Comments 166
Хотелось бы посмотреть как раз на целевые таблицы и их индексы. Какие-то общепринятые типа users, roles, users_roles и пример функции как отдаётся по API JSON для запроса типа GET /users/current/roles — список ролей текущего пользователя.
Хочется конкретный пример реализации чего-нибудь, а то так трудно что-то сказать.
Хочется увидеть:
— реализацию динамической сортировки
— динамические параметры к запросу
— роли пользователей и RLS на изменение данных и отображение
RLS на изменение данных и отображение
Да, реализовано, но это отдельная тема, при всем желании не поместится в комментарий.
Может быть в следующей статье.
RLS на изменение данных и отображение
Реализация RLS на изменение данных здесь — https://habr.com/ru/post/516040/
SELECT jsonb_pretty(actions."getCd"( current_id=>4)::jsonb) AS result ;
NOTICE: {
"id": 4,
"status": "Разработка ",
"endDate": "2020-12-31",
"programm": "Test 5",
"startDate": "2020-01-01",
"employeeId": 4,
"totalFactor": null,
"creationDate": "2020-08-19"
}
result
---------------------------------------------------------
{ +
"id": 4, +
"status": "Разработка ",+
"endDate": "2020-12-31", +
"programm": "Test 5", +
"startDate": "2020-01-01", +
"employeeId": 4, +
"totalFactor": null, +
"creationDate": "2020-08-19" +
}
(1 row)current_id=>4RETURN COALESCE((
WITH
«email_keys» AS
(SELECT jsonb_array_elements_text((CASE WHEN (jsonb_typeof(ljInput->'templateName') IS NOT DISTINCT FROM 'array') THEN ljInput->'templateName' ELSE '[]'::jsonb END)) AS key_name)
«email_values» AS
(SELECT
«email_keys».key_name,
COALESCE((SELECT COALESCE(«content_ref».jdesc->>(COALESCE(ljInput->'localeName', '0')), «content_ref».jdesc->>'0')
FROM public.«content_ref»
WHERE («content_ref».ref_id = 16) AND
(«content_ref».ref_name = «email_keys».key_name)
LIMIT 1
), '') AS key_value
FROM «email_keys»)
SELECT jsonb_object_agg(«email_values».key_name, «email_values».key_value)
FROM «email_values»
), '{}'::jsonb);
# \du
List of roles
Role name | Attributes | Member of
--------------------+------------------------------------------------------------+---------------------------------------------------------------------------
business_functions | Cannot login | {}
loc_audit_functions| Cannot login | {}
dba_role | Cannot login | {store,business_functions,service_functions,user_role,loc_audit_functions,sys_functions}
curr_dba | Create role | {dba_role}
emp1 | | {user_role}
emp2 | | {user_role}
emp3 | | {user_role}
man | | {user_role}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
prog1 | | {user_role}
prog2 | | {user_role}
prog3 | | {user_role}
prog4 | | {user_role}
service_functions | Cannot login | {}
store | Cannot login | {}
superman | | {user_role}
sys_functions | Cannot login | {}
user_role | Cannot login | {}Я имел в виду роли пользователей приложения, а не роли пользователей БД
Роли стандартные — «пользователь»,«руководитель»,«специалист кадровой службы» и т.д.
Организовано стандартно — отношение многие ко многим между таблицами users и roles. Плюс куча таблиц типа people, position, emploiment и т.п.
Соответственно разграничение доступа к данным реализуется с использованием Row Level Security и изменение логики бизнес-функции ветвлением внутри хранимой функции.
Просто детали реализации очень сильно связаны с предметной бизнес областью и весьма опосредованно с темой данной статьи.
и изменение логики бизнес-функции ветвлением внутри хранимой функции
Ага, один и тот же код внутри каждой хранимой функции. Или почти один и тот же с незначительными изменениями.
Тема статьи — пример реализации бизнес-логики в БД. Правила бизнес-доступа напрямую связаны с этой темой, потому этот вопрос и появился в первых же комментариях.
Тема Row Level Security будет чуть подробнее описана в следующей статье. Постараюсь описать возможности реализации скрытия данных и реализации ролевой модели доступа к данным. Внутренности хранимых функций вряд-ли будут раскрыты, так как сильно связаны с предметной областью. А если обезличивать и упрощать то и смотреть в общем то не на что, общая последовательность банальна и проста :
- IF
- SELECT
- JSON_BUILD_OBJECT
В разных вариациях и комбинациях.
Сорри.
Вообще говоря, в моем данном конкретном случае, бизнес логика не отличается особым разнообразием и сложностью, все что делает клиент это варианты 90% GET + UPDATE, пару вариантов FTS, простой PUT.
Мне показалось странным — зачем тратить время на изменение архитектуры посреди разработки и реализовать на backend то, что и так работает в БД. Поэтому этот этюд и родился, просто на память для себя, что было сделано и для экономии времени в будущем.
Однажды же начали реализовать проект используя бизнес логику в БД. Почему в следующий раз не придет такая мысль, на следующем проекте?
Как то, так.
Мне показалось странным — зачем реализовать на backend то, что и так работает в БД
Так много раз говорили уже — потому что это сложно поддерживать. Не написать один раз лишь бы как-то работало, а вносить изменения.
А в чем конкретно сложность?
При настроенном процессе разработки используя GitLab .
Я же ниже приводил примеры — нашли опечатку или добавили новый параметр в процедуру логирования, надо все это искать и исправлять вручную во всех местах.
Копипаста кода с ошибкой, копипаста названий переменных, которые не сооответствуют текущей процедуре, из-за чего сложнее разобраться, что она делает.
Подключить кеширование, обратиться к внешнему сервису, настроить шардинг — это все заметно сложнее, если бизнес-логика в БД.
Валидация введенных пользователем данных, интернационализация сообщений об ошибках — то же самое.
В языке с ООП общую логику можно поместить в базовые классы. При этом ограничив использование в вызывающем коде модификаторами public/private/protected, что удобнее при рефакторинге.
Конкретные алгоритмы обработки тоже проще на обычных языках описывать, они для этого и предназначены. Зачем при вызове функции каждый раз PERFORM писать? Зачем каждый раз перечислять поля ответа "isError, errorMsg", если можно написать "new Response()"? А если третье поле в ответ понадобится добавить? Снова везде искать и исправлять вручную. А еще можно где-нибудь пропустить, оно попадет на продакшн, потом будет задача на исправления бага, кто-то должен будет исправить, проверить, кто-то другой сделать код-ревью, кто-то из тестировщиков протестировать. В этом и заключается сложность поддержки.
EXCEPTION WHEN OTHERS THEN PERFORM loc_audit_functions.make_log ( 'business_function_template', 'STARTED', json_build_object ( --IN Parameters ) , TRUE ); PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR', json_build_object('SQLSTATE',SQLSTATE ), TRUE ); PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR', json_build_object('SQLERRM',SQLERRM ), TRUE ); GET STACKED DIAGNOSTICS error_message = RETURNED_SQLSTATE ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-RETURNED_SQLSTATE',json_build_object('RETURNED_SQLSTATE',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = COLUMN_NAME ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-COLUMN_NAME', json_build_object('COLUMN_NAME',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = CONSTRAINT_NAME ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-CONSTRAINT_NAME', json_build_object('CONSTRAINT_NAME',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = PG_DATATYPE_NAME ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-PG_DATATYPE_NAME', json_build_object('PG_DATATYPE_NAME',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = MESSAGE_TEXT ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-MESSAGE_TEXT',json_build_object('MESSAGE_TEXT',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = SCHEMA_NAME ; PERFORM loc_audit_functions.make_log (s 'business_function_template', ' ERROR-SCHEMA_NAME',json_build_object('SCHEMA_NAME',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = PG_EXCEPTION_DETAIL ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-PG_EXCEPTION_DETAIL', json_build_object('PG_EXCEPTION_DETAIL',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = PG_EXCEPTION_HINT ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-PG_EXCEPTION_HINT',json_build_object('PG_EXCEPTION_HINT',error_message ), TRUE ); GET STACKED DIAGNOSTICS error_message = PG_EXCEPTION_CONTEXT ; PERFORM loc_audit_functions.make_log ( 'business_function_template', ' ERROR-PG_EXCEPTION_CONTEXT',json_build_object('PG_EXCEPTION_CONTEXT',error_message ), TRUE ); RAISE WARNING 'ALARM: %' , SQLERRM ; SELECT json_build_object ( 'isError' , TRUE , 'errorMsg' , SQLERRM ) INTO error_json ; RETURN error_json ;
(специально целиком скопировал)
А потом вся эта штука копипастится во все функции, и при любом изменении процедуры логирования их все надо обновлять. Отдельно хочется отметить "--IN Parameters", которые надо писать вручную и которые поэтому будут вручную копироваться из других функций с похожими параметрами, и кто-нибудь когда-нибудь забудет переименовать переменные, и упадет это все только при возникновении исключения на продакшене. Чем это лучше одной (!) функции обработки исключения в базовом классе на обычном языке программирования, непонятно.
Зачем?
лучше одной (!) функции обработки исключения в базовом классе на обычном языке программирования,Тема этюда «Реализация бизнес-логики на уровне Базы Данных». Про обычные языки программирования, отдельные статьи и забота других авторов.
Дело не в том, часто или нет, а в том, что это случается, и появляется вопрос о сложности поддержки приложения.
Навскидку несколько причин, которые могут затрагивать все или несколько процедур:
— Появился новый параметр системы, который надо логировать — номер сервера, новый флаг в структуре пользовательского аккаунта
— Появился новый параметр процедуры
— Нашли опечатку в тексте сообщения
— Переименовали процедуру
Например, у вас в первом вызове make_log() перед "STARTED" пробела нет, а в остальных есть, это так и должно быть?
Или строка 'business_function_template' встречается несколько раз. Уверены, что все и всегда будут ее менять на правильное название процедуры перед выполнением этого SQL-кода?
Еще одну причину изменения этого кода я уже написал в предыдущем комментарии — задание правильных "IN Parameters". Скопировали из одной процедуры с ошибкой, потом из новой копии в другую процедуру, потом все это надо искать и исправлять. Это не предположения, это я по опыту говорю.
Тема этюда «Реализация бизнес-логики на уровне Базы Данных»
Так дело в том, что вы приводите это как альтернативу коду на обычном языке программирования. Реализация бизнес-логики на уровне базы данных это плохой подход, и у него есть недостатки, которые вы не упоминаете. Вы предлагаете свои наработки, чтобы кто-то ими воспользовался, но зачем кому-то пользоваться наработками для плохого подхода?
вы приводите это как альтернативу коду на обычном языке программирования— это ложная посылка. Со всеми вытекающими логическими последствиями.
У вас свое мнение что хорошее, что плохое, у меня свое.
