В современном мире основным источником информации о бытовом товаре для покупателя является интернет, посредством которого можно легко и быстро найти, сравнить, выбрать и даже купить модель товара того или иного типа. Однако мало кто из покупателей задумывается о том, что стоит за формированием контента, на основе которого он этот выбор делает.
Тем не менее, и владелец магазина, и его маркетинговый отдел прекрасно понимают необходимость предоставлять для товаров качественное, исчерпывающее и в то же время достаточно легко воспринимаемое клиентом описание.
Контент о товаре условно можно подразделить на несколько видов:
- Общая информация (фото, видео, редакторский текст).
- SEO (обвес для продвижения, поиска, сниппеты, микроразметка).
- Техническое описание (характеристики).
- Файлы документации.
- Связанные товары (сопутствующие, зависимые, обязательные, альтернативные и т.п.).
Информационная модель
В данной статье мы рассмотрим контент третьего типа — техническое описание (на самом деле, на основе этого контента можно получать почти все остальное).
Такой контент, как правило, представляет собой таблицу, состоящую из пар “Атрибут: Значение”. При этом под атрибутом следует понимать некоторое обособленное свойство группы близких по назначению товаров, отражающее их функциональные, физические и/или потребительские качества. Значение атрибута — это реализация такого свойства в данном конкретном товаре (говоря алгебраическим языком, значение есть действие атрибута на товар).
Атрибуты могут быть числовыми, категориальными и текстовыми.
Числовой атрибут представляет собой линейную шкалу, с помощью которой товары можно сравнивать между собой как обычные действительные числа. Как правило, это физическая величина (вес, объем, частота, мощность и т.п.) с единицей измерения (масштабом), либо количественный атрибут (без масштаба). Числовой атрибут в каждом товаре реализуется в виде конкретного числового значения с конкретной единицей измерения. Иногда два числовых атрибута объединяют в один для реализации интервального значения (от и до).
Категориальный атрибут представляет собой конечный список токенов (слов, словосочетаний, наименований, обозначений и т.п.) и в каждом конкретном товаре реализуется некоторым (возможно, пустым) подмножеством данного списка.
Наконец, текстовый атрибут в качестве значений может принимать любой текст из заданного алфавита, т.е. является аналогом категориального атрибута, но с бесконечным множеством возможных значений (звезда Клини в данном алфавите).
При желании все три типа атрибутов можно свести к последнему — текстовому. Для клиента, читающего описание товара, между ними нет никакой разницы. Однако стоит заметить, что чем более структурирован атрибут и чем лучше он оцифрован (пусть даже это будет конечный список векторов или матриц, а не просто число), тем легче его использовать в алгоритмах сравнения товаров и при вычислении их “функции полезности”, а также в фильтрах и тегах. Поэтому техническое описание тем качественнее, чем больше в нем числовых атрибутов и чем меньше (в идеале — совсем нет) текстовых.
Для каждого конкретного товара каждый атрибут в отдельности мало что значит, однако определенный набор атрибутов, реализованный в товаре, уже представляет собой некоторый “генетический код” данного товара, и поэтому от правильности выбора атрибутов зависит то, как данный товар будет соотноситься с другими, родственными товарами, насколько релевантен он будет в поиске, каким способом его можно будет отыскать в множестве подобных товаров.
Отсюда возникает дилемма: какой набор атрибутов, с одной стороны, достаточен для исчерпывающего (делающего его уникальным) описания одного товара, а с другой стороны, сколько вообще нужно атрибутов для того, чтобы адекватно описывать, сопоставлять и сравнивать товары в интернет-магазине или маркет-плейсе.
Как обычно, истина где-то посередине. Все товары необходимо разделить на группы таким образом, чтобы внутри каждой группы было как можно меньше малоиспользуемых атрибутов (крайний вариант: на каждый товар свой набор атрибутов) и в то же время количество этих групп должно быть как можно меньше, а их объем не должен сильно варьироваться от группы к группе (крайний вариант: единый набор атрибутов для всех товаров, т.е. одна группа товаров).
Обычно (и, как правило, эта логика оправдывается) принято подразделять товары на группы в соответствии с их функциями и потребительскими свойствами. Не стоит, например, искать одинаковые наборы атрибутов у микроволновой печи и бензиновой газонокосилки. В то же время, чайники и термопоты вполне могут быть объединены в одну группу товаров с одинаковым набором атрибутов.
