Comments 427
Итак, главный вопрос заключается в том, какую книгу(ы) я бы рекомендовал вместо этого? Я не знаю. Предлагайте в комментариях, если только я их не закрыл.
Как для 2008 года, я бы предложил «Совершенный код» (Code Complete) Макконнелла для начинающих разработчиков — гораздо менее категоричная книга, однако в 2020 году не все главы уже актуальны.
+1 за Макконела. Разносторонне, глубоко и без лишнего эпатажа в стиле «я писал код еще на древних египетских скрижалях»
Но, если вспомнить, что эта книга была, пожалуй, одной из первых, дававших базовые знания о грамотной промышленной разработке, много сейчас ей можно простить.
По сути, многие вещи, которые в ней были собраны вместе, сейчас являются стандартом и must have для всех профессиональных разработчиков — поэтому ее по-прежнему стоит рекомендовать.
Я согласен, что плохо для функции вносить неожиданные изменения в переменные своего собственного класса.
Методы в ООП взаимодействуют с состоянием объекта. Когда методы перестают это делать, а состояние начинает проталкиваться через аргументы, то код превращается в обычное процедурное программирование. Разве не так?
С более современными подходами, можно и состояние передавать через аргумент. Поля в таком случае скорее нужны для связей с другими объектами. И это по прежнему может быть ООП.
И это по прежнему может быть ООП.— но уже не Чистый Код.
Такие параметры лучше передавать аргументами метода
Вообще, идея интересная. Но ИМХО не для джавы и прочих ЯП, которые выбирают с учетом скорости разработки. Это что-то вроде const-correctness в c++, где вы можете помечать метод как const, гарантируя, что этот метод не может изменять поля своего объекта. Вот тут как раз люди с подобным осознанно заморачиваются (и все бы так делали). Только вот в плюсах это контракт типа «всё или ничего» — отдельные поля для указания выбрать нельзя. Ну есть еще mutable-поля, что по сути дает возможность их менять даже в конст-методах, но опять же, во всех. Если передавать все нужно аргументами метода — тут вылезут другие недостатки, вроде лишнего копирования тонны аргументов на каждый вызов и прочее, что тоже, согласитесь, не лучший вариант. Проскользнула мысль — разрешать для изменения указанные поля через синтаксис типа аттрибутов в C#, но многословность тоже никуда не исчезнет… Вообще, лично я бы смирился с тем, что в классе его поля — это как единая контролируемая неделимая сущность, и разрешить их изменять без договоренности «по одному» — нет большой выгоды. Но вот насчет статических полей и всяких глобальных переменных (если таковые имеют место быть в том или ином ЯП) — для их изменения как раз не помешало бы вводить те самые разрешения «по одному», ибо сайд-эффекты как раз имхо чаще завязаны на них (всякие errno и прочие). Плюс такого подхода — количество «разрешений» будет гораздо меньше, чем в первом варианте, а так же будет возникать ситуация, когда функции, изменяющие глобальные переменные, помимо своих собственных «разрешений» тащат за собой все разрешения всех вызываемых функций с сайд-эффектами. То есть, мы наглядно будем видеть, что там подкапотно ворочают в недрах вызовов. И да, этот список будет разрастаться, что будет являться показателем «я явно трогаю слишком много всего, надо что-то рефакторить», приводящее к будущим советам от новых гуру типа «не более пары разрешений на функцию» или «список разрешений должен помещаться в один экран» :)
Как-то так.
Например:
auto image = getImage();
image.mirror(); // плохой метод, меняет состояние объекта
auto mirrorImage = image.mirrored(); // хороший метод, состояние не модифицируется, но есть копирование
Тем более, что в современных С++ копирования можно избежать, если добавить перегрузку от rvalue-ref (метод Image mirrored() &&), например:
auto mirrorImage = getImage().mirrored(); // отлично, копирования нет, внешних побочных эффектов нет
В других языках может быть не всегда возможно избежать копии, но выбирая между производительностью и безопасностью\удобством чтения, лучше выбирать второе — оптимизировать ботллнек всегда можно потом. Например, иммутабельные строки выглядят как хороший пример такого выбора.
ну смотрите, у вас есть копирование. Причем картинки, тяжеловесного объекта. Вы всерьез считаете, что это всегда хорошо?
Во многих ситуациях — это плохо. Да, сложно работать с мутабельными объектами. Но жрать память, тратить беспечно ресурсы системы — не в каждом случае можно. В игровых движках за такую иммутабельность вам руки оторвут.
В программировании контроллеров — тоже.
Я к тому, что абстрактный спор — он оторван. Смотреть надо на целесообразность в конкретной реализации. Но лишнее копирование картинок — это даже на фронтенде не всегда хорошо.
ну смотрите, у вас есть копирование. Причем картинки, тяжеловесного объекта. Вы всерьез считаете, что это всегда хорошо?
Нет, не считаю, я считаю что не надо заниматься premature optimization и кидаться сразу делать АПИ мутабельным просто потому что «это быстрее».
Всегда можно воспользоваться вторым вариантом с перегрузкой по rvalue. Можно даже пойти дальше и оставить только эту перегрузку и не перегружать метод от lvalue, тогда уже компилятор будет бить по рукам, а не профайлер. На эту тему был доклад на cpp russia в прошлом году. Возможно, если бы писал класс Image, я бы так и сделал=)
Или, раз уж мы затронули тему игровых движков, то можно вспомнить статью Кармака 8 летней давности где он рассуждает о том что pure functions это хорошо, а сайд эффекты — плохо.
Это ложная дихотомия — либо мутабельность, либо скорость — можно взять и то и то, было бы желание.
Возможно, пример с картинкой не самый удачный, просто первое, что пришло в голову.
Вероятно, какой-нибудь class Matrix и transpose() vs. transposed() было бы лучшим примером.
ну смотрите, у вас есть копирование. Причем картинки, тяжеловесного объекта. Вы всерьез считаете, что это всегда хорошо?
Так ведь никто и не заставляет сразу же делать копирование. Для широкого класса операций (в том числе на картинках) можно результатом mirrored() вернуть нечnо, что ведёт себя как отзеркаленная картинка, но на деле просто осуществляет трансляцию координат из оригинального изображения при доступе. А например image.mirrored().mirrored() вообще вернёт image. Да даже с рисованием поверх этой картинки можно такие фокусы проворачивать, если операция рисования на самом деле создаёт только слой поверх оригинального изображения, а основной массив пикселей остаётся лежать как был.
Более того — в первой редакции этого кода можно и пожрать память, получить уже какой-то рабочий код, который умеет что-то делать с картинками, а потом начинать без изменения API его оптимизировать введением лени, отображений, трансляторов, определять когда нужно спекать эти отображения вместе, а когда не стоит, и прочую "магию".
Причем мы в таком случае бесплатно полчаем всякие undo/redo и прочие механизмы, потому что не ломаем данные которые у нас были.
Ломка данных опциональна, на самом деле. Например для того же рисования есть порог, при котором несколько "слоёв" имеет смысл объединить, чтобы не гонять доступ к пикселям через совсем уж толстые слои обёрток — потому что каждый слой будет требовать вычислительных расходов на каждую операцию доступа.
Для этого можно написать "фасад", который объединяет логику того что внутри него, но позволяет если что разобрать его обратно. Обычная персистентность же. Если то что внутри неизменяемо то в конструкторе считаем агрегацию для скажем десяти слоёв, и дальше работаем с ним как с цельным. А если нас просят сделать undo то мы можем взять наши сохраненные в конструкторе слои, выкинуть один последний и остальное вернуть как результат undo
auto image = getImage();
image.mirrorTo(image);
auto image = getImage();
auto mirrorImage = newImage()
image.mirrorTo(mirrorImage);
Неявная работа функции + лишнее действие. Не очень удобно.
Такой подход хорош только для супер-низкоуровневых АПИ где мы таким образом контролируем выделение памяти.
Но в сколько-нибудь высокоуровневом коде (а отражение картинок — это пример такого кода) параметры функции являются параметрами, а результат — это то что функция возвращает. Делать void-функцию которая мутирует параметры — ну блин, это вообще не очень.
auto image = getImage();
auto mirrored = std::move(image).mirrored();
std::cout << image.size() << std::endl; // warning, bugprone-use-after-move
image = getAnotherImage(); // OK
Такой подход лучше тем что существует тулинг, который позволяет отслеживать неправильное использование «мувнутых» объектов, а для общего случая (например mirror/nonmirror) такого тулинга нет — только программист знает, что ему нужно.
Если вам нужна копия, то придется явно это написать, и ревьюверу будет видно что тут тяжелая копия:
auto image = getImage();
auto mirrored = Image(image).mirrored();
Или можно воспользоваться Copy-On-Write (если объект полностью иммутабельный, то вам даже deep copy не нужно делать on write, что упрощает код и устраняет большинство проблем COW) и применить ваше решение с флажком «orientation» — тогда и копирование дешевое и иммутабельность сохраняется.
Если вам нужна копия, то придется явно это написать
Проблема в том, что вы же не думали об оптимизации заранее, сервис был маленький, ресурсов вагон и программист из комментария выше уже написал такой код:
auto image = getImage();
auto mirrorImage = image.mirrored(); // хороший метод, состояние не модифицируется, но есть копирование
setImage(mirrorImage);
В этом случае ему, на самом деле, копия была не нужна, исходную картинку можно было выбросить. В другом случае он же написал похожий код, вроде такого:
auto image = getImage();
auto flippedImage = image.flip(); // хороший метод, состояние не модифицируется, но есть копирование
setAnotherImage(flippedImage);
Только здесь ему уже надо было сохранить исходную картинку и получить перевернутую.
Эта история повторилась еще много-много раз. И когда вдруг поняли, что надо бы пооптимизировать лишние копирования, придется каждый такой кейс изучать заново и смотреть — где копирование было необходимым, а где можно и move. Считай, всю работу с картинками придется переписать.
Если программист из комментария не может решить где какой метод совать, есть куча других профессий.
Но тут скорее речь о том, что если есть выбор между тем, менять состояние объекта или не менять, то лучше избегать побочных эффектов, то есть не менять.Этот тезис вообще ниначем не основан, для относительного низкоуровнего кода вообще вреден. Прежде чем совать иммутабельность в плюсы, надо десять раз подумать а зачем оно вам надо.
В конечном итоге тут все зависит от реализации getImage(), в плюсах красивым образом написать ее вообще невозможно. Писать мувы в таких местах это вообще боль. Под него еще надо сам image правильно написать. Вы же понимаете что мув тоже копирует объект, просто правильным образом разруливает ссылки на тяжелые объекты внутри?
Если вы так гоняете этот image, куда проще в shared_ptr его обернуть, это еще и быстрее будет.
Два метода, один под явное копирование, а второй для мутации объекта будет лучшим выбором.
Этот код вообще бессмысленный
auto image = getImage();
auto mirrored = std::move(image).mirrored();
std::cout << image.size() << std::endl; // warning, bugprone-use-after-move
image = getAnotherImage(); // OKВы получили объект из функции. Если этот объект создается внутри функции и возвращается, мув бессмысленен. Если он гдето там внутри продолжает использоваться, то мув сломает внутрянку этого кода. В таком случае копию всеравно придется делать.
Так куда понятнее и проще, и не нужен тулинг отслеживать мувнутые объекты
auto image = getImage();
image.flip();
auto copyImage = Image(getImage());
copyImage.flip();Если вы пишете низкоуровневый код, отталкивайтесь от производительности, а не от советов из книжек про визуально красивый код на джаве
Этот код вообще бессмысленный
Этот код иллюстрирует пример когда у вас был объект, вы его мутировали, а потом через вереницу ифов использовали:
auto image = getImage();
image.flip();
if (someLongCondition1)
foo();
if (someLongCondition2)
bar();
// your code goes here
baz(image); // упс, вам тут нужен был исходный имадж, а не флипнутый
Да, пример тривиальный (на то он и пример). В случае мувнутого объекта вам тулы скажут что вы делаете что-то не то, а в этом случае вам надо полагаться на ревью/тесты.
Или вам никогда не приходилось часами отлаживать баги где десяток стейтов накладываются друг на друга?
Не думаю, что класс Image должен заботиться обо всех возможных трансформациях. Сегодня надо отражать по вертикали, завтра понадобится отражать по горизонтали, ресайзить, делать Ч/Б, делать негатив, менять гамму, накладывать маску, делать блюр, и ещё сотни эффектов — всё пихать в Image?
Лучше уж сделать composer, которому на входе скармливается иммутабельный Image (тот просто отдаёт владение своим битмапом, чтобы избежать лишнего копирования), потом у композера запрашиваются визуальные эффекты (которые стараются делать преобразования по месту, и могут быть вообще "ленивыми"), и на выходе создаётся результирующий иммутабельный Image (который опять же просто получает владение на получившийся битмап):
auto sourceImage = getImage();
auto composer = Composer{ };
auto resultImage = composer
.addImage(sourceImage.release())
.mirrorX() // в идеале, эффекты в композиции должны быть "ленивыми",
.mirrorX() // и эта пара mirrorX() должна аннигилировать при вызове compose()
.mirrorY()
.grayscale() // в идеале, должен выполниться первым для оптимизации последующих
.negateColors()
.mask(maskingImage)
.gaussianBlur(10)
.compose();А лучше даже обозвать его не Composer, а Composition, и сделать его комбинируемым с собой.
Сегодня надо отражать по вертикали, завтра понадобится отражать по горизонтали, ресайзить, делать Ч/Б, делать негатив, менять гамму, накладывать маску, делать блюр, и ещё сотни эффектов — всё пихать в Image? Лучше уж сделать composer, которому на входе скармливается иммутабельный
Нет, лучше сделать библиотеку. При этом часть перечисленного функционала должна быть реализована как функции (ресайзить, делать блюр), а часть как процедуры (отражение, создание негатива) чтобы при необходимости можно было не создавать новый Image а делать внутри того который есть. А часть — отдельно как функции и отдельно как процедуры, если создание нового это быстрее чем копирование + модификация.
Ещё, как написали ниже, можно сделать библиотеку/неймспейс с нужными функциями и сделать их stateless/pure — на вход объект картинки и на выход объект картинки. Но тут вкусовщина, кому-то нравится писать Composer(getImage())).foo().bar().baz().toImage(), кому-то foo(bar(baz(getImage()))).
В достаточно старых языках программирования (FORTRAN, PL/I и большинство их ровесников) было четкое, на уровне языка, разделение вызваемых модулей на функции — которые возвращают значение на основе переданных аргументов (возможно, производя на эти аргументы какие-то побочные эффекты), и процедуры — которые что-то делают с переданными им аргументами, но значения не возвращают, и сам смысл которых — как раз в том, что для функций называлось бы побочным эффектом.
И вот мне кажется, что автор «Чистого кода» использовал слово «функция» именно в этом контексте.
Нет, инкапсуляцию никто не отменял. Есть хороший доклад на тему ФП/ООП/Процедурщины, он довольно неплохо объясняет разницу между ними:
https://www.destroyallsoftware.com/talks/boundaries
Код кстати не какой-то хаскель/скала/идрис, а вполне приземлённый руби.