Дело не в мнениях, а в аргументах. Мы говорим не о дизайне обоев, кому что нравится, а о бизнес-системах, которые зарабатывают деньги, требуют деньги на свою поддержку, и работают на серверах с конкретными вычислительными ресурсами. А для бизнеса важны аргументы, почему стоит делать систему так или иначе.
Проблема с копипастой возникает не при создании, а при изменении. В одном месте изменили, в другом нет. Если у вас есть управляющая система, в который вы каким-то образом задаете шаблон и которая при изменении меняет во всех нужных местах, то это уже почти язык программирования.
Если перегенерировать исходники целиком, то их надо целиком писать на этой обертке. А если мы все равно пишем не на SQL, а на обертке для SQL, почему бы просто не писать на обычном языке программирования.
почему бы просто комментарий-маркер не оставлять и искать потом его?
Можно и так. Только зачем? Лучше взять язык программирования, в котором этим занимается компилятор.
Можно и так. Только зачем? Лучше взять язык программирования, в котором этим занимается компилятор.
Можно и взять, но стоит ли оно того? Каждая операция у вас будет гонять данные из оперативной памяти хоста БД в память хоста бекенда по сети, каждый раз данные нужно будет распарсить, для этого предварительно продублировав схему БД в кодовой базе.
Каждая операция у вас будет гонять данные из оперативной памяти хоста БД в память хоста бекенда по сети
Не каждая. А только те, которые и так надо возвращать на клиент. Разве что сервисные функции типа проверки авторизации запрашивают данные, которые никуда не возвращают. Ну так данных там не так уж много. А если пользователей настолько много, что это создает проблемы, то сессии можно вынести в отдельный быстрый кеш, а с базой так не получится.
каждый раз данные нужно будет распарсить
Драйверы для работы с БД сами парсят ответ БД и преобразуют его в сущности языка программирования — инты, строки, массивы и объекты. Программисту для этого ничего писать не надо.
для этого предварительно продублировав схему БД в кодовой базе
Никто не мешает использовать ассоциативные массивы без всяких схем, так же как это делается при обработке в БД. Просто почему-то так не делают, и это считается плохим кодом. Наверно есть какие-то причины на это, сложности в поддержке например.
Просто почему-то так не делают, и это считается плохим кодом.
В экосистеме PHP-фреймворка Laravel делают сплошь и рядом, хорошо если пропишут столбцы таблицы как @property в phpdoc класса записи. И не забудут удалить когда удалят из таблицы
в phpdoc класса записи
Так классы это же не ассоциативные массивы. В Laravel вроде тоже ActiveRecord, как и в Yii.
10 лет назад реализовал бизнес логику на MSSQL.
В какой-то момент уперлись в проблему производительности.
Пробовали оптимизацию SQL (ограниченный успех), переход на SQL CLR (опасно и жрет память).
В конечном итоге сделали доп. business layer и проблему масштабирования решили.
Сейчас приложение держит большую нагрузку по OLTP, пользуются на SaaS 3 из 4х крупнейших банков США и бизнес логика не проседает. Проявились другие узкие места, но не в бизнес логике.
Опять-таки, часть сложных вычислений (например, обработка видео) действительно лучше отдать в микросервисы (дал им данные — пусть считают).
Надо смотреть на много параметров: структура данных, объемы данных, число транзакций и т.д.
Я как-то пробовал сделать так бизнес логику. В конечном счете все переусложнилось в такую кашу, что я переписал все обычным кодом, что сократило его количество в несколько раз.
Написать-то можно, а как поддерживать потом?
Ну смотрити, лингвалео взяли и сократили 10к строк кода в 300 строк. После этого они перепишут обратно, сократив 300 строк кода в 10. Повторять пока не останется 1 строчка "сделать хорошо".
Я процитировал товарища APXEOLOG
В конечном счете все переусложнилось в такую кашу, что я переписал все обычным кодом, что сократило его количество в несколько раз.
Можете конкретные примеры попросить у человека выше.
В одном из докладов, кажется от Олега Бартунова слышал, что с определённого уровня БД становится тупо таблицами без какой-либо логики, т.к. даже проверка ограничения внешних ключей становится дорогой операцией. До такого я, увы, не доходил, но вполне допускаю.
Кроме того, современные БД поддерживают модель «мульти-мастер»
Наш кейс следующий:
1. Вся расчетная логика у нас на слэйвах, Мастер только пишет готовые результаты. По итогам тестов на сервере m5.8xlarge было достигнуто стабильное обновление 50К записей в секунду (для информации: вся VISA по миру обратывает 5К транзакций в секунду)
2. Если логика в хранимках и нет прямых обращений к базе извне, то вам не нужно делать внешних ключей: заложите проверку зависимостей только там, где это необходимо, прямо в хранимке. Нагрузка на базу заметно снизится.
3. Также помогает грамотная работа с индексами: не плодить их десятками на таблицу, а ограничиться 2-3 (у нас во всей системе 12 таблиц и 20 индексов). И минимизировать обновление значений первичных ключей (тоже возможно). Тогда при обновлении данных потребуется заметно меньше операций.
Про внешние ключи — да, тоже пришел к такому выводу. Хотя, подход не несёт рисков только если нет загрузки из внешних дампов напрямую в БД.
На другом проекте (мониторинг активности PostgreSQL) у меня вообще на десяток таблиц один внешний ключ, но там ввод данных от клиента вообще отсутствует в принципе.
Вот тут Кайт приводит размышления с тестами:
Эффективное проектирование приложений Oracle / Это база данных, а не свалка данных
www.rsdn.org/article/db/goodoraapp.xml#EZTAE
Я вообще пришёл к выводу что все чеки, проверки, ассерты самоё дешёвое, быстрое и надёжное делать в БД
все чеки, проверки, ассерты самоё дешёвое, быстрое и надёжное делать в БДсогласен.
Но в данном конкретном случае ситуация следующая, кратко (подробнее тут https://habr.com/ru/post/467719/ https://habr.com/ru/post/467575/ https://habr.com/ru/post/467277/).
Есть таблица строки в которую вставляются systemd сервисом, затем эти данные агрегируются в таблицы для анализа. Задача — максимально быстро получить и агрегировать данные. Ограничения FK в данном конкретном случае будут только мешать.
Микроскопом тоже можно забивать гвозди, но зачем. Поэтому, каждый элемент должен использоваться по назначению. База данных — реляционое хранилище и возможно отделные куски бизнес логики но не поголовно вся.
Как правило, у каждой хранимки свой запрос и свой ответ. При этом формат должен оставаться гибким, т.к. продукт постоянно растет, новые фичи каждый день вводятся.
Если сможете продемонстрировать, как с помощью объектов и метаданных сделать процесс работы с json удобнее, эффективнее и гибче, буду благодарен.
Проблема начинается, когда проект разрастается до такого размера, что нужна работа команды из более чем трех человек.
И тут системы командной работы для СУРБД в зачаточном состоянии.
Системы коллективной работы для других ЯП (JAVA, C#, Python и пр) очень плохо интегрируются с СУРБД.
По мне, писать логику БП в СУРБД, это закладывать мину в проект, которая рванет, через 1.5 — 2 года, когда сменится как минимум пара поколений программистов.
Стоимость изменений будет не просто высокой, а не подъемной.
когда сменится как минимум пара поколений программистов.
Почему? Зачем им меняться?
Реляционным СУБД не один десяток лет.
Все, что я делал на Oracle 20 лет назад, точно так же работает сейчас в PostgreSQL.
И точно также будет работать еще чрез 20 лет.
То, что сейчас на рынке масса backend-разработчиков и минимум DB разработчиков, так всегда была. Раньше например были толпы дельфинистов на одного ораклиста. Еще раньше толпы фоксистов на одного сиониста.
Мир не сильно то изменился за прошедшие 20 лет.
Посмотрим, что будет дальше.
Данные точно никуда не денутся, а данные нужно хранить и обрабатывать и управлять.
Если к самому SQL у меня претензий не только, нет, а наоборот, чтобы для работы с реляционными данными использовали только его.
А вот что касается императивных расширения для SQL (PlSQL, TSQL, PgPlSQL), то я лично, против их повального использования (чаще всего бездумного).
Скажем так, я не раз оказывался в ситуации, когда приходил на легаси проект, а предыдущие программисты уже ушли. Из документации только код без тестов, какое-то ТЗ которое было актуально лет 5 назад и все.
Разбираться в портянках хранимых процедур, это чуть лучше, чем разбираться в исходных кодах программы на Clipper.
Тут в хотя бы нельзя просто сделать сомомодефицируемую процедуру.
Хотя это можно сделать, но нужно немного извратиться.
Чем принципиально отличается цикл разработки хранимых функций и методов backend?
Я например использую возможности CI/CD в GitLab, тесты, патчи. Хотя реализовать автотесты уже не успел, а жаль.
Главный плюс, на мой взгляд, что в рамках одного SQL-запроса можно сразу сделать множество действий, что часто экономит 90+% ресурсов и времени.
Например, для выполнения какой операции надо сделать 10 действий. Сейчас в PHP делается 10 разных запросов, получаются сырые данные, потом как-то обрабатываются. Альтернатива — все это сделать в одном запросе:
1. Сначала из больших таблиц выбираются данные во временные таблицы (CTEs). Это делается строго один! раз
2. Далее работа идет с временными таблицами: они компактные, сидят в памяти
3. В концовке делаются необходимые обновления и формирование ответа.
Возьмите пример в своем проекте и попробуйте сделать через SQL — сами почувствуете разницу.
Почему не сформировать такой запрос с CTE на стороне PHP?
Какие бенефиты может дать PHP-прослойка, чтобы платить двойную зарплату, увеличивать размер кода в 2+ раз (в дополнение к SQL писать еще и PHP), снижать скорость разработки в 2+ раз, плодить новых багов и т.д.?
Приведите примеры, когда это действительно необходимо. Я привожу примеры, когда без этого отлично можно обойтись
Откуда 2+? Я не предлагаю дублировать логику на двух языках (в рамках бэкенда, по крайней мере, а пользовательская логика неизбежно будет дублировать серверную частично, если мы о пользователе думаем)
Валидацию параметров запроса прекрасно можно и SQL сделать — это не та операция, которая время и ресурсы занимает. Основные затраты идут именно на обработку.
Скажу честно, у меня не хватает фантазии, что остается для PHP. Давайте попробуем вместе найти — может, я заблуждаюсь…
Если взять все хранимки, которые есть в вашей базе, перенести их в ваш "сервис на го" в виде текстовых констант, и вместо db.executeStoredProcedure("getUsersProcedure") написать db.execute(getSqlResource("getUsers.sql")) то у вас из 30к строк миллион раздуется? Или как это работает?
Ну например с таким подходом у нас получается возможность чтобы два сервиса разных версий (с разным содержимым getUsers.sql) смотрели в одну базу и оба могли работать параллельно.
