Comments 829
www.businessinsider.com/high-paying-jobs-for-people-who-hate-math-2014-11
А если именно программировать – то алгебра уровня старших классов школы нужна как минимум (а это немало; я в свою очередь класса с 7-го не в то русло энергию направлял и в алгебре страшные провалы, о чём сейчас порой очень жалею).
Конкретно алгебра не особо нужна, всем нужна пожалуй только алгебра логики. Остальное же от задач зависит — кому-то нужен весь матан, кому-то только матрицы, а кому-то ничего.
Я сам ни разу не программист и вкатиться не пытаюсь, но мне показалось странным что автор не понимает вот этого:
выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор
Это не уравнение. Это команда машине увеличить переменную N на единицу. То есть конкретно этот пример может работать как счетчик.
Мне кажется, что автору статьи сейчас нужен обычный школьный репетитор по информатике, который за месяц занятий покажет основы на примере бейсика или паскаля, и если даже после этого луч света не появится — тогда точно можно забыть про программирование как про страшный сон, а если что-то будет получаться — уже думать что делать дальше.
нужно решать задачки на java или котлин, хотя котлин без java все же сложноват. Математику(leetcode) можно делать после освоения языка. Язык осваивается в виде сделаных 5-10 проектов. В большинстве случаев достаточно изучения web сервисов. Ну либо смотреть проекты на андроиде. Для начала написать hello world, потом добавить логику потом бд дальше сходить на собеседование(устроитья не цель, но если возьмут это круто) — узнать что спрашивают и двигаться в этом направлении.
Не плохой вариант javarush как-раз чтобы голова не болела, что делать. Но полностью к собеседованию не готовит. Как варик можно курсы от jetbrains, правда только присматривался, вроде не плохие, но лично не пробовал.
Основы программирования на паскале изучаются в школе. Думаю, обычный школьный репетитор по информатике не сможет помочь с решением задачек на java.
По моим школьным воспоминаниям, в паскале более или менее легко разобраться. Соответственно, можно быстрее попробовать себя в более осознанном программировании, чем "Hello, World!"
Учить java первым языком — глупая затея. С одной стороны это слишком низкоуровнево, с другой стороны много концепций приходится объяснять сразу. У меня был буквально один урок, когда школьница попросила её обучить джаве. И на том моменте, когда для чтения числа с клавиатуры нужно сделать обёртку из буфферизованного потока, а потом из ридера, я понял, что затея провальная.
И это мы ещё опускаем заклинания public static void main (но они не только в джаве, конечно). Даже на плюсах проще стартовать, имхо.
Да, сам недавно узнал. В мое-то время учились основам программирования на черепашке и паскале
Видел у К.Ю.Полякова робота для браузера с возможностью выбора языка из Python, JS, PHP, Dart, Lua. Ну и там еще прикручен редактор blockly для визуального конструирования.
Школьная алгебра нужна для того чтобы научить:
1) Точно выражать свои мысли (чтобы задача вообще была решена)
2) Оформлять их в строгой нотации (чтобы код скомпилировался)
3) Преобразовывать выражения из одной формы в другую без потери смысла (чтобы рефакторить)
Если человек не научился на алгебре раскрывать скобки у многочленов, то у него будут проблемы и в программировании.
Подробнее эту тему я раскрывал в своей статье Вот зачем нужна школьная алгебра
Конечно дорогу осилит идущий и полюбить можно после свадьбы...
— Знаешь, как называется любовь за деньги?
— Продакшен, как же ещё! :)
en.m.wikipedia.org/wiki/Summed-area_table
Фильтры всякие, антиалиасинг…
Всегда можно обойтись без чего либо или выучить когда понадобится, но лучше все таки знать, чтобы хорошо делать работу
И допускает обратную операцию дифференцирования. А еще у него есть много интересных свойств:
www.sfu.ca/math-coursenotes/Math%20158%20Course%20Notes/sec_VolumeAvgHeight.html
Добавлю еще. Метод позволяет быстро посчитать среднее значение на интервалах, что равносильно свертке с прямоугольной функцией, которая в свою очередь позволяет быстро найти приближение к свертке с гауссианом любой ширины(согласно предельной теореме) :)
Smoothed particles hydrodynamics- гидродинамика сглаженных частиц. применяется в GameDev-е для визуализации потоков жидкости и физики. Там диф-уры в частных производных в интегральной форме записи решаются.
Твердотельное моделирование (Компас-3D, SolidWorks, T-Flex etc.)- всякие огибающие и поиск точек касания- дифференциалов хоть отбавляй.
ЧПУ- если управлять «рукой» типа Куки- то там тоже дифференциальной геометрии с полярными координатами по самые помидоры. Гексапод без этой ерунды тоже ногами ровно дергать не сможет.
Периодически ради фана пишу моды для игр, математики в них на порядок больше:
Из того, что встречал/применял и что никогда не понадобилось в профессиональной деятельности: интегрирование, теория управления, мат.ожидание, собственно стереометрия, теория графов, конечные автоматы. Вот сейчас с симплекс-методом воюю… Конечные автоматы очень долго ждали своего часа, чтобы оказаться в списке «применено в том числе для рабочих задач».
В общем не хотите учить математику — идите в iOS разработку, тут вам ничего кроме геометрии не понадобится…
Вообще любая динамика, не обязательно в играх — тупо нормальная модель динамики спроса (но в итоге её всё равно к линейной приводят)…
А где там статистика может быть нужна?
Мне тоже так казалось до того как я попробовал обучить программированию своего брата. Выяснилось, что кроме умения читать книжки (о программировании) нужно ещё уметь мыслить как программист. А это навык, типа умения быстро бегать или боксировать, просто так, из воздуха не берётся. Несмотря на все наши попытки понять что такое массив и как его обрабатывать не получилось. Проблемы была в том, что братишка не мог в голове собрать как из мелких шагов на каждом этапе возникает целое решение.
Несмотря на все наши попытки понять что такое массив и как его обрабатывать не получилось.
Вариант для школьника: обычный двумерный массив — это морской бой.
Обработайте несколько матриц — одна твоя, другая противника.
Математика один из путей, допускаю, что работа историка по исследованию документов, поиску противоречий и построению непротиворечивой картины событий тоже тренирует нужный навык. У гипотетического двоечника проблемы могут возникнуть не с реактом и не с тем, чтобы прочитать кучу документации и туториалов. Ему может быть сложно понять что делает цикл for, как составить даже тривиальный алгоритм типа «переверни список», как соотносится между собой тело цикла и конечный результат работы.
Там на втором месте врач-педиатр, а еще есть медсестра.
Точно не для РФ и СНГ, у нас какой-нибудь педиатр — нищий.
Так что не совсем актуально в принципе.
Если поставить вопрос так: насколько нужен «чистый матан» (мат.анализ) программисту, то получили бы интересное исследование. Критерии сходимости рядов, разрывы функции, множества Парето, Слейтера и т.д.
Без хорошей школьной математики в программировании всегда будет. Всё-таки хорошая математическая база даёт преимущества в восприятии, написании, мышлении. В общем без математики никуда
Да уж. Когда въедливость и желание разобраться до сути во зло. Всё что требуется на начальном этапе — понять тот уровень абстракции, где надо просто верить в магию нижних уровней и жить с ней и продолжать разбираться с верхним уровнем.
Точно подмечено про магию. Так же и в математике сначала просто надо принять, почему на ноль делить нельзя например, а потом уже потихоньку начинаешь понимать почему нельзя. И вполне можно остановиться на уровне где деление на ноль просто магия которую нужно принять. В программировании также, есть решения и технологии которые просто работают и можно пользовать их не вникая как там все внутри устроено.
Неопределенности вида «0 делить на 0» учат разрешать в стандартном курсе анализа.
а почему не -∞?
lim_(x->0) 1/x = ∞
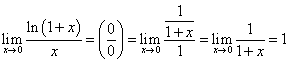
С таким же успехом можно делить 5 на апельсин и получить законное ведро гвоздей.
А на ноль делить нельзя.
Почему сразу врали? Все зависит от набора аксиом, задающих основу. А набор аксиом может зависеть от раздела математики или от выбранной математической модели.
В арифметике на ноль делить по жизни нельзя. Когда в школе говорят о невозможности деления на ноль, внезапно, проходят не математику вообще, а именно арифметику. И потому на самом деле никак нельзя.
Когда мы выходим за рамки арифметики, то получаем несколько иной базис (как минимум появляется понятие бесконечности), и уже тогда появляется возможность делить на ноль.
С параллельными прямыми такая же неувязка. У Евклида они не пересекаются. Пока мы в рамках евклидовой геометрии, это железобетонная истина.
А кое у кого очень даже пересекаются, но это уже совсем не евклидова геометрия.
А кое у кого очень даже пересекаются
А у кого-то их даже нет. Зависит, с какой стороны глобуса живёшь :)
А кое у кого очень даже пересекаются, но это уже совсем не евклидова геометрия.
Нет же, параллельные прямые не пересекаются по определению. Ни в какой из геометрий.
Нет же, параллельные прямые не пересекаются по определению. Ни в какой из геометрий.
Для некоторых видов геометрий, определение «паралельных прямых» некорректно в принципе, например в многомерных пространствах.
по этому они или не пересекаются или не верно сформулировано ваше выражение что «никогда по определению» поскольку надо указывать подробности их параллельности
Или вообще параллельные прямые становятся невозможными (в сферической геометрии).
Пес его знает.
Естественно, что далеко не в каждой неевклидовой геометрии имеются пересекающиеся параллельные прямые, но как-то случайно наткнулся на какую-то математическую модель, описывающую что-то, мне неведомое.
Зацепился сознанием за это и запомнил именно из-за параллельных прямых.
Во-первых, они вводились там как взаимно перпендикулярные третьей прямой (и назывались при этом именно параллельными).
Во-вторых, они не пересекались ни в какой из взятых на прямой точек, но однозначно пересекались в бесконечности (именно так, пересекались в бесконечности, оно там через предел как-то выводилось).
Кстати, еще немного о делении на ноль.
За пределами арифметики не везде можно делить на ноль.
Более того, кое-где в математике вообще деление не предусмотрено как класс.
Так что математика — она такая. Какой надо базис — такой и введут. И получат пространство с нужными свойствами. И будут люди, что не в теме, ужасаться и путаться, поскольку термины в этом пространстве будут знакомыми, но означать будут сущности с совершенно другим поведением (хотя и близкие "по духу").
Параллельность при этом остается синонимом непересекаемости.
Не обязательно. Скажем, параллельность по Лобачевскому — это частный случай непересекаемости. Через точку, не лежащую на прямой, можно провести бесконечно много прямых, не пересекающих данную, две из которых будут параллельными данной по Лобачевскому.
Причём, если пространство Лобачевского "распрямить" — то всё это множество непересекающих данную прямых "схлопнется" в одну прямую, параллельную данной и по Евклиду и по Лобачевскому.
там интересно получается
пусть у нас 2 продольных и n поперечных заборов. при любом n максимум площади будет при длине продольного забора равной 25. при n=2, это будет квадрат, но в задаче n=3
наилучшее соотношение площадь\периметр имеет квадрат, после круга, естественно
Ложное утверждение. Например, правильный шестиугольник лучше квадрата.
100 = 3x + 2y, где x и у — стороны совокупной конструкции.
Отсюда у = 50 — 1,5 х.
Дальше надо максимизировать величину х*(50 — 1,5*х), она же 50*х — 1,5 *х^2.
И здесь действительно надо взять от этого выражения производную. И приравнять ее к нулю. Это, насколько помню, учат в 11 классе.
Получится 50 — 3х = 0, т.е. х = 50/3.
y = 50 — 1,5x = 50 — 1,5*(50/3) = 25.
Итак, х = 16,667 и y = 25.
Дальше надо максимизировать величину х*(50 — 1,5*х), она же 50*х — 1,5 *х^2.
Если не сложно с этого момента можно подробнее. Не совсем понятно что Вы делаете. Все понятно до момента 50-1,5х=y
Чтобы найти максимальное или минимальное значение функции f(x), надо от этой функции «взять производную». Полученное выражение обозначают f`(x). И потом надо решить уравнение f`(x) = 0, тогда получим х, при котором экстремального значения достигает исходная функция f(x).
А чтобы взять производную от 50*х — 1,5 *х^2, надо знать формулу, по которой производная от a*x^b равна a*b*x^(b-1). Получается, что производная от 50*х — это 50, а производная от 1,5 *х^2 — это 3*х. А производная от всего выражения это как раз 50 — 3*х.
Дальше остается решить уравнение 50 — 3*х = 0.
для полной картины понимания Computer Science, мне необходимо будет заново учить алгебру, а затем и ВысшМат
Для полной картины даже этого не хватит… Я учился на ВМК, работаю в целом по специальности, и все равно — чем дальше, тем больше IT-направлений мне становятся непонятны и прямо-таки тяжелы для освоения.
Но чтобы стать средненьким программистом, этого понимания, в общем, не требуется. Базовые алгоритмы (хотя бы вслепую уметь писать сортировку) + решение задачек по предметной области (клепание форм, роутинг или куда там идёте) в общем и целом даст квалификацию на джуниора-мидла. А дальше уж посмотрите, имеет ли смысл жрать этот математический кактус… Сениору-архитектору это да, неплохо бы иметь технический склад характера + математический бекграунд.
PS: Я вот занимаюсь ИИ, так мне пришлось осваивать психологию и лингвистику. Тоже не фунт изюму…
Неужели чтобы стать программистом без технической базы, требуется так много времени?
Меня конечно вдохновляют статьи в интернете, где люди пишут, что за 1,5 года стали Java developer-ом и уехали в Германию, Канаду, США, однако оценивая свои печальный опыт я не уверен что такое возможно.
Ну, без описания начального уровня тут особо говорить не о чем. У меня был коллега, который имел опыта java разработки меньше, чем вы описываете (только курсы, де факто). Но придя на наш проект, он вполне вписался в работу, и примерно год вполне справлялся, в том числе писал например на скале. Но при этом у него, надо заметить, было примерно 10 лет опыта в другой области — 1С, т.е. скажем базы данных и SQL он знал вполне прилично. То есть, отсутствие опыта в самой разработке и языке/инструменте должно чем-то компенсироваться, как правило. Отсутствие знания математики — обычно тоже.
Германия тут кстати может упрощать дело — потому что дефицит программистов там вполне может быть больше, чем где-то в глубинке России, например, и если вы по остальным показателям проходите…
1С это ведь по сути VisualBasic с русским синтаксисом. Так что вполне язык программирования и навык качает. Пересесть с процедурного программированмя на ООП, не так и сложно. Особенно если практика ООП была в универе.
Я в общем то на своем опыте такое провернул. Спустя года 3 в 1с, может чуть раньше начал изучать не привязанные к языкам вещи, читал дядюшку боба, макконела, хабр, смотрел записи конференций, читал про ООП и паттерны. А потом, после еще полутора-двух лет перешел на котлин достаточно спокойно, даже с учетом что менторить некому меня было. Оценить трудно самому себя, но где то через месяц ушел от программирования в процедурном стиле, через месяцев 4-5 пошло более менее идиоматичное ООП, с элементами ФП. При наличии более опытных товарищей думаю быстрее бы прошла адаптация.
Вообще то там есть ООП, просто объекты фиксированы)
ООП это всякий там полиморфизм, наследование и т.п. там этого нет от слова совсем, то что там некоторые системные объекты «какбы» работают по принципам ООП, это не означает что оно там есть… этим же нельзя пользоваться
Такие выражения как: пределы, математическое мышление, экстремум, производные, многочлены и т.д. для меня оказались как речь на языке племени Майя.
Для 99% программ это не нужно.
Я сам не люблю и слабо понимаю математику, хотя и занимаюсь 3D графикой =)
Неужели чтобы стать программистом без технической базы, требуется так много времени?
Просто не нужно распыляться. Берите один язык и пользуйтесь им, любой.
А вот эта задача меня вообще заставила остановиться на чтении книги по CS
Какое отношение эта задача имеет к программированию? Никакого.
Качаю книгу Кернигана и Ричи «Язык С»
Вместо всяких курсов по CS и древних книг лучше обратите внимание на такую серию:
stolyarov.info/books/programming_intro
У меня, и многих моих коллег был путь снизу-вверх: от электроники к программированию.
Когда знаешь как работает железо, просто не может быть проблем с пониманием всех нюансов использования переменных/циклов/указателей.
.Для 99% программ это не нужно.
И вот на оставшийся процент и придется потратить 99% времени
Ни в одном учебном заведении электронику без математики не преподают.
Сначала просто математика. А потом уже электроника.
Керниган-Ритчи — великолепны. Не знаю как для взрослых, а для школьников отлично заходит для обучения азам.
.Паскаль в 2020 году это за гранью разумного
Почему? Вполне симпатичный язык для обучения. И полный по Тьюрингу естественно.
Почему? Вполне симпатичный язык для обучения.
Он депрекейтед.
У него плохой синтаксис.
Мы же не хотим чтобы школьники считали что их учат языку динозавров? Да и просто новичков не хотим учить вымершему языку.
Тем более что есть отличный Си. Живой, развивающися, на нем реально пишут продакшен софт, его синтаксис в основе примерно всего. На уровне обучения простейший. При обучении показываем немного самого простого сахара из плюсов и вообще хорошо. Страданий при обучении будет минимум.
И полный по Тьюрингу естественно.
Баш тоже Тьюринг полный. Но это же не повод его изучать первым?
Да и CSS Тьюринг полный. Это же не повод на нем писать программы?
en.m.wikipedia.org/wiki/Free_Pascal
Stable release 2 months ago
У него компактный компилятор, который легко спортировать на маленькую платформу
github.com/Clozure/ccl/releases
released this on 20 Apr
У него компактный компилятор, который легко спортировать на маленькую платформу
PS: Дельфисты атакуют. Вы хотя бы пишите что не так. Чем вам Керниган-Ритчи и Си как первый язык для обучения основам не угодил. Уже минимум пара поколений разрабочиков на них выросли.
Переход с Паскаля на Си без проблем, они весьма близки идеологически. Бейсик, тот да, ужасен. Сейчас я развлекаюсь с разным ретро, вот там Паскаль иногда заходит удобнее чем Си.
Ну а на работе конечно с++ only.
PS Паскаль это эпоха, это священная корова, наезжать на неё нельзя
Учить второй очень похожий язык вторым это потеря времени. Это для нас пара недель с синтаксисом ознакомится и можно писать. Все же одинаковое у них. Для начинающих это все сложно и требует кучу времени. Я бы вторым предложил учить Питон. И уже на нем преподавать весь остальной cs.
Так совсем хорошо выйдет и с парой Си/Питон уже любой язык будет знаком и похож на что-то уже выученное. (Любители Идриса проходите мимо, не про вас речь)
с я развлекаюсь с разным ретро, вот там Паскаль
Ключевое слово ретро. Не надо ретро учить первым. Потом как хобби да не вопрос. Но первым что-то живое нужно.
Более опытным программистам он очевидно удобней Паскаля, как минимум меньше букв в программе, но это достоинство на момент написания. Во многих областях до сих пор предпочитают весьма многословную АДА(у)
Переменные, циклы, структуры, указатели как самое сложное. И алгоритмы того же уровня. Пузырек и около того. 100 строк — предельный размер для программы. Их с любым стилем понять просто.
Свобода наоборот дает возможность поговорить с обучающимся. Почему он так сделал, а как еще можно сделать, а в чем разница? Красота же. Даже не углубляясь в тонкости в правильно написанной программе есть о чем поговорить.
Стиль это все потом. Тут что IDE сделает то и хорошо. Какой-нибудь MSVC вполне прилично все делает.
Для чего нужен первый язык — для связи бумажной алгоритмики с реальным программированием. В первом языке не должно быть свободы — он ДОЛЖЕН быть дубовым. Чтобы не отвлекаться на синтаксис, а заниматься непосредственно творчеством.
Какая радость для начинающего от возможности обратится к массиву пятью различными способами? Или написать инкрементацию тремя?
С Сями можно потратить полчасика на рассказ про git и помигать лампочками на ардуинке.
Какая радость для начинающего от возможности обратится к массиву пятью различными способами? Или написать инкрементацию тремя?
Вы тех же Керниган-Ритчи читали? Сначала рассказывается про один способ. Лабы, практика, вперед.
Все остальное в разделе указатели. Понимание что такое указатель приходит очень долго и очень тяжело. И чем больше примеров и того что можно пощупать в этом месте тем лучше.
С Сями можно потратить полчасика на рассказ про git
Если речь про обучение программированию с нуля в школе, то никак вы за полчасика с гит не разберётесь.

Тут важно что это Си. Живой, массовый и сложный проект. Учим не мертвому языку дедов, а живому на котором пишут живые проекты.
Quicksort, например, из 1960-х. Я так понимаю, вы его тоже будете рекомендовать не использовать? :)
Пффф, вы не видели глубин изобретательности, до которых могут дойти люди, поставившие себе четкую цель не использовать контроль версий.
Вы переоцениваете возможности обычных учеников. Я раньше на курсах всегда уделял час, чтобы рассказать основные команды гита. Более того, я даже сделал методичку с картинками, чтобы можно было с ее помощью дома все повторить.
Но так у меня сбежало 2 ученика. В обратной связи оставили "я даже не могу понять как сохранять проект, куда мне изучать программирование?".
Поэтому я гит даю только тем, кто умненький и не раньше второго занятия.
Вы мешаете в кучу язык для обучения и язык для разработки.
Язык для обучения должен быть неудобен. Он должен постоянно заставлять выкручивать мозги. Он обязан содержать минимум инструкций. Он должен научить человека программировать что угодно при помощи говна и палок.
Тут как в армии, на курсе молодого бойца: -«Любой дурак выкопает окоп лопатой. А ты сумей ножом и руками. Сумел? Потом выкопаешь чем угодно»
Не помню кто сказал что люди делятся на тех, кто программирует и тех кто нет. Те, кто программируют, могут программировать что угодно — от древней релейной логики до трассировки лучей на новейших видеокартах.
Поясню на примере: чего может быть проще перебрать массив от большего индекса к меньшему. Это если счетчик в цикле может уменьшатся. А если нет, только расти? Это для вас это проще чем элементарно, а для начинающего — интеллектуальный оргазм. Или выбрать каждый третий элемент, а приращение в цикле возможно только на единицу.
Или узнать величину файла не через запрос к системе, а через посимвольное считывание до достижения конца файла.
С точки зрения продакшена язык для обучения ужасен.
Но язык обучения не предназначен для разработки, хотя такое тоже встречается.
Впрочем, машина Тьюринга тоже сойдет.
Без глубоких заходов в IDE и библиотеки. С учтом того, что на С++ писали в Борланд билдере — правильно что без заходов.
В общем случае — это просто замена кодов машинных команд некими символьными обозначениями для облегчения запоминания.
Соответственно, все упирается в умения «процессора» (то есть исполнителя команд), его набор команд. Если это исполнитель умеет делать 100500 различных действий, закодированных каждое в свою команду (например, одной командой посчитать факториал, интеграл, переместить/скопировать целый блок памяти и т.п.) — то программирование на его ассемблере получается весьма высокоуровневым.
Машина Тьюринга — это абстрактная штука, чтоб говорить о ней предметно, нужно задаться какой-то конкретной реализацией. Так что рассмотрим очень похожую машину Поста. У нее всего 6 команд и унарная система счисления. Уже банальное сложение и вычитание двух чисел на ней — небольшая головоломка, в то время как почти любой процессор, программируемый на ассемблере, умеет это делать аппаратно.
Язык для обучения должен быть неудобен. Он должен постоянно заставлять выкручивать мозги. Он обязан содержать минимум инструкций. Он должен научить человека программировать что угодно при помощи говна и палок.
Вы принципиально путаете
1) обучение на профессионального хакера (в реймондовском смысле),
2) обучение на программиста вообще,
3) обучение на не-программиста с навыком автоматизации с помощью компьютера.
Ваш подход годится для (1) и изредка для (2), в то время как на них вообще статистически не нужно тратить усилия — сами обучатся — а основные методики надо нарабатывать для (3), потому что критична массовая компьютерная неграмотность.
Язык для обучения должен быть неудобен. Он должен постоянно заставлять выкручивать мозги. Он обязан содержать минимум инструкций. Он должен научить человека программировать что угодно при помощи говна и палок.
Это уже продвинутый уровень обучения, никак не начальный. Обучение борьбе начинается с простейших примитивных бросков, а не со сложных приёмов, которые даже не каждый КМС успешно выполнит.
Да, явная типизация может помочь в обучении, но жить без неё вполне можно (тем более, что в современном питоне есть опциональные аннотации типов). А вот без быстрого старта язык непригоден для большинства.
Любая магия, непонятная на старте, сильно отбивает охоту учиться, особенно у школьников, у которых нет дополнительных источников мотивации.
В своё время я, изучая книжку по Паскалю, тупо забил на работу с графикой (прочитал книжку, т.к. любил читать, но программы с использованием графики не делал), т.к. не понимал смысла нескольких строчек, необходимых для инициализации (работа с драйверами и т.п.) и лишь где-то через год, когда почитал подробнее про устройство PC, у меня вновь появился интерес к соответствующему разделу книги.
На кружке по изучению ардуинки можно использовать си, т.к. там программирование не является единственным направлением изучения (да и с вводом-выводом не приходится сталкиваться). Но для изучение именно основ программирования школьниками, си не очень подходит, т.к. способен отбить интерес прямо на старте.
Сравните write/writeln/read/readln, доступными из коробки в паскале.
Сравнил.
Почему write(a, b, c), где a, b, c типа real, и в то же время write(out, a, b, c), где a, b, c типа file? Как мне различить эти конструкции? Что будет, если я вызову write(a, b, c, out)?
В C было сразу понятно — есть printf с stdout, а есть fprintf с конкретным файлом (и можно тоже указать stdout).
Почему надо было писать write(a:15:3), что это за конструкция? Почему тут особый случай и почему я не могу сделать свою функцию с таким же? (Реально хотелось, как раз как переходник для вывода результатов.)
Почему в конце программы "end.", а не "end;"?
Почему перед else нельзя ставить точку с запятой, а перед end — можно, но она ни на что не влияет?
Почему var перед программой (процедурой, функцией) и почему один на все переменные?
Почему в списке формальных параметров var вдруг начинает значить передачу по указателю (или in-out, не помню точно)? Почему не отдельное слово?
Почему такое резкое отличие между procedure и function?
Зачем возможность вызова функции или процедуры просто по их имени, без скобок? (Сравнивая с современными, Паскаль ни капельки ни ФП, чтобы это можно было оправдать.)
И ещё два десятка подобных недоумённых вопросов, но, думаю, уже достаточно.
это запредельное количество синтаксических конструкций на старте, смысл которых невозможно объяснить человеку, который только-только начинает изучать язык.
Вот для меня как учившего оба в конце 80-х — в Паскале было больше подобных непонятных конструкций, которые надо было зазубрить без понимания их причины, чем в C, и они были каждая сама по себе непонятнее.
Сам же принцип "надо добавить определённые заклинания" был понятен с первого упоминания. Люди же здороваются и прощаются, так и тут...
Вы просто натягиваете опыт C на Паскаль, из-за чего и возникает недопонимание. Забудьте C, и тогда Паскаль станет простым и логичным языком.
Почему write(a, b, c), где a, b, c типа real, и в то же время write(out, a, b, c), где a, b, c типа file? Как мне различить эти конструкции? Что будет, если я вызову write(a, b, c, out)?
Только в отличие от C, где вы в printf можете запихнуть вообще всё, что угодно, выстрелив себе в ногу, в Паскале всё строго типизировано. Вы никак не сможете передать аргументы типа file в качестве параметров, кроме первого.
Почему надо было писать write(a:15:3), что это за конструкция? Почему тут особый случай и почему я не могу сделать свою функцию с таким же?
Потому что Write в Паскале — это compile-time конструкция. Так решили авторы языка. И если бы в Паскале был C-style printf, то он бы тоже был compile-time с проверкой типов аргументов при компиляции и без возможности генерации строки форматирования в рантайме.
Почему в конце программы "end.", а не "end;"? Почему перед else нельзя ставить точку с запятой, а перед end — можно, но она ни на что не влияет?
Потому что ; в C — это признак конца выражения, а в Паскале — разделитель между выражениями в блоке. Оба подхода имеют право на жизнь.
Почему var перед программой (процедурой, функцией) и почему один на все переменные?
Не забывайте, что Паскаль — язык для обучения азам. В С можно себе выстрелить в ногу, объявив scoped-based переменную с тем же именем, что и внешняя переменная. А ещё в C можно случайно перепутать вызов функции, объявление функции и объявление переменной.
Почему в списке формальных параметров var вдруг начинает значить передачу по указателю (или in-out, не помню точно)? Почему не отдельное слово?
А хрен его знает. Видимо, чтобы не плодить ключевые слова.
Почему такое резкое отличие между procedure и function?
Скорее, больше бесит, что функция не может вернуть record. И вызов без скобок тоже бесит, да.
Забудьте C, и тогда Паскаль станет простым и логичным языком.
Сколько ещё и каких нормальных языков я должен забыть, чтобы кривости Паскаля стали "простыми и логичными"?
Большинство языков таких тараканов не держат. Хотя можно сравнить этот write/writeln, например, с C++, где на шаблонах ещё и не такое можно построить (например, у парсеров на Spirit несколько разнотипных аргументов шаблонов в любом порядке)… но там юзер уже заранее готов к подобным шуткам, в отличие от тех, кто вообще впервые учится Паскалю.
(Заметьте, я сказал и про плюсы Паскаля. Но они не сыграли в его пользу, чтобы он выжил.)
Вы никак не сможете передать аргументы типа file в качестве параметров, кроме первого.
Почему собственно? Может, я хочу, чтобы напечатало тип аргумента и основные свойства как файла (имя, режим открытия и т.п.)?
Но главное таки не это, а то, что:
1) Эти якобы функции на самом деле не функции, а похожий механизм, но разбираемый компилятором,
2) Я не могу сделать такое же своими средствами, это нерасширяемый хак компилятора.
Если бы их не оформляли в виде "типа функций", это было бы честнее. Если бы дали аналогичное средство самим, это было бы полезнее и для учёбы, и для продуктина.
Потому что Write в Паскале — это compile-time конструкция. Так решили авторы языка. И если бы в Паскале был C-style printf, то он бы тоже был compile-time с проверкой типов аргументов при компиляции и без возможности генерации строки форматирования в рантайме.
Ну так где оно? Почему недоступно? Почему я не могу сделать свой write?
Ах, "язык для обучения"… ну так язык, который пригоден только для обучения, не будет в итоге вообще использоваться для обучения.
Видимо, поэтому в Delphi в итоге сделали впараллель C-подобный подход.
Потому что; в C — это признак конца выражения, а в Паскале — разделитель между выражениями в блоке. Оба подхода имеют право на жизнь.
С таким подходом любая глупость "имеет право на жизнь", хотя бы в качестве легаси.
Но если мы думаем о побочных эффектах решения, то вариант с разделителем имеет их сильно больше, и это от языка не зависит.
То же самое относится к необязательности блоковых скобок.
Скорее, больше бесит, что функция не может вернуть record. И вызов без скобок тоже бесит, да.
Тип возврата — да, проблема (в C это тоже полу-костыль).
Вот с таким кодом поработать и Паскаль за счастье будет