Очень рекомнедую глянуть, я для себя пару неожиданных вещей открыл.
По идее, чем больше параметров, тем сложнее. ООП стремится переложить большую часть сложности на этап создания объекта, и тем самым упростить интерфейс для конечных потребителей, уменьшая количество аргументов у метода до минимума. ФП, наоборот, оставляет потребителя разбираться с полным набором параметров самостоятельно. И в том и в другом подходе можно найти как свои преимущества, так и недостатки. Вот только практика показывает, что при попытке бездумно комбинировать разные подходы, вместо профита, получаются одни проблемы. Мода на ФП в ООП языках привела к тому, что порой на код без слез смотреть невозможно.
Ну чем вот отличается инстансный метод который неявно получает this от (MonadReader MyContext m) который получает тот же самый this точно также из эмбиент контекста? На мой взгляд, совершенно ничем
А если вы просто «потребляете» чей-то там класс или библиотеку, хотите понять почему-то там что-то не работает и у вас нет исходников, то да это проблема. Но как бы access modifiers именно для того и придумали чтобы вы не видели того, что вам не хотят показывать.
знать, на какие методы мне гарантированно можно не смотреть.
это тоже можно отнести к «вопросам к вашей IDE». И я бы даже сказал что это и нужно к ним относить. То есть для меня это всё из категории «найди все места где эта функция/переменная используется» или «найди все реализации этого интерфейса».
Перефразирую: как не читая тела функции понять, что она может делать, а что — нет?
В классическом ООП ответ: никак, вот есть у тебя void Foo() и можно гадать до посинения что он там делает.
Или как пример в статье которую я писал: я баг засадил, когда поменял 2 строчки кода местами, потому что певрая строчка (как потом оказалось) меняла стейт, который использовался следующей строчкой, и всё поломалось. Но менялось оно на уровне вложенности в десяток методов, за чем я не уследил.
Неплохо было бы такое ловить не на проде, а видеть сразу.
Есть такой термин — параметричность. Очень полезная штука. Например, возьмем функцию с такой сигнатурой:
foo : a -> aну или если вам ML не нравится возьмем раст:
fn foo<T>(t: T) -> T { ... }Эта функция может сделать две вещи: либо никогда не вернуть управление (запаниковать, войти в бесконечный цикл, ...), либо возвращает свой аргумент. Из этой информации и имени функции можно понимать что она делает, не читая её тело. Более того, в достаточно продвинутых языках можно генерировать тело по сигнатуре. То есть типы — первичны, а уж реализация — вторична, и во многом типа задают, что принципиально может делать функция, а чего — нет.
Как бы вы не попытались реализовать эту функцию, вы можете её реализовать только таким образом что я сказал. Если только не попытаетесь очень очень сильно саботировать сигнатуру, но обычно разработчик старается решить задачу, а не сделать аналог
#define TRUE FALSE
Причём в достаточно прошаренном языке (который не разрешает просто так эксепшны бросать тут и там) вам даже IDE самостоятельно сможет сгенерировать эту самую единственную реализацию:
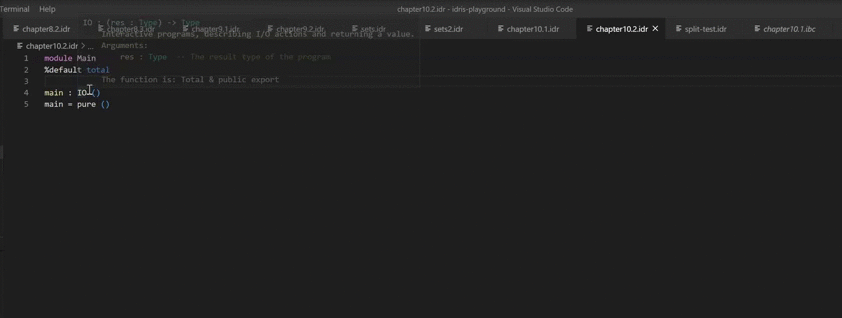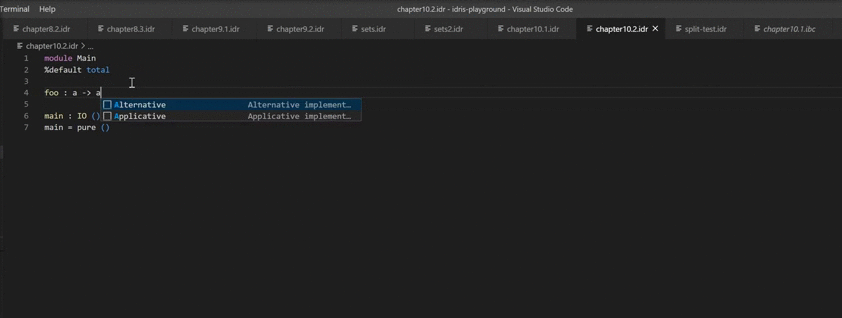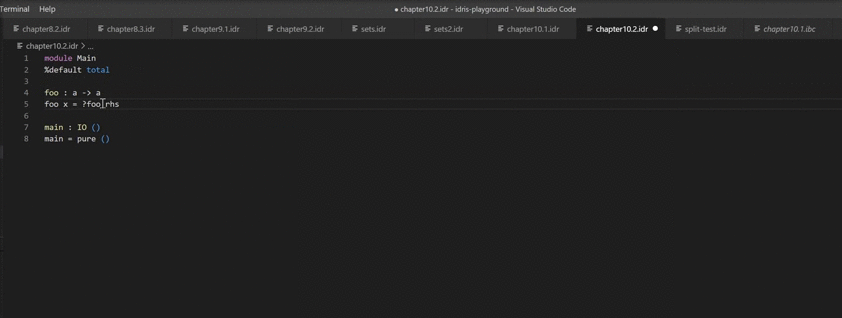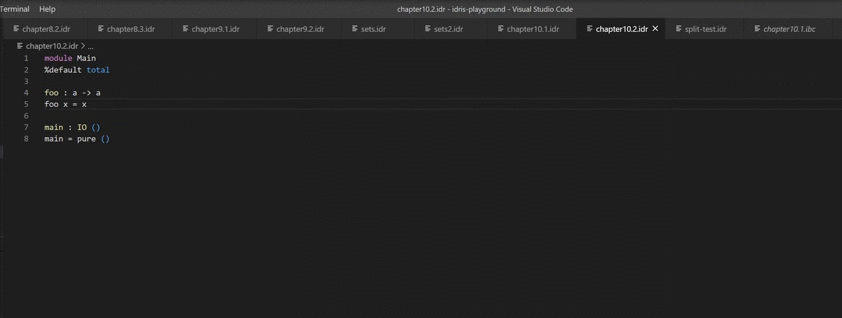
В реальности, конечно, часто выбор больше, но все равно множество разумных реализаций (исходя из названия функции, её аргументов и результата) очень и очень невелико, а часто состоит из всего 1 варианта
В реальности, конечно, часто выбор больше, но все равно множество разумных реализаций (исходя из названия функции, её аргументов и результата) очень и очень невелико, а часто состоит из всего 1 вариантаНе с вами ли вы обсуждали, совсем недавно, пример, где это было нифига не так?
Да, теоретически можно придумать язык, где типы полностью опишут вам функцию — но в этом случае они сами уже станут более сложными, чем написание функции на «классических» языках.
Сложность должна где-то жить, это, увы банальная истина.
P.S. Это не отменяет, конечно, того факта, что передача данных из одной функции в другую через
this — это, в большинстве случаев, плохая идея. Я, как правило, рассматриваю функции, нарушающие, временно, инварианты объекты, в котором эти функции живут, скорее средством оптимизации, которое можно применять, если потеря читаемости не слишком важна.Да, теоретически можно придумать язык, где типы полностью опишут вам функцию — но в этом случае они сами уже станут более сложными, чем написание функции на «классических» языках.
Вам не обязательно нужен язык, где тип полностью описывает всё, что происходит внутри, хотя и это неплохо, достаточно чтобы комбинация имя функции + типы позволяли с высокой точностью определять, что она может делать и примерно, как именно.
Например, если бы я увидел вызов пары функций в монаде State мне бы в голову не пришло поменять их местами, не проверив, что ничего не поломалось. А в шарпе я в зимой такую ошибку совершил. Хотя там понятно почему так получилось: я проверил всего лишь два десятка функций на 3-4 уровня по коллстеку, а нужно было заглянуть на 8 функций внутрь чтобы увидеть что там стейт мутируется.
Я, как правило, рассматриваю функции, нарушающие, временно, инварианты объекты, в котором эти функции живут, скорее средством оптимизации, которое можно применять, если потеря читаемости не слишком важна.
В тех самых языках про которые я говорю для этого есть монада ST — которая гарантирует, что вся грязь не вылезает из скоупа и в итоге всегда возвращает объект в валидное состояние.
Из этой информации и имени функции можно понимать что она делает, не читая её тело.
Но я правильно понимаю что такая функция «имеет доступ» исключительно к своим параметрам и всё? И скажем «внутри» у неё в принципе не может быть скажем доступа к какой-то базе данных или стороннему сервису? Или в ней тоже как-то описывается что она с ними делает и это можно понять не читая тело самой функции?
Правильно, в ней не может быть никаких хождений в БД, запросов по сети, доступа к какому-либо неявному стейту и так далее.
если оно в фунцкии нужно то оно выглядит примерно как
foo : (MonadHttp m, SqlBackend m) => UserId -> m User
foo = ...Ну если мне нужна такая детализация, я могу дальше уочнить, например SqlReadonlyBackend m или UserRepository m, ну и так далее.
Но обычно достаточно разграничивать функции по принципу: лезет в сеть/нет, лезет в бд/нет, может возвращать ошибку/нет, может вернуть нулл/нет, работает со стейтом/нет, пишет в консоль/нет, ...
Ну если мне нужна такая детализация
Дело не в детализации, а в том что там конкретно делается. Вы знаете что конкретно ваша фунцкия запишет в UserRepository не читая её тело?
я могу дальше уочнить, например SqlReadonlyBackend m или UserRepository m, ну и так далее.
Вот именно «я могу». А кто-то может так и не делать. Ну то есть получите вы библиотеку от человека, который «не смог» и вместо UserRepository запихал в параметры весь SqlBackend. И дальше что?
То есть вот эти ваши «я могу» это уже на мой взгляд начинаются code conventions. А их и в ООП никто не отменял.
Дело не в детализации, а в том что там конкретно делается. Вы знаете что конкретно ваша фунцкия запишет в UserRepository не читая её тело?
Знаю, одно из нескольких действий которые есть в репозитории.
Вот именно «я могу». А кто-то может так и не делать. Ну то есть получите вы библиотеку от человека, который «не смог» и вместо UserRepository запихал в параметры весь SqlBackend. И дальше что?
Если по задаче нужна была такая детализация — то это примерно как использовать string везде и парсить в int по месту — можно, но обычо так стараются не писать.
То есть вот эти ваши «я могу» это уже на мой взгляд начинаются code conventions. А их и в ООП никто не отменял.
Как в мейнстрим ООП языках отличить функцию которая ходит в БД от функции которая этого не делает?
Знаю, одно из нескольких действий которые есть в репозитории.
Какой конкретно контент будет туда записан? Ну вот у вас есть функция, которая получает строку и репозиторий. Вы не читая тело функции можете понять записывает она туда строку один в один или перед этим её как-то модифицирует?
Как в мейнстрим ООП языках отличить функцию которая ходит в БД от функции которая этого не делает?
А как в вашем примере отличить в какой репозиторй пишет функция получающая как параметер SqlBackend и пишет она туда или только читает?
То есть я понимаю что вы мне хотите сказать и вижу какие преимущества даёт такой подход. Но он всё равно не избавляет вас от необходимости читать тело функции. Он максимум облегчает вам это. Но такого облегчения при желании можно добиться и другими путями. В том числе и в ООП. Например установив определённые конвенции и придерживаясь их.
Какой конкретно контент будет туда записан? Ну вот у вас есть функция, которая получает строку и репозиторий. Вы не читая тело функции можете понять записывает она туда строку один в один или перед этим её как-то модифицирует?
Ну если написано так:
foo : (UserRepository m) =>
(str : String) -> m (WriteResult m str)то значит, что использовалась та самая строка, что передана, без модификаций. Правда, такой уровень детализации в типах мне кажется излишним.
То есть я понимаю что вы мне хотите сказать и вижу какие преимущества даёт такой подход. Но он всё равно не избавляет вас от необходимости читать тело функции. Он максимум облегчает вам это. Но такого облегчения при желании можно добиться и другими путями. В том числе и в ООП. Например установив определённые конвенции и придерживаясь их.
Ну если я увижу функцию
addUser : (UserRepository m) -> UserName -> UserPassword -> m ()То я не буду читать её тело, я просто предположу то, что может любой разумный человек: что функция берет и пишет в БД юзера вот с такими параметрами. Причем пишет в БД, а не по сети, в эластик, в файл или ещё куда-то
Ну если написано так:
Я честно говоря вот так на первый взгляд не могу со 100% уверенностью понять что функция WriteResult только пишет и больше ничего не делает. То есть может я синтаксис не особо хорошо понимаю, но из чего это должно следовать?
Ну если я увижу функцию.
…
То я не буду читать её тело, я просто предположу то, что может любой разумный человек: что функция берет и пишет в БД юзера вот с такими параметрами.
Ну так и если я увижу функцию
UserRepository.AddUser(userName, userPassword)то предположу тоже самое. И чем мои предположения хуже ваших? :)
Я честно говоря вот так на первый взгляд не могу со 100% уверенностью понять что функция WriteResult только пишет и больше ничего не делает. То есть может я синтаксис не особо хорошо понимаю, но из чего это должно следовать?
из связи результата и входного параметра.
то предположу тоже самое. И чем мои предположения хуже ваших? :)
Да нет, просто я вот например не вижу:
- есть какое-то логгирование в этом AddUser или нет?
- она может завершиться с ошибкой или нет?
- а она чистая или нет, мы меняем какой-то стейт самого UserRepository (может, кэши какие-то)?
- ...
То есть тут вопрос в том, какие предположения мы достоверно можем отмести
из связи результата и входного параметра.
А как будет выглядеть эта связь если WriteResult ещё что-то делает кроме как писать? Как мне понять что произойдёт если result по каким-то там причинам не сможет быть записан в бд? Например если он в неправильном формате?
есть какое-то логгирование в этом AddUser или нет?
…
а она чистая или нет, мы меняем какой-то стейт самого UserRepository (может, кэши какие-то)?
Пониемаете, я вот лично в 99,999% cлучаев даже не хочу это знать. И по вашему получатся что ради того самого 0,001% я должен каждый раз передавать мой логгер/кэш в параметрах. Мне лично это менее удобно и создаёт больше проблем чем решает.
она может завершиться с ошибкой или нет?
Это вообще к ООП отношения не имеет. В той же Java есть вот такое
public void init() throws CustoмException
{
}А как будет выглядеть эта связь если WriteResult ещё что-то делает кроме как писать? Как мне понять что произойдёт если result по каким-то там причинам не сможет быть записан в бд? Например если он в неправильном формате?
