
Многие знают и используют Terraform в повседневной работе, но для него до сих пор не сформировались лучшие практики. Каждой команде приходится изобретать свои подходы, методы.
Ваша инфраструктура почти наверняка начинается просто: несколько ресурсов + несколько разработчиков. Со временем она растёт во всевозможные стороны. Вы находите способы сгруппировать ресурсы в Terraform-модули, организовать код по папкам, и что здесь вообще может пойти не так? (известные последние слова)
Проходит время, и вы чувствуете, что ваша инфраструктура — это ваш новый питомец, но почему? Вас беспокоят необъяснимые изменения в инфраструктуре, вы боитесь прикасаться к инфраструктуре и коду — в итоге вы задерживаете новый функционал или снижаете качество…
После трёх лет управления на Github коллекцией community-модулей Terraform для AWS и долгосрочном поддержании Terraform в продакшене, Антон Бабенко готов поделиться своим опытом: как писать TF-модули, чтобы не было больно в будущем.
К концу доклада участники будут лучше знакомы с принципами управления ресурсами в Terraform, лучшими практиками, связанными с модулями в Terraform, и некоторыми принципами непрерывной интеграции, связанными с управлением инфраструктурой.
Видео:
Disclaimer: Замечу что доклад этот датирован ноябрем 2018 года — прошло уже 2 года. Рассматриваемая в докладе версия Terraform 0.11 уже не поддерживается. За прошедшие 2 года вышло 2 новых релизов, в которых появилась масса новшеств, улучшений и изменений. Прошу на это обратить внимание и сверятся с документацией.

Ссылки:
- terraform-community-modules + terraform-aws-modules
- antonbabenko/pre-commit-terraform — автоформатирование кода и документации
- antonbabenko/terrapin — генератор Terraform-модулей (WIP)
- antonbabenko/modules.tf-lambda — генератор Terraform-кода из визуальных диаграм (WIP)
- www.terraform-best-practices.com
- medium.com/@anton.babenko (Новые посты находятся на личном сайте www.antonbabenko.com)
- @antonbabenko — Twitter, и куча разных Slacks
Меня зовут Антон Бабенко. Кто-то из вас наверняка использовал код, который я писал. Я сейчас буду об этом говорить с большей уверенностью, чем когда-либо, потому что у меня есть доступ к статистике.
Я занимаюсь Terraform и являюсь активным участником и контрибьютором в большом количестве open source проектов, связанных с Terraform и Amazon с 2015-го года.
Примерно с тех пор я написал достаточно кода, чтобы изложить это в интересном виде. И об этом я попробую сейчас рассказать.
Я буду рассказывать о тонкостях и о специфике работы с Terraform. Но на самом деле это не является предметом для HighLoad. И сейчас вы поймете почему.
Со временем я начал писать Terraform-модули. Пользователи писали вопросы, я их переписывал. Потом я написал разные утилиты для форматирования кода с помощью pre-commit hook и т. д.
Было много интересных проектов. Мне нравится заниматься кодогенерированием, потому что я люблю, чтобы компьютер делал все больше и больше работы за меня и за программиста, поэтому сейчас работаю над генератором Terraform-кода из визуальных диаграмм. Возможно, кто-то из вас их видел. Это красивые коробочки со стрелочками. И я считаю, что это здорово, если можно нажать кнопочку «Экспорт» и получить это все как код.
Я из Украины. Я живу много лет в Норвегии.
Также информация для этого доклада была собрана от людей, которые знают мое имя и находят меня в социальных сетях. У меня почти всегда один и тот же ник.

https://github.com/terraform-aws-modules
https://registry.terraform.io/namespaces/terraform-aws-modules
Как я упомянул, я являюсь главным мейнтейнером Terraform AWS modules, который является одной из самых больших репозиторий на GitHub, где мы хостим модули для самых распространенных задач: VPC, Autoscaling, RDS.

И то, что вы слышали сейчас, это самое-самое базовое. Если вы сомневаетесь, что вы понимаете, что такое Terraform, то лучше проводить время где-нибудь в другом месте. Здесь будет много технических терминов. И уровень доклада я не постеснялся заявить самым максимальным. Это значит, что я могу рассказывать, используя все-все возможные термины без особого объяснения.

Terraform появился в 2014-ом году как утилита, которая позволяла писать, планировать и управлять инфраструктурой как код. Ключевое понятие здесь «инфраструктура как код».
Вся документация, как я сказал, написана на terraform.io. Я надеюсь, что большинство знают об этом сайте и прочитали документацию. Если так, то вы в нужном месте.

Вот так выглядит обычный Terraform-конфигурационный файл, где мы сначала определяем какие-то переменные.
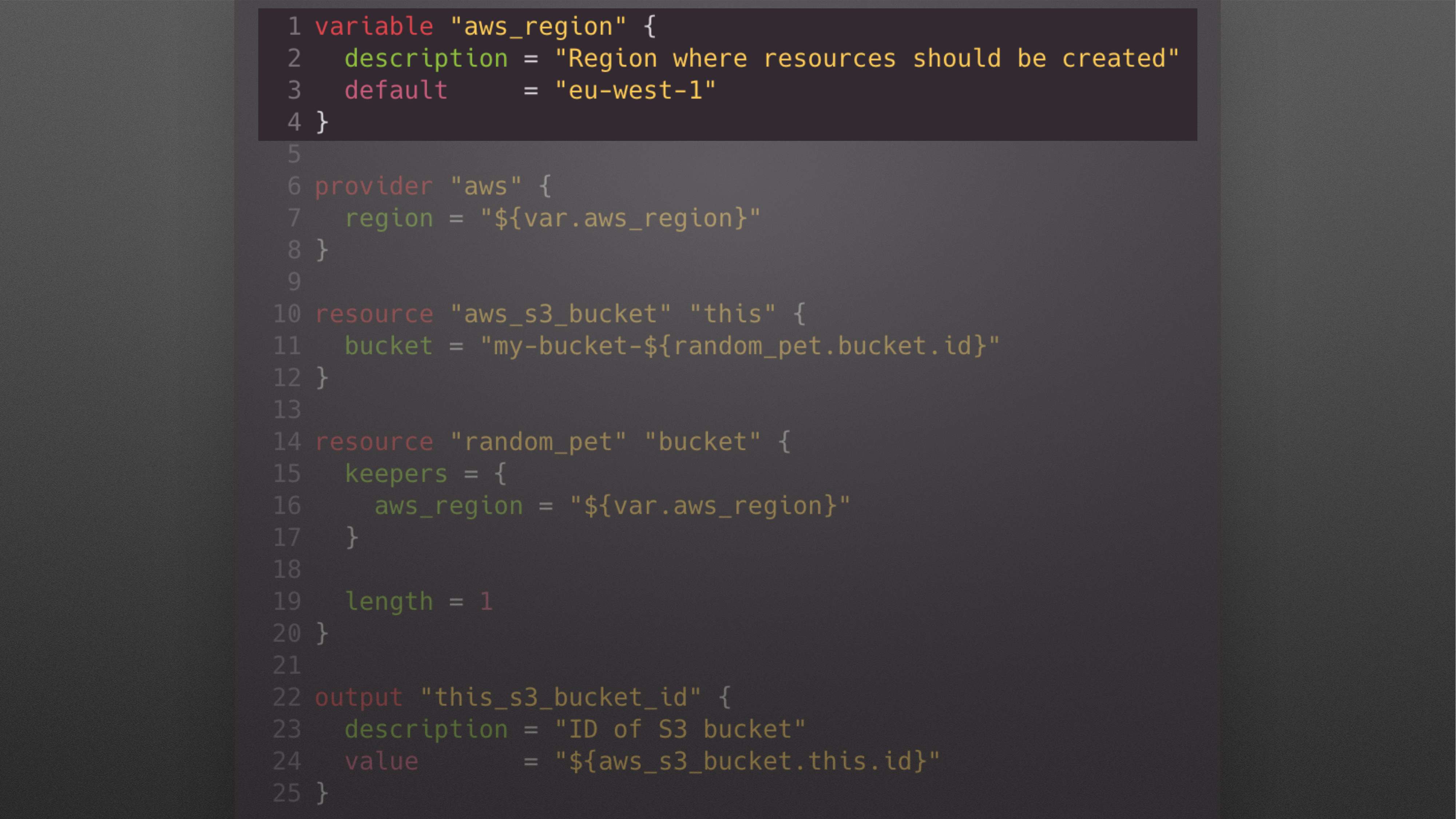
В данном случае мы определяем «aws_region».

Потом мы описываем, какие ресурсы мы хотим создать.
Запускаем какие-то команды, в частности «terraform init» для того, чтобы загрузить зависимости, провайдеры.

И запускаем команду «terraform apply» для того, чтобы проверить соответствует ли указанная конфигурация тем ресурсам, которые создали. Т. к. мы ничего не создавали до этого, то Terraform предлагает нам создать эти ресурсы.
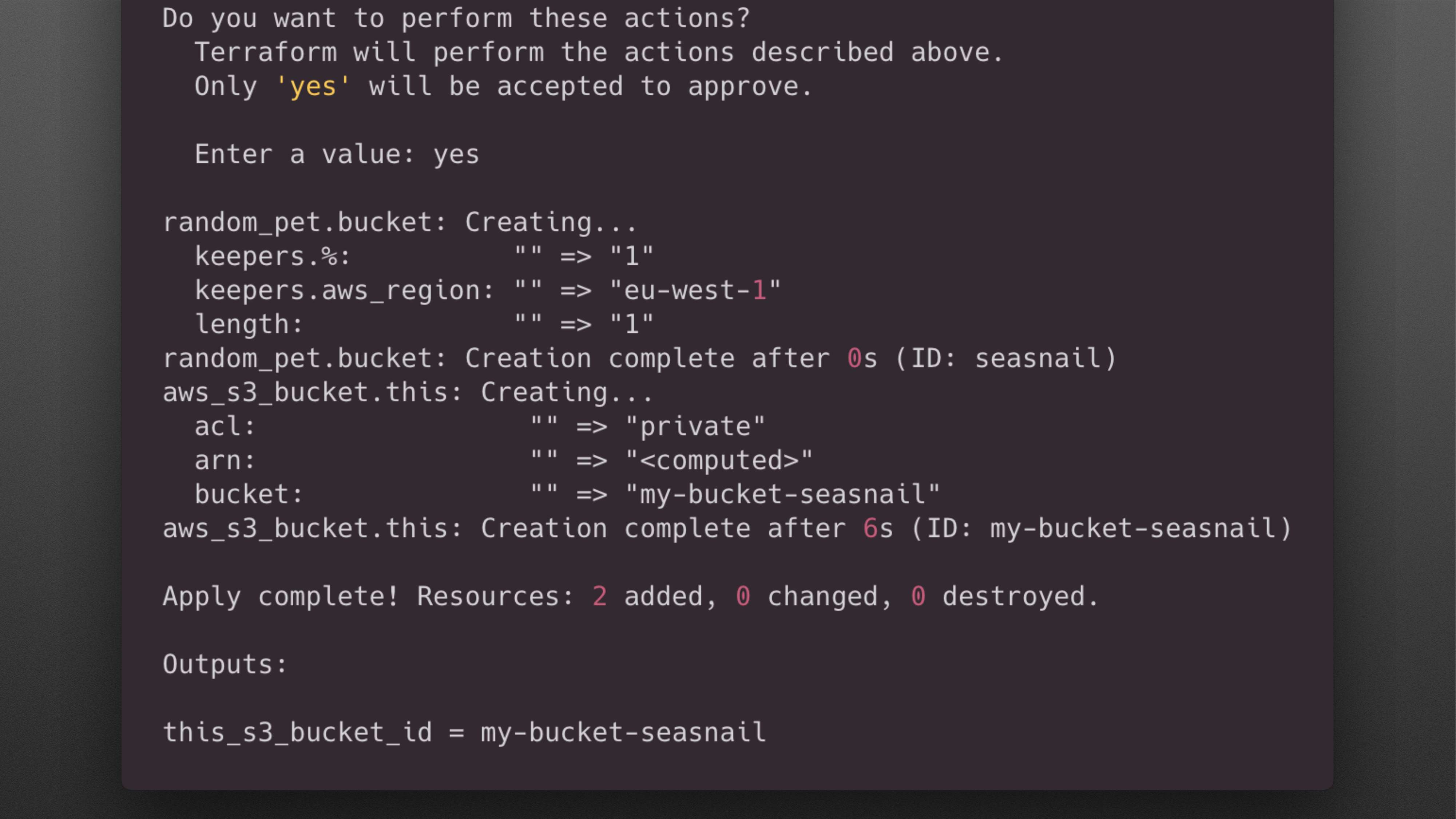
Мы подтверждаем это. Таким образом мы создаем bucket, который называется seasnail.

