисадминов.
не забывать его менять в случае миграций
Миграций в моем подходе будет в разы меньше, чем у вас. Потому что не надо будет создавать миграции на изменение валидации минимальной длины или формата email. А изменения типов полей происходят крайне редко.
Задача — прогонять тесты всех правил валидации, чем быстрее тем лучше. Приложение это сделает и быстрее, и с меньшим количеством кода и действий программистов и сисадминов.
Конечно у меня будет быстрее. Хоть Вы мне так и не ответили сколько у Вас будет правил валидации в апп из примера выше. Вот смотрите, я сделал экспертную оценку и предположил что их будет 14 или 15. Прогон тестов валидации займёт какое-то время. А у меня 0 валидаций в апп, прогон этих тестов займёт нулевое время. Что в бесконечное число раз быстрее Ваших тестов. Опять же повторюсь: лучший код это тот код который отсутствует.
С Миграциями та же история, с чего вы взяли что из будет в разы больше… в разы это значит от 2 до 19, если бы предполагалось до 20, то Вы бы наверное сказали в десятки раз… Попробуйте придумать пример из жизни где кода миграций будет хотя бы в 2 раза больше чем у Вас. Если вернуться опять к тому же примеру… ну я бы ещё 2 чека дополнительных написал...., т.е. к 50 строкам + 2 — 4%. 4% никак не в разы… однако у Вас кода валидации в 7 раз больше… вот это действительно в разы! + этот код можно назвать мусорным, т.к. он ничего не гарантирует
А у меня 0 валидаций в апп
Причем тут сколько у вас в апп, мы говорим о тестировании того, корректна ли логика валидации. Если у вас логика валидации в базе, значит и проверять надо в базе. Поэтому никакой бесконечности у вас нет. 100 INSERT-ов будут выполняться гораздо дольше 100 вызовов чистых функций.
С Миграциями та же история, с чего вы взяли что из будет в разы больше… в разы это значит от 2 до 19
Все регэкспы из статьи у меня будут в приложении, а у вас в базе. В моем варианте на них не надо создавать миграции, в вашем надо. Правил с регекспами половина от всех, это как раз и получается 2 раза. А если мы их каждое еще и скорректируем в дальнейшем, у вас снова будет столько же миграций, а в приложении 0. Уже в 4 раза получается.
+ этот код можно назвать мусорным, т.к. он ничего не гарантирует
Он не гарантирует то, что вы от него ожидаете. Но он и не должен, он пишется для валидации ввода.
А у меня будет в 7 раз меньше кода выполнять ту же самую задачу.
А, вот кстати более практическая задача, чем юнит-тесты. Подсветка сразу всех ошибок. Такой UX сейчас используется почти везде, а значит валидация в базе почти везде не подходит, так как эту задачу она не решает.
Если у вас логика валидации в базе, значит и проверять надо в базе.
Если я пишу email VARCHAR(100) NOT NULL, то я на 99,999% уверен что поле будет заполнено, а длина не превысит 100 символов. Юнит тесты за меня пишет и прокатывает аутсорсная комманда — Разработчики MySQL. Разработчики MySQL компетентные и грамотные люди, на их опыт можно положиться, как и на их продукт, он хорошо документирован, протестирован, высокопроизводителен, в отличие от Ваших велосипедов. Не занимайтесь велосипедостроительством, а лучше изучайте документацию инструментов, которые Вы используйте и используйте их на 70-100%, а не на 5-10%
Следуйте правилу:
If the database does something, odds are that it does it better, faster and cheaper, that you could do it yourself
Правил с регекспами половина от всех, это как раз и получается 2 раза. А если мы их каждое еще и скорректируем в дальнейшем, у вас снова будет столько же миграций, а в приложении 0. Уже в 4 раза получается.
У Вас с математикой плохо? Из 14-15 Ваших предполагаемых правил, ни одного с регэкспом. Эксперт из Вас не оч.
Он не гарантирует то, что вы от него ожидаете. Но он и не должен, он пишется для валидации ввода.
Если этот код ничего не гарантирует, требует на порядки больше усилий в разработке требует больше сотрудников, требует тестирования, требует самого кода в 14 раз больше, то от такого кода сам бог велел избавиться и забыть о нём как о страшном сне. Аминь )))
Подсветка сразу всех ошибок. Такой UX сейчас используется почти везде, а значит валидация в базе почти везде не подходит, так как эту задачу она не решает.
Этот недостаток зафиксирован в документации
github.com/asmgit/query2validation-exception#what-are-the-disadvantages-of-query2validationexception-solution
Но проблема в том, что Вы смешиваете бекэнд валидацию данных и UX валидацию.
UX валидацию прекрасно реализуется если на фронт передать SHOW CREATE TABLE, 98% кейсов мы обработаем, остальные вернуться из БД в пост обработке, это не будет проблемой.
Тем более Вы лукавите и валидейшены введённых данных пользователя не обеспечивают 100% инфы, часть без отправки в БД, не обработать, Вы почему-то это всегда упускаете
Если я пишу email VARCHAR(100) NOT NULL, то я на 99,999% уверен что поле будет заполнено, а длина не превысит 100 символов. Юнит тесты за меня пишет и прокатывает аутсорсная комманда — Разработчики MySQL.
Ха, так тогда и я на 100% уверен, что preg_match() в приложении сработает. Тогда и с логикой в приложении таких тестов будет запущено 0.
Если серьезно, вы не понимаете, зачем нужны тесты. Что если вы напишете email VARCHAR(100) CONSTRAINT CHECK(checkEmailFormat(email) = 1), а в очередной миграции поменяется checkEmailFormat()? Что если вы напишете DROP CONSTRAINT и перепутаете имя таблицы в миграции? Что если кто-то удалит этот CONSTRAINT по задаче, а где-то останется код, который рассчитывает, что невалидный email точно не будет вставлен в базу? Тесты нужны, чтобы запускать их после всех этих изменений. Не когда вы CONSTRAINT меняете, а когда вы меняете другой код, который с ним связан, а вы это не заметили. Встречали ситуацию, когда поменяли в одном месте, а сломалось в другом? Вот тесты для того и нужны, чтобы это предотвращать, они проверяют ожидаемое поведение.
Не занимайтесь велосипедостроительством, а лучше изучайте документацию инструментов
Изучайте общепринятые практики написания программного обеспечения.
— Все регэкспы из статьи у меня будут в приложении, а у вас в базе. Правил с регекспами половина от всех,
— У Вас с математикой плохо? Из 14-15 Ваших предполагаемых правил, ни одного с регэкспом.
Специально для вас:
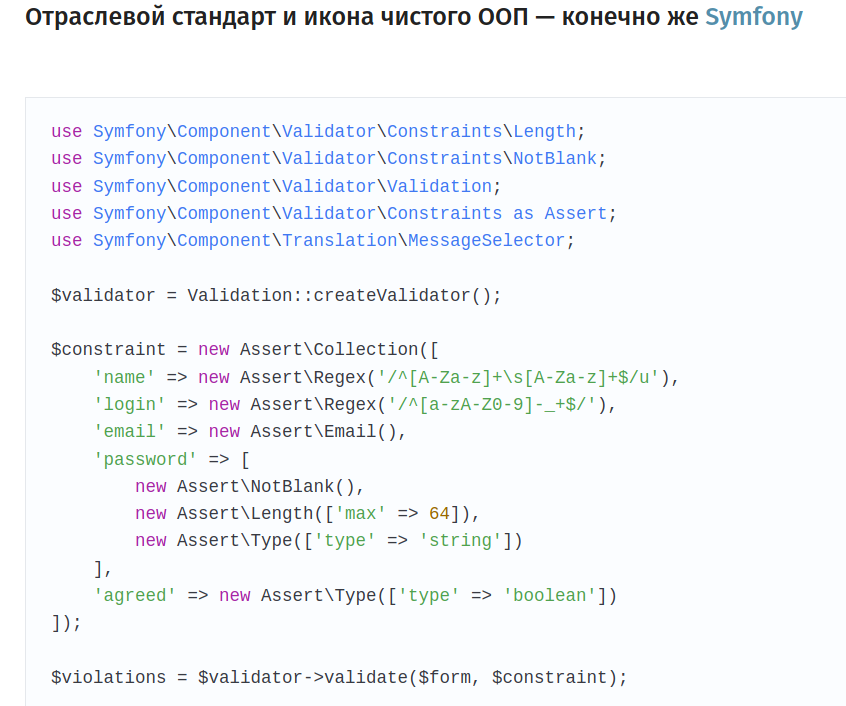
Вот там где Assert\Regex — это регэкспы.
Он не гарантирует то, что вы от него ожидаете.
Если этот код ничего не гарантирует
Подмена понятий. "Не то, что вы ожидаете" не означает "ничего". Поэтому ваша логика неверна.
Этот недостаток зафиксирован в документации
Ну и что с того, что зафиксирован? Бизнесу нужно подсвечивать все ошибки. Поэтому ваше решение неприменимо независимо от того, насколько оно быстрое и компактное.
Я вот кстати проверил производительность, с приложением получается 58 запросов в секунду, с базой 66. Разница 14%, при том что приложение гораздо проще в поддержке и тестировании.
требует на порядки больше усилий в разработке, требует больше сотрудников, требует тестирования, требует самого кода в 14 раз больше
В коде:
['email', 'email'], ['email', 'required']
В базe:
`email` ... NOT NULL CONSTRAINT CHECK (`email` REGEXP '^[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+(?:\\.[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+)*@(?:[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?\\.)+[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?$'))Где больше?)
"больше усилий" — не требует. 2 строчки кода, 4 слова. При этом подсвечиваются все ошибки сразу. Сколько усилий вам надо, чтобы подсвечивать все ошибки сразу?
"больше сотрудников" — не требует. Вам нужны и разработчики БД и разработчики кода. Мне только разработчики кода. А сколько из них вам понадобится, чтобы подсвечивать все ошибки сразу?
"требует тестирования" — требует тестирования бизнес-логика проекта. Если вы ее не тестируете, это недостаток вашего подхода, а не преимущество.