Если в сигнатуре этого нет, значит запись не может завершиться неуспешно. А учитывая, что в реальности БД всегда может поломаться, можно сделать вывод что это сигнатура описывает in-memory базу :) И Этот вывод мы смогли сделать просто из сигнатуры, ну потому что не бывает физической БД которая никогда не падает при записи.
Пониемаете, я вот лично в 99,999% cлучаев даже не хочу это знать. И по вашему получатся что ради того самого 0,001% я должен каждый раз передавать мой логгер/кэш в параметрах. Мне лично это менее удобно и создаёт больше проблем чем решает.
А у меня получается, что очень часто это нужно знать. А то был у меня например случай, когда я безобидную функцию вида int x = Sqr(otherInt) написал в цикле, а у меня упал эластик, потому что в него триллион логов посыпалось. Ну или многострадальный пример когда я поменял 2 строчки, и тоже на проде взорвалось в другом месте. Это далеко не 0.001%
Это вообще к ООП отношения не имеет. В той же Java есть вот такое
алгебраические эффекты сильно сложнее чем чекед эксепшны, именно поэтому последние не получили распространения. Но да, это один из примеров, когда из сигнатуры видно, что функция может упасть (или нет). Но в ваша функция AddUser разве так написана?
А учитывая, что в реальности БД всегда может поломаться, можно сделать вывод что это сигнатура описывает in-memory базу:
Угу. А если у меня работа с чем-то о чём я не знаю может оно там поломаться или нет? Гадать? Или лезть в тело функции и разбираться?
И мне всё ещё интересно как будет выглядеть сигнатура у функции, которая каким-либо образом модифицирует содержание прежде чем записать его куда-то?
А у меня получается, что очень часто это нужно знать. А то был у меня например случай, когда я безобидную функцию вида int x = Sqr(otherInt) написал в цикле, а у меня упал эластик, потому что в него триллион логов посыпалось.
А Sqr(otherInt) это ваша функция или чужая? Если ваша, то вы извините, но выяснить пишет она там что-то в логи или нет, так это и в ООП не особо большая проблема. Да, в вашем варианте круг поисков будет поуже, но на мой вгляд это не особо-то и критично.
А если это чужая функция, то откуда она знает как в ваш эластик писать?
Но в ваша функция AddUser разве так написана?
Ну так ещё раз: это не зависит от ООП или не ООП. В некоторых языках такое указывать нельзя, в других можно, в третьих обязательно.
Да и вообще в теории вы и ООП язык наверное можете создать в котором надо будет указывать контекст, который может использовать функция. только подозреваю что это опять же мало кому надо.
Угу. А если у меня работа с чем-то о чём я не знаю может оно там поломаться или нет? Гадать? Или лезть в тело функции и разбираться?
И мне всё ещё интересно как будет выглядеть сигнатура у функции, которая каким-либо образом модифицирует содержание прежде чем записать его куда-то?
Придется для этого обёртку сделать, но ничего невозможного нет. В типах там будет указано, что результат — то же значение, что мы передали. Дальше при желании пишутся пара теорем, что резульатт действительно такой как мы ожидаем (ну, вместо тестов) и порядок.
Но обычно так заморчиваться не надо, геморроя много, а толку — не очень.
А Sqr(otherInt) это ваша функция или чужая? Если ваша, то вы извините, но выяснить пишет она там что-то в логи или нет, так это и в ООП не особо большая проблема. Да, в вашем варианте круг поисков будет поуже, но на мой вгляд это не особо-то и критично.
Ну, где-то в решение она объявлена, в сигнатуре ничего про логи не написано, принимает инт, возвращает инт.
Да и вообще в теории вы и ООП язык наверное можете создать в котором надо будет указывать контекст, который может использовать функция. только подозреваю что это опять же мало кому надо.
Я про практические языки которые есть на рынке: джава, шарп, хаскель,… То что можно сделать химеру — это конечно никто не спорит, только её нет. А говорить о несуществующем не вижу большого смысла.
Но обычно так заморчиваться не надо, геморроя много, а толку — не очень.
То есть получается что цена вопроса это субъективное понимание «геморроя» и «толка». И если кто-то, как например я, считатает что вся эта овчинка в принципе выделки не стоит, то получается что и ООП не проблема? :)
Ну, где-то в решение она объявлена, в сигнатуре ничего про логи не написано, принимает инт, возвращает инт.
И как долго вам пришлось выяснять что она всё-таки пишет логи? :)
Я про практические языки которые есть на рынке: джава, шарп, хаскель,…
Я бы сказал что на это просто нет достаточного спроса. Если бы он действительно был, то и ЯП бы быстро появились.
И как долго вам пришлось выяснять что она всё-таки пишет логи? :)
Да сразу узнал, когда мне написали, что эластик уронился после такого-то коммита.
Я бы сказал что на это просто нет достаточного спроса. Если бы он действительно был, то и ЯП бы быстро появились.
На то чтобы такое было в ООП языках — безусловно. Потому что эффекты или должны быть, или нет. Если они есть, то никакой нуллябельности по-умолчанию, экспепшнов по-умолчанию и так далее. Это, кстати, можно видеть в расте.
Но в существующих языках таких ломающих изменений конечно никогда не будет. А в новых оно понемногу появляется: Раст, Котлин, Свифт, ...
А так да, определённые вещи однозначно проще реализовывать при помощи ООП, а некоторые удобнее при помощи ФП. И поэтому скорее всего их начнут использовать параллельно. Например тот же дотнет вполне себе позволяет «миксить» C# и F#. Пока ещё не особо удобно, но надеюсь что со временем сделают получше.
Понимаете, если разбить ООП и ФП по фичам (в смысле, популярные языки), то окажется, что Java это A,B,C,D,
шарп это A,B,C,E,F,G, а какой-нибудь хаскель это B,C,F,G,H,I,G,K,L,M. Если нарисовать диаграммки Венна, то окажется что они практически пересекаются. Но в этих нюансах и кроется основное различие. И под ООП лично я по крайней мере понимаю те компоненты, которые свойствены Java/C#/..., но не свойствены Haskell/Scala/..., в примере выше это A и E.
Поэтому мне кажется, что все разговоры про смерть ФП или ООП от неоднозначной формулировке: кто-то под ООП подразумевает объединение всех ООП языков, а кто-то наоборот — пересечение с исключением всего что есть в не-ООП языках.
Как я писал в статье, я расцениваю ФП как подход с единственным правилом "Пиши ссылочно прозрачные (ака чистые) функции". Всё, если у вас код на 100% соблюдает эт оправило, то код — фп, а если нет — то нет. При этом, будет там иерархия классов, иок контейнер или ещё что-то уже совершенно не важно. И я считаю, что этот подход просто строго лучше чем альтернатива. Ну примерно как то, что концепция "функций" строго удобнее для людей чем лонг джамп или что понятие переменной человеком воспринимается проще чем регистр.
Сколькими способами можно например написать такую функцию?
fn: Int -> Int
Одним? Двумя?… Миллиардом?
Когда вам надоест писать метакод, и вы спуститесь на уровень пониже, то увидите, сколько вариантов может генерировать одна настоящая функция.
При чем тут метауровень? Это чисто параметричность — то что функция не зависит от аргумента. Именно поэтому обобщённые функции это круто — не только потому, что мы исключаем копипасту, но и потому, что мы по игнатуре видем, что может с объектами делать функция, а чего — нет.
Сколькими способами можно например написать такую функцию?
fn: Int -> Int
Одним? Двумя?… Миллиардом?
(2^32)^(2^32) — количество обитателей легко считается. Общая формула: a -> b имеет b^a обитателей.
(2^32)^(2^32) — количество обитателей легко считается. Общая формула: a -> b имеет b^a обитателей.
Выше вы предлагаете генерировать по сигнатуре Int->Int какой-то конкретный вариант из (2^32)^(2^32) штук? Вам не кажется, что вероятность угадать верный вариант слишком мала?
Ну так когда мы можем понять РЕАЛИЗАЦИЮ по СИГНАТУРЕ — это и есть IoC, у нас реализация зависит от абстракции (ака сигнатуре), разве нет?). И плохо, когда работает наоборот: посигнатуре вроде мы имеем право работать, но вот нужно посмотреть реализацию и понять, что на самом деле вот так можно делать, а вот так — нельзя.
Ну так когда мы можем понять РЕАЛИЗАЦИЮ по СИГНАТУРЕ — это и есть IoC, у нас реализация зависит от абстракции (ака сигнатуре), разве нет?).
Я всё ещё не понимаю как вы там по сигнатуре угадываете конкретную реализацию? Вот есть у меня функция
int DoSomething(int x, int y);
как мне по одной только сигнатуре понять складывает она там или умножает? Или вообще что-то третье делает?
И плохо, когда работает наоборот: посигнатуре вроде мы имеем право работать, но вот нужно посмотреть реализацию и понять, что на самом деле вот так можно делать, а вот так — нельзя.
Вам всегда придётся куда-то смотреть как можно делать и как нельзя. Эта информация где-то должа быть записана. И я не вижу принципиальной разницы записана она в теле метода, в описании типа/класса, в какой-то аннотации или даже в форматe вызова функции.
По сигнатуре с конкретными типами почти никогда ничего сказать нельзя.
А вот сигнатура с генериками — совсем наоборот, очень редко когда нельзя сказать что она делает. Например функция:
fn T do_something<T,U>(T x, U y)
всегда возвращает первый аргумент и игнорирует второй (если не зависает паникой или ещё как).
Хотя в шарпе параметричность ломается с помощью typeof, это конечно очень жаль.
ну например так:
fn foo<T: Add>(a: T, b: T) -> T::Output { .. }
fn bar<T: Mul>(a: T, b: T) -> T::Output { .. }
fn baz1<R, T: Sub<Rhs=R>>(a: T, b: R) -> T::Output { .. }
fn baz2<R, T: Sub<Rhs=R>>(a: R, b: T) -> T::Output { .. }Или скажем как быть если внутри выполняется "(х + у) * (х-у) + (х +х)*(у * 42)… "?
Ну вы можете всё тело функции запихнуть так или иначев сигнатуру. Будет у вас тип AddXAndYMultipledByXMinusYPlusDoubleXMultYAnd42 — оно вам нужно? В чем смысл этих расспросов? Давайте я буду у вас спрашивать как что-нибудь в другом языке делается? Это уже переходит рамки приличия.
Будет у вас тип AddXAndYMultipledByXMinusYPlusDoubleXMultYAnd42
Т. е., чтобы добиться нужного уровня информативности (кажется все началось с необходимости понять, что происходит внутри метода, не заглядывая внутрь), надо второй раз «метаданными» написать реализацию метода?
Например, собрать рядом Expression, а в методе его скомпилить и выполнить — тоже нужно смотреть вне метода, чтобы понять, что он выполнит.
Не уходите, как раз к самому интересному подошли(=
Т. е., чтобы добиться нужного уровня информативности (кажется все началось с необходимости понять, что происходит внутри метода, не заглядывая внутрь), надо второй раз «метаданными» написать реализацию метода?
Да.
Поэтому так никто и не делает.
Но между "продублировать тело в сигнатуре" и "void Foo()" есть куча градаций. И золотая середина мне нравится куда больше, чем ни к чему не обязывающие сигнатуры мейнстрим языков.
И для того чтобы понять что делает функция foo : a -> a не нужны никакие сложные типы и дублирование тела в сигнатуре. Перефразируя, парметричность говорит что чем более абстрактная функция, тем меньше множество возможных её реализаций. А значит тем больше надежность и лучше работает интуиция, что функция может делать, а чего — нет.
И под "что может делать функция" я имею в виду не дословно расписать по шагам, что она делает, а класс, к которому функция относится, с той или иной степенью детализации. Я выше уже писал про "или нет", это всё про это.
Ну вот простой пример пусть будет функция:
bar : [a] -> [a]
bar xs = ...Я не знаю, как эта функция устроена, но я могу не глядя в реализацию сказать, что функция принимает список и возвращает список, причем результирующий список всегда состоит из элементов входного списка (повторяющихся 0..n раз, и возможно в другом порядке). Причем в случае раста это утверждение ещё строже: это элементы исходного списка, причем они повторяются не более одного раза (но некоторые могут в результате отсутствовать, вплоть до пустого списка). Часто этой информации мне будет достаточно, чтобы понять, как эту функцию вызывать и что делать с результатом.
Возможно кажется, что это всё бесполезные разглагольствования, но на самом деле это экономит часы и в итоге дни на отладку.
Перефразирую: как не читая тела функции понять, что она может делать, а что — нет?
Вот я всё и пытаюсь понять как такое должно работать. И получается что работает такое в ФП только если кто-то был настолько добр что поместил тело функции в сигнатуру. Что по вашим же словам обычно всё равно никто не делает. Плюс это самое тело функции вам всё равно надо читать, но просто в другом месте.
То есть бенефит от всего этого есть, но пожалуй только для не особо сложных функций. А если функция более-менее сложная, то вам и в ФП всё равно придётся лезть в её «тело» и разбираться уже там. Но взамен у вас сигнатуры заметно сильнее разбухают…
P.S.Ну или вот напишу я вам какой-нибудь, автодок, который автоматом копипэйстит тело функции в её комментарии. И сможете вы в ООП точно так же «понимать что делает функция не читая её тела».
P.P.S. И самое главное получается что каждый раз когда я буду менять реализацию своей функции, я должен буду менять её сигнатуру чтобы люди могли «понимать что она делает не читая её тела». И будет у меня при каждом багфиксе изменение сигнатур у каждого метода, который я хоть как-то тронул. Не сказал бы что такой вариант меня сильно радует…
То есть бенефит от всего этого есть, но пожалуй только для не особо сложных функций. А если функция более-менее сложная, то вам и в ФП всё равно придётся лезть в её «тело» и разбираться уже там. Но взамен у вас сигнатуры заметно сильнее разбухают…
Чем сложнее функция, тем наборот проще, потому что каждый констрейнт дает информацию о том, что она делает. По 3-4 консстрейнтам уже можно практически точно сказать, что делает функция.
P.S.Ну или вот напишу я вам какой-нибудь, автодок, который автоматом копипэйстит тело функции в её комментарии. И сможете вы в ООП точно так же «понимать что делает функция не читая её тела».
А этот комментарий будет проверяться компилятором? Например, что сложение не реализовано как вычитание? Раз уж доходит до абсурда
P.P.S. И самое главное получается что каждый раз когда я буду менять реализацию своей функции, я должен буду менять её сигнатуру чтобы люди могли «понимать что она делает не читая её тела». И будет у меня при каждом багфиксе изменение сигнатур у каждого метода, который я хоть как-то тронул. Не сказал бы что такой вариант меня сильно радует…
А ещё если смените String на Int то тоже код ломается, вот грустно. А у питонистов отлично — просто начал использовать переменную как число и ничего не поломалось. Красота.
