Всем привет! Типичная ситуация сложилась в компании, в которой я работаю. В бухгалтерии вечный аврал, людей не хватает, все занимаются чем-то безусловно важным, но по сути бесполезным. Такое положение дел не устраивало руководство.
Если подробнее, то проблема в том, что ресурсов бухгалтерии не хватает на текущие задачи, а выделять ставки под новых людей никто не хочет. Поэтому сверху приняли решение порезать некоторые задачи и освободить время бухгалтеров для более полезных дел. Под нож попала такая работа как сканирование и распознавание документов, копирование, внесение их в прочие рутинные радости.
Так передо мной, как аналитиком, встала задача: найти решение для распознавания документа типичного для моей компании — счет-фактуры — структурировать его в имеющиеся хранилища, а также в 1С. Решение, которое будет удобным, понятным, и не влетит компании в копеечку.
Опыт получился занятным, решил поделиться тем, что удалось собрать. Возможно я что-то упустил, поэтому велком в комментарии, если есть, что добавить.
Программы сканирования документов, программы распознавания документов — не новое решение на рынке, его можно найти как в бесплатных программах, так и встроенных в системы.
В ходе распознавания нашего счета-фактуры такими программами я увидел следующее:
Однако есть и проблемы:
Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
За 7-дневный срок триала я изучил и эту платформу.
Что отметил:
От использования этого софта были приятные впечатления. Однако, когда я обратился к ценнику системного решения ABBYY Flexicapture (а мне нужно именно системное), то выяснил, что решение, особенно кастомизированное, обходится в довольно круглую сумму, около 400 тыс. руб./мес. и выше за 10 тыс. страниц.
Я стал искать альтернативу. Как освободить руки сотрудника, получить качественное распознавание документов и не переживать за сохранность и структуру данных.
Вендор предлагает перекинуть значительную часть работы по экспорту данных в ERP с плеч бухгалтеров на роботов. По сути, именно это решает поставленную передо мной задачу. Чтобы познакомиться с распознаванием в этой системе, я взял у вендора триальную версию системы.
Здесь я обнаружил, что распознавание не преследует цели конвертировать полученные данные в новый документ-файл.
Здесь главная цель — распознавание реквизитов документа и их передача в другие системы/сайты/приложения. Кроме того, роботы складывают всю информацию куда надо: автоматически находят нужные папки и сохраняют в необходимых форматах.
Какие виды распознавания в системе я посмотрел:
Нам предлагается на основании шаблона документа распознать подгружаемый документ. Насколько мне известно, этот вид распознавания бесплатный, внутрь зашит движок Tesseract.
Что отметил:
Однако, вендор на данный кейс сообщил, что этот вид распознавания адаптирован под простые документы, с текстовой структурой или с легкими формами. И посоветовал для распознавания счета-фактуры использовать другой вид распознавания — intellect lab.
Процесс тот же, загружаем шаблон и по нему распознаем. Но здесь шаблон отправляется на облачный сервер.
От сервера получаем ответ (распознает такой тип документа или нет), и если распознается, то передается структура шаблона (переменные для маппинга), для сопоставления переменных, которые необходимо будет записать в RPA процессе.
В процессе воспроизведения мы отправляем уже документ, который хотели бы распознать и получаем ответ от iLab сервера о распознавании.