Есть также несколько похожих утилит. Многие из вас, кто пользуется Amazon, знают AWS CloudFormation или Google Cloud Deployment Manager, или Azure Resource Manager. У каждого из них есть своя какая-то реализация для управления ресурсами внутри каждого из этих public cloud провайдеров. Terraform особенно полезен в той связи, что он позволяет управлять более 100 провайдерами. (Подробнее тут)

Цели, которые преследовал Terraform с самого начала:
- Terraform дает единый вид ресурсов.
- Позволяет поддерживать все современные платформы.
- И Terraform с самого начала задумывался как утилита, которая позволяет менять инфраструктуру безопасно и предсказуемо.
В 2014-ом году слово «предсказуемо» звучало очень необычно в данном контексте.

Terraform является универсальной утилитой. Если у вас есть API, то можно управлять совершенно всем:
- Можно использовать более 120 провайдеров для управления всем, к чему душа лежит.
- Например, можно использовать Terraform для описания доступа к GitHub репозиториям.
- Можно даже баги в Jira создавать и закрывать.
- Можно управлять New Relic-метриками.
- Можно даже файлы в dropbox создавать, если очень хочется.
Это все достигается с помощью Terraform-провайдеров, у которых открытый API, которые можно описать на Go.

Допустим, мы начали использовать Terraform, прочитали какую-то документацию на сайте, посмотрели какое-то видео, начали писать main.tf, как я показывал на предыдущих слайдах.

И у вас все классно, у вас получился файл, который создает VPC.
Если вы хотите создать VPC, то вы указываете примерно вот эти 12 строк. Описываете в каком регионе вы хотите создать, какой cidr_block IP-адресов использовать. И все.

Естественно, постепенно проект будет расти.

И вы будете добавлять туда кучу нового всего: ресурсы, источники данных, вы будете интегрироваться с новыми провайдерами, неожиданно вы захотите использовать Terraform для того, чтобы управлять пользователями в вашем GitHub-аккаунте и т. д. Вы можете захотеть использовать разные DNS-провайдеры, скрещивать все подряд. Terraform легко позволяет это делать.

Рассмотрим следующим пример.
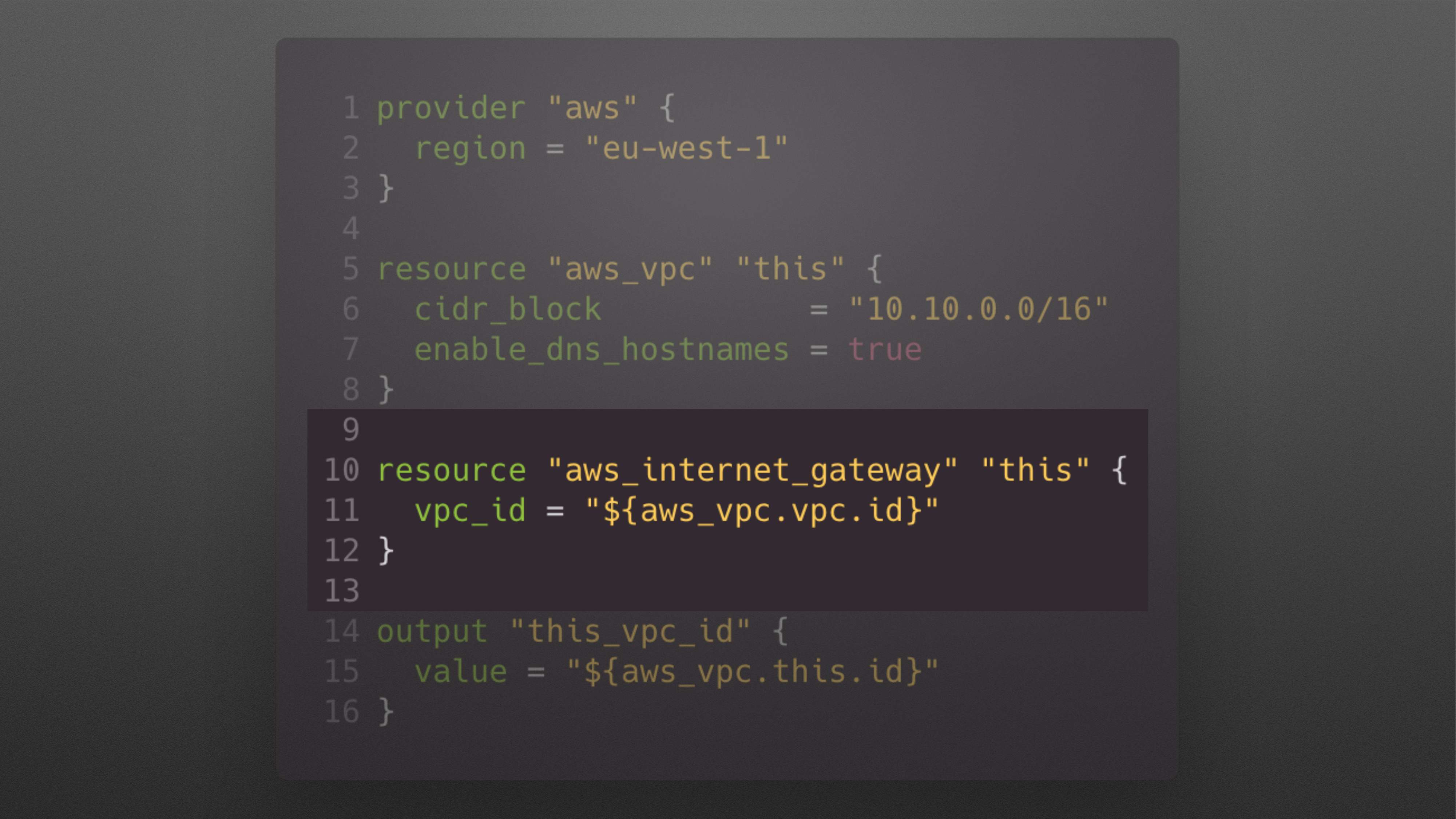
Вы постепенно добавляете internet_gateway, потому что вы хотите, чтобы ресурсы из вашего VPC имели доступ в интернет. Это хорошая идея.
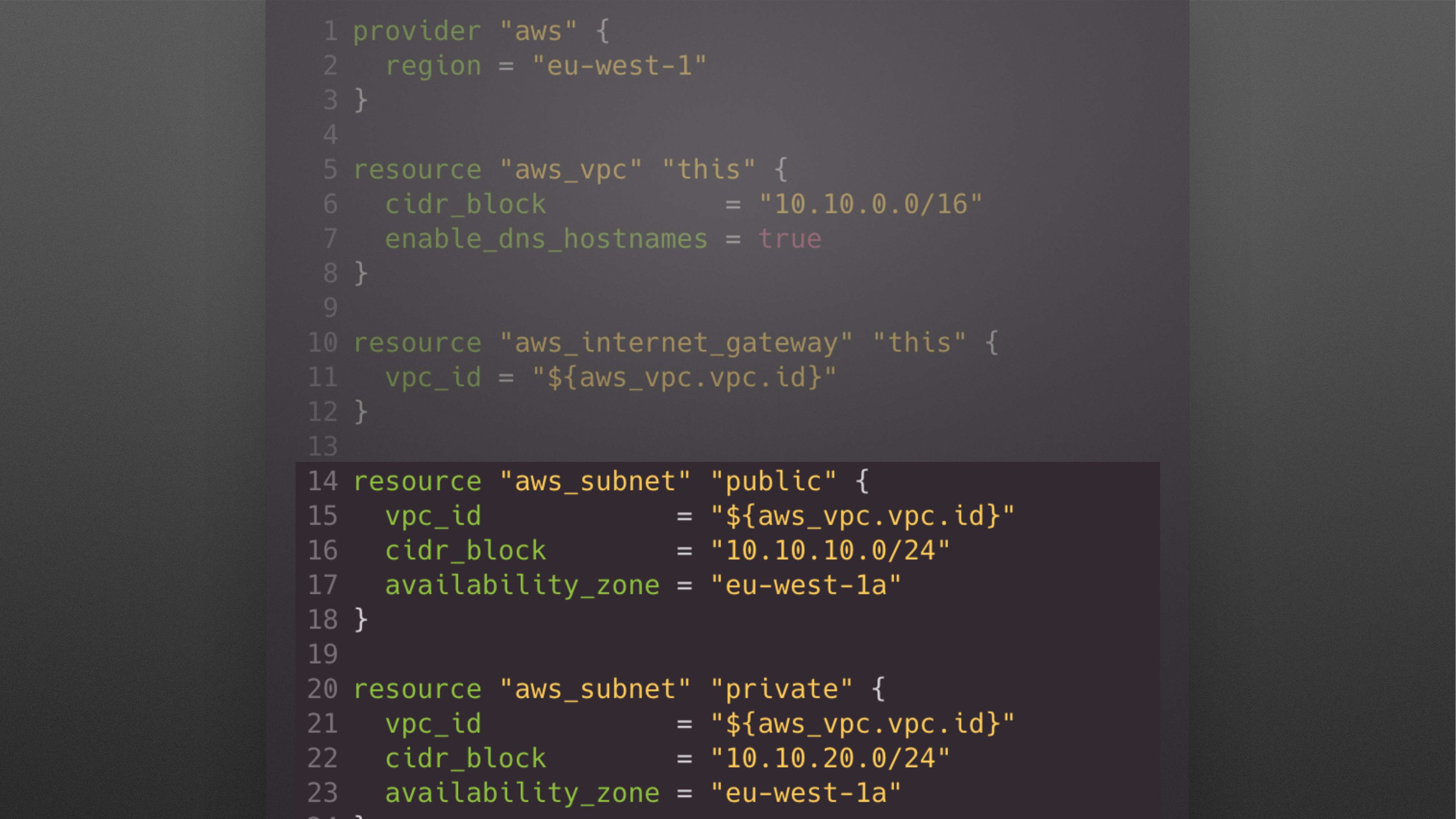
В итоге получается вот такой main.tf:

Это верхняя часть main.tf.
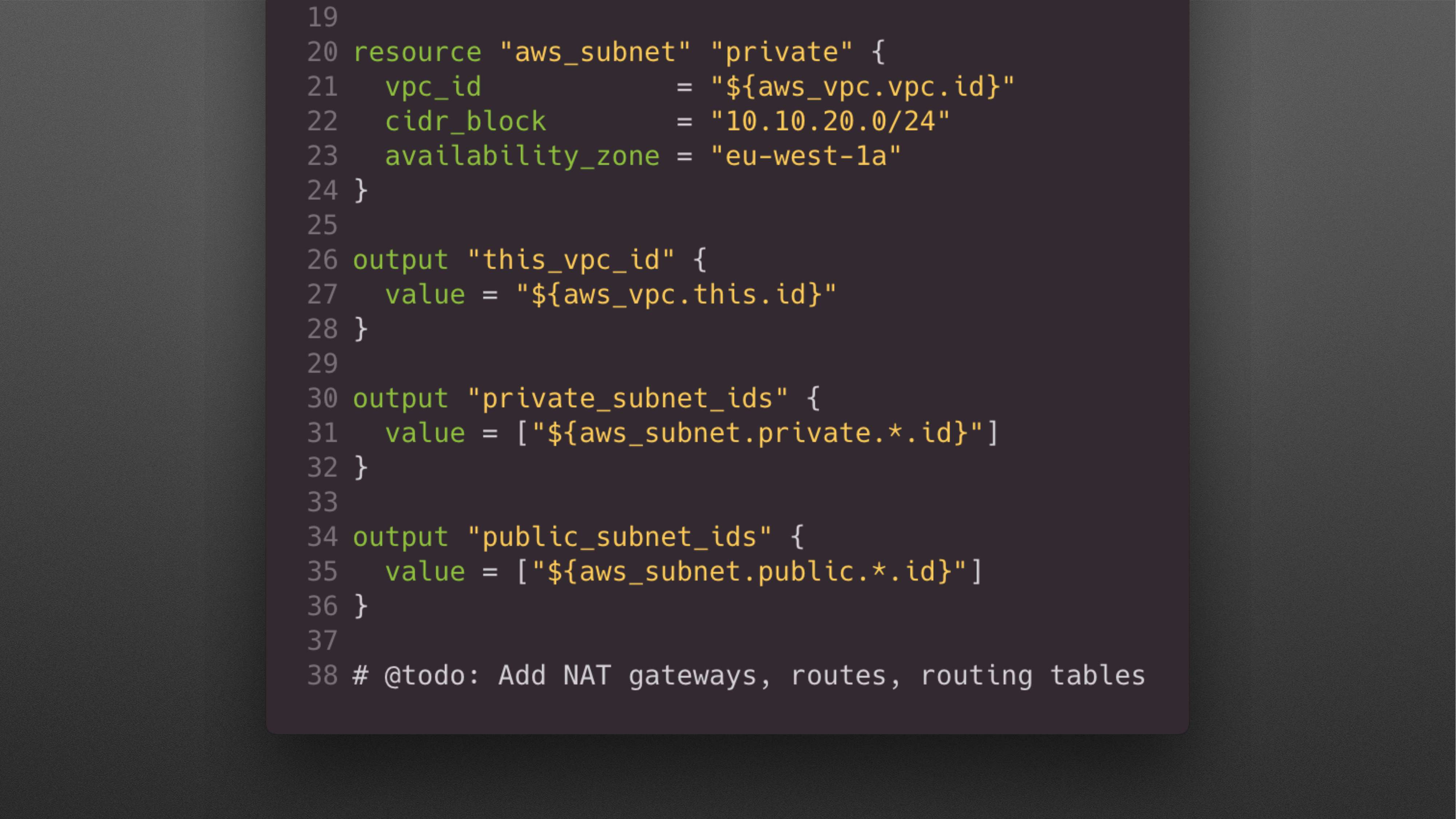
Это нижняя часть main.tf.
Потом вы добавляете subnet. К тому моменту, когда вы захотите добавить NAT gateways, routes, routing tables и кучу других subnets, у вас будет не 38 строк, а примерно 200-300 строк.

Т. е. ваш main.tf файл постепенно растет. И довольно часто люди складывают все в один файл. В main.tf появляется 10-20 Kb. Представьте, что 10-20 Kb – это текстовый контент. И всё со всем связано. С этим работать постепенно становится сложно. 10-20 Kb – это хороший user case, бывает и больше. И не всегда люди считают, что это плохо.
Как и в обычном программировании, т. е. не инфраструктура как код, мы привыкли использовать кучу разных классов, пакетов, модулей, группировки. Terraform позволяет делать примерно тоже самое.

- Код растет.
- Зависимости между ресурсами тоже растут.

И у нас возникает большая-большая нужда. Мы понимаем, что так жить мы дальше не можем. У нас код становится необъятным. 10-20 Kb – это, конечно, не очень необъятный, но это мы говорим только о network stack, т. е. вы добавили только сетевые ресурсы. Мы не говорим еще об Application Load Balancer, deployment ES cluster, Kubernetes и т. д., куда еще легко можно вплести 100 Kb. Если вы все это напишите, то вы очень скоро узнаете, что Terraform предоставляет Terraform-модули.

Terraform-модули – это самодостаточная Terraform-конфигурация, которая управляется как группа. Это все, что надо знать о Terraform-модулях. Они никакие не умные, они не позволяют делать вам какие-то сложные подключения в зависимости от чего-то. Это все ложится на плечи разработчиков. Т. е. это просто какая-то Terraform-конфигурация, которую вы уже написали. И можно просто ее вызывать как группу.

Таким образом мы пытаемся понять, как мы будем оптимизировать наши 10-20-30 Kb кода. Мы постепенно понимаем, что надо использовать какие-то модули.
Первый тип модулей, который встречается, это ресурсные модули. Они не понимают, о чем ваша инфраструктура, о чем ваш бизнес, где и какие условия. Это именно те модули, которые я вместе с open source сообществом администрируем, и которые мы выдвигаем, как самый начальный building blocks для вашей инфраструктуры.

Пример ресурсного модуля.

Когда мы вызываем ресурсный модуль, мы указываем с какого пути мы должны загрузить его содержимое.

Мы указываем какой версии мы хотим загрузить.

Мы передаем кучу аргументов туда. И все. Это все, что нам надо знать, когда мы используем этот модуль.

Многие думают, что если использовать последнюю версию, то все будет стабильно. Но нет. Инфраструктура должна быть версионной, мы четко должны ответить, какой версии была задеплоена та или иная компонента.
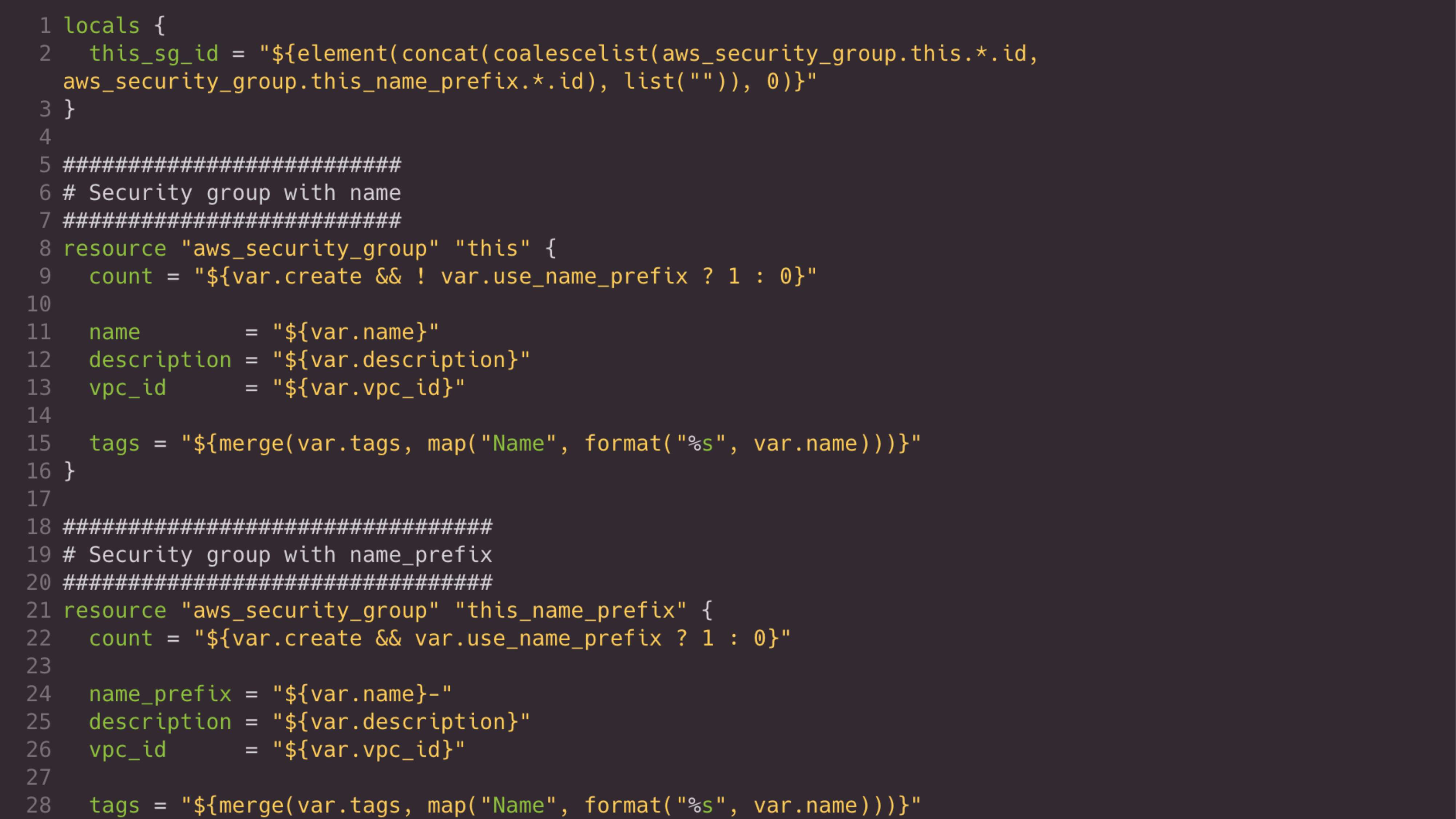
Перед вами код, который находится внутри этого модуля. Модуль security-group. Здесь скролл идет до 640-ой строчки. Создание security-croup ресурса в Amazon во всевозможной конфигурации – это очень нетривиальная задача. Недостаточно просто создать security-group и сказать, какие правила ей передавать. Это было бы очень просто. Внутри Amazon есть миллион разных ограничений. Например, если вы используете VPC endpoint, prefix list, различные API и пытается это всё со всем скрестить, то Terraform не позволяет вам это сделать. И Amazon API тоже не позволяет это. Поэтому надо спрятать эту всю страшную логику в модуль и пользователю выдавать код, который выглядит только вот так.
Пользователю не надо знать, как внутри оно сделано.