Пара (Группа товаров: Набор атрибутов) называется информационной моделью (инфомоделью, моделью).
Таким образом, информационная модель представляет собой многомерное пространство (гиперкуб), измерениями в котором выступают атрибуты, а точками — конкретные физические товары, а точнее, их представление в данной модели. Инфомодель эволюционирует во времени, т.к. пополняются списки значений категориальных атрибутов, добавляются новые атрибуты и единицы измерения.
Вариативность инфомоделей
Вспомним теперь о том, что товары, очень близкие по свойствам (одного назначения), производятся различными компаниями, количество которых может достигать нескольких сотен. У каждого производителя имеется свое собственное описание продукции, а значит, свое разбиение товаров на группы и своя информационная модель для каждой группы. Получается, что хотя производители и говорят практически об одном и том же, они пользуются разными формальными языками.
Это значит, что даже для одной группы товаров существует множество информационных моделей, а универсальной общепринятой модели не существует вовсе.
При создании собственного информационного каталога для интернет-магазина мы вынуждены так или иначе импортировать технические описания товаров извне. Это можно делать вручную силами собственной контент-команды, можно импортировать через API провайдеров контента и поставщиков, можно настраивать иные способы импорта контента из доверенных источников, а также комбинировать одни методы импорта с другими. Так или иначе, возникает задача определения операторов, отображающих внешние информационные модели во внутреннюю.
Кроме того, внутренняя модель также подвергается дальнейшей трансформации для предоставления данных на сайт интернет-магазина, в различные фиды для продвижения товаров на интернет-площадках. А если мы говорим о внутренней модели провайдера контента, то эта модель отображается в многочисленные информационные модели клиентов, приобретающих данный контент.
Таким образом, в общем случае мы имеем задачу двойного преобразования технического контента:
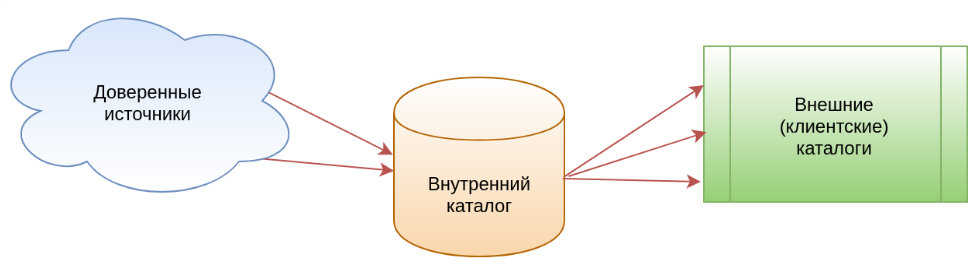
И на каждой из трех звеньев этой цепи мы имеем дело с различными информационными моделями и различным разбиением множества товаров на группы, так что при каждом преобразовании моделей мы вынуждены производить перевод с одного модельного языка на другой.
К сожалению, информационные модели — это не линейные пространства, а преобразование, переводящее одну инфомодель в другую, — не линейный оператор. Поэтому для создания транзитных преобразований (минующих внутренний каталог) отделаться перемножением матриц линейных операторов не удастся. И это не единственная проблема.
Трудности перевода
Перечислим некоторые из трудностей преобразования инфомоделей:
- Разбиение товаров на группы у доверенных источников может отличаться.
- Набор атрибутов в инфомоделях у всех доверенных источников разный (начиная от названий атрибутов и списочных значений и заканчивая используемыми физическими величинами).
- Язык (человеческий) моделей также может быть разным.
- Единицы измерения в числовом атрибуте могут указываться не в системе СИ и/или входить в название атрибута или в его значение.
- Товары могут быть описаны недостаточно полно.
- Значения могут быть ошибочными (даже у доверенных источников).
- Клиентские фиды и каталоги сильно отличаются своими требованиями.
Из перечисленных проблем возникают вопросы-задачи, знакомые всем, кто занимается обработкой (больших) данных.
- Как организовать свою внутреннюю информационную модель, чтобы максимально точно вместить описания доверенных источников и максимально полно и адекватно сформировать данные для клиентских каталогов?
- Как очистить входные данные от “шума”?
- Как формализовать операторы преобразования информационных моделей на этапах импорта и экспорта?