А ещё например окажется, что 90% запросов можно написать без sql на простом DSL и получить поддержку компилятора в случае неправильного построения запроса.
Чтобы не хранить SQL-код в базе, например, а в обычных текстовых файлах со всеми их преимуществами.
Какие бенефиты может дать PHP-прослойка, чтобы платить двойную зарплату, увеличивать размер кода в 2+ раз (в дополнение к SQL писать еще и PHP), снижать скорость разработки в 2+ раз, плодить новых багов и т.д.?
Такие, что не надо платить двойную зарплату, увеличивать размер кода в 2+ раз, снижать скорость разработки в 2+ раз, и плодить новых багов. Вы вот примеры просите, а сами примеров для этого утверждения не привели. Только на словах рассказываете, что на PHP было плохо, а на SQL стало хорошо, хотя причина может быть вовсе не в использовании SQL.
Продемонстрируйте, пжл
Пожалуйста:
$subscriptionList = UserSubscription::find()
->where(['=', 'status', UserStatus::ACTIVE])
->andWhere(['<=', 'subscr_date', $ldLastDate])
->with('user')
->all();
return $subscriptionList;6 строк кода. В 3 раза меньше, чем у вас. Фреймворк Yii2 с ActiveRecord.
В базу пойдет 2 запроса — один к таблице user_subscriptions с указанным фильтром, один к таблице users с IN (<идентификаторы из первого запроса>).
Ответ будет в виде:
[
{
"subscr_date": ...,
"user": {
"user_id": ...,
"user_name": ...
},
},
...
]Формат JSON или XML, в который надо преобразовать массив, определяется отдельным обработчиком на основе заголовков HTTP-запроса.
class UserSubscription extends ActiveRecord
{
public $user_id;
public $subscr_date;
...
public function tableName()
{
return 'user_subscriptions';
}
public function getUser()
{
return $this->hasOne(User::class, ['user_id' => 'user_id']);
}
public function fields()
{
return [
'subscr_date',
'user',
];
}
}
class User extends ActiveRecord
{
public $user_id;
public $user_name;
...
public function tableName()
{
return 'users';
}
public function getUserSubscription()
{
return $this->hasOne(UserSubscription::class, ['user_id' => 'user_id']);
}
}Описания классов и связи между ними делаются один раз и используются во всех действиях, связанных с этими сущностями.
Если сильно надо сделать ответ именно в том виде, можно либо поменять функцию fields(), либо написать foreach или array_map по месту, либо сделать отдельный класс UserSubscriptionResponse, в который поместить один из этих вариантов.
public function fields()
{
return [
'userId' => 'user_id',
'userName' => 'user.name',
'subscrdate' => 'subscr_date',
];
}
// или
return array_map($subscriptionList, function($subscription) {
return [
'userId' => $subscription->user_id,
'userName' => $subscription->user->name,
'subscrdate' => $subscription->subscr_date,
];
});один к таблице users с IN (<идентификаторы из первого запроса>).
Используют всякие сомнительные инструменты, потом приходится помогать в переписании подобного на чистый SQL. Последний раз это ускорило запрос в 150 раз, с 12 минут, до 5 сек.
Всё-таки работу с данными надо оставить SQL'ю
Используют всякие сомнительные инструменты, потом приходится помогать в переписании подобного на чистый SQL
Это с джойнами что-ли? Приведенный пример можно сделать с джойнами либо с IN, больше никак. Что в них более чистого?
Последний раз это ускорило запрос в 150 раз, с 12 минут, до 5 сек.
А можете привести код для этого примера? Я что-то сомневаюсь, что замена IN по ключу на JOIN может создавать такую разницу в производительности.
Всё-таки работу с данными надо оставить SQL'ю
Да никто с этим и не спорит — SELECT, WHERE, пусть он с ними и работает) А вот бизнес-логику на нем писать не надо.
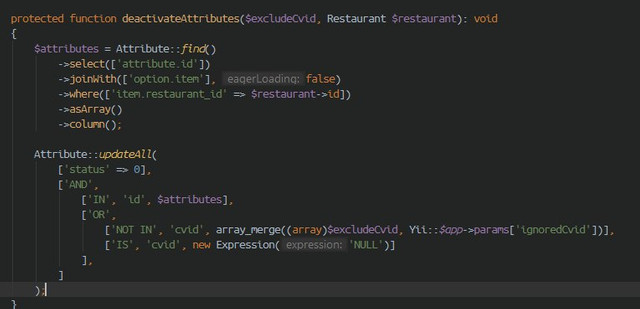
Так тормозил первый или второй запрос? И как в итоге сделали, джойны в UPDATE перенесли?
habr.com/ru/post/515628/#comment_21978610
1. Планировщик PG будет каждый раз ваш запрос перепланировать, тем более что там теперь два запроса.
2. Требуется прописывание доп. классов. Зачем? Завтра придут продакты, попросят еще 5 параметров включить. Будете класс переписывать? И все зависимости?
В моей случае это займет пару минут — в ответе дополнить 5 атрибутов.
3. А если запрос сложный, требуется получение данных из 5 таблиц, распаковка на лету json-данных из таблиц, использование этих данных в след. запросах?
Планировщик PG будет каждый раз ваш запрос перепланировать
Это проблема работы планировщика. Кроме того, я ни разу не слышал историй, чтобы планировщик был основной причиной тормозов в системе.
Требуется прописывание доп. классов. Зачем?
Затем, что так удобнее, чем работать с ассоциативными массивами.
Завтра придут продакты, попросят еще 5 параметров включить. Будете класс переписывать?
В моей случае это займет пару минут — в ответе дополнить 5 атрибутов.
Добавить в класс несколько полей нельзя описать словом "переписывать". Если это переписывание класса, тогда и добавление полей в ответ процедуры это тоже переписывание процедуры.
А в вашем случае вы будете менять ответы пары десятков процедур, которые возвращают эту сущность.
И все зависимости?
Не знаю, что вы подразумеваете под словом "зависимости", в моем понимании никакие зависимости переписывать не надо. Классы затем и выделяют, что они являются основной единицей изменений.
А если запрос сложный, требуется получение данных из 5 таблиц, распаковка на лету json-данных из таблиц, использование этих данных в след. запросах?
Если у вас данные для связи таблиц записаны в JSON, это проблема вашей архитектуры. Но вообще принципиальной разницы нет, просто вместо CTE переменные. Только таблицы обычно не джойнят, а используют IN по ключам. Считается, что в среднем случае это быстрее работает.
А зачем вам кстати каждый раз JSON-данные парсить?) Это же дополнительный оверхед. Как же максимальная скорость работы и все такое? Или вы уже согласны, что небольшой дополнительный оверхед для удобства это нормально?
Это проблема работы планировщика.
Вы серьезно? Качество работы бэкенда Вас не беспокоит? Тогда видимо мы зря дискутируем)
А в вашем случае вы будете менять ответы пары десятков процедур, которые возвращают эту сущность.
Эту сущность возвращает ровно одна хранимка. Другие хранимки возвращают другие ответы в соответствии со спецификацией API
Классы затем и выделяют, что они являются основной единицей изменений.
Одни классы могут зависеть от других — это и есть зависимости. Плюс на базе класса можно создать много объектов — это тоже зависимости. Чем больше зависимостей в системе, тем менее она надежна.
Если у вас данные для связи таблиц записаны в JSON, это проблема вашей архитектуры.
Понятно — про SQL-NoSQL структуру видимо не слышали. Подпишитесь на наш блог — скоро будет подробная статья на эту тему.
просто вместо CTE переменные
В чем ценность данные сначала в переменные складывать, а потом в новый запрос пихать? Почему это нельзя сделать в рамках одного запроса?
JSON-данные парсить
Вы знаете косты на эту операцию? В PG в секунду около миллиона таких операций можно сделать, и это на одном процессоре. У Вас сколько запросов в секунду идет?
что небольшой дополнительный оверхед для удобства это нормально?
Конечно, нормально — если он небольшой, а не десятикратный. Замена оптимизированного SQL-запроса из 10 CTE's на десять маленьких запросов с сохранением данных в переменную ухудшает производительность до 100! раз (да, и такого добивался, объединив 10 простых селектов в нормальный запрос)
Качество работы бэкенда Вас не беспокоит?
Нигде такого не говорил. Более того, в следующем предложении объяснил, что в моей практике качество бэкенда мало зависело от планировщика.
Эту сущность возвращает ровно одна хранимка. Другие хранимки возвращают другие ответы в соответствии со спецификацией API
Связку "user_id, user_name" у вас возвращает только одна процедура получения подписок? Что-то я сомневаюсь.
А вот добавится какой-нибудь "user_gender", чтобы выводить "Mr/Ms", и везде, где возвращается эта связка, надо будет его добавлять третьим полем. Я об этом говорю.
Одни классы могут зависеть от других — это и есть зависимости.
Это никак не отвечает на вопрос, зачем их вдруг надо менять при добавлении полей в класс.
Понятно — про SQL-NoSQL структуру видимо не слышали.
Вы уже второй человек из LinguaLeo, который применяет логические манипуляции.
Я слышал про структуру SQL-NoSQL, я говорю о том, что в части NoSQL не должно быть данных, от которых зависит SQL. Если вам надо джойнить таблицы по полю, выносите его в отдельный столбец. Это же вроде понятно из моего комментария.
В чем ценность данные сначала в переменные складывать, а потом в новый запрос пихать? Почему это нельзя сделать в рамках одного запроса?
А в чем ценность данные сначала во временные таблицы складывать, а потом в новый запрос пихать? В приведенном примере на SQL 2 запроса — к таблице user_subscriptions и к таблице users с джойном. Откуда взялся один запрос?
В PG в секунду около миллиона таких операций можно сделать
Конечно, нормально — если он небольшой, а не десятикратный.
Вот мы и добрались до сути разногласий. У вас одни критерии приемлемого оверхеда, у других другие.
А если ответ пользователю занимает 100 миллисекунд, то несколько миллисекунд на пару дополнительных запросов по внутренней гигабитной локалке ничего для пользователя не изменят, зато процесс разработки для программистов будет проще.
Да, обработка внутри базы экономит время на отправку данных в приложение. Зато создает другие сложности. Для многих эти сложности менее приемлемы, чем небольшое ускорение в данный момент. Может быть оно десятикратное в одной части, но на фоне других частей занимает максимум пару десятков процентов.
Вы уже второй человек из LinguaLeo, который применяет логические манипуляции.
А кто первый? Я так понимаю Олег и есть автор изначального поста, просто он почему-то с разных аккаунтов пишет.
Олег и есть автор изначального поста
Я как автор статьи официально заявляю — к LinguaLeo не имею никакого отношения.