Второй тип модулей, который состоит из ресурсных модулей, уже решает задачи, которые более применимы для вашего бизнеса. Часто это место, которое является расширением для Terraform и задает какие-то жесткие значения для тегов, для стандартов компании. Также там можно добавлять функционал, который Terraform не позволяет сейчас использовать. Это именно сейчас. Сейчас версия 0.11, которая вот-вот отойдет в прошлое. Но все равно препроцессоры, jsonnet, cookiecutter и куча других вещей являются тем вспомогательным механизмом, который надо использовать для полноценной работы.
Дальше я покажу некоторые примеры из этого.
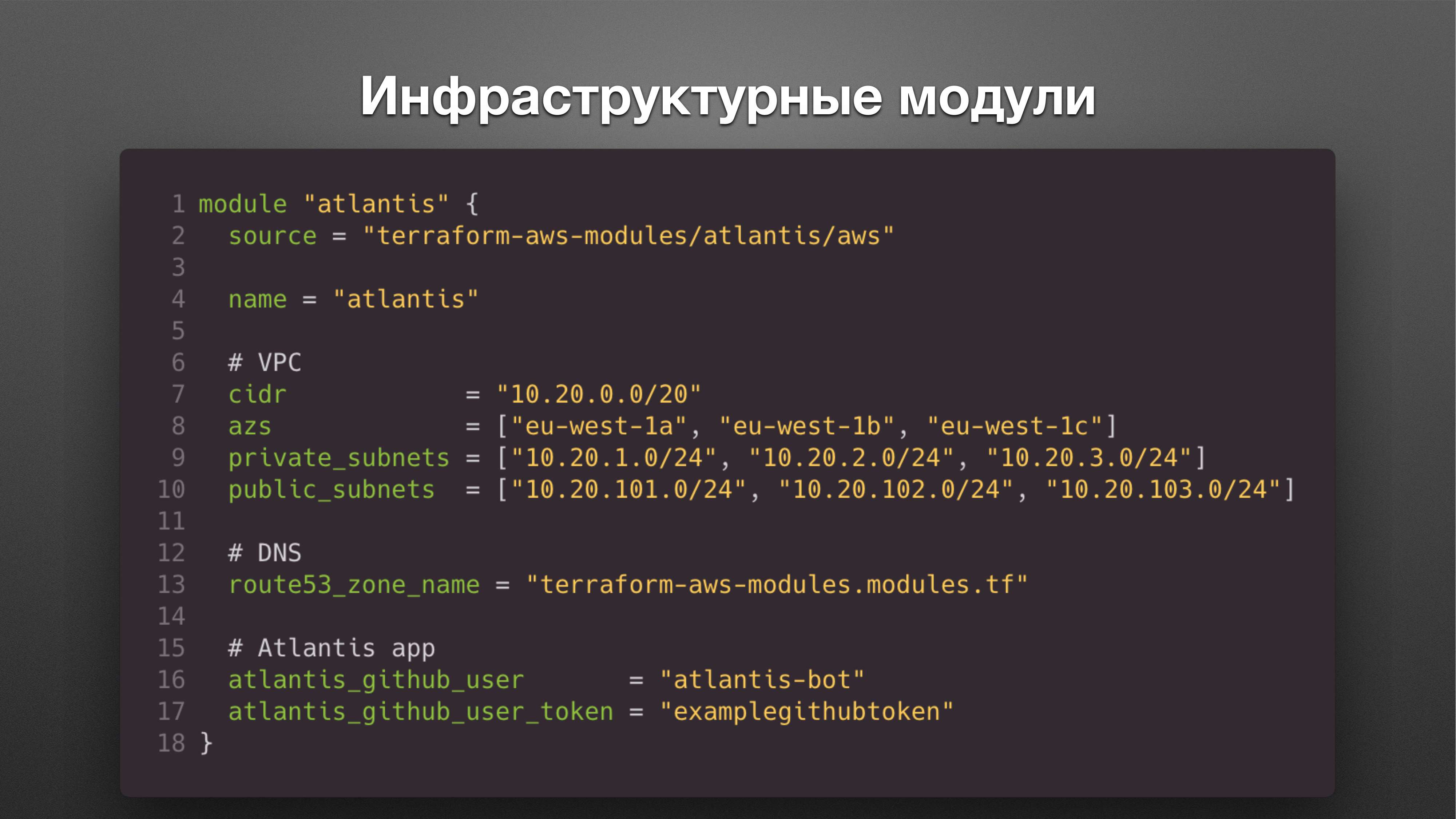
Инфраструктурный модуль вызывается точно таким же способом.

Указывается источник, откуда загрузить контент.

Передается куча значений, которые передаются в этот модуль.
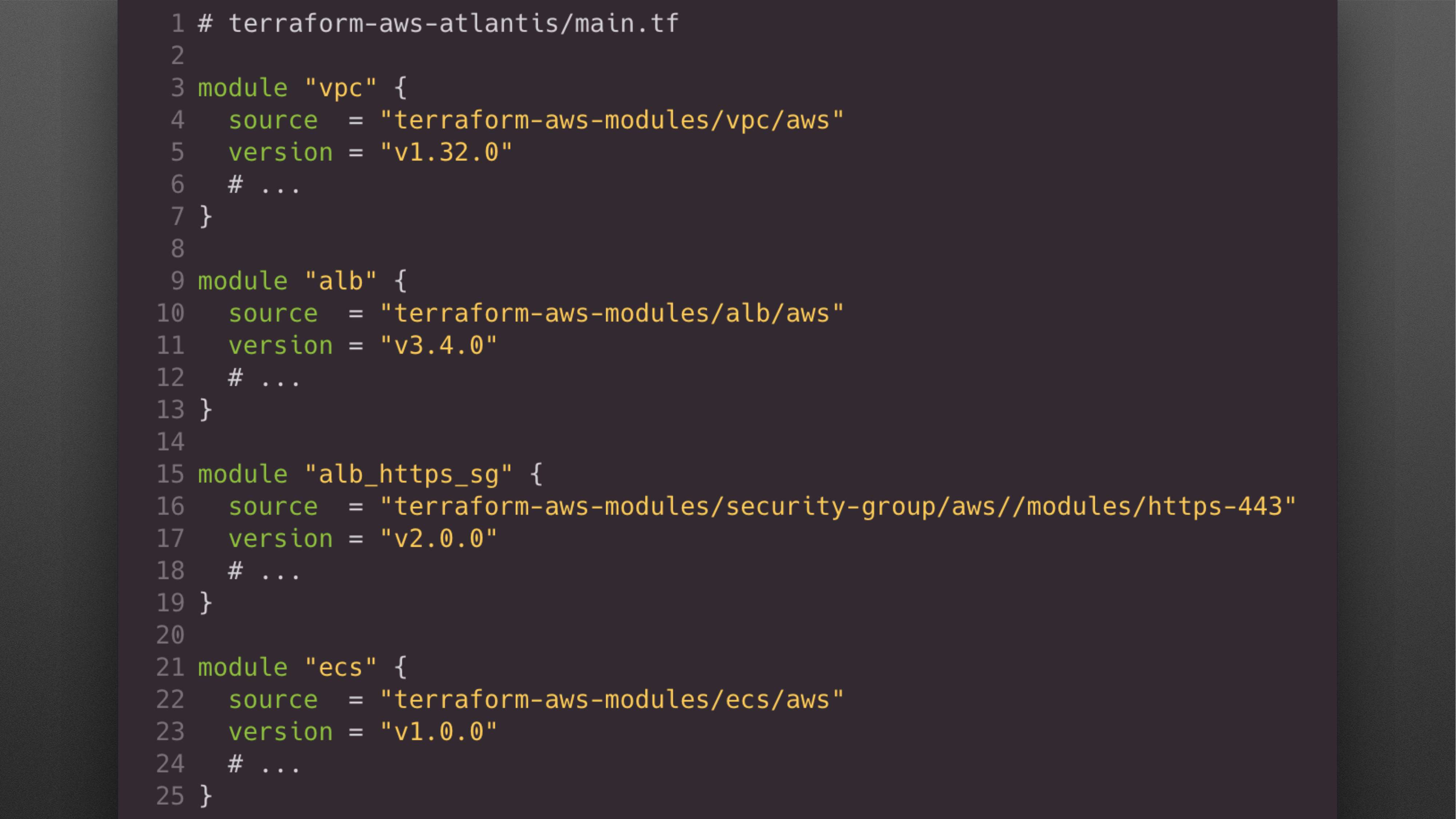
Далее внутри этого модуля вызывается куча ресурсных модулей для создания VPC или Application Load Balancer, или для создания security-group или для Elastic Container Service кластера.

Есть два типа модулей. Это важно понимать, потому что большинство информации, которую я сгруппировал в этом докладе, не написана в документации.
И документация в Terraform прямо сейчас достаточно проблематичная, потому что она просто говорит, что есть такие фичи, вы можете их использовать. Но она не говорит, как эти фичи использовать, почему так лучше использовать. Поэтому очень большое количество людей пишут что-то, с чем потом нельзя жить.

Давайте дальше посмотрим, как писать эти модули. Потом посмотрим, как их вызывать и как работать с кодом.
Terraform Registry — https://registry.terraform.io/
Совет № 0 – это не писать ресурсные модули. Большинство этих модулей уже написано за вас. Как я говорил, они open source, они не содержат никакой вашей бизнес-логики, в них нет захардкоженных значений для IP-адресов, паролей и т. д. Модуль является очень flexible. И он уже, скорее всего, написан. Для ресурсов от Amazon модулей много. Около 650. И большинство из них хорошего качества.

На данном примере к вам пришел кто-то и сказал: «Я хочу иметь возможность управлять базой данных. Создай модуль, чтобы я мог создавать базу данных». Человек не знает подробностей реализации ни Amazon, ни Terraform. Он просто говорит: «Я хочу управлять MSSQL». Т. е. мы подразумеваем, что он будет вызывать наш модуль, передаст туда тип движка, укажет time-зону.

И человек не должен знать, что мы внутри этого модуля будем создавать два разных ресурса: один для MSSQL, второй для всего остального только потому, что в Terraform 0.11 нельзя указывать значения time-зоны необязательным.