Чем сложнее функция, тем наборот проще, потому что каждый констрейнт дает информацию о том, что она делает. По 3-4 консстрейнтам уже можно практически точно сказать, что делает функция.
Я бы сказал что они скорее дают информацию о том что она в принципе не может делать и таким образом сужают «область поиска». Это полезно, но «покупается» за счёт «разбухающих сигнатур».
А этот комментарий будет проверяться компилятором? Например, что сложение не реализовано как вычитание? Раз уж доходит до абсурда
Проверяться не будет. Но я могу написать это таким образом что комментарий всегда будет один в один выглядеть как тело функции. И если функция не компилируется, то и комментария не будет. Но да, это я дoлжен проявить желание такое сделать и заставить меня вы не можете. Как впрочем и в ФП вы не можете никого заставить писать грамотные сигнатуры.
А ещё если смените String на Int то тоже код ломается, вот грустно.
Да, ломается. Но по моему опыту в «ООП языках» тело функции меняется гораздо чаще чем её сигнатура. И как раз таки смена сигнатур это обычно breaking changes и этого стараются по возможности избегать.
Я бы сказал что они скорее дают информацию о том что она в принципе не может делать и таким образом сужают «область поиска». Это полезно, но «покупается» за счёт «разбухающих сигнатур».
Ну они не сильно-то разбухают. Особенно в наш век IDE
Проверяться не будет. Но я могу написать это таким образом что комментарий всегда будет один в один выглядеть как тело функции. И если функция не компилируется, то и комментария не будет.
Это не поможет, по той же причине почему копирования тела в динамическом япе не заменит типизации.
Да, ломается. Но по моему опыту в «ООП языках» тело функции меняется гораздо чаще чем её сигнатура. И как раз таки смена сигнатур это обычно breaking changes и этого стараются по возможности избегать.
В данном случае, изменение сигнатуры это изменение требований. И я лучше получу ломающее изменение, чем человек молча напишет default(T) внутри тела, не меняя функцию, и у меня потом будет поломка из-за 0/null (был прецедент)
А у питонистов отлично — просто начал использовать переменную как число и ничего не поломалось.Вы python и javascript/php не перепутали? Это в javascript/php можно сравнивать всё со всем и в результате нет тразитивности ни у ==, ни ну <
Для меня это выглядит сомнительно, потому что на моем личном опыте те ошибки, которые я чаще всего встречал, были вызваны именно ошибками в семантике, а не в типах. Неправильный формат сообщения, забытый вызов метода внешнего окружения, неправильный алгоритм подсчёта, и тд.
Всё это можно и нужно проверять типами. Типизированная форматирующая строка это вообще один из примеров для начинающих идрисистов. Ну и немного теории если есть сомнения.
C. И в 99% случаев действительно мне либо вообще не интересно знать, что делает компонент, либо я закладываю, что каждый мой код работает с 5-10 реализациями одного интерфейса, и если я даже сделаю интерфейс типа Add, чтобы по сигнатуре догадываться, что там может быть только сложение чисел, у меня остальные 9 реализаций скажут «А нам то что делать? У нас не сложение используется». Сделать в сигнатуре разрешение на сложение, вычитание, умножение, деление, чтобы можно было все нужные кейсы покрыть? Сигнатура становится монстроуозной, а по ней уже не скажешь, что конкретно она делает. Сомневаюсь, что даже на языках с навороченной системой типов можно описать, как происходит алгоритм расчёта, какие числа и в какой последовательности мы используем операторы, а именно в этом чаще всего я встречал косяки.
Есть понятие разумного уточнения. Конечно отдельно редко пишут сложить-вычесть, но например можно наложить ограничение Num — то есть всё, что умеет в основные 4 арифметических операций. Коротко и понятно. Если нужны ещё более абстрактные вещи можно объединить, и так далее.
Никто же не расстраивается, что List в сишарпе реализует пару десятков интерфейсов?
Мне кажется, в этом и прелесть ООП, что в нем класс не берет на себя дополнительную обязанность знать, что и как делает его зависимость.
Как раз ООП более ограниченное. Если у вас есть синхронный метод вы в наследнике не сможете сделать его асинхронным никак. Потому что сигнатура жестко фиксируется родителем.
Назовите мне хоть одну систему или свод правил, которая бы смогла запретить безалаберному человеку или вредителю делать его дело плохо.
Система типов любого мейнстрим языка запрещает передавать строчки вместо чисел или вызывать у объектов несущестующие методы, за счёт чего ликвидирует класс ошибок связанных с этим.
А если человек адекватный, то даже в языке без nullable можно сделать себе жизнь комфортной простой договоренностью.
Нет
Я не про нарушение форматирования строки, я про то, что сторонний сервис ждет, условно, одной строки, а человек по ошибке отправляет другую. По вашей ссылке, насколько я понимаю, о другом идет речь.
Ну, всё в типы не запихнуть, не спорю. Но б0льшая часть ошибок что у людей встречаются типами ловится. Например, из недавноего когда игра провалилась, а через год разработчики обнаружили, что в скрипте поведения ИИ опечатка из-за чего он просто не работал по факту. Починили и игра сразу стала интересной! Но поезд ушел.
Разыменование нуллов, неправильные контракты, поздняя валидация десериализованных данных, дедлоки и остальное — основные проблемы, и для всех них есть решение.
В вашем предыдущем сообщении речь шла о понимании, что происходит внутри метода. У метода в аргументах 2 Num, на выходе один, что он конкретно делает, сказать точно уже нельзя, потому что это не Add, над которым можно проводить только одну операцию.
Ну я знаю, что над аргументами происходит арифметическая операция. Когда я говорю "я понимаю что делает функция" это не значит, что я с закрытыми глазами опишу как она выполняется, а то, что чтобы понять как её использовать мне не надо лезть глубже сигнатуры.
Выглядит как попытка экстраполировать свой частный опыт на всех. Если у вас не вышло, то это не значит, что у других людей не получается.
Кроме вашего кода есть ещё код коллег, а ещё библиотеки и фреймворки которые не обязательно вашим договоренностям следуют (а скорее — как правило не следуют). А ещё люди ошибаются. Я уж точно.
И как это ограничение мешает писать говнокод? По-прежнему в такой системе тонны способов написать что-то медленное, затрачивающее тонны ресурсов, приводящее к падению приложения, трудночитаемое, неподдерживаемое, ошибочно написанное и т.д.
Я говорю про то что у вас нет ошибок "'number' doesn't have property 'length'", а не то что это сильвербулет.
Я не знаю, в каком языке можно унаследоваться/обернуть синхронный объект/метод с сохранением сигнатуры и сделать его асинхронным.
Любой язык с типами высших порядков. Скала, как пример.
Вот я о том и говорил, что все системой типов не покрыть, только простые вещи типа передачи строки вместо числа
Нет, это была аналогия. Насколько система типов мейнстрим языка лучше бестиповых скриптов, настолько же продвинута система типов помогает по сравнению с ней.
От мелочей вроде форматирующей строки заканчивая тайпсейф многопоток и типизированных конечных автоматов (где переход в неправильное состояние — ошибка компиляции). А как вы наверное знаете, довольно много всяких бузинес-правил можно выразить как КА.
Всё конечно покрыть нельзя, но можно в разы больше того, что люди делают.
И как это выглядит? Я просто такого ни разу не встречал.
trait MyInterface[Self]:
type F[A]
def (item: Self) getSomething() (using Monad[F]): F[Int]
class SyncInterface
class AsyncInterface
given syncInstance as MyInterface[SyncInterface]:
type F[A] = Id[A]
def (item: SyncInterface) getSomething()(using Monad[Id]): Id[Int] = 42
given asyncInstance as MyInterface[AsyncInterface]:
type F[A] = IO[A]
def (item: AsyncInterface) getSomething()(using Monad[IO]): IO[Int] = () => 42 Я использую в качестве затычки IO который просто синхронный коллбек, но на самом деле там должно быть что-то из библиотеки cats, например вот это: https://typelevel.org/cats-effect/typeclasses/async.html
Работать будет точно так же как и пример.
Про продвинутую систему типов не знаю, почему-то пока что я не настолько сильно замечаю, что с переходом от того же Objective-C к Swift, где система типов гораздо сильнее, у меня резко уменьшилось количество ошибок. Но видимо это разнится от человека к человеку.
Кроме продвинутой системы типов ещё некоторое значение имеет прокладка между монитором и креслом :)
Ни один самый продвинутый инструмент не работает сам по себе. Программист на фортране может писать на фортране на любом языке программирования
По поводу примера, я так понимаю, тут просто создаётся ещё одна функция, которая оборачивает вызов синхронной функции и возвращает его в лямбде? Если так, то что мешает в том же ООП сделать интерфейс с асинхронным методом, реализовать класс с ним, а внутри вызывать объект с синхронным методом?
Но это будет не то же самое. В случае выше у вас две реализации имуют типы Id[A] и IO[A], ну или Sync<T> и Async<T> соответственно. А третья реализация может например возвращать Option — тоже полезный кейс.
А возвращать асинхронный метод часто плохо, например в расте чтобы выполнить асинхронный метод нужен явный рантайм, там нет подковёрного неявного тредпула где можно втихую задачи бросать. А значит если библиотека требует асинка то она сразу требует +50 зависимостей, что не очень.
Ну и если посмотреть на это философски, то это все равно что у вас есть две реализации функции, одна должна возвращать число, а другая — строку, и вы делаете общий тип — строку, а ту которая возвращает число вы просто пишете как myint.toString(). Можно ли так сделать? Да, строки более "Общие" чем числа (как асинк более общий, чем синк). Но тут во-первых эстетически это грязь, а во-вторых вам нужно теперь помнить, где числа а где нет, чтобы знать, когда в число парсить (нам ведь нужно это число где-то получить, правда?). В случае асинка это означает, что мы должны помнить, когда можно заблокироваться, а когда нельзя, или везде писать асинк-авейт, даже там, где мы передали реализацию которая на самом деле синхронная.
Ну и наконец, писать Task.FromResult/Promise.resolve на каждый чих утомляет.
Вот я о том же) Eсли человек и его команда хотят облегчить себе жизнь, то можно ведь выработать определенные правила, например, для работы с теми же опциональными значениями. Человек + тот же код ревью будут заменять собой правила компилятора, не 100% идеально конечно, но и не на уровне пустой траты времени, и к этому еще и смогут когда нужно это игнорировать, если это требует ситуация, без сложной возни с системой ограничений языка.
Тем не менее, ни с какими договоренностями я не видел чтобы люди избавились от nullref exception. И атрибуты вешали, и договаривались называть TryXXX если нулл может вернутся — все равно не помогало. А вот с Option явным такого не случается.
Не совсем наверное понимаю суть различия. Вот у нас есть некий
Ну так ваш completion очень похож на TaskCompletionSource (ну или Promise.resolve из жс), тот же асинк, только в профиль.
А если вы пользуетесь разными интерфейсами, то это как-то другой пример. Я приводил пример как написать один интерфейс, и у него будет один наследник синхронный, другой асинхронный, а третий, например, синхронный, но с возможностью сообщить явно об ошибке.
С одним интерфейсом вы можете писать код, который работает как для синронных, так и для асинхронных вариантов. В вашем случае вы можете или с A работать, или с B, но вы не можете написать одну функцию которая работает как с А, так и с B одинаково.
Мне кажется, что и в языках с убер типизацией люди никуда не ушли от багов. Количество поуменьшилось, но все равно есть + добавились другие проблемы, увеличение времени сборки, сложный обход системы типов, если нужно в каком-то случае что-то подкрутить, прочее. Не знаю точно, но ощущение такое есть) Или действительно с той же Scala баги практически исчезли?
Programming Defeatism: No technique will remove all bugs, so let's go with what worked in the 70s.
Понятно, что всех багов не исправить. Но сидеть со старыми инструментами все равно как-то неправильно.
И да, целые классы багов ушли. Я вот не припомню ни одного memory-safety бага в сишарп проектах на которых я был. Совпадение?
Не спорю, просто хотел понять фразу про «ограничение в ООП». Если в ООП тоже можно превратить синхронный вызов метода в асинхронный, то в чем его ограниченность?
Ну смотрите, в примере выше я могу взять MyInterface и написать функцию которая, например результат на два умножает. В вашем случае у вас есть два интерфейса A и B, и нет общего MyInterface, и такую функцию написать не получится.
Добавление типизации в той же Java решило много проблем в сравнении с JavaScript и незначительно усложнило язык, а вот дополнительное наращивание типизации для меня выглядит так, что мы больше усложняем себе жизнь новыми ключевыми словами, ограничениями с выводом типов, нюансами при работе с типами, чем решаем насущных проблем.
Нет, это классический парадокс блаба: вы знаете Java поэтому смотрите на JavaScript сверху вниз и видите, как фичи джавы помогают. А когда вы смотрите "Наверх", то выидите "странные языки", которые возможно такие же мощные как джава, но с какими-то странными прибабахами и сложностями на ровном месте. И зачем?! Ведь я знаю, как то же самое сделать на джаве, где ничего этого нет.
Это решается только кругозором. Ну или не решается, и человек до конца жизни уверен, что нашел идеальный инструмент.
Можно, например, сделать у A дженерик для аргументов и результирующего значения, и у B тоже. Можно будет писать нужные реализации А для операций над T, строки, числа, и тд и тп. Единственному классу, реализующему асинхронную работу, будет без разницы, с какой именно реализацией А работать.
Ну это похоже на правду, за исключением того, что без типов высших порядоков вы не сможете написать такой генерик. Ну не выразить на сишарпе или джаве тип T<i32>, чтобы пользователь мог сам выбрать реализацию. Поэтому и не получится Sync<i32> или Async<i32> выбрать по месту.
Что до времени компиляции, то если вы не пишете тяп-ляп, то все те же инварианты нужно все равно проверять, но уже другими инструментами: тестами, куа-инженерами которые тыкают кейсы руками и так далее. И всё это на порядки медленнее самого тормознутого тайпчекера. Нет никаких предпосылок, почему именно джава идеал, убираем проверки — небезопасно, добавляем — тормоза.
Ну вообще я сначала писал на JavaScript, только потом начал на Java, затем на Objective-C, а потом перешёл на Swift с более навороченной системой типов, чем в Java. Но почему-то уровень типизации Objective-C/Java мне показался золотой серединой, чтобы и опечаток/ошибок с типами было по минимуму, и работать было по-прежнему комфортно. Более навороченные дженерики вроде и хорошо, но порой начинается война с тем, как объяснить компилятору своё намерение, если накрутил какой-нибудь абстрактный компонент.
Ну свифт не особо мощнее джавы, особенно учитывая Arc вместо полноценного гц, с ним может казаться даже менее высокоуровневым. Дальше по спектру это скорее всякие скала/хаскель, или Rust в стиле Томаки.
Но в целом я понял вашу идею, спасибо, что разъяснили про Scala и ваши взгляды на типизацию. С «ограниченностью ООП» холиварный был вброс, но не хочу его начинать, согласен разве что с тем, что в мейнстримовых языках подобные задачи решатся чуть большим количеством кода, но для меня это не ограничение парадигмы, а недоработка разработчиков языков, которые фокусируются на других вещах.