Позиционирование здесь не прихоть разработчика, а требование языка. Каждая буковка, каждый символ должны стоять строго на своем месте. В редакторе вверху даже линеечка есть с разметкой что куда позиционировать.
Каждая буковка, каждый символ должны стоять строго на своем месте.
Ну судя по строке 37 (3700, если по разметке) и дальше, не всё так жёстко? Или тут две разные разметки?
Я писал на стандартном (фиксированного формата) Фортране, и не сказал бы, что это какой-то существенный ужас. В RPG меня больше напрягает сама логика языка — что и как делается — а не его конкретное представление. Не хочу выворачивать мышление на эту логику, для моих задач не окупится :)
Я плоховато fixed знаю (ну так скажем, на уровне чтения немного) и не помню уже что такое O-секция. Что-то связанное с выводом. Судя по всему — внешний источник для вывода с расписанными полями.
Не помню чтобы в наших старых такое встречалось.
Сама логика, особенно во FREE особо не напрягает — язык и язык. Она несколько отличается от общепринятой, но вся AS-ка отличается от привычного :-)
Что неудобно на RPG — пишу на С/С++.
У меня вот сейчас в задаче один из PGM объектов собирается и 15-ти модулей. Из которых пара SQLRPG, штуки три CPP остальные RPG
Давайте начнём хотя бы с того, что Паскаль появился на пару лет раньше С. И для языка, которому исполнилось уже 50 лет и который дошёл до наших дней практически в неизменном виде — это отличный результат.
Конечно, современные языки избавились от многих проблем, но вот выделить среди них хороший язык, который хорошо подходит для обучения программированию, я затрудняюсь. У всех имеются различные проблемы.
И для языка, которому исполнилось уже 50 лет и который дошёл до наших дней практически в неизменном виде — это отличный результат.
В практическом применении (которое надо с микроскопом искать) остался разве что Delphi, который очень изменился по сравнению с Паскалем 1970-го года. Поэтому нету ни "неизменного вида", ни "отличного результата": результат ужасный — язык вымер, причём завалив всю цепочку потомков (разве что Ada выжила на госзаказах).
Конечно, современные языки избавились от многих проблем, но вот выделить среди них хороший язык, который хорошо подходит для обучения программированию, я затрудняюсь. У всех имеются различные проблемы.
По сравнению с языком, который для этого уже не менее 20 лет не подходит, они все относительно неплохи. Python в этой роли разве что ленивый не предлагал. Я вот ещё смотрю на Swift.
язык вымер, причём завалив всю цепочку потомков (разве что Ada выжила на госзаказах)
Ада жива в PL/SQL
В практическом применении (которое надо с микроскопом искать) остался разве что Delphi, который очень изменился по сравнению с Паскалем 1970-го года
Дельфи также примерно обратно совместим с Паскалем, как С++ с обычным C.
PS цепочка начинается ещё с Алгола! habr.com/ru/post/317010
Так совсем хорошо выйдет и с парой Си/Питон уже любой язык будет знаком и похож на что-то уже выученное.
Да они ведь во многом похожи как языки, на базовом уровне. Те же переменные, if/for/etc, функции, etc — разница в чуть другом стиле синтаксиса и явном указании типа в Си. Паскаль и иже с ним туда же.
Если говорить о разнообразии, то есть множество используемых языков, которые намного сильнее отличаются — из относительно популярных например скала/f#/лиспы/хаскель.
А вот нужно ли разнообразие при обучении программированию — зависит, думаю, от уровня. Не вижу особой проблемы начинать с паскаля в школе, кто заинтересуется изучит и другие.
Да они же во многом похожи как языки, на базовом уровне. Те же переменные, if/for/etc, функции, etc — разница в чуть другом стиле синтаксиса и явном указании типа в Си. Паскаль и иже с ним туда же.
Это приходит через годы регулярного написания кода. До этого все сложно. Питон удобнее всего чтобы обучать именно CS.
Си быстро придут к плюсам при попытках учить на них. А плюсы сложны сами по себе, даже без всего остального. Люди будут одновременно мучаться с пониманием принципа работы хешмапы и с тем как это написать.
Не надо вываливать на человека сразу все. Пусть учит все по отдельности.
из относительно популярных например скала/f#/лиспы/хаскель.
Хотя бы полгода Коммон Лиспа курсе на четвертом это хорошо и полезно. Но не раньше. Человек перед изучение должен уметь код писать. Обычный и простой код.
Мы тут про азы. На чем рассказывать про циклы с переменными и на чем первый пузырек писать.
Хотя бы полгода Коммон Лиспа курсе на четвертом это хорошо и полезно. Но не раньше. Человек перед изучение должен уметь код писать. Обычный и простой код.
Мы тут про азы. На чем рассказывать про циклы с переменными и на чем первый пузырек писать.
Есть какие-то исследования, что условный питон эффективнее для начального обучения программированию, чем условный лисп? По-моему это совершенно неочевидно. Конечно, если речь не идёт о курсах типа "дата саенс за 21 день".
Берем 2 группы студентов технарей.
Считаем что они обучены простейшим вещам и ничего кроме них. Одну группу учим Хаскелю и cs на нем. Вторую Питону и cs на нем. Через год и через два года подбиваем результаты.
Вылетел 1 балл.
Попытка самоубийства 100 баллов.
Были какие-то исследования о том, что с функциональных языков вроде как неплохо начинать, но это всё довольно ненадёжно, и людей жалко, опыты такие проводить.
Ну а как вы себе это представляете? Берём студентов и начинаем экспериментировать с их жизнью, а если провал — ну ничего, новые через год придут?
хм. а почему нет-то? вы предлагаете ровно так же экспериментировать со всеми студентами, обучая их только по одному варианту (ведь неизвестно же, что он лучший).
При выборе языка программирования в школе/университете самый простой критерий — это смотреть, какие языки по факту востребованы на рынке, а из них уже выбирать объективно наименее навороченные. То есть можно для начала воспользоваться другими критериями, «простота обучения» не единственный из них.
Если же продвигать идею «а давайте обучать на языке X; пусть он непопулярен, зато проще для обучения», то надо сперва доказать, что он и вправду проще, потому что иначе в этой идее совсем смысла нет.
Если же продвигать идею «а давайте обучать на языке X; пусть он непопулярен, зато проще для обучения», то надо сперва доказать, что он и вправду проще, потому что иначе в этой идее совсем смысла нет.
хм, я бы говорил не про «проще для изучения», а про «лучше для обучения».
При выборе языка программирования в школе/университете самый простой критерий — это смотреть, какие языки по факту востребованы на рынке, а из них уже выбирать объективно наименее навороченные.
в раннем возрасте — не вижу ничего плохого в специальных языках для обучения.
читать дети тоже не по «Войне и миру» учатся, для этого придумали азбуки и красочные книжки с минимумом текста.
в университете — наверное, да, тут подразумевается, что начальные навыки программирования уже есть, можно выбирать из востребованных на рынке (и почему менее навороченные?).
впрочем, не вижу ничего плохого в изучении какого-то академического языка в университете (разумеется, знакомство с «реальными» языками при этом обязательно). впрочем, многие проекты, начинавшиеся как академические, со временем находят себе применение и в «гражданской жизни».
про «лучше для обучения».
Да пусть так. Осталось выяснить, как понять, какой же лучше.
не вижу ничего плохого в специальных языках для обучения.
Я тоже. К сожалению, они по факту все вымерли, ну вот разве что Scratch есть, но это всё-таки немного другая лига.
Осталось выяснить, как понять, какой же лучше.Если брать «программирование вообще», то максимально отвязанный от железа: лисп, тикль, питон или ещё что-то выразительное, но очень медленное.
Вот условно 30 лет назад такой опции не было: либо чисто учебный Бейсик, либо «туда-сюда» Паскаль, либо уже по хардкору с головой в C/С++ и иже с ними.
ненамного хуже «любого другого языка», и при этом очень популярен на практике.Это да. Но именно как учебный мне больше нравится лисп, просто потому, что на нём в силу единства данных и кода можно сделать вообще всё, и это будет достаточно лаконично. Своя система типов? Своё ООП с плюшками? ФП? Рекомендательные системы? Логическое программирование? Всё это можно реализовать в сотни-тысячи строк поверх ванильного лиспа. Тикль, внебрачный сын плюсов и лиспа, кстати, всё это же поддерживает, просто там синтаксис ещё более мутный. А вот как в питоне, например, перейти от ООП на классах к ООП на прототипах я вообще не пойму.
EDIT Правда, если учить студентов ближе к индустрии, то принцип «Если на текущем ЯП тебе приходится вывихивать мозг над задачей, а на другом ЯП это три строчки, пиши на другом плюс биндинг» придётся внушать. Питон изначально разрабатывался как язык — универсальный клей, так что тут он в самую тему.
Типов нет же.
Что, сегодня отменили? Вчера ещё были.
PS: да, я понимаю. Но давайте строже в деталях. Динамичность как раз достаточно мало мешает учебным задачам.
Скиньте, plz. Уложу в коллекцию.
Вообще, не то, чтобы я не был согласен — я как раз считаю, что расставлять статичность по максимуму (кроме явно огороженных мест) оно полезно всегда. Но чувство — не доказательство.
Даже в вашей цитате последней фразой написано, что использование термина "динамическая типизация" является стандартом :) И по факту непонимания (почти?) никогда не создаёт.
Привязывание более строгой терминологии, чтобы она покрывала все имеющиеся случаи, кажется весьма затруднительным. Например, по приведённой цитате не особо понятно, что означает "tractable syntactic method" или "static approximation [of behaviour]". Как к этому относиться в случае языка, который позволяет тьюринг-полные вычисления на уровне типов/во время компиляции? А если язык типа C# вроде бы статически типизированный (кроме "dynamic"), но с помощью reflection во время выполнения можно много чего нагородить?
Так-то хаскель читать полезно, кто б спорил. Но в качестве первого языка, на мой взгляд, идея так себе.
записи вида n = n + 1 ломали им мозг
А что тут мозголомного?
Есть коробочка на которой написано «n», и мы кладём туда +1 предмет.
так что для неподготовленного читателя тут написано «n равно n + 1».
так если человек учит программирование, особенно на нормальном языке, там в самом начале проходят операторы, и что бывают логические (типа ==) и операторы присваивания (пресловутое =)
Тут кстати на лицо проблемы проектирования которые тянутся из… языков типа си и бейсик, хотя логичней взять было паскаль для подобных конструкций
p.s. не помню кстати у себя проблем с такими выражениями
n := n + 1
Но потом решили, что и просто '=' понятно.
:)
Добавлю, что частое заблуждение в связи с присваиванием в виде "a = b + c" что "a" это нечто, что вы бы называли функцией. Это нечто не хранит значение, а вычисляется в момент использования, используя значения из "b" и "c". Думаю это заблуждение как раз идет из школьной алгебры или физики.
Поэтому "a = a + 1" — конструкция, которая всегда вызывает вопросы "а так разве можно?".
Это заблуждение возникает поголовно у всех, с кем я занимался с "честного" нуля.
Ага. Вот что делает следующая конструкция?
if (n = n + 1) { ... }Несмотря на то, что побочное действие оператора присваивания бывает иногда полезно и удобно, оно является источником ошибок.
Я не могу вспомнить быстрый выразительный язык.
А как же ванильный C?
Какие критерии?
Можно начать рассматривать со Swift или Go.
OK. Против Swift есть претензии?
Я ещё смотрю на старых зверей типа Java и на всякие Julia.
с вкраплениями магии
а где там магия?
1. Отсутствие беззнаковых целых. С 1.8 шаманство для их реализации проще, но всё-таки шаманство
2. Древнее развесистое дерево наследования, часть из которого deprecated, а в остальном можно запутаться. Как итог — введение стирания типов. Очень долго бегали от void* и каста к Object, а в итоге пришлось-таки сделать нечто подобное. Ну и единственный корень у дерева наследования мне не нравится, но это уже вкусовщина.
3. Невозможность просто сделать неизменяемый массив-член класса. Слово const зарезервировано, но использовать его нельзя :)
В последние годы появилось достаточно много "быстрых выразительных" языков для разных сфер применения. К предыдущему комментатору добавлю julia.
Я не смогу это доказать, но подозреваю, что благодаря JIT компилятору многие языки на платформе Java вполне дадут питону фору в производительности (если мы не говорим о пакетах для питона, написанных на самом деле на C/C++).
Я не смогу это доказать, но подозреваю, что благодаря JIT компилятору многие языки на платформе Java вполне дадут питону фору в производительности
То, что это так — к гадалке не ходи — в Питоне слишком много тратится на постоянную проверку типов, лукапы по словарям методов и т.п. Так что ускорение раза в 5-10 от их исключения вполне можно предсказать. Но вот точные цифры будут катастрофически зависеть от задачи. Мои текущие это в основном общение со сложными объектами с развесистыми атрибутами… на них, может, больше 5 и не выйдет. На математике, понятно, и 1000 может быть (но её и так всю переложили на numpy с продолжателями).
читать дети тоже не по «Войне и миру» учатся, для этого придумали азбуки и красочные книжки с минимумом текста.Но читать дети учатся все-таки сразу именно на реальном языке, а не придумывают для этого специально искусственный. А азбуки и красочные книжки — это аналог «Hello World» и подобных простых учебных программ, но не другого языка.
Ну а как вы себе это представляете? Берём студентов и начинаем экспериментировать с их жизнью, а если провал — ну ничего, новые через год придут?
Так иного варианта-то нет. Так и экспериментируют, только (почти) никому не говоря, что это эксперимент. Если у вас есть маховик времени из саги про ГП — можно попробовать часть студентов учить впараллель. Но ведь его нет?
Просто начинают с относительно небольшой группы и пытаются по ней оценивать, стоит ли расширять эксперимент… (в лучшем случае)
А если вы, условно, флагман типа MIT, там можно попытаться, но тоже не знаю, кому там подобные телодвижения интересны
хорошо, что не все рассуждают так, как вы
Люди туда работать идут не ради того, чтобы выяснять, первокурсник лучше освоит лисп или питон.
нет, конечно, они приходят с убеждением «XXX лучше», спорят друг с другом, пробуют доказать верность своего подхода, пишут по этому поводу научные работы…
что такого рода научная работа не представляется мне особенно интересной.
А она и будет составлять 1% от того, что делается в нормальном университете — но она должна выполняться, иначе там так и будут преподавать Паскаль вместе с программированием для ЕС ЭВМ на перфолентах.
ЕС-ЭВМ, по вашему
Я как раз хорошо отличаю, где ЕС ЭВМ, а где современный zSeries.
программистов не хватает. ;-)
Платить не пробовали, простите за резкость?
За деньги даже на RPG будут писать без особого плача.
Так платят… Но все умчались в стильно-модно-молодёжно, аджайл-кубернетис-девопс и прочие смузи. А серьёзные машины это типа кровавое легаси
Это точно. Платят. Не золотые горы, но вполне себе «по рынку».
Но тут нет модных фреймворков — нужно активно работать головой и руками.
И может придти вот такое:
Из PEX статистики работы XXXXXXXXX видно, что 33% времени и 36% ресурсов CPU тратится на выполнение QSQRPARS в программе YYYYYYYYY, т.е. парсинг статических выражений при подготовке SQL запроса.
Сократить данные ресурсозатраты практически до нуля можно путем описания параметров sql запросов через SQL Descriptor Area (SQLDA).
Поскольку NNNNNN один из наиболее активно используемых сервис модулей, необоснованное повышенное ресурсопотребление является малодопустимым. Просьба инициировать доработку YYYYYYYYY.
Причем, «описание параметров sql запросов через SQL Descriptor Area» в данном случае невозможно, поскольку запрос содержит конструкцию WHERE FIELD IN (VALUES LIST), где VALUES LIST генерируется «на лету» при каждом вызове программы. А такая вещь не параметризируется.
И вот конструкции типа
SELECT DISTINCT ELWWRD FROM ELWPF
LEFT JOIN EWFPF ON ELWWID=EWFID
WHERE EWFEWF IN (...) AND EWFTES='N'и
SELECT ELWEID, ELWSPE FROM ELWPF
WHERE ELWWRD IN (...) and ELWTES='N'
GROUP BY ELWEID, ELWSPE
HAVING COUNT(*)=MAX(ELWCNT)приходится переводить на «нативный» RPG (с чтением записей из файла по ключу типа
chain (curWrd: 'N') ELW30LF;
А все distict, group by, having count эмулировать вспомогательными средствами (в моем случае хорошо сработали сортированный список уникальных значений и список на основе SkipList для пар ключ-данные).
В результате все работает чуть быстрее и нагрузка упала:
Тестирование проведено в копии пром среды, запуск СМ осуществлен 34648 раз.
Среднее время получения ответа, при запуске СМ:
Текущая версия функционала (копия в пром среды от 25.01.2020) — 7.98 м. сек
Обновленная версия, СМ — 6.71 м. сек
Рессурсовзатратность QSQRPARS уменьшилась до незначительных показателей.
О них на модных митапах, видимо, как-то стыдновато рассказывать
Ну у нас свой митап есть :-) Начиналось с вутреннего «слета разработчиков EQ», с прошлого года выросло до IBM i DevConf
Трансформируется опыт разработки, не кодирования, а именно разработки. Умение правильно выбрать архитектуру, умение эффективно использовать ресурсы…
Из личных устриц. Был опыт разработки гетерогенных распределенных многопроцессных систем с гарантированным временем отклика. Это область близкая к промышленной автоматизации. А потом ушел в банк. Во-первых, опыт (на уровне интуиции) нахождения эффективных решений весьма пригодился — здесь чато приходится решать задачи на оптимизацию старых модулей к которым есть вопросы со стороны сопровождения в плане потребления ресурсов. Во-вторых, как-то попалась задачка где надо было с сжатое время обработать несоколько десятков миллионов объектов. Вот там очень помог опыт разработки мультипоточных и мультипроцессных систем с организацией обмена данных между потоками/процессами (в том числе опыт распараллеливания обработки данных в batch машинах).
Даже опыт работы с конечными автоматами и то пригождается иногда. Просто видишь задачу и сразу понимаешь что вот тут можно это использовать, там то…
И от языка и платформы это не зависит от слова совсем никак. Это общие, как ныне модно выражаться, паттерны. Которые ты или знаешь как использовать, или вообще при них ничего не слышал.
В общем, опыт — это не знание конкретного языка/фреймворка/платформы — это как раз нарабатывается быстро (я за полтора месяца вышел на уровень решения несложных боевых задач на IBM i на RPG хотя до того всю жизнь писан на С.С++ под винду, а придумать более разные платформы сложно).
Опыт — это прежде всего понимание даже не как надо, а как не надо решать ту или иную задачу. Общие подходы, которые формируются в голове еще до того, как напишете первую строчку кода.
Если ко мне на собеседование придет человек и начнет рассказывать как он круто знает буст, я найду что у него спросить :-) Безотносительно буста или какого-то конкретного языка или фреймворка.
Например попрошу набросать план для распараллеливания обработки 50млн объектов, каждый из которых тянет за собой еще десяток связанных объектов. Ну такие простенькие вопросы — как равномерно распределить нагрузку по обработчикам, как организовать обмен данными между процессами и т.п.
Мне не интересует из каких кирпичиков человека научили лепить результат — на барабане можно и зайца научить играть. Меня интересует умеет ли он думать головой и понимает ли какие грабли разложены в той же параллельной обработке данных.
Или еще можно попросить набросать архитектуру распределенной гетерогенной системы. С минимальными задержками в передаче информации с одного края на другой и обратно и гарантией сохранности этой информации и гарантией ее получения на другом конце.
Есть и еще более забавные задачки. Недавно вот на комбинаторику была — в записи 10 полей. Нужно составить все возможные их комбинации. Товарищ очень изящно ее решил.
Или вот такое — 15 программ. Первой может быть запущена любая из них (с передачей некоторого набора параметров). Из нее может вызываться также любая из оставшихся. Как это реализовать чтобы избежать ситуации когда
PgmA -> PgmB -> PgmC -> PgmA
т.е. не должно быть дублирования программы в коллстеке.
Вопросы из жизни все. Есть и еще. И много. Могу задачник уже делать.
Есть и еще более забавные задачки. Недавно вот на комбинаторику была — в записи 10 полей. Нужно составить все возможные их комбинации. Товарищ очень изящно ее решил.Такие вопросы программисту я бы даже постыдился задавать.
Или вот такое — 15 программ. Первой может быть запущена любая из них (с передачей некоторого набора параметров). Из нее может вызываться также любая из оставшихся. Как это реализовать чтобы избежать ситуации когда
Мне теперь стало интересно, у вас есть какой-то принципиально другой способ решать задачи на комбинаторику, не используя циклы?
Или вам просто конструкция цикла не нравится и вы ожидаете чего-то вроде итераторов или джойнов?
Но там есть внешний цикл по количеству полей, для которых нужно собрать возможные комбинации.
Ну предположим, есть поля A, B, C, D, E, F.
Один раз мы вызываем функцию с набором из всех пяти полей, в другой раз из трех — A, C, E
Это количество полей будет определять внешний цикл.
Будет еще внутренний цикл, он определяется количеством записей в таблице.
Ну и еще один цикл, его параметр будет переменным, это количество уже собранных наборов.
Все. Три цикла для любого количества полей. хоть 3 поля, хоть 30.
Будет еще внутренний цикл, он определяется количеством записей в таблице.
В какой таблице?
Ну и еще один цикл, его параметр будет переменным, это количество уже собранных наборов.
Зачем нам цикл по уже собранным наборам?
Покажите код, пожалуйста, действительно интересно. Из словесного описания пока что не складывается в чем смысл решения.
Был человек в статусе стажера (это 20 часов в неделю, фактически полставки). Пришел к нас совсем нулевой, без никакого опыта (сейчас уже крепкий миддл, достаточно способный парень).
Ну и дали ему задачку. Есть таблица в которой N полей и M записей. Коллеге потребовалось (не помню уже зачем, вроде бы что-то с тестами связанное) список строк, в которых были бы все возможные комбинации полей типа такого:
Поле1.Запись1 Поле2.Запись1 Поле3.Запись1…
Поле1.Запись1 Поле2.Запись1 Поле3.Запись2…
…
Поле1.Запись1 Поле2.Запись1 Поле3.ЗаписьM…
…
Поле1.Запись1 Поле2.Запись2 Поле3.Запись1…
Поле1.Запись1 Поле2.Запись2 Поле3.Запись2…
…
Поле1.Запись1 Поле2.Запись2 Поле3.ЗаписьM…
…
Поле1.ЗаписьM Поле2.ЗаписьM Поле3.ЗаписьM…
ну и так далее…
Количество полей и записей… ну пусть будет 5 полей и 20 записей…
Код приводить не стану — под рукой нет, да и мало чего скажет — RPGLE на IBM i
Но суть была такая (примерно). Товарищ взял две штуки DataQueue (очередь данных, есть такой системный объект на IBM i). Сначала заполнил первуою очередь всеми возможными значениями Поле1.
А потом цикл по оставшимся полям — берем элемент из очереди 1 и приписываем к нему все возможные значения (по количеству записей) очередного поля (со второго и далее). Полученные N-1 элементов записываем в очередь 2.
Когда очередь 1 становится пустой, меняем местами очереди (та, что была 2, стала 1 и наоборот) и переходим к следующему полю.
На выходе получаем очередь, где содержатся искомые строки.
В итоге — один начальный цикл инициализации очереди по количеству записей 1..M
Затем внешний цикл по количеству полей 2..N и две внутренних — по текущему количеству элементов во входной (а данном этапе) очереди и по количеству записей 1..M
Плюсом — функция параметризуется — на вход можно подавать набор полей по которым нужно строить комбинации. Сам алгоритм не завязан ни на количество полей, ни на количество записей.
У нас 1.8Тб только оперативки. А так — одноуровневая память с 64-разрядной адресацией. И 16Гб на задание (JOB)
Любая задача решается в контексте платформы на которой она решается. В нашем случае портабельность не нужна.
Кроме того, *DTAQ — это персистентный объект, хранящийся на диске. Так что в памяти там фактически только строка с которой в данный момент работаем.
Гигабайт от терабайта результата отличается во входных данных совсем чуть-чуть. Буквально на еденичку.
И самое главное зачем? Это за час в режиме собеседования пишется нормально. Типовой вопрос же. В прод пусть день займет. Чтобы красиво и падения переживало.
Что значит набросать план? Шедулер написать? Или какие-то примитивы для параллелизма даны, и надо в рамках них это сделать?
Ну и там ещё миллион вопросов последует.
Да ладно вам. Когда собеседующий хочет 50 абстрактных миллионов без привязки ко времени о шедулере даже речи не идет. От вас явно хотят типичных баззвордов.
А за самое рабочее решение «положить эти 50 миллионов в очередь, читать оттуда нужными пачками и обрабатывать нужным количеством воркеров» на работу точно не возьмут. Хотя в проде именно такое решение и будет.
Но дьявол в деталях. Что будет с пакетом, если воркер упал во время обработки? Кто должен фиксировать результат обработки так, чтобы нагрузка распределялась равномерно? Что будет, если заданно максимальное время и оно вышло, а обработка не завершена (такое допустимо например, когда задача одноразовая, ее можно выполнить не за один проход, но на ее выполнение можно выделить, скажем, полчаса в сутки в определенный период минимальной загрузки системы).
Если у человека есть или минимальный опыт, или просто умение просчитывать варианты, он такие вещи сразу держит в голове. И на любом этапе задается вопросом — «а что будет если...»
Плывут на таких вопросах те, кто привык пользоваться разными фреймворками и считать что фреймоворк отработает всегда на 100% надежно и корректно. А случись чего — «ну, это где-то там проблема...»
А у нас проблема всегда «здесь». И ее всегда надо обработать так, чтобы во-первых, зафиксировать что она была, во-вторых, сохранить целостность данных (в худшем случае — откатиться к стабильному состоянию на начало процесса.
В нашем случае пренебрежение этими правилами может привести к весьма печальным последствиям. Как вам непрохождение платежей по пластиковым картам банка в течении нескольких часов в масштабах страны?
Или сломалась проверка по спискам комплаенса, прошел платеж в сторону сомнительного корреспондента и регулятор выкатил штраф со многими нулями?
Такие вещи на фреймворк не спишешь. Это вам не сайт с котиками.
В принципе, у нас нет «неправильных ответов». Это все скорее чтобы понимать уровень кандидата и чему его учить, а что он и сам уже понимает.
Но дьявол в деталях. Что будет с пакетом, если воркер упал во время обработки? Кто должен фиксировать результат обработки так, чтобы нагрузка распределялась равномерно?
Очереди это все сами делают. Упал ну и ладно. Значит комита не было, следующий воркер задачу возьмет. Все само из коробки.
Что будет, если заданно максимальное время и оно вышло, а обработка не завершена (такое допустимо например, когда задача одноразовая, ее можно выполнить не за один проход, но на ее выполнение можно выделить, скажем, полчаса в сутки в определенный период минимальной загрузки системы).
Если задача бьется на несколько ну сделайте несколько очердей и перекладывайте по ним. Сделали свой кусочек работы — положили в следующую очередь. Следующий воркер сам возьмет и сделает свою часть работы.
Надо строго убивать по времени? Крон в помощь. Можно весь контейнер с воркером убивать.
Не надо ничего фиксировать или откатываться. Надо писать идемпотентный код. Особенно в случае сложного многоуровнего процессинга. Все падает иногда. В случайных и непредсказуемых местах.
На внешний код закладываться приходится. Раз начали про очереди, то закладываемся что они работают корректно. Считаем что данные из очереди берутся правильно, коммиты работают правильно, данные в очереди не теряются. Мы эту часть не контролируем. Писать самим дорого, и не факт что выйдет надежнее типового решения. Точнее даже факт что выйдет хуже.
Факапы у всех бывают. Ну упали, бывает. Быстро поднимаемся и работаем дальше. Принимаем меры чтобы по этой же причине больше не падать. Следующий раз из-за другой причины упадем.
Все иногда падают. Считаем стоимость даунтайма и принимаем соразмерные меры защиты. Карты с платежами у банков вполне себе ломаются временами. Да и наркобароны платежи свои проводят как-то. Все как у всех.
MessageQueue (MQ)? DataQueue (*DTAQ)? UserQueue (*USRQ)? Их тут всех есть. Они все разные и работают по-разному. В том числе и по эффективности и скорости.
Транзакции здесь работают на уровне задания. Так что два обработчика в разных заданиях не смогут работать в общей транзакции. Возможно, есть механизм общих транзакций, но мы им не пользуемся т.к. даже оычных стараемся избегать в силу того, что commitment control ощутимо нагружает систему (Вы не поверите, сколько ограничений перечислено в «нефункциональных требованиях к разработке» и насколько сложна система, которая способна на 90 и более процентов загрузить кластер из трех серверов на каждом из которых по 16 12-ядерных SMT8 процессоров и 2.5Тб оперативки).
Не поверите, но как-то пришлось переписывать вот такой запрос:
SELECT DISTINCT ELWWRD FROM ELWPF
LEFT JOIN EWFPF ON ELWWID=EWFID
WHERE EWFEWF IN (....) AND EWFTES='N'просто потому что список значений в IN(...) при каждом вызове функции был новым. А функция очень часто вызывается из самых разных мест. В результате:
Из PEX статистики работы XXXXXXXX видно, что 33% времени и 36% ресурсов CPU тратится на выполнение QSQRPARS в программе YYYYYY, т.е. парсинг статических выражений при подготовке SQL запроса,
Поскольку MMMMM один из наиболее активно используемых сервис модулей, необоснованное повышенное ресурсопотребление является малодопустимым. Просьба инициировать доработку YYYYYY.
Выкрутится удалось только полностью избавившись от SQL в этом месте (тоже особенность AS-ки — тут есть альтернативный способ доступа к файлам данных).
Так что тут все очень непросто. И многие решения, которые на других системах прокатят, тут не годятся.
Вы сейчас про какие очереди говорили?
MessageQueue (MQ)? DataQueue (*DTAQ)? UserQueue (*USRQ)? Их тут всех есть. Они все разные и работают по-разному. В том числе и по эффективности и скорости.
Допустим Kafka. Лицензия хорошая. Опенсорс. Работает под любой разумной операционкой.
Я верю в особенности архитектур. Бывает разное.
Но если ваша архитектура мешает работать, то пора от нее избавляться. Не знаю насколько именно ваша мешает, не работал с ней. На типовых это все решенные задачи. Делать не надо прямо ничего. Все само из коробки работает.
И особенности прежде всего в том, что есть два основных требования — производительность и надежность. Это на уровне паранойи, впрочем, вполне обоснованной. 3млрд изменений в БД в сутки (а обращений к БД на порядок больше, я думаю, если не на порядки) — это не кот наплакал. Огромное количество таблиц и огромное количество одновременно работающих с этими таблицами процессов.
Так что любое решение рассматривается прежде всего с точки производительности и надежности. Я уже приводил пример оптимизаций, которыми мы (в числе многих прочих задач) занимаемся.
У нас есть свои очереди. Основная — IBM MQ — про нее тут как-то давно писали уже
Также, есть персистентные системные объекты *DTAQ и *USRQ — очереди, реализованные на уровне самой операционки.
Есть UnixSockets — не является персистентным, но работает быстрее и не имеет некоторых ограничений очередей (впрочем, и некоторых их возможностей — он всегда FIFO, в отличии от *DTAQ и *USRQ которые могут быть FIFO, LIFO и KEYED).
Любое решение, которое мы привносим в систему, должно быть всесторонне протестировано — кмопонентный тест, бизнестест, интерационный тест и нагрузочный тест. Только после успешного прохождения тестов оно может быть внедрено на пром.
Заменить что-то на проме — огромные затраты. Про всю систему целиком уже не говорю.
Был пример — некий австралийский банк решил заменить весь легаси код, написанный на коболе. Обошлось им это в сумму с шестью нулями и несколько лет работы.
Ваши решения и даже ваши задачи оказываются абсолютно другими чем все привыкли. В обычном мире разработки всего этого нет, зато есть все другое. Подозреваю что с совместимостью у вас тоже не очень.
Условно я со знаниями Кафки не смогу спроектировать систему под ваши задачи на ваших технологиях. А вы со знаниями своих технологий не сможете сделать такую же систему на типовых решениях.
Был пример — некий австралийский банк решил заменить весь легаси код, написанный на коболе. Обошлось им это в сумму с шестью нулями и несколько лет работы.
Лучше сейчас чем еще через 5 лет. Все равно придется же. Нанимать на Кобол уже сейчас нереально сложно должно быть. Да траты, но куда деваться?
Тут лучший пример это наши банки. Без тонн легаси на Коболе. Тинек, Альфа и далее по списку. Они уже на голову выше всех типовых иностранных банков. По качеству софта и обслуживания клиентов.
Судя по их рассказам они все делают на типовых технологиях. И это хорошо работает.
Вы работаете с полностью несовместимым с мейнстримом стеком технологий.
А что есть мейнстрим? Вебразработка? Мобильная?
А какой стек используется в промавтоматизации? В телекоммуникациях?
Ваши решения и даже ваши задачи оказываются абсолютно другими чем все привыкли. В обычном мире разработки всего этого нет, зато есть все другое. Подозреваю что с совместимостью у вас тоже не очень.
Совсем не очень. В силу того, что мы работаем на платформе, которая очень мало где используется в РФ.
Тут лучший пример это наши банки. Без тонн легаси на Коболе. Тинек, Альфа и далее по списку. Они уже на голову выше всех типовых иностранных банков. По качеству софта и обслуживания клиентов.
Судя по их рассказам они все делают на типовых технологиях. И это хорошо работает.
Так вот позвольте представиться — Альфа-Банк, Управление разработки центральных банковских систем, главный разработчик.
То, что делается на «типовых технологиях» — это верхушка. То, что обсепечивает внешние интерфейсы.
Но опирается все это на код, написанный на 80% на RPG (остальное — C/C++) и работающий на платформе IBM i (бывшая AS/400) на серверах PowerS.
А то, что работает на типовых технологиях общается с нами через MQ и вебсервисы (которые сами ничего не не делают а только вызывают наши внутренние процедуры, передавая им набор параметров и получая ответ). А прямого доступа к данным ни у одной внешней системы нет.
А всю работу системы в плане обработки данных обеспечиваем мы. На своих «немейнстримных технологиях».
Тут такой слоеный пирог и в каждом слое свой стек и свои требования. И свои тараканы.
некий австралийский банк решил заменить весь легаси код, написанный на коболе. Обошлось им это в сумму с шестью нулями и несколько лет работы.
Неплохой вариант для банка, как мне кажется.
И такой переход надо делать «на лету», без остановки работы банка. Т.е. надо подготовить полностью рабочий вариант, потом какое-то время тестировать его в условиях параллельной работы старой и новой систем и только после этого уже выводить из эксплуатации старую систему.
При этом старая должна продолжать работать до последнего.
На момент перехода штат разработчиков, аналитиков, тестировщиков, сопровождения придется увеличить в полтора-два раза. Одна команда продолжает поддерживать старую систему, вторая — делает новую.
Работая на уровне развития АБС, могу точно сказать — бросить все тут нельзя. Да, какие-то вещи можно отложить до введения новой системы. Но какие-то никак. Выявился дефект промсреды — его надо править. Вышел новый ФЗ — надо дорабатывать систему для его выполнения. Поменял кто-то из внешних систем формат данных — надо адаптироваться к новому формату. И т.д. и т.п. Все это придется делать и на старой системе и на новой.
И все это при том, что старый код работает.
Тут вообще все очень консервативно. За модой никто не гонится. Просто потому что это бессмысленно.
Ну вот предствьте — сделали вы некий сайт. Он работает. Все довольны. А через год новый движок вышел. Кинетесь вы переделывать сатрый сайт на новый движок просто потому что он более современный? Сомневаюсь. Более того, если заказчик обратится к вам с просьбой доработать новый функционал и даст на это некоторый фиксированный бюджет и сроки, вы не кинетесь переделывать сайт под новый движок, а будете дорабатывать на старом. Потому что полная переделка не впишется ни в бюджет, ни в сроки.
И системы всё-таки устаревают.
На новое железо не хотят вставать старые операционки.
Новых операционках не хочет работать старый софт.
И с каждым поколением — всё дальше и больше.
Рано или поздно — переписывать придётся.
И вот тут следует найти баланс:
— чтобы действительно не делать работу впустую, не менять систему, которая ещё вполне себе может работать и может даже не до конца отбила деньги вложенные в неё, и в то же время
— чтобы не затягивать эксплуатацию морально и технически устаревшей системы, её переписывание вылилось в разумные сроки и суммы.
Там все, во-первых, мегаконсервативно, во-вторых, используются платформы, несколько отличающиеся от десктопных и даже инетсерверов.
Вот, к примеру мы работает на платформе, которая была создана в 88-м году — AS/400 от IBM. Сейчас эта платформа называется IBM i и продолжает поддерживтаться и развиваться. Выходят новые версии ОС (год или 2 назад мы перешли с 7.2 на 7.3, перодически накатываются мелкие апгрейды, последняя версия 7.4). Выходит новое железо — не так давно мы перешли с PowerS8 (824 на тесте и 828 на проме) на PowerS9 (924 и 928 соответственно).
Но все, что было написано, скажем, в 2016-м и ранее под 828, будет точно также работать и сейчас на 928. Более того, при переносе на более современное железо программынй код «самооптимизуруется» автоматически. Как это работает — объяснять долго, лучше погуглить что такое TIMI:
Одной из особенностей платформы IBM System i является использование высокоуровневой системы команд TIMI («Technology Independent Machine Interface», рус. Машинный интерфейс, независимый от технологии[3]), которая позволяет программам быть переносимыми и при этом получать пользу от более современного аппаратного и программного обеспечения без перекомпиляции.
TIMI является виртуальной системой команд, не зависящей от реальной системы команд центрального процессора. Приложения, работающие в режиме пользователя, могут содержать одновременно машинные коды TIMI и машинные коды конкретного процессора. Концептуально система сходна с архитектурой виртуальных машин, таких как Smalltalk, Java, .NET. Основное отличие от них — глубокая интеграция TIMI в архитектуру AS/400, таким образом, что приложения являются переносимыми между системами System i с различными микропроцессорами.
Особо надо отметить, что в отличие от других виртуальных машин, которые интерпретируют виртуальные инструкции при запуске ПО, инструкции TIMI не интерпретируются. При компиляции ПО, в объектном файле сохраняется как машинный код конкретного процессора, так и TIMI-код. Если приложение, скомпилированное для оригинальных 48-битных процессоров CISC AS/400, будет запущенно на системе с более новым RISC-процессором, например, 64-битном PowerPC, то операционная система проигнорирует машинный код старого процессора и оттранслирует[3] TIMI-код в инструкции нового процессора перед запуском.
Фактически, в этой системе отсутствует доступный разработчику ассемблер — он находится ниже уровня System Licensed Internal Code (SLIC), куда доступ разрешен только разработчикам системы. Выше SLIC — уровень разработчиков ПО — существуют тоьок те самые MI — машинные инструкции для работы с системными объектами.
В общем, эти системы изначально рассчитаны на очень долгий срок службы и переносимость ПО на более современные версии с использованием всех новых возможностей. И там нет такой острой необходимости переписывать все (и даже перекомпилировать все) только потому что железо устарело.
То, что написано под AS/400 в 1990-м, может быть перенесено и будет эффективно работать на IBM i в 2020-м. На совершенно других процессорах. Это не бытовуха типа маков, где с x86 на ARM перешли и привет — весь софт под переписку.
Тут время жизни софта исчисляется десятилетиями. И вкладываться в его переделку пока совсем не прижмет, только ради «модного стека» никто не будет — это неэффективные затраты.
Тут на любое телодвижение первый вопрос — «а сколько мы на этом заработаем?»
И это же нужен не 1-2 пенсионера, а нормальные такие IT-отделы: системы-то большие.
Типа, готовых специалистов нет — пусть, возьмём толковых, вырастим для себя сами.
А много ли захотят идти на работу в узкую, в рамках IT-технологий — нишу? Что потом делать с полученными знаниями и навыками?
Не могу сказать, чтобы у нас ощущалась острая нехватка кадров. И работают далеко не только пенсионеры, молодых достаточно много.
И ИТ служба у нас вполне себе нормальная. Я затруднюсь сказать сколько человек, но только разработчиков точно больше сотни (по трем городам — Мск, Спб и Екб). Я имею ввиду тех, кто работает именно на AS/400, есть еще кто работает с Pega, мобильная разработка, сайт…
А еще есть аналитики, сопровождение, поддержка — те, кто тоже обязаны очень хорошо понимать как работает эта система.
Тут просто определенны склад характера — глубокий бэкенд, умение писать надежный и эффективный код самому, не опираясь на фреймворки.
Такие люди, если что, легко находят себе работу в других областях — та же промавтоматизация в чем-то предъявляет схожие требования. Телекоммуникации (на нижнем уровне).
Конкретная платформа не так важна — до уровня решения несложных боевых задач человек, обладающий хоть каким-то опытом разработки, но впервые сталкивающийся с этой платформой, выходит через два-три месяца максимум. Дальше уже начинается накопление опыта и переход к более сложным задачам.
И такой человек потом за те же пару месяцев сможет перейти на любую другую платформу.
Я сам пришел три года назад. До этого писал исключительно на С/С++ под винды. Сейчас вот AS/400, RPG и местами С/С++ (там, где это удобнее и эффективнее). Благо концепция системы позволяет написать модуль на RPG, модуль на C/C++, а потом эти два модуля слепить в одну программу. И вызывать функции на С/С++ из функций на RPG и наоборот.
Как у вас обстоят дела с феноменами вроде Undefined Behavior из C++?
Как выглядит версионирование софта?
Как у вас обстоят дела с феноменами вроде Undefined Behavior из C++?
Честно скажу — очень давно не сталкивался. Видимо, интуитивно стараюсь избегать неоднозначных конструкций, в которых оно обычно проявляется.
Как выглядит версионирование софта?
Имеется ввиду наш софт?
В данном случае все завязано на особенности платформы.
Начнем с того, что написание исходного кода ведется на локальной машине (ноут, десктоп...) IDE — или RDi (Rational Development for i — IBM-овская IDE для разработки под AS/400 на базе Eclipce — обвешана всякими плагинами для работы с сервером) или VSC (но тут две проблемы — заброс исходников на сервер и разработки интерфейсов (дисплейные и принтерные формы — в RDi для них есть визуальный редактор).
А чтобы собрать поставку нужно сначала забросить все исходники на сервер и там уже собирать. Сейчас стараниями наших девопсов есть gradle плагин, который все это умеет. Так что первая проблема для VSC решена — прямо в его терминале запускаешь таск гредла и вперед.
Далее — особенности хранения исходников на AS-ке — там нельзя вот так просто взять и положить исходник программы. Там есть т.н. «физический файл исходных текстов» — pf-src. Он содержит в себе набор «элементов» (member) каждый из которых уже есть исходник программы, описание таблицы, SQL скрипт и т.п.
Т.е. исходники поставки, вне зависмости от количества объектов в ней — один pf-src.
Все эти файлы хранятся в специальной библиотеке (на каждом юните своя) со стандартным именем ASRC+мнемоника юнита
Т.о. развернуть поставку на сервере — это значит создать в том юните куда она ставится в соотв. библиотеке pf-src, заполнить его набором элементов и потом оттуда собрать каждый элемент (создать соответсвующий ему объект).
Каждая поставка (патч) имеет мнемонику + трехзначный номер версии. Нумерация начинается с 100. Далее, если изменяется бизнеслогика (новая версия FSD), номер увеличивается на 10 (100, 110, 120...). Если исправление дефекта или оптимизация без изменений в логике — увеличиваем номер на 1 (111, 112...)
Есть правила именования pf-src — мнемоника поставки (линейки, задачи) + SRC + номер версии. Например, работаю с линейкой ECL (мнемоника). Первая поставка. Версия 100. Она будет именоваться у нас везде как ECL#100. На юните разработчиков (он прежде всего для проверки что поставка собирается и не падает при запуске), PGM она будет лежать в ASRCPGM/ECLSRC100
Далее. В поставке может быть много объектов (у меня сейчас их более 160-ти). Собирать каждый руками — страшное дело. Посему пишется программа-инсталятор на языке CL (это командный язык AS/400, его команды могу использоваться как в интерактиве при работе в терминале, так для написания программ на нем, более того, программа на CL компилируется командой того же CL) которая складывается в тот же pf-src под фиксированным именем CRT+мнемоника поставки+номер версии (@CRTECL100).
Теперь чтобы развернуть поставку на юните достаточно скомпилировать инсталятор и запустить его. А он уже соберет все объекты.
На самом деле инсталятор чуть сложнее — он и окружение создает для сборки и проверяет пререквизиты (мнемоники других поставок, которые должны быть установлены на юните чтобы наша заработала) и в конце, елси все хорошо, регистрируется поставку в специальной базе (по ней и проверяются пререквизиты). Туда вносится полная мнемоника поставки — ECL#100, дата и время установки, ссылки на задачу в Jira, на FSD в Confluence, на страничку проекта в Confluence. А также профайл пользователя из под которого производилась установка.
Теперь мы можем простыми SQL запросами посмотреть какие поставки у нас в конкретном юните (вплоть до прома), в каких юнитах установлена наша поставка и т.п.
Слава девопсам, сейчас даше не нужно инсталяторы писать руками — все в гредле. Просто прописываются скрипты где описываются данные для поставки и все входящие в нее объекты и соотв. таск сам сгененирет инсталятор, забросит все на сервер, скомпилирует и запустит инсталятор. Нам нужно только написать в командной строке на компе gradle as400SyncAndDeploy и ждать что из этого получится :-)
У каждого объекта в AS/400 есть такое свойство как TEXT — это строка 50 символов для краткого комментария что это такое. Мы в гредл-скриптах, когда описываем объекты поставки вносим туда краткое описание. А плагин гредловый при создании инсталятора еще к описанию каждого объекта добавит мнемонику поставки — например, ECL#100. Таким образом, мы для каждого объекта в системе можем посмотреть каким патчем он был установлен — команда WRKOBJ имя объекта

и нажимаем 8 — описание объекта
Для программных объектов еще проще — там есть команда DSPPGM
там много экранов, в том числе описание объекта
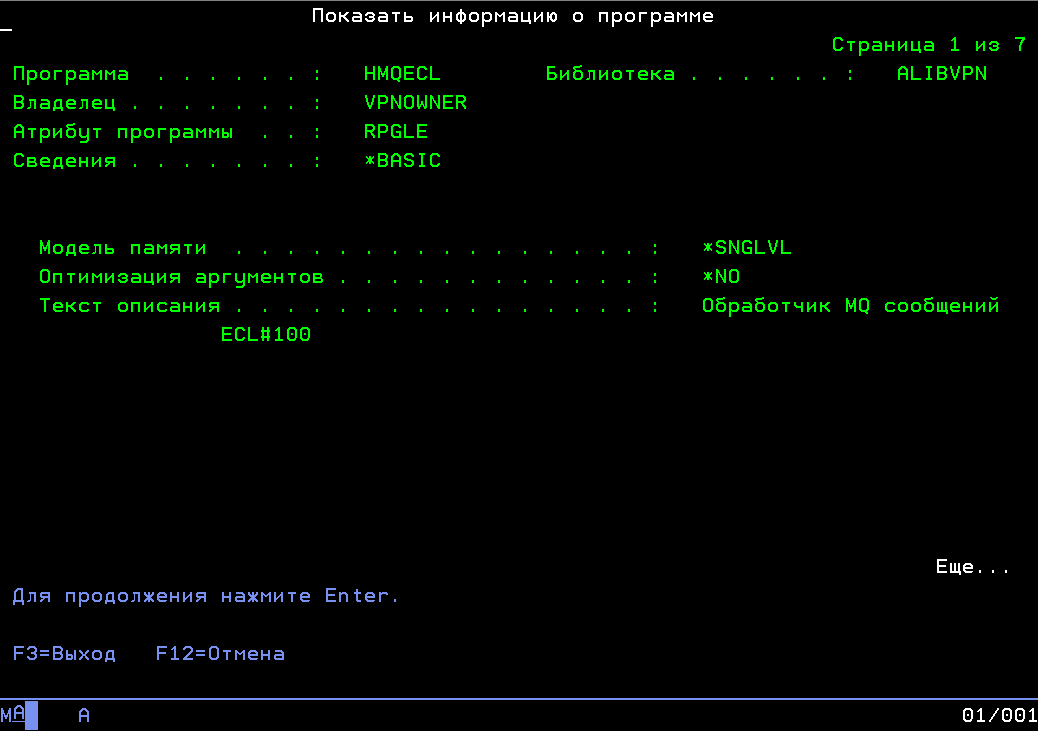
и список модулей из которых он собран
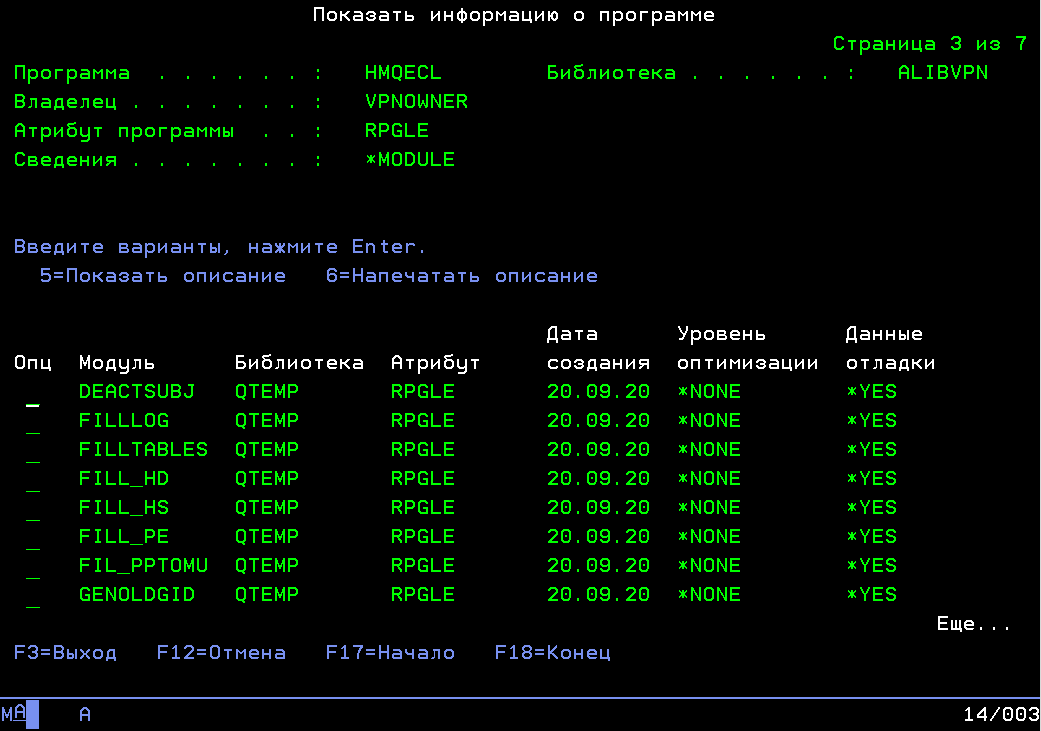
Для каждого модуля можем посмотреть информацию о нем где будет ссылка на pf-src где хранится его исходник