Напишите мне в личку, я предоставлю мои персональные данные ;-)
Я имел в виду LinguaLeo и OlegLinguaLeo. Я предположил, что это разные люди.
1 Планировщик PG будет каждый раз ваш запрос перепланировать, тем более что там теперь два запроса.
Звучит как преждевременная оптимизация. Скажите, сколько RPS вы потеряете на перепланировании запроса? Вы считали?
2 Требуется прописывание доп. классов. Зачем? Завтра придут продакты, попросят еще 5 параметров включить. Будете класс переписывать? И все зависимости?
Затем же, зачем люди придумали типчики. а не хранить всё как огромную хэшмапу хэшмап.
. Скажите, сколько RPS вы потеряете на перепланировании запроса? Вы считали?
Если сам запрос хорошо оптимизирован и быстро выполняется, то на планирование может уйти процентов 30 общего времени.
Это не самая большая проблема. Модель, когда сырые данные сначала мелкими запросами поступают в переменные, потом эти переменные обрабатываются, потом дергаются новые запросы и т.д. до 100! раз снижает производительность (может и больше, но пока не встречал)
как огромную хэшмапу хэшмап.
Не знаю, кто такую хранит.
Хранимка возвращает конкретный ответ в соответствии со спецификацией API. Надо расширить => обновляем спецификацию => добавляем несколько строк в одной! хранимке, которая за этот вызов отвечает.
Это не самая большая проблема. Модель, когда сырые данные сначала мелкими запросами поступают в переменные, потом эти переменные обрабатываются, потом дергаются новые запросы и т.д. до 100! раз снижает производительность (может и больше, но пока не встречал)
Проблема кучи мелких запросов есть, но её можно решить без того чтобы перезжать полностью в БД. Да и там есть любители написать подобный запрос, достаточно использовать курсор.
Не знаю, кто такую хранит.
А что такое JSON по-вашему? Ну или давайте проще: где мне можно посмотреть схему данных: какие данные лежат в какой табличке? Ну то есть вот есть юзер, у него есть поля имя, пароль, список ролей, каждая роль состоит из ...
У вас есть такая информация по данным с табличках?
Главный плюс, на мой взгляд, что в рамках одного SQL-запроса можно сразу сделать множество действий
А в рамках одной функции на PHP тоже можно сделать множество действий. Раз вы считаете это основным поводом, чтобы писать логику на SQL, значит то же самое можно считать основным поводом, чтобы писать логику на PHP.
что часто экономит 90+% ресурсов и времени
Неправда. Экономия 90% времени это экономия на вводе-выводе данных, а не количество действий в одном запросе. Они связаны, но это не одно и то же. Если ввод-вывод занимает мало, а вычисления тяжелые, то неважно, будете вы их делать в 1 запросе или в нескольких, разницы практически не будет.
Сейчас в PHP делается 10 разных запросов, получаются сырые данные, потом как-то обрабатываются. Альтернатива — все это сделать в одном запросе
Вы настолько часто повторяете эту манипуляцию, что складывается впечатление, что вы хотите кого-то обмануть. Или просто плохо представляете, как это работает.
У вас в процедуре тоже делается 10 разных запросов, получаются сырые данные, потом как-то обрабатываются. Альтернатива — все сделать в одной функции на PHP:
1. Сначала из больших таблиц выбираются данные в переменные. Это делается строго один! раз.
2. Далее работа идет с переменными: они компактные, сидят в памяти.
3. В концовке делаются необходимые обновления и формирование ответа.
Это не игра слов, это реальное описание процесса. Разница только в передаче данных из базы в PHP. Соответственно, если не выбирать из базы мегабайты данных, то разница будет практически незаметна, зато получаем удобство в написании логики и управлении кодом.
Возьмите пример в своем проекте и попробуйте сделать через SQL — сами почувствуете разницу.
Да вроде уже раз 20 в комментариях разные люди повторили — пробовали сделать через SQL, почувствовали разницу, больше не хотят делать через SQL.
habr.com/ru/company/lingualeo/blog/515530/#comment_21976428
(сравните мой пример и пример ниже на PHP)
В итоге PHP (или другой язык) просто дергает грамотный SQL-запрос, написанный специалистом. Вопрос ценности такой прослойки у меня и вызывает сомнения.
Я привожу конкретные примеры. Приведите, пжл, тоже примеры, когда использование PHP для обработки данных дает какие-либо преимущества.
habr.com/ru/post/312134/#comment_9853420
У вас неправильное понимание ситуации. Я показал вам, насколько проще управлять кодом, вносить изменения. У БД есть фора на пересылку данных, и всё. Как правило, эта фора не настолько значительная, чтобы создавать сложности в разработке и поддержке, в том числе масштабировании. Если производительности сервера не хватает, обычно дешевле арендовать еще один сервер, чем платить специалистам за увеличенное время внесения и тестирования изменений.
Недавно переписал приложуху на Node + Redis + MSSQL
MSSQL просто юзался как хранилище. Вся логика императивно описана на Node, Redis — кэш. Приложение обрабатывает десятки миллионов запросов в сутки. Около 30 серверов было задействовано. Аренда всего этого добра стоила $35к/мес на Azure + ещё привлекался консультант DevOps из Microsoft.
Переписал на MySQL + Node, вся логика в запросах SQL, кода стало в 25 раз меньше и с той же нагрузкой стал справляться всего 1 сервер v3/D8s, где крутиться nginx, Node, MySQL. Аренда стала около $2к/мес. Недавно правда нагрузка возросла на 50% вынести пришлось MySQL на отдельную машинку
В просто запросах или хранимках?
Хранимка тоже была в одной из итераций, но потом отпала необходимость, остался один единственный запрос в критичном месте.
Хранимка использовалась в критичном месте, для того чтобы сократить трафик между MySQL<->Node. В хранимке тупо несколько SELECT'ов, а потом
[result] = await db.query(«CALL my_proc()»);
res.user = result[0][0];
res.products = result[1];
и т.д.
Лично у меня основное отторжение вызывает именно идея хранить логику (запросы + клей) в хранимках. Сложные запросы к базе — ради бога, особенно на чтение. Главное чтобы запросы хранились в общей кодовой базе, под контролем гита, чтоб их изменение не вызывало необходимости миграции накатывать и т. п.
Я у сделал так:
— создал папку database/routines
— в ней подпапки functions, procedures, triggers, views и т.д.
— эту папку отслеживает git наряду с остальным кодом
— меняем нужные объекты БД, всё пишется в git
— выполняем код объекта в локальной dev базе
— в конце таска видим какие DB объекты были изменены
— создаём под них миграцию
2020_08_11_132100_orgs.js
require('require-sql');
module.exports.up = (db) => {
await db.query(require('../routines/functions/get_url_path.sql'));
await db.query(require('../routines/procedures/some_proc.sql'));
}
— коммитим
— всё это добро уходит в репозитарий и автоматом деплоится на стейдже
Проблем никаких не возникает. Можно конечно ещё доработать чутка систему:
— автоматом проверять с запуском тестов, что все текущие объекты в тексте соответствуют объектам в БД, тогда в случае ошибки в таком тесте, на стейдже сразу будет видно что разраб забыл положить скрипт в миграцию
— придумать что-нть с ролбеком миграции
Хотя вроде и так всё прекрасно работает…
Пытался что-то подобное лет 5 назад делать, но очень не понравилось. Из запомнившихся проблем:
- переключаешь ветки — состояние базы не соответствует состоянию репозитория, нормально обновление работает только в одном варианте — дропнуть базу и накатить заново, а это долго
- велик соблазн редактировать хранимки на локальной базе, а потом часто забываешь перенести в файлы и миграции
- миграции "генерировать" приходится вручную, следя за соответствием базы и sql файлов, аналогов git status для базы не нашёл
- конфликты миграций гитом не обнаруживаются — две миграции из разных веток с CREATE OR REPLACE одной хранимки не выявляются, кто пкрвый встал того и тапки с точностью до наоборот. Можно костыли типа версии в имени и отказ от CREATE OR REPLACE или DROP IF EXISTS, но а) віявляются в рантайме и вообще муторно.
- не нашёл тулинга для простой генерации миграций по текстовым файлам
нормально обновление работает только в одном варианте — дропнуть базу и накатить заново, а это долго
Просто все обновления объектов БД должны оформляться как патч, который суть — sql-скрипт и нет никаких препятствий к выполнению скрипта на живой базе. Идея стара, как мир реляционных СУБД
велик соблазн редактировать хранимки на локальной базепару раз разрабам за такое KPI опустить, соблазн и пропадет ;-)
Не соблазн пропадёт, а страх ему поддаться появится. Ну это мои ощущения о механизме работы. Сам, к счастью, не сталкивался.
пару раз разрабам за такое KPI опустить
А потом удивляемся, чего это разрабы не хотят с таким кодом работать)
Когда конкуренты будут брать задёшево обычных крудоклепателей.
При этом результат будет один и тот же. :-)
переключаешь ветки — состояние базы не соответствует состоянию репозитория, нормально обновление работает только в одном варианте — дропнуть базу и накатить заново, а это долго
Это не проблема объектов в БД, а проблема любых миграций: создали ветку, в мастере дропнули поле, переключились на ветку, ветка не работает. Тут только вместе с веткой клонировать БД для ветки и хоть логика в БД, хоть не в БД.
велик соблазн редактировать хранимки на локальной базе, а потом часто забываешь перенести в файлы и миграции
Когда работал с Oracle, то в PL/SQL Developer'е постоянно был такой соблазн, притом у всех разрабов, а разработка велась на dev сервере и просто выгружали скрипт, притом для выгрузки скрипта довольно много ручных телодвижений надо было. Меня это сильно напрягало, тогда я написал плагинчик (точнее прикрутил и затюнил имеющийся) и в контекстном меню объекта появился пункт выгрузки готовой миграции по объекту. После этого случаи у разрабов что кто-то не выгрузил миграцию практически исчезли. Всё дело в удобстве, а если инструмент не удобный, то хоть какие штрафы делай, хоть какие наказания, люди всё равно будут ошибаться и забывать.
Сейчас меня вполне устраивает в шторме, справа базы, таблички, для редактирования объектов ходим влево там где и app файлы, а т.к. сами базы редко разворачиваю, только клик на базу и F4 для открытия консоли, то путаницы просто ни разу не возникало. Ну а перед коммитом всё равно же авторевью идёт, ну и скидываешь все изменённые объекты в миграцию.
конфликты миграций гитом не обнаруживаются — две миграции из разных веток с CREATE OR REPLACE одной хранимки не выявляются, кто пкрвый встал того и тапки с точностью до наоборот. Можно костыли типа версии в имени и отказ от CREATE OR REPLACE или DROP IF EXISTS, но а) віявляются в рантайме и вообще муторно.
Почему не обнаруживаются? Работает идентично app коду.