Итого, ваши утверждения неверные. Нет, я понимаю, что вам хочется быть правым, но от того, что вы что-то повторяете по 10 раз, оно не станет верным.
UX валидацию прекрасно реализуется если на фронт передать SHOW CREATE TABLE
Ага, ну прямо лучшие практики безопасности и производительности. Мы не только при валидации базу дергаем, а еще и при показе формы, и пользователю показываем "смотри как у нас база устроена".
А вот правила валидации на бэкенде можно без проблем сериализовать в JSON и передать на фронтенд.
часть без отправки в БД, не обработать, Вы почему-то это всегда упускаете
Не упускаю, я сразу про это сказал — "реализуются на уровне БД потому что бизнес-логика хранит эти данные в БД", "Это часть модели данных, они и должны быть там прописаны".
Из примера выше ни одного поля с регэкспом нет.
Какой пример вы имеете в виду? Я говорю про код в моем комментарии, а проверки там взяты из статьи, из примера на чистом PHP. Там половина проверок — это регэкспы.
у меня получилась производительность в БД для регэкспа — ~860к строк в секунду, для
CHECK (credit_type IN (-1, 0, 1)
~2130к
комп домашний древний i5
Вот скрипты если интересно:
SET @@cte_max_recursion_depth = 99999999
;
DROP TABLE IF EXISTS test
;
CREATE TABLE test (
email VARCHAR(5) NOT NULL CONSTRAINT email_chk CHECK (`email` REGEXP '^[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+(?:\\.[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+)*@(?:[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?\\.)+[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?$')
-- credit_type tinyint NOT NULL CONSTRAINT credit_type_chk CHECK (credit_type IN (-1, 0, 1))
) ENGINE = MEMORY
;
INSERT test
WITH RECURSIVE p(n) AS (
SELECT 1 n
UNION ALL
SELECT n + 1 n FROM p WHERE n + 1 <= 1000000
)
SELECT 'a@b.c'
FROM p
;
DROP TABLE IF EXISTS test
;
Вставка email без валидации 385мс, с валидацией — 1164мс, вставка credit_type без валидации 339мс, с валидацией — 469мс
Кстати, а зачем в схеме БД Вы объявляете поля NOT NULL? У Вас же валидаторы это проверяют! Выкиньте этот лишний код из миграций, будьте последовательными. Например, если понадобится сделать уже имеющееся поле NOT NULL, то в валидаторе Вам просто надо добавить слово required, а в БД ещё придётся миграцию писать, лишняя работа.
+ на порядки сложнее в поддержке и разработке
Вы все-таки думаете, если что-то повторять несколько раз, то оно станет правдой?) Вы про порядки уже ошиблись в комментариях к другой статье, а теперь снова необоснованные утверждения делаете.
если у Вас апп делает всего 58 инсертов в секунду
Вот скрипты если интересно:
INSERT test WITH RECURSIVE p(n)
Вас не смущает, что у меня и база делает 66 ?)
Пользователи не выполняют рекурсивные CTE запросы внутри базы со вставкой миллиона строк. Я конечно же считал со всей сопутствующей обработкой — составили запрос, отправили из приложения в базу, поймали исключение в случае ошибки, достали из него название поля. Все как вы и предлагаете.
Вот код:
https://github.com/michael-vostrikov/stocks/tree/validation
Запуск:
php yii migrate/up
php yii validation-performance-test/run-app
php yii validation-performance-test/run-db
php yii validation-performance-test/run-pure-calls 1000у меня получилась производительность в БД для регэкспа — ~860к строк в секунду
Если делать проверку одного и того же значения одним и тем же регекспом, в приложении и за миллион таких проверок будет. А уж если в несколько потоков запустить…
У вас конечно инсерты делаются, только они делаются исключительно внутри базы, база видит весь запрос и может его оптимизировать. Имитируйте реальную работу пользователей.
Кстати, а зачем в схеме БД Вы объявляете поля NOT NULL? У Вас же валидаторы это проверяют!
Я уже несколько раз написал — потому что схема хранения данных и валидация введенных данных это не одно и то же. И не все NOT NULL поля вводятся пользователем.
Какой пример вы имеете в виду?
github.com/michael-vostrikov/stocks/blob/master/app/migrations/m200909_221603_init.php
Вы удалили что ли только что коммит… жалко
Коммит появился…
Вас не смущает, что у меня и база делает 66 ?)
Пользователи не выполняют рекурсивные CTE запросы внутри базы со вставкой миллиона строк. Я конечно же считал со всей сопутствующей обработкой — составили запрос, отправили из приложения в базу, поймали исключение в случае ошибки, достали из него название поля. Все как вы и предлагаете.
Всё равно очень мало… ща попробую на Ноде сваять
я против дублирования валидации в апп, если такая валидация всё-равно есть в БД
В БД нет валидации, которая подсвечивает все поля сразу. В БД нет валидации регэкспами. В БД нет даже проверки на пустую строку, только на NULL. Из чего следует, что нужно поддерживать 2 механизма валидации — в приложении и в базе (именно поддерживать, а не просто иметь в наличии). Вы убрали дублирование нескольких незначительных правил, зато сделали дублирование функциональности и усложнили реализацию бизнес-требований.
и я объяснил преимущества
требует меньше кода, более проста в поддержке
Ну давайте я повторю еще раз вопрос, который вы проигнорировали.
В коде:
['email', 'email'], ['email', 'required']В базe:
`email` ... NOT NULL CONSTRAINT CHECK (`email` REGEXP '^[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+(?:\\.[a-zA-Z0-9!#$%&\'*+\\/=?^_`{|}~-]+)*@(?:[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?\\.)+[a-zA-Z0-9](?:[a-zA-Z0-9-]*[a-zA-Z0-9])?$'))Где больше? А где проще в поддержке? То, которое в коде, поддерживать вообще не надо, его поддерживают разработчики фреймворка.
Усложнение реализации бизнес-требований, весь этот парсинг CREATE TABLE и передача на фронтенд, это тоже не проще в поддержке. А если мы разрабатываем API для использования сторонними системами, и фронтенда никакого нет? Видите, с вашим подходом постоянно всплывают какие-то ограничения.
m200909_221603_init.php
Это не валидация, а схема данных. Если некоторое поле типа INT заполняется приложением, для него вообще валидация пользовательского ввода не нужна, там и так будет INT. Эти проверки нужны для гарантии того, что приложение пишет правильно, даже если пользовательского ввода тут вообще нет. Если пришли неправильные данные, то генерируется ошибка с записью в лог и уходит оповещение разработчикам. А оповещать разработчиков о том, что пользователь ввел неправильные данные некорректно, из чего следует, что это разные механизмы.
В БД нет валидации, которая подсвечивает все поля сразу.
С этим согласен, но это мизерная плата по сравнению с преимуществами которые даёт БД.
В БД нет даже проверки на пустую строку, только на NULL
По моему всё фреймворки транслируют пустую строку из реквеста в NULL в БД, эт вроде как стандарт что ль. А в Оракле вообще пустая строка и есть NULL.
Вы убрали дублирование нескольких незначительных правил, зато сделали дублирование функциональности и усложнили реализацию бизнес-требований.
Эти не значительные правила 95% составляют.
Где больше?
Что Вы с этими емейлами привязались, таких полей по всей системе 1-2. Скажем в системе 500 таблиц, по 10 полей, часть заполняется автоматом, не требует валидации, ну из 3000-4000 полей 1-2 поля… можно написать регулярку… чем весь тот зоопарк городить который Вы предполагаете… потом ещё поддерживать его
Давайте на живом примере, напишите правила валидации для этих данных
github.com/michael-vostrikov/stocks/blob/master/app/migrations/m200909_221603_init.php
я немного вчера ошибся, таблица current_stock денормализованная и пользователем не заполняется, поэтому правил у Вас должно быть меньше 14-15. Только ещё плюсаните в эти правила уникальность поля document_types.name
Усложнение реализации бизнес-требований, весь этот парсинг CREATE TABLE и передача на фронтенд, это тоже не проще в поддержке. А если мы разрабатываем API для использования сторонними системами, и фронтенда никакого нет? Видите, с вашим подходом постоянно всплывают какие-то ограничения.
Опять Вы какими то абстракциями говорите, никакого парсинга я не предлагал, все данные схемы красиво лежат в information_schema.*
Давайте конкретные примеры разбирать.
Это не валидация, а схема данных.
Не надо заниматься софистикой. Данные должны быть консистентны и отвечать определённым правилам, апп не обеспечивает нужной надёжности и требует больше кода.
из чего следует, что это разные механизмы.
Это Вы только что нафантазировали какую-то свою реальность… БД вполне успешно валидирует данные
никакого парсинга я не предлагал
Предлагали:
"UX валидацию прекрасно реализуется если на фронт передать SHOW CREATE TABLE"
"Я не предлагаю передавать полностью show create table, естественно передаётся только схема для скафолдинга текущей формы"
Это Вы только что нафантазировали какую-то свою реальность… БД вполне успешно валидирует данные
Я не сказал, что она их не валидирует. Я сказал, что реакиця на ошибки валидации в этих случаях разная.
Предлагали:
«UX валидацию прекрасно реализуется если на фронт передать SHOW CREATE TABLE»
«Я не предлагаю передавать полностью show create table, естественно передаётся только схема для скафолдинга текущей формы»
Подразумевал под «передать SHOW CREATE TABLE» следующее — что вся информация о текущей схеме таблицы у нас уже есть в БД (получить наглядно её можно SHOW CREATE TABLE), но забрать её конечно же удобнее из соответствующих VIEW information_schema.COLUMNS, information_schema.INNODB_FOREIGN_COLS, information_schema.CHECK_CONSTRAINTS, information_schema.REFERENTIAL_CONSTRAINTS и т.д. + ограничить нужными столбцами
У Вас высокий уровень знаний в БД, я просто подумал что для Вас в контексте диалога это будет очевидно… ну если я не достаточно ясно выразился, то выше пояснения.
У меня в information_schema.CHECK_CONSTRAINTS.CHECK_CLAUSE написано:
(length(`password`) between 8 and 64)
(`agreed` between 0 and 1)
regexp_like(`guid`,_utf8mb3\'^[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$\')Как вы предлагаете без парсинга преобразовать это в параметры валидации для JS-фреймворка на фронте?
