Здравствуйте, читатели. Я порывался написать эту статью уже несколько раз, но каждый раз откладывал, поскольку, при мысли о необходимости провести глубокую рефлексию по накопленному опыту, меня накрывало уныние и печаль. Однако, я укрепился в своем намерении сделать это, чтобы поделиться опытом с теми из вас, кто планирует заняться чем-то подобным в сфере AI. Все нижеописанное относится к весьма конкретной сфере деятельности: AI в части компьютерного зрения.
Disclaimer: Я не специалист в нейросетях, но выполняю роль владельца продукта, в котором ключевую роль занимают нейросетевые модели компьютерного зрения. Эта статья для тех, кто вынужден делать такую же работу, а так же для тех специалистов ML, которые хотят понять, как на их деятельность смотрят люди со стороны бизнеса.
Итак, мы делаем продукт на основе компьютерного зрения, включающий детекцию, трекинг, идентификацию, реидентификацию людей, определение их пола и возраста.
Мы уже давно делаем различные проекты, в том числе с элементами ML, но проект, где эта часть занимает центральное место, мы делали впервые. За это время я, как владелец продукта, узнал много нового, странного и сформулировал некоторые принципы, которые важны для достижения успеха при создании таких продуктов.
Риск в продуктах с AI
Риск колоссальный. Собственно, создание AI-продукта фактически заканчивается, когда весь риск снят. Если в случае создания продуктов на классических алгоритмах вы тратите на работу с риском от 5 до 20% времени, то, в случае с AI-продуктами, сам процесс создания продукта — это борьба с риском. Я оцениваю объем потраченного времени на борьбу с риском до 90-95% времени от создания AI продукта. Из данного наблюдения следуют важные выводы.
Для продуктовых компаний
График доставки, а значит и стоимость с высокой степенью вероятности будут многократно провалены, с чем мы и столкнулись.
Риск настолько велик, что делать что-то по продукту до того, как завершена, протестирована и сдана часть, связанная с AI не имеет смысла.
Для контракторов
Заказчиков в сфере разработки AI-продуктов в SMB будет мало/не будет. Если вы не можете "зайти" к условному Tinkoff, можно сворачивать лавочку, хорошего бизнеса не будет. Государство — самый вероятный и прибыльный клиент.
Лучше сосредоточиться на разработке пайплайна для решения конкретных задач и предлагать услуги на его основе, чем браться за все что угодно в сфере того же компьютерного зрения. Тогда вы будете делать типовые инженерные проекты для клиентов, а не проекты в духе "дайте нам денег на то, чтобы понять что это вообще можно сделать".
Для руководителей
Не соглашайтесь работать над подсистемами AI по Scrum или другим методологиям, которые фиксируются на сроках продвижения.
Мне кажется, что для создания подсистем, использующих AI, Agile подходит плохо, потому что, при его использовании, вы будете двигаться в ритме "3 шага вперед, затем 2 назад" с непредсказуемыми сроками доставки функционала.
Никому нельзя верить
Практически все опубликованные материалы по работе моделей не поддаются верификации или получены на смешных наборах данных. Мы многократно сталкиваемся с тем, что научные статьи, описывающие те или иные подходы грешат искажением фактов, выдаванием желаемого за действительное.
Из недавних диалогов с тимлидом:
Контекст: YOLOv4 – самая точная real-time нейронная сеть на датасете Microsoft COCO
Я: а зачем мы тестируем нейросеть Yolo4 в сравнении с Yolo3;
TL: потому что мы не верим создателю модели, даже если он наш соотечественник.
В итоге, на наших данных местами Y3 выигрывает у Y4, являясь более предпочтительной.
Необходимость все проверять ведет к очень медленному продвижению по доставке продукта.
Четко зафиксируйте условия работы
Это не является открытием для инженера в сфере ML, но вы вряд ли об этом услышите от него четко и ясно. Мысль очень проста и проистекает из природы обучения нейросетевых моделей: подобрать/научить модель, которая будет работать в зафиксированных условиях, в разы проще, чем сделать модель, которая будет работать в широком спектре условий.
Простыми словами. Представьте, что вы делаете конвейеры для куриных яиц. Хотите поставить камеру на конвейер, чтобы она определяла дефектные яйца, цвет, размер, whatever. Вы даете задание ML-отделу решить эту задачу для вашего конвейера, для определенной модели камеры, в определенном месте крепления камеры, при определенном освещении. С высокой степенью вероятности задача будет успешно решена.