И на выходе из этого модуля человек будет иметь возможность просто получать адрес. Он не будет знать с какой базы данных, с какого ресурса мы внутри это все создаем. Это очень важный элемент скрытия. И это применимо не только для тех модулей, которые находятся в public в open source, а также для тех модулей, которые вы будете писать внутри своих проектов, команд.

Вот это второй аргумент, который является довольно важным, если вы используете Terraform какое-то время. У вас есть репозиторий, в котором вы складываете все свои Terraform-модули для вашей компании. И вполне нормально, что со временем этот проект вырастет до размера одного-двух мегабайт. Это нормально.
Но проблема заключается в том, как Terraform вызывает эти модули. Например, если вы будете вызывать модуль для создания каждого индивидуального пользователя, то Terraform сначала будет загружать весь репозиторий, а потом переходить в папку, где находятся конкретно этот модуль. Таким образом вы будете каждый раз загружать по одному мегабайту. Если вы управляете 100 или 200 пользователями, то вы загрузите 100 или 200 мегабайт, а потом уже перейдете в ту папку. Таким образом, естественно, вы не хотите каждый раз, когда нажимаете «Terraform init» загружать кучу всего.

https://github.com/mbtproject/mbt
Есть два решения этой проблемы. Первое заключается в том, чтобы использовать относительные пути. Таким образом вы в коде указываете, что папка локальная (./). И перед тем, как что-то запускать, вы делаете Git clone этого репозитория локально. Таким образом вы делаете это один раз.
Есть, конечно, куча downsides. Например, что нельзя использовать versioning. И с этим иногда сложно жить.
Второе решение. Если у вас много подмодулей и у вас есть уже какой-то устаканенный pipeline, то есть проект MBT, который позволяет собирать из монорепозитория много разных пакетов и загружать их на S3. Это очень хороший способ. Таким образом файл iam-user-1.0.0.zip будет весить всего лишь 1 Kb, потому что код для создания этого ресурса очень маленький. И это будет намного быстрее работать.

Поговорим о том, что нельзя использовать в модулях.

Почему в модулях это зло? Самая страшная вещь – это assume user. Assume user – это такой вариант аутентификации в провайдер, который могут использовать разные люди. Например, мы все будем ассюмить роль. Это значит, что Terraform будет принимать эту роль. И потом с этой ролью будет выполнять остальные действия.
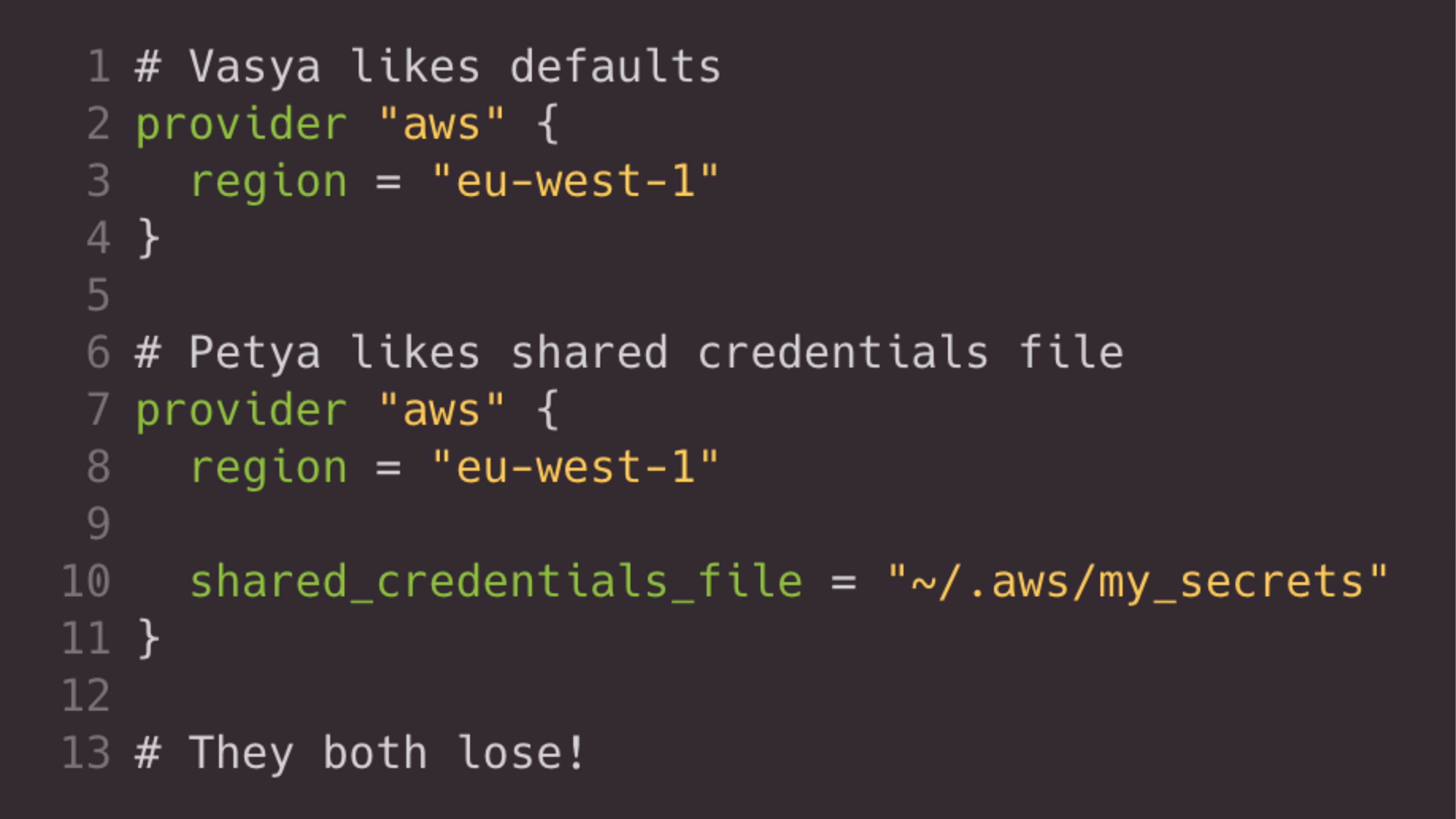
И зло заключается в том, что если Вася любит подключаться к Amazon одним способом, например, используя по умолчанию переменное окружение, а Петя любит использовать свой shared key, который у него находится в секретном месте, то в Terraform нельзя указывать и то и другое. И для того, чтобы они не испытывали страданий, не надо этот блок указывать в модуле. Это надо указывать уровнем выше. Т. е. у нас есть ресурсный модуль, инфраструктурный модуль и композиция сверху. И где-нибудь повыше это надо указывать.

Второе зло заключается в provisioner. Здесь зло не настолько тривиальное, потому что если пишите код и для вас он работает, то вы можете подумать, что если он работает, то зачем менять.

Зло заключается в том, что этот provisioner вы не всегда контролируете, когда он конкретно будет запускаться, во-первых. И, во-вторых, вы не контролируете, что значит aws ec2, т. е. мы говорим сейчас про Linux или про Windows. Таким образом, вы не можете писать что-то, что будет работать одинаково в разных операционных системах или для разных user cases.

Самый распространенный пример, который в том числе указан в официальной документации, это то, что если вы пишите aws_instance, указываете кучу аргументов, то ничего плохого в этом нет, если вы укажете там и provisioner «local-exec» и запустите свой ansible-playbook.

На самом деле – да, ничего плохого в этом нет. Но буквально скоро вы осознаете, что вот эта штука local-exec не существует, например, в launch_configuration.

И когда вы используете launch_configuration, и вы хотите из одного instance создать autoscaling group, то в launch_configuration нет понятия «provisioner». Там есть понятие «user data».
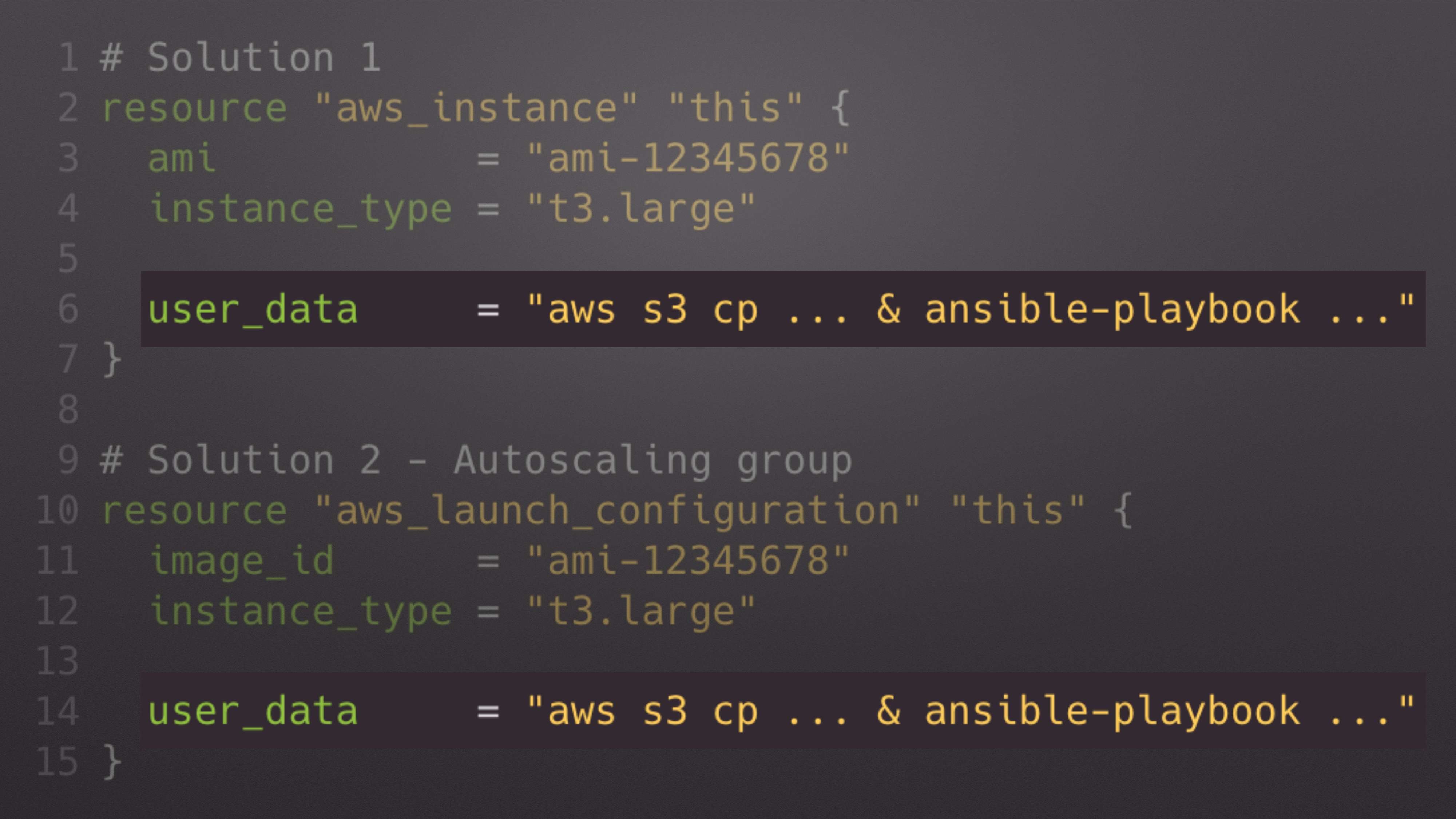
Поэтому более универсальным решением является использование user data. И будет запускаться либо на самом instance, когда instance включится, либо в этом же user data, когда autoscaling group будет использовать этот launch_configuration.