Вы с коллегой забрали одну процедуру создали ветки. Он поменял 15ю строчку, накатил на мастер, запустил миграцию. Вы изменили 100ю, мержитесь в мастер, измениться в дополнение к 15й строчке и ваша 100я, запускаете миграцию на мастере, в которой будут изменения 15й и 100й строчки, ну а если бы Вы изменили и 15ю и 100ю строчку, то был бы конфликт при мерже.
не нашёл тулинга для простой генерации миграций по текстовым файлам
не понял этого
Это не проблема объектов в БД, а проблема любых миграций
Для меня они особенно сильно выражаются на хранимках. Классические для схем таблиц у меня более-менее работают. Может потому что изменения в таблицах гораздо реже чем в логике.
Всё дело в удобстве
Полностью согласен! Собственно мой основной аргумент против хранимок — это неудобно поддерживать прежде всего. Второй — масштабирование на запись: чем больше нагрузки даём на сервер, тем быстрее упрёмся в потолок.
Почему не обнаруживаются?
О разных флоу, похоже, говорим.
Я примерно о таком:
- есть каталог procedures
- в нём файлы с телами процедур (не команды CREATE OR REPLACE)
- редактируем в ветке файл, синкаем с базой, дебажим, тестируем
- пишем миграцию (команду CREATE OR REPLACE)
- коммитим
git успешно смержит или покажет конфликт в файле с телом процедуры, но ника не покажет что есть две миграции с CREATE OR REPLACE. В одной дропается текущая (неизвестная гиту) процедура и создаётся новой 15-й строчкой. В другой дропается текущая (неизвестная гиту) процедура и создаётся с новой сотой строчкой. Проблема в том, что вторая миграция об изменённой 15-й строчке не знает, она использовала значение с оригинала.
Я примерно о таком:
— есть каталог procedures
— в нём файлы с телами процедур (не команды CREATE OR REPLACE)
— редактируем в ветке файл, синкаем с базой, дебажим, тестируем
— пишем миграцию (команду CREATE OR REPLACE)
коммитим
Нет, нет, нет. Вы меня немного не правильно поняли и это в корне меняет ситуацию и угол зрения на проблему.
Ещё раз прочитайте мой комментарий:
habr.com/ru/post/515628/#comment_21978458
Мы создаём файлы сразу с CREATE OR REPLACE и их же и выполняем, эти же файлы! В миграциях ссылка на файл, а не дублирование кода с приконкаченым CREATE OR REPLACE.
Вы, кстати, только что меня натолкнули на мысль как реализовать вот это:
Можно конечно ещё доработать чутка систему:
— автоматом проверять с запуском тестов, что все текущие объекты в тексте соответствуют объектам в БД, тогда в случае ошибки в таком тесте, на стейдже сразу будет видно что разраб забыл положить скрипт в миграцию
— придумать что-нть с ролбеком миграции
Надо при запуске программы запускать «миграцию объектов БД» которая:
— возьмёт список объектов в папке
/database/routines/
посчитает их хэши
— возьмёт список объектов в БД, посчитает их хэши
— сделает FULL OUTER JOIN
— создаст недостающие объекты в БД (просто выполнит соответствующий скрипт из папки /database/routines/*/*.sql)
— пересоздаст различающиеся объекты в БД (опять же просто выполнит соответствующий скрипт из папки /database/routines/*/*.sql)
— дропнет ненужные объекты в БД, которых нет в файлах (хотя это вроде и не требуется, но для красоты и чистоты БД можно сделать)
Это даст потрясающие улучшения:
— можно будет не писать миграции для объектов БД вида
2020_08_11_132100_orgs.js
require('require-sql');
module.exports.up = (db) => {
await db.query(require('../routines/functions/get_url_path.sql'));
await db.query(require('../routines/procedures/some_proc.sql'));
}— разработчик не сможет забыть сделать миграцию
— можно будет переключиться на любую ветку, переставить HEAD на любой коммит и состояние объектов БД станет соответствующее этому коммиту!
— разработка БД объектов идентична правке app-файлов: т.е. я открыл любой файл /database/routines/*/*.sql отредактировал, только вместо сохранения Ctrl+S, я жму Ctrl+Enter для выполнения скрипта в локальной dev БД. Хотя можно и Ctrl+S нажать, nodemon/watch отследит изменения файла, перезапустит программу, которая в свою очередь, сверит хэши и пересоздаст объект БД
Вы меня вдохновили на написание библиотеки!
+ если добавить возможность засинкать текущее состояние объектов БД в папку
/database/routines/
то это позволит легко её подключать и начинать пользоваться
(заметка для себя + FOR UPDATE SKIP LOCKED для запуска одной миграции при нескольких экземплярах Node)
Вот такой инструмент я и искал :) Даже начинал писать сам, но сделал одну огромную ошибку: начал с подобным подходом к миграции схем таблиц. А когда осознал, что вся моя генерация ALTER TABLE требует не только ИИ для понимания где переименование, а где удаление и создание, но и миграции данных, то уже энтузиазм иссяк.
Опять же, я не знаю, что там было написано на Node. Понятно, что джойны писать вручную не надо, или доставать все строки из таблицы, кешировать их в Redis и фильтровать в приложении. Может быть там такое приложение, где мало поведения сущностей, а есть в основном статистика. Или может вы еще не столкнулись с проблемами внесения изменений. Если есть несекретный запрос, приводите, что было на Node и что стало на SQL, поменяйте секретные названия и т.д., обсудим более предметно.
habr.com/ru/post/515628/#comment_21977756
этот код был переписан на SQL и стал работать в 150 раз быстрее и кода стало в 2 меньше
Проблема ORM и обработки данных на прикладных языках в том что они заставляют мыслить императивно. В итоге к накладным расходам по не оптимальному извлечению данных (тот же IN, корявые JOIN'ы, не использование специфики SQL, например, аналитические функции), накладывается тормозная императивная логика обработки, ну и кода конечно становиться больше.
Т.е. из примера выше, задача по-видимому обновить какие-то данные, но т.к. мы пишем на прикладном языке, да ещё обмазались ОРМ'а ми и QueryBuilder'ами, то и мылим императивно:
— сначала извлекаем id-шники с нужными критериями
— потом обновляем данные по этим критериям
А если мыслить декларативно, то всё умещается в 1 шаг
— мне надо обновить данные
а вот как обновить и по каким критериям я и описываю в запросе
В итоге получился такой код
$sql = "UPDATE `attribute` a
INNER JOIN `option` o ON a.option_id = o.id
INNER JOIN `item` i ON o.item_id = i.id
SET a.status = 0
WHERE i.restaurant_id = 776
AND a.deleted_at IS NULL
AND (a.cvid IS NOT NULL
OR a.cvid NOT IN (". array_merge((array)$excludeCvid, Yii::$app->params['ignoreCvid']) .")
)
AND NOT (a.status <=> 0)";
По хорошему и переменные $excludeCvid, Yii::$app->params['ignoreCvid'] должны быть обязательно в БД и на месте их должен был быть SELECT, но человек которому я помогал, сказал что эти данные из какого-то так текстового конфигурационного файла… дичь… Все данные, которые требуются для обработки, должны находиться в БД, притом в одной (максимально и по возможности конечно)
К вопросу VolCh, где-то он упоминал что мол, а что и конфиги и .env в БД что ли тоже вести?
Дак конечно вести! Если эти данные могут потребоваться для обработки. Ну в конце концов, можно просто при старте сервиса из .env загружать в соответствующую табличку.
Так тормозил первый или второй запрос? И как в итоге сделали, джойны в UPDATE перенесли?
Тормозил второй запрос, т.к. первый извлекал 49к значений, а потом строилась дичь вида:
UPDATE… WHERE id IN ([49к id-ников])
Хотя извлекать вообще ничего не надо было!
Я же Вам скинул очень показательный пример
Так это ж не на Node) В этой ветке вы же другой проект приводите в качестве возражения, я поэтому и спросил. Ну ок, рассмотрим этот.
Проблема ORM и обработки данных на прикладных языках в том что они заставляют мыслить императивно.
Это не проблема, а преимущество.
В итоге к накладным расходам по не оптимальному извлечению данных (тот же IN, корявые JOIN'ы, не использование специфики SQL, например, аналитические функции)
IN и JOIN это 2 взаимоисключающих варианта извлечения данных из связанных таблиц. По-другому сделать в принципе нельзя. Как единственно возможный набор вариантов может быть неоптимальным?
Аналитические функции используются в основном в статистике, а в бизнес-логике встречаются довольно редко. Стастистику мапить на объекты не надо, и поведения у нее нет, поэтому там обычно делают обычный SQL без ORM. В итоге в бизнес-логике используются преимущества ORM, в статистике преимущества SQL.
А если мыслить декларативно, то всё умещается в 1 шаг — мне надо обновить данные
А если мыслить логически, то когда вам надо будет какое-нибудь событие в очередь кидать с этими id-шниками или кеши обновлять, то вы перепишете все обратно. Но в данном случае да, это не требуется.
По хорошему и переменные $excludeCvid, Yii::$app->params['ignoreCvid'] должны быть обязательно в БД и на месте их должен был быть SELECT
Нет, по хорошему это зависит от назначения параметров. $excludeCvid вообще выглядит как ввод пользователя или что-то аналогичное, его в принципе нельзя в базу переместить.
ну и кода конечно становиться больше
В вашем запросе, который вы привели далее, кода больше, чем в версии на PHP. Все эти INNER JOIN ... ON ... и т.д.
На самом деле по символам чуть поменьше, и там пара дополнительных условий, но если добавить $restaurant->id и код отправки запроса, то будет больше. Или как минимум не сильно меньше.
К тому же есть SQL-инъекция, если $excludeCvid вводится пользователем.
В итоге получился такой код
Тормозил второй запрос, т.к. первый извлекал 49к значений
Так это не проблема использования ORM. В Yii можно сделать IN с подзапросом, оно бы работало так же быстро. То есть банально убрать 2 строчки ->asArray()->column().
Просто видимо при разработке решили, что там не должно быть много id-шников.
То есть получается ваше глобальное переписывание с усложнением внесения изменений было не нужно. Раньше все места использования атрибутов можно было найти по использованию класса Attribute, а теперь надо догадаться дополнительно поискать текстом по слову "attribute" и просмотреть несколько десятков или сотен нерелевантных результатов. Хороший показательный пример, зачем нужны ORM.
Это не проблема, а преимущество.
Смешно
Аналитические функции используются в основном в статистике, а в бизнес-логике встречаются довольно редко. Стастистику мапить на объекты не надо, и поведения у нее нет, поэтому там обычно делают обычный SQL без ORM. В итоге в бизнес-логике используются преимущества ORM, в статистике преимущества SQL.