Про "ограниченность" я говорил в буквальном смысле: некоторые вещи не выразить, как концепцию. Можно работать без такой абстракции (в конце концов, всё в итоге компилируется в ассемблер, где таких абстракций нет, и часть этой трансляции можно выполнить руками), но такой абстракции — нет, нельзя сделать. И это не ругательство и разделение на "ограниченные" и "полноценные" япы а просто констатация факта — ну просто такую штуку выразить нельзя. Как в хаскелле нельзя выразить некоторые вещи которые можно в идрисе — ну просто язык не настолько расширяем чтобы это работало.
То есть я не ругал, а просто констатировал некоторое свойство некоторых существующих языков (но не парадкигмы как таковой, к слову).
Спасибо вам за дискуссию, мне было очень интересно узнать ваши взгляды. И спасибо за материал про типизацию форматирования строки, до этого я не знал, что под это подводят доказательную базу.
Взаимно, было приятно поболтать)
Как в хаскелле нельзя выразить некоторые вещи которые можно в идрисе — ну просто язык не настолько расширяем чтобы это работало.Тут есть ещё некая схожесть с тьюринговская трясиной.
Если в языке типы — это тьюринг-полный язык (как в C++ и, вроде бы, в Haskell), то на них, очевидно, можно выразить что угодно (в том числе всё, что умеет Idris тоже можно).
Однако практически — этим пользоваться, конечно, будет невозможно.
И то же самое случается часто с разными фичами, которые вроде как, предназначены для использования — но при этом пользоваться всем этим могут только единицы.
Хороший пример — метапрограммирование в C++. Появилось оно ещё в C++98 (причём оно в язык было не добавлено, а открыто… во время стандартизации этому уже внимание чуть-чуть уделили), однако «простые смертные» могут им пользоваться только начиная с C++17 — потому что только там есть такие вещи, как fold expression и constexpr if. С ними метапрограммирование начинает быть похожим на обычное программирование, в то время, как до того — у вас получался, плюс-минус, «типа-как-бы-Lisp-посреди-C++». Который «осиливали» немногие…
Так шаблоны это не типы, это именно что шаблоны, кодген по, собственно, шаблону. Можно ли сгенерировать что-то что будет тайпчекаться? Можно. Но это не типы, и удобство соответствующее.
Так шаблоны это не типы, это именно что шаблоны, кодген по, собственно, шаблону.Вы либо не в курсе того, что такое шаблоны в C++, либо передёргиваете. Вот какой-нибудь Maybe — это тип или нет? Ну, по крайней мере обычно считается, что да. А в C++ такая же, по сути, вещь — это шаблон. Только там была забавная фича — было разрешено делать специализацию для конкретного типа. Ну там, чтобы
optional<bool> сделать эффективнее чем с помощью стандартной схемы. Это сделало язык описания типов тьюринг-полным, что сразу же «приспособили к делу». В Haskell (ну… в GHC) есть полноценное метапрограммирование, так что это всё не очень нужно. А в C++ есть даже целые библиотеки, позволяющие на этом всём программировать…Maybe — тайплевел функция. В отличие от шаблона это полноценный объект.
Ну серьезно, в расте вы же легко можете отличить макрос от функции, пусть даже макрос гигиенический. Хотя их почти везде можно взаимозаменяемо использовать.
Шаблоны плюсов и макросы это абсолютно разные вещи.
Макросы си работают тупо на уровне текста, макросы раста на уровне AST, а шаблоны плюсов на уровне типов.
Например, std::optional<T> это полноценный тип. А вот my_macro!(T) это новый кусок кода который нельзя вставить никуда кроме корня файла.
Как соотносятся дженерики раста и шаблоны плюсов я ответить не могу. Пока внятных объяснений от местных теоретиков я тоже не видел :)
Макросы си
А я не про макросы в Си. Я про макросы в расте. Которые куда ближе к шаблонам, нежели что-то другое.
std::optional<T>Не знаю глубоко плюсов, но насколько я знаю, шаблоны это шаблоны, а не типы, они даже не чекаются если вы их не инстанцировали, а если инстанцировали то проверяется уже результат раскрытия, а не что-то другое. Это сильно отличается от понятия "типа".
насколько я знаю, шаблоны это шаблоны, а не типы, они даже не чекаются если вы их не инстанцировалиЧекаются-чекаются. Вот, например.
А вот так — уже нет.
а если инстанцировали то проверяется уже результат раскрытия, а не что-то другоеТаки чекается «что-то другое»: шаблоны могут в несколько этапов раскрываться и на каждом этапе чекается то, что не зависит от реализации шаблона. Собственно идея концептов (полноценных, который должны были быть в C++11, а не та версия, которая дожила до C++20) была как раз в том, чтобы они могли чекаться вообще на этапе объявления. Стали бы они в этом случае «полноценными типами» в вашем мире или нет?
В Haskell подобная конструкция называется полиморфными типами… и если честно, большой разницы я не вижу: точно также всё чекается когда вы вот это вот пытетесь из функции, оперирующей «неполиморфными» типами проверяется…
Typeable — это способ получать в рантайме информацию о типах, а полиморфизм генериков не имеет ничего общего с шаблонами. Вот сводная табличка от майкрософта: https://docs.microsoft.com/en-us/cpp/extensions/generics-and-templates-visual-cpp?view=vs-2019
И хотя она касается сишарпа, параметрический полиморфизм в хаскелле работает так же, пусть и чуть-чуть богаче с rank-2, type family, undecidable instances и прочими приколами.
Я тоже не специалист, но у меня есть ощущение что темплейты это такие тайплевел функции только на (условно) js, т.е. чекаются во время вызова (инстанциирования).
Хороший пример — метапрограммирование в C++. Появилось оно ещё в C++98 (причём оно в язык было не добавлено, а открыто… во время стандартизации этому уже внимание чуть-чуть уделили), однако «простые смертные» могут им пользоваться только начиная с C++17
Ну, не знаю… Я вот себя не считаю «небожителем», и с даже специалистом по C++, но вот template'ы и использовал, и свои писал ещё задолго до 2017 года.
Скорее всего тут дело в том, что это «метапрограммирование» в C++98 имело своего предшественника ещё в C — директиву препроцессора #define с параметрами. Которую мне тоже пришлось в свое время освоить, потому как использовалась она очень широко. Ну, а с template уже хотя бы некоторые вещи можно было делать по аналогии. Но некоторые другие (типа классов-функторов для STL) — таки да, пришлось осваивать.
Ну, а ещё эта аналогия и приобретенные ранее привычки очень помогали искать ошибки, которых тогда было в количестве — ибо в старых стандартах дозволялись многие вещи, которые потом, после разворачивания шалона, не компилировались с малопонятными ошибками.
Да, другие. В safe Rust внутри функции с такой сигнатурой у вас нет ни одной возможности получить валидное значение типа T кроме переданного x.
fn add<T: Add>(x: T, y: T) -> TА почему мы не можем создать и вернуть пустой Т, нужен DefaultConstructible трейт?
Да, если для T не задано констрейнтов мы ничего не можем сделать. Для создания пустого нужен констрейнт T : Default, всё верно. Для того чтобы вернуть значение полученное из какой-нибудь захардкоженной числовой константы понадобится констрейнт, ну и так далее.
T : From<i32>
Любой необходимый функции функционал (сори за каламбур) обязан быть объявлен в сигнатуре. Именно поэтому она даёт столько пищи для размышлений и в куче случаев является исчерпывающей информацией о том, что это за функция и как её использовать, не глядя в тело.
Именно поэтому она даёт столько пищи для размышлений
Хорошо, допустим у меня есть функции lower_bound и upper_bound — у них требования на Т одинаковые (наличие оператора< и… всё?). Да, исходя из того, что требуемый контейнер/рэнж должен быть RandomAccess, я могу по сигнатуре догадаться что это бинарный поиск, но какой из двух? Или я уже придираюсь и хочу слишком много?
Просто мне абстрактно кажется, что есть достаточно большой класс функций с одинаковыми требованиями на Т/U где не заглянув в код/не посмотрев имя функции (а там doWork или ProcessValues), нельзя догадаться о том, что функция делает.
В реальности, по имени функции и сигнатуре часто можно увидеть полезные вещи:
Может вернуть нулл (нужно проверять всегда результат)
Может вернуть ошибку (нужно обрабатывать такую возможность)
Может ходить по сети (тогда нужно подумать, прежде чем такую функцию запускать в цикле)
Может писать в БД (тогда нужно подумать, как прокинуть контекст соединения чтобы всё эффективно работало)
Ну и так далее.
Что до примера, то я не очень понял. Возьмем хаскель, там есть тайпкласс Bounded который задаёт две функции minBound/maxBound
Если я увижу функцию вида
doWork : (Bounded a, Ord a) => Vector a -> Vector aТо мне в принципе очевидно, что происходит сортировка какого-то вида. Какого — не знаю, если мне нужно узнать точнее то надо уже идти смотреть тело. Но например в расте если я увижу такую функцию (и мы уберём bounded), я буду точно знать, что если я передал например функцию с уникальными элементами, то в результе будут тоже только уникальные элементы, и если мне например важно чтобы элементы не повторялись то я знаю что мне не нужно повторно валидировать результат.
Может вернуть нулл (нужно проверять всегда результат)
В С# для этого добавили Nullable References.
Может вернуть ошибку (нужно обрабатывать такую возможность)
В Jave поддрживается и надеюсь что рано или поздно добавят и в C#. А пока да, при необходимости приходится полагаться на всякие exception reflector'ы.
Может ходить по сети (тогда нужно подумать, прежде чем такую функцию запускать в цикле)
Может писать в БД (тогда нужно подумать, как прокинуть контекст соединения чтобы всё эффективно работало)
Это да, «нативно» такое те же C# с Java не поддерживают. Но на мой взгляд для такого есть coding conventions. Они не панацея и «работают» гораздо хуже, но жить можно.
В С# для этого добавили Nullable References.
Которые нормально не работают, но уже лучше, да, шаг в том направлении о котором я говорю
В Jave поддрживается и надеюсь что рано или поздно добавят и в C#. А пока да, при необходимости приходится полагаться на всякие exception reflector'ы.
Ну так оно фигово работает в таком виде. Вот скажите, как мне написать сигнатуру такой функции:
void Foo(Action action) {
action();
}Где Foo бросает ровно те же исключения, что и action? Насколько мне известно, в Java такое записать невозможно.
Это да, «нативно» такое те же C# с Java не поддерживают. Но на мой взгляд для такого есть coding conventions. Они не панацея и «работают» гораздо хуже, но жить можно.
Так так со всем. Нет нулляблов — ну ладно, будем конвенциями не забывать проверять на нулл. Эксепшны? Будем конвеншнами указывать, что где может выброситься (например, в проектах Project.Core/Project.Common могут бросаться только *BusinessException). И так далее.
с миру по нитке, голому — рубаха, в итоге разница суммарно выходит очень и очень существенная. Ну и нет причин, почему нельзя жить лучше, если можно.
А в чём по вашему заключается кривизна работы nullable references?
И да, в куче языков чего-то нет и не хватает. Ну так и Рим не за один день строился.
1 нельзя написать T? FirstOrNull(IEnumerable<T> source), например.
2 По той же причине нельзя написать структуру данных, которая возвращает такую функцию, например, мне нужно было такой интерфейс реализовать:
interface ISettings<T>
{
T? GetSettings();
}3 null propagation не работает в половине случаев: при вызове конструктора, при вызове статических методов
4 ...
короче, список проблем существенный, можно ещё продолжать и продолжать. И если null propagation — ну ладно, мы не гордые, напишем руками. то невозможность такой интерфейс сдеалть очень расстроила.
Вроде для этого приспособили атрибуты:
[return: MaybeNull]
T FirstOrNull(IEnumerable<T> source)Ну так что это, как не костыли? Плюс оно не будет правильно работать. Например, из моих персональных экстеншнов:
public static IEnumerable<T> WhereNotNull<T>(this IEnumerable<T?> source) where T : class =>
source.Where(x => x is {})!;
public static IEnumerable<T> WhereNotNull<T>(this IEnumerable<T?> source) where T : struct =>
source.Where(x => x is {}).Select(x => x.GetValueOrDefault());Тут даже реализация отличается, не получится атрибутом это выразить. Ну или делать if typeof(..) { .. }
Ну так что это, как не костыли?
Не совсем костыли. Под капотом оно все равно в атрибуты разворачивается.
Тут даже реализация отличается, не получится атрибутом это выразить. Ну или делать if typeof(..) {… }
Увы, дженерики C# для такого не предназначены. Вам надо в C++ лезть.
Конечно, есть костыль, который позволяет делать перегрузку для случаев, когда аргумент — class и когда — struct, но я не рекомендую им пользоваться.
Если сравнение с шаблонами то вот простой пример:
public static class C
{
public static void DoIt<T>(T t)
{
ReallyDoIt(t);
}
private static void ReallyDoIt(string s)
{
System.Console.WriteLine("string");
}
private static void ReallyDoIt<T>(T t)
{
System.Console.WriteLine("everything else");
}
}Вызов C.DoIt("Hello") выведет "everything else" в сишарпе и "string" если это переписать на плюсовые шаблоны
Но я имел в виду то, что в сишарпе есть хак для того чтобы ломать параметричность:
void Foo<T>()
{
if (typeof(T) == typeof(int)) {
Console.WriteLine("AZAZAZA");
}
else {
Console.WriteLine("Some generic code");
}
}Это ломает многие представления о том, что может делать функция — по сигнатуре никогда не узнаешь, не лезет ли функция в метаданные типа.
IoC это когда реализация зависит от абстракции, и тело метода зависящее от сигнатуры тут полностью подходит. Да, это простой случай, но — случай.
— вся инфа передается через сигнатуру
— вся инфа передается через контекст и новый граф объектов собирается перед каждым вызовом метода
И то и другое в общем случае ведет к несопровождаемым системам, поэтому задача программиста тут — выбрать такую сигнатуру, которая будет принимать минимальный набор параметров, дающий и итоге клиентский код, легко поддающийся сопровождению. Во многих случаях такое решение принять легко, например я не видел случаев чтобы люди из бизнес логики в DAO передавали коннекшн до БД аргументом метода) Во многих других сложно. В общем апишка должна быть настолько абстрактной, насколько это возможно, но не более того. Проблема в том, что так умеют с первого раза только эльфы, но мы ведь сейчас про теорию)
Если вы этот код дописываете, то вы по идее видите что делает каждый метод.То есть я правильно понимаю, что «для упрощения» мне предлагается разбить огромную функцию на 500 строк на 200 функций по 5-10 строк и потом, когда я хочу вот это вот править, я должен изучать уже не 500 строк, а 1500 строк?
Это точно называется «упрощение»? По моему это карго-культ называется.
Мне кажется люди, которые занимаются вот этот творческой нарезкой лапши забывают принцип, который хорошо сформулировал Эйнштейн: Делай так просто, как возможно, но не проще этого.