Если все-таки есть желание запустить provisioner, потому что он является склеивающим компонентом, когда один ресурс будет создан и в этот момент надо запустить свой provisioner, свою команду. Таких ситуаций очень много.
И самый правильный ресурс для этого называется null_resource. Null_resource – это фиктивный ресурс, который на самом деле не создается никогда. Он ничего не трогает, нет API, нет autoscaling. Но он позволяет регулировать, когда запускать команду. В данном случае запускается команда во время создания.

Ссылка http://bit.ly/common-traits-in-terraform-modules
Есть несколько признаков. Я не буду останавливаться на всех признаках очень детально. Есть статья об этом. Но если вы работали с Terraform или использовали чужие модули, то вы часто замечали, что многие модули, как и большую часть кода в open source, люди пишут для своих каких-то нужд. Человек его написал, решил свою задачу. Заколбасил его в GitHub, пускай живет. Он будет жить, но если там нет никакой документации и примеров, то никто им пользоваться не будет. И если там нет функционала, который позволяет решать чуть больше, чем его конкретную задачу, то им тоже никто не будет пользоваться. Есть очень много способов потерять пользователей.
Если вы хотите написать что-то, чтобы люди этим пользовались, то я рекомендую следовать этим признакам.
Это:
- Документация и примеры.
- Полный функционал.
- Разумные значения по умолчанию.
- Чистый код.
- Тесты.
Тесты – это отдельная ситуация, потому что их довольно сложно написать. Я больше верю в документацию и в примеры.

Итак, мы посмотрели, как писать модули. Есть два аргумента. Первый, который наиболее важный, это не пиши, если можешь, т. к. кучу-куча людей уже сделали эти задачи до вас. И второй, если все-таки решился, то провайдеры в модулях и provisioner старайся не использовать.
Это серая часть документации. Вы можете сейчас подумать: «Что-то непонятно. Не убедил». Но посмотрим через полгода.

Теперь поговорим о том, как вызывать эти модули.
Мы понимаем, что со временем наш код растет. У нас уже не один файл, у нас уже 20 файлов. Все они лежат в одной папке. Или, может, в пяти папках. Может быть, мы начинаем их как-то разбивать по регионам, по каким-то компонентам. Потом мы понимаем, что теперь у нас какие-то зачатки синхронизации, оркестрации должны возникать. Т. е. должны понять, что нам делать, если мы поменяли сетевые ресурсы, что нам делать с остальными нашими ресурсами, как вызывать эти зависимости и т. д.

Есть две крайности. Первая крайность – это все в одном. У нас есть один мастер-файл. До поры до времени это был официальная best practice на сайте Terraform.
Но сейчас это написано как deprecated и убрано. Со временем Terraform-сообщество поняло, что это далеко не best practice, потому что люди начинают использовать проект в разных видах. И есть проблемы. Например, когда мы указываем все зависимости в одном месте. Бывает ситуации, когда мы нажимаем «Terraform plan» и пока Terraform обновит состояния всех ресурсов, может пройти куча времени.
Куча времени – это, например, 5 минут. Для кого-то это куча времени. Я видел случаи, когда это занимало 15 минут. 15 минут AWS API дергался для того, чтобы понять, что со состоянием каждого ресурса. Это очень большая область.
И, естественно, появится связанная проблема, когда вы захотите поменять что-то в одном месте, потом подождали 15 минут, а оно вам выдало полотно каких-то изменений. Вы плюнули, написали «Yes», и что-то пошло не так. Это вполне реальный пример. Terraform не старается вас отгородить от проблем. Т. е. пишите, что хотите. Будут проблемы – ваши проблемы. Пока Terraform 0.11 не старается вам помочь никак. В 0.12 есть определенные интересные места, которые позволяют вам сказать: «Вася, ты действительно этого хочешь, можешь одумаешься?».

Второй способ заключается в уменьшение этой области, т. е. можно меньше связывать вызовы одного места из другого места.
Единственная проблема в том, что нужно писать больше кода, т. е. нужно описывать переменные в большом количестве файлов, обновлять это. Кому-то это не нравится. Для меня это нормально. А некоторые думают: «Зачем это писать в разных местах, я это все в одном месте заколбасю». Можно и так, но это вторая крайность.

У кого это все живет в одном месте? Один, два, три человека, т. е. кто-то использует.
А кто вызывает один конкретно компонент, один блок или один инфраструктурный модуль? Человек пять-семь. Это здорово.

Самый частый ответ – это где-то посередине. Если проект большой, то у вас часто будет ситуация, когда ни то решение не годится и там не все получается, поэтому у вас получается смесь. В этом ничего плохого нет, лишь бы вы понимали, что есть преимущество и у того, и у того.

Если изменилось что-то в stack VPC и вы захотели применить эти изменения EC2, т. е. вы захотели обновить autoscaling group, потому что у вас появилась новая subnet, то такого рода зависимости я называю оркестрацией. Есть какие-то решения: кто как использует?
Я могу подсказать, какие есть решения. Можно использовать Terraform для того, чтобы делать магию, а можно использовать make-файлы для использования Terraform. И смотреть, если там что-то поменялось, можно тут запустить.

Как вам такое решение? Кто-то верит, что это классное решение? Я вижу улыбку, видать сомнения закрались.

Конечно, не повторяйте это дома. Terraform никогда не был создан для того, чтобы запускаться из Terraform.
Мне на одном докладе сказали: «Нет, это не будет работать». Дело в том, что оно и не должно работать. Хоть оно и выглядит так эффектно, когда ты можешь из Terraform запустить Terraform, а там еще Terraform, но не надо так делать. Terraform должен всегда запускаться очень просто.

https://github.com/gruntwork-io/terragrunt/
Если у вас есть нужна в оркестрации вызовов, когда поменялось что-то в одном месте, то есть Terragrunt.
Terragrunt – это утилита, это надстройка над Terraform, которая позволяет координировать и оркестрировать вызовы инфраструктурных модулей.

Типичный Terraform-конфигурационный файл выглядит вот так.
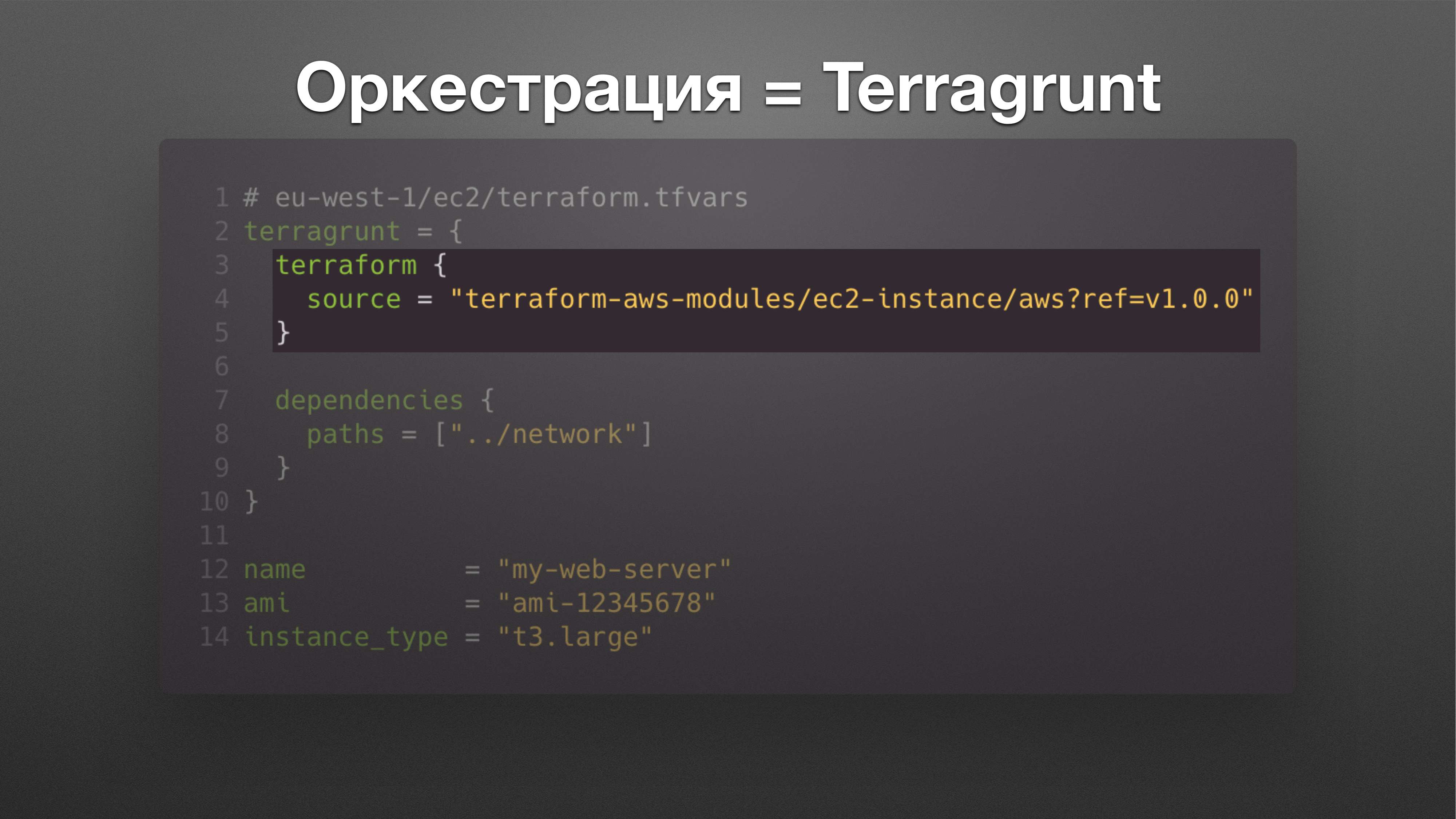
Вы указываете, какой конкретно модуль вы хотите вызвать.

Какие у модуля есть зависимости.

И какие аргументы этот модуль принимает. Это все, что нужно знать о Terragrunt.
Документация там есть, 1 700 звездочек на GitHub тоже есть. Но в большинстве случаев это то, что надо знать. И это очень легко вживить в компании, которые только начали работать с Terraform.

Таким образом, оркестрация – это Terragrunt. Другие варианты есть.