Теперь представьте, что вы делаете софт для подсчета яиц, который может быть установлен владельцами конвейеров по своему усмотрению в неизвестных условиях, на неизвестном расстоянии от ленты, неизвестных моделях камеры. Этот проект намного сложнее, а в общем виде, скорее всего обречен на провал.
Для вас это может стать откровением (как стало для меня), но мировоззрение и кругозор инженеров в сфере ML формируется именно на задачах первого типа. Задачи второго типа требуют от исполнителя иметь четкую связь с бизнес-реальностью, постоянно прокручивать в голове разные кейсы и их влияние на модель. Это доступно немногим, не стоит ожидать этого от всех специалистов.
Используйте метод пристального взгляда для оценки
Метод пристального взгляда заключается в том, что вы как владелец продукта смотрите на результат и говорите — ОК или не ОК. Требуйте подтверждение работоспособности на ваших данных в первую очередь именно таким способом.
Если вы не будете требовать подтверждения работоспособности таким образом, вы вряд ли сможете сами верить в то, что продукт работает, а убедить в этом ваших клиентов будет еще сложнее. Прекрасные статистические метрики в первую очередь ценны для самих инженеров, чтобы постоянно понимать как изменения влияют на результат.
Помните, что модель с прекрасными показателями Precision, Recall, F1, etc. при тестировании методом пристального взгляда может очень огорчить вас.
В общем, понятно, что хочется 99.99% всего и сразу, но часто визуальное подтверждение корректности дарит куда большую степень уверенности и воодушевляет людей, которые спонсируют разработку, чем красивые цифры, которые при практическом рассмотрении будут давать неоднозначные результаты.
Снизьте разрыв с бизнес-требованиями
Большинство нейросетей требуют, чтобы изображение обладало вполне определенным разрешением перед подачей в нее. Самый простой вариант, который применяется на практике — приведение исходного изображения к желаемому. Часто это не является проблемой, однако для детекторов single shot эта операция вообще может быть нелегитимной.
Ситуация. Допустим, вы хотите обрабатывать в realtime поток видео с помощью Yolo4. Ставите задачу инженеру — дай мне 60 FPS пайплайна на Tesla T4. Он выберет сетку размера 416x416 и будет приводить видео из исходного размера к этому, показывая вам, что все работает на заданном FPS.
При этом, очевидно что у Yolo4 есть минимальный размер людей в пикселах, которых она четко определяет (FYI: он составляет ~ 15% от высоты фрейма (около 110 px для 720p). Все люди, которые меньше этой высоты, будут детектироваться с низким качеством. Этот вопрос скорее всего останется за кадром, если никто его не поднимет на повестке. Я выяснил важность данного аспекта на кейсе, который приведен далее.
Нормальный человек думает так: чем больше разрешение видео — тем больше важных деталей на нем и тем лучше все будет работать. В случае с шаблонным стандартным подходом применения детекторов single shot в ML это не так — вообще нет никакой разницы какое разрешение вы подали, поскольку ваш фрейм просто уменьшат до размера входа нейросети и вы не получите никаких преимуществ.
Здесь есть явное противоречие бизнес-ожиданий и технологических возможностей.
Самое странное из того, что я видел выглядело так:
- целевое видео было размечено на предмет детекции людей;
- это видео было скормлено двум нейросетям Yolo4 размера 320x320, 416x416;
- получены разные результаты и спокойно записаны в таблицу.
Я не смог получить понятный ответ на вопрос "Зачем вы это делали, если, очевидным образом, при уменьшении размера, часть людей просто выпало из поля зрения нейросети 320x320, но осталась в 416x416"?
Правильный процесс, на мой взгляд, должен был выглядеть так:
- выполнить разметку видео;
- определить порог размера фигурки человека, которую может видеть нейросеть;
- выполнить масштабирование видео вы целевые разрешения нейросети;
- удалить из разметки те фигурки, которые стали меньше, чем порог детекции;
- провести бенчмарки.
На самом деле, мораль в том, чтобы подтвердить легитимность подхода с масштабированием изображения при использовании детекторов single shot в рамках заданных бизнес-требований.