Я наваял приложение на Node, максимально повторил Ваш код, та часть которая с БД
github.com/michael-vostrikov/stocks/commit/6ff0a0a3ff7082ee821369b50ebe0af242ed98fb
Подёргал его autocanon'ом, у меня при
need_error = 1 — приложение выдаёт в среднем ~1800 ответов в секунду
need_error = 0 — ~1200-1300RPS
need_error = Math.random() < 0.1 — тоже около ~1200-1300RPS
Код в студию.
Вот результаты автокенона

github.com/asmgit/erp_example_sql
если вопросы будут пишите, можно в телеграм
Ок, как проверить минимальную длину строки без парсинга?
Минимальную никак, только максимальную.
А вот параметры валидации в приложении можно, в Yii так и делается.Хорошая фича, а можно ссылку на доку
https://www.yiiframework.com/doc/guide/2.0/en/input-validation#using-client-side-validation
Behind the scene, yii\widgets\ActiveForm will read the validation rules declared in the model and generate appropriate JavaScript code for validators that support client-side validation.
комп домашний древний
Вот результаты автокенона
need_error = 0 — ~1200-1300RPS
У меня на вашем приложении такие результаты только если адрес неправильный, и в ответе заглушка nginx, до 3000 доходит. Вы бы проверили на всякий случай, что все правильно возвращается. Хотя может тут играет роль, что у меня ноутбук.
Если отправлять на правильный адрес, получается в среднем 400.
При этом у вас используется пул соединений, connectionLimit: 40. В PHP так нельзя сделать.
Если там поставить 1, получается 70 запросов в секунду, примерно столько же, сколько и в PHP. Но надо учитывать, что оно все равно переиспользуется во всех запросах, а PHP каждый раз подключается заново.
Что Вы с этими емейлами привязались, таких полей по всей системе 1-2.
В Yii более 20 встроеных валидаторов, при этом через базу без написания отдельного CONSTRAINT можно проверить штук 8-9, и то с натяжкой, так как нельзя проверить минимальную длину строки или задать минимальное и максимальное значение для int или date. Валидации для массивов значений в базе вообще нет.
['verificationCode', 'captcha'],
['password', 'compare', 'compareAttribute' => 'password_repeat'],
['age', 'integer', 'min' => 18, 'max' => 200],
['categoryIDs', 'each', 'rule' => ['integer']],Для всех этих ситуаций в приложении будет меньше кода, чем в базе, а именно одна строчка. А их в совокупности гораздо больше 1-2. И поддерживать сам код проверок не надо, он поддерживается разработчиками фреймворка.
Давайте на живом примере, напишите правила валидации для этих данных: m200909_221603_init.php
Давайте, хороший пример. Для Yii будут такие правила:
// documents
[['document_type_id', 'organization_id_address', 'organization_id_ur', 'status'], 'required'],
[['document_type_id', 'organization_id_address', 'organization_id_ur', 'status'], 'integer'],
[['document_type_id'], 'exist', 'targetClass' => DocumentType::class, 'targetAttribute' => ['document_type_id' => 'id']],
// document_positions
[['document_id', 'material_id'], 'required'],
[['document_id', 'material_id'], 'integer'],
[['document_id'], 'exist', 'targetClass' => Document::class, 'targetAttribute' => ['document_id' => 'id']],
[['material_id'], 'exist', 'targetClass' => Material::class, 'targetAttribute' => ['material_id' => 'id']],
// document_types
[['credit_type', 'name'], 'required'],
[['credit_type'], 'integer'],
[['credit_type'], 'in', [-1, 0, 1]],
[['name'], 'string', 'min' => 2, 'max' => 100],При этом мы говорим про проверку пользовательского ввода, а значит нам надо проверять все ошибки сразу и подсвечивать их в интерфейсе.
Покажите аналогичный код с валидацией через базу, как вы предлагаете, с передачей на фронтенд данных из information_schema.COLUMNS, INNODB_FOREIGN_COLS, .... Хотя бы для document_positions.
Проверка должна подсвечивать все ошибки сразу, это обязательное условие. Правильная реализация бизнес-требований это одна из причин, по которым используют фреймворки, потому что много функционала там уже реализовано.
CREATE TABLE для этих 3 таблиц занимает 27 строк, здесь кода валидации 16 строк, то есть в сумме кода всего в 1.5 раза больше, чем с валидацией в базе.
При этом его проще поддерживать. Можно обратить внимание на ограничение возможных значений credit_type — в базе будет ENUM, который требует ALTER TABLE при добавлении нового значения, что усложняет поддержку; и минимальную длину названия для типа документа — это хороший UX и защита от мусора в базе из-за случайных отправок формы, в базе это без специального CONSTRAINT сделать нельзя, а в приложении реализуется легко и аналогично максимальной длине.
Ситуации, когда надо будет менять код и в базе и приложении, это в основном переименование поля или изменение его типа, что происходит крайне редко.
У меня на вашем приложении такие результаты только если адрес неправильный, и в ответе заглушка nginx, до 3000 доходит.
Оч странно… при чём тут nginx…
Вы бы проверили на всякий случай, что все правильно возвращается.
Данные 100% корректные. На принтскринте выше мы получаем ~10% ошибок
1330 non 2xx responseчто полностью коррелирует с ожидаемым результатом
если запустить не в режиме
npm run dev_nolog
а в режиме
npm run dev
то производительность упадёт, но по логу будет видно что всё сходится.
В результате я уверен на 100%, уже не одно приложение так отлаживаю.
Вы точно запускали в режиме
npm run dev_nolog
?
Хотя может тут играет роль, что у меня ноутбук.
Эт вряд ли. У меня древний комп:
i5-2500K 3.30GHz, 16Gb RAM, HDD, без видео карты
ещё к тому же, всё это крутиться под докером
Может у Вас не отключены какие-то логи были? Например, мускульный general лог?
Чекните такой код:
fastify.get('/test_validation', async function (req, res) {
return {};
У меня делает около 3к RPS
А если ещё убрать коннект с мускуля
module.exports.default = fp(async fastify => {
return;
let db_pool = await mysql.createPool(db_config);
console.log('Connection pool created');
То у меня будет около 10к RPS
Вообще разрабы fastify заявляют hello world 56к RPS на нормальном железе
github.com/fastify/benchmarks#benchmarks
При этом у вас используется пул соединений, connectionLimit: 40. В PHP так нельзя сделать.
Если там поставить 1, получается 70 запросов в секунду, примерно столько же, сколько и в PHP. Но надо учитывать, что оно все равно переиспользуется во всех запросах, а PHP каждый раз подключается заново.
Ставить 1 коннект в пуле категорически не корректно! Т.к. при 10 одновременных запросах к php, он создаст 10 соединений к мускулю, в моём случае все 10 запросов к node будут пользоваться 1м соединением по очереди. Autocannon по умолчанию создаёт 10 соединений. Более корректно не релизить соединение, а дестроить его, тогда будут каждый раз реконнекты, но реконнект не даёт настолько существенную нагрузку или вообще не юзать для теста пул соединений.
Ща проверю кста…
Заменил пулл на коннект
fastify.addHook('preHandler', async (req) => {
//req.db = await db_pool.getConnection();
req.db = await mysql.createConnection(db_config);
и соответственно
req.db.close();
вместо релиза на закрытие, т.е. пул не использую вообще, полный аналог php получился, кол-во реквестов упало до ~600 RPS. Пул — сила! на легковесных запросах при их большом количестве.
Проверяйте…
Но даже при Ваших 400 на ноде и 60 на php, с php явно что-то не то…
Проверка должна подсвечивать все ошибки сразу, это обязательное условие.
С чего это вдруг стало обязательным условием? Это Вы сами только что придумали? Все ошибки сразу Вы в любом случае не сможете подсветить, я это очередной раз повторяю, часть Вы сможете отловить только в БД, как минимум это валидация FOREIGN KEY и UNIQUE валидация. Поэтому Ваши
В идеальном мире хочется отловить все ошибки на клиенте, для максимальной отзывчивости интерфейса и иметь все чеки, и констрейнты в БД, чтобы данные были консистентны и соответствовали тому, что мы об этих данных думаем и все валидейты прописать только 1 раз, т.е. проверка на уровне апп в идеальном мире избыточна.
Давайте разберём этот пример (я переименовал поле status в поле closed и ещё оно как бы типа boolean, т.е. в мускуле TINYINT IN (0, 1)).
// documents
[['document_type_id', 'organization_id_address', 'organization_id_ur', 'closed'], 'required'],
[['document_type_id', 'organization_id_address', 'organization_id_ur', 'closed'], 'integer'],
[['document_type_id'], 'exist', 'targetClass' => DocumentType::class, 'targetAttribute' => ['document_type_id' => 'id']],
Хотя нет… давайте разберём другой пример, а к тому ещё вернёмся
// document_positions
[['document_id', 'material_id'], 'required'],
[['document_id', 'material_id'], 'integer'],
[['document_id'], 'exist', 'targetClass' => Document::class, 'targetAttribute' => ['document_id' => 'id']],
[['material_id'], 'exist', 'targetClass' => Material::class, 'targetAttribute' => ['material_id' => 'id']],
Т.е. я, с помощью своей библиотеки, предлагаю вместо вот этого кода писать 0 строк, которые в бесконечное число раз легче поддерживать чем вот эти Ваши 4 строки кода (Вы, кста, забыли ещё поле cnt, но не об это речь).
Ещё ремарка:
[['document_id'], 'exist', 'targetClass' => Document::class, 'targetAttribute' => ['document_id' => 'id']],
[['material_id'], 'exist', 'targetClass' => Material::class, 'targetAttribute' => ['material_id' => 'id']],
вот эти валидейшены ничтожны, т.к. ничего реально не гарантируют, если после этой проверки и между записью данных в БД кто-то удалит строку из проверяемых таблиц, то у нас возникнет FOREIGN CONSTRAINT эксепшн (надеюсь возникнет, т.к. нормальный программист не пренебрегёт созданием FOREIGN CONSTRAINT в БД), т.е. кроме этих валидейшенов Вам надо написать код обработки FOREIGN CONSTRAINT эксепшна от БД. Этот код у Вас есть? Покажите пожалуйста его.
