
В повседневной продуктовой разработке, запертой в корпоративных технологических ограничениях, редко выпадает случай шагнуть за грань добра и зла в самое пекло хипстерских технологий. Но, когда ты сам несешь все риски и каждый день разработки вынимает деньги из твоего собственного кармана очень хочется срезать путь. В один из таких моментов я решил шагнуть в такой темный серверлес, о котором раньше думать было как-то стыдно. Под впечатлением от того, что получилось, я даже хотел написать статью «Конец гегемонии программистов», но спустя полгода эксплуатации и развития проекта понял, что ну не совсем еще конец и остались еще места в этом самом serverless-бэкенде, где надо использовать знания и опыт.
Архитектура
Первое что сделал, вычеркнул из списка ограничений страх вендорлока. Надо еще дожить до масштаба, чтобы это стало проблемой.
Второе решение было — не хочу ничего менеджить собственными силами, цена devopsов сейчас слишком высока, одной зарплатой можно оплатить год managed-решений в облаках.
Третье, пожалуй самое безрассудное и на грани «слабоумия и отваги», рискнуть пойти на новорожденное решение от MongoDB, которое в тот момент называлось Stitch, а сейчас называется Realm (но это не совсем тот самый Realm, а ядреная смесь из Stitch и Realm, которая получилась после приобретения последнего MongoDB, Inc в конце 2019 года)
Backend
В результате серверная сторона вышла вот такой:

Node и Redis в ней появились только для реализации Server Side Rendering и кэширования (ну и для того, чтобы не кормить Atlas лишними платными запросами), для тех кто не решает задачи SEO-оптимизации их можно легко выкинуть.
В результате бэк масштабируется в пару кликов до практически любого размера. И самое главное стоит копейки, за счет того, что платный computed-runtime по большей части потребляется один раз на измененные данные и сохраняется в кеше.
Frontend
Клиентская часть классическая: React + Redux + Redux-Saga + TypeScript

Здесь не стал экспериментировать, потому что клиент планировался сложный и довольно толстый, чтобы его можно было развивать и поддерживать нужно было что-то более-менее вменяемое. Ну и еще один ключевой момент, эти технологии знают почти все, поэтому легче найти разработчиков.
Аутентификация и авторизация
Ну а теперь самое интересно, для чего вообще нужно было все это мракобесие с Mongo.Realm. Вместе с лямбдами мы получаем полноценную интеграцию из коробки с ворохом способов аутентификации (Google, Apple, Facebook, Email/Password и прочими) и механизмом авторизации операций до уровня полей в коллекциях:
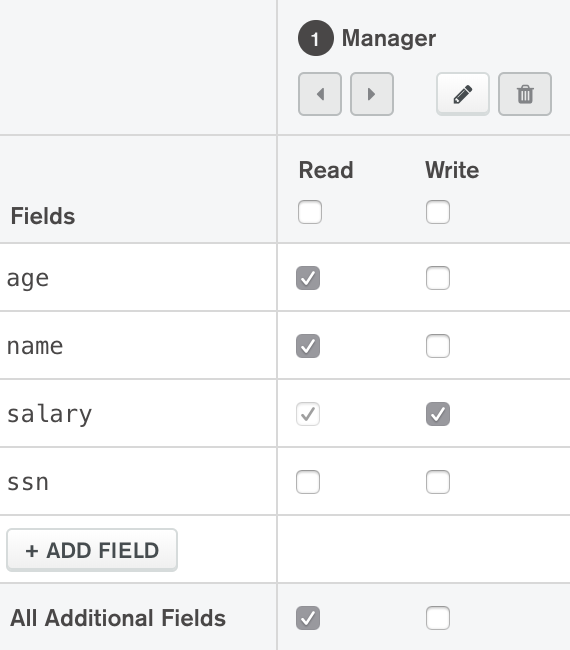
Кроме этого решение о доступе можно принимать по результатам выполнения функции и таким образом вполне реализуем полноценный механизм цепочки голосующих (пользователь, роль, группа, замещения, суперпользователь и т.д.).
Прочие радости
Также облачная монга нам из коробки дает sync наборов данных с клиентом, push-уведомления, хранилище секретов, триггеры (на события базы, аутентификация, работу по расписанию), вебхуки, хорошие логи и еще много чего. То есть снаружи оно обслуживается и воспринимается как полноценный сервис, при этом не приходится решать вопросы масштабирования и переноса между датацентрами, бекапов, мониторинга и кучи других задач.
Ну, а для самых безбашенных, есть возможность работы через GraphQL.