Т.е. всегда можно найти концы откуда что поставлено. Кем и когда.
Но ручная установка доступна только в юнит разработчиков и песочницы (копии юнитов компонентного тестирования — у каждой команды свой, служит для совместного тестирования и отладки силами аналитика и разработчика, впрочем, у нас есть аналтики, которые сами неплохо дебажат и еще ревью по коду делают). Песочница хороша тем, что может быть в любой момент пересоздана из соответсвующего юнита.
А вот в юнит компонентного тестирования поставка ставится уже через портал DevOps. Для этого нужно поставку официально оформить — коммит в гит, тег на коммит и запустить таск в Jenkins на этот тег.
Дженкинс уже вызовет гредл и тот по скриптам в поставке установит ее в юнит-хранилище поставок и создаст объект в Artifactory, добавив туда ReleaseNotes (тоже на основе информации из гредл-скриптов).
Это уже считается «оформленной поставкой» — ссылка на объект в артифактори публикуется на страничке задачи в Jira с переводом задачи из статуса Dev в статус DevDone и в Confluence дочерней страничкой к страничке с FSD.
Дальше уже все установки поставки в разные юниты идет по ссылке на артифактори. В компонентное тестирование сами ставим (разработчик или аналитик) через портал DevOps, в юниты бизнестестирования, интеграционного тестирования ставит сопровождение по заявке аналитика. При необходимости аналитик может заказать нагрузочное тестирование. Ну и установка на пром (внедрение) тоже по заявке ставит сопровождение.
Вот так, если кратенько :-)
Очень интересно, спасибо что так развернуто отвечаете.
Жаль только что это в комментариях останется, хотя уже тянет на статью.
Все это, кстати, развернуто за последние годы. Еще три года назад, когда я пришел, гитом так активно не ползовались, гредла не было у нас, не было артифактори, джиры… FSD хранились в базе Lotus. Альтренативы RDi для разработки не было т.к. она позволяла работать с исходниками на сервере — так и работали с тем юнитом, который сейчас отведен как хранилище поставок и закрыт для прямой записи (сейчас только через дженкинс туда ставится). Инсталяторы писали вручную по шаблонам…
Потом был переход к новой схеме. Когда прежде чем начать работу, брали исходники из юнита, создавали репозиторий в гите и втаскивали все туда прежде чем начать доработку.
Сейчас, конечно, все устаканилось, хотя бывает иногда попадается что-то совсем старое чего в гите нет. Но уже очень редко.
Я понимаю, но таки посмотрите на это всё с позиции приходящих к вам людей. Люди приходят, чтобы (в разных пропорциях) получать денежную компенсацию, решать интересные задачи, улучшать мир, получать новые навыки, получать трансферабельные новые навыки.
За трансферабельными навыками — это в учебное заведение или на курсы.
У нас будут прокачиваться те навыки, которые нужны для решения наших задач.
А поскольку сфера специфическая и платформа специфическая, то и навыки будут специфическими.
Если кандидат не согласен — значит не договорились.
Оплата по рынку. Плюс стабильность (тут не будет ситуации когда вдруг скажут «извините, но работы больше нет, проект закончился, нового заказчика не нашли, разбегаемся»). Плюс плюшки — 100% белый оклад, оговариваемый в оффере, бонусы все сверху по результатам работы (тут достаточно ровно выполнять все задачи и будешь иметь +15% от суммарного оклада за период, сделал больше — получишь больше). Плюс ДМС. Плюс страхование жизни и трудоспособности. Поднимешся по грейду — будут еще плюшки в виде различных компенсаций.
Так что тут все должны понимать — кандидат — куда он идет, мы — уровень кандидата, чего от него ждать прямо сейчас и чему его нужно еще учить.
И да. У нас нет «тестовых заданий» в прямом смысле (не решил — не прошел). У меня вот вообще никаких тестов не было. Просто рассказал какие задачи решал, мне рассказали чем занимаются тут. На том и договорились.
Фреймворков, как таковых, у нас нет. Поэтому знание конкретного фреймворка нас не интересует. Интересует как у человека голова работает. Общий подход к разработке.
Более того, те, кто привык работать с фреймворком и на 100% доверять ему (считая его абсолютно надежным и устойчивым) нас интересуют в меньше степени. Потому что у наких людей в среднем больше склонности сказать «я не знаю как это сделать потому что в моем фреймворке этого нет».
Оплата по рынку
А какой рынок вы смотрите если
А поскольку сфера специфическая и платформа специфическая, то и навыки будут специфическими.?
Нам нужен человек, который будет решать задачи нашего бизнеса. А человек, который будет прокачивать скиллы чтобы через два года уйти в другое место нам не нужен.
При этом у нас поощряется обучение. Если вы найдете курсы какие-то и сможете обосновать что они вам нужны для работы, то вам их с большой вероятностью оплатят (периодически идут рассылки — «если кто хочет, что-то нашел — сообщайте»).
Все это обговаривается на берегу. Если человек не согласен — его право. Однако, проблем с разработчиками у нас нет. Просто есть дополнительный фильтр — нужны люди, которые хотя заниматься именно нашими задачами и расти в рамках нашей компании. Такие находятся. Текучка у нас очень небольшая. Люди приходят надолго, растут как по позиции, так и по деньгам. «Пехоты» (вечных джунов) у нас нет. Или человек растет, или уходит. По крайней мере в нашей части (backend на IBM i). В части, которая занимается веб и мобильной разработкой, видимо, побольше. Но там нет специфики.
А человек, который будет прокачивать скиллы чтобы через два года уйти в другое место нам не нужен.
Какое у вас, однако, интересное отношение к сотрудникам
Я уж думал в ИТ прошли времена когда за стаж работы меньше 5-10 лет вешали ярлык «бегунок»
в ИТ если остановиться и сидеть на одном месте 5-10-20 лет, то потом не получится поменять работу, если с вашей конторой чтото случится, потому что опыт устареет, а ваши ценные бизнеспроцессы не будут котироваться.
Я работал в одном месте, у нас в отделе были человек 5 плюсовиков «старой школы», которые работали в этой конторе с середины 90х… и уже дядечки в годах (не пенсионных но близко), они работали на зарплате в -30% от моей (джуновской на тот момент)… и когда за чашкой чая мы разговаривали, они говорили что мало того что по плюсам мало вакансий, так ещё они очень сильно отстали в от современных веяний в ИТ и приходится довольствоваться тем что есть… тупо не берут, опыт частично не релевантен.
И забавно что вы считаете ваших работников железными болванчиками которые должны радеть за вашу фирму и совершенно не думать о своем собственном будущем.
p.s. потому что если у вас в конторе будут проблемы, вы их сократите не моргнув глазом, без всяких «нам нужен правильный человек»… сегодня нужен, завтра не нужен
Чтобы писать эффективный код, требуется, во-первых, ориентироваться в предметной области (как работает банк вообще и данная конкретная АБС в частности). Хотя бы на самом общем уровне. За себя скажу, что проработав три года (даже больше) я не могу про себя сказать что сильно хорошо во всем этом ориентируюсь. Да, некоторые вещи знаю достаточно прилично — как оно устроено, что с чем как связано и т.п. А некоторых не знаю практически совсем. Поэтому у нас есть разделение по командам — Тарифный модуль, Модуль пластиковых карт, Лимитный модуль, Система расчетов… Есть общие ядровые функции, есть комплаенс… Т.е. все равно у каждого есть какая-то специализация внутри системы. Без этого очень трудно ожидать от человека эффективной работы. Даже при том, что все ТЗ пишутся аналитиками — специально обученными людьми, которые лучше нас разбираются в тонкостях бизнес-процессов.
Во-вторых, нужно еще неплохо понимать как работает AS/400 (IBM i). Там тоже очень много тонкостей на понимание которых уходит время. Какие опции в каком случае надо выставить в DDS для физических файлов. Какие для логических. Какие операции эффективны по нагрузке, какие ресурсозатратны и их надо избегать или выносить в блок инициализации группы активации. И таких тонкостей тоже очень много, все это постигается далеко не сразу, на опыте. И на все это нужно время.
И вот точно не будут сокращать людей с опытом. Потому что это дорого. Подготовить нового спеца на замену тому, кто уже вник в систему.
Так что если человек стремится развиваться, проявлять проактивность — его будут двигать вверх. И по должности и по деньгам. Чтобы сохранить.
Возникает задача чуть посложнее — сразу вопрос — кому ее дать? Кто справится? Кто сможет оптимизировать старый модуль, который отрицательно влияет на эффективность? Явно не тот, кто работает тут без году неделя…
А сокращения… Я писал уже. Даже в нынешней ситуации у нас их не было. Никого не сократили, никому не понизили оклад.
Если Вам не везло с работодателем и к Вам относились как к расходному материалу, пехоте, цена которой рубль за пучок в базарный день — не значит что везде так. Возможно, это типично для вебразработки или мобильной. Но тут ситуация иная. Да, это узкая сфера у нас (но не в мире). Но тут отношение к специалисту с опытом разработки несоколько иное чем в других областях. Хорошего спеца не так просто найти и еще сложнее подготовить. Так что за них держатся. И чем выше по положению, тем сильнее держатся.
не значит что везде так.
И вот точно не будут сокращать людей с опытом
Везде так, когда бабки кончаются по какойто причине, чудес не бывает. Сократят не моргнув глазом, если бюджеты будут поджимать.
Никого не сократили, никому не понизили оклад.
и не повыслили тоже ;) вы таки договаривайте.
Я, так случилось, что хоть и работал программистом но был очень приближен к бюджетированию и экономистам. и знаю что стоит обычно за словами тимлидов/начальников отделов — «я не дам сокращать людей в моем отделе» — а за ними стоит то что их слово второе после текущего бюджета
А если в стране какойто кризис, банки могут начать резать целые подразделения, лет 5 назад на рынке труда было полно бывших банковских айтишников, я работал с админом который в течении 3х лет успел поработать в 3х банках у которых отозвали лицензию… до смешного доходило, в одном месте он отработал 2 месяца… был «успешный банк» у которого совершенно внезапно отозвали лицензию
По должности лично меня повысили в мае. Оклад тот же пока (т.к. вилки пересекаются), но появились дополнительные плюшки в виде более высокого коэффициента бонуса, дополнительных компенсационных выплат.
Ну а насчет отозвать лицензию… Банк 5-й (по-моему) с списке «системобразующих». Со всеми вытекающими.
По объему решаемых нами задач — сокращение своего IT автоматически приведет к передаче этих задач вендорам. А банку это по ряду причин не выгодно. Тенденция наоборот.
Кстати, за время кризиса точно знаю что в нашу команду приняли несколько новых сотрудников.
Так что скорее расширяемся чем сокращаемся.
Не, я понимаю, что в мелких банках, котрых с свое время насоздавали как «личный общак», ситуация немного иная. И по отношению к сотрудникам и по оплате.
Оплата по рынку. Плюс стабильность (тут не будет ситуации когда вдруг скажут «извините, но работы больше нет, проект закончился, нового заказчика не нашли, разбегаемся»).
Зато наверное легко могут сказать что банк закрыт (я ведь угадал с областью бизнеса, так?) или у отдела забирают все бизнес-задачи и передают в головной филиал, а на месте оставят только макак-менятелей картриджей в принтерах. Или вы Иегову за гениталии держите чем-то что так уверены что уверены в своей job security?
С закрытием отделения тоже не так просто. Скорее наоборот. Есть три команды — Мск, СПб и Екат. И есть курс на отказ от услуг вендоров в бекразработке.
Так что доля вендоров сокращается, доля своих разработчиков наращивается.
За время кризиса у нас не было ни увольнений, ни сокращений оплаты.
И отношение к ИТ командам здесь весьма разумное. Бизнес прекрасно понимает что мы наравне со всеми помогаем делать прибыль. А это основная цель банка.
Так что в плане отношения с работодателем и организации условий для работы тут все очень шоколадно.
Люди туда работать идут не ради того, чтобы выяснять, первокурсник лучше освоит лисп или питон.
Вот честно хотелось бы, чтобы именно ради таких вопросов и шли.
А то наши (большей части exUSSR) типовые вузы, где большинство преподавателей пенсионного возраста и в лучшем случае пишут фанфики по мотивам настоящей науки (а то и этим себя не озадачивают) — годятся только ради корочки.
вы как налогоплательщик считаете, что тратить деньги общества на выяснение «что лучше для университета — Питон или Лисп» — это хорошее расходование средств?
Я как налогоплательщик считаю, что образование должно быть чем выше качества, тем лучше, и для этого эксперименты жизненно необходимы — разумеется, по правильным методикам (включающим осторожное начало и независимое оценивание), но необходимы.
В остальном же резкий перевод на тему налогов выглядит приёмом некорректной полемики.
если бы какой-то язык давал прирост производительности труда по сравнению с другим хотя бы на 5%, все на нём бы сидели.
Это откровенная ерунда, потому что приросты бывают и в 500 и в 100500 процентов, но — в конкретных областях и для конкретных типов задач. Иначе бы новые языки просто не выстреливали, и мы бы действительно сидели на одном Фортране или Коболе. Если вы видите язык, который вышел из породившей его лаборатории и пошёл по миру, то он даёт прирост не 5%, а как минимум десятки процентов — иначе легаси не дало бы ему развиться.
потому что с практической точки зрения если даже студенты полгода посидят на Лиспе, всё равно ради реальной жизни через полгода они начнут изучать Питон или C, а если им это слишком сложно, то скорее всего, они для этой профессии слабо пригодны всё равно.
"Реальная жизнь" она разная бывает. Вон если больше половины (навскидку и например) применений Python это врапперы вокруг numpy/pandas/etc., то тем, кто использует его для таких задач, LISP нафиг не сдался.
А вот тем, кто целится на широкий спектр понимания CS, надо учить и LISP, и Forth, и обычные процедурные языки, и акторные цепочки из промисов… а вообще такому надо пройти, например, этот список до указанного уровня (знать по каждому слову, что оно и чем характерно). (Может, чуть устарел — ну так обновлять.)
резкий перевод на тему налогов выглядит приёмом некорректной полемики.Смотрите, этот приём корректен потому, что именно таким образом оцениваются предложения учёных в грантовых комиссиях. Если кто-то захочет провести подобную работу и выбить под это деньги, то проект будут изучать на предмет научной интересности, новизны и да, impact/spillover effects/importance, вот и всё.
Это откровенная ерунда, потому что приросты бывают и в 500 и в 100500 процентовБезусловно. Эта цитата относилась к языку «общего назначения» в рамках написания «софта широкого профиля». Сейчас мы имеем куда больший зоопарк языков и сфер применения, но если сосредоточиться на «учебных» языках, то назовите любую десятку — пусть там будет и Паскаль, и Питон, и Руби, и что угодно ещё. Вот я уверен, что не найдётся такого языка, который вот прямо все понимают, а Питон не понимают. Ну ведь уже учили и на Бейсике, и на Лого, и на чём только не. Любой не слишком замороченный язык плюс-минус одинаков.
А вот тем, кто целится на широкий спектр понимания CS,Мы здесь по сути обсуждаем «вход в IT», то есть с чего начать, а не чего в принципе стоит освоить. Это другой вопрос.
Есть какие-то исследования, что условный питон эффективнее для начального обучения программированию, чем условный лисп?
MIT таки писал какое-то обоснование, почему они перевели CISP со Scheme на Python. Можете поискать.
Не вижу особой проблемы начинать с паскаля в школе
Пачка граблей, которые непонятны и которые надо тупо запомнить, я об этом писал несколько раз: 1 2 и т.д.
Я понимаю критику C, но тогда надо брать не Pascal, а хотя бы Modula-3.
кто заинтересуется изучит и другие.
Школьное образование должно быть рассчитано не на того, кто заинтересуется, а на то, что останется в голове у того, кто не интересуется. Иначе вообще держать предмет нет смысла.
Я понимаю критику C, но тогда надо брать не Pascal, а хотя бы Modula-3.
Но зачем? Это очередной мертвый язык. Ни IDE, ни SO, ни реальных проектов. Ничего нет. Не надо откапывать стюардессу.
а нужно ли детям SO? мы же о первом языке говорим, это должна быть чуть ли не начальная школа
Да, а почему нет? Пусть привыкают что на правильно сформулированный вопрос как сделать тото интернет всегда ответит.
Мы же используем so. Так почему обучающимся не надо? Не надо решать за других. Есть сложившиеся практики. Надо просто обеспечить их доступность.
Начальная школа это вы преувеличиваете.
помните «математику уже затем учить надо, что она ум в порядок приводит»? программирование «приводит ум в порядок» ничем не хуже, я считаю, что его стоит изучать для развития детей, а не потому, что оно действительно многим пригодится в жизни.
и ещё есть одна мысль (не моя): программирование — это единственная «серьёзная» школьная дисциплина, где разрешено ошибаться (ситуация, когда программа не работает с первого раза, нормальна). и это тоже очень важно именно для развития детей.
первый язык должен ИМХО изучаться достаточно рано, никак не в ВУЗе. ну пусть не начальная школа, 5-6 класс.
уже в седьмом классе дети начинают изучение геометрии с почти полноценным аксиоматическим подходом, то есть ожидается, что они способны понимать и самостоятельно создавать достаточно сложные логические построения. так что и в программировании уже есть где развернуться.
Пусть привыкают что на правильно сформулированный вопрос как сделать тото интернет всегда ответит.
а вот как раз не всегда ответит.
нужно учить решать задачи самостоятельно, если этот навык есть — гуглить всегда научатся. обратное же неверно.
Мы же используем so. Так почему обучающимся не надо?
хотя бы потому, что он превратится ещё в один сайт с набором ГДЗ.
P. S. хотя за «правильно сформулированный вопрос» поставил плюс. но этот навык, наверное, нужно вырабатывать уже позже (по сути он не так уж сильно отличается от навыка самостоятельного поиска информации в библиотеке; что ранее ожидалось от студента, может быть старшеклассника)
первый язык должен ИМХО изучаться достаточно рано, никак не в ВУЗе. ну пусть не начальная школа, 5-6 класс.
уже в седьмом классе дети начинают изучение геометрии
И в итоге геометрия это один из самых непонятных и ненавистных предметов для школьников. Слишком сложно.
Нет смысла гнать. Я бы сказал раньше 9 класса точно рано. 9-10 только самые начала, остальное не влезет. 11 егэ и только подготовка к нему, остальное не важно уже. И в итоге на первом курсе быстрое повторение всего что было в школе. Можно за половину первого курса при желании.
но этот навык, наверное, нужно вырабатывать уже позже (по сути он не так уж сильно отличается от навыка самостоятельного поиска информации в библиотеке; что ранее ожидалось от студента, может быть старшеклассника)
На дворе 2020 год. Надо адаптироваться. Гугл у каждого в кармане. Умение им пользоваться в реальной жизни очень ценится. Человек нагугливший решение и разобравшийся в нем достоин хорошей оценки. Читать чужой код не так просто. Часто проще самому написать.
Проверять что человек разобрался в том что сдает должен преподаватель. Это не так сложно.
хотя бы потому, что он превратится ещё в один сайт с набором ГДЗ.
Вот этим программирование и отличается от многих предметов. Правильный ответ это приличное количество текста. Осмысленного текста. Который незнающий предмет даже прочитать не сможет. Пусть списывают и разбираются. Читать чужой код это нормальный способ обучения.
Нет смысла гнать. Я бы сказал раньше 9 класса точно рано. 9-10 только самые начала, остальное не влезет.
какой-нибудь лого в девятом классе? не смешно )
Вот этим программирование и отличается от многих предметов. Правильный ответ это приличное количество текста
гхм. что в математике, что в физике, что в химии проверяется решение, и это тоже «много текста».
Который незнающий предмет даже прочитать не сможет
и кого это останавливало? списывают всё подряд не разбираясь и не понимая что за символы списывают.
гхм. что в математике, что в физике, что в химии проверяется решение, и это тоже «много текста».
Там есть правильное решение, а есть неправильное. На школьном уровне это обычно поставить пару формул и все. Что спросить по этим формулам непонятно. Ну можно узнать откуда их человек списал или вообще наизусть помнит. Смысла в этом немного, но можно.
А вот даже строк 30 кода это стиль, имена, вообще оформление. Код с любого идеального решения виден сразу. Он просто хороший. Ни один школьник такое не напишет. Значит списан и можно пообщаться.
А почему тут i++? А что будет если ++i написать?
А почему этот цикл вот такой? А не вот сякой. А напиши его по другому. Как хочешь, но по другому.
А как ты выбрал имя вот для этой переменной? Особенно если она на хорошем английском названа.
И далее по теме. Любая строка, если она не авторская, вызывает вопросы.
А уж спросить как ты это проверял или проверил бы вообще замечательно. Даже корпорации не брезгуют такими вопросами. Корнер кейсы проверь по своему коду вслух. Делаем скидку на школьников и сами кейсы даем. А вот как их код будет работать на них пусть сами проговаривают.
и кого это останавливало? списывают всё подряд не разбираясь и не понимая что за символы списывают.
Да пусть. Если понимает как работает — зачет. Нет — на пересдачу. Тот же пузырек правильно реализованный без понимания человек не расскажет что и почему. С кодом перед глазами.
Ко всяким Лого и прочим «детским» языкам я отношусь с большим подозрением и не понимаю зачем оно вообще нужно.
ровно затем же, зачем и геометрия, например. я же выше написал. для развития абстрактного мышления. плюс для обучения планированию действий, умению заглядывать на несколько шагов вперёд.
побочный эффект: когда мы в старших классах начнём изучать «настоящий» язык, у учеников уже будет понимание того, что такое алгоритм, условие, цикл, переменная, а то и функция с рекурсией.
это обычная практика, когда одно и то же изучают несколько раз, та же площадь прямоугольника боюсь даже вспомнить сколько раз, тут вспоминали экстремумы функций, которые «наивно» проходят в 7-8 классе, а потом аналитически в 10 классе, s=v⋅t, которое проходится и в математике, и в физике, и т. д., и т. п.
BTW, вот обучение «настоящему» языку ИМХО можно уже сделать опциональным, далеко не всем оно нужно.
А почему этот цикл вот такой? А не вот сякой.
а что такое a⃗? а что означает стрелочка сверху? а в каких единицах оно измеряется?
Тот же пузырек правильно реализованный без понимания человек не расскажет что и почему. С кодом перед глазами.
вы опять про студентов, а я про детей.
И в итоге геометрия это один из самых непонятных и ненавистных предметов для школьников. Слишком сложно.Классическая проблема: есть хороший учитель и хороший учебник — можно и в 5-7 классе давать, и никакой ненависти не будет. Учебники Пойа, Локхарта или Киселёва вполне себе понятные и последовательные, а вот более новые, «академичные» учебники я бы школьникам в руки не давал, минимум студентам.
Нет смысла гнать. Я бы сказал раньше 9 класса точно рано.
в итоге геометрия это один из самых непонятных и ненавистных предметов для школьников. Слишком сложно
Очень красивый же предмет!
Разве может кому-то не нравиться?!
Паскаль по факту не сильно от него отличается (да, есть анклавы дельфистов и т.п. — но это чудовищно далеко от мейнстрима). Да, надо было сказать "надо было брать лет 20 назад", или даже раньше.
Сейчас обстановка интересна тем, что ломается всё — ждём, что выживет из новой волны языков. Хоть выбирай между Swift и Julia какими-нибудь...
Бейсик, тот да, ужасен.
Чем же бейсик так ужасен?
За других не ручаюсь.
а то я часто слышу как бейсик называют ужасным, но никто не может привести ни единого примера ужасности?.. максимум вспоминают косяки 70х годов прошлого века…
Не нравится и все. Неудобно как неудобная обувь. Может кто нибудь сможет найти явные причины этого, но я не зна
А серьезно я сторонник строгой типизации
А серьезно я сторонник строгой типизации
Так в питоне как раз строгая типизация и есть. Может, путаете с динамической типизацией?
И мне это не нравится.
Может, путаете с динамической типизацией?
В смысле как dynamic_cast с++?
Я не силен в теории современных языков. Когда я изучал программирование, их еще не было и терминология была сильно другая.
А еще меня раздражает питоновское форматирование. Мой любимый редактор на ней все время выкидывает фортели…
Впрочем это уже совсем мое старческое ворчание…
И еще. За все нужно платить. Питон хорош для маленьких поделок, на один, два, три листа кода. А вот с объемными проектами гарантированно будут проблемы.
В питоне, в переменной может быть все что угодно. Сейчас там число, чуть позже строка, а потом массив.
Не так. В Питоне переменная, по-сути, является нетипизированной ссылкой на строго типизированный объект. Т. к. эта «ссылка» нетипизированна, её в любой момент можно перенаправить на строго типизированный объект совершенно другого типа. Возможно, вы именно об этом и пишете далее («объект владеет переменной»), но тут уж, скорее, дело в отсутствии объявления переменных как такового. Впрочем, строго статически типизированный Rust позволяет наобъявлять что-то вроде
let x = 3;
let x = "blah";И ничего, как-то живут с этим.
В смысле как dynamic_cast с++?
В смысле, в языке с нестрогой типизацией вы запросто можете сложить вместе строку и массив целых чисел. Например, Javascript:
let msg = 'fuck my brain' + [1, 2]Питон такой содомии, всё же, не допускает.
Питон хорош для маленьких поделок, на один, два, три листа кода. А вот с объемными проектами гарантированно будут проблемы.
Да ну, нет. Объёмные проекты требуют дисциплины, пиши их хоть на чём. Питон, конечно, позволяет некоторый пофигизм, по-сравнению с С++ каким-нибудь, но с «объёмными проектами» там встают проблемы уже несколько иного порядка, на фоне которых все эти вот мелочи вроде «переменная владеет объектом или объект владеет переменной» вообще ни о чём.
Неудобно как неудобная обувь.
Пишу последние несколько лет, в основном, на Питоне. Мне, наоборот, удобно — даже если заранее знаю, что надо будет С++, зачастую мне быстрее и удобнее всё равно сперва написать прототип на Питоне. Что бесит, несмотря на мою любовь к Питону?
- Форматирование. К нему привыкаешь, без него Питон не был бы Питоном, оно снимает вопрос, оставлять фигурную скобку или переносить (но при этом усугубляет холивар «табы vs. пробелы»).
- Размытая и неявная грань между «ссылкой» и «значением». Некоторые объекты (большинство) передаются по ссылке всегда. Некоторые объекты передать по ссылке нельзя вообще никак.
- Сам синтаксис языка провоцирует совершать множество мелких ошибок, которые в C++ или Java спалил бы еще IntelliSense. А тут давай, до свиданья, в смысле, до рантайма.
- Иногда не хватает перегрузки функций — то, что легко и изящно делается на этапе объявления в таком неуклюжем языке, как C++, в минималистичном Питоне выглядит каким-то извращением.
Не так. В Питоне переменная, по-сути, является нетипизированной ссылкой на строго типизированный объект. Т.
Но при этом сам "строго типизированный объект" тоже может быть достаточно непредсказуемого типа из-за динамичности — можно менять поля и методы, можно заменить класс-подложку…
то, что он не допускает 2+"3", конечно, немного повышает порог, после которого начинаются чудеса и проблемы анализа (как ручного, так и машинного), но по сравнению с более устойчивыми в этом смысле языками — порог чудовищно низок.
Форматирование.
Его главная проблема не холивар — а когда встают вопросы типа "а сколько блоков и какие закрываются вот на этом сдвиге влево?"
При наличии {} все адекватные современные редакторы позволяют перейти на парную скобку, тут же такого нет (ну можно самому написать #end, конечно, но это локальное хакерство).
Сам синтаксис языка провоцирует совершать множество мелких ошибок, которые в C++ или Java спалил бы еще IntelliSense. А тут давай, до свиданья, в смысле, до рантайма.
Странно, ни разу не видел такого. Можно примеры?
Иногда не хватает перегрузки функций — то, что легко и изящно делается на этапе объявления в таком неуклюжем языке, как C++, в минималистичном Питоне выглядит каким-то извращением.
Имеется в виду необходимость писать с кучей именованных параметров со значениями по умолчанию?
Форматирование.
У меня почему-то проблем с визуальным разделением блоков как раз нет. Code folding работает, если что, во всех адекватных редакторах — можно свернуть блок, выделить строку, развернуть блок — выделенным окажется и всё содержимое. Навигацию хоткеями по блокам я, кажется, тоже где-то видел, но вот не помню, где именно (и правда ли видел).
Странно, ни разу не видел такого. Можно примеры?
Дык как раз всякая мелочь типа 2 + «3», когда код рефакторили, рефакторили, да не вырефакторововали. В итоге получается как в известной шутке: «Вы раз за разом стреляете себе в ногу, но всё время попадаете между пальцами.»
Имеется в виду необходимость писать с кучей именованных параметров со значениями по умолчанию?
Ну либо внутри функции парсить args и kwargs. Либо даже просто один-два параметра надо переопределить (чтобы работало и для 2 + 3, и для «2» + «3») — проверять типы переменных вручную в рантайме.
Code folding работает, если что, во всех адекватных редакторах — можно свернуть блок, выделить строку, развернуть блок — выделенным окажется и всё содержимое.
Меня интересует вариант без фолдинга. С фолдингом слишком много движений.
Навигацию я знаю — вон в vim есть роскошный плагинчик indentwise — но она в принципе не способна справиться с "тут закрываются сразу 3 блока, вам какой?" Тут нужно, чтобы появлялся отдельный попап с показом сразу всех подобных начал блоков. Вот такого я ни в одном IDE не видел, они явно не рассчитывают на проблемы таких языков.
Они, конечно, и на сишный
if (a)
if (b)
if(c)
d;
else
e;не рассчитывают, но там поставить обязательные {} это вопрос стиля и понимания от того, кто хотя бы раз сам походил по граблям.
Дык как раз всякая мелочь типа 2 + «3», когда код рефакторили, рефакторили, да не вырефакторововали.
Вы говорили про синтаксис языка. Этот случай не имеет отношения к синтаксису: это семантика типов и операций с ними.
Проблемы этой семантики известны, но их и IDE ловит, и линтеры — не всё, конечно, из-за неустранимой динамичности типизации, но заметную часть.
Таки есть замечания по синтаксису в этом плане?
не способна справиться с «тут закрываются сразу 3 блока, вам какой?»
В PyCharm, последовательно нажимая Ctrl-W, выделяем сначала «самый внутренний» блок, затем блок уровнем выше, затем ещё выше, и т. д. — это, думаю, должно быть удобнее просмотра попапа с показом начал. Вообще же, если редактор умеет правильно фолдить питоновский код, значит, структуру блоков он уже понимает, и задача написания плагина, который всё то же сделает одним хоткеем и без фолдинга должна быть достаточно тривиальной.
Этот случай не имеет отношения к синтаксису: это семантика типов и операций с ними.
Ой, да назовите, как хотите, у меня нет настроения заниматься буквоедством — семантика так семантика. Я про ошибки вида «структуру данных поменял, в десяти обработчиках исправил, в одиннадцатом забыл», и т. д., вплоть до банальных опечаток в именах переменных. IDE и линтеры, вроде бы, что-то ловят, но «не всё, конечно» — задолбать задолбают, а гарантий никаких.
это, думаю, должно быть удобнее просмотра попапа с показом начал.
Мне — нет. Многим, по отзывам, тоже.
Спасает только обычно малый размер функций.
Ой, да назовите, как хотите, у меня нет настроения заниматься буквоедством — семантика так семантика.
Не буквоедство, просто я в этом копался и хорошо чувствую разницу. OK, понятно.
IDE и линтеры, вроде бы, что-то ловят, но «не всё, конечно» — задолбать задолбают, а гарантий никаких.
Да, тут возможности сильно ниже типового языка со статической типизацией даже без современных плюшек типа систем типов.
При наличии {} все адекватные современные редакторы позволяют перейти на парную скобку, тут же такого нет (ну можно самому написать #end, конечно, но это локальное хакерство).
Всё есть. Адекватные Python-IDE позволяют. Даже Notepad++, что уж про PyCharm говорить. Точнее, не переход — а обозначение и сворачивание.
в языке с нестрогой типизацией вы запросто можете сложить вместе строку и массив целых чиселТипизация — это всё же больше о том, когда вы убираете у ваших данных поведение (или используете интерфейс иным неправильным образом), и они перестают тайпчекаться.
А сложение, которое дурно совпадает с конкатенацией — это мелочи.
Большие проекты на Python требуют MyPy.
Большие проекты на Python требуют MyPy.
я заметил тенденцию, что при росте размера проекта, туда начинают тащить и MyPy и контроль типов и абстрактные классы и самодельные интерфейсы… и и проект начинает быть похож а яву, написанную на питоне… причем это так забавно выглядит, сначала все мотивируется тем что питон выбран потому что не надо морочится всякой шелухой лишней… а потом те же люди начинают её туда костылить потому что окааазывается шелуха нужна
Python — просто не очень удачно спроектированный для широкого применения язык. Но это были лихие 90-е, тогда такой же Javascript был придуман и вообще казалось, что динамика с monkey patching даёт бесконечные возможности программисту (что правда).
Но для некоторых областей Python терпим и питоно-подобный синтаксис приятен.
и абстрактные классы и самодельные интерфейсыТут еще привычка к другим ЯП может сказываться. Абстрактные классы не особо нужны (inheritance coupling), самодельные интерфейсы покрываются Protocols из Python 3.8+.
флаг компилятора
Вроде, пишут, флаг линтера есть, флага компилятора нет. Но это не точно, точнее не могу сказать, мои попытки изучать Rust были весьма вялые и спорадические.
Ну не совсем. Типы-то вы можете указать, но рантайм Питона не обращает на них никакого внимания. Типы это для type checker, а оных немного и возможности их ограничены.
К сожалению, для data science библиотеки сплошной Питон.
habr.com/ru/news/t/519414
Одна из причин, почему я решил перестать заниматься дата сайенсом — потому что в 2014-м его можно было спокойно и продуктивно делать на плюсах (или $yourlangname), и никто не расстраивался, а в 2019-м уже все всё делают на питоне и ожидают знания питона
А как же скорость?!
Вообще мне кажется, что ниша учебных языков либо перестала быть востребованной, либо просто переживает тёмные времена. По факту Scratch, а дальше уже что-то взрослое.
Чем вам Керниган-Ритчи и Си как первый язык для обучения основам не угодилВ Си (и асме) ломает мозг и потом значительно усложняет освоения более высокоуровневых языков определение переменной: в С это именованный адрес (ячейка памяти), а в высокоуровневых языках — именованное значение.
До этого это именованное значение и все. Не надо ученикам голову лишними вещами забивать.
Именованное значение это скорее — константа.
Ну там всё равно будет фактический эквивалент адреса в виде какого-нибудь id объекта и проверки его на идентичность другому такому же.
(Уточнение: мне недавно доказывали, что в Haskell этого нет. Готов поверить: для таких языков идентичность может не являться чем-то важным по сравнению с равенством.)
Ну я ровно про это же. Проверить идентичность там таки доступно, и это типовой вариант для таких средств. Что этот адрес, даже если доступен, может меняться — это уже неизбежная специфика реализации.
Можно его сравнить на равенство другому.
На самом деле я сделал акцент на то, что «именованному значению» больше соответствует понятие константы, а не переменной.
Строгий «академический» ответ на этот вопрос приведен в монографии Столярова, ссылку на которую дали в комментах выше.
А я по-простому скажу. Си похож одновременно на самурайский меч, турецкую саблю и мушкетёрскую шпагу — устроен очень просто, в нём почти ничего нет, но приёмы написания программ на нём — сложны и замысловаты. И для освоения именно этих приёмов (и безопасного их применения!) нужно много специальных знаний.
Таким образом, изучение Си на уровне чуть выше элементарного тут же превращатся в изучение операционной системы (что такое файл? а дескриптор файла? И зачем функция dup2?), архитектуры компьютера (ошибки buffer overflow где-то рядом, а вместе с ними — опасные уязвимости) и прочих интересных вещей. Такие знания, разумеется, программисту тоже нужны, но на самом начальном этапе обучения программированию у студента начинается информационный перегруз — он не в состоянии справиться с потоком сведений и отделить важное от неважного, как, собственно, и произошло с автором исходного поста.
Все тонкости не нужны. Замысловатости заканчиваются на выборе имен переменных.
Прочитать файл — вот одна функция. Или вобще вот плюсовой стрим. Мы не стремимся к чистоте кода или языка. Мы стремимся чтобы попроще было. Просто прочитать или записать файл это несложно.
Что-то утекает или не безопасно? Ну и ладно. Файлик прочитан, данные из него корректно обработаны. Остальное не важно.
И непонятно, зечем вы спорите с тем, что сложность наращивать нужно постепенно. В школе тоже начинают с азов, а потом наращивают обороты. Язык С низковат уровнем и достаточно сложен для написания. Паскаль же весьма идеален для обучения базовым принципам программирования.
У человека проблема с пониманием N=N+1 и несложной задачки, а вы тут про примеры по 50-100 строк…
Тут я бессилен. Знание школьной математики и понимание абстракций предполагается изначально.
В школе тоже начинают с азов, а потом наращивают обороты. Язык С низковат уровнем и достаточно сложен для написания. Паскаль же весьма идеален для обучения базовым принципам программирования.
Да нет понятия низковат в начале обучения. Там циклы с ифами. Они везде одинаковые.
Сообщество разработчиков решило что Паскаль плохой и они не хотят на нем писать.
Сообщество бизнесменов решило что Паскаль плохой и они не хотят платить за написание на нем.
Но молодежь мы по прежнему будем заставлять жрать кактус. Зачем? Почему следующее поколение должно ходить по тем же граблям? Почему бы не взять что-то что оценено разработчиками и бизнесом? Люди деньги зарабатывают и точно понимают в качестве языков.
Я надеюсь что Си как рекомендация для начала скоро уйдет. Раст или Го смогут занять эту нишу лет через 5. Если для них все хорошо сложится.
Сообщество разработчиков решило что Паскаль плохой и они не хотят на нем писать.
Сообщество бизнесменов решило что Паскаль плохой и они не хотят платить за написание на нем.
Ни сообщество разработчиков, ни не сообщество бизнесменов ничего такого не решали.
Некоторые разработчики как пользовали Паскаль (не тот самый виртовский, конечно, а обновленный и дополненный, но и на С++ сейчас в основном пишут тоже не на том самом, доисторическом, а хотя бы на 11-м), так и пользуют.
Некоторые бизнесмены как полагались на программное обеспечение, которое было написано, сопровождается и пишется на Паскале (сейчас это как правило Delphi), так и полагаются до сих пор (как и на тот же Кобол, кстати).
И все, что характерно, деньги зарабатывают.
Понятно, что не будь наследия старого кода, никто бы на Паскале не программировал нигде, кроме как в хоббийных проектах или в научной компьютерной археологии (если такая существует).
Но это совсем не от того, что Паскаль "плохой", а от того, что основная часть индустрии работает на более других языках, соответственно, для тех языков богаче библиотеки, больше наработок, которые можно использовать.
Но молодежь мы по прежнему будем заставлять жрать кактус.
Я учился программированию в школе на Фортране (весьма популярный и очень широко используемый на тот момент язык) и ЯМБе (занятный такой язык, очень ограниченный в возможностях, чуть сложнее языка программирования программируемых калькуляторов).
Только потом в работе я их вообще никогда, нигде и никак не использовал. Программировал совсем на других языках (очень разных).
Вот точно то же самое может статься с любым "актуальным" языком, выбранным для обучения в школе — пока пациент дозреет до реальной работы, язык может стать нишевым, редко используемым, или окажется широко используемым, но в сфере, которая пациенту совершенно неинтересна.
Так что актуальность языка для начального обучения — так себе аргумент.
А вот общие навыки программирования, приобретенные при изучении Фортрана и даже ЯМБа, очень даже пригодились. В том числе даже в понимании фишек языков, которых в изученном мной Фортране не было как класса (тех же классов, кстати).
сейчас это как правило Delphi
Некоторые это подавляющее меньшинство.
Самый простой критерий. Количество вакансий на hh.
Delphi — 153
C++ — 1295
Java — 2876
И как вы понимате тенденция не в сторону роста Дельфи. Легаси живет и поддерживается. Местами даже развивается. Но это все уже легаси.
Но это совсем не от того, что Паскаль «плохой», а от того, что основная часть индустрии работает на более других языках, соответственно, для тех языков богаче библиотеки, больше наработок, которые можно использовать.
Это и есть выбор разработчиков. Никто не хочет делать билиотеки для Паскаля. Для того же Раста наделали оптом всего. Добровольно и бесплатно. На нем даже работы толком нет еще, а библиотеки уже пишут с радостью.
Это и есть выбор бизнеса. Бизнес считает что разработка на других языках эффективнее. И платит за разработку на них, а не на Паскале.
Вот точно то же самое может статься с любым «актуальным» языком, выбранным для обучения в школе — пока пациент дозреет до реальной работы, язык может стать нишевым, редко используемым, или окажется широко используемым, но в сфере, которая пациенту совершенно неинтересна.
Так что актуальность языка для начального обучения — так себе аргумент.
Мы точно знаем что Паскаль актуальным не будет никогда. У него уже нет сообщества (тот же so) в котором есть ответы на все вопросы. По поводу других языков такой уверенности нет, а сообщество есть. Выбор очевиден.
Кстати, Си спокойно съест if (i = 1), а Паскаль if (i:=1) не пропустит никак, да и заметно, что в сравнении что-то не так.
У меня Си был третьим языком после Бейсика и Ассемблера Z-80, Паскаль не учил вообще, просто писал на нём, когда надо было, без всякого обучения, уже после Си.
Кстати, Си спокойно съест if (i = 1), а Паскаль if (i:=1) не пропустит никак, да и заметно, что в сравнении что-то не так.
И компилятор и IDE скажут что не надо так писать. Игнорировать предупреждения это вообще плохая практика. Для любого обучающегося это обычная ошибка. Он ее найдет и поправит.
На чем учить? Все что ООП это сложно. Точнее так. Обезьянку научить кодить можно. Полгода-год и вперед деньги зарабатывать. Питон или js.
Но цель обучить программиста. Время есть, семью ему кормить не надо. С чего начать? Сразу Джаву или js давать? Он основы понимать не будет. Сразу Питон давать? Он еще дальше от основ будет. Это ему все аукнется потом. Нужен любой простой язык. Который близок к компьютерам. Чтобы обучить человека как машина работает. И научить програмировать эту машину. Асемблер сложно. Вот и остается Си. Раст молодой слишком. Лет через 5 может я за него топить буду.
Полгода-год и вперед деньги зарабатывать. Питон или js.
Подскажите, пожалуйста, где именно через полгода можно зарабатывать деньги со знанием питона или JS?
Джунов готовых работать за еду набирают много где
Забавно, что выразились вы очень точно, и сами не поняли что написали.
Ситуация очень простая: "деньги зарабатывать" вы не будете ни через полгода, ни через год.
Зарабатывать вы будете еду — это в лучшем случае, на большинстве стажерских должностей вообще никакая оплата, даже едой, не предполагается. А оставшаяся часть стажировок ещё и требует денег от вас — это всякие «платные курсы с трудоустройством», причём трудоустройство по итогу не слишком-то и гарантированное оказывается.
А оставшаяся часть стажировок ещё и требует денег от вас — это всякие «платные курсы с трудоустройством», причём трудоустройство по итогу не слишком-то и гарантированное оказывается.
Откровенный обман же. Если человек на такое покупается сам виноват.
В платных курсах нет ничего плохого. Работа преподавателей стоит денег. Обучение с преподавателем в среднем эффективнее чем без преподавателя. Но если они что-то там гарантируют, то бежать надо из таких мест.
Чтобы не думать и голоде и физическом выживании.
Первое — верно, второе — нет. Если вам нужно что-то ещё кроме еды (например жильё) — это уже не вариант, а без жилья вы физически выживать не очень сможете даже с едой.
Пойти работать за деньги которых хватает на еду это уже нормальный уровень для новичка. Он по уровню сравним, а то и ниже, со свежим выпускником не топового вуза. С чего ему платить больше? Дальше можно развиваться и набираться опыта.
Я другого пути не знаю. Смена профессии это больно.
Средняя зарплата в Москве около 80к. Делаем скидку что опыт нужнее всего и ставим планку в 50к на руки. Выглядит реально. Жить на 50к можно. Даже на аренду комнаты хватит.
Если вы влезли в кредиты и ипотеки, а потом решили сменить профессию вы сами виноваты. Думать надо заранее.
UPD
Хотя нет, это было бы слишком легко, социал-дарвинистского дурачка надо тыкать носом в его дурость.
Вам, конечно, не составит труда указать, где именно стажеру платят 50к на руки. Вообще в Москве стандартный уровень для стажера колеблется от 15 до 25. Технически можно снимать койку в общежитии для таджиков за 5к в месяц, но я хочу, чтобы и это вы проговорили прямо без вранья про 50к.
где именно стажеру платят 50к на руки. Вообще в Москве стандартный уровень для стажера колеблется от 15 до 25. Технически можно снимать койку в общежитии для таджиков за 5к в месяц
Для москвича сидящего на шее у родителей — вполне себе возможный вариант джуниорства.
Для москвича сидящего на шее у родителей
Вы добавляете в систему всё больше и больше неучтённых изначально параметров.
А для миллионера, которые получает доход с акций SP500, вообще зарплата за стажировку не нужна, если он просто захочет научиться из интереса.
Разговор про москвича на шее у родителей вообще не шёл. Москвич на шее у родителей может жить хорошо на подавляющем большинстве работ, потому что главная статья расхода для человека не из Москвы, работающего в Москве — это жильё.
Разговор про москвича на шее у родителей вообще не шёл. Москвич на шее у родителей может жить хорошо на подавляющем большинстве работ
Ситуация такова, что из-за желающих Вайти-в-АйТи, каждый год выпускает огромное количество студентов с дипломом программиста при отсутствии какого-либо опыта. Потому работодатель выбирая из их числа джуниора, может найти согласных на такую оплату, при которой без сидения на шее у родителей в большом дорогом городе не прожить.
Именно так.
Вы всё правильно пишете.
Именно это я пытался сказать, когда выше оставил недоверчивый комментарий к сомнительному утверждению: «полгода-год и вперёд — деньги зарабатывать».
Вот и вы подтвердили — нет, это так не работает.
Ваш личный пример не доказывает, что это работает в общем случае.
Открыл хедхантер, указал москву, вакансии для джунов. От 40-50к цифры
Открыл росстат, посмотрел среднюю зарплату, а там 50тыщ средняя зарплата в России. НУ ЧТО Ж, НАВЕРНОЕ ТАК И ЕСТЬ.
Как дети, ей-богу.
Вы, наверное, просто не в курсе, что на каждую вакансию работодатель получает от 100 до 500 откликов. Поэтому 90% резюме сразу идут в корзину. Например, по признаку возраста. Поэтому если вы «переехали из деревни в город», скажем, лет до 30 — у вас был шанс попасть в те резюме, которые выжили. А если бы вам было больше 30 — ваше резюме просто сразу ушло бы в корзину, возможно даже не ручным отсевом по возрасту, а по скрипту, проверяющему дату рождения.
И это только один параметр, остальные я даже не буду описывать, чтобы не слишком травмировать ваше прекраснодушное представление о рынке труда.
Вакансии есть. Типичной зарплаты в этих вакансиях для жизни, и даже аренды чего-нибудь скромного, хватает.
Дальше пробуйте. Я не верю что никто не возьмет. При должном старании и хоть каких-нибудь умениях.
Вообще в Москве стандартный уровень для стажера колеблется от 15 до 25
специалист коллцентра без опыта работы в Мск получает 30к
Устраиваться стажером за 15 это какойто суровый дауншифтинг с точки зрения рынка труда
@
«Я в вашем возрасте за копейки работал!»
@
«Это вклад в будущее»
и т.д. и т.п.
Специалист коллцентра получает 30к без опыта, потому что те, кто его нанимают и сами специалисты знают, что эти 30к как были, так и будут.
Перед носом стажера в JS висят зарплаты в 300кк/сек «когда-нибудь потом», поэтому прямо сейчас на горбу у них можно ездить значительно активнее, чем у операторов коллцентров и кассиров в ашане.
Да примерно везде. Надо искать не стажера, а джуна. Стажер это обычно студент не на полный день.
Ищите не большие корпорации, а мелкие конторки. Им люди сильнее нужны.
Рядом подтверждают что даже в провинции 25 платят.
По жилью не сильно в курсе рынка, дочка до прошлого года снимала двушку в достаточно центральном районе — 17 + коммуналка.
25 в Мск на мой взгляд совсем не те деньги, на которые стоит соглашаться.
Дельфисты атакуют
Насильников? ;)
Не знаю, мне нравится
github.com/Clozure/ccl/releases
released this on 20 Apr
Понятно, что это стёб, но вообще Lisp вполне хорошо подходит для обучения программированию в нормальном режиме (а не как у автора статьи, когда надо через год на работу устроиться). Правда, я бы посоветовал взять Racket — прекрасная современная реализация Scheme.
У него плохой синтаксис.
?!?
Посмотрите например пассаж про яблоки апельсины и целые числа.
В свете сползания с к плюсам половина текста уже не релевантна.
Просто он весьма необъективен, а Вирт мужик весьма порядочный
Впрочем это уже о другом
PS Да и посмотрите на его собственное детище язык AWK.
Посмотрите например пассаж про яблоки апельсины и целые числа.
Так он до сих пор прав. И в 2020 году это выглядит ужастно.
Можно складывать теплое с мягким. Да, это работает. Специально проверил.
program p1;
type
apple = integer;
orange = integer;
var
apple1 : apple = 0;
orange2 : orange = 0;
begin
apple1 := 1;
orange2 := 2;
writeln(apple1 + orange2);
end.В свете сползания с к плюсам половина текста уже не релевантна.
Плюсы это отдельно. Мы про первый язык. Для обучения самым основным понятиям.
Плюсам тут не место. Немного самого простого сахара взять из них и хватит. Чтобы обучающиеся страдали поменьше.
PS Да и посмотрите на его собственное детище язык AWK.
Специализированный язык. Вроде sed. Что такого? Тогда еще было непонятно как такое должно выглядеть чтобы удобно было. Вот и делали все подряд. Не проверишь не узнаешь. Это мы сейчас опытные.
#include <stdio.h>
typedef int apple;
typedef int orange;
apple apple1 = 0;
orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =2;
printf("%d\n",apple1+orange2);
return 0;
}Все чего то стOит, и за всеми решениями есть компромиссы
У Ады типы строже, а компилятор тяжелее
С break вообще все сложно. Была сильная парадигма структурного программирования. Она и сегодня во многом релевантна. А break в нее не укладывался толком.
Ключевое слово typedef позволяет программисту создать псевдоним для любого типа данных и использовать его вместо фактического имени типа. Чтобы объявить typedef (использовать псевдоним типа) — используйте ключевое слово typedef вместе с типом данных, для которого создается псевдоним, а затем, собственно, сам псевдоним.
А вот в документации по Паскалю слова синоним не видно. Как понять без эксперимента что это именно так будет работать я не уверен.
Ссылок не даю. Где лежит правильная документация на которую не стыдно сослатьcя я не уверен.
#include <stdio.h>
enum apple{one, two};
enum orange{four,five};
enum apple apple1 = 0;
enum orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =2;
printf("%d\n",apple1+orange2);
return 0;
}Занудным голосом лектора: enum в Сях это не тип, это просто кучка именованных интов. Используется чтобы избежать магических цифр в коде.
#include <stdio.h>
enum apple{one, two};
enum orange{four,five};
enum apple apple1 = 0;
enum orange orange2 = 0;
int main()
{
apple1 = 1;
orange2 =200;
printf("%f\n",1.0+2.0f+apple1+orange2+'b'+'a'+'n'+'a'+'n');
return 0;
}я это к тому, претензия на смешивание типов к Паскалю от Брайана по меньшей мере забавна.
Те, кто считает, что для того, чтобы научиться программировать, надо учить конкретные языки программирования, никогда программистами не станут. Язык — это не цель, а всего лишь инструмент. И изучать надо общие принципы работы с инструментами.
Да и просто новичков не хотим учить вымершему языку.
Тут Кобол никак похоронить не могут, а вы Паскаль в вымершие записали.
А что написано на Паскале из того, что все еще активно используется?
А Дельфи, Паскаль? Сколько там время жизни приложения?
Вот сейчас в банке. У нас работает огромное количество кода, написанного лет 10 назад. И никто его не будет менять до тех пор, пока оно работает. Да, при необходимость вносятся изменения, доработки.
Правда, у нас не кобол, RPG. Он вполне себе живет и развивается (хотя узконишевый, платформа AS/400).
На Паскале (точнее на Object Pascal, еще точнее на Delphi) написано огромное количество кода, который до сих пор используется и развивается. Лично знаю людей, которые занимаются не просто поддержкой такого кода, но и написанием нового.
Что еще интереснее, несмотря на среду разработки и диалект языка, далеко не весь код написан и пишется в парадигме ООП. Значительная часть — это просто старый добрый голый процедурный Паскаль (когда там в него юниты завезли?)
Более того, тот факт, что Embarcadero при наличии совершенно свободного (хотя и не столь продвинутого) конкурента (Free Pascal) пока не разорилась, продавая Delphi (не так уж и дешево, кстати, продавая), как бы намекает, что оно востребовано не только на уровне DIY.
Понятно, что язык стал весьма нишевым, но жив, и еще не подает признаков приближения смерти.
Вот с этого места — и без вкусовщины. Сможете обосновать?
Вот мнение stackoverflow. Можно по соседним разделам тоже покликать.
Я ни Паскаля ни Делфи там не вижу. Хотя даже очень молодой Раст уже есть.
Но можете ли вы аргументировать свое утверждение, что синтаксис паскаля плохой? Не для вас, а вообще? Потому что на мой взгляд, все подобные утверждения — чистая вкусовщина. Ну так, процентов на 90.
Писать код можно? Да можно.
Нравится? Нет.
Со мной общество согласно? Согласно. SO подверждает.
Бизнес со мной согласен? Тоже согласен. SO подверждает.
Считаем что я прав. Синтаксис плохой. Был бы хороший на нем люди бы хотели писать или бизнес платил бы. А ни того ни того не происходит.
Есть некие остатки работ по поддержке легаси. Так они много на чем есть. Не критерий.
Ну очень просто. Объективные показатели есть? Скажем, простота и эффективность парсера/компилятора (с этим у семейства C так себе обстоит). Не то чтобы они покрывали все аспекты, но попробовать сформулировать можно.
>Считаем что я прав. Синтаксис плохой. Был бы хороший на нем люди бы хотели писать
На мой взгляд, синтаксис в этом деле дело не то чтобы десятое, а скажем примерно пятое. Скажем, Java считается по синтаксису близким к C. Ну, насколько близки — это вопрос темный, но с другой стороны, не к паскалю же, верно? Если ли у них что-то общее в применении? Я бы сказал, что нифига — ниши разные. Популярны ли они за счет своего синтаксиса? Я бы тоже сказал, что нифига — популярны, но каждый по своему, за счет разных своих характеристик.
Ну очень просто. Объективные показатели есть? Скажем, простота и эффективность парсера/компилятора (с этим у семейства C так себе обстоит). Не то чтобы они покрывали все аспекты, но попробовать сформулировать можно.
Вот на простоту парсера/компилятора всем глубоко пофиг. Их пишут специальные люди, которым это нравится. Массам все равно.
Эффективность парсера/компилятора посчитанная в скорости сборки приложения уже важна. У плюсов с этим все очень плохо. Их в том числе за это не любят. Но для учебных целей это тоже не так важно. Проекты маленькие, собираются быстро в любом случае.
На мой взгляд, синтаксис в этом деле дело не то чтобы десятое, а скажем примерно пятое. Скажем, Java считается по синтаксису близким к C. Ну, насколько близки — это вопрос темный, но с другой стороны, не к паскалю же, верно? Если ли у них что-то общее в применении? Я бы сказал, что нифига — ниши разные. Популярны ли они за счет своего синтаксиса? Я бы тоже сказал, что нифига — популярны, но каждый по своему, за счет разных своих характеристик.
Хороший синтаксис с точки зрения бизнеса это такой который позволяет эффективно писать код и доводить его до прода. Бизнес умеет считать деньги.
Точка зрения разработчиков на язык тоже бизнесу важна. Если язык людям массово не нравится нанимать на него становится сложно. Это тоже потеря денег. Надо дольше искать, предлагать больше денег. Лишние траты.
Попробуйте сейчас нанять Перл разработчиков. А кода в проде на нем море.
В итоге популярными языками становятся те которые и программистам нравятся и код позволяют эффективно писать. А вот все остальное дело десятое. Почти все можно написать в общем на чем угодно. Исключения есть, но это именно исключения.
Язык часто выбирается по вкусу и по наличию людей.
Паскаль этот отбор не прошел. Хотя был сильнейший игрок на его стороне. Для своего времени Дельфи был великолепен. И все равно не пошел.
Паскаль этот отбор не прошел. Хотя был сильнейший игрок на его стороне. Для своего времени Дельфи был великолепен. И все равно не пошел.
Паскаль-то в своё время был популярен как сейчас Питон:
изначально это был учебный язык на котором учились студенты, и который потом использовался продакшне.
Классический Паскаль сдох во время перехода от Dos к Windows.
А Дельфи убила потеря совместимости исходников между восьмой и седьмой версиями. :(
А Дельфи убила потеря совместимости исходников между восьмой и седьмой версиями. :(
Скорее её платность. Когда даже MS выкатила бесплатную VS Express, Delphi продолжала оставаться платной, даже для учебных целей. Поэтому популярность её более-менее держалась только в СНГ, где всем тогда было плевать на лицензионную чистоту. Но где-то после 2008 года, у нас тоже началось движение в сторону легализации используемого софта.
Хотя попытка погнаться за .NET тоже была не на пользу. За Delphi никогда не стояло столь крупной компании, чтобы эффективно и успешно двигаться в разных направлениях.

А потом совсем уж какая-то "наркомания" вышла, в виде Delphi for PHP. В общем, полная расфокусировка.
Вот на простоту парсера/компилятора всем глубоко пофиг. Их пишут специальные люди, которым это нравится. Массам все равно.
Это не так, когда
1) Нужно поднимать компилятор, чтобы обеспечить просто правильную раскраску в редакторе,
2) Путаность синтаксиса доходит до той степени, что сообщения об ошибках просто становятся непонятными.
У меня как-то тупой ляп вызвал генерацию >7000 строк в выхлопе GCC, причём он сказал, что ещё самые длинные простыни урезал.
Но для учебных целей это тоже не так важно. Проекты маленькие, собираются быстро в любом случае.
Вот и у меня и было 7000 строк ошибок на учебном проекте. Ну да, он был с применением Boost.Spirit.
Vim вам все покрасит без проблем. Думаю что даже Notepad++ справится.
Подозреваю что если очень постараться их раскраску можно сломать, но зачем?
Плохие сообщения об ошибках известная проблема. Ну не могут же быть одни плюсы. Для действительно начальных проектов в 50-100 строк она не должна стрелять часто. А дальше обучение можно переводить на Питон.
Vim вам все покрасит без проблем. Думаю что даже Notepad++ справится. Подозреваю что если очень постараться их раскраску можно сломать, но зачем?
Так цель не сломать сам редактор, а написать что-то под конкретную задачу и принятый стиль. А сломается разметка сама, я уверен, что мало-мальски запутанные конструкты оно тупо ниасилит.