Про аналитические функции вы какой-то, извините меня, бред написали, видимо никогда с ними не работали. Расчёт трека транспортного средства, превышения скорости, заезд-выезд в геозоны, режим движение-остановки, расход топлива, сливы,
расчёт необходимости в уборке снега на основании дневника погоды, начисление подрядчикам согласно необходимости уборки и пройденного трека.
Это всё бизнес логика.
И если её реализовывать без SQL и аналитических функций, то будет огромная куча слабоработающего и тяжелоподдерживаемого кода.
$excludeCvid, Yii::$app->params['ignoreCvid']
На эти параметры не обращайте внимания, это костыль который не удалось исправить, там с десяток значений…
Но параметры пользователя если это массив, то надо написать через SQL
-- [1, 5, 6]
... IN (SELECT id FROM JSON_TABLE(@json, '$[*]' COLUMNS (id INT PATH "$")))
Так это не проблема использования ORM
Это как раз проблема ОРМ, ОРМ и прикладной язык мотивирует мыслить императивно, а значит более громоздко с кучей лишних шагов.
А если мыслить логически, то когда вам надо будет какое-нибудь событие в очередь кидать с этими id-шниками или кеши обновлять, то вы перепишете все обратно
Вы опять стали заложником императивного подхода. Если мне надо будет id-шник положить в очередь, например, для отправки пушей, то я просто сделаю ещё 1 INSERT
т.е. финальный код по идее должен выглядеть следующим образом:
START TRANSACTION
;
CREATE TEMPORARY TABLE tmp_update
SELECT a.id
FROM `attribute` a
INNER JOIN `option` o ON a.option_id = o.id
INNER JOIN `item` i ON o.item_id = i.id
SET a.status = 0
WHERE i.restaurant_id = 776
AND a.deleted_at IS NULL
AND (a.cvid IS NOT NULL
OR a.cvid NOT IN (
SELECT id FROM JSON_TABLE(@excludeCvid, '$[*]' COLUMNS (id INT PATH "$"))
)
)
AND NOT (a.status <=> 0)
FOR UPDATE SKIP LOCKED
;
UPDATE `attribute` a
INNER JOIN tmp_update t USING(id)
SET a.status = 0
;
INSERT queue (job_type, data)
SELECT 'send_notification', JSON('id', id, 'table', 'attribute')
FROM tmp_update
;
COMMIT
;
Более быстрого и надёжного кода невозможно написать на прикладных языках.
Я вообще ни разу не встречал чтобы с помощью ОРМ приложение стало бы:
— быстрее
— компактнее
— стало бы проще в поддержке
или кеши обновлять
Кэш это костыли, которые легко приводят к непокрываемым никакими тестами ошибкам и ещё тратятся ресурсы на поддержку этих костылей.
Если приходится что-то кэшировать, значит с приложением уже что-то не то, надо серьёзно подумать и попробовать избавиться от кэша.
Расчёт трека транспортного средства, превышения скорости
Я думал, вы агрегирующие функции имеете в виду, SUM/AVG всякие.
И если её реализовывать без SQL и аналитических функций, то будет огромная куча слабоработающего и тяжелоподдерживаемого кода.
Пример, пожалуйста. В моем понимании все, что вы перечислили, требует императивных алгоритмов, которые проще реализовать на обычном языке. На SQL будет тот же самый императивный код, только с особенностями SQL — ключевые слова типа PERFORM и т.д.
Но параметры пользователя если это массив, то надо написать через SQL
Я имел в виду, что $excludeCvid может задавать пользователь через галочки в интерфейсе перед тем как нажать кнопку, которая вызовет deactivateAttributes().
Это как раз проблема ОРМ, ОРМ и прикладной язык мотивирует мыслить императивно, а значит более громоздко с кучей лишних шагов.
Да где ж оно громоздко) Получается тот же самый запрос, как у вас, только не с JOIN, а с подзапросом в IN, и работает с такой же скоростью. Даже строк кода примерно столько же. Раз при этом используется ORM, значит тормоза предыдущего варианта не являются проблемой от использования ORM.
Если мне надо будет id-шник положить в очередь, например, для отправки пушей, то я просто сделаю ещё 1 INSERT
Какой такой INSERT, я говорю про специализированное ПО для очередей, типа Kafka и RabbitMQ.
т.е. финальный код по идее должен выглядеть следующим образом
Да, а в исходном варианте добавится только одна строчка
$kafkaManager->send('channel', array_column($attributes, 'id')). То есть более громоздко получается у вас.
Более быстрого и надёжного кода невозможно написать на прикладных языках.
Да запросто возможно. У вас результат INSERT на диск пишется с обновлением кластерного индекса по первичному ключу, с соответствующими чтениями страниц и перестроениями. А в специализированных очередях либо в памяти хранится, либо стримится на диск с записью в конец файла.
Я вообще ни разу не встречал чтобы с помощью ОРМ приложение стало бы компактнее и проще в поддержке
Про поддержку я привел пример выше, с поиском по "attribute". И в других комментариях приводил. Про компактнее пример с $kafkaManager, и вот тут, где в 3 раза меньше кода получилось. Также я писал про обработку Exception в каждой процедуре и про проверку ролей. В обычном языке это все описывается один раз в базовом классе либо где-то в начале стека вызовов. Просто возможно вы привыкли постоянно руками все исправлять, и вам не кажется это сложным. Либо вы переписываете проект и уходите на другой, оставляя поддержку кому-то другому. Либо просто не хотите замечать и игнорируете все примеры, которые вам приводят.
Если приходится что-то кэшировать, значит с приложением уже что-то не то
Ага, это называется "нагрузка". Можно упорно пытаться оптимизировать миллион SELECT-ов из таблицы с курсами валют, которая обновляется раз в сутки, а можно добавить кеш и не дергать базу лишний миллион раз. Вам возможно важнее иделогическая чистота, а большинству важнее экономия ресурсов сервера без серьезных изменений кода.
Я думал, вы агрегирующие функции имеете в виду, SUM/AVG всякие.
…
Пример, пожалуйста.
Скину сейчас Вам в личку кусочек кода. Код апроксимизации данных уровня топлива, там < десятка запросов, ~700 строк кода, императивного кода можно сказать нет. Код на Oracle со всякими крутыми фишками типа аналитических функций, рекурсивных CTE. Уровень сложности задачи — очень сложно. Код соответственно тоже не простой, но практически доведён со совершенства и работает идеально быстро.
Переписано было с C#, алгоритм был такой — выдёргиваем все данные трека за весь период из Oracle, раскладываем всё по структурам, создаём объектики и начинаем по ним всякими циклами бегать. Там было всё по красоте, структуры, классы, объекты, методы, всё как надо, только кода было на порядок больше, шевелилось еле-еле, памяти выжирало тонну, жило на нескольких сервах и горизонтально масштабировалось, при запуске одновременно больше 5 таких процессов падать начинало всё…
Мрак в общем, не предназначены прикладные языки для обработки данных.
В моем понимании все, что вы перечислили, требует императивных алгоритмов, которые проще реализовать на обычном языке. На SQL будет тот же самый императивный код, только с особенностями SQL — ключевые слова типа PERFORM и т.д.
Поэтому вы и не сможете написать код который бы работал так же быстро и был бы настолько же компактным и простым.
Тут надо научиться мыслить декларативно.
Скиньте мне в личку в ответ какой-нть кусок своего кода, я Вам покажу как его можно сделать быстрым и простым, а то своих примеров уже кучу привёл, а Вы всё не верите, может на примере своего кода поверите.
Какой такой INSERT, я говорю про специализированное ПО для очередей, типа Kafka и RabbitMQ.
Я не буду использовать зоопарк из баз данных, за счёт этого выиграю и в производительности, и в коде, и в администрировании, и в надёжности.
Вот выше пример я Вам рассказывал перехода с Node + Redis + MSSQL на MySQL + Node
habr.com/ru/post/515628/#comment_21977738
Да и не думаю что какой-нть RabbitMQ принципиально быстрее MySQL, да и не та это задача (очереди), чтобы отказываться от синергии единой БД.
Да, а в исходном варианте добавится только одна строчка
$kafkaManager->send('channel', array_column($attributes, 'id')). То есть более громоздко получается у вас.
Ок, так пойдёт? ))
INSERT queue (job_type, data) SELECT 'send_notification', JSON('id', id, 'table', 'attribute') FROM tmp_update
А у вас в какой момент коммит в MySQL будет? До или после постановки в очередь? Если ДО, а код постановки в очередь с ошибкой упадёт? То что вы делать будете? Ну а если ПОСЛЕ постановки в очередь, а коммит упадёт? То как быть? ACID СУБД гарантирует целостность данных в транзакции. У меня в единой транзакции и обновление данных и постановка в очередь, либо всё пройдёт, либо всё откатиться. А вы как будете действовать? Сами велосипед изобретать? А с неконсистентными данными что будете делать? Такую базу вместе с ПО только на помойку выкинуть, ну можно ещё показывать как делать не нужно.
Про поддержку я привел пример выше, с поиском по «attribute». И в других комментариях приводил. Про компактнее пример с $kafkaManager, и вот тут, где в 3 раза меньше кода получилось. Также я писал про обработку Exception в каждой процедуре и про проверку ролей. В обычном языке это все описывается один раз в базовом классе либо где-то в начале стека вызовов. Просто возможно вы привыкли постоянно руками все исправлять, и вам не кажется это сложным. Либо вы переписываете проект и уходите на другой, оставляя поддержку кому-то другому. Либо просто не хотите замечать и игнорируете все примеры, которые вам приводят.
Поиск и подсветка это дело IDE, у меня вроде ищет. У Oracle компиляция пакетов, он на этой стадии валидирует все объекты, если удалить например столбец из таблицы, то пакет который его использовал станет невалидным. Про эксепш не понял, но и я не говорил что надо эксепш в каждую процедуру пихать, как раз наоборот. Про роли тоже непонятно… ну у меня статья есть как RLS в MySQL-е можно реализовать, кода минимум, всё в одном месте.
Ваш пример по ссылке, это ж КвериБилдер, уже много раз писал что это дичь дичайшая, на простеньком запросике ещё можно написать, будь что-нть посложнее, это во-первых превратиться в нечитаемую абракадабру, во-вторых, сгенерит абсолютно никому не известный SQL, который потом придётся отлаживать, очень часто на Laravel'е с этим КвериБилдером ошибки вываливаются, часто генерит не то что хотел разраб. Ну и в-третьих, реально сложные запросы он просто не в состоянии сгенерить.
Ага, это называется «нагрузка». Можно упорно пытаться оптимизировать миллион SELECT-ов из таблицы с курсами валют, которая обновляется раз в сутки, а можно добавить кеш и не дергать базу лишний миллион раз. Вам возможно важнее иделогическая чистота, а большинству важнее экономия ресурсов сервера без серьезных изменений кода.