Что отметил по поводу этого распознавания:
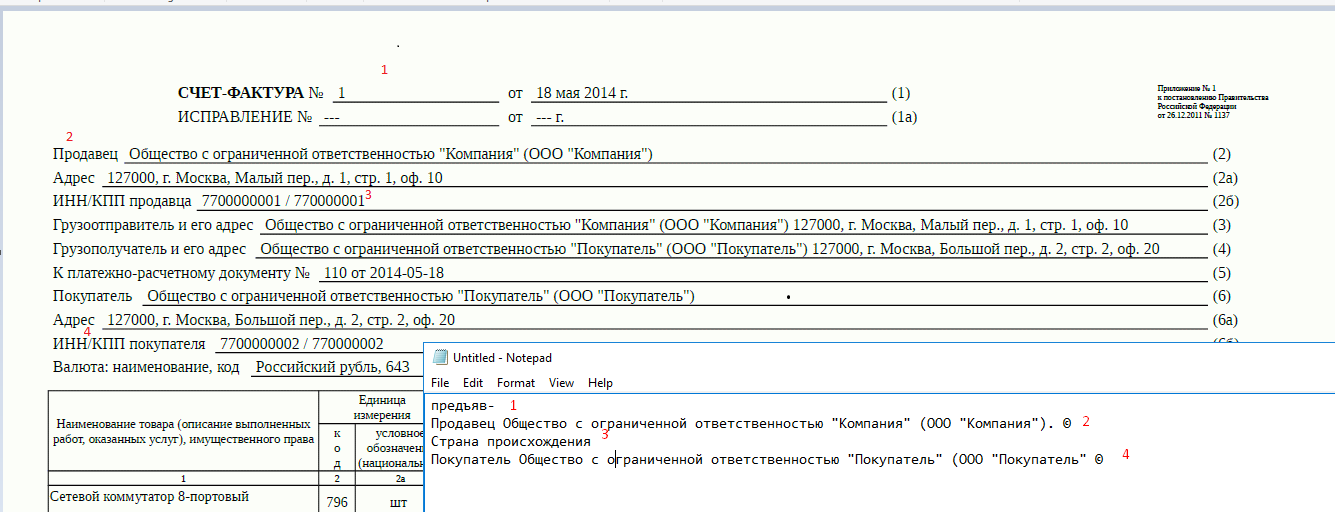
Сам процесс распознавания документов довольно сложно отобразить на видео, так как это происходит в коробке, а экран пустует несколько секунд. Поэтому я сделал отдельную запись распознанных данных в блокнот для визуализации.

Соответственно, эти же данные робот записывает в 1С, создавая там новый документ:

Что удалось выяснить по ценам: Если мы, например, хотим работать масштабно именно с ilab распознаванием, то за наши 10 000 документов придется выложить:
Робот бессрочный, а 10 000 документов на какое-то время хватит. Довольно выгодно получается, как минимум в том, что заплатим за все один раз.
Что понравилось в распознавании в этой платформе в целом:
Если подробнее, то проблема в том, что ресурсов бухгалтерии не хватает на текущие задачи, а выделять ставки под новых людей никто не хочет. Поэтому сверху приняли решение порезать некоторые задачи и освободить время бухгалтеров для более полезных дел. Под нож попала такая работа как сканирование и распознавание документов, копирование, внесение их в прочие рутинные радости.