выглядит — восхительно!
По вашему коду даже если совершенно не знать языка, на котором написано, легко выделяются некоторые структуры. Например, ясно что каждая из строк со знаком "=" это объявление чего-то вроде функции, знак ":" некоторым образом задаёт типы, в скобках после названия определяемой функции стоят аргументы, некоторые используемые операторы можно догадаться что делают, и т.п. А по APL из предыдущего коммента не понятно ни-че-го.
Это, какой-то диалект APL, или другой язык?
Я обосновывал неоднократно, повторю основное:
- Отсутствие обязательности блоковых скобок. Устранено в Modula (там сделано if cond then… else… end, без глупого begin).
Сюда же: различие между while (нужны скобки для блока) и repeat-until (не нужны). - ';' как разделитель, а не завершитель — всех сбивает с толку, взрывается перед else.
- Особый (недоступный прикладному программисту) для повторения — синтаксис форматного I/O (типа write(a:5:2)). Тут же — выделенный необязательный первый аргумент.
- Дебильные приоритеты операций, так, что в if a>0 or b>0 надо ставить скобки, чтобы оно не поняло как if a>(0 or b)>0.
- Необязательность необходимости писать () для вызова функции или процедуры без аргументов.
Это то, на чём шёл регулярный взрыв мозга у моих учеников.
Разумеется, есть и вкусности — паскалевский порядок определения переменных (var x: int вместо int x) начинают только сейчас массово ценить, или различие двух делений. Но при его старте они были сильно менее важны, чем все названные диверсии.
Никогда не было взрыва мозга от таких конструкций.
- В С/С++ те же проблемы.
- Это надо просто принять. Если мозг на это все еще реагирует, считайте, что условный оператор имеет форму
if ... then begin ... end else begin end;
Мозг сразу успокоится.
Считайте, что write в паскале не функция, а оператор (по крайней мере нам так объясняли). Мозг сразу успокаивается.
"Необязательный первый аргумент" вообще не напрягает. Обычный полиморфизм (тип первого аргумента отличается), даром что у оператора, а не у функции.
Какие приоритеты введены, такие есть. Достаточно просто выучить.
Это вы еще с MUMPS не имели дело, после которого я скобки везде расставляю: например, 2+(2*2).
А в чем проблема?
В С/С++ те же проблемы.
Во-первых, не те же. ';' в качестве разделителя они не вводили.
Во-вторых, не зря почти все современные языки имеют принудительные блоки — или в форме {} (Rust, Go, Swift), или в форме then/else — end (Ruby).
Считайте, что write в паскале не функция, а оператор (по крайней мере нам так объясняли). Мозг сразу успокаивается.
Ну как и говорилось — ещё одно исключение, которое надо тупо зазубрить.
Это вы еще с MUMPS не имели дело
Я имел дело с kdb+. Там приоритетов считай нет и порядок разбора — справа налево. Но почему я должен этим загромождать мозги свежеобучаемых?
А в чем проблема?
В неестественности.
В моем комментарии циферки пунктов после 2-го пропали почему-то, не уследил, ну да ладно,
"';' в качестве разделителя" — это уже второй пункт.
А вот проблемы со скобочками блоков у С/С++ и Паскаля общие (если не считать repeat… until).
На
if (...)
...;
...;
многие обожглись (хотя современные компиляторы вроде предупреждать должны).
Ну как и говорилось — ещё одно исключение, которое надо тупо зазубрить.
Таких исключений и неестественностей в любом языке достаточно, чтобы создать некоторые сложности обучаемому. Одно то, что char — число, которое можно прибавить к другому числу, но 1+'1' почему-то равно совсем не 2, многим тоже взрывает мозг. И ничего, как-то собирают потом его в кучу.
delhi_heir
Лучше писать вот так:
Это хабр отступы съел, хотя и обрамил вроде тегом кода на Delphi. Да и действительно, кое-где оно явно не "по феншую" получилось. Не углядел, однако. Впрочем, формирование отступов у языковых конструкций — тема холливарная сама по себе.
считайте, что условный оператор имеет формуif ... then begin ... end else begin end;
Лучше писать вот так:
if ... then begin
...
end else begin
...
end;
и в С++ тоже:
if ... {
...
}else{
...
};
Но это, конечно, тоже выкрутас, не повторяемый в пользовательских функциях, где можно урезать список аргументов в вызове только начиная с последнего аргумента.
Так и я не лично для себя. Но когда это продвигают пригодным для сейчас учебным языком — выглядит, мягко говоря, странно.
У них есть свои ограничения, само собой, но это практичные языки, на которых можно делать проекты прямо сегодня, закончив учиться.
Что названо словом «это»?
Паскаль.
— из-за динамической типизации, Питону не хватает Строгости
— а упоминавшемуся выше, C не хватает Простоты
Минус же Паскаля в том:
— что если знаешь любой C-подобный язык, то перед тобой открываются широкие возможности
— если знаешь Паскаль, то выбор невелик: не самый распространённый Дельфи, и чуток полегче выучить PL/SQL основанный на Аде.
Первый и главный минус Паскаля в том, что он (Паскаль, а не какие-то современные потомки в виде Delphi с заметными отклонениями от предка) непригоден для сколь-нибудь реальных задач. Даже массивы переменной длины и модули это уже расширение языка.
Я даже не рассматривал в своих предыдущих комментариях классический Паскаль Вирта; все оценки шли хотя бы от уровня TP5, где всё это уже есть. Возможно, это стоило упомянуть раньше, но я рассматривал его именно как учебный язык при условии, что самые большие ляпы уже нейтрализованы. Но если и их включать, то получится вообще абсолютная непригодность.
С по сравнению с этим реален, а его сложные проблемы вроде указателей можно вводить в обучение постепенно.
что если знаешь любой C-подобный язык, то перед тобой открываются широкие возможности
Идущему на профессионала перейти на C-подобные после Паскаля нет проблем, если уже научен базе. Я это наблюдал неоднократно.
А вот тем, для кого программирование только малая (хоть и обязательная) часть профессионального багажа, тем будет сложно.
из-за динамической типизации, Питону не хватает Строгости
Личный опыт показывает, что для обучения динамичность не мешает до определённого момента — грубо говоря, выхода на 200-строчные программы. Но этот рубеж и так проходят те, кто идут в программисты — поэтому им и смена языка не проблема.
Первый и главный минус Паскаля в том, что он (Паскаль, а не какие-то современные потомки в виде Delphi с заметными отклонениями от предка) непригоден для сколь-нибудь реальных зада
Пару лет назад правил написанную на Паскале программу для пульта с ОЗУ меньше мегабайта (правда, это крайне редкая и специфическая узкая область применения, где чаще применяется C «как у Арудины»).
И вы тоже путаете сильную типизацию (лучше так говорить, чем "строгую"), которая в Питоне есть для примитивных типов и в значительной мере — для объектов, со статической, которой там таки нет, если не подключать всякие аннотации и линтеры.
Я частично согласен с предполагаемой сутью вашего утверждения, но давайте быть таки чуть строже в терминах и не путать ортогональные вещи.
Вот, откровенно не считаю книгу Кернигана и Ритчи древней. Мне кажется она открывает глаза на многое. По крайней мере с другими языками жить становится проще и понятней.
Математика не то чтобы сильно нужна, но если даже с квадратным уравнением проблемы, стоит заняться чем-то другим, правда.
А какие могут быть сложности с линейными уравнениями или это шутка?
Есть люди мечтающие Вайти-в-АйТи, у которых всё плохо с линейными уравнениями.
Не смотря на то что это тяжко все, не мешало работать в компании связанной с энергетикой и реализовывать вычислительную математику для электрических схем.
Просто у кого-то все на интуиции, а кому-то надо код писать глядя в справочник)
Не знать — это нормально. Ненормально — не уметь загуглить и разобраться.
Я формулу тоже, конечно же, не помню. Ну выведу минут за 10-15, если окажусь без интернета и будет очень надо.
Кстати, раз вы разработкой игр занимаетесь, наверняка знаете, только не задумывались. Какой ray tracing без квадратного уравнения?
Тоже была пауза почти в 8 лет в ИТ, тоже работал админом… тоже некоторые разочарования в планах (точнее сроках) Только проблемы несколько иного порядка мне планы тормозят.
Коммерческим программистом (ready to relocalte) за 1,5 года стать мОжно, если есть какаято база, я в первые в жизни открыл питон в 2016 году устроившись работать сразу миддлом на питон-бекенд программиста. НО я до этого программированием увлекался как хобби с 97 года… писал на VB/C#/Java и работал около 5 лет 1C программистом в 2000х хотя у меня до сих пор возникают проблемы с собеседованиями (в РФ)
А в данном вопросе надо пройти собес так чтобы с опытом 1,5 года убедить работодателя тебя релоцировать...imho довольно непростое занятие
Но вот конкретно у меня проблемы были
1) с языком, я думал что довольно сносно знаю язык и надо «чуть подтянуть»… до первого звонка рекрутера из вакансии на Monster ;) а раскачать язык на уровень выше надо минимум полгода (и то это тоже при оптимитичном варианте)
2) Вопрос «решил через 1,5 года переехать в США» — это ооочень оптимистично, я в течении года прошерстил все миграционные особенности большинства «нормальных» стран и это далеко не такой простой и легкий путь как часто пишут на хабре (очень часто забывают упоминать очень важные детали, о типе визы, о работодателе, о наличии профильного образования, которые зачастую являются заградительными у многих стран)
===
но вот знания теории (в плане какойто математики) на самом деле не так важны, важнее знать типовые вопросы на собеседованиях, остальное не так важно, всёравно большая часть работы это рутинные типовые сервисы где большинство этого не нужно
а) Нормально относилась в школе к математике за пределами таблицы умножения.
б) Закончила хотя бы пару курсов технического ВУЗа.
И им не понять истинных гуманитариев или естественников. То что кажется очевидным технократам в понимании Нила Стивенсона — как задачка про огораживание загона — для кого-то вовсе неочевидно.
Для сравнения и получения гм… сходных ощущений можно окунуться в биологию. У меня знакомая написала как-то популярную (в её понимании) статью по биологии.
Вот пример фразы: "… успех комбинации блокирования ингибирования PD-1 / PD-L1 с комплементарным ингибитором иммунной контрольной точки CTLA-4 при меланоме и немелкоклеточном раке легкого...". Я из всей статьи понимаю только отдельные слова.
Способность понять технический текст – привилегия. Она дается образованием, которое доступно лишь членам элиты. Вот какой смысл я вкладываю в слово «технократ». «Криптономикон» Нил Стивенсон
По поводу цитаты, терминология — это не самая большая проблема. Имхо, сложнее сам подход к проблеме, аппарат науки и реальная деятельность. По-моему, расшифровать текст сравнительно несложно, если знать, что аббревиатуры — обычно белки (или другие конструкты) и загуглить некоторые термины (вроде «контрольной точки»). Скорее всего за месяц вдумчивого чтения, получится с лету понимать о чем речь. Другое дело, что в реальной лабе ничего не светит (кроме повторения банальностей), но вот и с программированием та же штука.
Что у меня всплывает в голове связанное с квадратным уравнением -коэффициенты… дискриминант… теорема Виета… кубическое уравнение сводится к квадратному… график — парабола… задача на экзамене по математике должна приводить к квадратному уравнению… производная — линейная функция, интеграл — кубическая… уравнение теплопроводности с источником… и т.д… И у биологов, очевидно, аналогично.
Отличие химиков-биологов от настоящих программистов заключается в том, что их код не имеет ничего общего с индустриальным программированием, потому что конечной целью не является написание и сопровождение кода. Для химика-биолога программирование — это просто использование вспомогательного инструмента для решения своих задач.
Я не знаю, у меня это личная нелюбовь, или действительно звоночек, когда человек по любому поводу, вот прямо начиная с квадратного уравнения и знакомства с языком С, лезет смотреть видеоролики? Я понимаю, что времена такие, но все же мне кажется, что чтение — это в крови, если человек по умолчанию настроен на аудио/видео канал, то кодерство не совсем его стезя. А по теме — ну да, потому и существует в этой области высшее образование и вообще наука всякая, не всё так просто.
Не кодер, но всё же с чтением документации проблем обычно не возникает.
Но не смотря на это, обычно выбираю видео, а не текст по многим причинам:
1) Легче воспринимается
2) Привычная единая площадка. Обычно это Ютуб или Khan academy
3) В большинстве видео (да хоть по квадратным уравнениям) есть живые примеры и их решения
4) Легче рассчитать время которое будет потрачено на ознакомление с материалом
Но есть и недостатки, такие как:
1) Высокая фрагментированность контента — найти полный глубокий видеокурс по некой теме сложнее, чаще всего это просто запись лекций. В книге по языку можно найти в одном месте и теорию и практику; различные темы структурированы и разбиты на главы.
2) Может не быть подходящего видео, даже на английском языке. Тогда именно приходится читать, а не смотреть.
Но в целом, мне чаще необходимо разобраться с некой проблемой здесь и сейчас, а нужный видеоролик, в отличие от книги, находится в паре нажатий кнопок, что и определяет тип контента.
Как мне кажется, для глубокого изучения больше подходят либо книги, либо курсы, наподобие тех, что предлагает Cisco, пускай последние и являются книгами с интерактивной практикой.
Также, посмею предположить, что вы учились до эпохи интернета, из-за чего учебная литература вам привычней. Заранее извиняюсь, если не прав.
1) Легче воспринимается
вот это и непонятно.
текст можно читать с любой скоростью. эту скорость можно произвольно менять. непонятные вещи можно перечитывать несколько раз.
видео же идёт с какой-то заданной кем-то другим скоростью. перемотать ровно на пару предложений назад — тот ещё квест.
Также, посмею предположить, что вы учились до эпохи интернета, из-за чего учебная литература вам привычней
дело не только в этом. психологи говорят, что люди делятся в визуалов, аудиалов и т. п.
но программирование подразумевает работу с текстом. много текста. если же для вас работа с текстом некомфортна, то зачем же туда полезли?
психологи говорят, что люди делятся в визуалов, аудиалов и т. п
В таком случае мы, похоже, спорим о вкусе фломастеров
Знаете, я примерно всю жизнь: вернее, ту ее часть, в которой сталкивался, ненавидел обучающие ролики. И внезапно именно в программировании, области от меня достаточно удаленной, ролики начали заходить. Может быть, на просмотре ролика в сознании включаются те же механизмы, которые обрабатывают обычную оффлайновую лекцию?
видео же идёт с какой-то заданной кем-то другим скоростьюСкорость меняется легко, как угодно, разве нет? Можно по хоткеям скорость менять, можно сразу позицию выбирать, никаких проблем.
перемотать ровно на пару предложений назад — тот ещё квестЕсли открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно (кстати, это неплохой вариант, хотя конечно книжка все-равно выигрывает).
психологи говорят, что люди делятся в визуалов, аудиалов и т. пЧитал, что это полнейший бред, нет четкого деления.
если же для вас работа с текстом некомфортна, то зачем же туда полезлиТак он же не программист, он что-то другое по видео изучает, насколько я понял из первого предложения.
Вообще, мне все-равно как кто изучает, если доходит до цели. С книгой наверняка лучше, но может кому-то удобнее видео (бывают же люди со проблемами зрения, дислексики и т.д.). По видео удобно историю вопроса смотреть, интервью и т.д.
Мне видеокурсы не нравятся тем, что они обычно сделаны ужасно. Книгу может написать талантливый человек в одиночку (плюс редактор), а запись видео подразумевает более разнообразные навыки.
Скорость меняется легко, как угодно, разве нет?
да, меняется. но не так легко, как при чтении, и не как угодно, но меняется.
Если открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно
спасибо, не знал, что на ютубе можно посмотреть список субтитров.
это возражение снимается.
Читал, что это полнейший бред, нет четкого деления.
«нет чёткого деления» — да, как и на умных и глупых, например.
«полная ернуда» — нет, конечно.
Так он же не программист, он что-то другое по видео изучает, насколько я понял из первого предложения.
фраза была обращена не только (не столько) к 1tuz
не как угодно, но меняетсяЕсли именно онлайн, то существуют расширения (например github.com/igrigorik/videospeed, скорость от 0.1x до 16x). Оффлайн, как минимум vlc.
да, как и на умных и глупых, например.«полная ернуда» — нет, конечноДеление на визуалов/аудиалов/кинестетиков (вак), это одна из многих теорий обучения, полно других, но почему-то именно идея вак всем запомнилась. Проблема в том, что те, кто предложили эту модель, еще постулировали, что со временем приоритет меняется и выравнивается, а еще то, что сила влияния какого-либо из факторов, который человек сам себе выбрал, часто не совпадает. И да, модель вак критикуют.
Слепые аудио слушают вообще на огромной скорости.
Честно, мне не понятен спор, я написал в начале, что не защищаю видео-формат, но высказанные претензии весьма надуманные. Я частенько смотрю лекции (не по программированию) в незнакомых областях или от топовых лекторов в своей области. Бывают лекторы, которые могут объяснить сложные вещи за минимальное время.
Критиковать с сильной позиции легко, но попробуйте стать «адвокатом дьявола» и непредвзято посмотрите 3 случайных видео из этого канала www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw (есть начала линала, дифф и про нейросети) и напишите мне, что канал совершенно бесполезен для новичка.
Я в целом не против видео как формата, но в программировании (если это не касается программирования графики, анимаций и т.п., где нужно визуализировать какую то динамику) более естественным источником знаний мне видится текст.
З.Ы. Причем тут школа и слабая база я не очень понял. Я например в сельской школе учился, но предпочитаю текст.
«новое поколение» уже местами просто с текстами работать умеет хуже чем с видео/аудио
… но, ведь, исходники программ — это ТЕКСТЫ, а не видео!
ничего, скоро натренируют нйеросети на распознавание видео и можно будет программы в видео писать
А «новое поколение» уже местами просто с текстами работать умеет хуже чем с видео/аудио.
Если это то же "новое поколение", для которого голосовой звонок без предварительного согласования — почти преступление, то что-то не сходится.
дело больше в проработке, потому что смотреть его интересноНу я примерно о том же, что видеоматериал бывает полезен, если хорошо сделан.
Если бы кто-то действительно хотел написать про минусы обучения при помощи видео, то (имхо) начинать нужно было с другого. Как минимум с того, что
1. рандомные видео в youtube обычно это не полноценный курс
2. сделаны неизвестно кем (не знаю правда или нет, но рассказывали, что встречаются люди, которые делают видео, но не способные пройти рабочее собеседование по теме своих роликов)
3. видеокурсы не прошли проверку рецензентами и наверняка содержат ошибки (комментарии не спасают)
4. материалы не прошли проверку временем, нет людей, которые бы сказали, что изучили предмет только по видео
5. как правило нет практических заданий (в книгах обычно есть)
6. копировать примеры неудобно, официальные мануалы удобнее (и как правило лишены ошибок)
7. Не являются стандартом в преподавании предмета, сложно ссылаться на видеокурс.
Имхо, видеолекции от известных универов (например, MIT OpenCourseWare) или интервью смотреть ок (+ можно почитать сначала обсуждение/критику курсов на каком-нибудь ycombinator). Учиться только на видеокурсах, вероятно, не стоит. Повторять известное и смотреть как подан материал вполне нормально.
в сельской школе училсяСельские школы не обязательно слабые. У меня друг тоже из маленькой сельской школы, так у него подготовка намного лучше моей пгт'вской (у меня в классе были люди, которые читать нормально не могли, не то, что в математику думать, впрочем сами не учились). Это уже частности, впрочем.
> перемотать ровно на пару предложений назад — тот ещё квест
Если открыть скрипт субтитров (на youtube или на coursera), то можно сразу ткнуть куда нужно (кстати, это неплохой вариант, хотя конечно книжка все-равно выигрывает).А как это сделать на ютубе? Я вижу как включить субтитры, и как их выбрать или настроить, но где посмотреть весь скрипт и куда там можно "ткнуть" в упор не вижу.

дальше нажать open transcript
справа должен открыться транскрипт (как на скриншоте).
Честно, я особенно не пользуюсь такой функцией, но бывает хочу поиском на странице найти текст, вот тогда транскрипт бывает полезен.
anton0xf возможно, что у вас именно такая ситуация.
Впрочем, эта незадача довольно легко обходится расширениями, например chrome.google.com/webstore/detail/language-learning-with-yo/jkhhdcaafjabenpmpcpgdjiffdpmmcjb
По-идее, такие расширения для изучения языков, но транскрипт они показывают в разы удобнее, чем родной механизм youtube.

Сейчас же я не могу найти видео с субтитрами, но без такой возможности. И даже в тех видео эти кнопки уже есть. Хотя если нажать на «поработать над переводом» на открывшейся странице выводится фигвам — «В видео, которое вы выбрали, нельзя переводить субтитры и метаданные». Но кнопка-то есть. Ну и транскрипт тоже выводится. Раньше-то его можно было увидеть только на странице работы над переводом, а теперь вот прямо рядом с видео.
Сейчас же я не могу найти видео с субтитрами, но без такой возможности. И даже в тех видео эти кнопки уже есть. Хотя если нажать на «поработать над переводом» на открывшейся странице выводится фигвам — «В видео, которое вы выбрали, нельзя переводить субтитры и метаданные». Но кнопка-то есть..
Самое забавное что ютуб эту функциональность к сожалению отключить планирует скоро. Поскольку используется малым числом пользователей. Так что останемся мы без добровольных переводов предложенных средствами ютуба. Разве что переводчики напрямую с автором списываться будут и уже он будет сам субтитры добавлять.
Как хорошо спрятали! Спасибо!
текст можно читать с любой скоростью. эту скорость можно произвольно менять. непонятные вещи можно перечитывать несколько раз.
видео же идёт с какой-то заданной кем-то другим скоростью.
И темп восприятия и стиль. Мне, например, всегда было легче сначала увидеть всю картину целиком, а затем начать заполнять фрагменты подробностями.
Видео такое не позволяет. Там долго и нудно рассказываются какие-то частности они продолжают разжевываться (видимо, ориентируясь на совсем непроходимых) даже когда уже все понятно.
Кстати, про оффлайновые лекции. Не знаю как сейчас, а когда (и там где) я учился, лекции практически никогда на не строились на одном учебнике. И сдать курс только по конспектам можно было на слабенькую троечку в лучшем случае. Всегда давался список литературы и подразумевалось, что конспект лекции это всего лишь план для работы с этой литературой.
К тому же иногда скорость передачи информации определённого канала подходит изначально.
В качестве основного источника информации такие видео врядли подходят, но вот для расширения кругозора — почему бы нет? (Примерно как чтение хабра)
В целом мне кажется, тут есть ещё и более глобальная проблема. Да, можно сводить дискуссию к теме «кому что удобнее», но по факту по целому ряду причин среднестатистическое видео содержит информацию менее высокого качества, нежели текст. Если речь не идёт о чём-то совсем уж научно-популярном, конечно.
но по факту по целому ряду причин среднестатистическое видео содержит информацию менее высокого качества, нежели текстОднако Coursera и прочие ведь нормально заходит, и не только из-за проверки заданий. Приходится смотреть видео потому, что там легче найти понятную поверхностную информацию (когда этого достаточно).
Хотя легкодоступный текст лучше такого же видео. Просто почему-то их реже делают. Если писать, так глубоко и обо всём, и в итоге нужно потратить время. А обучающие видео всегда делают с упором на доступность (и иногда даже получается), и время нормировано. Но квадратных уравнений и прочего базового материала это не касается, слишком долго смотреть видео про единственный кирпичик знаний, к тому же если не смотреть цельный курс, то эффективность подачи сильно падает.
1) Легче воспринимается
Меня видео (да и вообще лекции) нереально утомляют, потому что скорость подачи материала не соответствует скорости его усвоения. Если материал подаётся слишком медленно, то становится скучно, мозг начинает отвлекаться, теряется концентрация, материал не усваивается. Если же подаётся слишком быстро, то просто перестаёшь материал понимать, потому что непонимание нарастает как снежный ком.
2) Привычная единая площадка. Обычно это Ютуб или Khan academy
А какая разница, какая площадка?
3) В большинстве видео (да хоть по квадратным уравнениям) есть живые примеры и их решения
Ага. А если дело касается кода, то что, просто перенабирать куски программ с экрана, вместо того, чтобы просто сделать копи-паст текста?
4) Легче рассчитать время которое будет потрачено на ознакомление с материалом
Одного видео мало. Полноценное изучение материала невозможно без самостоятельной работы (практики), а сколько времени уйдёт на это, оценить уже невозможно.
чаще всего это просто запись лекций.
Потому что так тупо проще. Вместо того, чтобы потратить кучу времени на создание качественных материалов, просто пишем видео. Пипл схавает.
Заметьте, в технических вузах вам лектор ведет лекцию, а не выдают книгу со словами — учите. Лично мне, тяжело дается чтение. По моим ощущениям лекция/видеоурок раз 5 эффективнее чем чтение документации. Естественно, без документации никак и гугл наше все. Когда тебе нужно не всю тему понять, а лишь ньюансы — документация лучшее средство, но когда нужно с нуля что-то освоить, то эффективность преподавателя заметно выше.
Поэтому приводить в пример техническую лекцию или Курсеру можно, но это всё товары значительно более трудозатратные, чем статья в блоге, даже очень хорошая. Поэтому хорошего видео и меньше, чем текста.
Заметьте, в технических вузах вам лектор ведет лекцию, а не выдают книгу со словами — учите.
Это уже давно не так или не везде. Наблюдаю за обучением своих детей. Какая-то "методичка" (пусть даже примитивная) обязательна, и опираются на неё даже больше, чем на живые лекции.
Живые лекции, с одной стороны, пережиток отсутствия лёгкого копирования данных (окончательно закончилось около 2000-го), с другой стороны, метод общения с аудиторией — но польза будет только тогда, когда это реальное общение ("мы не поняли, объясните детальнее", "а зачем такой сложный путь?" и т.п.)
И то сейчас это лучше делать, если сначала попытаются сами прочитать и понять (и решить стартовые задачи) и только потом спрашивать (на семинарах).
Ещё мне вспоминается мой университетский преподаватель по физике. Когда я у него спросил. как мне понять физику, он посоветовал расписывать переходы между формулами самостоятельно, да, те самые «отсюда очевидно следует». Сначала между формулами вы будете переходить за пару часов, а потом действительно станет очевидно. Если очевидно сразу, то вы или гений (что статистически маловероятно), или делаете что-то сильно не так. Физику я так толком и не понял, кроме используемой в работе, но метод рабочий.
Знания самой математики вам не много дадут в плане изучения программирования как профессии. Но умение решать уравнения, строить доказательства и логические размышления тренирует те же навыки, которые программист использует при поиске багов, проектировании алгоритмов (даже тривиальных), изучении кода, документации и книг. Все остальное в программировании это мириада фактов (типа устройство CPU, POSIX API и т.д.) которые служат основой для построения логических цепочек с помощью вышеозначенного навыка.
Так как мы говорим о навыке, то потребуется немалое время для его выработки (сколько времени нужно чтобы получить разряд по боксу?). Новые нейронные связи не быстро формируются. Хорошая новость заключается в том, что навык можно набивать практикой и одновременно читать и разбираться в языках, платформах, сетях, БД, железе и т.д. Не знаю сколько времени уйдёт до достижения «нанимаемого» уровня, но я бы готовился к 6-18 месяцам довольно интенсивной работы по несколько часов в день.
Странно что сразу программистом и переезд. Может сначала хотя бы устроиться "джуном" на полгодика тут? Это помогло бы "быстро въехать".
IT конечно та ещё кроличья нора.
Я долго вникал почему 0 в степени 0 равен 1, и у меня ощущение что я до конца так и не понял всей сути.
это хорошо, что не поняли.
Выражение 0⁰ (ноль в нулевой степени) многие учебники считают неопределённым и лишённым смысла
впрочем, не обижайтесь, но бессмысленно рассуждать о 0⁰ человеку, который не знает/понимает производных.
по остальному… боюсь вас обидеть, но как-то слишком сложно у вас всё заходит. того же k&r я читал подростком и я был поражён изящностью и … какое слово подобрать? очевидностью? … выбранных решений. это одна из немногих вещей, которые не нужно учить, а нужно понять и оно навсегда останется в памяти.
выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор.
если спустя несколько лет в IT вы говорите такое, программирование — не ваше.
btw, а как же вы админили? я не представляю админства без скриптов, и выражения вроде N=$((N+1)) вполне обыденны.
ИМХО чтобы стать хорошим специалистом в любой области нужно гореть, интересоваться этой темой. сколько вам лет? судя по ребёнку, к которому ходит репетитор, не так уж и мало. если вы к этому возрасту не проявили склонности к программированию, то почему сейчас что-то должно измениться?
BTW, а почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше. адвокаты, думаю, много больше.
что-то подумал я… скорее всего, история придумана.
не верится, что вот такой вот человек, любящий видеотуториалы, написал вдруг написал статью для хабра. откуда он узнал про хабр? тут нет видеороликов. как решил сам писать статьи?
А еще адекватный взрослый человек должен прекрасно понимать, что никому "там" он не нужен без профильного образования, опыта работы, рекомендаций, портфолио (не обязательно все пункты сразу). Ну и ещё момент: очень сложно вот так вот взять и кардинально поменять свою жизнь, когда в ней столько якорей. Это я если что про ребенка, который уже с репетитором занимается. Так что согласен с вами, статья с большой долей вероятности ничего общего с действительностью не имеет.
Ломанулись толпы которые программировать не любят и не хотят, но хотят денег.
Смотришь количество курсов «Стань фронтэндером за 30 дней и зарабатывай 100к+» и офигеваешь.
Статья на Хабре это неплохая строчка в резюме.
Статья на Хабре это неплохая строчка в резюме.
У Вас какое-то предвзятое мнение. Лично мне строчка в резюме о «статье на хабре» ни о чем не говорит. Тем более все-таки не научная же статья была написана. Возможно она имела бы значение для публицистов, журналистов и т.д.
Ломанулись толпы которые программировать не любят и не хотят, но хотят денег.Многие работают только ради денег, и вполне рационально поступают. Я тоже так делаю. А развлечения по интересам — по вечерам.
и не получать от работы никакого удовольствияХотя зря вы так фривольно с квантификаторами всеобщности. В любом упорядоченном труде находишь хоть какое-удовольствие, в том числе и интеллектуальное. Вопрос в том, что днём рутинно
очень сложно вот так вот взять и кардинально поменять свою жизнь, когда в ней столько якорей. Это я если что про ребенка...
В моем случае наоборот. Ребенок является мощной мотивацией к действиям. Думаю это все индивидуально у всех.
откуда он узнал про хабр? тут нет видеороликов. как решил сам писать статьи?
А что именно смутило то?
Про хабр знают многие, более-менее связанные с IT. Это же не закрытый клуб единомышленников :)
Решение о написании статьи было принято исходя из соображении, что на данном ресурсе и сконцентрированы в основном — developer-ы, которые могут дать дельные рекомендации и советы по исправлению багов в моем плане и подходе к изучению програмирования.
почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше. адвокаты, думаю, много больше
Самое начало же топика, предыстория вопроса дана текстом. Нейрохирурги и дантисты требуют 1. мед.диплома, 2. хорошей практики 3. невероятно прямых рук 4. высокой стрессоустойчивости 5. высокий уровень ответственности 6. конкуренция не обязательно ниже 7. хирургия требует некоторой доли таланта и т.д.
Пошли бы вы к специалисту, который переучился в нейрохирурги из админов после 25 лет?
PS. Я имел в виду возраст (25), а не стаж. Если у хирурга 25 лет стажа, то ему очень очень много лет:

Нейрохирурги и дантисты требуют 1. мед.диплома, 2. хорошей практики 3. невероятно прямых рук 4. высокой стрессоустойчивости 5. высокий уровень ответственности 6. конкуренция не обязательно ниже 7. хирургия требует некоторой доли таланта и т.д.
1. без диплома по специальности получить программисту рабочую визу в США реально?
2. как и программирование;
7. как и программирование.
Пошли бы вы к специалисту, который переучился в нейрохирурги из админов после 25 лет?
почему бы и нет? разумеется, не к самоучке, который сам решил, что он готов работать нейрохирургом, а к человеку, имеющему право заниматься медицинской практикой.
более того, я почти уверен, что такой нейрохирург, если найдётся, будет лучше среднестатистического (ибо он не случайно попал в медиститут подростком и чудом не был отчислен, а сознательно в зрелом возрасте понял, что хочет стать врачом и положил на это кучу сил и времени).
впрочем, речь-то была совсем не про это. почему-то то, что стать нейрохирургом сложно, понимают все.
но вот вот автор статьи (если это не фейк, в чём я сомневаюсь) решил стать программистом без каких-либо предпосылок к этому за пару месяцев просмотра видеороликов на досуге. притом не просто джуном, а получить приглашение на релокацию в США.
программисту рабочую визу в США реально
Не было речи о визе в США (у меня). Медикам также очень сложно устроится в других странах, даже с дипломом, странно, что вы не знали об этом (нужно доучиваться и подтверждать, а в случае штатов, это очень тяжело и конкуренция огромна). Более того, юристам тоже не поможет их рф диплом в штатах.
2,7. Далеко не всякое программирование. Нейрохирург, это между прочим, тот кто в теории может открыть голову и попытаться исправить баг в программе, которую написала эволюция и случай. Мне обычно вспоминается анекдот, про кардиохирурга и механика, но с нейрохирургом по-моему все еще более иронично.
сознательно в зрелом возрасте понял, что хочет стать врачом и положил на это кучу сил и времени).Эээ, мне бы ваш оптимизм. Мне попадались только люди переходящие из медицины в другие области, но не в нее. Возможно я преувеличиваю сложности перехода в нейрохирургию и мед., но что-то не вижу рвущихся в нее взрослых людей.
PS. Коммент, изменился, поэтому добавлю:
почему-то то, что стать нейрохирургом сложно, понимают все но вот вот автор статьи (если это не фейк, в чём я сомневаюсь) решил стать программистомНу это же желание стать, не факт что получится. Может и фейк, раз «НЕ» в заголовке. Зарплаты, наверное, привлекают и примеры (которыми наводнена сеть). Это ведь практически единственный шанс для обычного человека получить неплохую зарплату умом и упорством.
С медиками есть еще другие сложности (долго и дорого учиться по сравнению с другими специальностями; низкий уровень обучения в медвузах; медицина сильно бюрократизирована; непотизм и взятки). Адвокатов просто много.
Впрочем я понял ваш посыл. Со временем, скорее всего, интерес «вайти» пропадет.
btw, а как же вы админили? я не представляю админства без скриптов, и выражения вроде N=$((N+1)) вполне обыденны.
Как-то так и админили, без скриптов. В основнов обходились стандартными средствами Windows, ну или сторонними приложениями. Максимум что делали, простенькие bat-файлы писали, для бекапов например.
Видимо задач таких не было, чтобы использовать скрипты по полной…
если вы к этому возрасту не проявили склонности к программированию, то почему сейчас что-то должно измениться?
Наверное, потому что появилась цель и желание научиться программированию.
BTW, а почему вы решили стать программистом? из-за зарплаты? так нейрохирурги или дантисты получают не меньше.
Как бы зарплата тоже имеет определенный вес. Однако больше исхожу из понимания что в IT сфере у меня есть определенный background, ну а developer-ом, т.к. входной порог на зарубежный рынок будет намного проще, нежели например sales-ом.
Я как-то себе не представляю возможным переезжать и обучиться ради этого, например на нефтяника или врача.
Есть множество причин считать 0⁰ = 1.
сорри, хотел вот это написать:
https://www.wolframalpha.com/input/?i=lim+0%5Ex+as+x-%3E0%2B
это достаточная причина не считать 0⁰ = 1
В обычной же жизни необходимо решить, что именно ты хочешь получить. Это будет не абстрактное изучение программирования ради программирования, а более чёткая цель, например, интернет-магазин, который будет продавать садовый инвентарь; приложение на Android для синхронизации заметок; пошаговая стратегия в любимой вселенной, чтобы скоротать время между поездками в метро. Когда будет чёткая цель, тогда появятся границы, определяющие на что стоит тратить время, а на что нет.
Многие вещи проще заказать у других людей, чем пытаться сделать самому. Чтобы сделать бутерброд с ветчиной, мне надо лишь купить ингредиенты в магазине, т.е. мне не надо тратить время, чтобы покупать зерно, выращивать его, обрабатывать, покупать печь, сделать там хлеб, вырастить свинью, добыть и обработать её мясо и т.д. Я просто покупаю ингредиенты в магазине и получаю нужный результат. Если я захочу углубиться, я начну экспериментировать с хлебом, толщиной нарезки, добавлять\убирать сыр, менять овощи, а не уходить в селекцию семян зерна, выбор плодородной почты и качественных удобрений.
Если я захочу углубиться, я начну экспериментировать с хлебом, толщиной нарезки, добавлять\убирать сыр, менять овощи, а не уходить в селекцию семян зерна, выбор плодородной почты и качественных удобрений.
хороший шеф-повар будет интересоваться и сортом («селекция семян»), и регионом происхождения («выбор плодородной почвы»), и т. п.
Повар-технолог обычной столовой всё-таки таким не заморачивается. И эта квалификация эквивалент отнюдь не джуна. Джунами и мидлами можно считать поваров 2-4 разрядов, которые не разрабатывают рецептуру.
Повар-технолог обычной столовой всё-таки таким не заморачивается
в ПТУ поваров не учат, что есть картофель разных сортов, один больше пригоден для одних блюд, другой для других? не верю. и что пшеница бывает разных сортов, уверен, тоже учат. и чем разные сорта муки/манки друг от друга отличаются.
да что там профессиональный повар, почти любая хорошая домохозяйка вам про это расскажет (пусть, быть может и в бытовых терминах).
и любой человек, неравнодушный к вину, расскажет вам, что вкус вина зависит не только от сорта винограда и способа приготовления вина, но и от местности произрастания винограда (читай почвы и климата), года (читай погоды) и т. п.
да что там говорить, на рынке астраханские помидоры стоят дороже волгоградских, и все понимают, что это из-за того, что астраханские слаще — в астрахани банально солнца больше (может быть есть и другие причины, кстати).
У "Thinking in Java" ("Философия Java") было аж целых три издания, так вот первое — как раз вполне для новичков. В следующих напихали больше конкретных технологий. Не знаю, правда, есть ли у 1-го официальный русский перевод.
P.S. А, нет — даже уже четыре.
Удачи, не сдавайтесь, немного терпения и упорства (много) и у Вас все получится!
Аааарррр Java и Js разные языки
Может быть программирование просто не ваше? Может быть не стоит себя мучатт, если не идёт?
Второе — чтобы научиться программировать надо… программировать. Внезапно, правда? Надо постоянно решать задачи и реализовывать их в коде. От элементарного, до сложного. Тут важно понимать — пытаться разобраться в механизмах и принципах работы той или иной технологии до той степени, до которой это требует решаемая задача.
Третье, касательно теории и прочного фундамента — тут нужна хорошо составленная программа, освоив которую вы научитесь решать типовые задачи и у вас будет достаточное представление касательно смежных областей знаний и их взаимосвязи с программированием, чтобы уже самостоятельно заниматься углубленным изучением интересующих вас областей в интересующем вас направлении.
Четвертое — первый и второй пункт важнее третьего.
Решение то получил, однако понять, как преподаватель решила не смог:Например так:
Wolfram
Алгоритм, построенный мной для изучения программирования, дал сбой практически в самом начале.Возможно потому, что стоило ставить конкретные цели? Хотя бы лабораторные работы из университета по джаве. Они очень простые.
Я не то что не помню, как решаются такие задачи, — я элементарно, как выяснилось, попросту не знаю Алгебру за 10-11 класс!Ммм нет, эта задача 7 класса.
Или все-таки это не моё? И профессия «разработчик» — это для элиты, «касты особенных людей»?Да, для тех, кто в школе учился. Школьных знаний математики достаточно в программировании веба.
Так вот, проанализировав прошедший месяц-полтора самостоятельного обучения, для меня стало очевидно, что я как «хомяк в колесе», вроде как бы и бегу (учусь), а по факту стою на месте.Нет конкретных целей, вот невидно прогресса, даже если он есть.
Ммм нет, эта задача 7 класса.
хм, и как её решить ограничиваясь знаниями семиклассника? или под решением вы имели в виду использование вольфрама?
подумал, решил, ограничиваясь курсом 7 класса. но, всё-таки в этом случае задача становится олимпиадной, а с использованием производной — типовой, так что я бы не говорил, что это задача 7 класса.
Покажите пожалуйста задачник для 7го класса где ищут экстремумы, правда интересно. Ах да, спец школы в расчет, конечно же, не берём.
mathematics-tests.com/algebra-7-klass-novoe/kontrolnye-raboty-novye/mordkovich-novoe
Максимум линейной функции.
Максимум параболы в 7 классе был. Так что вполне решаемо.
Ммм нет, эта задача 7 класса.
Программиста сразу видно по тому, что он считает с нуля :)
(тоже думал, что седьмой, но оказался всё же восьмой https://www.yaklass.ru/p/algebra/8-klass/kvadratichnaia-funktciia-funktciia-y-k-x-11012/funktciia-y-ax-bx-c-ee-svoistva-i-grafik-9108/re-92d9d602-f9c6-43f6-8f78-6f80b2c8227a)
По предыдущей ссылке для 8 класса для максимума даётся вывод из производной квадратичной функции как факт, без упоминания его получения. Я думаю, что это довольно мусорное оторванное от всего знание. Хотя я не помню, может эту формулу можно иначе получить, но ad hoc для взрослого возраста из школы всё же нужно что-то более тупое, как производные (достаточно просто знать, что это такое).
ой ли. многие математики активно используют подобный софт.
Поверьте, сталкивался не раз с ситуацией:
— Нужно решить вот эту задачу
— Она не решаемая
— Почему?
— В этом фреймворке нет компонента для ее решения
Все. Полный аут.
Да где угодно. Вот вы строите загон для животных (Робинзон что-то подобное делал) — какой толщины должны быть ветки? Какая должна быть высота забора? Как прочно надо приматывать? Итд итп…
(Да, это физика, но выливается снова в математику)
Если вы в селе, то есть десятки более опытных соседей, которые в случае чего подскажут просто из своего опыта готовые практические результаты. А когда один-два — экспериментировать слишком дорого, надо подсчитать с запасом...
(Да, это физика, но выливается снова в математику)
приведенный пример, миллионы лет воспроизводился миллионами людей, которые даже читать не умели, а уж считать и буковки — это все привелегия господ
Оно то понятно что там в основе математика лежит, только это все делается имперически, а не расчетами
Почему сразу аут? Человек знает возможности инструмента и адекватно оценивает свои силы.
Нужно дополнительные вопросы задавать:
- В каком фреймворке есть такой компонент?
- Сколько будет стоить допиливание фреймворка для решения этой задачи?
В общем то тащить несколько фреймворков в один проект тоже плохая идея, поэтому неплохо задать вопрос:
- Как можно изменить задачу, чтобы она ложилась на фреймворк?
Что значит «адекватно оценивает свои силы»? Если ты не можешь написать нужный алгоритм сам, а можешь только использовать готовые реализации, тебе нужно поискать другое место работы. Там, где от тебя не будут требовать «невозможного».
Ну вот из старого пример. Была разработка некоего многопоточного приложения и в нем был нужен индикатор относительной загрузки потоков плюс флаг что поток подвис и его надо перезапустить. Писалось все это на CBuilder. Разработчик утверждал что это невозможно потому что таких средств нет в VCL. Пришлось ткнуть человека носом в MSDN, где есть функции, возвращающие количество тактов процессора, использованные кодом потока внутри процесса и кодом всего процесс в целом. Т.е. надо было просто выйти за рамки VCL и написать небольшой кусок кода на WinAPI.
Из текущего. Взяли нового разработчика. Говорит, что писал на питоне, есть опыт разработки, вроде как все круто. Прошел год и видно, что ничего не умеет, кроме как дергать готовые функции из библиотек.
Питона у нас нет. Есть RPG? C/C++, CL (еще есть COBOL, но не пользуемся). Есть своя кодовая база, но многие вещи нужно просто реализовывать самому. С человеком сплошные проблемы — «а это как сделать, а тут что писать?» Ну почитай документацию, погугли, включи, наконец, мозг. Ничего сверхестетсвенного не требуется. Задачки тривиальные на уровне исключить дубли, отсортировать в нужном порядке и т.п…
есть задание на разработку от бизнеса, мы его реализуем.
У вас бизнес никогда не просил дичь, которую в постановке бизнеса просто нецелесообразно делать?
Да, вы правы. Когда человек совсем не подходит под ваши требования — ему лучше выбрать другое место работы.
Вот только вы подаете это так, что если человек не может вписаться в произвольный стек технологий, то он профнепригоден.
Тут с вашей стороны косяк. Зачем вы брали нового разработчика, который "писал на питоне", и давали задачи по всяким другим языкам?
Найти готового разработчика под платформу AS/400 (IBM i) в РФ малореально — их очень мало. Поэтому берется человек и обучается. И это декларируется «на берегу», еще на собеседовании все честно рассказывают. Если согласился — значит принял правила игры. И подразумевается что разработчик не просто лепит задачу из кирпичиков, но еще и делает что-то сам. В том числе и думает о том, какое решение выбрать для получения максимальной эффективности (это вообще краеугольный камень нашей разработки). И действует самостоятельно, а не бежит чуть что к соседу с вопросами «а это как сделать?» (это допустимо на начальном этапе обучения, но не спустя год работы).
Со временем, если человек растет в квалификации, он получает возможность выбирать подходы, не соответсвующие ТЗ, если считает что его подход будет эффективнее. И там уже аналитик при написании ТЗ советуется — а как будет реализовано вот это или вот это (потому что ТЗ у нас это еще и документация по задаче — если эта задача потом кому-то другому попадет на доработку, он должен быстро разобраться как это работает и куда вставить новый кусок кода — для этого то, что написано в ТЗ должно соответствовать тому, что написано в коде).
Вот у меня сейчас большая задача в работе (примерно под мегабайт только написанного кода, без описаний таблиц, индексов и всяких настроечных скриптов). 33 таблицы, 54 индекса. Суть в том, что извне (через MQ) приходит некоторая информация в XML (достаточно наворочнные — минимум три варианта форматов, внутри списки, вложенные структуры и т.п.). Все это нужно разобрать, разложить по таблицам (с учетом того, что там уже есть). С сохранением целостности — если по дороге что-то пошло не так, то полный откат к начальному состоянию. Ну и потом еще куча всяких проверок и поисков по различным параметрам. И дополнительно все это надо увязать с другими, уже существующими компонентами системы.
ТЗ пишется параллельно разработке — сначала черновик с постановкой цели для каждой функции, потом ее эффективная реализация, потом описание конкретного алгоритма. Ну и тестирование, естественно. В том числе и нагрузочное. Тут приходится много думать, в том числе и «вот есть кажущееся правильным решение, а можно ли повысить эффективность, где ее можно повысить, где можно использовать кеширование данных чтобы не перечитывать одну таблицу несколько раз, а сразу втянуть в память все что нужно, а потом работать из памяти».
И у нас подразумевается, что любой разработчик должен выходить на уровень решения таких задач, а не быть просто кодировщиком. Т.е. вечные джуны тут не нужны — они должны расти до мидлов и сеньоров. Или искать место работы где попроще, где можно годами на одном фреймворке лепить однотипные поделки из типовых кирпичиков.
Нет, экстремум квадратичной функции выводится аналитически через выделение полного квадрата, безо всяких производных. У меня в школе это точно было, и пресловутое "минус бэ на два а" запомнилось как отче наш. Погуглил учебники, это вроде даже 9 класс, хотя техника та же, что в 8 классе для вывода формулы корней уравнения.
Мне кажется, программисту нужна начальная математика в основном. Если это в норме, то можно начать изучать программирование. Главное подобрать хорошие курсы(советую посмотреть на Udemy) или книги(для начала в джава советую Герберта шилдта «Java 8 руководство для начинающих»; или если не жалко переплатить 2-3к сначала прочитать «hed first java», потом того же шилдта, но не для начинающих, а полное руководство), дальше уже начнёте понимать в этом и разберётесь что читать дальше. Котлин тоже очень крутой язык, советую разобраться в java (пофрилансить неплохо было бы) и если с джавой всё ок, то хотя бы учить Котлин. Дальше уже пробовать искать работу(если зашёл Котлин, то выучить его, тоже пофрилансить, дальше можно попробовать переехать.
Конечно не забывайте читать книги!
P.S. во время обучения решайте задачки на Codewars
Вы смотрите на программирование как на что-то самодостаточное, вещь в себе. Но это всё равно что смотреть на иностранный язык с точки зрения лингвиста или на овцу с точки зрения зоолога: необходимый объём знаний огромен, дальнейшее обучение довольно быстрое, смежные области примерно понятны.
Однако надо ли так глубоко копать? Всё зависит о целей. Вот вы, когда английский язык учили, разбирались в его происхождении, родственных связях, классификации? Вряд ли. Но говорить-то на нём можете. Так же и мясник, например, вообще не слышал ни о каком цитогенезе, но баранью вырезку сделает на загляденье.
То же самое и с программами. Любая программа — это инструмент для решения задачи. Как английский язык — инструмент для решения задачи «прочитать Китса в оригинале», а овечья анатомия — задачи «получить вырезку».
Поэтому стоит начинать именно с задачи, и это совсем необязательно математическая задача. В учебниках приводят задачи из математики (как ваша с пастбищем) в основном потому, что те, кто изучает программирование, как правило, хорошо знают математику, и решить то же квадратное уравнение могут чуть ли не в уме. Благодаря этому они могут сосредоточиться не на задаче (она для них очень простая), а на инструменте. Потом, в реальной жизни, разработчик, наоборот, хорошо знает инструмент, и может сосредоточиться на задаче. Вам же приходится тратить силы и на задачу, и на инструмент.
Какая у вас основная специальность, или направление? Посмотрите, что автоматизируют там, и попробуйте решить похожие задачи. Тогда вы не будете терять время и силы на задачу, а сможете изучать инструмент.
Вы же говорите о качестве решения. Это бесспорно, того же Китса можно читать по-разному. Что-то вроде такого:
«Так, что-то про деревья...»
«Листок упал на мой разум»
«Листья падают на душу»
«Как лист увядший падает на душу»
«Как лист увядший… М-м, любопытная аллюзия на Тидемана! Жаль, Китс не знал его в переводе Нильсена – он гораздо ближе к оригиналу, чем канвальдовский»
Параллели с миром программистов, думаю, вы сможете провести лучше меня)
Как человек, всю свою профессиональную карьеру стоящий на грани "зарыться навсегда в одну узкую область" могу сказать, что в этом неудачном пути обучения отсутствовал навык breath vs depth. И навык делегирования ответов.
Объясняю: в любой области всегда можно копать дальше. Например, начинаем мы копать в Computer Science. CS нас быстро подводит к пониманию вычислимости, которое напрямую связано с перечисляемостью и разрешимостью множеств, что в свою очередь нас утыкает лицом в математическую логику и теорию множеств, которая совершенно не стесняется перепрыгивать из счётных множеств в несчётные, что опасно близко нас подводит к множеству R и открывающейся при этом несчётной бездне. Где-то тут рядом с лёгкостью всплывает функциональный анализ, теория групп и понеслось…
Это мы всё ещё не прочитали первую главу CS, которая к программированию не относится.
Вместо этого надо уметь принимать часть решений на веру. Запоминать, что там "есть что-то такое" и вовремя останавливаться. Приспичит — можно нырнуть. Не приспичит — держать голову над водой.
Программирование — это не наука, это смесь ремесла и искуства. Кусок программирования уводит нас в район теории алгоритмов, кусок — в другие интереснейшие области теории. Но, основная часть — это навык, а не знания. Навык отличается от знания в том, что знание всегда либо ищет ответ, либо опирается на другие знания; а навык опирается на опыт.
Таким образом надо уметь в нужный момент прекращать искать знания и начинать рабатывать опыт. Одно другое не исключает (знания сильно помогают), но без опыта никакого результата не будет, даже если вы выучите все курсы MIT'а наизусть.
Программирование — как рисование. 10000 часов теории сильно помогут вам научиться рисовать. 10000 часов рисования научат вас рисовать.
Что надо делать: программировать. Берёте и пишите программу. Копипаста, "оно работает но я не знаю почему" и т.д. Опыт — важнее, чем 100% понимание происходящего.
Копипаста, "оно работает но я не знаю почему" и т.д. Опыт — важнее, чем 100% понимание происходящего.
гхм, это однозначно вредный совет.
я понимаю, что это продолжение вот этого правильного совета:
Вместо этого надо уметь принимать часть решений на веру. Запоминать, что там "есть что-то такое" и вовремя останавливаться. Приспичит — можно нырнуть. Не приспичит — держать голову над водой.
но бездумная копипаста ни к чему хорошему не приводит (и не учит программировать тоже).
"Бездумную копипасту" придумали вы. Я говорил про копипасту. Она — основна для начала изучения любой области. Берёшь готовое и пробуешь использовать. Работающее можно ломать и смотреть как оно не работает (или работает). А если работающего нет, что ломать не понятно.
"оно работает но я не знаю почему"
это можно понять как руководство к действию: «работает — и ладно, нечего разбираться»
Вы не можете копипастить код не разбираясь — он не будет работать. Переменные не те, отступы не те и т.д. Как только начинаете "сшивать" код, начинаете разбираться. Хотя бы поверхностно — но для общей интуиции очень полезно.
вы недооцениваете упорство и нежелание думать некоторых людей.
«что тут думать, прыгать надо»
про это даже на stackoverflow написано «this practice should be avoided»
Математика и программирование — отличающиеся вещи. Очень большая ошибка полагать, что программирование будет похоже на математику. Это верный способ так и не понять элементарных вещей.
Дело в том, что математика оперирует довольно сложными и довольно туманными абстракциями (число, функция, производная, уравнение, предел и так далее). Есть множество вариантов базовых аксиом и все это на самом деле очень сложно.
Задача изучения математики — освоить эти абстракции и научиться применять их для решения задач.
Программирование — это другая задача. Программист по сути имеет дело с неким устройством, которое нужно заставить сделать то что нужно. Здесь нет ничего абстрактного как в математике. Все абстракции вводятся поверх вполне материальных существующих битов и вводятся только чтобы упростить понимание того что происходит с этими битами. Устройство это состоит из памяти и процессора, перекладывающего числа из одних ячеек в другие согласно программе. Все что нужно программисту — научиться писать программы, перекладывающие числа именно требуемым образом. Здесь нет тех абстракций из тонкого воздуха, как в математике, все очень конкретно и очень определенно.
Другими словами: в математике мы имеем дело с абстрактными объектами, про которые не говорится как их изготовить, в программировании — речь всегда идет о вещах, которые имеют материальное воплощение в битах памяти.
На днях смеялся, как мой ребенок осваивает программирование. Он научился на питоне писать операторы while (true), break, if с одним условием и присваивания. Теперь он пишет любые программы и решает олимпиадные задачи по информатике для детей. Его код чудовищен, но все чудесным образом работает. Т.е. он осознал как работает эта «машина»: она умеет перекладывать числа из одной переменной в другую, ходить по кругу, выходить из круга и учитывать условия. Этого достаточно, воображение ребенка отыскивает последовательность операторов для решения нужной задачи и можно считать что он уже программист.
то выражение типа N=N+1 и более сложные уравнения меня загоняли в легкий ступор.Потому что это никакая не математика. Это инструкция для процессора достать число из ячейки с именем N, прибавить к нему 1 и снова положить в ячейку N. Это инструкция для машины а не уравнение. То что это выглядит как уравнение — плохая аналогия, сбивающая с толку. На самом деле здесь записано что-то типа «PutTo N value (N+1)».
Плохая новость заключается в том, что если человек этого всего не понял сам и у него школьная математика вызывает трудности, то высока вероятность, что его склад ума очень плохо подходит для программирования. Таким людям обычно стоит изучать программирование в качестве дополнения к негой основной профессии для того, чтобы быть аналитиком, дизайнером или что-то подобное.
То что это выглядит как уравнение — плохая аналогия, сбивающая с толку.
Вот да, знаю многих людей, которые не могли осознать суть присваивания из-за этой путаницы.
В этом плане Паскаль с его := (часто читают как «пусть будет равно», аналогично конструкции QBasic «LET A = B+C») имеет некоторое преимущество перед языками, где для присваивания используется просто знак равенства (каковых, увы, большинство).
А уж синтаксис присваивания в языке «Рапира» вообще прозрачен: a + b -> x сначала вычисляем выражение операции, и только после этого результат помещаем в указанную переменную.
Чем глубже я ухожу в хорошо написанный код, тем больше там оказывается этих "туманных абстракций". В системе конфигурации реализовывать ковариантное или контрвариантное наследование свойств? Является ли exception методом сохранения инварианта функции?
Забавно, что большая часть теоретических результатов CS, применяемых для "конструктивного программирования" (другого у нас нет) доказывается неконструктивными методами (собственно, одним-единственным — диагональным методом Кантора).
Он же явно строит двумерной бесконечной матрице «не-диагональ».
Вот только не надо считать конструктивными методы, которые говорят "возьмите бесконечное множество элементов бесконечной длины, разложите их квадратной матрицей, для каждой из бесконечного числа позиций, выполните вот это простое действие...".
В системе типов результатом такого вычисления будет bottom type.
fn diagonal_build () ->! {
loop {
loop {
...
}
}
}И без единого break'а, замечу. Чистой воды divergence type.
Во всех учебниках по теории алгоритмов такой тип зацикливания принимается за ответ "нет" вне зависимости от того, насколько вкусные результаты нас ждут после достижения бесконечности.
Только диоганальный метод — он вполне себе конечный.
Он по индексу i возвращает значение ячейки (i,i) (возможно как-то модифицированное).
Даже если мы примем, что это перечисляющий метод, то разрешающим он не является.
Потому что в финале у нас assert diagonal(S) not in S, что требует досчитать до бесконечности дважды.
Но сам diagonal(S) — вполне конструктивен (настолько же, насколько S конструктивно. Например, если в S вычислимы все клетки, то и diagonal(S) вычислим ровно в том же смысле).
И даже diagonal(S) != S_i тоже вычислимо проверяется. После этого возникает проблема с переходом к бесконечности — достаточно ли, эффективно по i доказывать X != S_i, или нужно больше, чтобы сказать X \not in S. Насколько я помню классическую конструктививную логику — этого достаточно, но я не полностью уверен.
Это как раз и есть разница между перечислимыми и разрешимыми множествами. Есть множества, которые мы можем перечислить (перечислять), но для которых мы не можем в конечное время дать ответ, относится ли данный элемент к указанному множеству или нет. Приличная доля всех теорем в теории алгоритмов с ответом "нет, не можем" как раз сводится к ситуации, когда перечисление есть, а разрешения нет.
(https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D1%87%D0%B8%D1%81%D0%BB%D0%B8%D0%BC%D0%BE%D0%B5_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE)
Теория алгоритмов говорит, что попытка разрешения для неразрешимого множества невозможна (алгоритм никогда не закончится). Собственно, в районе assert diagonal(S) in S мы это видим интуитивно, если S — бесконечный генератор.
Если S разрешимо, то и diag(S) разрешимо.
Если S перечислимо, то и diag(S) станет перечислимым.
Это даже распространяется дальше, например, на перечислимость снизу или сверху (которая нужна для полумер и колмогоровской сложности соответственно).
Конечно, задача разрешить diag от перечислимого множества — не разрешима (и для конкретного перечислимого множества может являться просто проблемой остановки).
Можно ли считать конструктивной математику, оперирующую неразрешимыми множествами? Я (основываясь на программистской интуиции) так считать не могу.
Хотя бы потому, что множество программ перечисляющих множества — разрешимо (это, примерно, все программы правильной сигнатуры), а множество программ разрешающих множество — нет (и даже не перечислимо).
Вы подняли крайне интересный вопрос. Анализировать приятнее перечислимые множества и перечисляющие алгоритмы. При этом перечисляющие алгоритмы не дают нам ответа на наши вопросы, к ним нужно применить ту самую злосчастную функцию минимизации, после которой наш компьютер (может быть) зависает и никто не может сказать заранее зависнет он или нет.
Т.е. с точки зрения практического программиста, конструктивная математика — это математика, которая даёт нам независающие разрешающие алгоритмы. Т.е. она решает наши проблемы и не глючит.
При этом у нас есть теоремы, которые говорят, что статический анализ может быть только для перечисляющих.
Вот тут вот главная драма программирования и зарыта.
Но тогда у него будут фолс-позитиврешы (какие-то алгоритмы, которые на самом деле разрешающие, будут считаться не-разрешающими).
Вот где-то тут мною прочитанная книжка либо убежала в скучные дали, либо не осветила этот вопрос. Вообще, практические и философвские вопросы разобраны там на удивление скудно. Видимо, сказывается то, что автору хотелось про теорию алгоритмов рассказывать, а не про программирование (а мне интересно было больше про последствия для программирования).
Забавно, что большая часть теоретических результатов CS, применяемых для «конструктивного программирования» (другого у нас нет) доказывается неконструктивными методами (собственно, одним-единственным — диагональным методом Кантора).Доказательство само по себе — это уже нечто не совсем конструктивное, потому что «конструктивный» факт можно просто проверить. Вообще, это удивительная загадка, как не детерминированная по своей сути нейронная сеть мозга может воспроизводить такую вещь, как доказательства, которые предполагают 100% уверенность. Например, если мы видим довольно сложный, если его разобрать до бита алгоритм, который увеличивает счетчик до 5, а потом сбрасывает на 0 и повторяет, то мы точно знаем, что число 6 там не появится. В этой уверенности первично ощущение нейронной сети, что такого не может быть никогда. А все формальные доказательства — вторичны, и предназначены только для того, чтобы привести нейронную сеть мозга в состояние уверенности. Когда-то математика и наука об интеллекте сойдутся в одно целое и это было бы очень интересно.
Ну, бывают конструктивные доказательства. Например, хорошим вариантом доказательства существования чего-либо является эффективный алгоритм его конструирования.
А насчёт "уверенности нейронных сетей" — броуновское движение молекул полностью хаотичное, но мы можем быть полностью уверены, что молекулы не сгруппируются в половине комнаты сами по себе. Все "уверенные" события — всегда результат микроскопической вероятности обратного; поскольку "снизу" там квантовая физика с волновыми функциями, мы никогда не может быть уверены, что какое-то событие произойдёт точно, просто вероятность обратного такова, что ей можно пренебречь.
В каком-то смысле это как анализ через пределы. dt устремляем к нулю, и отбрасываем ничтожно малые.
N=N+1Дело в том что после этой записи практически сразу следовала задача. Мое подсознание автоматом применило аналогию с формулой a=b+c, ну и следом представилось а=а+1.
То есть подставив любо значение (e.g. 6=6+1). Я не мог уяснить как 6 может быть равно 7. С этим и был связан ступор.
PutTo N value (N+1)Благодарю за разъяснение, теперь разобрался.
В программировании математика как таковая не нужна.
Математика и программирование — отличающиеся вещи. Очень большая ошибка полагать, что программирование будет похоже на математику. Это верный способ так и не понять элементарных вещей.
Есть две большие ошибки.
Первая, считать, что программирование состоит только из обычной математики.
Вторая, считать, что в программировании математика вообще не нужна.
Начнем с того, что программирование само по себе некоторыми считается (не без оснований) разделом прикладной математики. И, если принять это, получаем, что изучая программирование человек изучает математику.
Кроме того, даже самому убогому формошлепу нужны азы арифметики и геометрии (отличить прямоугольник от круга и прикинуть количество строк, влезающих в элемент интерфейса). А это, внезапно, тоже математика.
На более серьезных уровнях программирования вылезают другие разделы математики — булева алгебра (те самые операции над битиками), теория множеств и т.п. И что занятно, многие, пользуясь всеми этими математическими знаниями, отрицают то, что они используют математику.
Описание предметной области, внезапно, очень часто без сложной математики не обходится.
Если есть желание понимать, "о чем программа", а не замыкаться в своем уютном мирке исполнителя чужих заданий, не понятных смыслом своим, то знать хотя бы основы высшей математики просто приходится.
Ну и еще математика тренирует многие навыки, потребные при программировании.
А уж как в некоторых случаях тяжело работать с программистами, отрицающими необходимость математики в программировании.
Но и замыкаться на "чистой математике" нельзя. Ее недостаточно. Еще нужны лингвистические навыки в виде как минимум умения связно выражать то, что должна делать программа, на используемом языке программирования.
замыкаться на «чистой математике» нельзя. Ее недостаточно. Еще нужны лингвистические навыки в виде как минимум умения связно выражать то, что должна делать программа, на используемом языке программирования
Есть и такой раздел математики en.wikipedia.org/wiki/Computational_linguistics
Кстати, еще один пример проникновения "ненужной" математики в различные сферы, в том числе "исключительно гуманитарные" ("лингвистам математика точно не нужна", (с) школьник старших классов, желающий поступать на соответствующий факультет вуза).
Впрочем, математическая модель, описывающая объекты, изучаемые лингвистикой, не обеспечивает сама по себе владение лингвистическими навыками, как и уравнения математической физики — это далеко не вся физика, хотя без математики в физике уже давно совсем никак.
хотя без математики в физике уже давно совсем никак.
Я бы сказал что физика в принципе не может существовать без математики
это далеко не вся физика,
а что вы знаете в физике — что не является математикой?
Для начала нужно определиться, что есть математика и что есть физика.
И похоже что тут мы и застрянем…
Достаточно взять элементарный закон Ома который учат в школе, только не в школьном его варианте, а в интегральной форме (в которой он собственно изначально и должен быть представлен) и сразу получается что без математики дальше чтото делать в физике нельзя.
Математика это абстрактный язык описания явлений, физика это часть реального мира который может быть описан математикой. конечно физика может существовать без математики (взял в руку молоток и забил гвоздь, никакой математики, также как программирование может существовать без языков программирования)
а что вы знаете в физике — что не является математикой?
Как минимум интерпретация математических выражений применительно к окружающей реальности.
U=IR не имеет особого смысла без представления о том, что такое напряжение, сила тока и сопротивление, и какова их природа.
Ну допустим вы представляете что существую некие атомы с зарядами, всякие там кристаллические решетки. без языка описания этих сущностей и процессов между ними… это просто какието не имеет никакого смысла
В математике нет понятий сопротивления, напряжения и силы тока.
Математика описывает только зависимости между этими величинами.
Или, если не замыкаться в рамках закона Ома, математика в рамках физики описывает только закономерности в поведении и структуре физических объектов и их систем. Интерпретация смысла знаков в уравнениях — это уже не математика, а физика
При этом одна и та же математическая конструкция может описывать разные физические процессы. И знание, какой именно процесс в данном конкретном случае описывает данное уравнение, лежит вне пределов математики.
В математике нет понятий сопротивления, напряжения и силы тока.
А вот прикладная математика рассматривает применение математических методов, алгоритмов в др. областях науки и техники.
В математике нет понятий сопротивления, напряжения и силы тока.
Эти понятия — более высокий уровень абстракции, точнее сказать — прикладной
Попробуйте без математики объяснить зависимость напряжение от силы тока, чисто физическими понятиями.
математика в рамках физики описывает только закономерности в поведении и структуре физических объектов и их систем.
Конечно, я и упоминал что математика — это универсальный язык описания всего вокруг. Она не источник всего, она лишь язык описания.
Еще раз. Если взять в руки кувалду и стукнуть по стене — вы зная ТОЛЬКО физику, не сможете сказать, упадет стена или нет. Просто потому что у вас нет инструментов это сделать, кроме математики.
И знание, какой именно процесс в данном конкретном случае описывает данное уравнение, лежит вне пределов математики.
тоже верно, однако вы вполне можете вывести математическую модель этого процесса, даже не зная о его существовании. А если рассматривать вселенную как единый математический объект (а почему кстати и нет) то уравнение, пусть оно будет сколь угодно большим, будет всёравно существовать и даже описывать поведение животных к примеру.
Эти понятия — более высокий уровень абстракции, точнее сказать — прикладной
Вот этот уровень абстракции и есть та физика, которая совсем не математика
Попробуйте без математики объяснить зависимость напряжение от силы тока, чисто физическими понятиями.
Это естественно для современной физики, и я никак это не оспариваю, но есть нюанс.
U=IR
F=ma
С точки зрения математики это одно и то же — одна величина равна произведению двух других. Только "переменные" промаркированы по разному (что может с точки зрения математики говорить как о принципиальном различии смысла величин в формулах, так и о том, что это просто разные случаи одного и того же).
С точки зрения физики это два совершенно разных физических закона из разных разделов физики (тот самый более высокий уровень абстракции).
U=IR
Это вы школьную физику в пример привели. Настоящий вид этой формулы — интегральный
С точки зрения математики это одно и то же — одна величина равна произведению двух других.
еще раз повторюсь, не стоит ограничиваться школьной математикой. Никто не считает значимые вещи тупо перемножением двух величин не вникая в их сущность. Каждая из этих букв — это отдельная формула для удобства упрощенная. То же самое напряжение связано с напряженностью поля как минимум, сопротивление размером проводника и температурой и проч.проч. а то что вы привели в пример максимально упрощенный школьный вариант, где эти параметры отсутствую, совершенно не значит что их можно игнорировать в обсуждении значимости математики :) в таких расчетах.
Вообще чтобы не возникало желания сказать что «математика не знает что это разные сущности» — скажу опять, представляйте себе вселенную как ЕДИНУЮ математическую модель, где все сущности связанны друг с другом… что собственно и есть.
Начнем с того, что программирование само по себе некоторыми считается (не без оснований) разделом прикладной математики.
… я бы сказал что вообще все в этом мире можно описать математикой и в некотором роде отнести к ней… У меня лично не совсем хватило усидчивости и вычислительных возможностей мозга чтобы полноценно ей увлечься, благодаря отличным преподавателями физики и вышки в университете где я всего семестр отучился, я реально стал смотреть на мир несколько иначе… и вот очень понимаю Перельмана с его фразой «Я знаю, как управлять Вселенной»
только это не значит что нужно прямо учить математику чтобы уметь программировать. Мне вот лениво представлять себе программы как чрезвычайно сложные математические выражения и продумывать оптимизации с этой точки зрения, поскольку это не несет зачастую никаких бонусов, кроме разве что удовлетворения от глубинного понимания этих процессов… а людям еще более далеким от математики это будет более чем непонятно в принципе
Я долго вникал почему 0 в степени 0 равен 1, и у меня ощущение что я до конца так и не понял всей сути.
Ноль в степени ноль в математике не определенно, также как и ноль делить на ноль, ноль умножить на бесконечность и т.п.
Эти значения доопределяются для каждого конкретного случая, связанного с предельным переходом.
Например, в функции y = x^x, при положительных значениях х, все определенно и понятно (постройте этот график и убедитесь сами, можно попутно найти минимум этой функции). Так вот, при x, стремящемся к нулю справа (при x, меньших нуля, эта функция неопределенна), легко видеть, что значение функции стремиться к единице. Его еще называют значением по непрерывности. Поэтому, ничего нам не мешает доопределить эту функцию в нуле, так чтобы для всех неотрицательных значениях x, функция сохраняла непрерывность (и даже дифференцируемость).
На мой вопрос: «как решаются такие уравнения?», ответ был очень прост: «учи исследование функции, начало анализа и задачи на оптимизацию. Алгебра 10-11 класс».
Мы квадратные уравнения изучали в пятом-шестом классе. А тригонометрию вам в школе преподавали? А стереометрию? Классов у нас было десять, анализа, исследования функции и оптимизации не было, но я лично в десятом классе все это легко выучил самостоятельно (по учебнику для первого курса ВТУЗов).
Начинаю осознавать, что для полной картины понимания Computer Science, мне необходимо будет заново учить алгебру, а затем и ВысшМат.
Программисту математика нужна именно как точка опоры, в основном ради абстрактного мышления. Иначе, как вы будете придумывать собственные алгоритмы, не имея абстрактного мышления? Возможно только тупое использование чужих наработок, но любой шаг в сторону будет очень болезненным.
Пример, возьмите опенсорсную библиотеку компьютерного зрения OpenCV. Ее использование – современный тренд в распознавании чего-либо с помощью элементов искусственного интеллекта. Так там большинство алгоритмов используют не просто высшую математику, а математику из арсенала мехмата МГУ, т.е., нечто запредельного уровня сложности.
А вот сама прикладная математика в обычной жизни редко применяется. Мне даже школьная тригонометрия практически ни разу не пригодилась. Но для разработки игр эта вещь очень полезная.
Могу открыть маленький секрет, достаточно знать не объемный курс высшей математики, а просто быть способным легко усваивать нужную тему. А по сложным алгоритмам можно попросить помощи на форуме математиков. Я вот недавно задал там вопрос: «Как группировать бинарные матрицы по степени их похожести?» ( dxdy.ru/topic142232.html ) и нашел ответ с общей помощью, что позволяет мне программировать дальше.
Программисту математика нужна именно как точка опоры, в основном ради абстрактного мышления.
Не соглашусь. Я давно заметил, что из крутых математиков редко получаются хорошие программисты. Понимание навороченных математических абстракций слабо связано с пониманием абстракций программистских.
Иначе, как вы будете придумывать собственные алгоритмы, не имея абстрактного мышления? Возможно только тупое использование чужих наработок, но любой шаг в сторону будет очень болезненным.
Так современное программиование — это не придумывание новых алгоритмов, а переиспользование уже существующих. Велосипеды обычно не нужны, потребность в новых реализациях и новых алгоритмах не насколько велика.
Пример, возьмите опенсорсную библиотеку компьютерного зрения OpenCV. Ее использование – современный тренд в распознавании чего-либо с помощью элементов искусственного интеллекта. Так там большинство алгоритмов используют не просто высшую математику, а математику из арсенала мехмата МГУ, т.е., нечто запредельного уровня сложности.
Вот только эта библиотека разрабатывалась не математиками для математиков, она нацелена на широкие массы. Да, там реализованы сложные алгоритмы. Но пользователю этой библиотеки совершенно не обязательно уметь эти алгоритмы реализовывать самостоятельно.
Не соглашусь. Я давно заметил, что из крутых математиков редко получаются хорошие программисты. Понимание навороченных математических абстракций слабо связано с пониманием абстракций программистских.
Согласен в то части, то 100%-ные математики не готовят себя к программированию, поэтому они его просто не знают. Но среди крутых программистов трудно найти человека, который совершенно не знает математику. Возьмите трехтомник Кнута, «Искусство программирования». Сможете ли вы утверждать, что он не знает математику? Да он ее знает покруче некоторых дипломированных математиков.
Хорошо назовите пример крутого программиста, в части нетривиального программирования, который в математике ноль, как, скажем, Александр Сергеевич Пушкин.
Так современное программиование — это не придумывание новых алгоритмов, а переиспользование уже существующих.
Глупости это все. Нет, ну есть системные программисты, прикладные и технические. Если вы ведете речь о технических программистах, то, соглашусь, они только обслуживают чужой код, не более. И за стандартные пределы своей компетенции не выходят. Чем то похожи на специалистов по калькулятору. Вы же не будете ставить им задачу создать новый алгоритм сложения или там вычисления месячной нормы амортизации, когда определена законодательно только квартальная. Последнюю они в состоянии разделить только на три, что не при любом законе правильно.
Вот только эта библиотека разрабатывалась не математиками для математиков, она нацелена на широкие массы. Да, там реализованы сложные алгоритмы. Но пользователю этой библиотеки совершенно не обязательно уметь эти алгоритмы реализовывать самостоятельно.
Речь идет не столько о самостоятельной реализации алгоритмов OpenCV, сколько о понимании их работы. А как вы их поймете, если не знаете математики? А непонимание чревато. Убедился на себе. Я вот сейчас пишу обучающую программу по распознаванию встроенных субтитров видео роликов и перевода их на русский язык. В том числе использую OpenCV (наряду с SDL и FFmpeg / FFplay). Так вот использование алгоритмов OpenCV вслепую, по аналогии с опубликованными примерами, приводит, в конечном счете, к плачевным результатам (для более-менее серьезных проектов). И только когда я начал вникать в алгоритмы и пользоваться их собственными аналогами, дела пошли лучше. И даже код получался проще и понятнее. Надеюсь, я еще опубликую здесь свою статью об этом.
Велосипеды обычно не нужны, потребность в новых реализациях и новых алгоритмах не насколько велика.
В более-менее серьезном проекте очень даже бывает нужны. Иначе вы вынуждены ограничивать себя тем пространством, который вам оставил разработчик, что далеко не всех устраивает.
Если вы наслышаны про 1С, то можете знать о мегатоннах холивара и сра*а на эту тему. А все почему? Потому, что программировали его люди, плохо знающие математику, соответственно, со слабым абстрактным мышлением. В итоге, «ежики плакали, кололись, но ели кактус». А куда деваться бедным пользователям?
Возьмем простейшую ситуацию. Допустим, вы специалист по интерфейсу программ. Вам поставили задачу использовать MDI-интерфейс, но чтобы в дочерних окнах были локальные меню. Не будем спорить, зачем? Приказы начальства не обсуждают. Вы думаете: «а, щас, задача – два пальца об асфальт». Делаете, но болт! Не получается. Начинаете копать глубоко и выясняете, что локальные меню запрещает парадигма MDI на уровне системных dll. Вот те на! И действительно, никто не использует локальное меню. Вместо этого применяется контекстное меню, панель инструментов, командную панель, кнопочное меню, различного рода панели управления, но полноценного локального меню в дочерних окнах нет (возьмите для примера интерфейс 1С любой версии).
И что делать? Изобретать собственный вариант псевдо MDI? Или эмулировать собственное меню? Это можно, но очень долго. Также непросто обстоят дела с закладками окон, можно использовать тяжелые внешние библиотеки, но нужно ли?
Хорошо, вас переключили на SDI-интерфейс. Говорят, сделай нам мультипоточный интерфейс с перегружаемыми либо неявным образом переключаемыми клиентским окнами. Есть хороший прототип для работы? «Брезенту ненту!», как говорил старый Райкин.
И так за что не возьмись, если делать что-то свое, то, как правило, хороших прототипов нет. Ну, попробуйте по быстрому, включить в свое приложение проигрывание видео файлов. Постоянно будете либо использовать монстры, которых вполне можно избежать, либо долго думать, как выкрутится из ситуации.
Короче говоря, если не изобретать свои велосипеды, там, где это реально необходимо, программировать хорошие продукты будет тяжело. Даже в математике, которая якобы напридумала всего, как многие считают, на сотни лет вперед, очень часто бывает, что для решения реальных задач нет подходящего математического аппарата. Просто вы с этим не сталкивались, но это факт.
Поэтому, думать, творить и изобретать что-то свое очень полезно, если не хотите быть последним человеком в своей специальности. Однако это совсем не отменяет изучение чужого опыта, скорее наоборот. Как говорил Ньютон: «Если я и увидел дальше, то только потому, что стоял на плечах гигантов!».
Требуется некий алгоритм. Готового на данный момент нет. Мы не хотим изобретать велосипед и ищем готовое решение. Нашли. Но в составе некоторого фреймворка. Увы, реализация нужного алгоритма очень глубоко интегрирована в фреймворк — просто так его не «выкусить» отдельно.
Что тут можно сделать? Портировать весь фреймворк на нашу платформу. Возможно. Но. Есть тонкость — ваша задача, использующая что-то из этого фреймворка пойдет на пром. И потащит за собой весь фреймворк. Все, что выводится на пром, должно быть предварительно всесторонне протестировано. В том числе и пройти через нагрузочное тестирование. Т.е. вы не можете вытащить на пром портированный вами фреймворк, полностью его не протестировав. А это время. И не факт что оно пройдет через все стадии тестирования без допиливания.
Таким образом, вы только на подготовительные работы убьете кучу времени с непредсказуемым результатом.
В данном случае проще и эффективнее реализовать нужный алгоритм самому. Тогда тестировать придется только то, что нужно вам. Намного более реальная задача. И по усилиям и по срокам.
Увы, реализация нужного алгоритма очень глубоко интегрирована в фреймворк — просто так его не «выкусить» отдельно.
Что тут можно сделать? Портировать весь фреймворк на нашу платформу. Возможно.
Достаточно интересная проблема. Я ее называю проблемой модульного программирования. Ладно там в языках свервысокого уровня, типа 1С, когда просто сама платформа ограничивает вас в ваших хотелках. Но ведь даже в С++ писать на уровне слабосвязанных модулей, так чтобы можно было их легко менять «как перчатки» очень тяжело.
Интересовался этой темой в Интернете. Как всегда, ничего путного нет. Хотя на абстрактном уровне вроде все понятно. Программные модули в С++ можно структурировать на уровне:
– Каталогов / файлов;
– Классов / структур;
– Процедур / функций, в т.ч., inline functions.
Однако проблемы здесь связаны с иерархическими зависимостями и распределенным использованием. Как с этим бороться? Непонятно!
Тем не менее, собственный код я пытаюсь делать модульным и взаимозаменяемым. Но с используемыми фреймворками такие номера не прокатывают. Их приходится включать целиком. Максимум, что они позволяют это пакетное разделение, а на бинарном уровне – соответствующие библиотеки поддержки, в виде конкретных dll.
Но даже для собственных модулей встают вопросы. Где описывать хидер файлы общего назначения? Только в общем файле StdAfx.h или как-то раздельно для каждого включаемого пакета? Как отслеживать точки входа и выхода для используемых классов? А ведь могут быть еще и другие точки управления. Может быть, это все описывать в каком-либо внешнем скрипте, по которому некий мастер будет генерировать конечный код проекта? И т.д. и т.п., вопросов много, а ответы приходится искать методом «научного втыка» :).
А как вы решаете проблемы модульности собственного кода?
Я не портирую на нашу платформу (IBM i) сложных фреймоворков в силу ее специфичности. Если что-то нужно, я просто реализую нужный алгоритм и делаю атомарный модуль (тут это называется *SRVPGM — нечто типа dll в винде, но со специфическими заморочками). На круг это выходит проще и быстрее (с учетом тестирования) чем тащить что-то объемное с других платформ.
У нас есть своя «кодовая база», так называетмые «леса» (LES — низкоуровневые сервисы общего назначения) куда каждый может вносить свой вклад в виде реализации полезных алгоритмов. Фактически это куча *SRVPGM, объединенных одной *BNDDIR (что-то типа библиотеки импорта в винде) — чтобы подключить нужный модуль достаточно добавить исходник (т.н. copysource) с прототипом и подключить LESBNDDIR к проекту.
Основная проблема с портированием — концепция т.н. «групп активации» (ACTIVATION GROUP, ACTGRP) — это такое подмножество задачи (JOB). Для каждой программы указывается тип группы активации.
*CALLER — вызываемая программа работает в той же группе активации, что и вызывающая (наиболее предпочтительный у нас способ)
*NEW — программа каждый раз создает новую группу активации и работает в ней. У нас крайне не рекомендуется т.к. страдает эффективность.
Именованная — программа имеет свою группу активации, которая создается при первом ее запуске в рамках данного задания (JOB) и удаляется только вместе с окончанием задания (или специальной командой RLSACTGRP).
С одной стороны, группы активации не имеют изолированной памяти (память на IBMi одноуровневая, изоляция памяти идет на уровне задания, внутри задания память доступна всем программа в нем работающим). С другой же, в рамках группы активации между вызовами программы сохраняются открытые файловые дескрипторы, глобальные и статические переменные. Т.е. если вы сделали программу (или SRVPGM) с именованной группой активации и в ней где-то используете статическую переменную, то при втором (и последующих) вызовах этой программы в рамках одного задания значения этих переменных будут сохраняться с предыдущего вызова.
В общем, при портировании чужого фреймворка где используются глобальные и статические переменные, могут быть сюрпризы — нужно быть очень внимательным и досконально разбираться во всех потрохах.
У кого-то из наших с этим были какие-то проблемы, когда он попытался сделать SRVPGM, внутри которой были контейнеры из STL, а наружу торчали врапперы для использования этого из RPG программ (в RPG нет объектности). Как раз что-то там со статикой порой странновато работало.
Посему я для своих целей сделал свои контейнеры (то, к чему привык и то, чего мне нехватало в RPG) — двусвязный список, SkipList (сортированый список пар данные-ключ) и на его основе обычный сортированный список (где данные одновременно являются ключом) и «набор» (однотипные данные, они же ключ + специфические функции типа AND/OR/XOR по двум наборам, разность наборов и еще некоторая специфика) — все это отлично работает из RPG программ через врапперы.
а какой смысл в использовании столь экзотической архитектуры?
унаследованный код — понятно, но вы же, судя по вашим сообщениям, занимаетесь активной разработкой.
Основной язык программирования — RPG. Он хорошо работает с БД, хорошо работает со строками. Но есть вещи, которые удобнее делать на С/С++. Есть вещи, котрых лично мне нехватает в RPG. И я их себе дописываю на С/С++.
Тут еще есть более экзотяческая вещь — концепция ILE (Intergated Language Environment). Если кратко — в составе ОС идет набор компиляторов — CL (Comman Language — системный язык операционки, достаточно мощный), COBOL (у нас не используется, но он есть), С/С++ и RPG. И концепция ILE позволяет писать разные куски кода на разных языках, компилировать каждый в отдельный модуль (аналог объектного файла), а потом несколько модулей собирать в один программный объект (исполняемая программа PGM или сервисная SRVPGM). Т.е. получаем некоторые функции написаны на С, некоторые на RPG и все они друг из друга вызываются (при правильном описании прототипов и понимании принципа соотвествия типов и способов передачи параметров).
Более того, там еще можно непосредственно в код вставлять SQL запросы (есть препроцессор соответсвующий)…
Все это позволяет достаточно гибко писать весьма эффективный код.
Ну а возможности самой системы… На тесте стоит сервер PowerS 924 c 18-ядерным SMT8 процессором и 1.8Тб оперативки, выделяющий 16Гб памяти на задачу (JOB). Нехватает одной задачи — можно распараллелиться через submit job (SBMJOB или spawn) и организовать параллельную обработку с обменом данными через очереди (DataQueue/UserQueue), пайпы или юникссокеты.
На проме — кластер из трех PowerS 928 (каждый по 18 12-ядерных SMT8 процессоров и 2.5Тб оперативки).
Операционка сейчас IBM i 7.3 TR8 Ждем апгрейда до 7.4 в обозримом будущем.
В общем, это весьма интересный мир.
Есть даже возможность самому попробовать эту систему «на зуб» — есть публичный AS/400 сервер pub400.com Там немного запутанная регистрация, но все бесплатно. Потребуется только пройти регистрацию чтобы создался профайл и скачать, например, с IBM бесплатный пакет Access i Client Solutions (тоже надо бесплатно зарегистриоваться). Настройка на сервер там тривиальная.
В профайле будет одна профайловая библиотека (аналог папки в винде) и возможность создать еще одну. И немного дискового пространства. Для простеньких тестовых программок хватит. просто попробовать.
Там нет ассемблера. В принципе. Т.к. есть определенный уровень, ниже которого доступ запрещен. Всем. Кроме разработчиков самой ОС. Это уровень TIMI — машинных инструкций, не зависящих от технологии.
Ну и еще много всяких чудес. Кому интересно — есть неплохая книга — Френк Солтис (один из отцов-основателей AS/400, которая потом «ребрендилась в IBM i) „Основы AS/400“. Там от истории и достаточно популярного изложения до достатчно сложный вещей — базы данных (DB2, она тоже интегрирована в систему), уровней защиты, машинных инструкций, устройства одноуровневой памяти, структуры указателей (они там 16-байтные) и прочих потрохов.
Менее года назад я был в Буэнос-Айресе на встрече с группой пользователей этой системы. По окончании встречи молодой репортер газеты «La Nacion» спросил меня: «Сформулируйте, пожалуйста, коротко причины того, почему в AS/400 столь много новшеств?». И я ответил: «Потому что никто из ее создателей не заканчивал MIT.» Заинтригованный моим ответом, репортер попросил разъяснений. Я сказал, что не собирался критиковать MIT, а лишь имел в виду то, что разработчики AS/400 имели совершенно иной опыт, нежели выпускники MIT. Так как всегда было трудно заставить кого-либо переехать с восточного побережья в 70-тысячный миннесотский городок, в лаборатории IBM в Рочестере практически не оказалось выпускников университетов, расположенных на востоке США. И создатели AS/400 — представители «школ» Среднего Запада — не были так сильно привязаны к проектным решениям, используемым другими компаниями.
Френк Солтис, „Основы AS/400“
В общем, ничуть не жалею что ушел в этот мир. Очень расширяет кругозор и в чем-то даже взгляды на жизнь. Ну и уровень разработки тут весьма серьезный.
В принципе, если говорить о конкретном банке, то ИТ тут почти „государство в государстве“ — от обычной ИТ компании отличаемся только тем, что у нас всегда постоянный заказчик, постоянная тематика и постоянная платформа.
Думаю, что сразу можно предположить, что в системах подобного типа нет вирусов. Это так? А как насчет интерфейсов программ? Насколько удобно иметь с ними дело? И почему указатели 16-ти байтные при терабайтах памяти?
И, интересно, а дома вы какую операционку используете?
И почему указатели 16-ти байтные при терабайтах памяти?
У Солтиса это разъяснено. Не то чтобы он убедил, но по крайней мере объяснил мотивы.
Но конкретная реализация может и сократить их длину.
Ваша система вызывает страх и ужас. Своей изощренностью, закрытостью и уникальностью. Это действительно другой мир, который принять могут «не только лишь все».
Это только по первости. Когда немного вникнешь, то там видна четкая логика и цельность во всем.
Начать с того, что она вполне самодостаточна «из коробки» (хотя это не совсем то выражение — она сделана под определенную платформу — IBM PowerSystem и поставляется только вместе с ней, отдельно ее не бывает и на другую платформу не встанет).
Т.е. там сразу есть
— Встроенные компиляторы (CL, RPG, COBOL, C/C++). Фактически компиляция — это просто команда типа CRTBNDRPG/CTRBNDCPP/CRTBNDCL и т.п. Что забавно — компиляция программы, написанной на системном языке CL осуществляется командой этого же языка CL — язык очень мощный, референс по командам порядка 2300 страниц. Часть может использоваться как в интеактиве, так и в программе. Есть еще язык описания данных (таблицы, индексы, дисплейные и принтерные файлы) — DDS
— Встроенную БД DB2. Причем, исторически сложилось так, что работать с ней можно как средствами SQL, так и «прямым доступом» (функции позиционирования курсора, чтения, записи, удалеиния — в RPG и CL они встроены, в С/С++ входят в состав библиотеки RECIO).
— Встроенный редактор (ужасен и неудобен, но он есть) — SEU
— Встроенный отладчик (требуется привычка, но возможности неплохие, в том числе можно «прицепиться» к уже работающей в фоне задаче и отлаживать ее)
— Встроенное средство для выполнения SQL в интерактиве.
Т.е. все нужно для работы уже есть.
Думаю, что сразу можно предположить, что в системах подобного типа нет вирусов. Это так?
Ни разу не слышал :-)
А как насчет интерфейсов программ? Насколько удобно иметь с ними дело?
Ну тут надо понимать, что это не десктопная система. Общение с ней идет через эмулятор терминала IBM5250. Изначально это были реально аппаратные терминалы, обмен данными с сервером идет в блочном режиме, как бы «экранами». Фактически «экран» аналогичен записи в таблице БД. На языке DDS описывается структура каждого экрана в которой есть поля (они типизированы как и в таблицах, кроме того у каждого поля есть набор аттрибутов — положение на экране, ввод — ввод/вывод — вывод — скрытое ну и еще рад дополнительных всяких типа цвета, инверсии, яркости и т.п.). Вывод экрана — той же командой что и запись в таблицу БД. Чтение — как и из таблицы.
Т.е. открываем дисплейный файл (как обычную таблицу, но со специальным аттрибутом workstation), в нем будет несколько форматов записей — каждый формат — экран. Присваиваем переменным-полям значения и делаем write с именем нужного формата. Экран отображается на мониторе. Потом делаем read и система ждет пока пользователь заполнит допустимые поля и нажмет enter (или служебную клавишу) — после этого управление возвращается в программу и мы можем работать с переменными.
Выглядит это как-то так (картинка их интернетов):

Ну а главное меню системы (когда подключаешься к серверу) примерно так выглядит:

Сейчас есть программные эмуляторы этих терминалов, т.н. TN5250. Их много разных, под разные платформы. Платные и бесплатные. Даже под андроид есть :-)
Мы пользуемся бесплатным пакетом от IBM — Access i Client Solutions. Там кроме собственно эмулятор терминала еще много всяких утилит — для работы с БД, интерактивный SQL, просмотр spool файлов (это вывод на принтер без них тоже никуда — результат компиляции, в том числе и ошибки туда выводятся, джоблоги, дампы при падении программы и т.п.).
Большая часть того, что мы разрабатываем, все-таки, предназначено для работы в фоновом режиме и не имеет интерфейса. С внешним миром оно общается через вебсервисы (сервис посылает запрос, мы его обрабатываем, отдаем ответ). Ну или просто обрабатывает данные.
Но есть и т.н. «опции» (это уже термин нашей АБС — автоматизированной банковской системы) — программы, позволяющие работать с таблицами в терминале. Просмотр, ввод и изменение денных и т.п. Но это для внутреннего пользования больше.
Когда привыкаешь к этому стилю, убеждаешься что работать в таком режиме достаточно комфортно и быстро. Зачастую даже быстрее чем с GUI. Есть особенность, к которой привыкать приходится — в оригинальном 5250 не 12 функциональных клавиш, а 24. И они активно задействованы. Ну скажем, в отладчике, чтобы загрузить дополнительный модуль для отладки нужно нажать F14, а найти следующее вхождение текста — F16 :-) Первое время на пальцах считаешь, потом привыкаешь автоматом — F13 = Shift+F1 и т.д.
И почему указатели 16-ти байтные при терабайтах памяти?
А вот тут все сложно.
Из того же Солтиса:
Программы, и прикладные, и системные адресуют объекты при помощи 16-байтовых указателей; которые точнее было бы называть 128-разрядными (их используют все прикладные программы с момента появления System/38 в 1978 году). Но не все разряды: этого указателя используются, поэтому AS/400 обычно не называют 128-разрядным компьютером. Указатель содержит 64-разрядный адрес одноуровневой памяти, а также несколько разрядов дескриптора и неиспользуемые разряды, зарезервированные для будущих расширений.
Я еще, к стыду своему, не до конца осилил как это все внутри работает.
Если реально интересно — it.wikireading.ru/6119
И, интересно, а дома вы какую операционку используете?
Дома винда. И на работе тоже винда. Т.е. пишем под виндой все. Там есть специализированная IDE — RDi (Rational Development for i) на базе эклипса, заточенная на работу с сервером AS/400.
IBM i — это новое название — изначально она была AS/400, потом серия «ребрендингов» — System i, iSystems, IBM i — все это одно и тоже — сейчас у IBM две мейнфреймовых платформы —
i — исторически это System/32 — /34 — /36 — /38 — Advansed System 400
и
z — это System/370 — /390 (возможно она же и AIX, я эту ветку не знаю совсем, вроде как что-то Unix-like)
Вообще, разработка вглядит примерно так: пишем код на локальном компе. Потом забрасываем его на сервер и там запускаем компиляцию (в эмуляторе терминала). Если были ошибки — смотрим спулы, там будет листинг с указанием где что не нравится.
Если собралось — в терминале запускаем и смотрим как работает. Нужна отладка — там же отлаживаемся (хотя RDi позволяет удаленную отладку, но мне как-то не зашло, некоторые пользуются)
В реальной жизни все сложнее. Каждая поставка это несколько объектов (у меня вот сейчас в работе была большая задача — там 162 объекта в поставке) Собрать все это руками замумукешься. Поэтому в поставке пишется «инсталлятор» — программа на CL, которая собирает все объекты поставки (ну и еще ряд специфических действий типа регистрации поставки в специальной таблице).
Я еще застал времена, когда все это делалось руками. Сейчас этот процесс автоматизирован усилиями наших DevOps'ов — мы просто пришем gradle скрипы с описанием поставки, а потом запускаем gradle task соответсвующий. Он уже сам генерирует инсталлятор, включает его в поставку, забрасывает все на сервер, компилирует и запускает инсталлятор.
Это работает для тестовой сборки на юните для разработчиков (удостоверится что все собирается нормально и запускается). Дальше уже оформление поставки — коммит в гит, установка тега с мнемоникой патча, запуск соотв. задачи в jenkins которая таким же образом — собирает и устанавливает поставку в юнит-хранилище и создает объект в artifactory. Оттуда уже можно через портал devops устанавливать патч в юниты компонентного тестирования.
А вот в юниты интеграционного и бизнес тестирования уже надо на поддержку заявку подавать — туда только они ставят. И на пром тоже только они (у нас вообще мало у кого есть доступ к прому — это отдельный сервер, мы на тестовом работаетм).
Так что свой мир, свои правила.
Раньше AIX был на RS/6000 и прочих ThinkPad 800-й серии (и кстати на PC тоже) но после объединения линеек продуктов и перехода с PowerPC на Power, теперь он опционально живёт на IBM Power Systems то-есть на AS/400, вместе с линуксом и IBM i (OS/400). То чему так противился Солтис и компания таки случилось. И лучше-бы он не противился ибо может быть сейчас-бы была жива Workplace OS — грандиозный план IBM по созданию единой микроядерной OS для всех видов IBM-овских машин. И может быть, мир был-бы немножко другим.
Вы хорошо объясняете, может быть, у вас талант технического писателя? Однако для меня это все темный лес. Тем более что IBM это корпорация как «государство в государстве». Какой смысл вникать в ее закрытые системы, если нет ни желания, ни возможности там работать?
Однако открытые стандарты IBM могут быть интересны. Как, скажем, Intel открыла доступ к своему корпоративному продукту OpenCV (который разрабатывала, в том числе, команда Вадима Писаревского из России).
Вы хорошо объясняете, может быть, у вас талант технического писателя?
Спасибо. Талант не талант, но все свои наработки всегда документирую. Как для других, так и для себя.
Какой смысл вникать в ее закрытые системы, если нет ни желания, ни возможности там работать?
Абстрактно конечно смысла нет. Но в определенных областях они используются и чем черт не шутит… Я вот тоже, когда позвали в банк, пошел просто поговорить — как-то не мыслил себя в этой области. А в процессе разговора вдруг загорелся — люди понравились, да рассказали интересно.
Спасибо. Талант не талант, но все свои наработки всегда документирую. Как для других, так и для себя.
Я книгу по программированию написать не думали? Я бы хотел наваять что-нибудь на тему интерфейса пользователя и модульности в C++ / WTL (не дожидаясь стандарта С++20). Но пока опыта маловато, я ведь не профессиональный программист, просто любитель.
Однако мне нравится роль «свободного художника», никому ничего не обязан, делаешь, что хочешь. У вас ведь в корпорации очень круто, но программист должен быть интегрирован в систему, ее культуру и т.п. Для молодых мозгов это может быть интересно, но я уже как бы вышел из этого возраста. Запад мне резко перестал быть интересен, с какого-то времени. Многие мои однокурсники по мехмату МГУ, в смутные времена, уехали в Штаты и Западную Европу. Сейчас практически все вернулись. По этому поводу я всегда вспоминаю предсказание одного старца: «Возвращайтесь в Россию! Скоро туда будут ехать на подножках товарных вагонов.».
Сам я живу в непризнанной республике ЛНР. Здесь можно достаточно быстро и без проблем получить российское гражданство и выехать в Россию учиться или работать. Хотя есть много оснований для сценария типа «Крым-2», но для Донбасса. Тем более что Донбасс в царские времена был исконно российской территорией (пока его дедушка Ленин не подарил хохлам). Даже сроки называются, до 2024 года (симсоны так вообще называют конкретную дату – сентябрь 2024 года).
Россия мне очень интересна. В свое время я работал в Белгороде, в НИИ, мог даже получить квартиру там, но предпочел уехать в Москву, на учебу, а потом вернулся домой, в Луганскую, тогда, область.
Сейчас, конкретно, пишу программу по распознаванию встроенных субтитров в обучающих видео, вроде «Easy French» на Ютубе. Цель, заменить английский перевод, русским. Во французский язык я влюбился благодаря певице ZAZ (для примера, www.youtube.com/watch?v=MOk5yYLAQvU ). Там будет встроенный видеопроигрыватель, адаптированный для целей обучения. В общем, проект для меня интересный, хотя к Франции я относительно равнодушен, но может быть кто-то из моих предков, царских времен, хоть и жил в России, но разговаривал на французском…
Я читал Солтиса, но проблема этой книги в том, что она переполнена совершенно нетехническими восторгами по поводу буквально каждой мелочи. Есть какая-то более сухая альтернатива (но связная и последовательная, а не внутренние доки)?
Честно говоря, лирику я читал по диагонали, но чем дальше, тем больше там технических подробностей и подробностей весьма серьезных и глубоких. Таких, что не все с первого раза заходит. Видимо, после первого прочтения потребуется второе и третье, уже выборочно.
Со внутренними доками не все так просто. Качество их оставляет желать лучшего. Да и язык тоже. После того же MSDN многие вещи воспринимаются очень тяжело чисто по языку и стилю изложения.
при x, меньших нуля, эта функция неопределенна
Вообще-то определена www.wolframalpha.com/input/?i=complexplot++x%5Ex
И вдобавок в -1 -2 -3 даже не в комплексной плоскости.
Поэтому непрерывности, при x < 0, у этой функции нет, а гладкости тем более. А поскольку речь шла, о предельном значении по непрерывности справа, то я и утверждал, что данная функция не определенна по непрерывности слева. Хотя, строго говоря, функция определенна, как уже говорилось, как разрывная функция и то за исключением иррациональных аргументов. Причем, мера рациональных чисел на любом отрезке равна нулю. Это дает нам право говорить, что строго математически, данная функция не определенна, при x < 0, почти всюду.
Вас такой ответ устроит :)?
На вашем рисунке нет никакой функции в отрицательной полуплоскости аргумента.А вот я вижу, что есть:

Поэтому непрерывности, при x < 0, у этой функции нет, а гладкости тем более. А поскольку речь шла, о предельном значении по непрерывности справа, то я и утверждал, что данная функция не определенна по непрерывности слева.А вольфрам считает иначе: www.wolframalpha.com/input/?i=lim+x%5Ex+as+x-%3E0-
Сложнее вопрос обстоит с рациональными аргументами, здесь помимо действительных, могут быть комплексные значения, а для отрицательных иррациональных чисел функция не определенна даже в комплексной плоскости и вообще для любых числовых множеств.
А вольфрам считает иначе: www.wolframalpha.com/input/?i=x%5Ex+where+x%3D-pi
Вас такой ответ устроит :)?Не устроит, ибо я не вижу на графике разрывов.
Не устроит, ибо я не вижу на графике разрывов.А то, что в левой части графика изображена комплексная функция, вы видите? На рисунке представлены действительная (real) и мнимая (imaginary) части комплексного значения. Действительного предела (по непрерывности) слева для этой функции нет. Есть только предел слева для real-части комплексного значения. А это, как бы, не одно и то же.
Тоже самое для минус пи в степени минус пи. Это выражение многозначно, как, скажем sin(x) на бесконечности. Вы можете выбрать любое значении от –1 до +1 и указать некоторую подпоследовательность, сходящееся к этому значению, что, однако, не сделает это выражение определенным, только с точностью до некоторой подпоследовательности.
Вы можете сказать, что приведенное значение «главное». Тогда я скажу, что «главное» значение sin(x) на бесконечности равно нулю, что проблемы, понятно, не закроет.
Тоже самое для минус пи в степени минус пи. Это выражение многозначно, как, скажем sin(x) на бесконечности.
Скорее оно многозначно так же, как квадртаный корень: sqrt(4) — это либо +2, либо -2. Но вы же не хотите сказать, что квадратный корень — разрывная функция?
А вот функция y = x^x для иррациональных отрицательных чисел просто неопределенна, другими словами, многозначна. Это означает, что существуют разные подпоследовательности, сходящиеся к аргументу, но имеющие различные значения. Равно, как это обстоит с sin(x) на бесконечности. Только sin(x) многозначна в «точках» плюс / минус бесконечность, а x^x многозначная для всех иррациональных отрицательных чисел.
Простите, что с вами спорю, но "неопределена" и "многозначна" — разные понятия. Функция sin(1/x) в нуле неопределена — у нее нет значения. Функция x^x определена везде, включая x = 0 и x = -pi, и при определенных аргументах она многозначна.
Многозначность, как я понимаю, это значение корня функции, дающее одно и то же значение, не чувствительное от некоторой константы или ее кратной величины. Пример, x = arcsin(y). Если y0 – корень, то и y0 + 2pi*n – тоже корень. В этом смысле также многозначна функция Ln(z) в комплексной плоскости (и в отрицательной вещественной полуплоскости), с точностью до 2pi*i.
Однако функция у = x^x, при x = 0 – неопределенна, хотя имеет там предел по непрерывности, равный 1.
Наш спор, по-видимому, заключается в нюансах понятий «неопределенна» и «многозначна». Т.е., разные подпоследовательности могут давать разные значения, которые можно списать на многозначность. Именно в этом смысле я отождествлял эти понятия. Хотя, допускаю, более тонкий анализ может внести некоторые коррективы в наши рассуждения, если определиться с терминологией.
Ситуация с извлечением корня и возведением в степень x^x ровно одна и та же. У этих функций есть разные ветви, и нужно для каждого конкретного применения эту ветвь выбирать. Просто для корня в силу его популярности решили, что обычно проще использовать одну конкретную ветвь. При этом если рассматривать эту ветвь, но такая комплексная функция по необходимости получается разрывной. Вот и с x^x то же самое — если брать "обычную" ветвь логарифма, то неоднозначности не будет. И такая функция тоже будет разрывна — всё как у sqrt.
В треде, к которому относятся эти комментарии, речь про комплексные числа и соответсвующие функции. Хоть в школе хоть не в школе, у функции корня при этом никак не одно значение.
Однако рас против однозначного определения x^x в 1/2 никто ничего не сказал, значит обсуждается только этот самый principial root.
Если коротко, то функция y = x^x аналитическая на всей комплексной плоскости, за исключением может быть каких-то особых точек. Функция эквивалентна следующей: y = exp[x ln(x)], поэтому если логарифм аналитичен для всех комплексных x, тогда проблем нет — мы рассматриваем композицию аналитических функций.
Пусть x = r exp[i q], тогда ln(x) = ln(r) + i q, это основная ветвь логарифма, остальные отличаются на 2pi, т.е. i q, i (q + 2pi), i (q + 4pi) и так далее. Таким образом, при x = x_r, где x_r — строго отрицательное вещественное число, представимое как |x_r| exp[i pi], то ln(x) = ln(|x_r|) + i pi. Т.е. логарифм определен для всех отрицательных вещественных чисел, x ln(x) тоже, exp[ x ln(x)] тоже.
Остается проблема x = 0. Формально, ln(x = 0) = -Inf, но это не помогает. Попробовать разобраться можно так: посмотрим, как себя ведет x ln(x) при x близком к 0. Если эта величина примерно 0, значит x^x = exp[ x ln(x)] = exp [0] = 1 и проблема решена. Можно попробовать приложить правило Лопиталя, у которого есть ряд ограничений, но суть такова: если у вас есть две 'хорошие' функции, предел каждой из которых в какой-то точке это 0 или бесконечность, а вы хотите найти предел отношения этих двух функций, то если существует предел отношения производных этих двух функций (функции хорошие и должны быть дифференцируемы вплоть до предельной точки), то предел отношения этих двух функций равен пределу отношения их производных. Прикладываем эту теорию к нашему случаю:
x ln(x) при x -> 0 это f(x) / g(x), где f(x) = ln(x), g(x) = 1/x, обе функции 'хорошие' вплоть до x = 0, обе стремятся к бесконечности. Берем производные, получаем f'(x) = 1 / x, g'(x) = - 1/x^2, предел отношение f'(x) / g'(x) = (1 / x) / (-1 / x^2) = -x, что при x -> +0 едет к -0. Таким образом, x ln(x) при x = 0 это 0*, а значит exp[x ln(x)] = 1, а значит x ^ x при x = 0 это 1.
Как проверить численно? Берем убывающую последовательность x = 1 / w, где w = 10, 100, 1000, 10000, ..., считаем exp [x ln(x)] = exp [- ln(w) / w]. Не силен в питоне, но вот такой говнокод
import numpy as np
[np.exp(-np.log(w) / w) for w in
[10 ** i for i in range(1, 20, 2)]
]выдает
[0.7943282347242815, 0.9931160484209338, 0.9998848773724686, 0.9999983881917339, 0.9999999792767343, 0.9999999997467156, 0.9999999999970066, 0.9999999999999655, 0.9999999999999996, 1.0]Я согласен, что «композиция аналитических функций» функция аналитическая, но вы сами пишете, что есть «основная ветвь логарифма», а «остальные отличаются на 2pi». Другими словами, логарифм для отрицательных аргументов – функция многозначная. Как тот же sin(x) на бесконечности. Из этого следует, что значение отрицательного иррационального числа в точно такой же степени величина многозначная, даже если можно говорить о «главном» значении.
Что отличает однозначное значение от многозначного? Вы, как профессионал в математике, должны знать, что если непрерывная функция в некоторой точке однозначна, то любая подпоследовательность сходится к этому значению. А если многозначна, то разные подпоследовательности, сходящиеся к искомому аргументу, могут давать разные значения, как вышеупомянутый sin(x) на бесконечности.
И это достаточно очевидно. Возьмем тот же пример www.wolframalpha.com/input/?i=x%5Ex+where+x%3D-pi, указанный samrrr чуть выше. Речь идет о минус пи в степени минус пи. Представим минус пи в виде двух подпоследовательностей рациональных чисел, сходящихся к этому аргументу. В первой последовательности все числители будут четными, а во второй нечетными при нечетном знаменателе. Таким образом, мы получим два разных предельных значения, первое будет положительным числом, а второе отрицательным. Можно также подобрать подпоследовательность, дающую комплексный предел.
Так что, не все так однозначно :).
Если я не ошибся, то (-pi)^(-pi) = pi^(-pi) (cos(pi^2 + 2 pi^2 n) + i sin(pi^2 + 2 pi^2 n)), где n — целое число. Интересный результат заключается в том, что не существует чисто вещественного значения, потому что для этого необходимо, чтобы pi^2 + 2 pi^2 n = 2pi k, где k — целое, или n = k / pi - 1/2. Если k=0, n = -1/2 и не целое, k!=0 — n даже не рациональное, а скорее всего трансцендентное. Т.е. (-pi) ^ (-pi) представляет собой бесконечное количество чисто комплексных чисел, расположенных на окружности r = pi^(-pi).
Не уверен правда, что это легко показать с помощью двух по-разному сходящихся последовательностей, нужно придумать пример.
Моя попытка была показать, что 0^0 = 1 это не просто 'кто-то так решил', а это действительно предельное поведение функции x^x в 0, и что с помощью комплексных чисел это можно прямо посчитать.
Моя попытка была показать, что 0^0 = 1 это не просто 'кто-то так решил', а это действительно предельное поведение функции x^x в 0, и что с помощью комплексных чисел это можно прямо посчитать.
Да, это предельное значение, но только справа. Слева предел не существует, просто потому, что x^x не является непрерывной функцией и даже, вообще говоря, однозначной. Хотя сама эта функция в математике довольно широко используется и изучается.
Однако, что нам мешает рассмотреть композиции типа f(x)^g(x), таких, что f(0) = 0 и g(0) = 0, при x –> 0. Там вообще могут быть чудеса.
x^x имеет пределы с обеих сторон от 0, эти пределы равны, это даже видно из графика который вам присылали:
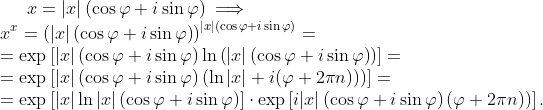
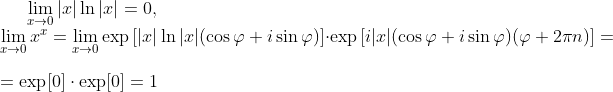
Значение предела не зависит от того, с какой "стороны" к нему приближаться. "Сторона" регулируется phi — для 0+0 phi = 0, для 0-0 phi = pi, а если с чисто мнимой оси, то phi = +- pi/2. Любые значения между тоже допустимы.
Слева предел не существует, просто потому, что x^x не является непрерывной функцией и даже, вообще говоря, однозначной.Напоминаю, вольфрам считает иначе: www.wolframalpha.com/input/?i=lim+x%5Ex+as+x-%3E0-
Вы считаете что он ошибается?
И Что это за ваше новшество в математике, под названием «действительный предел»
Однако то, что предел слева существует и равен единице, я уже согласился в посте выше.
Только вот эта функция не имеет никакого отношения к x^x. И поэтому обсуждать, чему равен интеграл от функции дирихле я не стану.
А я всё думал, когда же дойдёт до этой функции. Осталось только заявить, что иррациональных чисел больше, чем рациональных.
Я уже писал об этом где-то выше (мера рациональных чисел на любом отрезке равна нулю).
Только вот эта функция не имеет никакого отношения к x^x. И поэтому обсуждать, чему равен интеграл от функции дирихле я не стану.
А зачем об этом вообще сообщать? Мы и так знаем, что интеграл Римана для функции Дирихле не существует, а интеграл Лебега, на любом конечном промежутке равен нулю.
Вот например это не единица:
www.wolframalpha.com/input/?i=lim+x%5E%281%2Fln+x%29
Хотя 0^0 же.
www.wolframalpha.com/input/?i=x%5Ex%3B+x%3D0
Смотря что вы имеете ввиду под 0^0. x^x имеет предел единицу, x^(1/ln(x)) = exp(ln(x)/ln(x)) = exp(1) это вообще константа и любой ее предел будет exp(1).
Ну т.е. ситуация 0^0 это ситуация f(x) * g(x) где f(x) -> 0 а g(x) -> inf. А дальше все просто — какие функции выберете, такой результат и получите. Вот в 0 x быстрее едет к 0 чем ln(x) к -inf, поэтому x^x в нуле будет единицей. Возьмите вместо ^x степень, которая будет ехат к 0 медленнее чем ln(x) к бесконечности — получите предел exp(-inf) = 0. Делов-то.
Однако если есть какая-то функция, например x^x, то при подстановке нуля её значение не определено, но при этом у этой точки существует левый и правый пределы, и они оба равны единице. Но это не меняет того, что 0^0 это неопределённость.
inf/inf не то что неопределённость, а даже смысла не имеет, потому что в R нет такого элемента, как inf.Поэтому есть дополненный R
en.wikipedia.org/wiki/Extended_real_number_line
Но какова причина вводить 0^0 как неопределённость?Почитайте учебник высшей математики, или погуглите.
ru.wikipedia.org/wiki/%D0%9D%D0%BE%D0%BB%D1%8C_%D0%B2_%D0%BD%D1%83%D0%BB%D0%B5%D0%B2%D0%BE%D0%B9_%D1%81%D1%82%D0%B5%D0%BF%D0%B5%D0%BD%D0%B8
Вы не вводите 2^3 как неопределённость просто потому, что неопределённость и всё?Это же вполне конкретное число.
Чему равно 2 \infty?
Предлагаю вам всё-таки открыть учебник и прочитать его. Там есть ответ на этот вопрос.
signum тоже в нуле имеет неустранимый разрыв, что не мешает ей быть в нуле определённой.
Это вообще выдуманная на пустом месте функция, а выдумать можно что угодно и как угодно.
Операция взятия целой части (или дробной части) тоже имеет довольно много неустранимых разрывов.
Разрывы никак не связаны с тем, определена ли функция в конкретной точке или нет.
Ну и 0^0 — вполне конкретное число
Нет. Если вы не желаете учить высшую математику, то это не значит, что надо навязывать другим, своё мнение о 0^0.
Ничего запредельного там нет. За запредельное получают Филдса, а не зачёт по матану и линалу на младших курсах. Давайте всё же не девальвировать определения.
Что-то я смотрю в этом топике собралось много математиков :). Ладно, вы на мехмате МГУ учились? Сдавали матан по 4-х томному ротапринтерному изданию Л.И. Камынина (в Интернете нашел только первый типографский том, 430 стр., для первых двух семестров: fileskachat.com/getfile/27047_d05727eb8e4a7ae1f574f7fd501e2c21 ). Во втором типографском томе 620 страниц. Для многих вчерашних школьников это был «шок и трепет».
Замечу, что в ротапринтерном издании, по которому мы сдавали экзамены, текста практически не было, одни формулы. А конспектировать лектора Камынина было почти нереально. Он писал мелом на доске слишком быстро, понять ничего было невозможно. Иногда поворачивался к нам лицом и говорил: «Что? Не понимаете, что я пишу? Тогда переходите на факультет почвоведения!». Юморист!
А кроме него был еще семинарист А.И. Штерн. Сдать ему зачет с первой попытки было почти невозможно. Он начинал принимать зачеты за две недели до их официального начала и заканчивал через две недели после последнего экзамена, коих было по пять-шесть, по десять дней на каждый. Не получил зачет, не допускаешься к экзаменам. Экзамены переносятся на конец лета. Не успел пересдать до начала семестра, вылетаешь из универа. Сдать зачет формально было просто нельзя.
Начинал он с того, что каждому раздавал индивидуальные задачи. Решай их самостоятельно, дома, в общаге. Пользуйся, чем хочешь. Помощи от сокурсников можно было не ждать, ибо все были в похожем состоянии. Если решишь задачу за три дня, то ты почти гений. За неделю – хорошо. А некоторым и месяца не хватало.
Потом был очный зачет. С восьми утра до восьми вечера. Если уложишься, молодец! Тем, кто посещал все семинары и лекции (у нас было свободное посещение) и решал все домашние задачи, было значительно легче. А все задачи между семинарами решить было очень сложно. Не было тогда программ помощников, типа «Maple», да и компьютера были в зачаточном состоянии. Давал он всего лишь по 30 задач, среди которых встречались такие: lim((sin(tg(x)) – tg(sin(x)))/x^7), при x->0. Можно было, конечно, разделять задачи между одногруппниками, то технически это тоже было непросто.
При этом Штерн был очень дотошен в части доказательств. Доказывать ему надо было абсолютно безупречно. Его любимое хобби, искать ошибки в учебниках и монографиях. Скажем, в 22-м издании «Линейной алгебры» Куроша он нашел всего две (!) ошибки (не опечатки). Вот и попробуйте ему что-либо доказать «на пальцах». Некоторые ребята реально сходили с ума и их реально забирали в Кащенко.
Да были у нас уникумы, которые читали опусы Камынина, как художественную литературу. День-два почитали и как молодые горные козлики побежали к девочкам в гости или там играть в футбол. А ты, как дурак, сидишь над учебниками и конспектами десять дней подряд, по 12 часов, и усваиваешь только часть материала. А там, как повезет, счастливый билет или не очень. А нужно было еще не просто сдать экзамены, а сдать на стипендию.
Хорошо, вернемся к OpenCV. Вы там со всеми алгоритмами на «ты»? Библиотека огромная, реализованных алгоритмов – невероятное количество. Вот так просто берем и лихо их применяем? Я пробовал адаптировать готовые примеры для своих целей. Получалось плохо, пока не начал вникать в алгоритмы и не писать, для лучшего их освоения, собственные аналоги. Стало и проще и эффективнее.
У нас вылетали с мехмата за неуспеваемость призеры международных математических олимпиад и выпускники физмат-школы при МГУ, не считая поехавших умом. Т.е., трудно было реально и прежде всего в первых четырех семестрах и именно по матану Камынина / Штерна. Другие препы были по сравнению с ними на порядок легче. Но были и те, кто всю учебу воспринимал играючи, вундеркинды они и в Африке вундеркинды.
Физкультура ещё была. Из-за физкультуры я тоже чуть не вылетел, дважды.
Нас тоже серьезно гоняли, кстати, именно в университете я впервые встал на коньки и поехал, причем даже ни разу не упал.
Хорошо было на старших курсах, первая пара – бассейн. Спускаешься с 24-го этажа жилого крыла Главного Здания и на лифте, на минус третий этаж. А там настоящий бассейн, поплавал, сходил в местную столовую, на минус первом этаже, выпил двойную порцию двойного кофе (запах молотой арабики был слышен на многих этажах выше), взбодрился слегонца, все, можно идти на следующую пару, с надеждой не заснуть (про студенческую ночную жизнь не буду здесь говорить).
Когда я несколько лет назад занимался машинным обучением, у меня не было проблем с тем, чтобы взять произвольную статью с arxiv и зашарить, что там происходит. Математика в машинном обучении на самом деле довольно простая.
Я вот делаю сейчас распознавание встроенных субтитров в обучающих видео, с целью их перевода, а заодно и адаптирую внешний консольный опенсорсный плейер FFplay.c в свой проект (для удобной интерактивной работы с видео). Да, можно использовать готовые алгоритмы, но они, как правило, не всегда дают тот эффект, который ожидаешь. Начал кодировать свои собственные идеи. Пока нравится больше. А некоторые алгоритмические моменты обсуждал на сайте математиков: dxdy.ru/topic142232.html.
Хотите запредельное — возьмите Жирара и почитайте восьмую главу и дальше.
Чем-то похоже на формализм теории доказательств из математической логики. В математике легко найти и позапредельнее, никто спорить не будет. Но я лучше дам вам школьную задачку, на квадратные уравнения (которые мы проходили в пятом классе). Нужно найти ошибку в рассуждениях. Правда, содержимое будет из квантовой механики, но это для маскировки :).
Общее уравнение Шредингера (УрШ) можно рассматривать как квадратное уравнение относительно постоянной Планка h. Решаем его, получаем формально два корня. Но постоянная Планка то одна, поэтому либо дискриминант квадратного уравнения равен нулю, либо у постоянной Планка есть второе фундаментальное значение. Оба случая интересны. В первом варианте получаем из одного уравнения два, что упрощает решение и анализ УрШа. А, во втором, делаем научное «открытие», постоянная Планка имеет два разных значения. Ура, товарищи! Куда обращаться за Нобелевской Премией? :)
Преподаватель (если он хороший) укажет обучаемому, где нужно остановиться, поймёт, почему обучаемый полез не в те дебри и объяснит, почему пока туда соваться не нужно, а так же покажет более лёгкий путь.
Такого преподавателья, видимо, нужно искать на каких-то курсах, но курсы сегодня не очень качественные (именно по части преподавателей), поэтому здесь ждёт засада. Нужно перебирать, тратить время и деньги.
От себя могу добавить, что курсы с нуля готовятся и у нас, но пока недоступны. Но теоретически мы могли бы помочь друг другу путём тестирования материала «на кошках» (добровольцах). Если вдруг у кого-то появится интерес — пишите в личку.
Почему жы все нетехнари пытаются зайти в самые высококонкурентные сферы программирования. Сфера мобильной разработки и вообще Java — высококонкурентна. Обратить стоит лучше усилия на WEB разработку. Особенно на фронтенд. Знаю много гуманитариев преуспевших на фронтенде как таковом при большом желании. Математика там вообще не нужна. Профессия скажем react разработчика котируется везде и в России и в Европе и Америке. Но не нужно циклиться на книгах. Набирается минимум знаний из книг и люди устраиваются джуном в офис. Там учиться надо у опытных людей. Потом поменяв несколько работ, и поднявшись хотя бы до реального миддла, можно пытаться устраиваться зарубеж. Без реального опыта в офисе хорошим разработчикам не стать никак. У кого-то до крепкого миддла путь по офисам занимает год, у кого-то 5. Тут уж все зависит от желания учиться.
Там очень много некомпетентных разработчиков. Много просто знающих по верхам HTML и css. Среди java программистов или C# не найдешь тех, кто не знает паттерны разработки и работу с БД и сервером, во фронтенде сплошь и рядом. В фронтенде гораздо ниже порог входа в разработку. Но реально грамотных разработчиков во фронтенде знакомых со всеми тонкостями JS и построения правильных архитектур, глубокими знаниями js фреймворков днем с огнём не найдешь — они всегда при деле и имеют зарплаты не ниже всех остальных разработчиков в других языках с таким уровнем.
Если вы сможете найти любовь к чему-то, будь то комбинаторика, 3D-графика, ИИ, то двигайтесь в этом направлении.
Если желание именно разобраться — то снизу вверх, от теории к практике. Это долго.
Наоборот, если есть желание побыстрее войти в среду и работать в команде, то пробуйте сверху вниз, например, в случае с вебом, сначала поставьте и настройте wordpress.
Если это не ваша любовь, а ваша любовь только деньги — то увы, этот путь будет два вас намного сложнее. Имейте ввиду, вас может стошнить от задачек на вычисление факториала. Пусть вас подпитывает дисциплина. За год вполне реально стать джуном.
Мне кажется, по любой теме, книг в мире больше чем одна. И все же вы берете только ту, которую вам посоветовали. Она вам не подходит, потому что требует знания другого ЯП и не рассчитана для новичков. Ммм, что же делать? Может посмотреть другие книги по языку, пролистать их, сравнить подачу материала? Нет, лучше выучить другой ЯП. Бум!
Вообще такое бывает в реальном мире: ожидания с реальностью расходятся. Корректируйте план с учетом новой информации. Можно учить язык, делать приложения как получится и выделить время и доучивать мат. часть. Позже: смотреть свой код, переписывать или удалять и делать что-то новое.
Можно похоронить себя на несколько лет в теории и потихоньку выбираться «из тьмы гуманитарности на свет точных наук». Вот только, если вы чего-то не знаете или не умеете, найдется масса желающих тыкнуть вас носом. Если слушать каждого, учить все, что советуют и как советуют, может и 5 лет не хватить. Стоит обозначить для себя границы знаний и навыков, которых должно быть достаточно для первой работы по каким-то своим критериям и уже от этого нырять в теорию на нужную глубину, пилить какие-то программы. Потом на основе собеседований закрывать пробелы.
Мне нравится «луковичный» (или как-то так) подход к самообучению. Это когда вы сначала узнаете, например, что функция это законсервированный кусок кода, который можно вызвать в нужных местах. Со временем узнаете, что функции бывают разных видов, гуглите что такое арность и глубоко выдыхаете, узнаете больше вариантов использования.
На примитивное, но хорошо понятное лично вам определение наслаивается все больше информации, у вас формируется более глубокое понимание. При этом, если знание можно закрепить на практике, то лучше это сделать. Ну и дальше в таком духе по всем фронтам.
Непонятные в деталях вещи, вы помечаете, чтобы знать, куда вернуться позже. НО пытаетесь понять, на доступном сейчас уровне. Видите вы мат. формулу, а она для вас просто набор прикольных скобочек и знаков. Окей, привет гугл. Непомогло? В список на проработку. Необязательно понимать все и сразу. Но можно ведь понять, для чего эту формулу использовать, какие проблемы она может решить.
Вот смотрите: у вас есть готовая формула для решения задачи из учебника. Вы учитесь программировать. Вы не пробовали, просто ради интереса, написать программу, которая будет решать эту задачу за вас?
Разработка действительно не для всех. Нужно обладать очень важным качеством — умением думать, анализировать задачи, смотреть на них с разных уровней абстракций. К счастью, этому можно научиться.
P.S. Работодатели смотрят не только на уровней знаний CS, и не для всех это ключевой показатель. Уровень владения ЯП и экосистемой, на каких языках говорите, как вы общаетесь, сможете ли влиться в коллектив — все имеет значение. Не знаю, есть ли какой-то главный критерий, потому что знаком с людьми, которые толком не зная самого языка, минимально осваивали фреймворк и получали оффер. И росли до нормальных специалистов, — помогали коллеги и любознательность. Один знакомый, пошел тестировщиком, за год освоился, выучил язык и стал программистом в той же компании, но у него техническое образование и некоторый профильный бэкграунд. Бывает наоборот, человек приходит программистом, а в итоге занимает совсем другое место. К цели обычно ведет множество путей, и никто за вас не выберет тот, который лучше всего вам подходит.
Мой Вам совет, начните ваш путь с верстки сайтов и фронтенда.
Верстая сайты, вы сразу видите результат и вам не нужно сразу вникать в сложные вещи.
Если вы сможете верстать сайты то вы сможете понять как с помощью javascript проводить простейшие манипуляции с кодом страницы, которые невозможно/очень муторно делать без него. Если вы поймете это, ты вы уже точно будете знать, что такое переменная и функция, какие бывают типы данных, зачем нужны объекты и массивы и как ими манипулировать. И главное, Вы поймете зачем оно все нужно и почему без этого не обойтись.
Если вы знаете все это, значит вы уже понимаете программирование на базовом уровне.
И если вы будете все время практиковаться, пытаться реализовывать все новые фичи, вы точно придете к успеху. Читать книги, сайты, смотреть видюшки вам ничего не даст если вы не будете каждый день кодить. Проверено очень горьким опытом.
И вот на первом уроке по программированию я всегда говорю, что программирование — это в первую очередь математика. Если в голове нет математики, то никакого программирования не получится. Соответственно, если дитятко решило пойти в вуз по направлению программирования (а это я узнаю, потому что нужно сдавать ЕГЭ по информатике)Я правильно понял, что в качестве разработчика вы не работаете, и при этом судите о программировании основываясь на задачах из егэ?
Задачи в егэ не имеют никакого отношения к реальным программам на работе. В егэ наследование даже не рассматривается, зато задач по типу: Напиши функцию вычисляющую плошадь треугольника. Примерно половина.
ближайшие несколько лет векторами, матрицами и прочими тройными интегралами вперемешку с диффурами, ведь всё равно мозгов на матанализНе стоит путать полезную в программировании линейную алгебру, с довольно бесполезным матанализом.
Что касается матанализа, то да, согласен, эта штука нужна не каждый день, но чтобы получит диплом о высшем техническом образовании, с ним разминуться не получится.
Кстати, задача из текущего поста — задача, решенная через матан
Я правильно понял, что в качестве разработчика вы не работаете, и при этом судите о программировании основываясь на задачах из егэ?
он говорит, что ученики, выбравшие информатику на ЕГЭ без достаточного знания математики, ошибаются.
потому что в ВУЗе на тех специальностях, на которые можно поступить по результатам этого экзамена, будет много высшей математики.
Почему вы думаете, что ваша "вражда с математикой" не является "враждой со школьным/институтским преподавателем математики"?
Вы бы хоть постеснялись публично такие вещи говорить. Потому что вам скорее всего с окружением в детстве повезло, в генетической лотерее выиграли и поэтому получилось наверстать необходимые навыки мышления другими способами.
Но широкая публика ведь видит только верхушку айсберга и будет думать что математика действительно не нужна. Потом индивидуумы из широкой публики пытаются осилить программирование и у них закономерно возникают проблемы. И приходится им наверстывать навыки мышления применительно к программированию, хотя можно было бы проще и раньше.
Пока по статье мы видим, что проблема возникла у индивидуума, считающего, что математика нужна. Ещё мы видим ряд комплексов ему сочувствующих. Например, один считает, что его частный взгляд на вопрос даёт ему право влиять на чужие судьбы, указывая, каким путём им НЕ следует идти (я бы постеснялся вот этого); другой стесняется возможности озвучивать свои взгляды и ждёт того же от окружающих.
Я сочувствую, что у вас такие обстоятельства.
Но в свете них ваш посыл еще более вреден. У вас — типичная ошибка выжившего. На одного такого как вы приходятся миллионы людей, которые так и останутся в своем окружении алкоголиков.
Вы хотите чтобы все вокруг превозмогали так же как и вы когда-то?
Касательно вашей проекции негативных коннотаций. Я не считаю, что я как-то по особенному что-то превозмогал или был в особенных (на тот момент) обстоятельствах. Я просто шёл своим путём, и так как другого у меня не было, не могу сказать, что он лучше или хуже. Но я определённо могу сказать окружающим, что пройти им возможно, и думаю, что эта позиция в целом более конструктивна и позитивна, и уж точно нет причин стесняться её.
Помню телепередачу в 90-е годы, где родители возмущались тем, что обучают математике… финансистов! Можете представить себе финансиста, который не знает сколько будет 2+2?
А автор статьи человек взрослый. И ему все это программирование не очень интересно. Ему нужны деньги и только.
Приветствую. Мне интересно узнать как Вы пришли к такому умозаключению. Если бы программирование было не интересно я бы наверное даже не пытался выучить программирование. Разве не так?
Деньги имеют весомый аргумент в жизни каждого конечно. Но по моим личным убеждениям, финансы — это не сама цель, к которой нужно стремиться, а результат определенной деятельности человека.
Стремление «свалить» на запад, если Вы это имеете ввиду, связано с финансами отчасти, и меньшей части. Очень много других факторов и преимуществ. Но, думаю, Вы и так прекрасно об этом знаете…
По поводу обучения. Если Вам всё-таки это нужно, а самостоятельно не получается, возьмите репетитора или учителя. Порог вхождения — это максимум месяц, потом сможете самостоятельно.
Когда я уезжал, в 91, программирование было совсем не в тренде, за него платили копейки. У уехал я из-за антисемитизма, а не за колбасой. Это потом ближе к 2000 внезапно стали платить.не могу сказать, что я сильно сопротивлялся
И да по фигу какой язык. Потом у программиста занимает неделю, чтобы начать писать на новом для него языке.
Ну а потом можно потратить время на детали, стиль и тд.
Хоть всю жизнь на совершенствование.
Вот откуда берётся подобный максимализм?Преподаватели делятся на 2 типа: первые считают, что их предмет самый важный, а вторые — что единственный.
Ну а я преподаю в университете. И сделал вывод, что познания в математике вообще никак не коррелируют со способностями писать код. Да, есть корреляция между математическими способностями и способностями придумывать и реализовывать алгоритмы. Но и без математики вполне себе можно быть высокооплачиваемым формошлёпом.
Особенность таких людей, что их больше уважают и ценят и при прочих равных условиях им зачем-то дают лишние преференции
Но и без математики вполне себе можно быть высокооплачиваемым формошлёпом.
и не обязательно формошлепом
Математика хороша тем что там очень нужно сильноразвитое абстрактное мышления и логика и в программировании нужно тоже самое
Тоесть если ты тянешь математику — в программировании будет легко, НО эти вещи не взаимосвязаны.
Тоесть если взять хорошего программиста — то из него можно сделать хорошего математика (если он в процессе со скуки не помрет)
Интересы решают. Если человек умеет и в математику, и в программирование, то он в итоге сваливается в то, чем ему нравится заниматься больше: становится либо крутым математиком, либо крутым программистом.