Добейтесь общения на человеческом языке
Я в IT уже 15 лет, умею программировать на нескольких языках, хорошо знаю матчасть. Однако, каждый раз когда я общаюсь с отделом ML, самая частая фраза, которую я говорю: "Я не понимаю, объясните понятнее".
Мне не обломно говорить это столько, сколько надо, в противном случае меня просто завалят переусложненными, специфическими вещами с кучей деталей, под которыми пропадет свет истины.
У нас есть прецеденты, когда специалисты из BigData или Backend не могут найти общий язык с людьми из ML, поскольку не каждый может и хочет заставлять людей общаться на понятном языке.
В общем, используйте "Я не понимаю" тогда, когда вам это удобно. Я вообще часто использую… Если мне начинают рассказывать что-то в терминах инструмента исполнителя, я стараюсь перевести рассуждения в область логических размышлений вне специфики домена знаний исполнителя, чтобы оценить разумность.
Как только исполнитель начинает рассказывать о реализации в рамках своего инструмента — это красный флаг для обсуждения задачи.
Если вы, как менеджер, не можете добиться того, чтобы ваши специалисты ML объяснили вам все на понятном вам языке, думаю, что стоит сразу менять либо работу, либо специалистов.
Инструменты для производительного инференса — Terra Incognita
Если вам надо, чтобы работало быстро на платформе Nvidia — вам надо связываться с Nvidia DeepStream или аналогичными фреймворками. Однако, через DeepStream точно будет быстрее всего. Из моего разговора с представителем Nvidia Inception, они настолько заинтересованы в том, чтобы кто-то делал и демонстрировал практические кейсы на DeepStream, что складывается впечатление, что это почти никто не умеет.
При этом переход от "Работает в PyTorch" к "работает на DeepStream" это отдельный большой и сложный проект, который может потребовать как написать что-то нетривиальное на C, чтобы расширить Gstreamer, так и поменять модели, поскольку они, например, не совместимы TensorRT.
Сама по себе отладка приложений в DeepStream — это тоже отдельная песня, которая включает регулярную борьбу с Segmentation Fault, даже если вы программируете на Python c NumPy, а сама отладка — весьма нетривиальна из-за архитектуры Gstreamer.
Но, если вы хотите максимально быстрый инференс на Nvidia — это один из немногих путей добиться эффективного использования ускорителей. Мне кажется, что скоро возникнет отдельная отрасль разработки — реализация производительного инференса на Nvidia, поскольку требования к знаниям инженеров для реализации таких пайплайнов выходят как за ожидаемые требования к знаниям для инженеров ML, так и требования к знаниям разработчиков.
Смекалка и брутфорс
ML-инженеры стремятся оставаться в рамках своих инструментов и склонны к брутфорсному решению задач именно искусственным интеллектом. Они будут пытаться решить проблему в рамках своих инструментов, всячески игнорируя эвристики, логические ограничения бизнес-среды, etc. При этом фокусировка на данных аспектах может значительно ускорить производительность и снизить нагрузку на оборудование.
Будет здорово, если вы сможете добиться того, чтобы в вашей команде таким аспектам системы уделялось должное внимание.
Добейтесь четкого понимания цели движения и плана по ее достижению
Нигде раньше, я не видел такой ценности в диаграммах WBS как в ML… Каждый аспект ML-пайплайна требует существенной работы для снятия риска доставки. Я пришел к тому, что сделал в Trello вот такую канбан-борду, чтобы оценивать готовность ML-части продукта с точки зрения удовлетворения бизнес-потребностей.