Ибо эта вот «лапша» — это явное создание чего-то, что проще, чем это возможно. Если метод в 50, 100 или даже 500 строк не удаётся разбить на два метода, которые могут читаться и правиться совершенно независимо друг от друга… то его не нужно разбивать вообще!
Хотя в последнем случае, когда речь идёт о 500 строк, обычно удаётся выделить самостоятельные компоненты… но это не делается созданием десяти методов
do_⅕_of_work, do_⅖_of_work и так далее.Но на мой взгляд редко какую функцию на 500 строк нельзя разбить на отдельные функции влезающие на экран монитора так чтобы читаемость при этом не повысилась.
И у Мартина как раз и описывается как это стоило бы делать чтобы читаемость повышалась. И да он местами перегибает палку, но идея вполне понятна.
И да он местами перегибает палку, но идея вполне понятна.Нет. Идея нифига непонятно. Ибо цель — не получить текст, который приятно читать, а текст, который легко менять!
Потому что следующим действием за шинковкой кода в лапшу следует его обмазывание большим-большим количеством юниттестов.
Ребяяяты! Если вам, для того, чтобы понять — правильно вы поняли, что делает код или нет недосточно самого этого кода… то вы утратили его понимание, извините.
Оно теперь у вас сосредоточено в тестах, а не в голове разработчика.
И да, так иногда приходится-таки поступать… но это ни разу не то, к чему стоит стремиться…
Но на мой взгляд редко какую функцию на 500 строк нельзя разбить на отдельные функции влезающие на экран монитора так чтобы читаемость при этом не повысилась.Зависит от монитора. Некоторые функции в 100 строк уже сложно делить. Но функции в 2-3 строки — это почти всегда профанация. Они очень редко имеют смысл сами по себе, то есть это либо требование языка (скажем какая-нибудь функция
operator+ — это почти всего несамостоятельные 2-3 строки кода), либо часть группы функций… а тогда и не нужно считать что длина этой функции — 2-3 строки.Вообще не слишком полезно оперировать «длиной функции», скорее полезно выделать «неделимый блок кода», который нужно прочитать чтобы понять что функция делает.
Скажем в Haskell функции обычно структурированы реально как 1-2-3 строки… но при этом то, что я уподобил бы аналогу функции в обычных языках — это группа тесно связанных между собой функций, которые не имеют документации (то если не предназначены для самостоятельного использования).
Ребяяяты! Если вам, для того, чтобы понять — правильно вы поняли, что делает код или нет недосточно самого этого кода… то вы утратили его понимание, извините.
Оно теперь у вас сосредоточено в тестах, а не в голове разработчика.
Это как раз правильно, если только не заниматься Job security.
Другое дело, что при таком подходе тесты тоже становятся загадочными, и вот это уже плохо.
Нет. Идея нифига непонятно. Ибо цель — не получить текст, который приятно читать, а текст, который легко менять!
Цель получить и то и другое. И когда у вас вместо одной огромной функции несколько небольших, то и менять их проще. Грубо говоря если вы ваш метод на 500 строк разобьёте на 25 методов, то 20 строк, то какова вероятность что вам придётся фиксить все 25 методов при каком-то минорном багфиксе? По моему опыту она стрeмится к нулю. Обычно придётся пофиксить 1-2 метода. Ну может 3-4. Ну максимум половину.
Более того каждый метод можно отдать фиксить отдельному человеку и потом не будет особых проблем всё это замерджить обратно. А вот если у вас пяток человек паралелльно должны фиксить какой-то метод в несколько тысяч строк, то я могу только посочувствовать тому, кто это потом будет вместе мерджить…
Потому что следующим действием за шинковкой кода в лапшу следует его обмазывание большим-большим количеством юниттестов.
Если вам что-то мешает использоватъ юнит-тесты, то и не надо этого делать. Но если вы их используете, то да, маленькие методы тестировать проще чем один большой.
Зависит от монитора.
Конечно зависит. Но где бы я не работал обычно у людей мониторы были более-менее одинаковые и именно с этим пунктом ни разу проблем не возникало.
Некоторые функции в 100 строк уже сложно делить. Но функции в 2-3 строки — это почти всегда профанация.
Не надо пытаться всё обязaтельно разбить на функции по 2-3 строки. Но если у вас есть кусок кода, который можно вынести в отдельную функцию на 2-3 строки и ваша основная функция непомерно разрослась, то почему бы и не вынести?
Вообще не слишком полезно оперировать «длиной функции», скорее полезно выделать «неделимый блок кода», который нужно прочитать чтобы понять что функция делает.
Естественно. И я пока ни разу не встречал «неделимый блок кода» длинной в 500 строк. И даже длинной в 100 строк не могу припомнить.
А как вы это будете делать в ФП? Особенно интересует обращение к isSuite :-)
Методы в ООП взаимодействуют с состоянием объекта. Когда методы перестают это делать, а состояние начинает проталкиваться через аргументы, то код превращается в обычное процедурное программирование. Разве не так?
Так, только Мартин работает не с состоянием, а со скрытыми аргументами. Допустим, я меняю класс PrimeGenerator и вызываю checkOddNumbersForSubsequentPrimes. И тут у меня всё падает, потому что, оказывается, я должен был проинициализировать (статические!) поля primes и multiplesOfPrimeFactors, причём проинициализировать их в два этапа: присвоить каждому новый экземпляр соответствующего класса и вызвать set2AsFirstPrime. Если бы я написал точно такой код в процедурном языке, например, на C, то коллеги быстро объяснили бы мне, что это полнейшее безобразие. Но если перед этим безобразием написать слово class, то оно магически превращается в "чистый код" Мартина.
Мне как-то достался такой класс, где параметры были убраны в поля. Судя по истории, изначально он был вполне компактным, но, конечно же, со временем и сам класс, и его методы разрослись, и понять что откуда берётся и где оно поменяется в следующий раз было очень сложно. Да, в том коде было много других проблем, но изменяющиеся поля вместо явных аргументов делали всё только хуже.
Может возникнуть вопрос, а как отличить состояние от скрытых аргументов? По моему мнению, состояние, во-первых, влияет на дальнейшее поведение объекта, а не только на текущий вызов, во-вторых, зависит от предыдущего состояния, в-третьих, объект переходит из одного корректного состояния в другое корректное состояние, то есть состояние полностью инициализируется в конструкторе и публичный интерфейс объекта не допускает частичной смены состояния. Если состояние не ломается при возникновении ошибок (т.е. выполняются гарантии исключений) и состояние меняется атомарно, то вообще хорошо. Скрытые аргументы наоборот, влияют только на один конкретный вызов публичного метода (ну или некой правильной последовательности вызовов), зависят только от аргументов этого вызова, а в остальное время содержат мусор.
. И тут у меня всё падает, потому что, оказывается, я должен был проинициализировать (статические!) поля primes и multiplesOfPrimeFactors,
Ну так сделайте не статический класс у которого все конструкторы требуют этих аргументов. В чём проблема то?
Если бы я написал точно такой код в процедурном языке, например, на C, то коллеги быстро объяснили бы мне, что это полнейшее безобразие.
Вам и в ООП языке коллеги очень быстро объяснят что так делать ну совсем не надо. Хотя это конечно в обоих случаях от коллег зависит.
Слабо, имхо вы спорите про идеальный код, забывая, что код должен ещё и решать какую-то задачу. И в контексте задачи код Фаулера выглядит аккуратным и лаконичным. Может не идеальна по всем его критериям, но и код не должен быть идеальным, мфаулер это понимает, вы — нет.
Одно из лучших качеств хорошего программиста — разбираться в чужом коде и понимать подход его автора. Кидаться на первую же строку кода и кричать что все криво написано — это борьба с ветряными мельницами.
Р.Мартина не читал, но осуждаю (после всего вышепрочитанного)!
А что касается книг, до Фаулера пока не дошел, но Макконел с его «Совершенный код» мне зашел отлично, на порядки лучше чем «Чистый код».
Все эти книги пишуться для ознакомления, и совершенно не важно их читать а потом заниматься миссионерством и поисками серебрянной пули.
А вот уметь понимать чужой код и спокойно объяснять ошибки (а если бы автор так сделал, то осталось бы только короткое замечание про isSuite, который действительно бы следовало передавать как параметр)
Так что в основном книга походу хорошая, а все прдхявы автора чистая вкусовшина.
А, это еще и перевод, тогда понятно, хэштега #blm не хватает только)
Ну да, ну да… Пошёл он нафиг, Чистый код...
Почему автор не привёл свой вариант рефакторинга всех этих классов?
Давайте относиться с уважением к хорошим книжкам, которые не являются истиной в последней инстанции. Но задают неплохие принципы кодирования в достаточно простой форме.
Примеры в статье вырваны из контекста. Например SetupTeardownIncluder — это не идеал. Где Мартин сказал, что это супер классный кусок кода? Это результат рефакторинга, через разбиение толстых методов на маленькие. Который приводится, чтобы объяснить, что маленькие функции — это очень важно. Даже если не применять другие принципы из книги вовсе.
И вот мне интересно, какой процент из голосовавших читал эту книжку, и может сказать, что она являлась бесполезной тратой времени?
Что вообще вы ожидаете от книги? Волшебный секрет «Тайны драконы», который прибавит 200К к ЗП?
Я считаю, подобного рода статьи без весомых альтернатив, не больше чем оправданием школьника, который не стал учить физику, потому что «в жизни не пригодится». Но давайте поплюсуем за очередной холивар до 100?
(Рискую кармой, а не головой.)
Почему автор не привёл свой вариант рефакторинга всех этих классов?
Мне кажется, что автор объяснил это здесь:
Это рефакторинг уже существующего фрагмента кода, который, по-видимому, изначально не был написан им. Этот код уже имел сомнительный API и сомнительное поведение, оба из которых сохраняются в рефакторинге.
В итоге же автор признал, что, вероятно, Мартин сделал всё, что мог с кодом, но довести до идеала было невозможно.
Хотя теперь непонятно зачем вообще такой пример был нужен.
Согласен. Чистый код и многие другие публикации Мартина отличное чтиво! Читал и перечитывал несколько раз.
Почему автор не привёл свой вариант рефакторинга всех этих классов?
Ну на мой взгляд стоило бы:
- убрать все приватные члены класса: по их использованию понятно, что тут нужна просто функция
- заинлайнить все приватные функции кроме includeSetupAndTeardownPages и тех что используются в ней напрямую
- а ещё лучше было бы вместо
void Render()сделатьRenderResult Render(), где Render — чистая функция, которая просто возвращает RenderResult, и второй компонент который будет превращать RenderResult в действие с минимальным количеством усилий. Потому что тут как раз нурашется SRP: класс одновременно решает и какие данные отрисовывтаь, и как. Разбить это на два этапа: формирование данных которые отрисовываем и рендерер, в котором нет никакой логики сложнее "отрисовываю то что мне дают" — было бы куда лучше, нет?
Про PrimeGenerator молчу — код ужасен. Хороший мысленный эксперимент, который это показывает — а как оно будет работать в многопоточной среде? Правильно, всё развалится, причем нет никаких причин, почему нужно инициализировать primes/multiplesOfPrimeFactors. Лишнее действие, которое только ухудшает код.
Я далеко не эксперт и конечно никогда книжек не писал, но мне кажется это вполне разумные предложения, которые код в разы бы улучшили. Ну то есть хотя бы вот так:
class PrimeGenerator {
private final int[] primes;
private final ArrayList<Integer> multiplesOfPrimeFactors;
private PrimeGenerator(int n) {
primes = new int[n];
multiplesOfPrimeFactors = new ArrayList<Integer>();
}
protected static int[] generate(int n) {
var generator = new PrimeGenerator(n);
generator.set2AsFirstPrime();
generator.checkOddNumbersForSubsequentPrimes();
return generator.primes;
}
private void set2AsFirstPrime() {
primes[0] = 2;
multiplesOfPrimeFactors.add(2);
}
private void checkOddNumbersForSubsequentPrimes() {
int primeIndex = 1;
for (int candidate = 3;
primeIndex < primes.length;
candidate += 2) {
if (isPrime(candidate))
primes[primeIndex++] = candidate;
}
}
private boolean isPrime(int candidate) {
if (isLeastRelevantMultipleOfNextLargerPrimeFactor(candidate)) {
multiplesOfPrimeFactors.add(candidate);
return false;
}
return isNotMultipleOfAnyPreviousPrimeFactor(candidate);
}
private boolean
isLeastRelevantMultipleOfNextLargerPrimeFactor(int candidate) {
int nextLargerPrimeFactor = primes[multiplesOfPrimeFactors.size()];
int leastRelevantMultiple = nextLargerPrimeFactor * nextLargerPrimeFactor;
return candidate == leastRelevantMultiple;
}
private boolean
isNotMultipleOfAnyPreviousPrimeFactor(int candidate) {
for (int n = 1; n < multiplesOfPrimeFactors.size(); n++) {
if (isMultipleOfNthPrimeFactor(candidate, n))
return false;
}
return true;
}
private boolean
isMultipleOfNthPrimeFactor(int candidate, int n) {
return
candidate == smallestOddNthMultipleNotLessThanCandidate(candidate, n);
}
private int
smallestOddNthMultipleNotLessThanCandidate(int candidate, int n) {
int multiple = multiplesOfPrimeFactors.get(n);
while (multiple < candidate)
multiple += 2 * primes[n];
multiplesOfPrimeFactors.set(n, multiple);
return multiple;
}
}А приватные мутабельные статик переменные в книжке по чистому коду это… Очень сильно.
Дальше уже вопросы по тому, почему такой простой алгоритм занимает под сотню строк кода, но это уже оставим на откуп автору
private static boolean isNotMultipleOfAnyPreviousPrimeFactor(int candidate) {
for (int n = 1; n < multiplesOfPrimeFactors.size(); n++) {
if (isMultipleOfNthPrimeFactor(candidate, n))
return false;
}
return true;
}Выглядит будто эта штука принимает candidate лишь для того, чтобы протолкнуть дальше в isMultipleOfNthPrimeFactor.
Если (а точнее — когда) бизнес выкатит новое требование для isMultipleOfNthPrimeFactor, и кроме (candidate, n) у него появится еще несколько параметров (от фазы луны, левой пятки бешеного принтера, системы скидок на ближайшие выходные), то такое решение придется переписывать по цепочке. Частным случаем этой проблемы является props drilling. В классическом ООП такие параметры станут не аргументами методов, а свойствами объекта, а значит изменений в коде будет на порядок меньше.
На самом деле, мне кажется если все это написать в одну функцию и упростить, то и места в 2 раза меньше займет, и понятней станет. Потому что вот это:
private boolean
isLeastRelevantMultipleOfNextLargerPrimeFactor(int candidate) {
int nextLargerPrimeFactor = primes[multiplesOfPrimeFactors.size()];
int leastRelevantMultiple = nextLargerPrimeFactor * nextLargerPrimeFactor;
return candidate == leastRelevantMultiple;
}Это прям как из известного комикса "Это мост"
{kind=link}

Просто я решил обойтись минимумом изменений — буквально 2 строчки кода, но теперь тут нет глобального мутабельного стейта и в целом стало получше
Я абсолютно не одобряю этого якобы гуру который писал изначальный код.