Так передо мной, как аналитиком, встала задача: найти решение для распознавания документа типичного для моей компании — счет-фактуры — структурировать его в имеющиеся хранилища, а также в 1С. Решение, которое будет удобным, понятным, и не влетит компании в копеечку.
Опыт получился занятным, решил поделиться тем, что удалось собрать. Возможно я что-то упустил, поэтому велком в комментарии, если есть, что добавить.
Программы сканирования документов, программы распознавания документов — не новое решение на рынке, его можно найти как в бесплатных программах, так и встроенных в системы.
Начал я с бесплатных программ:
- glmageReader
- Paperwork
- VietOCR
- CuneiForm.
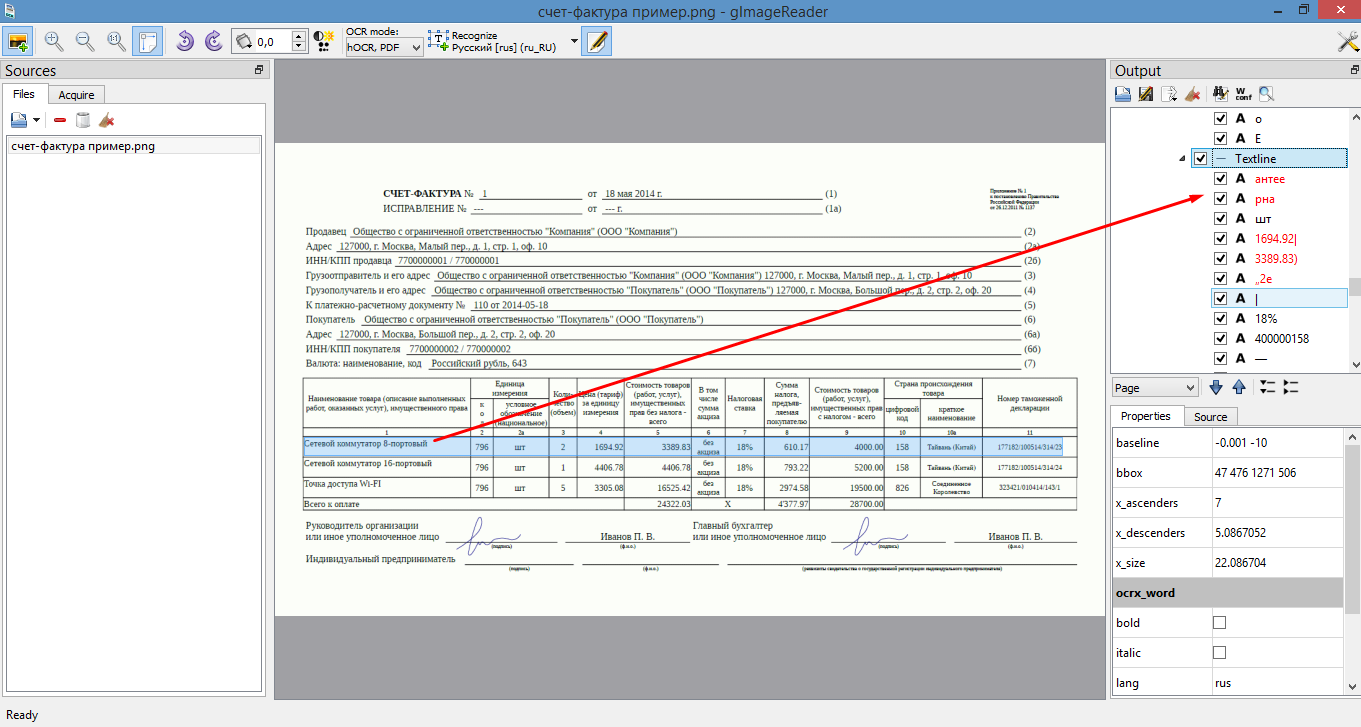
В ходе распознавания нашего счета-фактуры такими программами я увидел следующее:
- В таких программах как VietOCR, Paperwork, glmageReader можно настроить хранение отсканированных документов в определенные папки, Paperwork умеет их даже сортировать, согласно меткам.
- В основном они хорошо справляются с текстом, а там, где текст распознан некорректно, в некоторых программах можно вручную изменить содержимое, прежде чем экспортировать файл.

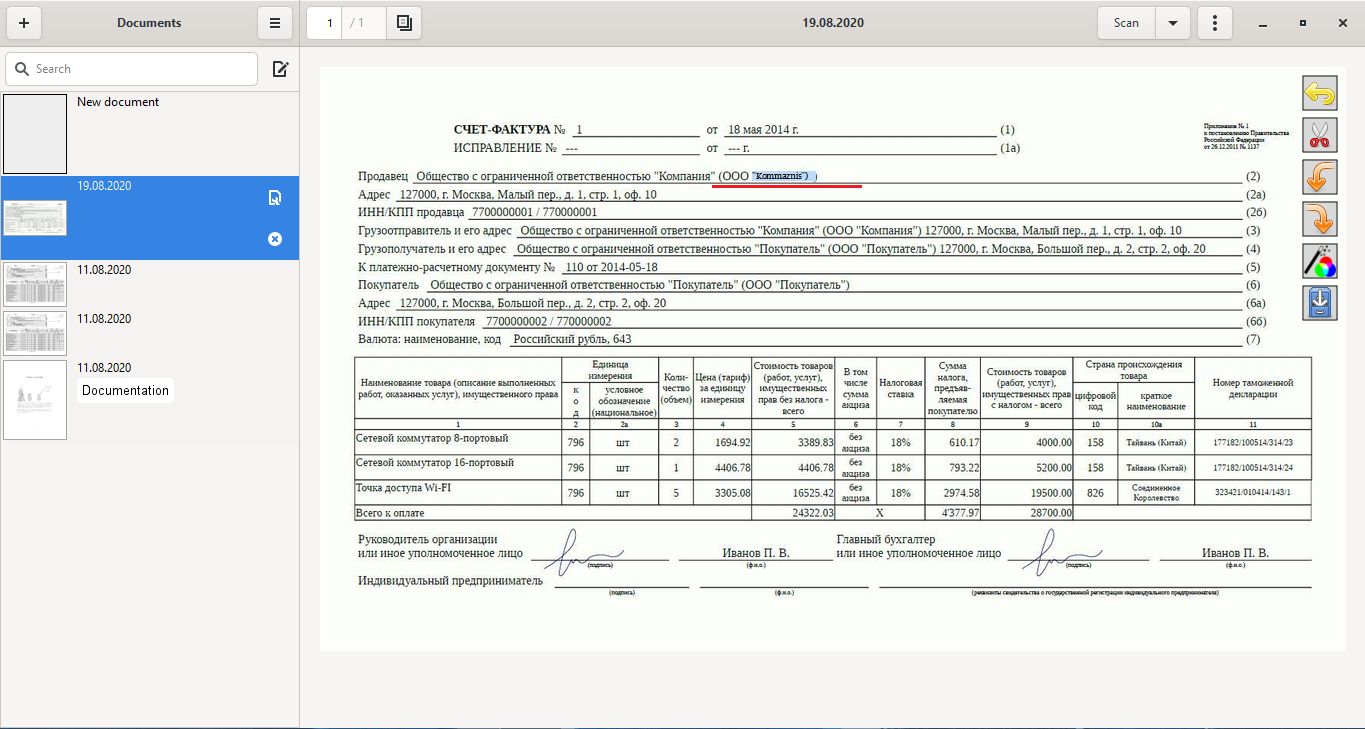
Однако есть и проблемы:
- Есть разница между работой с pdf сканами и png. Не всегда удается удачно конвертировать png в pdf.