Да, я понимаю, что есть системы где эта проверка будет проходить в 99.99% случаев и FOREIGN CONSTRAINT эксепшн от БД будет прилетать оооочень редко, но эти Ваши валидейшены не исключают такой ситуации. Есть системы где мы можем ловить FOREIGN CONSTRAINT эксепшн от БД после валидейшена довольно часто, например какие-нть биржи. Т.е. валидация в апп даёт иногда 99,99%, иногда 50%, в общем никаких гарантий.
Моя библиотека даёт 100% гарантии. Да, она не умеет выдавать все ошибки одновременно (но и система валидации в апп ничего не гарантирует, т.к. после валидации в момент записи всё-равно может прилететь ошибка которую мы вроде как уже отвалидировали).
И да, самое главное, на основе схемы данных в БД можно передать на фронт основную часть валидейшенов, т.е. 95% простых проверок реализовать как в идеальном мире (см. выше) остальные 5% проверить в апп и на бэке.
О, кстати! Дак ведь можно и для апп сгенерить большую часть проверок из БД!!! + её можете дополнить теми проверками которые сложно реализуются на уровне БД.
Т.е. пишем функцию, код конеш упрощён, требует допила для продакта и разбора всех случаев, в общем набросок, который текущую ситуацию полностью описывает
let generate_validations_from_db = async (db, table_name, cols) => {
db.register_vars({table_name, cols});
let ret = await db.query(`
WITH c AS (
SELECT col FROM JSON_TABLE(@cols, '$[*]' COLUMNS (col VARCHAR(65) PATH '$')) t
)
SELECT c.COLUMN_NAME col
, IF(c.IS_NULLABLE = 'NO', 1, 0) required
, c.COLUMN_TYPE type
, c.COLUMN_COMMENT comment
, f.REFERENCED_TABLE_NAME ref_table_name
, f.REFERENCED_COLUMN_NAME ref_col_name
FROM INFORMATION_SCHEMA.COLUMNS c
LEFT JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE f
ON f.TABLE_SCHEMA = c.TABLE_SCHEMA
AND f.TABLE_NAME = c.TABLE_NAME
AND f.COLUMN_NAME = c.COLUMN_NAME
WHERE c.TABLE_SCHEMA = DATABASE()
AND c.TABLE_NAME = @table_name
AND c.COLUMN_NAME IN (SELECT col FROM c)
`);
}
Далее вызываем:
// SET @table_name = 'document_positions', @cols = '["document_id", "material_id", "cnt"]'
let validations = generate_validations_from_db(db, 'document_positions', ["document_id", "material_id", "cnt"]);
[
{
"col": "document_id",
"required": 1,
"type": "int unsigned",
"comment": "Документ",
"ref_table_name": "documents",
"ref_col_name": "id"
},
{
"col": "material_id",
"required": 1,
"type": "int unsigned",
"comment": "Материал",
"ref_table_name": "materials",
"ref_col_name": "id"
},
{
"col": "cnt",
"required": 0,
"type": "int",
"comment": "Количество",
"ref_table_name": null,
"ref_col_name": null
}
]
На основе этих данных без труда генерятся любые валидейшены хоть для апп, хоть для фронта, притом не надо писать ни строчки кода + изейши дополняются, в случае необходимости какой-то экзотикой, типа минимальная длина. И все лучшие принципы программирования в деле: KISS, Database First, DRY и т.д.
Михаил, реально, наша дискуссия меня провоцирует на фундаментально-уникальные решения, которые ещё никто нигде не применял! Спасибо Вам огромное. Уверен, на 100%, если бы какая-нть, из выше указанных библиотек в статье, совместила свою поделку с разработанным мною принципом Database First, то она стала бы отраслевым стандартом.
Эти диалоги реально вдохновляют. Меня так же, в дискуссии, вдохновил VolCh, за что ему отдельный респект. Результатом стала уникальная процедура обновления DB-объектов
github.com/asmgit/erp_example_sql/blob/master/lib/migrations.js#L163
npm run migrate routines
обновляет все объекты БД, её ещё конечно можно чутка доработать: обновлять только те объекты которые необходимо, а не все, прикрутить webpack, что бы при сохранении файла объекты автоматом обновлялись, но даже без этого, это уже прорыв.
CREATE TABLE для этих 3 таблиц занимает 27 строк, здесь кода валидации 16 строк, то есть в сумме кода всего в 1.5 раза больше, чем с валидацией в базе.
Ну как бы миграция никуда у Вас не девается, Вы её также пишите
При этом его проще поддерживать.
Проще только выстрелить себе в ногу
Можно обратить внимание на ограничение возможных значений credit_type — в базе будет ENUM, который требует ALTER TABLE при добавлении нового значения, что усложняет поддержку
credit_type тип TINYINT CHECK credit_type IN (-1, 0, 1)
и это не усложняет поддержку, а не даёт выстрелить себе в ногу, не путайте пожалуйста понятия
и минимальную длину названия для типа документа — это хороший UX и защита от мусора в базе из-за случайных отправок формы, в базе это без специального CONSTRAINT сделать нельзя
Минимальную длину действительно не реализуешь без специального CONSTRAINT, но и защиты от мусора она никой не даёт… так только в мечтах. Реальное использование мин длины это, например, в длине пароля или длины ИНН, а остальное, это всё Ваши фантазии.
Ситуации, когда надо будет менять код и в базе и приложении, это в основном переименование поля или изменение его типа, что происходит крайне редко.
Это практически каждая первая ситуация. Добавление поля — самая частая ситуация, 98%.
П.С. Михаил, Вы мне реально материала на статью наковыряли, жалко не успеваю всё это сделать, даже наши прошлые изыскания времени нет закончить, да и работы ща что-то подвалило…
Как много проектов вы реализовали с таким подходом? Судя по packagist, это очень похоже на концепт, который нигде не применяется, даже вами...
На практике все равно придется иметь отдельную от БД библиотеку для валидации, т.к. база не покрывает всех кейсов. При этом проверка на уникальность в 99.99%, как вы сами сказали, сработает и в стандартном валидаторе. Я, к примеру, ни разу не встречал зафейленные таким образом запросы. И получается, что не будет единого источника правды: за тем, чтобы узнать реальные правила валидации надо будет всегда заглядывать в оба места. Лично мне это не удобно, т.к. смена контекста код — база очень напрягает.
Это все не обращая внимания на то, что DTO с которым работает пользователь маппится на базу не один к одному. К примеру, в БД поле name, а от пользователя приходит firstName, lastName и middleName.
Уверен, на 100%, если бы какая-нть, из выше указанных библиотек в статье, совместила свою поделку с разработанным мною принципом Database First, то она стала бы отраслевым стандартом.
В symfony/validator есть нечто похожее
Я не топил за продвижение, за маркетинг, просто реализовал для себя, для проекта где работаю, выложил, никуда не продвигал, оказалась супер успешная вещь.
т.к. база не покрывает всех кейсовВот про то и речь, если БД не покрывает, то и данным этим грош цена
При этом проверка на уникальность в 99.99%, как вы сами сказали, сработает и в стандартном валидаторе.
Стандартных валидаторов на это нет.
Я, к примеру, ни разу не встречал зафейленные таким образом запросы.А я встречал.
И получается, что не будет единого источника правды: за тем, чтобы узнать реальные правила валидации надо будет всегда заглядывать в оба места. Лично мне это не удобно, т.к. смена контекста код — база очень напрягает.Конечно напрягает, но БД более источник знания чем менее, и чем апп, поэтому и предлагаю в первую очередь на БД ориентироваться, а не на абстрактные правила валидации, которые абсолютно ничего не гарантируют.
Это все не обращая внимания на то, что DTO с которым работает пользователь маппится на базу не один к одному
Как правило это фантазии и 99% мапиться 1 к 1, а если не мапится, то это ошибки архитектуры. Примеры кидайте.
В symfony/validator есть нечто похожее
Если, Symfony это реализовали, то они красавчики, которые только подтверждают правило, до которого я тоже дошёл. Завтра посмотрю подробнее.
Я не понимаю, Вы что ли за всё плохое и против всего хорошего?
Я вроде, концептуально, сокращаю кол-во кода при более высокой функциональности, что не так. Объясните.
При этом проверка на уникальность в 99.99%, как вы сами сказали, сработает и в стандартном валидаторе
А мой подход работает в 100% и это дорогого стоит. Когда у Вас приложение которое работает всегда, но иногда глючит, моё работает всегда. Притом мой подход требует меньше кодинга, проще, компактнее, дешевле в обслуживании.
Как правило это фантазии и 99% мапиться 1 к 1, а если не мапится, то это ошибки архитектуры. Примеры кидайте.
Недавно была задача: при регистрации заполнять анкету. По факту часть полей формы использовалась для генерации документов и в таблицу в итоге не уходила. При этом форма достаточно большая плюс присутствовала загрузка файлов поэтому, кстати, было отдельное требование, чтобы вся валидация была на фронтенде.
Еще немаловажный факт, что валидные данные нам нужны до вставки в БД.
{
"username": null
}class UserDTO
{
/**
* @var mixed
*
* @Assert\NotBlank()
* @Assert\Type("string")
*/
public $username;
}class User
{
/**
* @ORM\Column(type="string")
*/
private string $username;
public function __construct(string $username)
{
$this->username = $username;
}
}$dto = $this->serializer->deserialize($json, UserDTO::class, 'json');
$user = new User($dto->username); // PHP Fatal error: Uncaught TypeError
$this->entityManager->persist($user);
$this->entityManager->flush();— то что не пойдёт в БД, например, капчу
— то что сложно валидировать в БД, например, миме тайпы файлов, размеры картинок и т.д.
Я только против дублирования в апп и в БД если в этом нет необходимости.
Еще немаловажный факт, что валидные данные нам нужны до вставки в БД.Не, можно просто избавиться от ОРМ, тогда всё упростится и ускорится.