Стоит ли говорить о том, какое влияние этот язык оказал на развитие области в целом? И ему (автору) не мешало при этом отсутствие особых знаний в математике. Более того, для него даже переменные и функции — это «существительные» и «глаголы», «подлежащие» и «сказуемые», и так далее.
Ну perl язык с точки зрения прода — так себе, больше похож на эзотерический язык — чего только стоят программы из одной строки.
Я лишь приведу один простой пример из реальной жизни: есть такой очень известный язык программирования Perl. Так вот, его создатель, Ларри Уолл, является лингвистом по образованию
lol
То, что вы никогда не слышали про математическую лингвистику, не значит, что лингвисту «не нужна математика»!
KvanTTT
perl язык с точки зрения прода — так себе, больше похож на эзотерический язык — чего только стоят программы из одной строки
KvanTTT, напомнило ифкуиль:
короткая фраза у́кшшоул э́йхнуф приблизительно переводится как «Что-то заставило группу бегущих клоунов начинать спотыкаться» или «Группа клоунов начинает спотыкаться на бегу». Этот смысл составляется так:
Группа клоунов («клоун» по-ифкуильски — кшуль) рассматривается как совокупность более-менее равных членов, без имеющих значения различий. (То есть, они все клоуны, и если даже играют разные роли и делают разные трюки, в высказывании этому не придаётся значения)
Клоуны в группе объединены общей контекстной задачей, то есть едины в своём беге общей целью.
Повествование идёт об определённой группе клоунов, целиком и в одном определённом месте, а не, допустим, как часть какой-то большей группы или о всех группах клоунов вообще.
Клоуны начинают запинаться (э́йхнуф) по какой-то внешней, от них не зависящей, причине, и рассматриваются как испытывающие какое-то внешнее воздействие, заставившее их совершать действие.
Слово со смыслом «начинать спотыкаться» здесь составлено из корня слова хуф, означающего «шаг в беге», и добавлением к нему уточняющих аффиксов, которые означают:
Что множество совершаемых клоунами беговых шагов рассматривается как одно устремлённое действие, то есть именно как бег. Это обозначено изменением первой согласной буквы корня: х → хн.
Беспорядочность и разрозненность шагов этого действия. Что, логично, означает, что бег этот спотыкающийся.
Что предыдущий смысл (беспорядочность, разрозненность) имеет постепенно появляющееся распространение в пространстве/времени, то есть, беспорядочность в беге начинается. Это сочетание обозначено приставкой эй-.
Также в этих словах точно определено, что смысл фразы прямой (а не переносный, образный), отсутствуют какие-либо подразумевающиеся выводы из этой фразы (то есть, намерение предложения — простое повествование, а не намёк или пример какого-то более общего заявления), и что значение имеет всё событие целиком, а не какая-то его часть, то есть смыслового ударения нет.
А основа кшуль («клоун») не является изначальным корнем, но происходит от корня кш-ль, имеющего значение «дурак» и «лох; смешной/нелепый человек» путём добавления смысла формальности и постоянства, что означает «человек, ведущий себя как смешной дурак по профессии», стало быть клоун или скоморох.
А может быть, это просто такая скрытая форма увиливания от конечной цели? И вы не хотите перезжать / выходить из зоны комфорта? Увиливаете с помощью синдрома отвлечённого внимания + прокрастинации.
… я как «хомяк в колесе», вроде как бы и бегу (учусь), а по факту стою на месте.К сожалению столкнулся с точно такой-же ситуацией=( Было интересно изучить Kotlin не имея за спиной ничего связанного с dev. Но все свелось к тому, что помимо изучения синтаксиса, в котелке должен быть определенный бэкгрануд, на изучение которого уйдет ещё больше времени, чем на изучение конкретного языка.
Уважаемый автор, я жду от Вас вторую статью, в которой (я надеюсь), Вы всё-таки найдете ответ на вопросы:
Или все-таки это не моё? И профессия «разработчик» — это для элиты, «касты особенных людей»?
Автор себя загрузил чисто психологически. Постараюсь подсказать решение. Учился в школе 8 классов, потом в училище 3 года. Но потом решил поступить в политех и так как надо было сдавать вступительные экзамены — то выяснилось, что у меня немаленький такой провал в знаниях за последние 5 лет учебы. С осени родители заплатили за заочные подготовительные курсы, там мне дали материалы и задачи, которые я должен освоить и научиться решать, чтобы успешно сдать экзамены. Но до нового года я еще ходил на учебу в училище, после была практика. Так как работать по профессии я не хотел(передумал), то решил приложить все усилия, чтобы поступить в политех. Для этого решил прогулять двухмесячную практику(но без последствий) и вместо неё каждый день самостоятельно по 5-6 часов учился. Учился следующим методом — взял толковые учебники и вначале полностью прочитывал одну тему по которой были задачи из подготовительных курсов, потом решал эти задачи, а формулы и основные понятия и способы решения записывал на отдельных листочках А4. Таким способом за 2 месяца я освоил материал за последние 5 обучения, успешно здал экзамены — более 80 баллов(82 и 84) из 100 и успешно поступил в политех на бесплатное обучение да ещё и со стипендией. Так что тут есть два урока: 1 в общеобразовательных заведениях все обучение очень разтянуто во времени и освоить эту информацию можно за короткое время; 2 — если не отчаиваться, то при определенном усердии можно освоить даже очень большой объем информации за разумное время.
Но для начала такого обучения я бы посоветовал прочитать книгу "Думай как математик" Барабары Оакли, там есть все необходимые психологические моменты и подходы для успешного даже очень сложных наук и решения задач любого уровня сложности и глубины. Ну чтобы было интересно при обучении, то придумайте и создайте небольшое приложение или сайт в той области где хотели бы работать, первый блин может получится комом, но заметите что чем дальше — тем все лучше и быстрее у вас будет получаться. Это я к тому, что обучение без практического применения — это как научиться водить без машины. И тут на хабре есть много толковых планов по обучению например. Так что все в ваших руках!
P.S. и было хорошо после того как вам тут дадут много советов в комментариях, узнать ваши выводы в конце статьи. Успехов!
Собственно, для автора поста: Программист — не технарь, программист — гуманитарий, т.к. по сути он — переводчик.
Переводчик – это специалист, который умеет не просто перевести, но и интерпретировать речь или текст с одного языка на другой.
И задача программиста: перевести озвученные потребности
0. Дался английский — дастся и программирование (по-сути псевдо-английский);
1. Учить тот язык, который соответствует задачам, что планируется/хочется решать. Не нужно учить 'латынь и древнегреческий' (фортраны-паскали и прочее) если планируется 'говорить' с IOSом;
2. Не нужно учить математику сверх уже имеющихся школьных знаний==базовой теории, достаточных для того, чтобы понять разницу в Big O Complexity. Т.е. не нужна ученая степень, но нужно понимать такие вещи, как логика, проценты, матрицы и геометрия. И до тех пор пока не появится задача, требующая этого навыка (возможно она не появится вовсе; возможно выбрать сферу, в которой она не понадобится, раз с ней такие 'сложности'), математика — это факультатив. Просто, когда-нибудь позже (и, довольно-таки, скоро), с профессиональным ростом, само появится желание с ней познакомиться — и это будет в удовольствие, а не в напряг, но на данном этапе — это как утверждать, что у тебя не получится говорить на иностранном — если ты не знаешь как сказать о цифрах/числах (думаю тут уже и становится понятно, насколько 'классно' без цифр/чисел можно говорить на любом языке). Пока же от 'К.О.Д.' Петцольда пользы больше будет;
3. Нужно осознать, что придётся 'перевести-на-компьютерный' понятия из человеческого мира (они же существительные: экран, кнопка, кошелёк, сумма, платёж), и действия над ними (они же глаголы), сходи туда-то, возьми то-то, сделай с этим что-то, и отдай это. По-сути сводится к 'бутылочному горлышку' в виде CRUD + UIные пляски а-ля анимируй вот это (если фронтенд). Ничего сложного, главное осознать сам факт/парадигму — ты просто объясняешь, с чем и что ты хочешь сделать. И в итоге по-любишь компьютеры больше людей — они однозначно трактуют и точно делают, для аутичного мизантропа меня — просто рай, кстати;
4. Прямая дорога на Udemy (например) -> покупается курс часов на 10-20(для начала), по интересующей технологии -> в один монитор учебное видео + во второй IDE -> ручками делаешь всё от и до -> PROFIT. Цена вопроса в дни скидок, что раз в месяц стабильно, ~ 800 руб. Очень не рекомендую (внимание: крайне субъективное мнение!) русскоязычные курсы на русских платформах, ибо дорого+устаревше+в-отрыве-от-реальных-задач == лютый треш. Лучше добивать английский, раз уже есть база и в планах релокация.
5. Параллельно (в целях экономии времени и вообще) изучать любую доступную информацию в любом виде (короткими кусками, статьями и 15-45минутными видео, не книгами по 2 тыс стр) о best practice в проектировании и архитектуре ПО — очень недооценнёное, редкоупоминаемое (до позиции senior) для новичка знание, которому нужно просвещаться факультативно, после основных задача, но вот прям сразу начинать, да. Нужно учится мыслить проектно/архитектурно — всё остальное пыль, прах и тлен, если этому не начать учиться уже с позиции нуба. Проясняющая аналогия: ты знаешь кучу иностранных слова и не можешь связать их в осмысленный текст, или же ты знаешь как строится речь, и если что в гугл-переводчике слово подглядишь. (Так делают все);
6. Программирование — это кайф, в нём нет никаких напрягов — в нём есть удовольствие(даже когда сложно). Компьютер — твой верный партнёр, а не 'непонятный враг', он надёжен, исполнителен, быстр, не устаёт. Не нужно его бояться, или пытаться 'по-бороть', прост, нужно заговорить с ним — на его языке, всио. (Сложнее заказчика понять).
Собственно, для автора поста: Программист — не технарь, программист — гуманитарий, т.к. по сути он — переводчик
Архитектор домов — тоже гуманитарий, переводящий с языка заказчиков на язык прораба и строителей? :)
В строительстве есть еще проектировщики разных разделов, которые как раз и выступают "переводчиками" между архитектором-гуманитарием и строителями. И в IT то же самое — кто-то визуализирует желание заказчика в архитектуру, а потом кто-то рубит код разной степени "технарности". Даже если это один и тот же человек, это разные роли. Автор комментария выше, похоже, этого нюанса не учел.
— Бывает гусеница, а зайка? Червячок, а верблюд?
— Юра, ну что ты какие спрашиваешь глупости!
Сейчас же — «глупости». И сейчас же предположение, что ребёнок болтает зря, только чтобы болтать. Юра краснеет.
— А как же бывает жук-олень, жук-носорог?(с)
Речь велась об абстракции в программировании.
А получилось все приблизительно так же (на данный момент никуда не сдвинулся).
— выбирал игровой движок исходя из размера комьюинити и роялитил на будущее.
— под движо выбрал язык программирования, мне нужны были хотя бы азы чтобы понимать ролики на ютубе, выбор был C#
— в итоге оплатил курсы на itvdn и прошел все что было по C#, через несколько месяцев получил C#full stack сертификат (2015 год), хотя по сути ни строчки кодга я не написал для себя.
— так же осонзнал две вещи, на русском очень мало материала и так же что я забыл (или не знал) алгебру. На тот момент подумал что хорошо бы знать все о векторах и кватернионах.
— пошел учить английский и читать математику начиная с 5 класса.
— пошли книги по управлению проектами вроде «Мифического человека месяца» и саморазвитию.
…
— много всякого другого интересного от
…
— сейчас вот купил и развернул дома на виртуалках confluence+jira+bitbucket и пытаюсь сдружить авторизацию через nginx. По отдельности на субдоменах работают, а вот подружить — уже надо покапатсья в nginx поглубже и понять.
Что хочу сказать. Это все интересно. Если вам не интересно узнавать и изучать что-то новое будет тяжело. Ведь языки и другие инструменты разработки постоянно меняются и они повышают уровень абстракциии, да и знать надо языки а не язык, ведь это просто инструмент который в одной ситуации вам подойдет, а в другой нет.
Решать проблемы надо по мере их поступления, а не пытаться быть готовым к ним заранее.
Вы же не готовитесь к жизни, вы живете как есть имея какие то базовые навыки и что то узнаете только по мере необходимости.
Пытаться узнать «что там под капотом» и уметь в это… это такая же болезнь как и «Синдром самозванца». Вы правда думаете, что большинство изучает все настолько? Вспомните школьников и чуть старше, они просто используют язык как конструктор. Остальное если понадобиться, то уже позже, на этапе оптимизации если до нее дойдет.
А сейчас и вы, и я и многие другие — как дети, которым дали кубики и они вместо того чтобы начать из них что-то строить, лезут в сопромат.
А ведь чем дольше ты к этому идешь, тем сложнее продолжать и не сдаваться. Только сейчас, пощупав всего понемногу, мой пазл начинает защелкиваться и все те разрозненные куски информации накапливающиеся все то время, складываются в общую картину.
Думаю для людей с таким мышлением два, или три пути. Первый — самостоятельный, долгий и мучительный. Второй — год-два с ментором (но где ж его взять когда тебе 35 — 40 лет, кому ты нужен?), третий — тебе повезло и тебя взяли в компанию по знакомству и там ты всему научился (я лично знаю такого человека). Но везет не всем)))
Из практических советов, которые мне помогли, могу порекомендовать следующее:
1. Если что-то не понятно сейчас, все равно делай! Смотри курсы и повторяй (пиши код) за ведущим. Если это книга, повторяй за автором. Просто смотреть или читать, пользы мало. Даже если не до конца понимаешь почему оно работает, ты получаешь долю удовлетворения от самого факта, что у тебя что-то получилось. Это дает тебе энергию двигаться дальше.
2. Пробуй какие-то библиотеки еще ДО того как ты пришел к выводу что ты гуру в этом языке программирования. Например если ты изучаешь JS, сразу тыкай Jquery. Если CSS, сразу юзай Bootstrap. Моей ошибкой было то, что мне казалось что подобные вещи мне не освоить так как я еще не на достаточном уровне владею языком. А все как раз наоборот, эти библиотеки как раз и созданы для того чтобы облегчить решение задач.
3. ООП — его я по настоящему понял когда прочувствовал как работает MVC. Так сложилось что я после попыток с JS и PHP взялся за Ruby on rails. Вообще с фреймворками для начинающих беда — куча каких-то файлов разложенных по такой же куче папок. Повторял, повторял за туториалами, и бах — картина мира сложилась. И все стало ясно как день. А как только что-то защелкнулось, ВСЁ!!!, меня уже не остановить! На этот стержень начинают прилипать те обрывки которые я все эти годы копил.
И самый главное — не бросай!
Как мне кажется все, что нужно это знать что тебе нужно.
Хорошо когда есть ментор и скажет что учить, у меня такого не было и много времени пошло на то что бы учить кучу мусора который уже и забыл.
Начал я по нимногу входить в ИТ. совмещая с основной роботой в торговли. за года 2 я гдето был на половине пути. И только потом поднажав за пол года выучил все что надо. Реально если заменить 8 часов работы на обучение то за пол года это под силу. Скажу так — Математика если тут нужна, то не сразу… мне пока не нужна ваще. А к тому времени когда тебе придется решать такие вопросы то понимание того как сделать придет само. И второе — наверное, не надо так сильно лезть под капот, зачем для джависта знать С, я понимаю что JVM на нем и т.д. но 90% людей это уже разбирают будучи Синьорами. так что напишу еще раз «нужно знать что тебе нужно» и ничего больше. Когда столкнешься с задачей где нужна математика, ты ее сделаешь без особого труда, ведь если ты выучил и поместил в голове столько информации для освоения языка. то это всего лишь очередная фича в твоем задании.
Мне кажется, что все это — наоборот, хороший знак. То, что вы решили докопаться до основ, а не фигачить формочки в продакшон, как некоторые любят. Да, это не простой путь, да, он займет больше времени, но, мне кажется, вы осилите. Главное — найти мотивацию, т.е. не просто молотить книги, но и закреплять практическими задачами. Мне кажется, я знаю алгебру 10-11 класса только потому, что она помогала мне тогда постигать программирование, а не наоборот.

У меня нет опыта преподавания кому-то программирования в целом, но я бы предположил, что стоит пойти по такому пути. Понятно, что одним комментарием вряд ли можно всему научить, но тем не менее, попробую дать направляющие.
- Начать с алгоритмов на базовом уровне, как последовательность инструкций кому-то («зайди в магазин», «возьми с полки пачку конфет», «оплати на кассе»), заодно освоив такие вещи, как ветвления («если закончилась еда, то сходи в магазин») и циклы («отожмись от пола 10 раз», «занимайся каждый день, пока не сдашь экзамен» и так далее).
- Взять простейший язык программирования, как уже советовали ранее. Пускай даже BASIC или Паскаль. И начать формулировать на нем простейшие алгоритмы. Например: «1) считать число с клавиатуры; 2) если это число меньше 18, то написать на экране «Несовершеннолетний», иначе написать «Совершеннолетний»». И так далее. Постепенно усложняя алгоритмы, добавляя больше ветвлений и циклов.
- Прийти к пониманию необходимости вынесения повторяющихся действий в отдельные места в коде (процедуры / функции). В примере выше «сходи в магазин» может быть отдельной процедурой.
Если закончилась еда, то <сходить в магазин>.
Процедура <сходить в магазин>:
Дойти до магазина.
Купить нужные продукты.
Вернуться домой.
Попутно поняв, что эти процедуры можно сделать гибкими за счет параметров. Например процедуру «сходить в магазин» можно снабдить параметрами, говорящими, что именно надо купить в магазине. Сама процедура по сути остается та же, но она каждый раз позволит покупать разные продукты. А в качестве практики, реализовывать подобные на языке программирования, где в качестве инструкций уже будут инструкции именно для компьютера: прочитать ввод пользователя, проанализировать его, прочитать или записать что-то в/из файла, и так далее.
- Ознакомиться с простейшими типами данных и понять разницу между ними: числа, строки, boolean (да/нет) и так далее. Ознакомиться с составными типами данных, например массивы: массив чисел, массив строк, и так далее. Например, может быть массив чисел, содержащий все оценки ребенка по математике за последний месяц: [5,4,4,5,3,5,5,5,4]. И в качестве практики, можно попробовать высчитать при помощи ЯП средний балл за этот месяц.
- Постепенно можно прийти к понимаю ООП. Например, есть общий тип данных (класс) «Школьник», и есть конкретные «воплощения» этого класса (объекты): «Вася», «Петя», «Вова». Класс «Школьник» может содержать метод (процедуру) «Нарисовать рисунок», но каждый конкретный школьник может его реализовывать по-своему. Условно, учитель дает всем «Школьникам» задание «Нарисовать рисунок», вызвав соответствующий метод у каждого конкретного ученика («Вася.Нарисовать_рисунок», «Петя.Нарисовать_рисунок» и так далее), но каждый ученик сделает рисунок по-своему. Учитель взаимодействует с учениками, как со «Школьниками» (объектами класса «Школьник») не зная об их специфических особенностях. Соотв-но, все эти действия можно перевести и в компьютерную плоскость.
- Ну и практика, практика, практика. Постоянно усложняя себе задачи, а также пробуя себя в различных «средах» (графика/игры, веб, десктопные или мобильные приложения, и так далее) и постепенно их осваивая, изучая имеющиеся в современном мире инструментарии для реализации тех или иных задач, и «набивая шишки».
Важно также понимать, что конкретный ЯП не важен. Важно понять суть происходящего, а конкретный ЯП уже будет просто синтаксисом, позволяющим сформулировать те или иные вещи компьютеру.
Вероятно авторы прелагают решить её массированным подбором.
А вообще лучше пытаться опердени какие-то программировать.
А скажите, только у меня, гуманитария(*), вопрос, откуда вообще взялась задача про скотный двор? Программист ее решит, вообще не имея представления о математике. А потом еще и оптимизирует это. И в этом весь смысл — программистское решение задачи даст на порядок больше знаний и навыков, чем математическое.
Очень печально, что автор поста не понимает, что тут главное:
предполагает определенное знакомство с основными понятиями программирования такими как переменные, операторы присваивания, циклы, функции
И если вот этого "определенного знакомства" нет, то суши весла. Ну в самом деле же!
(*) de jure у меня есть свидетельство среднего образования "лаборанта-программиста", но де-факто и по диплому я гуманитарий.
Если даже простые вещи не получаются, то смысла продолжать пытаться в разработку нет совершенно, потому что всё равно будешь вечно догоняющим.
Нужно заниматься тем что получается лучше чем у других, тогда в этом достигнешь успеха. А программирование можно оставить как хобби, саморазвитие и т.п.
1) Прочел книгу
«Чарльз Петцольд, Код. Тайный язык информатики», стало все ясно и понятно
2) Изучил основы программирования за месяц (циклы, массивы, и тд)
2.1) Углубился в основы языка (прототипы, замыкания, колбэки, промисы, ...) — еще месяц
3) Взял готовые качественные курсы по созданию проектов на React Redux, а не решалок всяких задачек как на известном всем *екслете (с проектами там все норм, но без них — топтание на месте) — плюс еще 2-3 месяца.
4) Профит! Сразу можно в бой на проекты, но придется поднапрячься для поиска вакансий. Но это уже другая история
На мой взгляд неправильно говорить, что вы изучили основы программирования "за месяц", если до этого год "теряли" на сценарий автора статьи.
Потому что обучение у вас происходило в тот год, о котором вы в своем комментарии решили много не рассказывать.
Профит пришел именно тогда когда я узнал, что нужна боевая модель обучения СРАЗУ на проектах (конечно изучив основы предварительно, 1-2 месяца максимум). И только тогда я смог реально реализоваться в своих проектах, и интерес к программированию сразу стал как минимум х5.
Решая мелкие бесконечные задачки я не понимал для чего они мне, это можно было делать и в свободное время от проектов, а не тратить все свое время
нужна боевая модель обучения СРАЗУ на проектах (конечно изучив основы предварительно, 1-2 месяца максимум)
Я все еще сомневаюсь в таком подходе. Потому что если человек не потратил год вечеров на изучение тех самых основ языка, то при получении ТЗ на проект будет просто ступор: "Что тут вообще делать?".
Я согласен, что для человека важна мотивация к изучению, но это не обязательно должно быть изготовление чего-нибудь полезного и применимого. Многим достаточно ощущения прогресса и одобрение со стороны преподавателя.
Заметьте, у вас все таки сначала был год разбирательства с основами, а уже потом — месяц того, что вы называете "изучением js". Поэтому ваш пример не совсем подходит для доказательства того, что подход "сразу боевой проект" — удачная идея.
Чтобы наглядно показать что этот подход работает, нужно взять человека который действительно раньше никак не изучал программирование и дать ему боевой проект.
По моим наблюдениям, "основы за месяц" получается только у тех, кто уже раньше изучал программирование, пусть даже в школе и на другом языке.
--Очень хочу стать первоклассным хирургом, читал что они много получают денег, уважаемые люди, могут работать в любых странах и про них пишут статьи. Я уже купил самый дорогой скальпель и изрезал всю кожаную мебель в доме, почти добрался до домашних животных, но они убегают от меня. Скажите что ещё необходимо сделать, ведь я так хочу стать хирургом и приносить пользу обществу??
Как по мне, если в таком длинном пути ты запутался, то надо трезво взвесить на что ты способен и не пытаться объять необъятное.
Вот тут в начале карантина статью накатал:
habr.com/ru/post/497158
Как я учил — в поисковике вбиваешь «уроки по Java с задачами». Пропадаешь в них на пол года. Через пол года начинаешь писать тестовый проект, попутно изучая уроки с других ресурсов и КАЖДЫЙ ДЕНЬ РЕШАЕШЬ ЗАДАЧИ. Всё. В статье подробно всё расписано для плюсов, но думаю суть поймешь — часы практики каждый будний день.
Это неправильный подход, тебе нужен skill суметь вычленять только то что тебе нужно. Я называю это «хитрость студента». Студент, в запаре за ночь до сдачи решает поставленную задачу ad-hoc, всеми доступными методами.
Двигайся как трактор, который прокладывает путь себе сам, своими гусеницами. Всех наук и всю математику наперед ты все равно не изучишь.
На ошибку тебя также подтолкнуло излишнее доверие. Не всякая книга хороша. Книга по CS судя по задаче странная книга, мне сложно увидеть в этой задаче прямое отношение к программированию и информатике. С тем же успехом ты можешь взять любой математический задачник для ВУЗ'ов и заняться решением его задач. Задачи ты решать научишься. Но вот научишься ли решать программные задачи? Большой вопрос.
Научишься ли строить приложения, собирать проекты, работать в системах управления версиями, коммуницировать с командой? Поэтому представляется что данный путь повел тебя в никуда.
Далее, в неверном направлении тебя подтолкнул математик. Нет чтобы детально пошагово решить задачу объясняя каждый шаг. Ну да, это бы отняло на 5 минут больше. Нет чтобы открыть книжки и все-таки детально написать тебе какой раздел какого учебника почитать, это же целых еще 5 минут! Зато это сэкономило бы тебе дни.
Мораль — молчание зло. Умей выбить из людей то что тебе нужно. (Скилл коммуникации)
Программирование это кроме собственно програмимирования, стык совсем других вещей — и инженерии, и хитрости и смекалки. Здесь на хабре была неплохая статья про 4 типа программистов. Подумай, а надо ли тебе пытаться стать rock star?
Полезно также уметь максимально эффективно искать помощь, — как пример зарегистрироваться на math.stackexchange.com и задать все вопросы. Или как самую первую «помощь» тупо-прагматично вбивать свои вопросы в поисковые энжины — в Google, Yandex, groups.google.com итд. Тот же 0^0 — попробуй, это сразу же выдаст страницу Wikipedia.
Прочти книгу
«Программист-прагматик. Путь от подмастерья к мастеру»
выражение типа N=N+1 и более сложные уравнения
Рекомендую ознакомиться с системой команд простого учебного компьютера Little Man Computer. Online симулятор этого компьютера здесь.
А вот моя статья.
в 90-х годах, когда был выбор из 2-3 языков
Ну все же даже в 80-х было чуть побольше — Алгол, Бейсик, Фокал, Рапира, Паскаль, Фортран, Кобол, да тот же C.
LOGO, в конце концов (уроки по которому в «Пионерской правде» публиковались).
Причём разные бейсики были несколько различавшиеся в иногда существенных деталях — где-то присваивание было просто "=", где-то нужен был оператор LET; где-то была возможна только один оператор на строку, а где-то можно было несколько впихать, через разделитель — и т.д, и т.п.
А без понимания, какой язык будет актуальнее — легко можно было схватиться в библиотеке за книжку по PL/1 (что я и сделал как-то), APL, Аде или Модуле с Обероном.
Пролог и Форт тоже тогда уже были.
В 90-х пошло еще расширение — появились Хаскел, Питон, Java, JS, Perl, PHP, Visual Basic (в котором от старого бейсика осталось не так много) и т.п.
Я когда работать после вуза устроился (в самом конце 90-х), «производственным стандартом» оказался вообще FoxPro. Да-да, и для расчетных задач (из-за чего расчеты дико затягивались).
С другой стороны, всякая устаревшая экзотика «ушла в архив», настала эпоха персоналок и актуальность языков уже ощущалась на практике — в отличие от 80-х, когда всё было в основном теоретически по книжкам (ну разве что в классе информатики можно было пощупать что-то типа БК/Агата/Микроши и попробовать свои программки на бейсике или фокале).
Но в целом, разнообразие было немаленькое. Другое дело, что информация даже о самом существовании многих языков не так была доступна, как сейчас. Что было на слуху в ближайшем окружении — то и учили.
Во-вторых, см. сюда: www.ncbi.nlm.nih.gov/pmc/articles/PMC2577970 — «LISP Interpreters for MS-DOS-Based Microcomputers». А МС-ДОС компьютеры в 80-х работали с «640 К хватит для всех».
Например, был PC-LISP.
И кстати, интересно было б глянуть на машину с гигабайтами ОЗУ в 80-х.
интересно было б глянуть на машину с гигабайтами ОЗУ в 80-х