Как все это работает
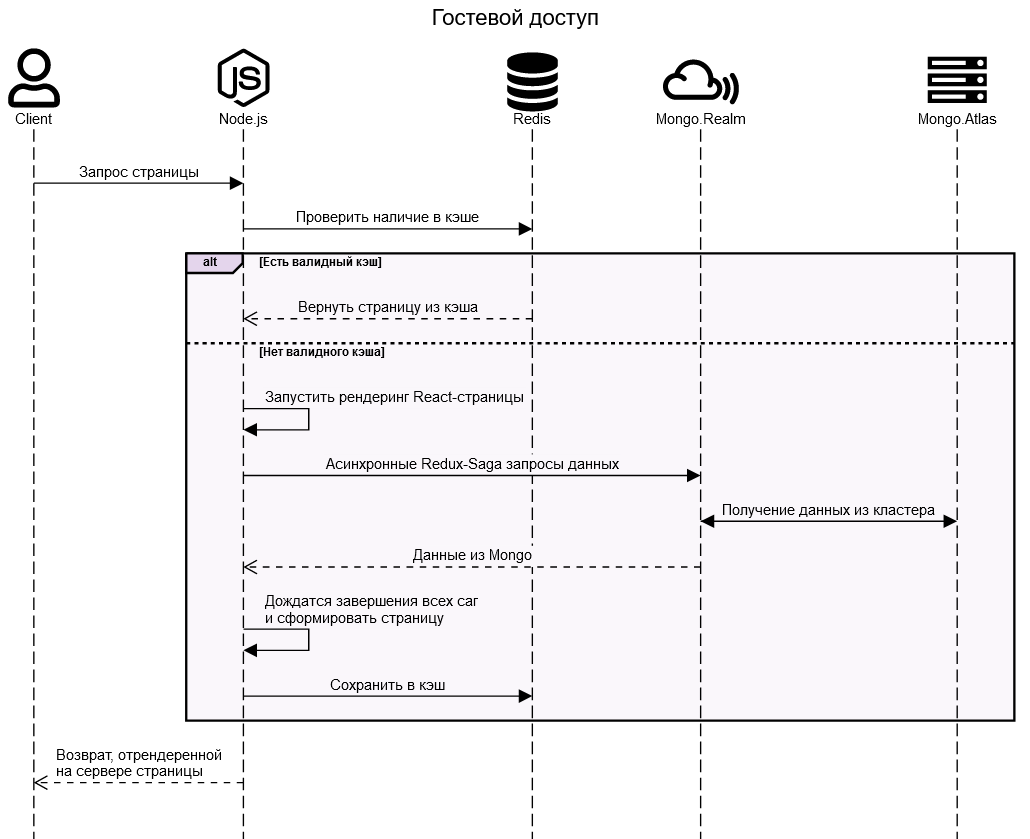
В случае если попали в кэш, при 100 RPS на один экземпляр (в конфигурации по одному ядру и одному гигабайту на один экземпляр Node.js под управлением PM2), время ответа укладывается в 200 мс, в противном случае вместе со всеми запросами к Mongo серверный рендер отрабатывает до 500 мс.
В работе с Mongo.Realm есть нюансы, которые никак не отражены в документации, но проявляются во всех недорогих инстансах с разделяемой памятью (M1, M2, M5): если запросы выполняются от имени клиента, то, видимо в качестве защиты от перегрузок, периодически время ответа на какой-нибудь aggregation-pipeline может резко вырасти до 5-10 секунд на запрос. При этом, если вызывается серверная функция (с тем же самым aggregation-pipeline), которая выполняется от имени системного пользователя, то таких трюков не наблюдается.
Возможно дело именно в типе кластера, и со временем это исправят или все решится переходом на М10 и выше, но сейчас для некоторых сложных запросов пришлось пойти на рискованный шаг и для чтения данных анонимными пользователями сделать несколько функций исполняемых от имени системного пользователя, в этом случае правила авторизации для доступа к данным игнорируются, и за безопасностью надо следить уже самим в коде.
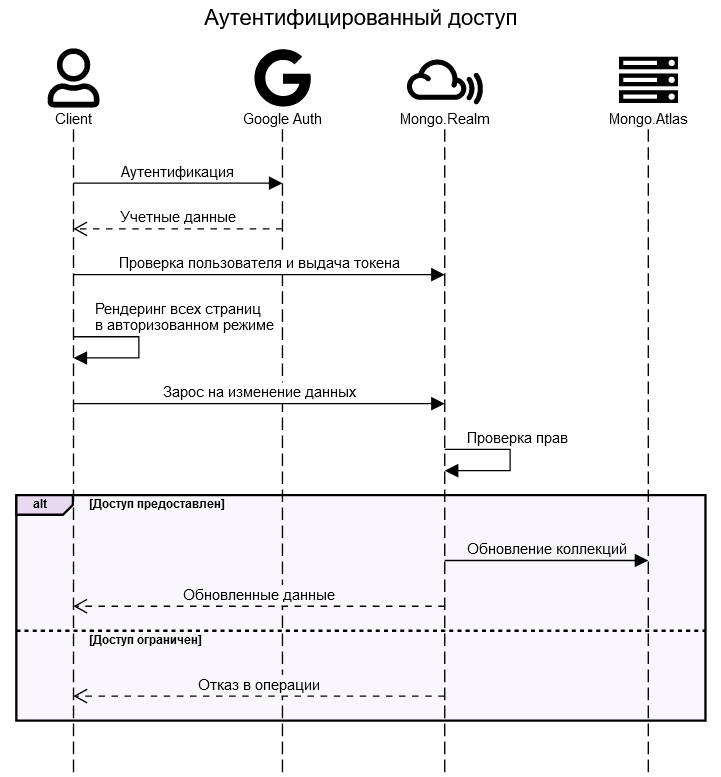
В случае аутентифицированного доступа Server Side Rendering не нужен, все работает прямо на клиенте.
Выводы
В заголовок вынесен ресурс потраченный на разработку, а именно полтора программиста (1 фронтендер и ½ бэкендера). Ровно столько и 5 месяцев работы, понадобилось для вывода в прод довольно развесистого портала с собственной системой управления контентом, интеграцией с несколькими поставщиками данных включая нечеткие сопоставления, оптимизированного под самые суровые требования по SEO и c поддержкой мобильный браузеров как first class citizen.
Весь мой предыдущий, более чем 16-летний опыт управления разработкой говорил, что ресурсоемкость этого проекта будет раза в 4 выше.
Дальнейшая эксплуатация и развитие безусловно покажут насколько опрометчивы были эти решения, но на текущий момент сэкономлено примерно 1,5 миллиона и все работает как надо.