Атомизированная модель
Если проблема различия разговорных языков решается относительно просто (нужно договориться о том, что и во внутренней модели, и во внешних доверенных источниках будет использоваться только английский язык и метрическая система мер), то различие в группах и наборах атрибутов требует построения такой принимающей модели, в которую бы все внешние атрибуты попали максимально разделенными, декомпозированными. Иначе говоря, операторы, преобразующие внешние инфомодели во внутреннюю модель (операторы импорта) не должны склеивать отдельные атрибуты в один, но вполне могут разделять один сложный атрибут на несколько более простых (т.е. увеличивать размерность инфомодели).
С другой стороны, чтобы максимально упростить синтез новых информационных моделей для клиентской стороны (экспорт), внутренняя модель также должна быть максимально структурирована и разбита на элементарные атрибуты так, чтобы операторы экспорта смогли бы сложить из них максимальное разнообразие внешних моделей (с понижением размерности инфомодели).
Такая атомизированная модель обладает рядом преимуществ по чисто комбинаторным причинам. Действительно, имея в арсенале всего три характеристики A, B, C, мы можем составить из них как минимум 5 (число Белла при n=3) непустых моделей ({A,B,C}, {A+B,C}, {A+C,B}, {A,B+C}, {A+B+C}). Эти комбинированные модели могут соответствовать разным внешним моделям, но при этом ложатся в одну внутреннюю модель.
Второе преимущество состоит в том, что такую модель легче модерировать. Если характеристика A задана всего один раз, то ее переименование, пополнение набора значений или единиц измерения, исправление ошибок производится также всего лишь один раз во внутренней системе. Если же мы внутреннюю модель сделаем такой, что в ней будут представлены все возможные комбинации из внешних моделей, то дальнейшее управление усложняется экспоненциально относительно атомизированной модели.
Очистка данных
Помимо проблемы сопоставления атрибутов разных внешних инфомоделей с внутренней моделью существует и проблема “шума” в исходных данных. Во-первых, данные могут быть неполны. Для импорта это не проблема, но это значит, что доверенный источник должен быть дополнен еще каким-то источником. Полнота данных о товаре означает, что в рамках одной информационной модели не существует двух товаров с одинаковым набором значений атрибутов. Полнота, очевидно, зависит от источника данных. Если в одном доверенном источнике относительно мало товаров, то их модель описания может быть бедной, т.к. малого набора атрибутов достаточно для их различия внутри данной модели. При объединении данных из многих доверенных источников полнота может быть утеряна, а значит, во внутренней модели описание товаров должно быть максимально подробным.
Таким образом, имеется необходимость получать данные для одного и того же товара хотя бы из двух-трех источников.
Это же требование делает возможным процесс верификации данных. Дело в том, что все ошибаются, в том числе и сайты производителей. Чтобы выявить ошибки, нужно уметь производить сопоставление импортируемых данных между собой и с описаниями товаров из данной группы. А для корректного сопоставления нам снова требуется единая атомизированная модель. Только в том случае, когда мы можем сопоставить данные из различных источников в рамках одной инфомодели, мы можем также выявить некоторые ошибки и тем самым очистить данные (например, не пропускать в систему противоречащие друг другу значения или пропускать только наиболее вероятные альтернативы).
Почему инфомодель не может быть всеобъемлющей?
Ранее мы уже отмечали, что при создании инфомодели необходимо соблюдать некоторый баланс между полнотой модели и глубиной разделения товаров на группы. Обсудим этот момент подробнее.
Очевидно, что делать одну модель для одного или 10 товаров неразумно хотя бы ввиду сопоставления затрат на создание модели и эффекта от ее использования. Из всего вышесказанного должно быть уже очевидно, что создание инфомодели — дело хлопотное и затратное как по времени, так и по интеллектуальным ресурсам. Если при наличии 1000 товаров в каталоге создавать группы по 10 товаров, то нам потребуется 100 моделей, каждую из которых нужно создать и поддерживать.
Здесь, конечно, есть свои приемы экономии. Например, многие атрибуты (вроде частоты или веса) встречаются во многих моделях. Поэтому их создание и настройку проще вынести в отдельный каталог атрибутов, а модель собирать из них как “лего”.
Но ведь помимо создания модели потребуется еще произвести построение операторов импорта/экспорта, забирающих и отдающих контент во внешние модели. А в этих внешних моделях, как правило, категоризация (разбиение на группы) происходит по своим принципам. Потребуется создать несколько сотен операторов ради одной-двух внешних моделей. Это опять-таки накладно и весьма избыточно.