Симфони посмотрел, подход грамотный, я пришёл точно к такой же идее как и Симфони, и реализовал, но не для схемы ОРМ, как в Симфони, а для схемы БД
Оч странно… при чём тут nginx…
Я запускал в докере c --network="host", а на хосте у меня nginx.
Чекните такой код: у меня делает около 3к RPS
А если ещё убрать коннект с мускуля то у меня будет около 10к RPS
Да, у меня такие же цифры.
при 10 одновременных запросах к php, он создаст 10 соединений к мускулю
А при 10 последовательных тоже 10, а у вас 1.
Заменил пулл на коннект, кол-во реквестов упало до ~600 RPS
У меня 300. Видимо MySQL почему-то подтормаживает. General log не включен.
Но даже при Ваших 400 на ноде и 60 на php, с php явно что-то не то…
Еще одна причина — у вас кода в приложении почти нет, сразу запрос в БД идет, а у меня фреймворк инициализируется. Может попозже попробую на чистом PHP переписать и проверю.
С чего это вдруг стало обязательным условием? Это Вы сами только что придумали?
С того, что такое бизнес-требование имеется практически в любом приложении. Да, сам придумал. Мы же сраниваем написание бизнес-приложения, а не лабы для студентов. А у них есть определенные требования по UI и UX. Елси ваш подход не позволяет реализовать требования, значит он бесполезен, независимо от того, насколько все быстро работает.
часть Вы сможете отловить только в БД, как минимум это валидация FOREIGN KEY и UNIQUE валидация
Нет, не только. Код для валидации FOREIGN KEY я привел, это валидатор exist. Если в базе записи с указанным id нет, он выдаст ошибку. если есть, не выдаст.
Да, если в это же время добавлять или удалять записи с таким id, то гарантии нет. Но это не то же самое, что и "отловить только в БД". Только в БД можно отловить только вот эту незначительную часть ситуаций.
А самое главное, что ошибочного поведения все равно не будет даже в таких ситуациях. Потому что БД выбросит исключение. Но в этом случае необязательно его ловить и парсить текст ошибки, чтобы извлечь название поля, можно просто показать надпись "произошла ошибка, поторите запрос".
Поэтому Ваши влажные фантазии по поводу того что ВСЕ и СРАЗУ беспочвенны.
Это у вас фантазии по поводу того, что валидация пользовательского ввода почему-то должна гарантировать консистентное сохранение данных.
Для гарантий консистентности есть БД, вот пусть она этим и занимается.
Еще раз — нужно валидировать сразу все поля. Не гарантировать консистентность, а валидировать ввод. Если пользователь указал несуществующий на момент запроса id в document_id и material_id, интерфейс должен показывать ошибку в обоих полях. Можете передавать данные из служебных таблиц на клиент или еще что угодно, но надо обеспечить такое поведение, потому что оно требуется по задаче. Если у вас такого кода нет, значит без этой валидации в приложении обойтись нельзя, и этот спор не имеет смысла.
Т.е. я, с помощью своей библиотеки, предлагаю вместо вот этого кода писать 0 строк, которые в бесконечное число раз легче поддерживать чем вот эти Ваши 4 строки кода
Слушайте, у нас вроде серьезный разговор на инженерные темы, а вы такими манипуляциями занимаетесь. А библиотека ваша к проекту за 0 строк подключается? А вызовы нужных функций в нужных местах за 0 строк делаются?
В примере с валидацией email или телефона по маске у вас тоже кода больше будет, чем у меня. Может давайте я тоже эту разницу посчитаю за бесконечность?
Так как база покрывает не все случаи валидации, как вы сами сказали, значит таких мест будет много. То есть приложение в сумму бесконечностей раз легче поддерживать. Всё в соответствии с вашими методами подсчетов.
вот эти валидейшены ничтожны, т.к. ничего реально не гарантируют
И не должны. Я не знаю, с чего вы решили, что валидация пользовательского ввода должна гарантировать сохранение данных. Между вводом и базой они вообще могут 10 раз трансформироваться, и в базу пойдет не то, что было введено.
если после этой проверки и между записью данных в БД кто-то удалит строку из проверяемых таблиц, то у нас возникнет FOREIGN CONSTRAINT эксепшн
Бинго. Поэтому даже с валидацией в приложении неконсистентных данных в базе не будет. Только таких эксепшенов крайне мало, а некорректного пользовательского ввода много, потому что люди иногда ошибаются. Поэтому надо этот ввод проверять на ошибки.
И да, самое главное, на основе схемы данных в БД можно передать на фронт основную часть валидейшенов
Ну давайте еще раз. От вас нужен код, который делает то же самое, что и мой — валидирует все поля сразу для таблицы document_positions.
Если у вас такого кода нет, значит без валидации в приложении обойтись нельзя.
На основе этих данных без труда генерятся любые валидейшены хоть для апп, хоть для фронта, притом не надо писать ни строчки кода
Сгенерируйте валидацию для формы входа по email, при том, что можно зайти через соцсети или по телефону.
Сгенерируйте валидацию капчи.
Сгенерируйте валидацию что поле password должно повторять password_repeat.
Сгенерируйте валидацию массива category_id.
Нельзя обойтись без кода в приложении. А писать все правила валидации надо в одном месте, а не разбрасывать по разным системам. Следовательно, все правила должны быть в приложении и проверяться одним мехнизмом. Один механизм — KISS и DRY.
решения, которые ещё никто нигде не применял
Может их не применяли потому что они неудобны?
credit_type тип TINYINT CHECK credit_type IN (-1, 0, 1)
У нас же был разговор, как это реализовать без парсинга выражений, через типы БД.
И нет, для добавления нового типа все равно нужен ALTER TABLE.
и это не усложняет поддержку, а не даёт выстрелить себе в ногу, не путайте пожалуйста понятия
Каким образом развитие системы (добавление новых типов чего бы то ни было) это выстрел в ногу?
Ваш подход усложняет развитие системы.
Реальное использование мин длины это, например, в длине пароля или длины ИНН, а остальное, это всё Ваши фантазии
Вы похоже не понимаете. Мы разговариваем о написании бизнес-приложения. Приходит к вам собственник бизнеса и говорит "Сделайте ограничение минимальной длины в поле ввода, чтобы сотрудники не вводили ерунду и не тратили время на ее исправление". Вы ему тоже скажете "Это ваши фантазии"?
Это практически каждая первая ситуация. Добавление поля — самая частая ситуация, 98%.
Не все новые поля вводятся пользователем. И если вы добавите новое поле в базу, вам в любом случае надо будет добавлять его в приложение в список разрешенных полей формы. Не пробрасывать же список полей от пользователя напрямую в базу.
Ну давайте еще раз. От вас нужен код, который делает то же самое, что и мой — валидирует все поля сразу для таблицы document_positions.
Выше Вы не видите что ли этот код?
Сгенерируйте валидацию для формы входа по email, при том, что можно зайти через соцсети или по телефону.
Сгенерируйте валидацию капчи.
Сгенерируйте валидацию что поле password должно повторять password_repeat.
Сгенерируйте валидацию массива category_id.
4й раз:
Я же Вам несколько раз писал, но напишу и 3й, мб прочитаете всё-таки, я не против валидации введённых пользователем данных, я против дублирования валидации в апп, если такая валидация всё-равно есть в БД и я объяснил преимущества: даже на Ваших тестах она быстрее, требует меньше кода, более проста в поддержке.
Моя библиотека + тот код который я написал, полностью автоматически создаёт правила валидации для редактирования таблицы document_positions. Или Вы и с этим тоже будете спорить? Я ничего не понимаю. Я предложил решение, оно на порядок улучшило систему. Что не так?
И если вы добавите новое поле в базу, вам в любом случае надо будет добавлять его в приложение в список разрешенных полей формы. Не пробрасывать же список полей от пользователя напрямую в базу.
Да, но кода-то существенно уменьшается. Не надо поддерживать 95% кода в 2х местах, в БД и в апп, достаточно указать новое поле для генерации в правилах валидации.
Может их не применяли потому что они неудобны?
Писать меньше кода неудобнее? Мб просто никто так широко ещё не мыслил? Хотя вон вроде выше написали, что в Симфони есть подобный функционал… ещё не смотрел.
Кстати!!! Вы меня ещё на 1 гениальную мысль натолкнули. Можно же спиcок этих полей задать по дефолту скажем вот таким запросом:
SELECT c.COLUMN_NAME col
FROM INFORMATION_SCHEMA.COLUMNS c
WHERE c.TABLE_SCHEMA = DATABASE()
AND c.TABLE_NAME = @table_name
AND c.EXTRA NOT IN ('VIRTUAL GENERATED', 'STORED GENERATED', 'auto_increment')
AND c.EXTRA NOT LIKE 'DEFAULT_GENERATED%'Далее создать модели данных, туда включать ту информацию о схеме данных которой нет в самой базе, там же можно дополнить правила валидации, если в этом есть необходимость
/database/models/organizations.js
module.exports.exclude_cols_from_db_vatidations = ['phone_verified'];
module.exports.additional_vatidations = {'avatar': data => image_validator(data)};
Ну и далее запускаем функцию которая получает на основе этой информации все правила валидации и юзаем её и для фронта и для бэка
let validation_rules = generate_validations(db, 'organizations');
Оч круто получается!
UPD:
Посмотрел на Симфони, они реализовали именно то что я: генерация правил валидации из схемы данных (Automatic validation constraint). Правильное и мудрое решение.
Выше Вы не видите что ли этот код?
Да, теперь увидел) Я думал, что это просто пример результата работы вашего кода, и особо не всматривался что там написано.
4й раз:
я не против валидации введённых пользователем данных, я против дублирования валидации в апп
4-й раз — я рад, что вы не против, но я отвечал на конкретное утверждение "На основе этих данных без труда генерятся любые валидейшены". Не любые, а значит с вашим подходом у нас появляются две разных системы валидации вместо одной, где программист должен писать правила. То есть 2 системы, требующие поддержки.
Я предложил решение, оно на порядок улучшило систему. Что не так?