Ну базу как раз и нужно дёргать, она для того и существует, единственно достоверный источник данных, у MySQL часто используемые данные и так лежат в памяти в innodb_pool, в который обычно вся база и помещается.
Т.е. всё работает и так быстро, тут гораздо важнее правильно извлекать эти данные, т.е. написать правильный SELECT
Скину сейчас Вам в личку кусочек кода.
Решил отложить ответ здесь, пока не разберусь в алгоритме. На PHP получается заметно меньше кода за счет вынесения копипасты в функции и простой работы с массивами, и я бы не сказал, что там сильно сложные вычисления, все в рамках обычной статистики. Разве что если данных слишком много, то придется кусками читать. Из аналитических функций используются только LAG, LEAD, и MEDIAN, которые несложно реализовать в обычном языке. Код императивный, результаты предыдущих запросов используются в следующих, и поменять местами их нельзя.
со всякими крутыми фишками типа аналитических функций
Аналитические функции нужны только в SQL из-за его декларативной природы. Обычно их называют оконные функции, поэтому я не сразу понял, о чем вы говорите. В обычном языке программирования они не нужны или реализуются тривиально, обычно в сочетании с сортировкой данных для имитации PARTITION BY. LAG и LEAD например это предыдущий и следующий элемент массива, $a[$index - 1] и $a[$index + 1].
Скиньте мне в личку в ответ какой-нть кусок своего кода, я Вам покажу как его можно сделать быстрым и простым
Ну вот пример, который я выше привел, сделайте. Особенно интересует про "простым")
$subscriptionList = UserSubscription::find()
->where(['=', 'status', UserStatus::ACTIVE])
->andWhere(['<=', 'subscr_date', $ldLastDate])
->with('user')
->all();
return $subscriptionList;У меня нет таких примеров, перенесение которых в БД улучшит поддержку приложения. Мне не нужен быстрый и простой код (а на самом деле не простой), который сложно поддерживать. Вернее, всегда есть компромисс, и в большинстве случаев он не в пользу ускорения.
а то своих примеров уже кучу привёл, а Вы всё не верите, может на примере своего кода поверите.
Повторюсь, я согласен, что обработка в БД может дать ускорение, я и сам так делал, в основном для всяких отчетностей. Я говорю о том, что в большинстве случаев увеличение сложности поддержки это не оправдывает. Особенно на уровне "переносим всю логику в БД". Основной критерий — поддерживаемость, а не быстрота.
Если ДО, а код постановки в очередь с ошибкой упадёт? То что вы делать будете?
Записываем в базу, после успешного коммита пишем в очередь. Если ошибка записи в очередь, повторяем несколько раз, потом падаем с сообщением об ошибке, сообщение об ошибке записывается в лог.
Зависит от задачи в общем-то. Иногда может понадобиться писать в очередь после открытия транзакции и до коммита в БД, но обычно БД это главный объект обеспечения достоверности. Если туда записано, то в остальные сервисы можно прочитать оттуда и отправить.
ACID СУБД гарантирует целостность данных в транзакции. У меня в единой транзакции и обновление данных и постановка в очередь
Ну вот поэтому у вас и долго, поэтому можно написать более быстрый код.
А вы как будете действовать? Сами велосипед изобретать?
Такую базу вместе с ПО только на помойку выкинуть, ну можно ещё показывать как делать не нужно.
Ага, расскажите это всем компаниям, у которых этими инструментами нормально обрабатывается Big Data.
Ничего не надо изобретать, для этих инструментов есть наработанные механизмы отказоустойчивости, либо встроенные, либо отдельными проектами.
А если уж сильно надо, можно и велосипед написать. Он работает в сторонке и основной бизнес-логике не мешает, ее переписывать не надо.
Вы сначала за скорость топили, а теперь уже надежность появилась. Опять появляется вопрос критериев, который вы и другие сторонники логики в БД почему-то игнорируют.
Про эксепш не понял, но и я не говорил что надо эксепш в каждую процедуру пихать, как раз наоборот.
Тогда у вас ошибки в этих процедурах будут теряться.
Про роли тоже непонятно… ну у меня статья есть как RLS в MySQL-е можно реализовать
Я имел в виду, что автор предлагает писать специальный IF в каждой процедуре.
В вашей статье:
"Обновились только строки которые видим" — Как сделать показ ошибки "Доступ ограничен, запросите доступ у вашего менеджера на такой-то странице"?
"Можно добавить ещё одно VIEW e_docs" — Копипаста из t_docs с изменениями, куча лишних сущностей (вьюшек). Если кроме warehouse_org_id надо будет проверять номер офиса или там подразделения, надо будет везде искать и исправлять.
Никак нельзя на SQL копипасты избежать, не предназначен он для написания логики.
будь что-нть посложнее, это во-первых превратиться в нечитаемую абракадабру, во-вторых, сгенерит абсолютно никому не известный SQL
Не превратится и не сгенерит. Часто проверяю, что он там сгенерил, все нормально. Если в кверибилдере будет абракадабра, то в SQL и подавно, обратных примеров вроде не встречал. Если нужен сильно сложный запрос, его можно на чистом SQL написать. Из-за пары случаев усложнять весь код нет смысла.
часто используемые данные и так лежат в памяти в innodb_pool, в который обычно вся база и помещается
Любая база работает медленнее, чем отдельный кеш, а закешированные результаты запросов часто выбиваются другими запросами. Как раз из-за ACID.
А еще вы не учитываете подключение к БД по сети и авторизацию с проверкой прав доступа. Не подключаться к БД миллион раз работает быстрее, чем подключаться, даже если запросы не выполнять.
Жалею немного что Вам такой сложный пример дал что Вы с ним зашились, но это и есть реальная работа, а не студенческие проектики, не домашние странички…
Могу скинуть код попроще типа агрегации трекинговых данных, тот код который сможете осилить, убедитесь что он реально будет компактнее и быстрее работать.
Жалею немного что Вам такой сложный пример
Так это плохо говорит о вашем коде) Потому что из него непонятен алгоритм, нужно спрашивать автора, какие там данные в таблицах и что он хотел сделать. Это и имеют в виду, когда говорят о сложности поддержки. Не говоря уже про однобуквенные переменные в вашем коде.
Я перенес на PHP только половину кода, так как не хотел отвлекать вас вопросами. Давайте я их задам, вы на них ответите, я перепишу полностью и напишу статью про рефакторинг. Узнаем мнение аудитории Хабра. Согласны?
убедитесь что он реально будет компактнее и быстрее
работать.
А зачем убеждаться, если
Основной критерий — поддерживаемость, а не быстрота.
Вообще впечталение, что сторонники переноса всей бизнес-логики в базу руководствуются прежде всего скоростью работы.
но это и есть реальная работа, а не студенческие проектики, не домашние странички
Раз уж вы решили помериться, могу описать один кейс, которым недавно занимался. Есть хранилище Apache HBase с несколькими миллиардами записей, он возвращает JSON с данными полей в base64, одно из полей содержит другой JSON, специфичный для источника данных. Надо достать данные за некоторый диапазон дат, декодировать JSON->Base64->JSON, достать из результата некоторые поля, разные для каждого источника, построить XML и выдать его на STDOUT, который читает другая программа. С повторением чтения в случае ошибок сети, параллельной обработкой для ускорения, и т.д. Полная обработка всех данных с распараллеливанием занимает недели 2. Там много кода с классами, широко используется ООП и наследование. Самая что ни на есть обработка данных. Ну как, сможете такое сделать на SQL?
Если что, на HBase перешли после MySQL, там и запись была долгая, и чтение по диапазону дат, и шардинг с отказоустойчивостью приходилось вручную реализовывать. Консультировались по настройке с техподдержкой MySQL (или может это Percona была), сказали, что быстрее сделать не получится. Поэтому перешли на другую БД, нереляционную. С быстрым доступом по ключу и сканом по диапазону ключей, диапазон дат кодируется в ключе.
Есть хранилище Apache HBase с несколькими миллиардами записей, он возвращает JSON с данными полей в base64, одно из полей содержит другой JSON, специфичный для источника данных. Надо достать данные за некоторый диапазон дат, декодировать JSON->Base64->JSON, достать из результата некоторые поля, разные для каждого источника, построить XML и выдать его на STDOUT, который читает другая программа. С повторением чтения в случае ошибок сети, параллельной обработкой для ускорения, и т.д. Полная обработка всех данных с распараллеливанием занимает недели 2. Там много кода с классами, широко используется ООП и наследование. Самая что ни на есть обработка данных. Ну как, сможете такое сделать на SQL?
Самый главный вопрос: а чем занимается та программка, которой отдают данные на вход? Возможно написав логику преобразования + логику той программы, можно было бы ускорить на порядки процесс. Ну, а преобразование форматов это совсем не то для чего разрабатывались СУБД, хотя думаю PostgresSQL легко бы справился с JSON->Base64->JSON->XML, а на MSSQL с его FOR JSON PATH, FOR XML, наверняка ещё бы компактнее можно было написать…
Вот, кстати, только вчера хорошая статья вышла как в PostgresSQL большие данные обрабатывают
habr.com/ru/company/tensor/blog/516384
я перепишу полностью и напишу статью про рефакторинг. Узнаем мнение аудитории Хабра. Согласны?
В личку предложил: вместе придумать интересный кейс и написать совместную статью, рассмотрев проблему с двух сторон, плюсы/минусы. Думаю это действительно будет полезно сообществу.
а чем занимается та программка, которой отдают данные на вход? Возможно написав логику преобразования + логику той программы, можно было бы ускорить на порядки процесс.
Построение полнотекстового индекса. Программа сторонняя, написана на C++. Сомневаюсь, что SQL быстрее C++. Логика преобразования идет в 20 потоков, а SQL однопоточный, здесь тоже вряд ли можно ожидать ускорения.
вот поэтому Вы и не можете написать тот код, который я вам скинул, ни на 2000 строк в PHP ни даже на 5к, просто прикладные языки не предназначены для этого
Если кому-то интересна эта дискуссия, я переписал присланный мне в личке алгоритм полностью. Если убрать пустые строки и одиночные закрывающие скобки, получается:
SQL — 606
PHP — 411
Если не убирать, то 656/566 соответственно.
На PHP на треть меньше кода и практически нет скопированных участков, что упрощает понимание и внесение изменений. При этом там кое-где код можно сделать еще попроще, и добавить использование ORM, тогда кода будет меньше раза в 2.
Понятно, что это просто слова, и без кода их проверить нельзя, но раз об этом зашел разговор, то надо упомянуть и то, что получилось в результате.
Тормозил второй запрос
Добавлю, что возможно это было из-за дополнительного OR, из-за чего оптимизатор не мог нормально оптимизировать запрос. Лично я бы все равно так не сделал, я бы OR поместил в первый запрос. Фильтр по IN лучше делать единственным, тогда он мало чем отличается от JOIN по ключу.