Теперь давайте поговорим, как работать с кодом.
Если у вас есть необходимость добавить новые фичи в код в большинстве случаев это легко. Вы пишите новый ресурс, тут все просто.

Если у вас есть какой-то ресурс, который вы создали заранее, например, вы про Terraform узнали после того, как вы открыли AWS-аккаунт и хотите использовать те ресурсы, которые у вас уже есть, то будет уместно расширить свой модуль таким образом, чтобы он поддерживал использование существующих ресурсов.

И поддерживал создание новых ресурсов, используя ресурс block.

На выходе мы всегда возвращаем output id в зависимости оттого, что было использовано.

Вторая очень существенная проблема в Terraform 0.11 – это работа со списками.

Сложность заключается в том, что если мы имеем такой список users.

И когда мы создаем этих users, используя block resource, то все проходит нормально. Мы проходим по всему списку, создаем каждому файлик. Все нормально. И потом, например, user3, который по середине, должен быть убран отсюда, то все ресурсы, которые были созданы после него, они будут пересоздаваться, потому что индекс изменится.

Работа со списками в stateful-окружении. Что такое stateful-окружение? Это та ситуация, когда возникает новое значение при создании этого ресурса. Например, AWS Access Key или AWS Secret Key, т. е. когда мы создаем user’а, нам приходит новый Access или Secret Key. И каждый раз, когда мы будем удалять какого-то user’а, у этого user’а будет новый ключ. Но это не по фэншуй, потому что user не захочет с нами дружить, если мы будем каждый раз создавать нового user’а для него, когда кто-то покидает команду.

Решение такое. Это код, написанный на Jsonnet. Jsonnet – Это язык создания шаблонов от Google.
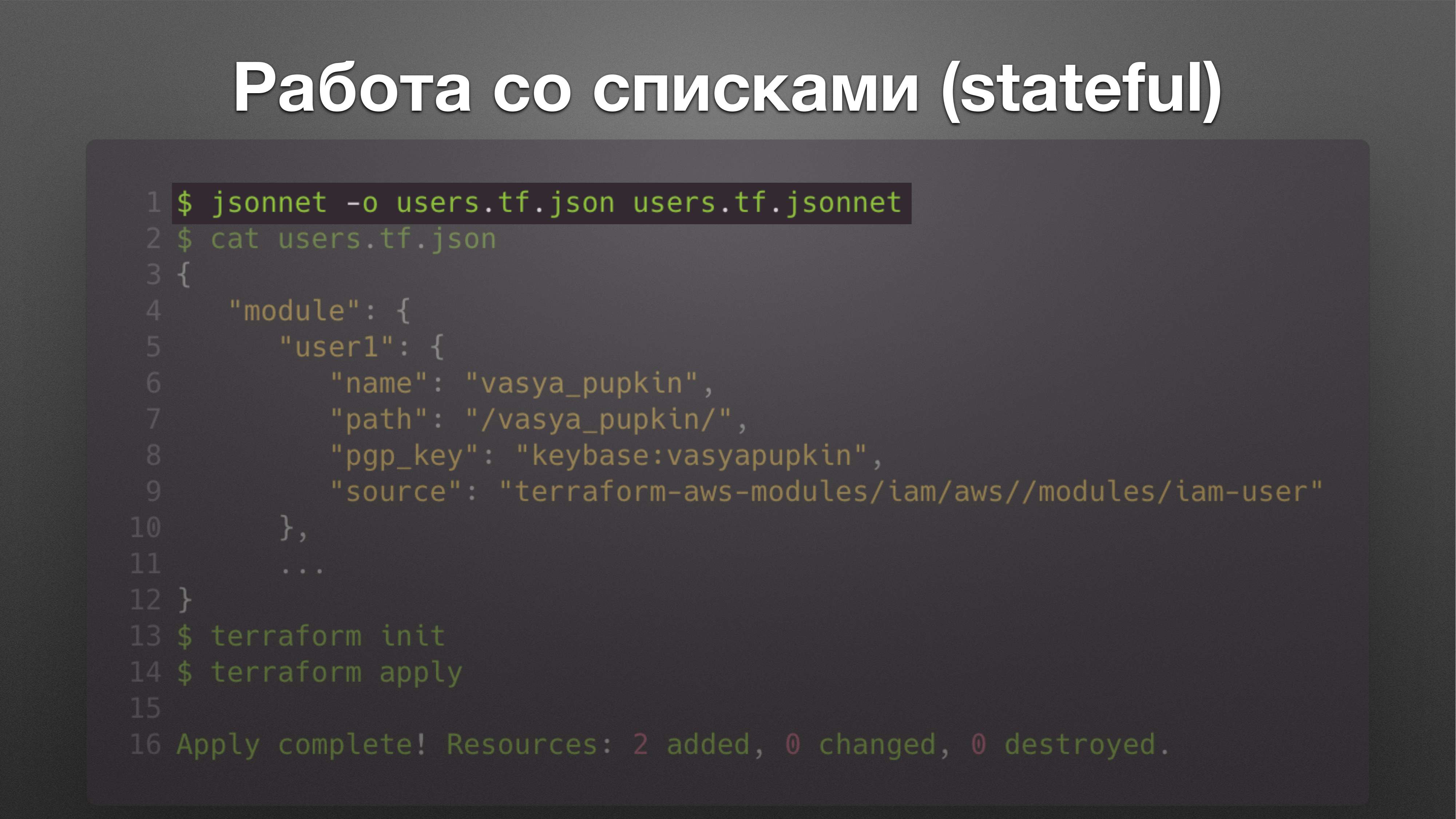
Это команда позволяет принять этот шаблон и на выходе он возвращает json-файл, который сделан по вашему шаблону.
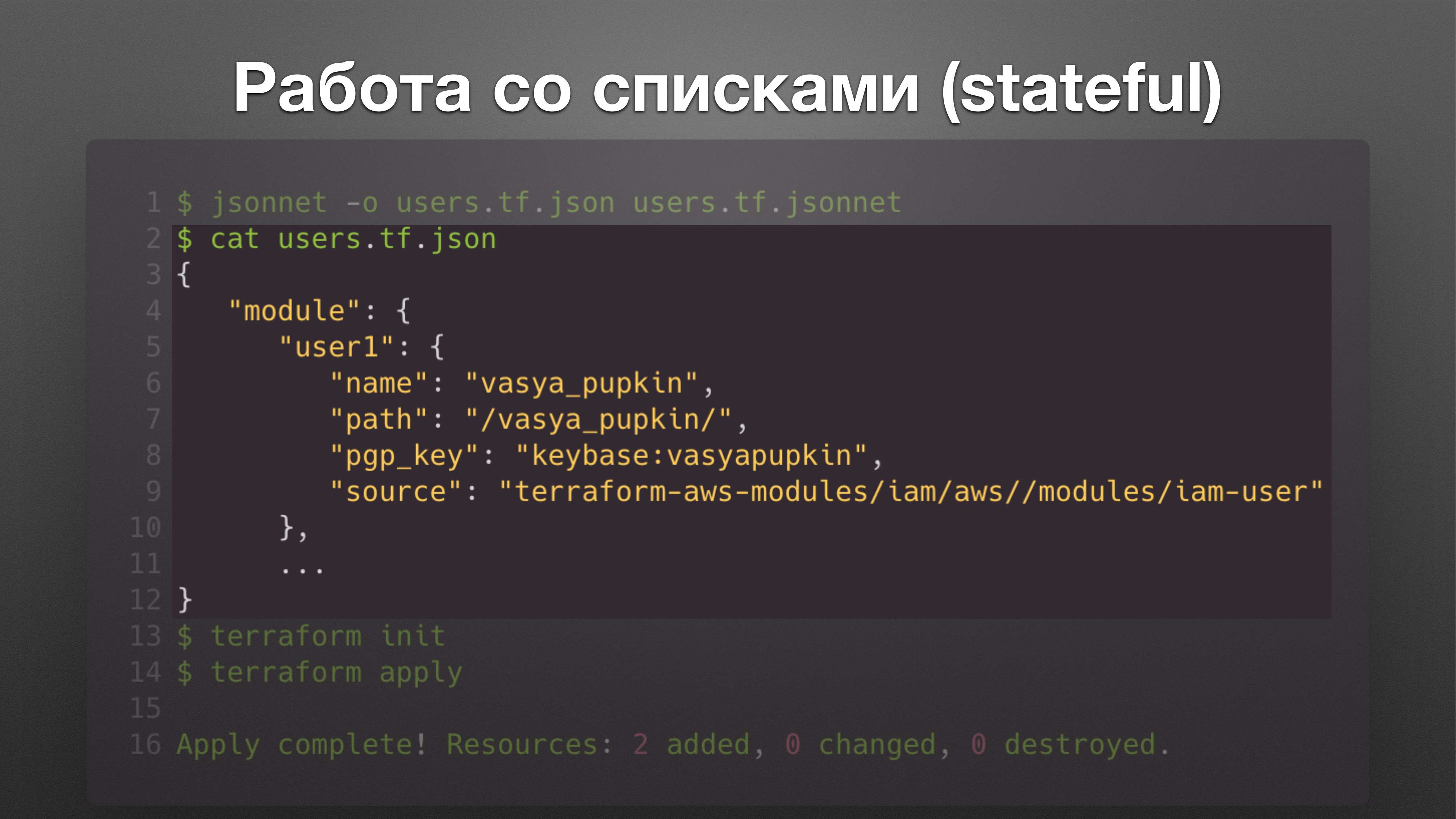
Шаблон выглядит вот так.
Terraform позволяет работать и с HCL, и с Json одинаково, поэтому если у вас есть возможность генерировать Json, то вы можете его подсунуть в Terraform. Файл с расширением .tf.json будет успешно загружен.
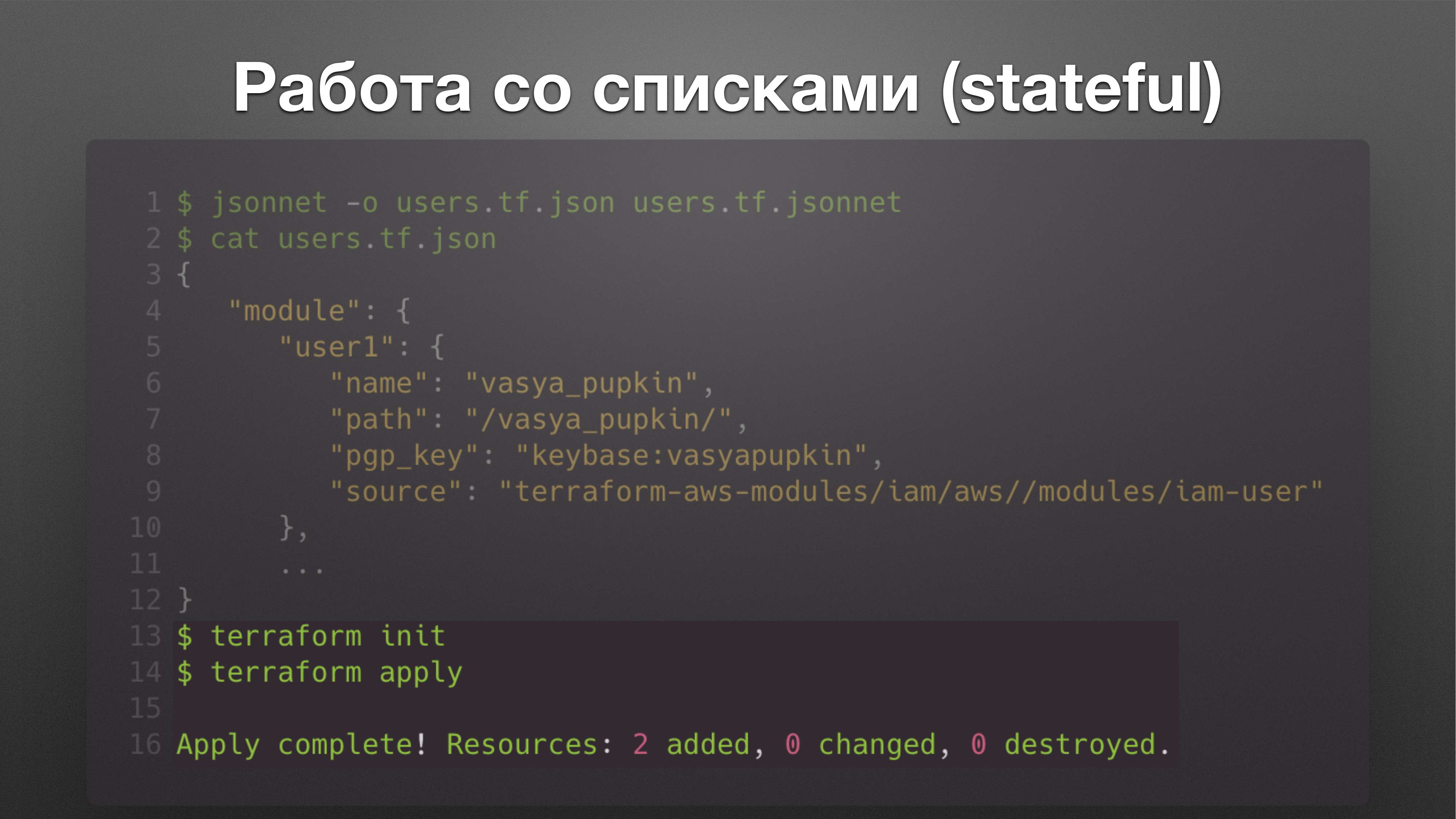
И потом мы работаем с этим как обычно: terraform init, terramorm apply. И мы создаем двух user’ов.
Теперь нам не страшно, если кто-то покинет команду. Мы просто отредактируем json-файл. Вася Пупкин ушел, Петя Пяточкин остался. Петя Пяточкин не получит новый ключ.