- Большинство таких программ сложно справляются с распознаванием документов табличного вида, даже самого простого формата. В результате мы получаем распознанный текст без размеченных полей.

- Иногда неточно определяется шрифт, вследствие чего при конвертации весь распознанный текст наезжает друг на друга.
- В процессе распознавания иногда необходимо делать выравнивание по ключевым словам, с доворотами и смещением координат.
- В некоторых программах таблица распознавалась как картинка и экспортировалась в новый документ Word тоже в качестве картинки, очень урезанной, которую даже сложно разглядеть.
- При редактировании распознанного содержимого в некоторых программах возникали проблемы, менялся шрифт или сам текст.


Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
Затем я исследовал распознавание в ABBYY FineReader 15 Corporate
За 7-дневный срок триала я изучил и эту платформу.
Что отметил:
- Когда я открыл png файл, он отлично был считан и в результате удачно конвертирован в pdf без потери качества изображения и текста.
- Программа отлично знает, как отсканировать документ для редактирования текста. Причем в режиме редактирования файла формата png текст удается отредактировать без проблем, но иногда слетает разметка.
- Однако то же самое я не могу сказать про редактирование файла-скана pdf. При попытке редактирования летели слои.
- Табличный вид распознается качественно, вся структура сохраняется, меня это порадовало.