Мне напоминает ту ситуацию, что чтобы сложить два числа на джаве нужно минимум пять интрефейсов и три фабрики.
На самом деле всё даже хуже. Куча функций которые имеют в назавнии просто какую-то проверку (например isPrime) на самом деле мутируют внутреннее состояние.
А наЧетвёртомУровнеСтэкаФункций алгоритма мы узнаем что он состоит из двух вложенных циклов (если я правильно понял в итоге).
Весь абсурд в том что алгоритм Эратосфена (ты ли это?) это один цельный алгоритм в котором все взаимосвязано по сути алгоритма. Вместо дробления на части надо во-первых сделать отслыку к литературе в комментариях, во-вторых добавить комментарии которые объясняют почему тот или иной шаг вообще имеет смысл.
Cам алгоритм полагается на то что все его шаги выполняются последовательно внутри цикла, где n всё время увеличивается. Т.е. все эти методы по отдельности смысла не несут, потому что их нельзя вызвать когда захочется. Таким образом код усложняется в разы, т.к. мне надо хранить в голове условие на внутренее состояние. Получается что в отличии от нормального подхода, где внутреннее состояние я узнаю строчкой выше — теперь мне надо искать место вызова функции.
Имеем: функция имеет на входе семь аргументов string (да, их можно сбить в одну структуру, но зачем? они хранятся текстом в разных полях таблицы), выдаёт один integer. Длина функции — те самые 2-3 тысячи строк, учитывая автоисправление обнаруженных ошибок, неизбежных записей данных не в те поля (например город может располагаться внутри города — в этом случае один из них попадёт в поле другого назначения), встроенные в код автодополнения (не нашли проспект Гагарина — начинаем искать проспект Юрия Гагарина и т.д.).
Как этой функции сделать три аргумента если их семь? Как её сжать с двух тысяч строк до десяти? И зачем?
Действительно, странные советы.
функция имеет на входе семь аргументов string (да, их можно сбить в одну структуру, но зачем? они хранятся текстом в разных полях таблицы)
Например затем, что есть риск перепутать порядок аргументов.
Как её сжать с двух тысяч строк до десяти? И зачем?
Выделить подпрограммы же. Валидация, поиск, автодополнение...
Зачем? Например, чтобы код легче читался, и чтобы проще было тестировать.
Их же все равно не станет два. Вам все равно ничто не помешает сделать addr.street = city, и компилятор такое слопает. Ну и что что структура — внутри-то все равно можно перепутать.
Если они все строки — то реально перепутать будет нельзя только если завести семь отдельных алиасов для типа строка — по одному на каждый тип поля. И хранить city в типе данных city. Это можно — только вот знаете, я ни разу не видел, чтобы кто-то так реально упоролся, и завел типы для улицы, типа улицы, города, района и пр — и чтобы все они строковые. Видимо практической пользы от такого меньше, чем вреда от перепутывания.
На самом деле, это процедура в Sybase. Все данные передаются по именам параметров. То есть если например адрес без улицы, то параметр Street просто в списке параметров можно не писать. Некоторые языки программирования позволяют так делать. Так что перепутать сложно, если конечно не передавать параметры без имён через запятую.
Все данные передаются по именам параметров.
Да, это уже хорошо.
Если бы этот код был написан на какой-нибудь java, он мог бы выглядеть как someObj.someMethod(street, houseNumber, region, city), а сигнатура могла бы внезапно иметь другой порядок аргументов city, region. На Java именованной передачи параметров нет, поэтому ошибка была бы менее очевидна.
То есть если вы в куче мест должны передавать несколько параметров по одиночке, то вероятность что-то перепутать выше чем когда вы один раз заполнили dto-шку и потом передаёте уже только её.
Плюс вам никто не запрещает всё-таки и использовать отдельные классы/типы вместо простых строк. Это не всегда оправданно, но иногда всё таки имеет смысл. И как раз таки с «составляющими» адреса это делается достаточно чвсто.
И естественно прежде чем что-то делать лучше сначала подумать головой, а не просто бездумно следовать каким-то советам из какой-то книжки. Но я бы сказал что по моему опыту всё-таки методы на несколько тысяч строк и/или с кучей параметров обычно создают больше проблем чем небольшие методы с dto-шками.
Я заводил отдельные типы, образно говоря, для всяких индексов рук и индексов пальцев. Получалось годно.
я ни разу не видел, чтобы кто-то так реально упоролся, и завел типы для улицы, типа улицы, города, района и пр — и чтобы все они строковые.
Я как раз в TypeScript делал брендированые типы для HexString, Base64String, Base64UrlString и т.п. — чтобы случайно не забыть сконвертировать при передаче в функции. Если бы делал модуль для работы с персональными данными (имена, адреса, телефоны, емейлы, почтовые индексы, и кучу других строковых типов), то скорее всего сделал бы так же.
Ошибка была как раз в том, что переменные назывались похоже и из-за копипасты два раза обрабатывали один и тот же файл.
Приемочный (acceptance) тест прошел бы это толко в одном случае: в кейсе теста файлы должны быть одинаковы. В противном случае — у вас что-то с тестами не так.
Но если у вас перепутанные аргументы не скомпилируется вы же это заметите?
Ну, если программист фигово написал, с этим конечно ничего не поделать.
Есть хорошая практика делать ньютайпы, по крайней мере в тех языках которые это разрешают:
fn foo(first_document: Document, second_document: Document) {
}vs
struct FirstDocument(Document);
struct SecondDocument(Document);
fn foo(first_document: FirstDocument, second_document: SecondDocument) {
}И тут уже не получится просто так перепутать, и передать одно вместо другого. Возможно, кажется, что это бесполезная обертка, но весьма помогает. Я так оборачивал Latitude(f64)/Longitude(f64), и спасло не раз.
Ну, я предполагал, что етсь такие понятия, как первый и второй документ, а не то что это просто порядок.
Но прям все баги типами находить дорого, так что так не делают на практике.
А мне кажется, что Latitude/Longitude — такое же глупое разделение как и FirstDocument/SecondDocument. Тип у обоих одинаковый, это угловая координата. Ну да, у них разные диапазоны, но чтобы из того извлечь какую-то выгоду в плане корректности программы — нужны завтипы.
Единственный момент где разделение Latitude/Longitude поможет на уровне типов — это передача аргументов из функции в функцию в цепочке. Но в таком случае куда проще сделать составной тип GeoPoint и таскать всюду одно значение вместо двух.
Тип у обоих одинаковый, это угловая координата.Это неважно. Вы делаете ту же ошибку, что и многие сторонники ООП: исходите из подхода «мы описываем в программе наш мир». Это — неправильный подход. Если переменные даже одного типа у вас не должны «путаться» — то полезно рассматривать их как разные типы. Например координаты X и Y в какой-нибудь программе вёрстки.
Если же типы у вас, объективно, разные, но, при этом, смешиваются — то это один тип. Например координаты точки могут задаваться как X,Y и как α,D. Там размерности как раз разные, но типы — одинаковые (подтипы, конечно, разные).
Ну да, у них разные диапазоны, но чтобы из того извлечь какую-то выгоду в плане корректности программы — нужны завтипы.Ничего не нужно. Типы-диапазоны были ещё в PL/I. И даже если вы не можете вставить проверку диапазонов (язык не позволяет или компилятор этого не реализуется) — всё равно лучше, чтобы это были разные типы: если у вас две библиотеки, одна из которых принимает широту/долготу, а другая — долготу/широту (вроде такая разницы была в API Google Maps и Yandex Maps), то разные типы вас спасут от кучи ошибок — и завтипы для этого совершенно не нужны.
Но в таком случае куда проще сделать составной тип GeoPoint и таскать всюду одно значение вместо двух.Это полезная оптимизация, но она ортогональна к типам «долгота» и «широта». Для определения длины светового дня, скажем, вам нужна широта (и время года, конечно) — и вам всё равно нужно будет из GeoPoint вытащить именно её, а не долготу.
Все перечисленное вами работает только в том случае, когда нет необходимости постоянно приводить или преобразовывать типы туда-сюда. Потому что в момент преобразования типа компилятор уже не "поймает" нас за руку, если мы приведём не тот тип или не к тому типу.
Координаты X и Y действительно можно разделить по типам, потому что с ними можно сделать кучу интересных вещей с сохранением этого признака: их можно сложить, вычесть, умножить и поделить на скаляр, и при этом результат останется координатой относительно той же оси.
А вот для широты и долготы это не работает: разность или сумма двух широт смысла не имеет и широтой не является. Их можно только преобразовывать в число либо строку и обратно, а также передавать из функции в функцию по цепочке. Преобразованиям типы не помогают, а передачу по цепочке полностью берет на себя GeoPoint.
Это полезная оптимизация, но она ортогональна к типам «долгота» и «широта». Для определения длины светового дня, скажем, вам нужна широта (и время года, конечно) — и вам всё равно нужно будет из GeoPoint вытащить именно её, а не долготу.
Можно сделать перегрузку, которая принимает GeoPoint и вытаскивает оттуда широту.
А вот для широты и долготы это не работаетРаботает отлично.
Разность или сумма двух широт смысла не имеет и широтой не является.Да, это ещё пара типов. И вот уже в этом случае — всё будет хорошо. Широта и долгота тут похожи на температуру. Или время. Где есть time_point и duration.
Их можно только преобразовывать в число либо строку и обратно, а также передавать из функции в функцию по цепочке.В каком месте вы преобразуете число в строку и обратно, проверяя — находится ли объект за полярным кругом?
То, что вы не можете себе предствить никаких других операций с широтой и долготой, кроме как передачи их в функцию и из функции — обозначает, всего-навсего, что вы никогда не разрабатывали никаких картографических алгоритмов.
Можно сделать перегрузку, которая принимает GeoPoint и вытаскивает оттуда широту.Ну да. После чего перепутать её с перегрузкой, которая вытаскивает оттуда долготу.
Да, если ваша программа никаких вычислений с широтой и долготой не осуществляет — то GeoPoint будет достаточно. Но внутри каких-нибудь Super Maps (будещего убийцы Google Maps и Yandex Maps) — это, несомненно, два отличных типа.
Координаты X и Y действительно можно разделить по типам, потому что с ними можно сделать кучу интересных вещей с сохранением этого признака: их можно сложить, вычесть, умножить и поделить на скаляр, и при этом результат останется координатой относительно той же оси.Это уже ни в какие ворота не лезет. В чём вообще отличие координат X и Y от широты и долготы? На малых масштабах они чётко пересчитываются друг в друга. морская миля — не забыли как определяется?
Да, это ещё пара типов. И вот уже в этом случае — всё будет хорошо.
Неа, не будет. Разве что на тех самых малых масштабах, на которых можно творить любую дичь и надеяться что никто не заметит.
В каком месте вы преобразуете число в строку и обратно, проверяя — находится ли объект за полярным кругом?
Конкретно в данном случае надо преобразовать в число.
Ну да. После чего перепутать её с перегрузкой, которая вытаскивает оттуда долготу.
Простите, а откуда вообще возьмется перегрузка функции определения длины светового дня, которая вытаскивает долготу, чтобы с ней можно было что-то перепутать?
Это уже ни в какие ворота не лезет. В чём вообще отличие координат X и Y от широты и долготы? На малых масштабах они чётко пересчитываются друг в друга
Ага, а потом на больших программа что-то глючить начинает...
Разве что на тех самых малых масштабах, на которых можно творить любую дичь и надеяться что никто не заметит.В тех же самых масштабах в которых в полиграции можно отделять координаты X и Y.
Простите, а откуда вообще возьмется перегрузка функции определения длины светового дня, которая вытаскивает долготу, чтобы с ней можно было что-то перепутать?Что значит «откуда возьмётся»? Из какой-нибудь астрономической библиотеки. И она широту ниоткуда вытаскивать не будет, разуеется: для определения длины светового дня только она и нужна.
Вот только поскольку вы решили смешать в кучу широту и долготу — то она может принимать и долготу тоже.
Вообще в картографических программах перепутать при вызове функции широту и долготу — любимое развлечение. И нет — они далеко не везде ходят парами. Как бы вам этого не хотелось.
Если же, наоборот, вы начали путать переменные одного типа и хотите разделить этот тип на два — то их «расщепление» — это сложная творческая работа.
Вывод: чтобы получить качественный результат лучше вначале завести столько типов, сколько вы сможете, а потом, когда выяснится, с неизбежностью, что вы, всё-таки, «мельчите»… кой-какие из них убрать.
Можно это закостылить (тот же C++) через псевдоаргументы — переменные, но это будет выглядеть явным насилием.
Ну и проверку типа они всё равно не дадут без имён переменных. Если у вас переменные все названы как cartesianStart или polarStart, вы увидите разницу. А если просто start, присвоение в одном месте, а передача в функцию в другом, и между ними хотя бы два экрана? Будете вспоминать дядю Боба с «функции не больше 10 строк» и доказывать это всем начиная с математиков и физиков?
Вариант с разными типами всё-таки проще и его явно легче продвигать.
Нужны языки хотя бы начала 90х а не 80х в которых можно легко завести новый тип данных.А причём тут года? В Pascal в 1970м это уже было возможно, а в каком-нибудь JavaScript, созданном в 90е — нет. Так что речь не о годах…
Вот прям в оригинальном паскале, Вы точно не про ObjectPascal?
Вот прям в оригинальном паскале, Вы точно не про ObjectPascal?В самом оригинальном, оригинальнее некуда. В Ада это расширили. Это, правда, уже не 1970й год, а аж 1983й… но всё равно. Кстати может и в Modula-2 уже было как в Ada, я просто с Modula-2 никогда не сталкивался практически, только в книжках читал… То, что умел Pascal полвека назад C++ научили в C++11, то что в Ada сделали — так и до сих пор нету…
Очевидно что к языкам с динамической типизацией это не применимо.Ну почему же неприменимо-то? В Python вы можете свои типы данных создавать. Вот, например. А в JavaScript — нельзя. Вроде как и до сих пор нельзя.
Длина функции — те самые 2-3 тысячи строк
Хм, а как вы эту вашу «функцию в 2-3 тысячи строк» тестите? Ведь при таком раскладе если вы где-то в одной строчке поменяли что-то, то вам по хорошему всю функцию целиком тестить надо. Или вы не тестите?
Как этой функции сделать три аргумента если их семь?
Делаете банальные dto-шки. В вашем случае я бы сказал что улица, город, номер дома, почтовый индекс и подобное великолепно «пакуются» в какой-нибудь объект типа «адрес».
Как её сжать с двух тысяч строк до десяти?
Её надо не сжимать, а разбить на н-ное количество более мелких функций. И десять там строк или не десять, но я бы сказал что если у вас какая-то функция не влезает целиком на экран монитора/в окошко редактора, то что-то пошло не так.
Её надо не сжимать, а разбить на н-ное количество более мелких функций.
Не так просто.
Слой адресов может быть пропущен, или может быть лишний. Пример: 2й Покровский проезд, мкр. Белая Дача, г. Котельники — слой «мкр. Белая Дача» лишний. Может быть задублирован.