Картинки кликабельны:
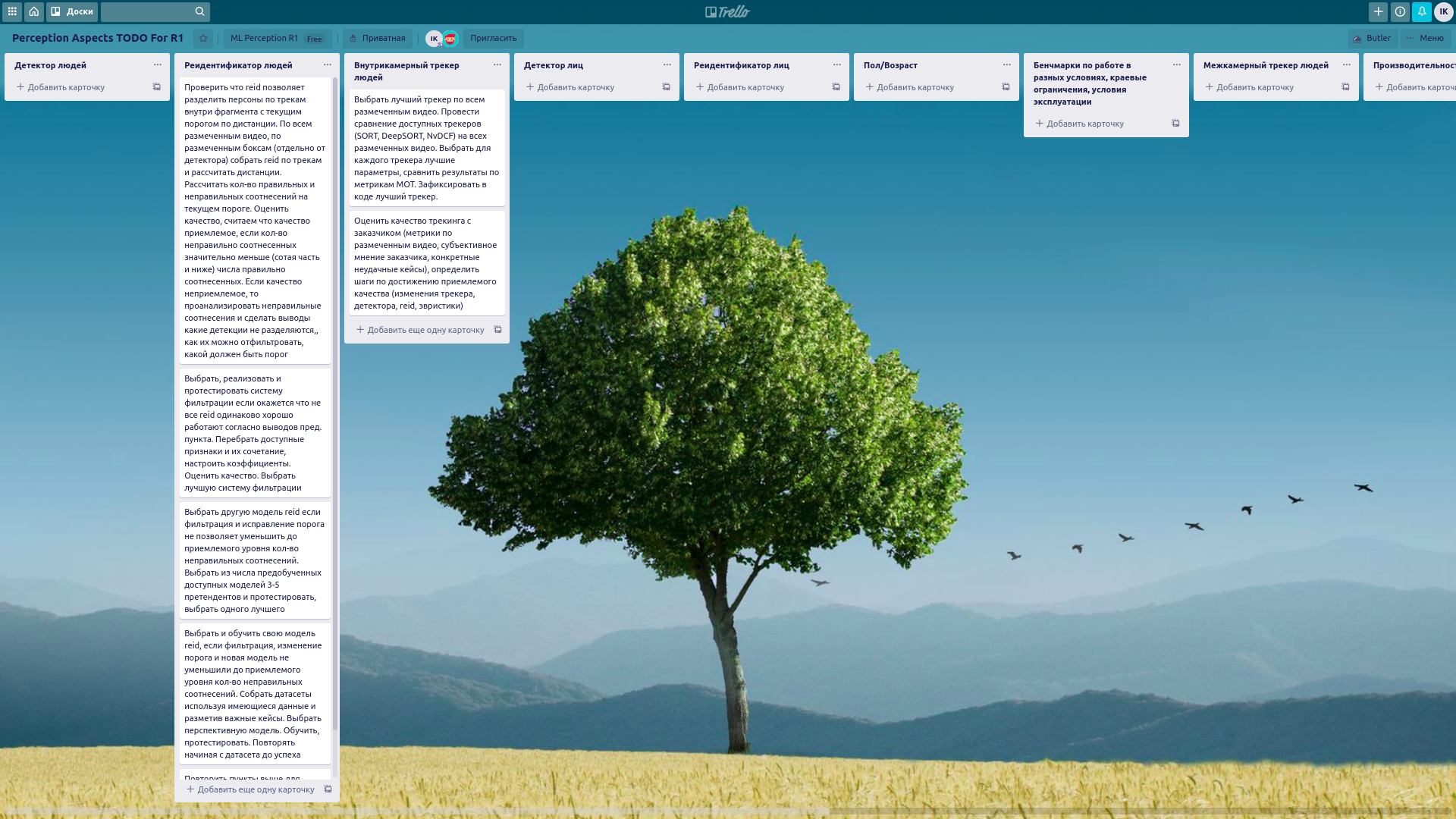
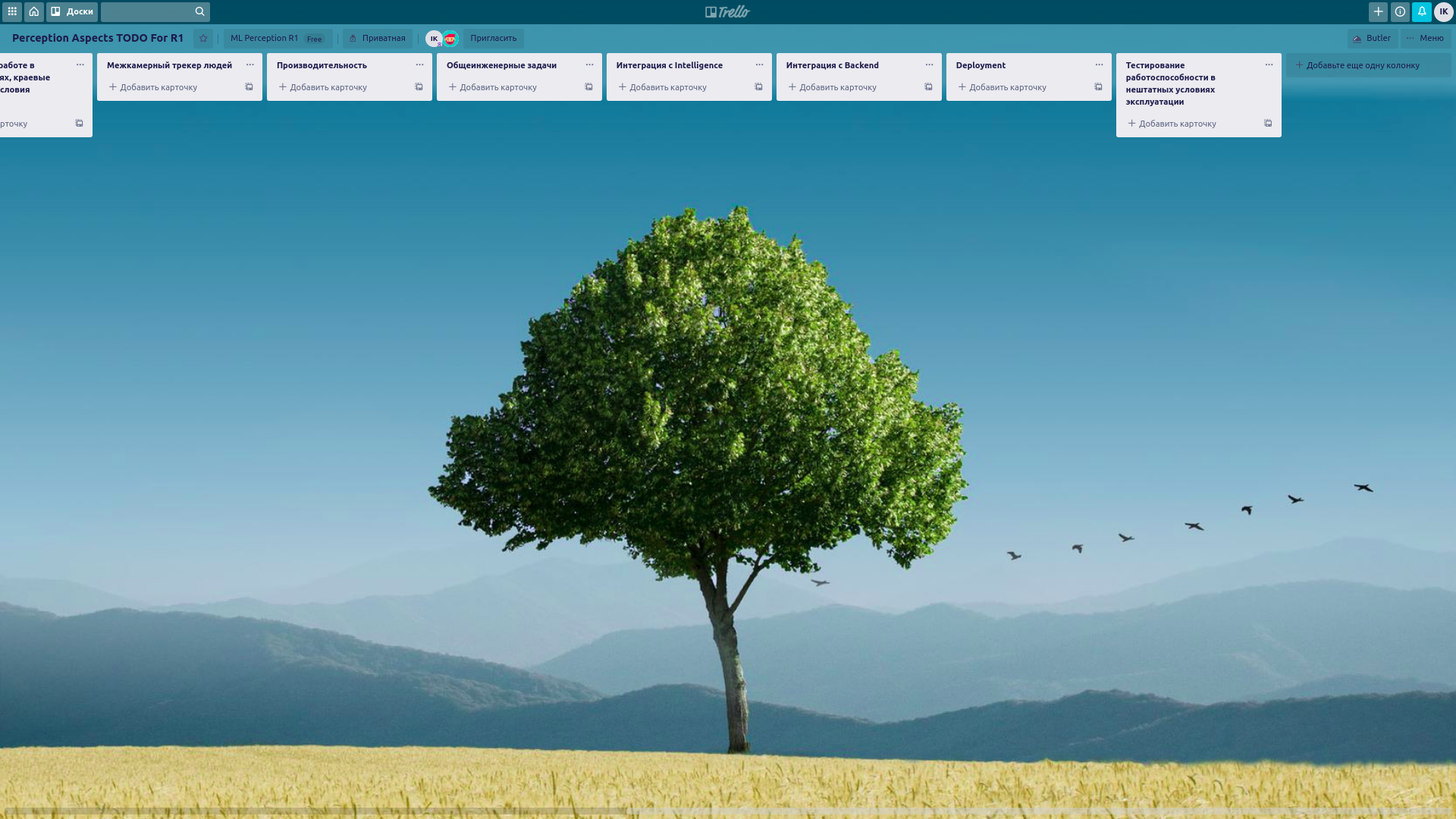
Ослеживайте связь задач, которые создаются в системе управления задачами, с карточками в WBS.
Используйте инструменты принятия решений при создании задач
Именно в разрезе ML я осознал важность различных методик при работе над задачами. В обычных инженерных проектах этого не требуется — декомпозиция легка и непринужденна, продвижение про проекту итеративное. Здесь же я предлагаю использовать подход с четким пониманием что мы делаем и зачем. Это позволит не зарыться в исследованиях и ответить на вопросы "куда мы потратили несколько человекомесяцев, не продвинувшись по доставке продукта".
Мне кажется, что начать можно с заполнения квадрата Декарта для каждой исследовательской задачи:

Четко и подробно фиксируйте критерии успешности, провала каждой исследовательской задачи и последствия из них до начала работы над задачей. Только так вы сможете через некоторое время проследить, где вы находитесь, почему оказались в этой точке.
ML-проекты — это не проекты по разработке ПО, нужна другая методология, другой подход работы с целями, иные способы принятия решений, создание четкого трека целей, решений, задач, последствий.
Обеспечьте как можно больший объем данных как можно раньше
Чем раньше вы обеспечите команду ML данными, которые возможны в реальном мире, сформулируете ожидания относительно обработки этих данных, тем ниже шанс, что команда сделает что-то, что работает только при температуре 23 градуса цельсия, только с 14 до 16 часов, при ретроградном Юпитере.
Данные и их разметка должны генерироваться той частью компании, которая формулирует свои ожидания. Данные для обучения и тестирования работы моделей AI — это тоже элемент требований, а не тестовая среда, которая возникает когда что-то готово.