Дак конечно вести! Если эти данные могут потребоваться для обработки. Ну в конце концов, можно просто при старте сервиса из .env загружать в соответствующую табличку.
В большинстве случаев, имхо, это только потому что:
- нет простого, удобного и быстрого способа работать с файлами и внешними переменными из хранимок
- нет даже глобальных констант
Иными словами, решили перенести БЛ в хранимки — надо переносить и её параметры и прочие конфиги в таблицы или тупые функии типа getDefaultLanguage => RETURN SELECT 'ru', потому что другого нормального способа нет
— маленьких проектов
— пэт проектов
— студенческих проектов
— для демонстрации ОПП: смотрите, у нас тут инкапсуляция, наследование, объектики, стрелочки
А для больших серьёзных проектов с большими данными только SQL, с ним проще, быстрее, дешевле
-Ну работал я с ORM, проблем не было.
-проект какой, размер, нагрузка?
-ну маленький…
Не для демонстрации ООП, а для использования его преимуществ. Ну и есть мнение, что с реально большими данными SQL не справляется, даже если горизонтально масштабироваться вроде не нужно: скорость вставки и скорость выборки обратны друг другу: или обложимся индексами и получим медленную вставку, или почти моментальная вставка, но фуллскан
Это точно ANSI SQL
CREATE TABLE mydataset.newtable
(
x INT64 OPTIONS(description="An optional INTEGER field"),
y STRUCT<
a ARRAY<STRING> OPTIONS(description="A repeated STRING field"),
b BOOL
>
)
PARTITION BY _PARTITIONDATE
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
partition_expiration_days=1,
description="a table that expires in 2025, with each partition living for 24 hours",
labels=[("org_unit", "development")]
)?
Вы можете как угодно формировать входные параметры и ответ, получив данные из БД. Как угодно их проверять, валидировать и т. п. без задействия подключения к БД (дополнительный пинг, как минимум, для пользователя). применять какие-то трансформации, параметры, которых записаны не в БД или в совсем другой БД. Обогащать данные одних таблиц данныеми не из БД и т. п.
В нашем проекте 95+% процентов задач бэка связаны именно с работой с данными, и для этих задач SQL подходит гораздо лучше любого не-SQL языка. Поэтому от PHP-кода в 1 млн строк осталось меньше 10К строк (и то почти весь на Go переписали)
Есть гипотеза, что множество других проектов также выиграют от такого маневра. Со своей стороны постараюсь наглядно показать его бенефиты
На нашем проекте 100% задач связано с работами с данными. Но вот формировать, например, HTML разметку на SQL из данных в таблицах я больше не хочу — уже был такой опыт. Лучше я вытяну данные одним или несколькими SQL запросами в табличном виде и обработаю их на PHP и отдам пользователю хоть в HTML, хоть в JSON, хоть в XML — в зависимости от HTTP заголовка.
А почему у вас так сильно уменьшилось количество кода надо смотреть на конкретных примерах.
(сравните мой пример и пример ниже на PHP)
Насколько я понял, это приведено в качестве шутки.
В итоге PHP (или другой язык) просто дергает грамотный SQL-запрос, написанный специалистом.
В том запросе нет ничего, что требует грамотного специалиста по БД. Там 2 обычных селекта с обычным WHERE. Такие примеры приводятся в любой книге по PHP для начинающих и в документации к фреймворкам.
Вопрос ценности такой прослойки у меня и вызывает сомнения.
И в той, и в этой статье в комментариях много лющдей написали, что основная ценность — проще писать код и вносить изменения, в том числе тестировать, масштабировать, подключать внешние сервисы, использовать системы контроля версий и ветки в них.
Дроблением на простые запросы этого не решишь — наоборот, только усложнишь разработку и производительность снизишь в десятки раз.
При работе с данными 90+% времени уходит на тестирование запросов: какие планы они используют, насколько быстро выполняются. Какие для этого есть средства в PHP?
Тот же плагин в PhpStorm на базе которого построена DataGrip )
Правда, если писать логику на PHP, то гораздо меньше времени нужно на запросы тратить.
Кстати, а какие средства построковой отладки есть postgres?
Так вот из таких простых селектов потом и вырастает монолит на миллионы строк кода. И сервера жрет немеренно.
Не понимаю. У нас идет разговор про ваш пример процедуры с двумя селектами. Если из них вырастает монолит на миллионы строк кода, зачем тогда ваш подход использовать?
Идея современного SQL — в том, чтобы писать эффективные запросы
Да никто не спорит с тем, чтобы писать эффективные запросы. Спорят с тем, откуда их вызывать — из базы или из приложения.
Дроблением на простые запросы этого не решишь
Да я вроде и не говорил, что решишь. У вас 2 запроса, в том примере на PHP 2 запроса, в моем примере на PHP тоже 2 запроса. Никакого дробления нет.
При работе с данными 90+% времени уходит на тестирование запросов: какие планы они используют, насколько быстро выполняются. Какие для этого есть средства в PHP?
Зачем проверять планы запросов на PHP? SQL с EXPLAIN нормально с этим справляется.
Если у вас 90% времени уходит на тестирование запросов, это может говорить о том, что ваш подход неоптимален и занимает много времени при разработке. Ну а что, вы только и делаете, что запросы тестируете, вместо того, чтобы бизнес-логику писать)
Если из них вырастает монолит на миллионы строк кода, зачем тогда ваш подход использовать?
Монолит вырастает, если делать множество мелких запросов и обрабатывать сырые данные в PHP. Пример выше очень простой. Для более сложной задачи (например, отобразить страницу как эта на хабре) потребуется гораздо больше запросов. Так вот, в рамках SQL это вполне можно уместить в один качественный запрос, и сразу вернуть json, на базе которого будет построена страница. Навскидку в пределах 500 строк будет хранимка.
Спорят с тем, откуда их вызывать — из базы или из приложения.
Да, вот и у меня вопрос — зачем из приложения запрос запускать, если он все равно в базе выполняется? Это как просить соседа открывать вам дверь, хотя можете и сами открыть ключом.
У вас 2 запроса
У меня один запрос, планировщик его один раз прогнал, и более того план сохранил — больше не будет дергаться. И чем сложнее запрос, тем больше будет различие в скорости.
SQL с EXPLAIN нормально с этим справляется.
Так если Вы все равно лезете в базу и оптимизируете там запросы, то почему там сразу весь код не сделать?
запросы тестируете, вместо того, чтобы бизнес-логику писать)
Запросы и есть бизнес-логика) Они на входе берут параметры и на выходе дают ответ с данными.
Монолит вырастает, если делать множество мелких запросов и обрабатывать сырые данные в PHP.
Ну у вас 2 запроса, и в PHP 2 запроса. У вас будет больше запросов, и в PHP будет больше запросов. Вообще никакой разницы. Если в PHP будет монолит, то и у вас будет монолит.
Так вот, в рамках SQL это вполне можно уместить в один качественный запрос, и сразу вернуть json, на базе которого будет построена страница. Навскидку в пределах 500 строк будет хранимка.
Ну а в PHP это можно уместить в одну качественную функцию, и сразу вернуть ассоциативный массив, на базе которого будет построена страница. Навскидку в пределах 100 строк будет функция. У меня вон там в другой ветке в 3 раза меньше кода получилось, чем на SQL.
Да, вот и у меня вопрос — зачем из приложения запрос запускать, если он все равно в базе выполняется?
Потому что это сложно поддерживать.
https://habr.com/ru/post/515628/#comment_21976090
https://habr.com/ru/post/515628/#comment_21973700
https://habr.com/ru/post/515628/#comment_21973912
Это только мои комменты. Другие люди тоже примеры приводили.
У меня один запрос
Там 2 селекта, и движок БД будет выполнять 2 запроса.
Так если Вы все равно лезете в базу и оптимизируете там запросы, то почему там сразу весь код не сделать?
Потому что это сложно поддерживать.
И вообще, из-за одного EXPLAIN весь код в базу переносить? Это какой-то странный критерий построения приложений. Я еще и в PHP лезу, и код без запросов там пишу. Почему из-за этого там весь код не сделать?
Запросы и есть бизнес-логика)
Нет, бизнес-логика это то, что в них описано. Сущности, их взаимосвязи и логика обработки. А вы получается 1 час в день ее пишете, а 7 часов тестируете.
Ну давайте пример. Допустим, у нас есть массив точек и мы теперь хотим их хранить в формате GoogleMaps. Код для подбного преобразования можно посмотреть здесь: https://github.com/narfunikita/Osrm.Client/blob/master/Src/Osrm.Client/OsrmPolylineConverter.cs#L68
Соответственно в сишарпе это будет выглядеть как:
using Osrm.Client;
var points = db.GetPointsSomehow();
var encodedPath = OsrmPolylineConverter.Encode(points);
return encodedPath;То есть, выгрузили с БД точки, заэнкодили, отправили. Покажите, как это будет выглядеть на SQL. Если на SQL нет подобного конвертера, конечно, нужно показать как его можно написать (и это будет минусом для SQL что для него нет библиотеки которую можно подключить в 1 строку).
Можно одним запросам получить, например, список объектов с сортировкой по удалению от конкретной точки (или других объектов)
SELECT * FROM places ORDER BY location <-> point '(101,456)' LIMIT 10;
SQL-язык тем и хорош, что отлично подходит не только для написания запросов, но и для чтения этих запросов другими программистами. По нашему опыту, ввод грамотного разраба в тему занимает около месяца — затем он пишет качественные хранимки. Чем компактнее и понятнее ваш код, тем проще его и поддерживать, и развивать, и новых людей привлекать
Вопрос автору: Есть IDE, разработчики привыкли что в ней есть типизация и автокомплит, так же тулингом может контролироваться что зависимости удовлетворены (статический анализ). Есть так же линтеры (могут проверять сложность кода, кодстайл и частные случаи). Все это помогает рефакторить (и иметь чуть больше уверенности что не ломаешь старое) и вводить новых людей в курс дела (можно назвать это самодокументируемым кодом если на то пошло) и позволяет держать связи между элементами системы в более надежной сцепке. Если команда растет, то необходимость в таких инструментах тоже растет.
Как обстоят дела со статическим анализом, автокомплитом, типизацией?
Пример:
SELECT _ FROM _ WHERE status = _;Везде где "_" хочу видеть автокоплит, особенно в поле status и не значений, а понятных констант с понятными наименованиями.
Автокомплитом качественный SQL-запрос не напишешь. И анализ идет не кода, а самого запроса (для этих целей есть EXPLAIN ANALYZE).
Это примерно как сравнивать автомобиль и самолет: способы управления совершенно разные. Хотя и тот, и другой предназначен для перемещения в пространстве.
В датагрипе есть автокомплит хороший:
Реализация бизнес-логики на уровне хранимых функций PostgreSQL