en.wikipedia.org/wiki/Symbolics
The Ivory 390k transistor VLSI implementation designed in Symbolics Common Lisp using NS, a custom Symbolics Hardware Design Language (HDL), addressed a 40-bit word (8 bits tag, 32 bits data/address). Since it only addressed full words and not bytes or half-words, this allowed addressing of 4 Gigawords (GW) or 16 gigabytes (GB) of memory
Современные 64-разрядные процессоры в персоналках теоретически могут адресовать 16 эксабайт. Ну хорошо, учитывая, что физическая шина максимум 48 разрядов, 256 ТБ. Это же не означает, что в машины реально столько ставится. Даже отбросив в сторону финансовый вопрос — пока что объем модулей подобрался только к единицам ТБ, а количество слотов редко бывет больше 8.
Автор утверждает что у него есть сертификаты Microsoft (и не один).
Это как минимум означает, что человек умеет работать с информацией (в том числе разбирается, где нужное — а где лишнее),
и умеет искать информацию.
Он говорит что «прочитав гору статей и просмотрев кучу видео «Как стать Java программистом»», он не смог разобраться более продвинутой книге
«Философия Java», мол, она не для новичков.
Парадокс в том, что после усвоения «горы статей» и «кучи видео», (и, разумеется практики, не зря же он себе IDE поставил), он перестал бы быть новичком.
Если конечно, голова на плечах есть, а она есть, если у него есть сертификаты MCP, MCSA и VCP.
Так что что-то не сходится.
Потому что Java не нужна. Учи Flutter.
Но теперь вернемся с небес на землю. Даже если вы на отлично закончите профильный вуз, то всё равно большинство формул вы вскоре забудете, но у вас сохранится качественное понимание сути вещей и процессов, а также не будет пугать терминология. Это и есть самое главное — понимание сути, дающее понимание где и что надо искать. Тогда вы просто откроете справочник и найдете нужную вам формулу. Главное — знать, что искать.
Поэтому, я бы ограничился поиском учебных материалов, дающих «на пальцах» понимание математических, физических, статистических и прочих сущностей. Например, что такое интеграл? Я это легко объяснил своему 11-летнему сыну. Мы рассмотрели ситуацию, когда он пробегает 10 секунд с изменяющейся скоростью в процессе бега. Я нарисовал график зависимости скорости от времени и заштриховал область под кривой линией скорости. Всё! Площадь заштрихованного участка и есть определенный интеграл, а он в свою очередь есть преодоленное расстояние. Также рассмотрел с ним вопрос, как без формул примерно посчитать эту площадь, разбив участок под кривой на прямоугольные столбики и просуммировав их площади. Вот этого понимания более чем достаточно. То же самое и с производной. В прикладной плоскости она отображает скорость изменения процесса в определенный момент времени.
Еще случайно увидел в книжном магазине и купил ребенку книжку «Статистика в котиках» (или как-то так). Там прям на пальцах, доступным для детей языком, в картинках с котиками объясняются основные статистические понятия. В принципе этого уже достаточно для понимания основ статистики. И т.д.
В итоге, если вы будете понимать суть, то будете знать… например, какую библиотеку питона, какой алгоритм кластеризации оптимальней всего применить для вашего набора данных… Конкретные формулы вам знать не надо, всё за вас сделают питоновские модули.
Так что процесс обучения можно сильно упростить и, главное, сделать его интересным.
Третье… Всё вышеуказанное нужно лишь для того, чтобы обеспечить себе и своим проектам конкурентные преимущества. Однако, в большинстве случаев вы будете работать с шаблонными решениями. Вышеуказанные знания нужны, чтобы можно было выйти за рамки шаблонов. Но если этого не требуется, то… в пределе можно вообще без каких-либо особых знаний и умений просто нагугливать готовые решения :)
твердо решил максимум за 1 год самостоятельно выучить Kotlin и строить планы по иммиграции на ПМЖ в США.Я считаю именно это главной причиной провала. Вам не нужен был ни Котлин, ни Джава как сама цель, вам нужно было ПМЖ в США. В принципе, я это часто вижу, ведь многие в профессию идут из-за денег, каких-то личных амбиций или иных причин, совершенно не связанных с программированием.
«НА СЕБЯ ПОСМОТРИ!» — воскликнут многие, дескать я тоже оказался тут, и наверняка получаю 300к в наносекунду. Нет. Просто в свое время у меня был Спектрум, несколько книжек по нему и сломанный магнитофон, и принцип «хочешь поиграть в игру — напиши ее сам». Как и тогда, так и сегодня, я практически не помню ничего из школьного курса алгебры и геометрии (кроме того, что я ненавидел геометрию), я не учился на модных курсах ЦС50 (хотя курс крайне годный, на мой взгляд), да и вообще, доставать инфу в те годы приходилось преимущественно методом научного тыка. Так что можно сказать, что у меня вообще никакого компьютерного образования нет.
Итог: пишу на десятке разных языков, достаточно свободно могу слепить из сниппетов со стековерфлоу что-то под незнакомую платформу, даже без особенного чтения документации под нее. На данный момент безработный. До этого зарабатывал 30к рублей в месяц за написание прошивок к собственным железкам на одном заводике.
я это часто вижу, ведь многие в профессию идут из-за денег, каких-то личных амбиций или иных причин, совершенно не связанных с программированием
Я долго пытался прояснить этот вопрос в своей статье на тему того, как стать программистом, но так и не услышал внятного ответа.
Я процитирую кусочек своего комментария:
«Но в мире миллионы людей каждый день делают неинтересную работу. И не все из них надрываются ради куска хлеба — многие сами выбрали её, потому что она их привлекала немного больше, чем другие. Но они не грезили этой работой в детстве; она, как вы пишете, не отвлекала их от учёбы и не зудела в голове. Просто выбрали и работают.
Вы считаете, что они все плохие работники, и им не следовало даже начинать? Если работник не засыпал с детства в обнимку с работой — это плохой работник, и он не может выполнять свои обязанности? Почему «жгучий интерес» подходит для выбора профессии, а «просто интерес» уже нет?»
Если работник не засыпал с детства в обнимку с работой — это плохой работник, и он не может выполнять свои обязанности?
На самом деле, прямой корреляции нет. Вспомнилась фраза какого-то писателя (не помню дословно, но смысл такой): можно написать хорошее произведение на заказ, а можно от души тягомотину написать.
Опять же неинтересная работа понятие относительное: кому-то интересно писать что-то новое, а кому-то в чужом коде разбираться и фиксить баги. Любая работа не может постоянно 24x7 быть интересной, ИМХО.
Если работник не засыпал с детства в обнимку с работой — это плохой работник, и он не может выполнять свои обязанности
Вы немного смещаете акценты. Тут речь немного о другом
В принципе, я это часто вижу, ведь многие в профессию идут из-за денег
Когда человек пришел исключительно и только за деньгами, он будет делать ровно то, за что ему платят. А это отсутствие развития ибо чтобы развиваться, нужно всегда делать чуть больше.
Тут человек будет отсиживать на работе ровно с 9-ти до 6-ти и выполнять ровно то, что ему поручат. Потому что за большее не заплатят сразу, а иного стимула, кроме как получить зарплату, у него нет.
Прогресс всегда и везде двигается энтузиастами. Теми, для кого интересен сам процесс. Эти люди отнюдь не альтруисты-бессеребрянники, но материальный стимул у них не на первом месте.
он будет делать ровно то, за что ему платят
Это плохо?
выполнять ровно то, что ему поручат.
Это плохо?
Прогресс всегда и везде двигается энтузиастами
Выполнять свои обязанности и двигать прогресс — это разве одно и то же?
Мне кажется, вы по умолчанию (почему-то) отождествляете работу программистом и развитие цивилизации.
Это плохо?
Для какого-нибудь слесаря или токаря — неплохо. Для дворника тоже неплохо.
Для человека же, профессия которого требует постоянного саморазвития это плохо.
Выполнять свои обязанности и двигать прогресс — это разве одно и то же?
Странный вопрос. Кто-то заказывал и оплачивал Попову изобретение радио? А представьте на его месте исполнителя, который работает ровно от звонка до звонка и делает ровно то, что ему оплачивают.
И так по всем фронтам. Нет линукса, нет OpenSource Software. Совсем нет. Вообще. Потому что его создание не оплачивается (на начальном этапе точно). Много чего нет. Зато куча «добросовестных исполнителей». Серая офисная биомасса.
Мне кажется, вы по умолчанию (почему-то) отождествляете работу программистом и развитие цивилизации.
А вы с чем ее отождествляете? С офисным планктоном, тупо перекладывающим бумажки на нелюбимой, но терпимой потому что там платят и дают возможность закрывать кредит, работе?
Для человека же, профессия которого требует постоянного саморазвития это плохо.Не понимаю этого тезиса. На работу ходят за деньгами, и надо чётко соизмерять доход с затраченными силами и возможными проблемами из-за выхода в чужую компетенцию и за пределы должностной инструкции, иными словами — если сделать полезную для работодателя в понимании исполнителя штуку, что он получит: премию (какого размера?), почётную грамоту или по шапке за то, что занимался фигнёй, когда сроки горят. То же с «саморазвитием»: если работодатель хочет, чтобы исполнитель изучал новые технологии или инструменты после работы, то не исключено, что применяться полученные знания будут уже у другого работодателя. Короче, классика — «Кому надо, тот и платит».
Далее. Каждый год ФЗП пересматривается. В прошлом году подняли на 5%. Руководство решило так — раздать всем по +5% неинтересно. Посему кто просто работает — оставили как было. Кто делает чуть больше — те получили больше. Некоторые +25% к текущему.
Т.е. есть система поощрений. Пассивные мало кому нужны. Ну может и нужны там, где это «пехота», которую всегда можно поменять. Где рынок рабочей силы переполнен, а квалификация не является определяющей — достаточно чтобы человек умел пользоваться нужным фреймворком.
У нас немного сложнее. Нужно и платформу более-менее знать и в предметную область приходится въезжать. Иначе будут проблемы с эффективностью, а тут на эту тему, мягко говоря, пунктик. Так что хорошим спецом тут человек становится года через два. И терять его уже становится невыгодно. Посему стараются стимулировать. Материально, плюшками различными (ну там страховки, льготы, компенсации всякие — чем выше грейд, тем больше плюшек).
Везде, где мне приходилось работать последние… сколько? лет тридцать, наверное… ценилась проактивность.Вам повезло, мне нет: где-то говорили большое человеческое спасибо, где-то оплачивали материалы в двойном размере и время как пойдёт, где-то ругали, утверждая, что это нам не надо, а потом с удовольствием пользуясь… Так что теперь только письменное распоряжения, ТЗ и в идеале предоплату. Не скажу, чья история более типовая, то ли я неудачник, то ли кругом куча мудаков :)
Вам повезло, мне нет: где-то говорили большое человеческое спасибо, где-то оплачивали материалы в двойном размере и время как пойдёт, где-то ругали, утверждая, что это нам не надо, а потом с удовольствием пользуясь…
Я этого нахлебался еще до того как в ИТ ушел.
Были моменты, когда предлагали вроде бы и неплохие условия, а спинным мозгом чувствовал блуду и отказывался. Даже если по деньгам хорошо обещали.
Так что, наверное, просто везло на интуиции выезжать.
Завышенная самооценка работает примерно так. Таинственный голос в голове тебе шепчет: «Какой-то шведский инфантил Маркус Перссон написал Minecraft, а финский студент создал ядро Linux. И вообще, ты видел вчера этих смешных подростков у полки IT в книжном магазине, листавших литературу по C# и обсуждавших, как подготовиться к собеседованию? Нет, ты их видел? Неужели такой великий гений, как ты, не сможет разобраться хотя бы в основных алгоритмах сортировки и не поймет, как работает паттерн Декоратор? Соберись, тряпка! Нам с тобой еще захватывать мир, и нужно уже с чего-то начать». Ну, и действительно берешь и в конце концов разбираешься. Не сразу, конечно, но прогресс идет.
Собственно, все, что вы описываете, я плюс-минус тоже проходил. Когда начинаешь изучать что-то конкретное и выясняешь, что тебе нужно предварительно изучить пять других фишек, технологий и т.п, а потом берешь ту из них, что кажется самой легкой, и обнаруживаешь, что тебе опять ничего не понятно, потому что нужно сперва изучить то-то и то-то, и руки совсем опускаются. Хорошая новость в том, что по этому дереву, как я выяснил, вполне реально добраться до корня. В каждом конкретном случае он будет свой. И это вовсе не какой-нибудь ассемблер или что-нибудь столь же фундаментальное, а курсы, книги, сайты с заданиями, проекты, подходящие для вашего нынешнего уровня понимания. То есть, в моем случае пришлось дойти до «углубленных» учебников по информатике за 10-11 класс Полякова и геймдева на Scratch’е. После них все встало на свои места, так как я сумел в общих чертах увидеть картину целиком.
Ну, и в частных случаях примерно шел по тому же пути. Например, захотел разобраться в алгоритмах. Решил, что читать Кнута пока рано, и Кормена, наверное, тоже, поэтому взял Скиену, так как показалось, что он будет проще. Завис на второй главе. Потом через пару месяцев купил «Грокаем алгоритмы» какого-то индуса, где основы объяснялись на пальцах и на смешных картинках, очень образно и доступно. Да, еще немного комбинаторики было в этом промежутке: курсы по ней прошел на курсере и первые две главы задачника Виленкина прорешал. Теперь Скиена идет намного легче. Примерно то же с матаном. Учебник МГУ я не осилил, но после комиксов Гоника уже показалось, что зверь не так страшен.
Ну, или, скажем, впервые взять IT нахрапом я попытался несколько лет назад, начав сходу с изучения Yii по какому-то англоязычному пособию. Тогда я хотел сделать сайт под один свой проект. В итоге потерпел крах. Но все время с тех пор я со своим мелким занимался Скретчем, чисто ради фана, ну, и еще сочинением всяких приблуд для Майнкрафта с помощью Питона, по книге с подробными инструкциями. Когда-то в детстве я делал игрушки на спектрумовском бейсике, поэтому с понимание n = n + 1 проблем, конечно, не было, что такое переменные, циклы и функции, я тоже имел базовое понятие, но о существовании, скажем, рекурсии узнал только в этом году, так что в целом Скретч – это как раз то, что мне нужно было, чтобы поверить в свои силы. Это был мой уровень на тот момент. В итоге от простых проектов мы перешли ко всяким игрушкам типа симулятора сельского хозяйства, стрелялке, гоночкам в стиле ZX Spectrum и т.п., в общем в какой-то момент Скретч я перерос. И тогда такой: «Ну, блин, раз я могу сделать простую игру на Скретче, попроще, но по сути не намного хуже того, что в моем Андроиде, то что мешает просто выучить другой синтаксис и повторить то же самое?» Месяцев 9 назад записался на курсы по Питону для начинающих на Курсере от ВШЭ. Вот, с этого все закрутилось. Не могу сказать, что все шло гладко. Первые недели все было слишком легко, а последние – слишком сложно. Курс показался не до конца сбалансированным, так скачок от простого к сложному слишком резкий. Но в целом возникло подозрение, что Питон я в итоге осилю.
Дальше повторялось много раз то, что я уже описал. Например, брал книгу Лутца о Питоне, доходил до чего-то, чего не мог понять, скажем, до регулярных выражений, зависал, а потом после школьного учебника, где тема разбиралась на пальцах, преодолевал это препятствие. То есть, как мне кажется, все сложности преодолимы. Главное, что нужно прокачать – это мотивацию, веру в себя. Ну, и дальше идешь к тому узлу древа познаний, где все еще более-менее понятно, но уже есть то, что еще неизвестно.
Очень сильно помогают всякие полуигровые ресурсы в интернете. В моем случае это codewars. Пишешь много кода, применяешь те же алгоритмы на практике. За 9 месяцев я получил там 3 кю. Для выпускника какого-нибудь факультета прикладной информатики это так себе успех, а я там многому научился. В начале года иногда зависал на задачах 6-7 кю, сейчас делаю зачади 3-4 кю.
Ну, и, конечно, реальные проекты, но доступного уровня. Скажем, сейчас мы с мелким делаем текстовую РПГ на питоне, тренирую скилл по ООП, а для одной подруги понемногу пилю сайт на Django. Второе продвигается медленнее, чем хотелось бы, но и мотивирует неплохо. Вот, как-то так. Мотивация + алгоритм «от сложного к простому». Ну, и вера в себя. И да поможет нам компьютерный бог!
На примере Вашей задачи с загоном, для решения бизнес-задачи Вам не обязательно знать производные, достаточно элементарных действия (для того чтобы выразить площадь через X) а дальше в цикле найти максимальное приближение. Это буквально пара минут времени, 10 строчек кода и 96 микросекунд на его выполнение (на i5 не самом свежем), для нахождения площади длины и ширины с точностью 0,001.
Бизнесу надо здесь и сейчас решать задачи и получать прибыль и пока Вы будите учиться всё делать правильно и выслушивать академические курсы по архитектуре и прочему, кто-то займет Ваше место и сделает это «в лоб», тем самым решив бизнес-задачу. При этом ему никто не запретит потом разобраться в производных и произвести рефакторинг.
Минимально жизнеспособный продукт — бизнес и ничего личного.
И поверьте, люди которые работают в очень крутых компаниях, не очень сильно преуспели в своём деле. Посмотрите на Яндекс, Mail, VK и т.д. все эти продукты очень сильно уступают своим зарубежным аналогам(жалкое подобие). Это говорит о том, что люди у нас работают малограмотные, либо бюджеты на разработку/проектирование очень сильно занижены. То, что наука отсатёт я вообще молчу.
Мне как программисту без аттестата это видно невооруженным глазом.
А знаете что неверно спроектированные сервис имеет низкий предел развития, т.е. как всегда собрались, распилили бюджет и разбежались.
Кто со мной не согласен?
Это говорит о том, что люди у нас работают малограмотные, либо бюджеты на разработку/проектирование очень сильно заниженыЯ бы не был столь категоричен. Зато я заметил другую особенность: процесс производства у нас куда важнее конечного результата. Всем наплевать, насколько ты гениален и крут, главное — это сдавать таски вовремя, не подводить руководство, не материться, не быть токсичным, соглашаться со всеми, поддерживать корпоративный дух. Обязательно приходить в белой рубашке. Не опаздывать к 8 утра. Улыбаться и не считать работницу ХР за свинью.
А теперь вопрос — вы в этих главных правилах что-то видите, связанное с программированием? Что-то связанное с творчеством и полетом фантазии? Лично я вижу обычную серую массу (даже если человек гениален, его заставляют быть серой массой), которая делает обычный серый массовый продукт, для другой такой же серой массы — КАК ЖЕ СТРАННО, ЧТО НА ВЫХОДЕ ПОЛУЧАЕТСЯ ЧТО-ТО СЕРОЕ!!!
Зато я заметил другую особенность: процесс производства у нас куда важнее конечного результата. Всем наплевать, насколько ты гениален и крут, главное — это сдавать таски вовремя, не подводить руководство, не материться, не быть токсичным, соглашаться со всеми, поддерживать корпоративный дух. Обязательно приходить в белой рубашке. Не опаздывать к 8 утра. Улыбаться и не считать работницу ХР за свинью.
«у нас»? ИМХО это во всём мире так (скорее к нам пришло с запада)
Посмотрите на Яндекс, Mail, VK и т.д. все эти продукты очень сильно уступают своим зарубежным аналогам(жалкое подобие)
а можете подкрепить свои тезисы конкретными примерами?
да, мне поиск и переводчик от яндекса нравятся меньше, чем гугловские аналоги, но говорить «жалкое подобие» я бы не стал, отличные продукты на самом деле, просто у гугла ещё чуть лучше.
по поводу vk и fb — плотно не пользуюсь ни тем, не другим, но явно, что в области UI/UX fb проектируют марсиане, в vk старательно копируют, но тут уже работают человеки, волей-неволей у них получается более user-friendly.
либо бюджеты на разработку/проектирование очень сильно занижены
разумеется, бюджеты локальных русскоязычных продуктов будут на порядки ниже, чем глобальных (или даже локальных штатовских, европейских и китайских). просто потому, что экономики разные по масштбам, да и людей у нас меньше.
У Яндекса более релевантный поиск по Рунету.
Почтовиков сейчас множество, все плюс/минус одно и то же.
С чем предлагаете сравнивать mail.ru? Если с gmail, то по мне так mail.ru — приятнее глазу. Гугловский выглядит как студенческая поделка, когда функционал написали а UI/UX… — да хрен с ним.
Навигаторы — более функциональные и точные (хотя бы потому, что собирают более адекватную информацию о пробках).
Зарубежные аналоги 2gis покажете?
webstorm используют программисты во всём мире.
Да вон хотя бы почитать рассказы уехавших за бугор: какое недоумение у них вызывают online-сервисы иностранных банков, после того, чем они пользовались в России.
Так что про «малограмотные» — это Вы загнули.
какое недоумение у них вызывают online-сервисы иностранных банков, после того, чем они пользовались в России.
Не первый раз об этом слышу и не могу понять, в чём причина этого?
1) Банки очень богатые.
2) Программистов полным-полно.
3) Рабочие схемы уже давно отработаны и существуют.
Тем более что они всё равно все потихоньку пеереезжают с Кобола, ну добавить к общей смене системы приличный онлайн-банк это же копейки. В чём там проблема? Тупые 90-летние директора в советах директоров, которые привыкли платить чеками?
В то время как за бугром запросто можно встретить магазин где принимают визу и не принимают мастеркард.
«там» гораздо более ответственно подходят к вопросу экономики. у нас вендор сказал что надо систему через год полностью обновить, все банки как один взяли под козырек и бахнули кучу ярдов на переписывание софта… у них… вендор пошел далеко и надолго вместе со своим софтом.
по этому там и кобол и полосатые карты в ходу и клиентский софт это кривенткий фронт прикрученные к древнейшей системе на коболе.
у нас вендор сказал что надо систему через год полностью обновить, все банки как один взяли под козырек и бахнули кучу ярдов на переписывание софта
Точно знаете? Что-то я такого не замечал у нас. Три с лишним года в этой системе, причем, на самом бэкенде (то, что крутится на уровне АБС — управление разработки центральных банковских систем, команда ядровых функций АБС) — могу ответственно заявить — ничего подобного у нас нет. Ни одна доработка просто так не делается. Что работает, никогда не будет трогаться без необходимости. Все доработки или инициируются бизнесом (а вот нам надо чтобы...), или необходимостью оптимизации, или выявленными дефектами промсреды.
И еще — пользовательские сервисы и «банковский софт» (что вы вообще под этим имели ввиду?) это две большие разницы. Есть, скажем, мобильный клиент — его постоянно перепиливают. Но на нас (тот самый «банковский софт» — функции уровня АБС) это не сказывается вообще никак. На разве что вебсервис какой попросят (с нашей стороны это т.н. «сервисмодуль», который по набору данных от ws выдает нужный резалтсет или вызывает процедуру изменения соответствующей таблицы в БД. Но сервисмодуль это такая маленькая фитюлька, которая пишется за полдня (дольше порой поставку оформлять).
Вообще, в банках деньги считать умеют. И очень хорошо. И просто так «бухать кучу ярдов» никто никуда не будет. Там на любое «а давайте...» первым делом спросят «а сколько мы на это потратим и сколько заработаем?».
Конкретно у нас уже несколько лет взят курс на отказ от услуг вендоров и переход на разработку собственными силами. Просто потому что это дешевле. За разработку модуля, которую наш разраб уровня мидла сделает за неделю, максимум две, вендоры просят несколько сотен тысяч. И все равно потом тестируем на всех уровнях мы сами.
Точно знаете? Что-то я такого не замечал у нас.
Ну вот что я видел, в конце 2000х приходит виза/mc и говорит, «к концу года у вас должна быть поддержка EMV и обязательный PCI DSS compliance (я застал времена когда он был еще опциональным), иначе фиг вам, а не продление лицензии»
точно также была история с PayWave и PayPass… типа «как минимум 70% точек должно его поддерживать, если нет — давайдосвидания, остальные 30% через год»
Я работал в двух разных процессингах и видел оба этих фокуса в живую… и банк всегда со вздохом «ну всё, начинаем миграцию, закупаем новые терминалы»
Конкретно у нас уже несколько лет взят курс на отказ от услуг вендоров и переход на разработку собственными силами.
и что у вас и процессинговый софт самописный? я вот заметил обратную тенденцию в этой сфере.
И еще — пользовательские сервисы и «банковский софт» (что вы вообще под этим имели ввиду?) это две большие разницы
Я отлично это знаю, банковский софт это вообще темный лес и кошмар-ужас, и прикручивать к нему пользовательский фронт, зачастую — сочинять всякие промежуточные прокладки и костыли, чтобы оно хоть както работало.
(например прятать от клиента технический овердрафт при использовании всяких модных СБП и прочих фокусов про моментальные платежи) и вообще все механизмы реального функционирования продуктов которые до сих пор остались старые (типа 5 дней на банковскую транзакцию, 30 дней на процессинговую)… когда бабла нет но клиент об этом знать не должен.
я уж молчу, что в некоторых процессинговых системах нет транзакций в БД, помню у меня волосы на голове шевелились когда я писал модуль для этой штуки.
1) списываем со счета x руб
2) зачисляем на счет x руб
3) если мигнёт свет между 1 и 2… то в течении 5 дней бухгалтерия разъедется менеджеры увидят и поправят
4) «Это норма» (с)
+1) а теперь объясни клиенту что вообще происходит
+2) один зеленый банк, который несколько лет назад начислял штрафы по 2-5 рублей в месяц за овердрафт по дебетовкам, когда вы делали операции которые арифметически никогда не приводили к минусу
p.s. я работал НЕ в зеленом банке
p.p.s. забавно, но я работал (относительно давно) в процессинге который был связан с альфой, хоть и не совсем напрямую, удивительно как вы не замечаете реалий :)
Ну вот что я видел, в конце 2000х приходит виза/mc и говорит, «к концу года у вас должна быть поддержка EMV и обязательный PCI DSS compliance (я застал времена когда он был еще опциональным), иначе фиг вам, а не продление лицензии»
точно также была история с PayWave и PayPass… типа «как минимум 70% точек должно его поддерживать, если нет — давайдосвидания, остальные 30% через год»
PCI DSS в 2006-м году стал обязательным стандартом для европы. Естественно, что все банки, которые попадают в эту юрисдикцию, обязаны ему следовать.
и что у вас и процессинговый софт самописный? я вот заметил обратную тенденцию в этой сфере.
Думаю что нет. Но я немножко ниже работаю — на уровне ядра АБС. Процессинг для нас — одна из множества внешних систем. С ним больше команда модуля пластиковых карт работает.
А наша команда отвечает за ядровые функции. Хотя я лично сейчас сместился в сторону комплаенса.
У нас даже ядро АБС не самописное. Но вокруг него огромная куча уже нашего кода, который обеспечивает соответствие работы ядра нашим реалиям. Там это изначально заложено — расширяемость ядра.
Да, приходится подстраиваться под законодательство. Вышел 229ФЗ — нам лишняя головная боль обеспечить его выполнение. Поменял росфин формат поставляемых нам списков комплаенс — мы обеспечиваем прием и интеграцию информации в систему.
Но ядро при этом как работало, так и работает. Добавляются/меняются отдельные модули.
я уж молчу, что в некоторых процессинговых системах нет транзакций в БД, помню у меня волосы на голове шевелились когда я писал модуль для этой штуки.
1) списываем со счета x руб
2) зачисляем на счет x руб
3) если мигнёт свет между 1 и 2… то в течении 5 дней бухгалтерия разъедется менеджеры увидят и поправят
4) «Это норма» (с)
+1) а теперь объясни клиенту что вообще происходит
+2) один зеленый банк, который несколько лет назад начислял штрафы по 2-5 рублей в месяц за овердрафт по дебетовкам, когда вы делали операции которые арифметически никогда не приводили к минусу
Ну это уже выбор платформы, аппаратуры и АБС. Целостность данных у нас обеспечивается на уровне ОС (на нашей платформе БД есть неотъемлемая часть ОС, она в нее интегрирована и вс целостность данных поддерживается самой ОС на уровне системного журналирования всех операций с БД).
Странно, что сервера не прикрыты никакой резервной системой питания. У нас как-то на ТП авария была. Так мы об это узнали только когда пришла рассылка по возможности выключить лишние электроприборы т.к. здание на несколько часов перешло на собственные генраторы. Ну и в коридорах освещение перешло на аварийное. Но ни один комп не пергрузился.
По поводу технических овердрафтов — тут от АБС зависит. У нас АБС работает в реальном времени (с переключением всех операций в юнит ночного ввода, когда в дневном идет EOD с последующим накатом из ночи в новый день по журналам).
забавно, но я работал (относительно давно) в процессинге который был связан с альфой, хоть и не совсем напрямую, удивительно как вы не замечаете реалий :)
Я просто в других реалиях. Более глубоких. На уровне той черепахи (АБС), на которой стоят слоны (внешние системы, в т.ч. и процессинг)
PCI DSS в 2006-м году стал обязательным стандартом для европы. Естественно, что все банки, которые попадают в эту юрисдикцию, обязаны ему следовать.
ну DSS это конечно отдельный разговор (я вообще всеми руками за такое ужесточение и требования), я просто привел его в пример как вендор навязывает банкам требования подразумевающие огромные затраты денег, причем таких объемов что они сопоставимы с затратами на то чтобы вообще бизнес закрыть (почему собственно и популярны сторонние процессинги)
EMV тоже стал стандартом для европы, однако в США силенок не хватило банкам ультиматумы ставить для апгрейда
Странно, что сервера не прикрыты никакой резервной системой питания.
ну я просто пример привел же с питанием (на моей памяти был такой случай, выгорела розетка в серверной)… бывает проблемы с охлаждением еще (тоже у меня был такой случай)
А на самом деле, вы должны знать что всегда периодически чтото падает у банков… если вы периодически общаетесь со своим коллцентром, то должны знать что существует такое событие как «сбер упал», когда это к вам никакого отношения не имеет но телефоны обрывают — вам и насколько часто такое происходит. потом есть ночные остановки у всех банков на обновление ПО. потом бывают кривые обновления и их откаты обратно. помню как с канистрами бегали на АЗС когда в Москве блекаут был и топливо в ДГУ начало заканчиваться… и гасили ненужные сервисы чтобы продлить работу…
По поводу технических овердрафтов — тут от АБС зависит.
тех.овердрафт зависит от много чего, я правда из карточной сферы, так там весь техпроцесс на этом построен и куча костылей вокруг
простая операция:
1) вы перевели 100р через c2c например
2) вам упала смс что пришло 100р
3) вы их сняли в банкомате.
в реальности:
1) у отправителя ставится холд на 100р (на счете 100р, на балансе 0)
2) вам система пишет что у вас 100р (на счете 0р, на балансе 100р)
3) вы снимаете 100р в банкомате (на счете -100р, на балансе 0р, овердрафт!)
4) в течении 5-30 дней реальное бабло приходит и становится 0,0
5) банк начисляет штраф за овердрафт
А на самом деле, вы должны знать что всегда периодически чтото падает у банков… если вы периодически общаетесь со своим коллцентром, то должны знать что существует такое событие как «сбер упал», когда это к вам никакого отношения не имеет но телефоны обрывают — вам и насколько часто такое происходит.
Не… Мы с коллцентром не общаемся. Есть сопровождение, есть поддержка. Их задача обеспечивать бесперебойную работу. В том числе и откатить или остановить что-то из процессов.
Мы вообще на 95% общаемся только с аналитиками. Они получают дефекты от сопровождения, задания на разработку от бизнеса.
потом есть ночные остановки у всех банков на обновление ПО
На самом деле, это не остановка. Это переход на новый банковский день. Сведение баланса и прочие операции. В терминах АБС это называется EOD — End Of Day. Где-то в рекламе какого банка даже было что-то типа «платежи проводятся с 4 утра и до полуночи». Так вот с полуночи до 4 утра как раз и идет EOD. И новые внедрения на пром проводятся в рамках него.
У нас чуть сложнее. У нас все платежи круглосуточно. Перед началом EOD создается копия промюнита — юнит ночного ввода и все операции переводятся туда. Там как бы еще продолжается день. А в основном юните начинается процесс EOD. Когда он закончится, начинается накат из ночного юнита в новый день. Накат осуществляется по журналам (каждая таблица имеет т.н. «журнал» в котором фиксируются все изменения для каждой записи). Все записи в таблице изменяются толок через специальный RR модуль — модуль внешнего ввода, который вызывает другой модуль — UR, апдейт модуль, передавая ему нужные данные. А тот уже отвечает за журналирование изменений.
У RR модуля три режима — внешний ввод, накат (по журналу из юнита ночного ввода) и рекавери — восставноление по журналу текущего юнита.
Есть еще «головной журнал» где хранятся заголовки всех детальных журналов. По нему видно в каких таблицах были изменения и как получить соответсвующие записи из детальных журналов. За его заполнение тоже отвечает UR модуль.
При накате специальный процесс идет по головному журналу и для каждой записи вызывает соотв. RR модуль, передавая ему ключ его детального журнала. А тот уже берет данные по этому ключу из «своего» журнала и передает их в UR. Так все, что было сделано в течении существования юнита ночного ввода, переносится в дневной юнит в новый день.
простая операция:
1) вы перевели 100р через c2c например
2) вам упала смс что пришло 100р
3) вы их сняли в банкомате.
в реальности:
1) у отправителя ставится холд на 100р (на счете 100р, на балансе 0)
2) вам система пишет что у вас 100р (на счете 0р, на балансе 100р)
3) вы снимаете 100р в банкомате (на счете -100р, на балансе 0р, овердрафт!)
4) в течении 5-30 дней реальное бабло приходит и становится 0,0
5) банк начисляет штраф за овердрафт
Я знаю как это бывает и почему. Обслуживался в одном банке, где синхронизация холдов и остатков по счетам проводилась в EODе Там легко было, имея две карты, привязанные к одному счету, уйти в теховердрафт на сумму в два остатка по счету на начало дня.
Правда, за это не штрафовали т.к. считалось что это особенность функционирвания системы.
У нас такого нет — все доступные остатки считаются с учетом холдов. Т.е. послал 100р на крату — сразу видишь их доступными на счете. Расплатился картой — сразу видишь «уход» денег со счета (хотя фактически они еще там, просто сумма встала на холд и тебе показывают что она как будто списана уже). Если операция не прошла, холд снимается, для пользователя это выглядит как отмена операции с возвратом денег.
Хотя я тут могу не до конца быть точным в деталях т.к. вижу это исключительно со стороны как все это работает на уровне АБС с таблицами счетов (в том числе и то, что отдается мобильному клиенту или в инетбанк по запросу через WS).
Но в целом модуль пластиковых карт — это отдельная команда. Я с ними вообще не работал (чуть работал с командой системы расчетов — там была задача на стыке их темы и наших ядровых функций). Но сейчас и от этого ушел, слава богу. Сейчас по комплаенсу — жулики-мошенники, террористы-экстремисты, риски, проверки…
На самом деле, это не остановка. Это переход на новый банковский день.
Карточный процессинг не останавливается при переходе на новый день, я имею в виду именно реальную остановку прода, когда вы не сможете расплатиться карточкой и сделать любую операцию по ней.
Правда, за это не штрафовали т.к. считалось что это особенность функционирвания системы.
ну да, там разного рода костыли вокруг этого построены, проблемы начинаются когда сроки сильно растягиваются и начинают вокруг костылей обходить
У нас такого нет — все доступные остатки считаются с учетом холдов.
это для клиентов, банк то должен считать реальные деньги
плюс есть вполне реальная вероятность что операция всётаки не пройдет и тех.овердрафт превратится в настоящий
===
p.s. эх… наверное мне стоит вернуться опять в эту сферу… как я по всему этому скучаю…
Карточный процессинг не останавливается при переходе на новый день, я имею в виду именно реальную остановку прода, когда вы не сможете расплатиться карточкой и сделать любую операцию по ней.
Карточный процессинг для нас (ядра) — внешняя система.
Реальной остановки прода я не припомню. Последний инцидент, связанный с картами — когда пришлось остановить одну из подсистем в связи с… Ну тут не важно в связи с чем. И при этом на пару часов были недоступны операции по картам. Но это все была оперативная работа сопровождения — быстро перевести процесс на запасные рельсы. Наша работа была уже потом — исправление дефекта.
Но штатных регулярных остановок прода у нас не бывает. В том числе и для установки нового ПО. Я уже описал за счет чего.
это для клиентов, банк то должен считать реальные деньги
плюс есть вполне реальная вероятность что операция всётаки не пройдет и тех.овердрафт превратится в настоящий
Так банк и считает. Есть остаток на счете и есть холды. Это для банка. Для клиента для операций доступна сумма в виде остатка на счет минус сумма холдов. Это ограничение не дает ему уходить в технический овердрафт.
Холд в системе появляется сразу после оплаты картой — у нас нет кешира (как в некоторых банках, где холды могут накапливаться в кешире а потом разом сливаться в систему — вот там есть условия для технических овердрафтов).
Для клиента для операций доступна сумма в виде остатка на счет минус сумма холдов. Это ограничение не дает ему уходить в технический овердрафт.
когда вы через любую мнгновенную систему переводов, переводите клиенту деньги, у него на счете их нет и быть не может… но он может ими расплатиться плюс возникает риск отмены операции перевода со стороны системы этот перевод инициировавшей. вот вам возможность тех.овердрафта
и ограничение вам не поможет
А пока не пришло — он даже не знает что они у него есть.
Или вы хотите сказать, что деньги могут придти клиенту, они им расплатился, а с той стороны прошла отмена операции? Но это какой-то очень кривой процессинг — уведомлять клиента о поступлении до подтверждения перевода и закрытия транзакции на этом участке.
деньги между банками ходят не мгновенно (бывают между некоторыми банкоми договора об ускоренных расчетов, но всеравно в пределах опердня), а несколько раз в день и обычно только по будням (и вообще 3-5 дней если не повезет) это хорошо кстати юрлица знают, и у физиков тут отличия нет хотя они это не видят зачастую
например если я вам через по Visa c2c из ньюйорка отправлю 100$ то смска вам прилетит почти мгновенно, а деньги для банка будут ползти еще неделю, да еще и с несколькими посредниками и постфактум еще через пару недель вы на курсовые разницы можете встрять (тоже полно таких историй в интернете, корни их как раз отсюда же растут, типа купил айфон за 500$ а через месяц банку еще должен 50 хотя было все по нулям только что)
А все эти модные веяния с c2c, СБП и вообще любых систем с «мгновенными переводами» это всегда виртуальные деньги, потому что никуда вышеописанная система не девается и фактические расчеты происходят сильно позже
Тем более что они всё равно все потихоньку пеереезжают с Кобола, ну добавить к общей смене системы приличный онлайн-банк это же копейки. В чём там проблема?
Проблема в том, что Вы, видимо, не очень хорошо себе представляете как все это работает внутри.
Можете показать конкретный пример как кто-то «потихоньку пеереезжают с Кобола»? Я слышал только про один австралийский банк. Которому это обошлось в несколько лет и сумму с шестью нулями.
Автоматизированная банковская система — это вам не сайт ООО «Сукин и сын». Она не должна останавливаться ни на секунду и там не должно быть ошибок, которые приведут к потери денег клиента или непрохождению платежа.
А теперь представьте — вам нужно осуществить «бесшовный» переход с одной системы на другую. Для этого вам нужно для начала поставить в пару к работающему серверу еще один (стоимость сервера несколько сотен тысяч долларов). Затем нужно Разработать и установить на новый сервер новую систему. Объемы кода там… Да хрен его знает сколько. Никто не оценивал, но чуть больше чем офердофига. Потом провести всевозможные тесты нового кода. Компонентные, бизнес, интеграционные, нагрузочные…
Потом нужно перенести все данные. Это тысячи таблиц, во многих по несколько десятков миллионов записей.
Потом нужно запустить старую и новую систему синхронно и убедиться что новая система дает идентичный старой результат.
И только после этого вы сможете выводить из эксплуатации старую систему.
И все это весьма поверхностное описание процесса. Потому что еще надо постоянно поддерживать старую систему пока она не выведена из эксплуатации. Вышел новый ФЗ (тот же 229-й, к примеру) — будте любезны дорабатывать АБС для его выполения. Изменил регулятор форму отчетности — опять доработка… Вылез дефект на проме — все бросили и срочно закрываем…
Переходить с Кобола все равно придется. Как нанимать на него я не представляю. Даже если залить деньгами желающих не очень много будет.
Вроде логично пока деньги есть и все еще хорошо начать переход. Потратится сейчас чтобы потом лучше было. А то придут конкуренты без Кобола и отнимут рынок. Просто за счет более качественных и современных услуг.
В каком еще языке есть нативный тип данных с фиксированной десятичной точкой (см. рекуррентное соотношение Мюллера, тут на эту тему была статья, как раз про кобол).
И почему вы думаете, что все вот так прямо спят и видеть как бы работать на фронте с новомодными стеками (и бросать привычный стек каждый раз как появилось что-то более модное)?
Кобол до сих пор поддерживается на тех платформах, которые используются в финтехе. Изучить его, придя в финтех, не такая проблема. Для человека с опытом разработки.
Да, есть более современные альтернативы. И мы ими пользуемся (у нас на платформе кобол входит в состав набора компиляторов, хоть мы им и не пользуемся).
В общем и целом, тут нет проблемы. Такой, чтобы вкладывать в ее решение сотни тысяч доллларов.
А рынок удерживается в данном случае не тем, на каком языке написано ядро системы. Это вообще дело десятое. Я сейчас могу написать программу их нескольких модулей, включая кобол, С/С++ и еще других языках. И она будет работать так, что никто, пользующийся мобильным клиентом не узнает из какого модуля пришел ответ на его запрос. И это совершенно не будет влиять на то, поддерживает мобильный клиент биометрию, или нет. Это вообще совершенно разные уровни, решающие совершенно разные задачи.
Такой, чтобы вкладывать в ее решение сотни тысяч доллларов.
Может ли быть такое, что в решение деньги уже вложили, просто вы этого не знаете, т.к. варитесь в собственном соку?
Ну а легаси систему держат потому что она пока что справляется.
Может ли быть такое, что в решение деньги уже вложили, просто вы этого не знаете, т.к. варитесь в собственном соку?
Что Вы имеете ввиду? Что где-то работает некая параллельная система? Или что?
По должности я как-бы немножко обязан знать что у нас работает в той части, за которую мы отвечаем.
Никаких поползновений сменить систему «на более современную» (а есть ли что-то более современное для нас вообще?) у нас нет.
Про модные даже речи не идет.
Хотя бы плюс-минус актуальные технологии.
Вы предлагаете все законсервировать, заманивать разработчиков деньгами и стабильностью и делать всего по минимуму. То что требуется регуляторами или без чего вообще работать нельзя.
Это же путь в никуда. Заманивать хороших разработчиков будет все тяжелее и тяжелее. Денег везде неплохо, писать черти на чем не хочется и в резюме плохо смотреться будет. Молодые и дерзкие точно что-нибудь придумают после чего у них будет на голову удобнее все. И захват рынка случится сам собой. Что это будет я не знаю. Наверно ни кто не знает, но точно что-то будет.
Не знаю насколько применимо но из свежего: момпнтпльные пернводы, одноразовые карточки, pci dss (для тех знает что такое) тянут на выкидывание с рынка тех кто не сможет так работать.
И все банки живущие в стабильности и экономящие сотни тысяч останутся у разбитого корыта.
Про модные даже речи не идет.
Хотя бы плюс-минус актуальные технологии.
Ну назовите «актуальные» с Вашей точки зрения технологии разработки под IBM i (софт, работающий на серверах IBM PowerS9). Фактически это менфреймы ориентированные на одновременную работы тысяч задач в фоне, с интегрированной в ОС БД DB2 for i
Молодые и дерзкие точно что-нибудь придумают после чего у них будет на голову удобнее все.
Молодые и дерзкие здесь первые пару месяцев только разбираются с какой стороны вообще к этой системе подступиться.
Тут разработчик начинает что-то понимать минимум через год работы. В плане того как писать чтобы нагрузочное тестирование пройти. Что и где можно использовать, а что и где нельзя. Я уже приводил тут пример неправильного использования скуля молодыми и дерзкими. Сегодня вот опять закрывал дефект где неправильно работал поиск по имени — а всего-то надо было посмотреть с какими опциями собран индекс и что эти опции значат (а эти знания даются постоянным штудирование специфических мануалов на сотни и тысячи станиц).
Не знаю насколько применимо но из свежего: момпнтпльные пернводы, одноразовые карточки, pci dss (для тех знает что такое) тянут на выкидывание с рынка тех кто не сможет так работать.
Это все совершенно другая тема. Это фронт, в лучшем случае мидл. Но все это опирается на грубокий бэк. Ядро АБС. И все, что придумают «молодые и дерзкие» на фронтах, будем реализовывать мы на уровне ядра. И реализовывать так, чтобы оно не перегружало сервера, даже в пике, чтобы оно правильно стыковалось с еще 100500 работающими на сервере процессами и т.д. и т.п.
А банки, которые не могут обеспечить стабильность и правильную работу ядра своей АБС просто лишаться лицензии. Потому что каждый серьезный инцидент, отражающийся на работоспособности банка, будет рассматриваться регулятором с вынесением соответствующего решения (от штрафа со многими нулями и до...) Тут не поле для экспериментов. Тут скорее минное поле. Вроде и все тесты пройдешь (компонентный, бизнес, интеграционный, нагрузочный...) а все равно чуток замираешь когда на пром выходит задача (особенно если задача сложная).
А развитие в смысле новых технологий идет. Только любая идей молодых и дерзких исследуется под микроскопом со всех сторон.
Повторюсь — это не сайт ООО «Рога и копыта», который упал на час, да и фиг с ним. Поднимем, гнилой палкой подопрем и дальше как-нибудь работать будет. Зато бантики вон какие красивые у нас. А что тормозит — так это у вас браузер хреновый — обновите и все будет.
Ну назовите «актуальные» с Вашей точки зрения технологии разработки под IBM i (софт, работающий на серверах IBM PowerS9). Фактически это менфреймы ориентированные на одновременную работы тысяч задач в фоне, с интегрированной в ОС БД DB2 for i
Я не готов это вообще назвать актуальной системой. Не Кобол, конечно. Но уже неактуально. Насколько неактуально и пора ли переписывть? Не знаю. Кобол точно пора.
Повторюсь — это не сайт ООО «Рога и копыта», который упал на час, да и фиг с ним. Поднимем, гнилой палкой подопрем и дальше как-нибудь работать будет. Зато бантики вон какие красивые у нас. А что тормозит — так это у вас браузер хреновый — обновите и все будет.
Зря вы с таким пренебрежением говорите о всех вокруг. Поверьте в мире есть много неглупых людей которые умеют делать хороший и надежный софт. И простои не только у вас стоят сотни миллионов в час.
Почем вы оцените простой крупного сервиса ФАНГ? Или поближе к нам час недоступности Вайлдберриз какого-нибдуь?
Тоже повторюсь банки падают достаточно регулярно. И никто не умер. Все как у всех. Упали, поднялись, подсчитали убытки, работаем дальше. Предпринимаем действия чтобы по этой причине больше не падать.
И все, что придумают «молодые и дерзкие» на фронтах, будем реализовывать мы на уровне ядра. И реализовывать так, чтобы оно не перегружало сервера, даже в пике, чтобы оно правильно стыковалось с еще 100500 работающими на сервере процессами и т.д. и т.п.
И чем старее ваши технологии тем это сложнее. Наслаивание легаси, сложность найма, неизвестность стека, сложность изучения.
Да и просто новые технологии они не просто новые, они лучше старых. Иначе бы они их не вытеснили. Вы каждый день тратите лишние силы на разработку из за устаревших технологий. Это тоже большие деньги. Тайм ту маркет стоит дорого.
Модные хипстеры сожравшие рынок могут быть и из Эппла условного. Они из ниоткуда забрали заметную часть рынка. Просто за счет технологий. Пока конкуренты с Коболом и технологиями 80х сидят Эппл просто предоставил нормальные услуги клиентам. По российским меркам услуги даже не лучшие.
Можно и дальше экономить на переписывании. Сколько-то лет это будет экономия. А потом внезапно все. И придется терять рынок и переписывать срочно. Итоговая потеря денег явно больше выйдет.
Я не готов это вообще назвать актуальной системой. Не Кобол, конечно. Но уже неактуально. Насколько неактуально и пора ли переписывть? Не знаю. Кобол точно пора.
Хорошо. Назовите актуальную. Которая удовлетворяла бы всем требованиям по производительности, надежности, способности восстановления в случае сбоя и т.д. и т.п. И скажите, в какой еще системе старое ПО при переносе на более современную платформу не только не потребует пересборки, но и автоматически подстроится под новые возможности и будет их эффективно использовать?
А заодно объясните, почему эта неактуальная система продолжает развиваться как на уровне аппаратуры, так и на уровне ОС.
Зря вы с таким пренебрежением говорите о всех вокруг. Поверьте в мире есть много неглупых людей которые умеют делать хороший и надежный софт. И простои не только у вас стоят сотни миллионов в час.
Почем вы оцените простой крупного сервиса ФАНГ? Или поближе к нам час недоступности Вайлдберриз какого-нибдуь?
Я далеко не ко всем так отношусь. Поверьте, я с очень разными системами работал и знаю что почем. И знаю, что большинство халтуры в этом мире прикрывается красивыми словами о «современных технологиях» и прочим треском. Давно живу, поверьте.
И чем старее ваши технологии тем это сложнее. Наслаивание легаси, сложность найма, неизвестность стека, сложность изучения.
А вы хотите чтобы все просто было? Нашли на вокзале васю, дали ему в руки новую технологию и он с ходу начал писать отличный софт? Так не бывает.
Все ваши «новые технологии» и «замечательные фреймворки» разработываются людьми, с огромным опытом и пониманием сути проблемы. И огромное количество человеко-часов разработки на нижнем уровне. Только ради того, чтобы любой вася мог «предоставить услугу клиенту» и считать себя пупом земли.
Вы поймите, мы не предоставляем услуги клиенту. Мы делаем возможным это делать другим. С минимальными для них затратами. Если угодно — мы делаем тот самый «фреймворк», которым пользуются вася-петя-коля чтобы предоставить клиенту современную красивую услугу.
Оставь голую БД и скажи этому васе что его красивое мобильное приложение в ответ на простейший запрос должно собрать данные по десятку таблиц — будет оно нормально работать? Нет. Поэтому мы говорим — вот тебе, вася, REST API, лепи своего клиента на нем. Занимайся интерфейсом, остальное наша забота. А нужно тебе еще что-то сверх имеющегося — говори, не стесняйся, мы сделаем.
Пока конкуренты с Коболом и технологиями 80х сидят Эппл просто предоставил нормальные услуги клиентам
И опять за деревьями леса не видите. Любая услуга — это очень небольшая видимая часть айсберга. А есть еще его подводная часть, огромная, но никому не видная. Но без нее невозможно.
Вы в курсе, что замечательная система Apple Car Audio (та самая «услуга клиенту») основана на RTOS QNX Neutrino к которой Apple вообще никакого отношения не имеет (они ее просто купили права на ее использование у компании Blackberry, ранее RIM, которая в свое время выкупила ее у Hartman а та до этого — у QNX Software Systems). Это просто пример того, на чем на самом деле основываются «услуги».
И уж поверьте — в микроядре QNX не используются никакие модные фреймворки. Там сплошной низкоуровневый легаси код. А все бантики накручиваются уже поверх.
Так и у нас. Есть ядро автоматизированной банковской системы. Где во главу угла положена надежность и эффективность возведенные в абсолют. А все «услуги клиентам» уже опираются на это самое ядро, предоставляющее соответствующие API.
Да и просто новые технологии они не просто новые, они лучше старых. Иначе бы они их не вытеснили. Вы каждый день тратите лишние силы на разработку из за устаревших технологий. Это тоже большие деньги. Тайм ту маркет стоит дорого.
Не все так просто. Есть маркетинг. Который убеждает человека покупать то, что ему не нужно. И успех того же Эппла — это чисто маркетинговый успех.
TTM — палка о двух концах. Классический пример — MS Windows. Скорее выбросить на рынок недотестированный продукт чтобы занять нишу, а потом латать дыры бесконечными обновлениями (часть из которых закрывая одну проблему, приносит другую).
В общем, тут не все так просто. Вы смотрите сверху и не видите того, что скрывается внутри. Пользуетесь фреймворками, не задумываясь о том, кто их для вашего удобства сделал и как.
Хорошо. Назовите актуальную. Которая удовлетворяла бы всем требованиям по производительности, надежности, способности восстановления в случае сбоя и т.д. и т.п. И скажите, в какой еще системе старое ПО при переносе на более современную платформу не только не потребует пересборки, но и автоматически подстроится под новые возможности и будет их эффективно использовать?
Эти проблемы успешно решены. У вашей платформы нет ничего что не было бы сделано в типовых вещах. Иногда по другому, но скорее лучше а не хуже чем у вас. Массовость решает.
Все хотят маштабируемые и надежные решения. Вы же не считаете что это у вас такое уникальное требование?
Джава отлично возится куда угодно. Без пересборки. Хотя я не понимаю почему пересобрать это проблема. Сборки должны быть повторяемыми.
А заодно объясните, почему эта неактуальная система продолжает развиваться как на уровне аппаратуры, так и на уровне ОС.
Ты вы деньги платите. Почему бы и нет? Пока есть достаточно платящие клиенты все будут развивать.
Вы поймите, мы не предоставляем услуги клиенту. Мы делаем возможным это делать другим. С минимальными для них затратами. Если угодно — мы делаем тот самый «фреймворк», которым пользуются вася-петя-коля чтобы предоставить клиенту современную красивую услугу.
Вы именно предоставляете услуги клиенту. Просто ваш клиент это соседний отдел вашего же банка. А так все типовое. rest, база, очереди. Все как у всех.
У вас внутренний проект. Фреймворк это совсем другое.
Не все так просто. Есть маркетинг. Который убеждает человека покупать то, что ему не нужно. И успех того же Эппла — это чисто маркетинговый успех.
У них именно прорыв по качеству сервиса, по сравнению с другими банками. Маркетинг это хорошо, но только на маркетинге никуда не уедешь. Продукт тоже надо хороший делать. А для захвата рынка лучший.
TTM — палка о двух концах. Классический пример — MS Windows. Скорее выбросить на рынок недотестированный продукт чтобы занять нишу, а потом латать дыры бесконечными обновлениями (часть из которых закрывая одну проблему, приносит другую).
Не надо делать плохо. Надо делать хорошо. И тайм ту маркет держать низким. Крутитесь как хотите. Жизнь такая.
В общем, тут не все так просто. Вы смотрите сверху и не видите того, что скрывается внутри. Пользуетесь фреймворками, не задумываясь о том, кто их для вашего удобства сделал и как.
Да вроде все известно. Вот исходники, вот кучи статей. Все опенсорс, бери и смотри. Хочешь залезть в глубины и законтрибьютить? Велкам! Мир уже давно так живет.
Нет никаких секретных систем или тайных знаний.
А легаси есть. Иногда его много. И оно иногда сильно мешает. Настолько что это приводит к разорению бизнеса или полному переписыванию. Мир изменился, а система не может. Разработчиков тех уже нет, новые не нанимаются, басфактор 0. Как вы сами написали новому разбираться надо чуть ли не годами.
Дорого все это и рискованно. Бизнес или забирает деньги и уходит или выделяет денег на переделку всего.
Банки в этом смысле самые медленные. Но даже до них начинает доходить. Похоже вакансии на Кобол совсем закрываться перестали. Придется потратится. Деньги точно есть, нужно только желание их потратить. И можно будет снова лет 20-30 спокойно жить.
Эти проблемы успешно решены. У вашей платформы нет ничего что не было бы сделано в типовых вещах. Иногда по другому, но скорее лучше а не хуже чем у вас.
Боюсь, Вы бесконечно далеки от системного программирования.
Вот скажите, на какой платформе реализована одноуровневая модель памяти, не требующая переключения сегментов (перезагрузки сегментных регистров) при переключении процессов?
На какой платформе реализован TIMI (набор машинных инструкций, не зависящий от технологии), позволяющий автоматически персобирать исполняемый код при переносе софта на, например, новый процессор?
Джава отлично возится куда угодно. Без пересборки.
Вот вы сейчас серьзно? Правда думаете что hiload с 3млрд изменений (только изменений!) БД в сутки будет нормально работать на джаве? У нас под джаву выделен отдельный сервер (один из трех в кластере) и это вечная головная боль — низкая производительность при неумеренном потреблении ресурсов.
Хотя я не понимаю почему пересобрать это проблема.
Ну хотя бы потому, что количество модулей, которые нужно пересобрать исчисляется десятками тысяч. Если не сотнями.
Боюсь, вы даже отдаленно себе не представляете как работает автоматизированная банковская система. Сколько там крутится одновременно процессов и задач. Кластер из трех PowerS928 (а это 16 12-ядерных SMT8 процессоров — 1536 параллельных вычислительных потоков и 2.5ТБ памяти на сервер) в моменты пиковых нарузок загружен более чем на 90%. Именно по процессорному времени.
А так все типовое. rest, база, очереди
Да вообще все как у всех. Только очень много. И БД из тысяч (если не десятков тысяч) таблиц. И очередей сотни. Рест — это вообще где-то там, на уровне внешней системы.
У них именно прорыв по качеству сервиса, по сравнению с другими банками.
А можно подробнее — что именно? В чем именно прорыв и на чем он основан?
Вот скажите честно — вы когда-нибудь занимались разработкой на уровне ОС? Не вот эти все внешние красивые плюшки, а то, на что они опираются? Судя по Вашем взгляду на жизнь — нет.
Вы можете себе представить, что к сложному запросу по нескольким таблицам по несколько десятков миллионов записей в каждой может предъявляться требование что он должен выполняться не более 100мс (при том, что решение «в лоб» дает 1500-2000мс)? И этот запрос вызывается по несколько тысяч раз за день (например, проверка получателя платежа по спискам террористов-экстремистов, жуликов-мошенников, санкционным спискам, и еще черт знает по чему) с разным набором параметров.
И начинаешь дробить запрос. Делать различные высокоселективные предвыборки, использовать частотный словарь и еще черт знает как изголяться лишь бы все это укладывалось в заданные таймауты.
Банки в этом смысле самые медленные.
Потому что там огромные объемы данных и очень сложные процессы.
Вот наши оценки — порядка 35млн клиентов (данные по клиенту это несколько, ближе к десятку, таблиц, а у клиента еще есть «субъекты» — всякие уполномоченные лица и т.п.)
Порядка 145млн счетов (тут аналогично — это сильно не одна таблица)
около 7млрд операций только по картам (а еще некарточные операции) в день.
Ядро АБС обслуживает порядка 60 внешних банковских систем
час простоя — около 25млн только прямых убытков.
Внутри работает около 30тыс программных объектов, 15тыс таблиц в БД. Ну и так далее…
Много вам лично приходилось работать с системами подобного масштаба? Именно на уровне ядра.
Мы с Вами говорим о разных вещах. Вы явно смотрите с внешней стороны. А я все это вижу изнутри. Для вас быстрые переводы C2C это просто удобный клиентский сервис, а для меня это длинная цепочка проверок (того же получателя надо по всем параметрам прогнать по всем спискам — совпадение имени полное-частичное, совпадение реквизитов ДУЛ, совпадение ИНН, уровни рисков, степени подозрительности и еще черт знает что) в первую очередь.
Для вас сервис заведения нового клиента это вопрос удобства заполнения формы, а для меня это опять длинная цепочка проверок.
И так во всем. Любая API для удобного клиентского сервиса на нашей стороне выливается в использование десятков модулей, таблиц.
Боюсь, Вы бесконечно далеки от системного программирования.
Вот скажите, на какой платформе реализована одноуровневая модель памяти, не требующая переключения сегментов (перезагрузки сегментных регистров) при переключении процессов?
На какой платформе реализован TIMI (набор машинных инструкций, не зависящий от технологии), позволяющий автоматически персобирать исполняемый код при переносе софта на, например, новый процессор?
У вас абстракции протекли.
Вот вы сейчас серьзно? Правда думаете что hiload с 3млрд изменений (только изменений!) БД в сутки будет нормально работать на джаве? У нас под джаву выделен отдельный сервер (один из трех в кластере) и это вечная головная боль — низкая производительность при неумеренном потреблении ресурсов.
Абсолютно. Половина Гугла Джава. Половина Яндекса Джава. А вам видите ли производительности не хватает?
Вот скажите честно — вы когда-нибудь занимались разработкой на уровне ОС? Не вот эти все внешние красивые плюшки, а то, на что они опираются? Судя по Вашем взгляду на жизнь — нет.
Вы сами пишите что вы данные из таблички в табличку перекладываете. Я занимаюсь ровно тем же. Перекладывать данные по табличкам умею. С очередями, гарантиями, шардированием, отказоустойчиво. Все как полагается.
Вы можете себе представить, что к сложному запросу по нескольким таблицам по несколько десятков миллионов записей в каждой может предъявляться требование что он должен выполняться не более 100мс (при том, что решение «в лоб» дает 1500-2000мс)? И этот запрос вызывается по несколько тысяч раз за день (например, проверка получателя платежа по спискам террористов-экстремистов, жуликов-мошенников, санкционным спискам, и еще черт знает по чему) с разным набором параметров.
Запрос в Редис. Одна штука. Выполняется со скоростью сети. В условиях одного ДЦ можно считать что миллисекунд 10. 1000 запросов в день выдержит Редис запущенный на калькуляторе.
Считать и обновлять табличку отдельным процессом, на скорости запросов никак не скажется. Писать неделю.
Видите как все просто на современной архитектуре? Не нужно все это что у вас. Просто правильный инструмент взять нужно.
Много вам лично приходилось работать с системами подобного масштаба? Именно на уровне ядра.
Да. Нет никакого секретного ядра. Есть обычные балансеры, обычный шардированный процессинг, не менее обычные и не менее обычные шардированные очереди. Это не очень просто (а когда перешардировать надо иногда и очень сложно), но все типовое.
25 миллионов за час простоя это не очень дорого. Вы же про рубли?
Для вас быстрые переводы C2C это просто удобный клиентский сервис, а для меня это длинная цепочка проверок (того же получателя надо по всем параметрам прогнать по всем спискам — совпадение имени полное-частичное, совпадение реквизитов ДУЛ, совпадение ИНН, уровни рисков, степени подозрительности и еще черт знает что) в первую очередь.
Это все отдельные микросервисы в современной архитектуре. Пишутся отдельно. Маштабируются отдельно. Проблем не доставляют, если не падают.
Кеши помогают. 170 миллионов чего угодно кешируется где угодно без особых проблем и затрат. 100 байт данных на 170 миллионов записей это порядка 20 гигабайт памяти. Все горячее хешированное или по id в кеши влезет без проблем. Кеши в сети. Маштабируются горизонтально без проблем. Доступ те же 10мс если все в одном ДЦ. Совсем в лоб уже не влазит, но немного подумав точно влезет в память. И чтение становится моментальным.
Считать и обновлять табличку отдельным процессом, на скорости запросов никак не скажется.
а как же всякие race conditions?
Глобально эта проблема в таких ситуациях решаема. И она всегда решаема так чтобы не аффектить чтение.
Как ее решить для любого конкретного слуая зависит от.
Глобально эта проблема в таких ситуациях решаема. И она всегда решаема так чтобы не аффектить чтение.
именно с балансом счёта — не уверен.
впрочем, балансы — это только малая часть; приводимые примеры с оценкой рисков точно могут быть легко кэшированы/шардированы/etc.
Там типичный сценарий читаем много и быстро, пишем отдельно и можно не очень быстро. Все эти таблички с запретом на переводы или рискованными переводами можно совсем не в риалтайме обновлять.
Типичная задача, типичное решение.
Балансы это отдельно. Тут читаем столько же сколько и пишем. Кеши бесполезны. Скорее даже вредны.
Показ в приложении пользователю (б2с) это отдельный случай. Тут на минуту или две кешировать это святое. Чтобы квоты жесткие не вводить и основные базы не грузить на пустом месте.
Боюсь, Вы бесконечно далеки от системного программирования. Вот скажите, на какой платформе реализована одноуровневая модель памяти, не требующая переключения сегментов (перезагрузки сегментных регистров) при переключении процессов?
Если дословно: x86, внезапно. Потому что "сегментные регистры" (CS/DS/ES/SS) в современных реализациях на x86-32 могут использоваться, но практически никто в современных ОС это не делает (все обычные Unix, и Windows, и пр. — один раз инициализируют при переключении в целевой режим и больше не трогают; для x86-64 они вообще несут в себе только указание на выбранный режим. Всё остальное делается только страничным механизмом.
А если учитывать, что в POWER та же страничная адресация — разницы тут и нет.
(Если быть въедливым — в POWER, точно так же как в zSeries, страничный механизм работает по комбинации address space + linear address. Но это становится важным только для виртуализации уровня ОС.)
Специфика AS/400, если въедливо читать источники — в том, что поверх этой плоской системы сделана объектная модель с контролем доступа. Возможно, тут страничная система помогает — а, возможно, и нет. Если нельзя произвольно создать ссылку на то, чего тебе не давали, проитерировать списки всех объектов и т.п., есть контроль доступа по правам и спискам и разделение пространств видимости по этим правам — то система надёжна даже при работе всех пользовательских приложений под общими правами. Но это, считаем, обеспечивает сейчас любой браузер (если исключить костыли всяких легасей). А вот чем именно тут могла бы помочь страничная защита, где границы между адресными пространствами — никакой Солтис не пишет.
На какой платформе реализован TIMI (набор машинных инструкций, не зависящий от технологии), позволяющий автоматически персобирать исполняемый код при переносе софта на, например, новый процессор?
JVM. Дотнет. Это только с ходу две, которые существуют уже десятилетиями.
И для них (как минимум для JVM) есть все варианты в диапазоне: интерпретация всегда; JIT после интерпретации; JIT на первом старте с возможной перекомпиляцией; AOT (ahead of time — предкомпиляция до старта) — активно используется, например, в Android.
Так что и тут нет ничего уникального. Новое — возможно, на 80-е (можно спорить, были ли подходы JVM мотивированы разработкой AS/400 или нет), но уникальность давно закончилась.
Так что "бесконечно далеки от системного программирования" давно вы тут (и, боюсь, книга Солтиса своими неуместными восторгами тут очень мешает объективному сравнению).
IBM берёт своё не этим.
Про highload на Java уже сказали — полно его. Хотя вот сейчас подумалось — любовь IBM к Java во внешнем слое может быть как раз вызвана сходством подходов :)
Вы можете себе представить, что к сложному запросу по нескольким таблицам по несколько десятков миллионов записей в каждой может предъявляться требование что он должен выполняться не более 100мс (при том, что решение «в лоб» дает 1500-2000мс)?
Я могу. Только не понимаю, при чём тут ОС. Больша́я часть успеха тут 1) достигается современным грамотным железом, и 2) собственно оптимизацией на уровне БД. От ОС требуется только чтобы мешала по минимуму :)
Ну ещё в случае AS/400, как прочитал, драйвера БД фактически находятся на уровне ОС. Это не обязательно хорошо — Oracle показывает работу и на плоских дисках.
Как вы сами написали новому разбираться надо чуть ли не годами.
Начинать что-то писать человек даже с нуля начинает через два-три месяца обучения. Но там он пишет тупо по ТЗ — как аналитик расписал, так и напишет. Ошибся аналитик — ошибка перейдет в код (только недавно проводил работу с молодым на эту тему).
Чтобы писать эффективно, нужно хоть немножко представлять предметную область. Что в каких таблицах, как оно между собой связано, по каким законам живет.
Вот пример о чем написал выше. У клиента есть риски. Они разбиты на группы — репутационные, страновые… У каждого риска свой код.
Человеку была поставлена задача — добавляются региональные риски (Крым-Севастополь). Нужно сделать модуль, который их устанавливает. Т.е. заводится новый клиент, у него устанавливается регион (или редактируется клиент и меняется регион). После успешного заведения клиента вызывается модуль актуализации рисков. Оттуда вызывается модуль актуализации реприсков, страновых рисков и добавился модуль региональных рисков. Я когда-то далал по страновым задачу, ну товарищ взял за основу мое и модифицировал ее на региональные. А на тесте выяснилось, что региональные устанавливает она корректно, но снимает в процессе страновые.
Стали разбираться — выяснился косяк аналитика — не выделена отдельная группа под региональные риски. Опытный разраб это дело сразу бы просек и не тратил бы время, а ткнул бы аналитика носом. А неопытный потратил время на разработку неработающего модуля.
Это просто последний пример из жизни.
Так что время уходит не на научиться писать на конкретном языке под конкретную платформу. Это несложно. Я вот кобола не знаю, но уверен, что на освоение мне потребуется месяц-полтора. А то и меньше с учетом того, что саму платформу я знаю и нужен тоько синтаксис понять.
Время уходит на понимание как правильно решить конкретную задачу в данной предметной области. Что с чем связано и что как работает.
И случай не уникальный. До этого занимался разработкой систем мониторинга инженерного оборудования зданий — там тоже без понимания что из себя представляет топология сети (контроллеры-устройства) и знания протоколов обмена ничего толком не сделаешь. Особенно на том уровне, на котором я работал — разработка микроядра распределенной гетерогенной системы. Так что как бы хорошо человек ни знал С/С++, на котором все это писалось, пока он не вникнет как все это работает, классификацию устройств, структуру данных в протоколах обмена, сами протоколы со всеми таймаутами, квитированием и обработкой аварийных ситуаций, ничего путного он сделать не сможет.
А на тесте выяснилось, что региональные устанавливает она корректно, но снимает в процессе страновые.
Обычная бага. Правится не менее обычным способом.
У всех бывает. Писать код без багов никто еще не научился.
Стали разбираться — выяснился косяк аналитика — не выделена отдельная группа под региональные риски. Опытный разраб это дело сразу бы просек и не тратил бы время, а ткнул бы аналитика носом. А неопытный потратил время на разработку неработающего модуля.
У вас явно виден техдог. Не должно одно ломать второе. Тем более если на это тестов нет. У вас их явно нет.
Опять возвращаемся к тому же. Рефакоринг, переписывание. Это все в конечном итоге экономит деньги.
В каком еще языке есть нативный тип данных с фиксированной десятичной точкой (см. рекуррентное соотношение Мюллера, тут на эту тему была статья, как раз про кобол).
Я тут одного не понимаю — зачем именно нативный тип?
Полноценная реализация такого на любом процедурном языке это задача для студента на неделю или для спеца на день. Где-то оно будет, конечно, компактнее выглядеть, как на C++ или любом другом современном ООП языке с дженериками или темплетами, где-то не так явно, но будет.
Можно, конечно, вспомнить встроенную поддержку десятичной плавучки в zSeries и POWER, но вот в чём цирк — у неё не фиксированная точка. Поэтому я вообще плохо понимаю, зачем она такая (особенно с Chen-Ho BCD), для какой легаси она нужна? Может, кто объяснит (без рекламных лозунгов)?
И почему вы думаете, что все вот так прямо спят и видеть как бы работать на фронте с новомодными стеками (и бросать привычный стек каждый раз как появилось что-то более модное)?
Естественно, не все. Но работать на современном языке, который применим ещё где-то кроме тысячи банков, лучше, чем на древнем.
Я сейчас могу написать программу их нескольких модулей, включая кобол, С/С++ и еще других языках.
Ну вот поэтому плавная миграция должна происходить.
Переходить с Кобола все равно придется. Как нанимать на него я не представляю. Даже если залить деньгами желающих не очень много будет.
Думаю, тут переход можно делать только по модулям или вообще по функциям, используя методы, которые позволяют интеграцию с коболом. Грубо говоря, если в Коболе это foo(a, b), где a и b — numeric(10,2), то для C++ это будет void foo(const Numeric<10,2>&a, const Numeric<10,2>&b) (не вчитывался в коболовские конвенции, но предполагаю передачу по ссылке).
И только после того как целый слой и его стыки с соседними переведены — начинать трансформацию дальше.
Да, процесс будет многолетний. Но скорее всего он того стоит.
Хотя я бы переводил не на С++ (я его упомянул потому, что ваш оппонент назвал его в числе языков для своей платформы), а просто на что-то сходное процедурное, без тяжёлых тараканов Кобола, но и без опасных указателей и тому подобных низкоуровневых штук. Может, PL/1. Может, что-то совсем иное.
В начале 90-х я видел контору, которая занималась переводом софта с Кобола на ещё тогдашний C++. Вряд ли это были, конечно, столь центральные банковские системы.
все эти продукты очень сильно уступают своим зарубежным аналогам(жалкое подобие)
у меня все больше складывается ощущение что исторический каргокульт в нашей стране (за бугром все полюбому лучше) очень сильно до сих пор на людей ввлияет
Я видел разное зарубежное ПО, и, ну никак не могу сказать что оно в чемто лучше нашего… про гугл я так вообще кроме матерных слов ничего сказать не могу… про софт разных именитых железячных компаний темболее
в среднем софт одинаков, но по моему ощущению, в некоторых сферах (напимер в финтехе) он гораздо лучше
Должна у тебя появиться цель — то чего ты хочешь достичь с помощью программирования. Твой пэт проджект например, который решает твои собственные потребности. Не нужно учить всё программирование целиком. Изучай только то, что тебе нужно для достижения цели. Реализуй. Поставь новую цель. Повтори.
А работал я сначала с 1с, а сейчас под андроид пишу, от железа очень далеко.
2) Java — плохой язык в качестве первого. Возьмите что-то более простое. Питон, паскаль (PascalABC вполне норм) или хотя бы javascript (хотя там свои сложности). Когда освоитесь с базовыми вещами и получите опыт с какими-нибудь пет-прожектом, возвращайтесь к джаве.
3) Не пытайтесь сразу постичь все сто слоёв абстракции. Выбрали один уровень — посмотрите два слоя вглубь и один вверх. Этого на первом этапе достаточно.
Вот изучаете вы массивы. Вам точно нужно изучить, как с ними работать. Если копнуть, тут же всплывут вопросы: как их хранит в памяти ваш компилятор/интерпретатор; сколько времени выполняются разные операции и почему; есть ли отличие в массивах между разными языками, и почему. Если копнуть ещё чуть глубже, вам придется изучать выделение памяти и системные вызовы, устройство оперативной памяти и кэшей процессора, привлекать понятие амортизированной сложности алгоритма итд; а ещё глубже — и вот вы уже углубились в электронику, а затем и в физику. Это как чтение википедии — заныриваешь в одном месте, всплываешь в двадцати ссылках от исходной статьи. Остановитесь на одном-двух «хопах» и обучение пойдет быстрее.
Как НЕ надо начинать изучать программирование