Решение — это генерация правил для приложения по данным из служебных таблиц БД? Теперь добавьте условие, что у нас документы или материалы могут быть помечены как удаленные, а пользователь должен указывать только активные. В приложении это реализуется тривиально, а у вас появляется SQL-код is_deleted = 0 в CHECK CONSTRAINT, который надо парсить, чтобы сгенерировать нужное правило в приложении. Либо писать в приложени вручную, как в моем подходе. Вот это и не так. Поэтому это не улучшение, а усложнение.
Не надо поддерживать 95% кода в 2х местах, в БД и в апп, достаточно указать новое поле для генерации в правилах валидации.
О да, ['new_field', 'integer'] это прям очень много кода, который надо поддерживать) В данном случае единственная разница между вашим и моим подходом это то, что мне надо указать еще и тип. А, ну может еще и required. Это не требует ни большой работы программиста, ни долгих проверок в рантайме приложения. Зато все правила валидации находятся в одном месте, а не в двух. В 95% случаев это гораздо важнее, так как упрощает поддержку и анализ кода.
Писать меньше кода неудобнее?
Поддерживать неудобнее. Анализировать поведение системы неудобнее.
Можно же спиcок этих полей задать по дефолту скажем вот таким запросом
Поле password_hash. Служебные поля, которые должны заполняться автоматически, типа created_at. То есть в приложении надо делать еще и систему исключений полей. Вместо списка проверок делаем список того, что не надо проверять. Это усложняет поддержку и анализ кода.
Посмотрел на Симфони, они реализовали именно то что я
Не совсем то, что вы, там правила валидации генерируются на основе информации из кода (т.е. из аннотаций). Валидация там кстати тоже аннотациями делается. То есть любая валидация находится в приложении, а не в базе. И проверки при сохранении данных делаются 2 раза, в приложении и в базе, а вы говорили, что против этого.
значит с вашим подходом у нас появляются две разных системы валидации вместо одной, где программист должен писать правила. То есть 2 системы, требующие поддержки.
Вы опять что ли не прочитали комментарий выше? Я предложил систему где все валидаторы мы пишем в одном месте (притом без дублирования кода) 95% автоматом подтягиваем из схемы БД, остальные 5% прописываем в апп. Пользуем получившимися проверками везде — хоть фронт, хоть апп, хоть БД.
О да, ['new_field', 'integer'] это прям очень много кода, который надо поддерживать) В данном случае единственная разница между вашим и моим подходом это то, что мне надо указать еще и тип. А, ну может еще и required. Это не требует ни большой работы программиста, ни долгих проверок в рантайме приложения.
так… т.е. Вы сами для себя оправдывайте дублирование кода… мда…
берём вот это ваше дублированное выражение, берём скажем 500 таблиц в системе, умножаем скажем на 10 полей, минимум надо проверить тип, NOT NULL, FOREIGN CONSTRAINT, т.е. выходит 15000-25000 бессмысленного дублированного кода, который надо поддерживать в схеме данных и в апп и держать всегда строго синхронизированным. Отличное решение! Напоминаю, есть принципы КИСС, ДРАЙ, которые совсем не приветствуют то что Вы придумали.
Поле password_hash. Служебные поля, которые должны заполняться автоматически, типа created_at. То есть в приложении надо делать еще и систему исключений полей. Вместо списка проверок делаем список того, что не надо проверять. Это усложняет поддержку и анализ кода.
Дак я и сделал эту систему, Вы опять что ли не читали комментарий выше? Сколько надо исключить полей из примера который мы с Вами выше описывали? 0. Сколько полей password_hash в обычной системе? У меня 1 в обычных проектах, там где требуется рефакторинг схемы данных — 2. Поля created_at у меня исключены, если Вы опять не внимательно читаете комментарий.
И проверки при сохранении данных делаются 2 раза, в приложении и в базе, а вы говорили, что против этого.
В первую очередь я против дублирования кода. В Симфони делается именно то же что придумал я — генерация валидейшенов на основе схемы данных. Насколько я знаю работает там это так, я изменяю схему данных, т.е. те файлики с аннотациями, на основе этого генерятся миграции и получается начинает работать автовалидация. Понимаете? 1 изменение вместо 2х, в одном месте. Не отдельно делается миграция, потом (если программист не забыл), ищется место где же эти данные валидируются для вставки и изменения (притом для Ларавеля это 2 разных правила, что меня ещё в 2 раза больше возмущает), потом схема валидации приводится в соответствии со схемой БД.
значит с вашим подходом у нас появляются две разных системы валидации вместо одной, где программист должен писать правила
Вы опять что ли не прочитали комментарий выше?
Читаю:
"я не против валидации введённых пользователем данных, я против дублирования валидации в апп"
"95% автоматом подтягиваем из схемы БД, остальные 5% прописываем в апп"
Писать некоторые правила в апп надо? Надо. Писать некоторые правила в БД надо? Надо. Значит это 2 системы, где программист должен писать правила. Что не так? Неважно, что они не дублируются, важно, что посмотрев в одно место, нельзя узнать все правила валидации данных для некоторой формы.
т.е. Вы сами для себя оправдывайте дублирование кода… мда…
Ну одно да потому. Я не "оправдываю дублирование кода", я говорю, что в общем случае это не дублирование. Валидация отдельно, сохранение отдельно. Это разные подсистемы, и они могут существовать друг без друга.
Пользуем получившимися проверками везде — хоть фронт, хоть апп, хоть БД.
Вы же только что сказали, что против дублирования. Теперь уже дублировать можно, если оно автоматом генерируется?
Если вы не в курсе, правила валидации в Yii тоже генерируются по БД. Только делается это один раз при создании класса модели, и далее их можно дополнить как надо, не прикручивая парсинг SQL.
т.е. выходит 15000-25000 бессмысленного дублированного кода, который надо поддерживать в схеме данных и в апп и держать всегда строго синхронизированным
Нет, не надо. Еще раз — валидация введенных пользователем данных это не то же самое, что ограничения в схеме хранения. Поэтому он не бессмысленный и не дублированный, он дает возможности, которых нет в БД — провалидировать форму логина например, и синхронизировать его необязательно — длину VARCHAR можно сразу сделать с запасом, чтобы не делать ALTER TABLE если правила вдруг изменятся. Кроме того, не все NOT NULL и FOREIGN CONSTRAINT вводятся пользователем, поэтому не все из них надо валидировать в приложении. А самое главное, правила для тех, которые надо валидировать, находятся в одном месте в описаниии формы ввода. Упрощение поддержки это тоже одна из целей, для которой пишется код. Итого, если убрать ваши преувеличения, никакого дублирования и нет, весь код нужен для какой-то цели. И по опыту разработки таких систем могу сказать, что никаких проблем такое "дублирование" не создает. А когда одни правила в одном месте, а другие в другом, это создает.
Напоминаю, есть принципы КИСС, ДРАЙ, которые совсем не приветствуют то что Вы придумали.
У вас 2 системы задания правил валидации, у меня 1. Это и есть КИСС и ДРАЙ. Напоминаю, что эти принципы придуманы для упрощения разработки и поддержки.
Дак я и сделал эту систему
let validations = generate_validations_from_db(db, 'document_positions', ["document_id", "material_id", "cnt"]);
Пфф, а чем это отличается от "берём скажем 500 таблиц в системе, умножаем скажем на 10 полей"? У вас тоже все эти поля будут перечислены в приложении, и тоже при добавлении нового поля надо будет сихронизировать код. А для примера с is_deleted все равно надо вручную проверку FOREIGN KEY писать.
В первую очередь я против дублирования кода.
Зато почему-то не против дублирования подсистем. Дублирование подсистем сложнее в поддержке, чем дублирование проверки на int.
Не отдельно делается миграция, потом (если программист не забыл), ищется место где же эти данные валидируются для вставки и изменения
Если программист забудет добавить поле в форму ввода, туда данные не будут попадать. Это заметит он сам, это заметят автотесты, это заметит тестировщик, даже сама база может бросить исключение, если поле NOT NULL. Миграция вообще делается как следствие новых требований к данным, поэтому маловерятно, что в результате выполнения задачи будет миграция, но не будет изменений в интерфейсе.
Первая самая большая (по моим оценкам около 95%) — БД — отвечает за достоверность данных, на основе неё часть правил можно транслировать для апп и фронта, но часть правил можно проверить исключительно только на БД, например, FOREIGN KEY, UNIQUE и другие правила, поэтому БДшная система проверки правил присутствует в любом случае.
Вторая система это в апп — тут мы проверяем пользовательский ввод, капча, пасворд конфирм, то что не пойдёт в БД + то что сложно проверять в БД, например миме типы, размеры картинок
Третья — валидация на фронте, в неё мы можем забрать инфу из схемы БД и из апп валидаторов + дополнить тем что сложно проверять в апп и БД и тем что не пойдёт в апп.
Теперь уже дублировать можно, если оно автоматом генерируется?
Технически это не генерация, а валидация на основе схемы БД, кода то нет, ничего не задубоированно.
Если вы не в курсе, правила валидации в Yii тоже генерируются по БД. Только делается это один раз при создании класса модели, и далее их можно дополнить как надо, не прикручивая парсинг SQL.
Приведите пример кода. В моём коде нет никакого парсинга SQL, Вы придумываете.
Нет, не надо. Еще раз — валидация введенных пользователем данных это не то же самое, что ограничения в схеме хранения.
Ещё, в очередной раз, уже сбился со счёту в какой:
Я же Вам несколько раз писал, но напишу и 3й, мб прочитаете всё-таки, я не против валидации введённых пользователем данных, я против дублирования валидации в апп, если такая валидация всё-равно есть в БД и я объяснил преимущества: даже на Ваших тестах она быстрее, требует меньше кода, более проста в поддержке.
длину VARCHAR можно сразу сделать с запасом, чтобы не делать ALTER TABLE если правила вдруг изменятсяОт такого подхода надо держаться подальше как от огня. Потом думай а есть там запас или нет, проверять надо как схему валидации так и БД. Дак сделайте вообще все поля типа TEXT NULLABLE и храните в них любые данные, а валидаторы эти Ваши в апп всё проверят.
Да, действительно а почему Вы так не делайте?