Интеграция Terraform с другими средствами, по сути, не является задачей Terraform. Terraform создавался как платформа для создания ресурсов и все. И все, что подходит потом – это не забота Terraform. И не надо туда вплетать его. Есть Ansible, который делает все, что надо.
Но возникают ситуации, когда мы хотим дополнить Terraform и вызвать какую-то команду после того, как что-то выполнилось.
Первый способ. Мы создаем output, где мы пишем эту команду.

А потом эту команду вызываем из shell terraform output и указываем это значение, которое мы хотим. Таким образом исполняется команда со всеми подставленными значениями. Это очень удобно.

Второй способ. Это использование null_resource в зависимости от изменений в нашей инфраструктуре. Мы можем вызывать тот же local-exeс, как только изменится ID какого-то ресурса.

Естественно, это все гладко на бумаге, потому что Amazon как и все остальные public-провайдеры имеет кучу своих edge cases.
Самый распространенный edge cases заключается в том, что, когда вы открыли AWS-аккаунт, важно, какие вы регионы используете; включена ли эта фича там; может быть, вы его открыли после декабря 2013-го года; может быть, вы используете дефолт в VPC и т. д. Есть много ограничений. И Amazon разбросал их по всей документации.

Есть несколько вещей, которые я рекомендую избегать.
Для начала избегайте всех несекретных аргументов внутри Terraform plan или Terraform CLI. Все это можно сложить либо в tfvars-файл, либо в переменное окружение.
Но не надо запоминать всю эту магическую команду. Terraform plan – var и понеслась. Первая переменная – var, вторая переменная – var, третья, четвертая. Самый важный принцип инфраструктуры как код, который я чаще всего использую, это то, что, просто взглянув на код, я должен прекрасно понимать, что там задеплоено, в каком состоянии и с какими значениями. И поэтому мне не надо читать документацию или спрашивать Васю о том, какие параметры он использовал для создания нашего кластера. Мне достаточно открыть файл с расширением tfvars, который часто совпадает с окружением, и посмотреть все там.
Также не надо использовать аргументы target для уменьшения области действия. Для этого намного проще использовать маленькие инфраструктурные модули.
Также не надо ограничивать и увеличивать parallelism. Если у меня 150 ресурсов и я хочу увеличить parallelism Amazon с 10, которые по умолчанию, до 100, то, скорее всего, что-то пойдет не так. Или может пойти хорошо сейчас, но, когда Amazon скажет, что вы слишком много делаете вызовов, у вас посыплются проблемы.
Terraform большинство этих проблем будет пытаться перезапустить, но вы не добьетесь почти ничего. Parallelism=1 – это важная вещь, которую надо использовать, если вы споткнулись об какой-то баг внутри AWS API или внутри Terraform-провайдера. И тогда надо указать: parallelism=1 и ждать, пока Terraform закончит один вызов, потом второй, потом третий. По очереди он их будет запускать.
Часто меня спрашивают: «Почему я считаю, что Terraform workspaces – это зло?». Я верю, что принцип инфраструктуры как код заключается в том, чтобы видеть, какая инфраструктура была создана и с какими значениями.
Workspaces было создано не со стороны пользователей. Это не значит, что пользователи написали в GitHub issues, что жить не можем без Terraform workspaces. Нет, не так. Terraform Enterprise – это коммерческое решение. Terraform от HashiCorp решило, что нам надо workspaces, поэтому мы это запилим. Я считаю, что намного проще это положить в отдельную папку. Тогда будет чуть больше файлов, но будет понятней.

Как работать с кодом? По сути, работа со списками – единственная боль. И воспринимайте Terraform проще. Это не та вещь, которая будет вам делать все классно. Не надо пихать туда все, что написано в документации.

В теме доклада было написано «на будущее». Я очень кратко об этом скажу. На будущее – это значит, что скоро выйдет 0.12.

0.12 – это куча всего нового. Если вы пришли из обычного программирования, то вы скучаете по всяким динамическим блокам, циклам, по правильным и условным операциям сравнения, где левая и правая часть вычисляются не одновременно, а в зависимости от ситуации. Вы очень сильно по этому скучаете, поэтому 0.12 вам решит это.

Но! Если вы будете писать меньше и проще, используя готовые модули, сторонние решения, то вам не надо будет ждать и надеяться, что 0.12 придет и все за вас починит.

Спасибо за доклад! Ты говорил об инфраструктуре как код и про тесты сказал буквально одно слово. Нужны ли тесты в модулях? Чья это ответственность? Нужно самому писать или это ответственность модулей?
Следующий год будет засыпан докладами о том, что мы решили все тестировать. Что тестировать – это самый большой вопрос. Есть куча зависимостей, куча ограничений разных провайдеров. Когда мы с тобой разговариваем, и ты говоришь: «Мне нужны тесты», то я спрашиваю: «Что ты будешь тестировать?». Ты говоришь, что будешь тестировать в своем регионе. Тогда я говорю, что в моем регионе это не работает. Т. е. мы даже на этом с тобой не сможем договориться. Не говоря уже о том, что есть куча технических проблем. Т. е. как написать эти тесты, чтобы они были адекватными.
Я исследую эту тему активно, т. е. как автоматически генерировать тесты на основании той инфраструктуры, которую ты написал. Т. е. если ты написал этот код, то мне надо его запустить, на основании этого я смогу создать тесты.
Terratest – это одна из самых часто упоминаемых библиотек, которая позволяет писать тесты интеграционные для Terraform. Это одна из утилит. Мне больше нравится тип DSL, например, rspec.
Антон, спасибо за доклад! Меня зовут Валерий. Позволю себя немножко философский вопрос. Есть, условно, provisioning, есть deployment. Provisioning мою инфраструктуру создает, в deployment мы ее чем-то наливаем полезным, например, серверами, приложениями и т. д. И у меня в голове сидит, что Terraform больше для provisioning, а Ansible больше для deployment, потому что Ansible и на физическую инфраструктуру позволяет поставить nginx, Postgres. Но при этом и Ansible вроде бы позволяет сделать provisioning, например, амазонских или гугловых ресурсов. Но и Terraform позволяет с помощью своих модулей задеплоить какой-то софт. С твоей точки зрения, есть ли какая-то граница, которая проходит между Terraform и Ansible, где и что лучше использовать? Или, например, ты думаешь, что Ansible – это уже фигня, надо пытаться Terraform для всего использовать?
Хороший вопрос, Валерий. Я считаю, что Terraform с 2014-го года не изменился в плане предназначения. Он создан для инфраструктуры и умер для инфраструктуры. У нас по-прежнему была и будет нужда в configuration management Ansible. Вызов в том, что там есть user data внутри launch_configuration. И там ты дергаешь Ansible и т. д. Вот это стандартное разграничение, которое мне больше всего нравится.
Если мы говорим про in beautiful infrastructure, то есть утилиты типа Packer, которая собирает этот образ. И дальше Terraform использует data source для поиска этого образа и обновления своей launch_configuration. Т. е. таким образом pipeline заключается в том, что мы дергаем сначала Tracker, потом дергаем Terraform. И если произошел build, то происходит новое изменение.
Здравствуйте! Спасибо за доклад! Меня зовут Миша, компания RBS. Можно Ansible вызывать через provisioner при создании ресурса. А также в Ansible есть такая тема, как динамический инвентарь. И можно сначала вызвать Terraform, а потом вызвать Ansible, который из state возьмет ресурсы и выполнит. Что лучше?
И то и то люди используют с одинаковым успехом. Мне кажется, что динамический инвентарь в Ansible – это удобная вещь, если мы не говорим про autoscaling group. Потому что в autoscaling group у нас есть уже свой инструментарий, который называется launch_configuration. Мы в launch_configuration записываем все, что надо запускать, когда создаем новый ресурс. Поэтому с Amazon использовать динамический инвентарь и читать Terraform ts файл, по-моему, это излишнее. А если вы используете другие средства, где нет понятия «autoscaling group», например, вы используете DigitalOcean или какой-то другой провайдер, где нет autoscaling group, то там вам надо будет ручками дергать API, находить IP-адреса, формировать dynamic inventory файл, и Ansible будет уже по нему бродить. Т. е. для Amazon есть launch_configuration, а для всего остального есть dynamic inventory.