Наконец, если мы хотим использовать такие вещи, как машинное обучение для выявления ошибок, отклонений и для автоматизации импорта/экспорта данных, нам потребуется достаточно большая группа однородных описаний товаров, обладающих единой инфомоделью. Иначе машинное обучение будет некорректным.
ОК, почему же тогда не создать модель, которая включит все товары каталога? Одна модель требует одного акта творения и, казалось бы, сильно экономит на поддержке.
Однако и у этой крайности есть свои недостатки. Во-первых, эта модель получится крайне разреженной. Вспомним, что товар в инфомодели — это вектор значений атрибутов. Если модель очень широкая, то может оказаться, что каждый товар использует 1-2% атрибутов, хотя все вместе товары используют 100% атрибутов.
У нас получается очень разреженная модель данных, а такие модели как правило очень требовательны к вычислительным ресурсам, поскольку сильно разреженные векторы требуют постоянной упаковки и распаковки для экономии памяти, а значит, производить массовые операции над каталогом становится трудоемкой задачей.
С точки зрения Data Science к такому информационному пространству следует применить алгоритмы понижения размерности, выкинув все незначащие атрибуты и распилив это единое пространство на несколько независимых подпространств, размерность которых будет в разы ниже исходной. Но это и есть не что иное, как переход к группам товаров со схожей информационной моделью (категоризация).
Во-вторых, глобальную информационную модель также необходимо обслуживать — пополнять атрибутами, расширять списки значений, модифицировать операторы импорта/экспорта при таких изменениях. Здесь мы снова упираемся в проблему, когда необходимость внести небольшие изменения затрагивает весь каталог. А кроме того, повышаются риски возникновения дублирующих или перекрывающих атрибутов, поскольку отследить корректность модели становится непосильной для человека задачей.
В-третьих, если внутренняя модель используется для заполнения описаний “руками”, то контент-менеджер будет вынужден подолгу обозревать инфомодель в поисках нужного ему атрибута для простановки значения. А это огромная потеря времени и ресурсов компании.
Против глобальной инфомодели можно привести еще ряд аргументов, связанных с процессами управления каталогом, разделением прав доступа, отслеживанием модификаций модели, автоматизацией проверки качества вносимых значений и т.д.
Таким образом, чаще всего информационные модели строятся на группах очень схожих товаров, соблюдая паритет между всеобъемлемостью и тривиальностью модели. Когда мы имеем дело с товарной группой, где отличие по заполненности модели у товаров составляет 5-10%, мы не только упрощаем себе жизнь в плане управления моделью и привязки к ней операторов импорта/экспорта, но получаем еще ряд бонусов.
Избыточная атомизация модели
В попытках построить максимально элементарную инфомодель можно дойти до такого типа модели, который называется “Да/Нет”-моделью. В такой модели существует ровно два вида атрибутов — числовые (с единицами измерения) и категориальные с одинаковым списком значений {‘Да’,’Нет’}. Очевидно, что любой категориальный атрибут сводится к совокупности “Да/Нет”-атрибутов. Для этого достаточно взять список значений данного категориального атрибута и превратить его в одноименный список атрибутов. Тогда, если в товаре данное значение исходного атрибута присутствует, одноименный “Да/Нет”-атрибут принимает значение ‘Да’, а в противном случае — ‘Нет’.
Такая сверхатомизированная модель имеет право на существование и даже нередко применяется на практике. Однако легко понять, что и она очень сложна для целей сопоставления внешних моделей с внутренними. Достаточно заметить, что добавление нового значения категориального атрибута практически никак не затрагивает формулы операторов импорта/экспорта, в то время как соответствующее добавление “Да/Нет”-атрибута может потребовать правок во многих сопровождающих алгоритмах преобразования инфомоделей.
Кроме того, такая модель будет сильно разреженной и окажется в сотни раз больше исходной модели со списочными атрибутами, в результате чего мы получаем все те проблемы, которые описывали для случая всеобъемлющей модели.
Оправдать пользу “Да/Нет”-модели можно разве что в каталогах с очень простым, слабо меняющимся описанием (вроде каталогов выборных листовок “Да-Да-Нет-Да”), либо если эта модель спрятана “под капотом” системы искусственного интеллекта, который самостоятельно формирует группы товаров и инфомодели для них, самостоятельно создает операторы импорта/экспорта, самостоятельно верифицирует и пополняет данные на основе внешних раздражителей (фидбэков от внешних систем и контролирующих алгоритмов).