А самое главное, правила для тех, которые надо валидировать, находятся в одном месте в описаниии формы ввода. Упрощение поддержки это тоже одна из целей, для которой пишется код. Итого, если убрать ваши преувеличения, никакого дублирования и нет, весь код нужен для какой-то цели. И по опыту разработки таких систем могу сказать, что никаких проблем такое «дублирование» не создает. А когда одни правила в одном месте, а другие в другом, это создаетДак не все они в одном месте, есть правила которые, например, можно только в БД проверить, а как Вы говорите что ну не будем проверять, там раз в 1000 случаев вылетит какая-то ошибка у пользователя, ну и фиг с ним, это дилетантский подход, так не разрабатывают серьёзные системы. А дублировать код только для того чтобы он был в одном месте так себе подход, ну тогда хотя бы дублируйте его в комментариях, просто в качестве документации, чтобы всё-таки источником достоверности было 1 место, а не 2
У вас 2 системы задания правил валидации, у меня 1.
И у Вас, и у меня их 3 (2 на бэке). Но у Вас апп частично в большей части повторяет схему БД + оверхэд на поддержку + оверхэдная нагрузка на сервер БД.
Пфф, а чем это отличается от «берём скажем 500 таблиц в системе, умножаем скажем на 10 полей»? У вас тоже все эти поля будут перечислены в приложении, и тоже при добавлении нового поля надо будет сихронизировать код.
1. у меня только поля перечислены, а у Вас и типы, и required и констрейнты и уникальности
2. далее я предложил систему которая требует ещё меньше поддержки, а именно указывать только исключительные случае, т.е. только те поля которые не транслируются напрямую из пользовательского ввода в БД, коих совсем не много. Про is_deleted и FOREIGN KEY ничего не понял, как это вообще между собой связано
Зато почему-то не против дублирования подсистем. Дублирование подсистем сложнее в поддержке, чем дублирование проверки на int.
У меня подсистемы не дублируют друг друга, только в исключительных случаях. У Вас 95% кода продублировано.
Если программист забудет добавить поле в форму ввода, туда данные не будут попадать. Это заметит он сам, это заметят автотесты, это заметит тестировщик, даже сама база может бросить исключение, если поле NOT NULL. Миграция вообще делается как следствие новых требований к данным, поэтому маловерятно, что в результате выполнения задачи будет миграция, но не будет изменений в интерфейсе.
— программист написал миграцию на увеличение длины поля, на увеличение длины поля в валидаторе забыл
— программист написал увеличение длины поля в валидаторе, миграцию на увеличение длины поля забыл
И оба этих случая должен будет проверять тестировщик и/или поддерживать оба случая в автотестах, т.е. усложнение работы в 2 раза
Дак я Вам больше скажу этих систем не 2, а 3
Третья — валидация на фронте, в неё мы можем забрать инфу из схемы БД
Я говорю про те системы, где программист должен писать правила валидации вручную и куда он должен смотреть при анализе логики валидации. Я же несколько раз это повторил. При чем тут то, куда мы можем забрать инфу из БД?
но часть правил можно проверить исключительно только на БД
Нет. Гарантировать можно только на БД, а проверить для 99% случаев ввода данных пользователем можно и в приложении. Поэтому не "исключительно".
и далее их можно дополнить как надо, не прикручивая парсинг SQL.
Приведите пример кода. В моём коде нет никакого парсинга SQL, Вы придумываете.
Я уже привел — когда у материалов и документов есть поле is_deleted, а нам надо чтобы пользователь указывал только те, в которых это поле равно 0.
У вас либо надо писать код на SQL и потом его парсить, либо писать проверку в приложении, а значит ваша система для таких случаев бесполезна.
Да, действительно а почему Вы так не делайте?
М.б. потому что делать все поля TEXT NULLABLE мне не надо? А убрать лишний ALTER TABLE на продакшене надо.
VARCHAR по факту и так всегда делается с запасом, длина большинства данных меньше этой циферки.
Дак не все они в одном месте, есть правила которые, например, можно только в БД проверить
Нет таких правил. Гарантировать 100% результат такой проверки можно в БД, а проверить для 99% случаев можно и в приложении. Если мы попадем в тот 1% случаев, база выбросит исключение. Только нам не надо будет его ловить и парсить текст, чтобы достать название поля.
Ещё, в очередной раз, уже сбился со счёту в какой
Объясните, зачем вы это пишете? Как связана информация о том, что вы не против валидации в апп с тем, что валидация форм это не то же самое, что ограничения в схеме хранения? Я правда не понимаю, как связаны ваши предпочтения с назначением разных подсистем приложения.
там раз в 1000 случаев вылетит какая-то ошибка у пользователя, ну и фиг с ним, это дилетантский подход, так не разрабатывают серьёзные системы
Разрабатывают. Практически любое приложение с логикой не в БД так работает.
Тем более вы сами сказали, что только недавно поняли, что можно брать некоторые правила валидации из БД, дата коммитов в вашем репозитории 10 месяцев назад. Значит до этого все как-то обходились без вашего расширения к Laravel.
Ошибка не "вылетит раз в 1000 случаев", а в 999 случаях вылетит одна ошибка, а в 1 случае другая. Напомню, мы говорим про ошибки валидации, они по определению должны случаться.
— У вас 2 системы задания правил валидации, у меня 1.
— И у Вас, и у меня их 3 (2 на бэке)
Нет. У меня правила валидации пишутся (программистом) в одном месте, а у вас в двух.
у меня только поля перечислены, а у Вас и типы, и required и констрейнты и уникальности
Во, начались компромиссы. Для вас приемлемо дублировать поля, для меня еще и типы. Потому что так все правила находятся в одном месте, и это проще поддерживать, проще реализовывать разные требования.
я предложил систему которая требует ещё меньше поддержки, а именно указывать только исключительные случае
Я про это как раз и написал:
"Вместо списка проверок делаем список того, что не надо проверять. Это усложняет поддержку и анализ кода."
Про is_deleted и FOREIGN KEY ничего не понял, как это вообще между собой связано
" — автоматически создаёт правила валидации для редактирования таблицы document_positions. Что не так?"
" — Теперь добавьте условие, что у нас документы или материалы могут быть помечены как удаленные, а пользователь должен указывать только активные."
У вас автоматически по FOREIGN KEY сгенерируется недостаточная проверка, она будет проверять только наличие, а нам надо проверять еще и is_deleted.
У меня подсистемы не дублируют друг друга, только в исключительных случаях.
Ну раз вы делаете вид, что не понимаете, объясню подробнее. Само наличие 2 подсистем, где надо писать правила — это дублирование функциональности. Неважно, что там правила разные, программист все равно должен смотреть в обе вместо одной.
программист написал миграцию на увеличение длины поля, на увеличение длины поля в валидаторе забыл
А нафига он ее писал тогда?) Написал и не проверил работу?
программист написал увеличение длины поля в валидаторе, миграцию на увеличение длины поля забыл
Тогда база выдаст ошибку, и невалидных данных в базу не попадет. Но вообще это странный программист, который так делает. Как они сохраняться-то будут. Можно еще текст в поле INT писать, это примерно настолько же нелогично.
и/или поддерживать оба случая в автотестах, т.е. усложнение работы в 2 раза
Вы все-таки не понимаете, зачем нужны автотесты. Оба этих случая должны присутствовать в автотестах в любом варианте. Особенно в вашем, когда в базе могут быть еще и всякие триггеры на вставку.
ru.wikipedia.org/wiki/%D0%94%D1%83%D0%B1%D0%BB%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5
т.е. этот код повторяет схему данных и должен поддерживаться и там, и там, если в Вашей системе координат приемлемо создавать поля TEXT для всех полей на всю схему, ну что уж…
Нет таких правил. Гарантировать 100% результат такой проверки можно в БД, а проверить для 99% случаев можно и в приложении. Если мы попадем в тот 1% случаев, база выбросит исключение. Только нам не надо будет его ловить и парсить текст, чтобы достать название поля.
Есть такие правила, как минимум это FOREIGN и UNIQIE CONSTRAINT, могу ещё Вам найти пример из жизни где проверить данные просто нереально на уровне апп. А если Ваша программа работает только в 99% случаев, то это дилетантский подход, он подходит только для домашних страничек, студенческих проектов, демонстрации языка программирования. Для серьёзных проектов: финансы, медицина, любой биллинг такое допущение просто не приемлемо. Я Вам показал код (+ благодаря нашей дискуссии его ещё и доработал) для высоконагруженных проектов с высокими требованиями на консистентность данных, который работает быстрее Вашего, требует меньше программистов, код не убивает производительность БД, кода на порядки меньше, в 2 раза меньше кода для его поддержки в автотестах, тестировщику и самому программисту, идентичный подход используют сообщества типа Симфони… ну я даж не знаю о чём Вы спорите
Вот все хочу оставить последнее слово за вами и закончить этот разговор, но вы такие высказывания делаете, что нельзя не указать на ошибки в логике.
Есть такие правила, как минимум это FOREIGN и UNIQIE CONSTRAINT, могу ещё Вам найти пример из жизни где проверить данные просто нереально на уровне апп.
Вот вам проверка на уровне апп, которая ловит 99% случаев:
[['document_type_id'], 'exist', 'targetClass' => DocumentType::class, 'targetAttribute' => ['document_type_id' => 'id']],Если пользователь ввел несуществующий document_id, она покажет ошибку. Как же она может показывать ошибку, если это "просто нереально"? Значит реально.
А если Ваша программа работает только в 99% случаев
Подмена понятий. Она показывает правильную ошибку валидации пользователю в 99% случаев, а работает (т.е. невалидные данные не попадают в систему) в 100% случаев.
идентичный подход используют сообщества типа Симфони… ну я даж не знаю о чём Вы спорите
О том, что там не идентичный подход. Там — правильный подход, все правила валидации написаны в приложении, а не раскиданы по разным системам.
Вот вам проверка на уровне апп, которая ловит 99% случаев
Дак в 99%, а не в 100
Она показывает правильную ошибку валидации пользователю в 99% случаев, а работает (т.е. невалидные данные не попадают в систему) в 100% случаев
Ну т.е. требует поддержки и в БД и в апп чтобы работало в 100% случаев, моя система работает в 100% случаев и требует поддержки только в БД.