- OCR редактор хорошо распознал мой сформированный pdf счет-фактуры. Где-то пару символов требовалось поправить вручную.
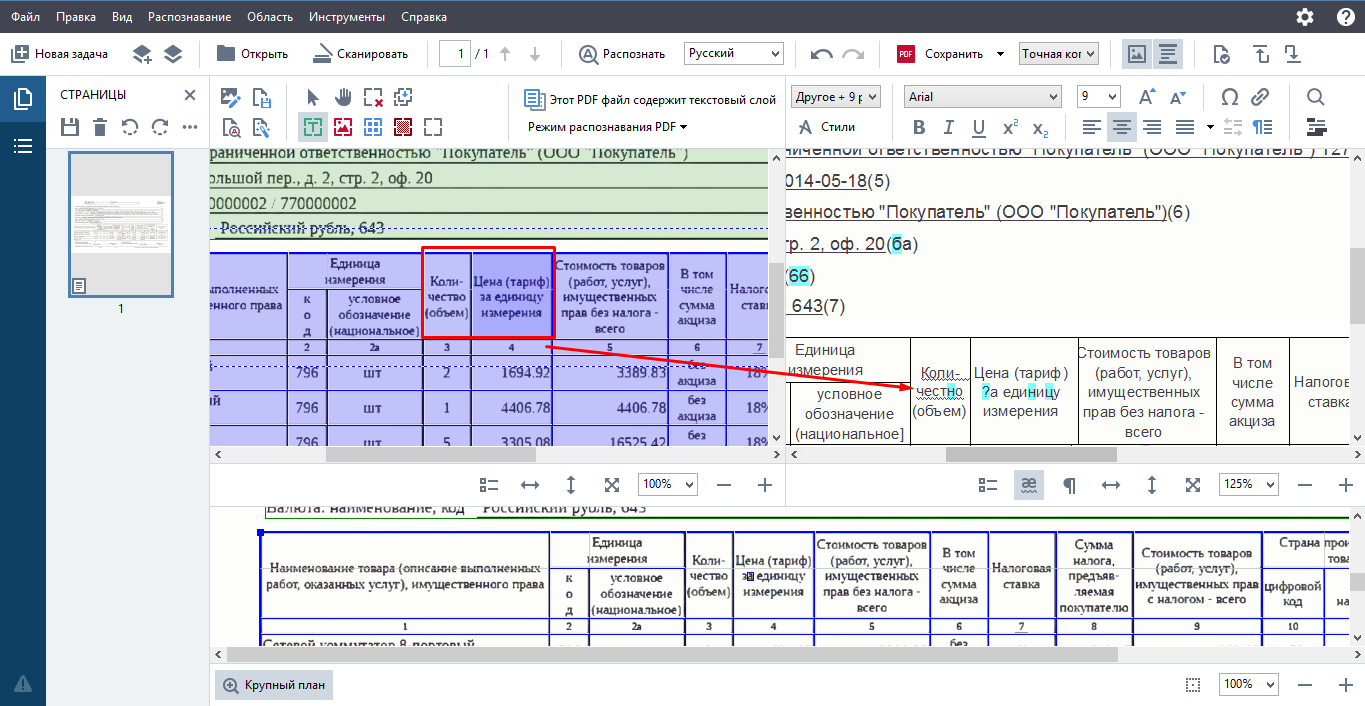
- Однако, была ситуация, что почти весь подобный документ распознался с меньшей точностью и данных для изменения вручную было уйма. Думаю, здесь можно было бы решить вопрос технически, но это затратило бы больше времени.
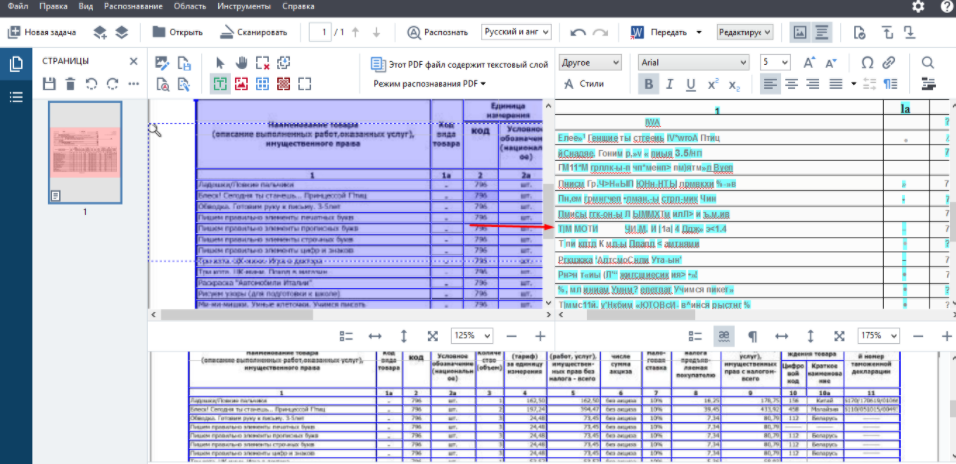
- Здесь можно настроить автоматическую конвертацию входящих документов, которые регулярно будут тянуться из указанной папки, по указанному расписанию.
- Он позволяет сравнивать версии документов, даже если они в разных форматах. При большом потоке документов и правок в них, это очень удобно.


От использования этого софта были приятные впечатления. Однако, когда я обратился к ценнику системного решения ABBYY Flexicapture (а мне нужно именно системное), то выяснил, что решение, особенно кастомизированное, обходится в довольно круглую сумму, около 400 тыс. руб./мес. и выше за 10 тыс. страниц.
Я стал искать альтернативу. Как освободить руки сотрудника, получить качественное распознавание документов и не переживать за сохранность и структуру данных.
И тут я решил получше разглядеть ELMA RPA, которую я уже изучал ранее.
Вендор предлагает перекинуть значительную часть работы по экспорту данных в ERP с плеч бухгалтеров на роботов. По сути, именно это решает поставленную передо мной задачу. Чтобы познакомиться с распознаванием в этой системе, я взял у вендора триальную версию системы.