Еще одно применение “Да/Нет”-модели — это сопоставление с каким-то внешним каталогом, модель которого имеет такой же тип. В этом случае импорт контента немного усложнится: сначала оператор импорта выполнит заливку во внутреннюю “Да/Нет”-модель, затем другой оператор произведет сопоставление данных с нативной внутренней моделью, содержащей списочные категориальные атрибуты.
Бонусы атомизированной модели
Для начала заметим, что если инфомодель соответствует такой группе товаров, у которых заполнены примерно одни и те же атрибуты, то такие товары легко сравнивать между собой. А это очень важный аспект выбора товара покупателем.
Далее, если модель максимально декомпозирована, то и сравнение товаров в ней, и любая аналитика по имеющемуся контенту (статистический обсчет товарной группы) будут максимально детальными. Пользуясь атомизированной моделью, вы можете как под микроскопом выявить отличия в описаниях товаров, локализовать ошибочные значения, исключить неоднозначное толкование атрибутов, производить поиск зависимых атрибутов и вычислять отсутствующие знания о товаре.
Выше уже отмечалось, что атомизированная модель позволяет порождать большое количество комбинаций атрибутов, что упрощает создание операторов экспорта во внешние модели. Чем мельче элементарный квант модели, тем точнее мы можем выстроить правила экспорта данных для их соответствия требованиям заказчика или маркетплейса.
Ряд бонусов атомизированной модели проявляется тогда, когда мы говорим о системе управления контентом и ее интерфейсах.
Прежде всего, мы можем накладывать ограничения на допустимые значения атрибутов при вводе их как человеком-оператором, так и оператором импорта. Например, для числового атрибута можно задать ограничивающий диапазон либо превентивно, исходя из его физического смысла, либо на основе статанализа значений для ранее описанных товаров.
Можно также запретить вводить дробные значения для атрибутов количества или ограничить число знаков после запятой для значений частоты процессора.
В случае категориальных атрибутов часто используется ограничение на количество одновременно вводимых значений. Так, атрибуты подтипа “селект” позволяют выбрать только одно значение.
Наконец, можно выполнять перекрестную проверку значений и/или восполнение знаний о товаре. А именно, из физических соображений можно связать атрибуты формулами так, что если часть введенных значений позволяет однозначно вычислить остальные, то мы можем либо автоматически заполнить недостающие атрибуты, либо проверить правильность их заполнения.
Категориальные атрибуты с фиксированными списками значений и заданными у этих значений синонимами, а также с иерархией значений позволяют контролировать возникновение дублирующих атрибутов и значений. Отсутствие дублирующих фрагментов инфомодели означает более качественное ее использование при импорте/экспорте данных и более качественный поиск и сравнение товаров.
Еще одним важным бонусом атомизированной модели является то, что с помощью операторов экспорта из нее можно генерировать не только таблицу технических характеристик, которая больше ориентирована на читабельность, но и отдельный список фильтров для сайта, который будет включать более структурированные атрибуты, а также отдельный список атрибутов для таблицы сравнения товаров. Кроме того, можно строить экспорт SEO-текстов и метатегов, автоматическую генерацию наименований товаров и кратких описаний.
Ранее мы отмечали, что при создании модели и выборе источников лучше использовать один язык — английский. Однако внешние клиентские каталоги могут требовать контент на различных языках. Наличие атомизированной модели позволяет создавать словари токенов для перевода атрибутов, значений и единиц измерения на другие языки. Здесь важно, чтобы как названия атрибутов, так и их значения были максимально цельными с лингвистической точки зрения, что позволит нивелировать неоднозначность перевода.
В завершение заметим, что, имея качественное и хорошо структурированное техническое описание товара, мы можем применять алгоритмы машинного поиска других видов контента — изображений, документации, видеороликов, маркетинговых текстов и т.п.
Подводя итоги, зафиксируем тезисно основные выводы:
- Информационная модель у каждого своя, поэтому для адекватного взаимодействия инфомоделей нужно создавать внутреннюю принимающую модель.
- Внутренняя модель должна быть атомизированной, аналитической.
- Больше числовых атрибутов, меньше текстовых!
- Модель должна соответствовать группе однотипных товаров так, чтобы отличие между товарами группы по количеству используемых атрибутов было не более 5-10%.
- Группы товаров не должны быть мелкими.
- Язык (человеческий) внутренней модели и подключаемых доверенных источников должен быть английским, а система мер — СИ.
- Модель “Да/Нет” использовать с осторожностью, а лучше вообще не использовать.