Там — правильный подход, все правила валидации написаны в приложении, а не раскиданы по разным системам.
Скорее он ущербный, т.к. поделки вроде Симфони, пытаются эмулировать возможности БД, но не гарантирует валидности данных. Часть валидаций можно эффективно реализовать только в БД, они об этом почему то умалчивают. Вот сейчас как раз начинаю писать технические требования к статье, которую мы с Вами договорились написать, там есть именно такие моменты.
Кстати… я их уже описал в БД, в схеме, но могу сейчас Вам скинуть на реализацию, просто чтобы подумать, задачка довольно интересная, решается только на уровне БД, через пару-тройку дней надеюсь закончить и кинуть Вам статью на рецензию, увидите правильный ответ.
Если интересно порешать задачку, то черкните здесь или в личку, скину задачку
моя система работает в 100% случаев и требует поддержки только в БД
Ну как это только в БД, вы же сами писали:
"Вторая система это в апп — тут мы проверяем пользовательский ввод, капча, пасворд конфирм, то что не пойдёт в БД + то что сложно проверять в БД, например миме типы, размеры картинок"
поделки вроде Симфони, пытаются эмулировать возможности БД, но не гарантирует валидности данных
Ничего они не пытаются эмулировать. И гарантировать валидность сохраненных данных не должны. Это вы сами себе придумали, что они должны выполнять функции БД, и удивляетесь, что они этого не делают. Правила валидации ввода должны проверять валидность ввода, и более ничего.
Если интересно, скину задачку
Да, скиньте сюда в комменты, может кому-то еще будет интересно посмотреть.
CREATE TABLE test_client_price (
organization_id int unsigned NOT NULL COMMENT 'Клиент',
price_type_id int unsigned NOT NULL COMMENT 'Тип прайса',
organization_id_manufacturer int unsigned DEFAULT NULL COMMENT 'Производитель',
material_id int unsigned DEFAULT NULL COMMENT 'Материал',
coefficient decimal(10,5) NOT NULL DEFAULT '1.00000' COMMENT 'Коэффициент',
KEY price_type_id (`price_type_id`),
KEY material_id (`material_id`),
CONSTRAINT test_client_price_material_id_fk FOREIGN KEY (`material_id`) REFERENCES `materials` (`id`),
CONSTRAINT test_client_price_organization_id_fk FOREIGN KEY (`organization_id`) REFERENCES `organizations` (`id`),
CONSTRAINT test_client_price_price_type_id_fk FOREIGN KEY (`price_type_id`) REFERENCES `price_types` (`id`),
CONSTRAINT test_client_price_material_idorganization_id_manufacturer_chk CHECK (((`material_id` is null) or (`organization_id_manufacturer` is null)))
) COMMENT='Прайсы клиентов'
Прайсы клиентов, в ней указываются по какому прайсу работаем с клиентом, т.е., например, запись
organization_id — 1
price_type_id — 77
organization_id_manufacturer — NULL
material_id — NULL
обозначает что для клиента 1 действует прайс с ид 77
запись
organization_id — 1
price_type_id — 78
organization_id_manufacturer — 2
material_id — NULL
обозначает что для клиента с ид 1 и производителем (organization_id_manufacturer) для производителя с ид 2 действует прайс 78
это более приоритетно чем предыдущее правило
запись
organization_id — 1
price_type_id — 79
organization_id_manufacturer — NULL
material_id — 6
обозначает что для клиента с ид 1 и товаром (material_id) с ид 6 действует прайс 79
это более приоритетно чем предыдущее правило
Задача, обеспечить уникальность правил, т.е. одно общее правило для клиента, т.е.
organization_id NOT NULL
price_type_id NOT NULL
organization_id_manufacturer NULL
material_id int unsigned NULL
далее уникальные правила для каждого производителя
organization_id NOT NULL
price_type_id NOT NULL
organization_id_manufacturer NOT NULL
material_id int unsigned NULL
и уникальное правило для материалов
organization_id NOT NULL
price_type_id NOT NULL
organization_id_manufacturer NULL
material_id int unsigned NOT NULL
+ если organization_id_manufacturer и material_id заполнены одновременно, это не валидно
Надеюсь понятно объяснил?
Реализовать такое на уровне апп оч сложно, на уровне БД, в 10 строк кода уложиться более чем
Если я правильно понял, тут правильнее делать по-другому. У одного клиента много прайсов по материалам, один материал участвует в многих прайсах клиентов, связь между этими сущностями многие-ко-многим. У одного клиента много прайсов по производителям, один производитель участвует в многих прайсах клиентов, связь между этими сущностями тоже многие-ко-многим. 2 разные связи, значит должно быть 2 разные промежуточные таблицы.
-- Таблица общих правил
client_price (
organization_id NOT NULL,
price_type_id NOT NULL,
coefficient NOT NULL,
UNIQUE(organization_id, price_type_id)
)
-- Таблица правил для производителей
client_price_manufacturer (
organization_id NOT NULL,
organization_id_manufacturer NOT NULL,
price_type_id NOT NULL,
coefficient NOT NULL
UNIQUE(organization_id, organization_id_manufacturer, price_type_id)
)
-- Таблица правил для материалов
client_price_material (
organization_id NOT NULL,
material_id NOT NULL,
price_type_id NOT NULL,
coefficient NOT NULL,
UNIQUE(organization_id, material_id, price_type_id)
)Такая модель наиболее точно отражает предметную область. Ни одного NULL-поля, ни одного кастомного CONSTRAINT, все нормально покрывается стандартными UNIQUE-индексами. Поверх этого можно делать любую обработку в приложении, в том числе и проверку приоритетов. Получаем 3 результата, проверяем наличие нужной записи по очереди в третьем, втором, первом. Все красиво получается, прямое отражение требований.
А вы как приоритеты проверяете, неужели через сложный ORDER BY?
если organization_id_manufacturer и material_id заполнены одновременно, это не валидно
И вас это не наталкивает на мысль, что возможно в вашей модели данных что-то не так?)
Смешивание валидаций разных слоев приложения — это не драй и не кисс, это layering violation.
Задача валидатора уровня http request — проверить валидность пользовательского ввода и выдать ошибки валидации, отформатированные для фронтенда (уж не знаю, может, там сервер-сайд рендеринг, может, json с ошибками, который фронтенд понимает). Это не отменяет остальных проверок. В какой-нибудь метод User::changeEmail(string email) значение может прилететь, внезапно, откуда угодно, а не только из конкретного http-ендпоинта.
(Хотя, конечно, это тоже не оч дизайн, лучше User::changeEmail(Email email), где Email — value object с валидацией и выбрасиванием исключения в конструкторе.)
То, что мы валидируем емейл два раза, совершенно не должно смущать. Никого не смущает же дополнительная проверка на фронтенде? Это то же самое.
Что у вас БД проверит, валидность емейла? Я бы посмотрел на check constraint для проверки емейла по RFC5322 :-)
Не, есть подход с хранимками на всё-всё-всё, имеет право на существование, но это уже вообще о другом.
Всё что не прописано в БД в CHECK CONSTRAINT не гарантированно даже на 0,1%
У меня со 100% вероятностью, поскольку иначе чем через персистенцию сущности в базу попасть ничего не может.
Так это все разные проверки, на разных слоях.
Валидность емейла, например, может определяться в том числе наличием MX-записи для домена, что из базы не проверишь.
А уникальность емейла в данной таблице может как раз только база обеспечить.
Что касается дублирования — в базе, конечно, дублировать проверку на rfc5522 не стоит. А вот в приложении на уровнях Application и Domain — стоит: app level validation позволит отдать пользователю человеческие ошибки валидации на раннем этапе (валидация реквеста), а domain level validation гарантирует валидность емейла в любом случае, откуда бы он там ни прилетел в коде (просто выкидывая исключение). При этом, разумеется, обе проверки могут внутри сводиться к вызову какого-нибудь Email::isValid(), дублировать регулярки не надо, конечно :-) Более того, если используется какой-нибудь ValueObject Email, и строки из реквеста при валидации мапятся на value objects, проверка на самом деле будет одна (я так и делаю, но этот подход почему-то непопулярен — многие почему-то боятся делать по классу на каждый тип, хотя в ООП типы классами и выражаются).
habr.com/ru/post/521292/#comment_22160844
т.е. идея такая: основную часть подтягиваем из схемы, дополняем апп валидаторам, пользуем везде — фронт, апп, БД. Схема идеальная, кода минимум и он в одном месте!
Это все типичные leaky abstractions. Выглядит хорошо, пока не погрузишься в детали.
Вот, например, типичная проверка, когда при регистрации просят ввести пароль дважды (опустим то, что так уже не модно). Это типичная UI-валидация, которая не имеет отношения ко всем остальным слоям — за пределами UI мы ничего не знаем и не хотим знать про двойной ввод пароля.
Или, например, пользователи из России привыкли вводить телефон в формате 8xxxx, и мы для них делаем интерфейсный костыль, но на уровне домена и инфраструктуры оперируем нормальным форматом +7xxx.
Да и вообще структура HTTP-запроса и структура базы — это две большие разницы. Они могут вообще не совпадать совсем. То, что они иногда похожи — ничего не значит.
Если делать с умом, ничего и не продублируется. :-)
Делаются value objects вида
class Email {
private final value:string;
constructor(email: string) {
if (!isValid(email)) throw new InvalidEmail(email);
this.value = email;
}
static isValid(email: string): boolean {
return ...;
}
toString(): string {
return this.value;
}
}На Application уровне данные запроса мапятся на ValueObjects, которые гарантированно валидны, весь код уровня "ниже", работающий с емейлами, требует объекты класса Email.
Да, тут нужна нормальная ORM, умеющая полноценно работать с embeddables. Всякие активрекорды в пролёте, но туда им и дорога.
Еще частый юзкейс: валидация на базе всех введенных данных. К примеру, для валидация р/с и к/с надо знать значение БИК. На первый взгляд rakit/validation так не умеет.
Если кому-то хочется знать выбор автора, но не хочется тратить время на загрузку гитхаба и чтение readme, то он выбрал Rakit Validation.
Можете не благодарить.
Валидация в PHP. Красота или лапша?