Здесь я обнаружил, что распознавание не преследует цели конвертировать полученные данные в новый документ-файл.
Здесь главная цель — распознавание реквизитов документа и их передача в другие системы/сайты/приложения. Кроме того, роботы складывают всю информацию куда надо: автоматически находят нужные папки и сохраняют в необходимых форматах.
Какие виды распознавания в системе я посмотрел:
Распознавание по шаблону
Нам предлагается на основании шаблона документа распознать подгружаемый документ. Насколько мне известно, этот вид распознавания бесплатный, внутрь зашит движок Tesseract.
Что отметил:
- Этот вид распознавания работает именно со сканами формата jpg и png, pdf он пока не рассматривает. Но продукт еще молодой, думаю, все впереди.
- Этот вид распознавания входит в бесплатную версию Community Edition
- Удобно размечен текст по блокам, которые можно сопоставить, согласно переменным, которые мы создали в контексте робота. Таким образом вручную настроить, что именно тянем в распознавание.
- Нашу счет-фактуру он распознал 50/50, некоторые слова подменил как посчитал нужным. :)

Однако, вендор на данный кейс сообщил, что этот вид распознавания адаптирован под простые документы, с текстовой структурой или с легкими формами. И посоветовал для распознавания счета-фактуры использовать другой вид распознавания — intellect lab.
Процесс тот же, загружаем шаблон и по нему распознаем. Но здесь шаблон отправляется на облачный сервер.
От сервера получаем ответ (распознает такой тип документа или нет), и если распознается, то передается структура шаблона (переменные для маппинга), для сопоставления переменных, которые необходимо будет записать в RPA процессе.
В процессе воспроизведения мы отправляем уже документ, который хотели бы распознать и получаем ответ от iLab сервера о распознавании.
Что отметил по поводу этого распознавания:
- Здесь уже распознавание работает как программа сканирования документов pdf, и при этом работает и с форматами jpg и png.
- Качество документа не влияет на эффективность распознавания. Даже документы с плохим качеством распознаются корректно.
- Счет-фактура распозналась полностью и без подмен переменных.
- Робот сумел получить скан с почты, распознать его и создать его экземпляр в 1С. То есть автоматически сохранил файл там, где мы ему задали, что, естественно, крайне удобно.
- Входит в бесплатную Community Edition в виде распознавания документа в облаке. Подходит, если используем стандартные типы (СФ, УПД, АВР и др.), и, например до 100 документов в месяц или до 500 в год. (Стоит заметить, что считаем не в страницах, а в документах непосредственно.)
Сам процесс распознавания документов довольно сложно отобразить на видео, так как это происходит в коробке, а экран пустует несколько секунд. Поэтому я сделал отдельную запись распознанных данных в блокнот для визуализации.
Соответственно, эти же данные робот записывает в 1С, создавая там новый документ:
Что удалось выяснить по ценам: Если мы, например, хотим работать масштабно именно с ilab распознаванием, то за наши 10 000 документов придется выложить:
- примерно 180 000 руб. единовременно,
- плюс, допустим, 400 000 руб. покупка робота с оркестратором
- итого: 580 000 руб.
Робот бессрочный, а 10 000 документов на какое-то время хватит. Довольно выгодно получается, как минимум в том, что заплатим за все один раз.
Что понравилось в распознавании в этой платформе в целом:
- Можно настроить получение документов по событию, а также, например из электронной почты и любых других внешних источников. У меня пока была цель настроить получение с почты.
- Все считанные данные с документа можно спокойно записать в контекстные переменные и далее их передать в необходимые системы, приложения, сайты, ВМ и т д. И я не переписываю уже ничего руками.
- Скорость обработки. 15 секунд и объект распознан, а остальной порядок действий — это счет по минутам. Если заявиться с потоковым сканированием с большим количеством документов, думаю это не составит больших временных затрат.
- Много качественного функционала в свободном доступе, для небольших компаний им можно вполне обойтись.
Итого:
- Бесплатные программы справляются с задачей распознавания документов лучше, чем я предполагал, однако за счет них значительно ускорить работу с большим объемом не удастся
- ABBYY FineReader хорошо справляется с обработкой и распознаванием документов после, однако, чтобы получить системное решение, нужны большие финансовые возможности.
- ELMA RPA удивила по качеству распознавания документов, вариативностью, а также возможностям хранения и передачи после распознавания, но стоит учесть, что продукт молодой.