Ошибки ввода адреса корректируются с учётом наличия других ошибок более высокого уровня.
Одним словом просто поверьте, что если разбивать код на множество функций, то придётся передавать слишком большое количество аргументов, а скорость важна.
+ Код разрастётся ещё на 50-100%.
Хм, а как вы эту вашу «функцию в 2-3 тысячи строк» тестите? Ведь при таком раскладе если вы где-то в одной строчке поменяли что-то, то вам по хорошему всю функцию целиком тестить надо
А при вашем подходе нет?
Одним словом просто поверьте, что если разбивать код на множество функций, то придётся передавать слишком большое количество аргументов, а скорость важна.
+ Код разрастётся ещё на 50-100%.
Вы знаете, я в своё время тоже думал что разбитие на более мелкие функции сильно ударит по скорости. Даже решил всякие там стресс-тесты поделать. В общем как минимум в С#/Java у меня какой-то особой разницы в скорости не получилось.
Потом я не вижу в чём проблема передачи аргументов если они все грамотно «упакованы» в dto.
Ну и самое главное даже если вдруг код и вырастет на 50-100%, то а чём проблема если он при этом станет более структурированным и читаемым.
А при вашем подходе нет?
При моём подходе в зависимости от изменений. То есть без тестирования не обойтись, но его в среднем будет меньше.
Плюс и код-ревью проще делать когда ты всю изменяемую функцию можешь за раз увидеть и быстро понять что она делает.
Зависит от задачи же. У нас например есть код который от инлайнов пары критических функций выигрывает на 20-30% скорости всего сервиса в целом.
Я бы сказал это не меньше зависит от компилятора да и вообще самого языка в целом.
это понятно, в нашем случае мы раст используем, а не что-нибудь гц-подобное. Но язык языком, а писать правильно тоже надо. А то у нас тут был пример, человек на хаскелле написал программку, переписал на раст и получил замедление в 3 раза. Прибежал в чат рассказывать, какой раст плохой, толку с него — возишься с борровчекером, а он потом медленнее гц.
Так что навык пользования инструмента тоже весьма важен.
При этом код, разумеется, критичный для бизнеса, и поэтому поддерживать его работоспособность (то есть — держать этого работника) является залогом продолжения работы всей организации. В общем, у меня есть теория, что за длинным и запутанным кодом как правило стоит один или несколько сотрудников, которые таким образом просто обеспечивают себе гарантированную работу до пенсии. Потому что при желании — разбить и отрефакторить большую часть можно было бы (с усилиями, но возможно). Просто пока что все усилия сделать это саботируются теми самыми коллегами, а бизнес не видит смысла «переписывать ради переписывания» (что тоже правильно).
Опять же — не во всех языках есть вложенные функции / процедуры. Следовательно, вместо одной из процедур пакета, другие программисты в вашем случае получат отдельный пакет, с кучей процедур — одна из них нужна, остальные нет.
Либо, можно продождать разработку в общем пакете, и он будет весь замусорен процедурами.
Учитывая, что в системе пакетов и так овердофига, это нельзя считать красивым решением.
Как этой функции сделать три аргумента если их семь?
Мне кажется это должна быть функция от одного аргумента — адреса. А адрес может быть структурой с любым количеством обязательных и не очень полей.
И зачем?
Потом оценка задача добавить какую-нибудь легковесную доп проверку выливается в неделю
да, их можно сбить в одну структуру, но зачем?
В случае с адресами, конечно, маловероятно, но в общем виде — где сегодня семь параметров, завтра восемь, послезавтра девять. Сегодня они передаются в один метод, у которого поменяете интерфейс, а завтра в два метода, а послезавтра будете менять уже интерфейсы трёх методов (не считая тестов). А если ещё не все параметры обязательные и внезапно кто-то здраво решит, что нужно не null передавать, а сделать перегрузки с набором только обязательных аргументов, это все стремится превратиться в локальный адок и место множественных опечаток. Кучка конструкторов у класса Address выглядит более удобным решением. Пользователь метода всегда знает, что вызывает метод с валидным параметром, метод не отвечает за полноту данных адреса — за это очень предсказуемо отвечает класс Address, и ошибка контролируется на этапе инстанцирования. Мне кажется, все очень складно получается.
В случае с адресами, конечно, маловероятно, но в общем виде — где сегодня семь параметров, завтра восемь, послезавтра девять.Знаете — я, конечно, с геотаргетингом больше 10 лет назад работал, но вряд ли адреса с тех пор сильно упорядоченней стали.
Где сегодня семь — там завтра может быть и семьдесят семь. Ибо в разных странах адреса сильно по разному устроены и как их вложить в прокрустово ложе SQL — никто толком не знает. То ли завести пару десятков столбцов (из которых большая часть будет пуста), то ли несколько таблиц (а потом их связывать — то ещё развлечение), то ли ещё как-нибудь… а может вообще дописать модуль в PostgreSQL и завести там тип «адрес»?
В общем… абстрагиваться и где возможно передавать сущность «адрес», не пытаясь понять что у этого адреса внутре — очень правильное решение.
Даже если вы пока за границу ваш продукт продавать и не собираетесь…
Пфф, элементарно :)
create table address
(
id integer primary key,
value jsonb not null
);- По жсону есть индексы
- если у нас есть однотипные поля которые нам нужны то мы можем их выносить уже на уровень отдельной колонки
В любом случае — лучше решать эту отдельно от задачи «куда засунуть данные для которых среди предусмотренных 7 строке нет места».
Ну если данные однтипны — то в колонку, если опциональны — то в жсон. Никуда не возвращаемся, есть ответ.
Никуда не возвращаемся, есть ответ.В теории-то есть, а вот на практике…
Ну если данные однтипны — то в колонку, если опциональны — то в жсон.Вот только ответ зависит от того, кого на нашем сайте регистрируется больше.
И если вдруг он стал популярен не там, где вы рассчитывали и все посетители, вдруг, стали резко искать по полю «метро», которое у вас изначально было в опциональных данных… в общем классика: в действительности всё не так, как на самом деле
Если у вас индексы внезапно начинают формироваться динамически на основнаии пользовательских данных — это уже супер кастомные вещи, которые не решаются из коробки. Возможно тогда даже РСУБД в принципе это плохой выбор.
Если у вас индексы внезапно начинают формироваться динамически на основнаии пользовательских данных
Позвольте, но на основании чего ещё их формировать? Цель создания индекса — это ускорить некоторый класс запросов. И если после создания индекса оказывается, что на реальных данных дискриминатор индекса производит такие же вложенные циклы, как если бы этого индекса совсем не было — то индекс не нужен, совсем — даже если с точки зрения логики для этого типа фактов индексирование именно по этому полю выглядит логично. Например, если у вас в таблице события есть индекс по типу события — ну, логично ведь? Потом оказывается, что все сто миллионов событий на практике имеют тип "день рождения" (и других событий там вообще нет) — то вы с этого индекса поимеете только небольшое замедление при добавлении новой строки события (на пересчёт индекса).
Индексы обычно формируются в стиле "вот у нас есть WHERE по этим колонкам, их пихаем в индекс".
А когда вы сами не знаете что у вас за колонки и запросы формируются не кодом или хранимками, а конечным пользователем, тогда история другая.
Потом оказывается, что все сто миллионов событий на практике имеют тип "день рождения" (и других событий там вообще нет) — то вы с этого индекса поимеете только небольшое замедление при добавлении новой строки события (на пересчёт индекса).
Речь была не про данные с плохим распределением, а про то, когда у вас запросы условно это eval(...) пользовательского SQL. Вы просто физически тогда не знаете что за запросы и какие им индексы нужны. Речь выше про это шла.
А чем принципиально та ситуация вверху отличается от "вот у нас есть WHERE по этим колонкам"? И то, и другое, с точки зрения базы, одинаковой важности запросы. Ну может один чаще повторяется — и то не уверен. Полностью статичный WHERE чаще всего используются внутренним кодом, а намного чаще кому-то "просто спроситьпосмотреть", и во многих системах с RDBMS фильтрация позволяет добавлять свои критерии в некоторых пределах.
Да, реальное распределение данных в создании индекса — не единственный момент, который нужно учитывать, его всегда нужно умножать на условный вес запросов по таким данным.
Я против этой идеи и возражал — там в цитате "по пользовательским данным", а надо — "по пользовательским запросам". Такой вариант точнее, но даже если запросы динамически делают пользователи, лучший индекс будет учитывать не просто по каким полям фильтруют, но ещё и как данные реально лежат, и по каким критериям их дискриминировать.
Это уже другой вопрос, есть принятые техники. Для колонки где большое количество данных одного типа можно либо сделать фильтрованнвый индекс, либо использовать columnstore. А вот как делать эффективные индексы для пользовательских запросов я не представляю даже в теории. Впрочем, никогда это не интересовался, обычно наоборот запросы пишутся чуть ли не со спецификой конкретной БД, и с рассчетом на определенные индексы и план запроса.
Так в том и проблема, что для пользовательских запросов нет надёжного способа сказать, какой будет план, пока уже жареные петухи не начнут прицеливаться. Там уже анализ идёт на боевых данных и серверах, благо индексы не меняют сути запроса. Даже на каждом сервере в итоге могут быть немного разное индексирование, как раз из-за конкретного распределения данных на шарде.
Но вон индексацию по блобам jsonb у нас внутри как-то исследовали и выпустили внутреннюю ноту, чтоб ни-ни — jsonb только в проекцию, но не в предикаты. Подробности найти тяжело, но видимо тогда совсем там плохо было.
Хм, мне было бы очень полезная информация. А то у нас сейчас монга, и много кто из знакомых говорит "да перенеси в жсонб в постгрю, а потом понемногу типизируете. Индексы-всё остальное будет работать так же или быстрее". Вот я и думал поисследовать, но если этим кто-то занимался то сэкономило бы кучу времени.
Полагаю, автор статьи особо не видел говнокода, с функциями на тысячи строк, циклами с 6-7 уровнями вложенности, классами о шестистах public методах, наследуемых от 5-6 других классов. Вот чтобы такое не писать, и нужен "совершенный код".
Немного личного опыта. Однажды я реализовал некую подсистему в стиле "не больше 4х строк на метод". Код офигеть как понятен (не считая некоторой лапши из вызовов методов, но вложенность вызовов небольшая), но, к слову, почему-то заметно тормозит в некоторых случаях. Вопрос, связаны ли тормоза с таким стилем кода. У меня нет явных подтверждений этой гипотезы, но подозрения закрадываются.
Немного личного опыта. Однажды я реализовал некую подсистему в стиле «не больше 4х строк на метод». Код офигеть как понятен
Ну, не знаю, не знаю. Такой стиль написания, если смысл функции хоть чуть-чуть оказывается непонятен, вынуждает читающего беuать взад-вперед по по тексту программы не меньше, чем чем классический «фортрановский» спагетти-код с кучей GOTO.
И уж, во всяком случае, я бы предпочел вместо private функций, состоящие из вызова одного метода одного поля класса, вставлять в код сам вызов этого метода, чтобы избежать дополнительного уровня абстракции. Потому что даже если потребеутся поменять логику реализации, найти все все такие вызовы и переписать их можно обычным поиском-заменой в редакторе.
undel.
но, к слову, почему-то заметно тормозит в некоторых случаях
Может зависеть от платформы, напримерп, поддерживает ли компилятор инлайнинг. А может было что-то еще. Надо профилировать.
Насколько я помню, одной из причин тормозов был некэшированный доступ в бд (sqlite). Несколько тысяч запросов обрабатывались неприличное время. В большинстве паттернов использования данные читались только 1 раз, и кэш прикручивать было бессмысленно.
А как это связано с разбиением на функции?
Не знаю.
Насколько я могу вспомнить, это единственный случай, когда мой код тормозит, и я не могу ничего сделать. Оптимизировать просто нечего, так как всё уже предельно просто. В рамках текущей архитектуры.
А вот если архитектуру поменять, возможности откроются, наверно. Взамен функций из 4х строк.
Поэтому у меня впечатление, как будто в данном случае проблемы из-за такой архитектуры.
Оптимизировать просто нечего, так как всё уже предельно просто.
Оптимизация, это не всегда упрощение (кеш, предсказание переходов, JIT это усложенение, а не упрощение)
В большинстве паттернов использования данные читались только 1 раз, и кэш прикручивать было бессмысленно.
Мне ваш анализ ситуации непонятен. Некешированный доступ к бд — источник тормозов, но, в то же время кеш ничего бы не исправил.
Я правильно понимаю, что исследование произваодительности показало, что узкое место — доступ к БД (т.е. задача IO/Network bound)?
А что именно в этом доступе к БД тормозило? Генерация запросов, latency в сети, составление планов? Исполнение запросов?
Некешированный доступ к бд — источник тормозов, но, в то же время кеш ничего бы не исправил.
Кэш чтения ускоряет второй и далее доступ, но данные принципиально читаются 1 раз. Число попаданий в кэш при поиске около нуля, следовательно, от него один оверхед.
А что именно в этом доступе к БД тормозило? Генерация запросов, latency в сети, составление планов? Исполнение запросов?
Я даже не вникал далее. По сути, таблица sqlite использовалась практически как key-value хранилище. Иногда ключей, которые нужно прочитать, были десятки или сотни тысяч, и, хм, такое количество запросов, имхо, есть ошибка. Ну, это типа как кто-то использовал бы документы MS Word для хранения гигапиксельных картинок. Мы просто решили избегать подобных сценариев, а изначально такие сценарии вообще не предполагались.
Возможно, если бы я нашёл способ делать запросы не по одному ключу, а массово, то скорость бы повысилась. Какой-то эвристический preload и кэш записи… Но это бы сделало архитектуру как минимум более запутанной, а скорее всего — весьма запутанной. Это бы точно отменило архитектуру "4 строки на метод". Я не стал, т.к. система свои базовые функции выполняла.
Итак, главный вопрос заключается в том, какую книгу(ы) я бы рекомендовал вместо этого?
Я бы предложил не относится ни к какому источнику как к абсолютной истине. Читать как можно больше и как можно более разного. Критически оценивать и переосмысливать прочитанное. Извлекать из каждой книги что-то полезное, даже из объективно плохой.
Это говорит о том, что очень многие не готовы признать что являются большинством дрочащим на гуру. А вот про других такое сказать вполне не против.
Да, дядюшка Боб во многом пишет именно чтобы свой бренд продвигать, вот только книги его не были бы так популярны если бы он фигню писал. В его книгах очень много здравого.
Книги мартина написаны, не для того чтобы продвигать бренд, а чтобы продвигать консалтинговые услуги. Это разное. Людям, которые способны сами разобраться в вопросе — платные услуги по решению их задач не нужны. Следовательно книги мартина не будут учить людей хорошо программировать, потому что тогда его услуги не понадобятся. Поэтому очевидно они учат программировать неправильно, так чтобы вам пришлось платить мартину за решение.
книги дядюшки Боба вообще нет смысла читатьРазумеется. Зачем читать книгу в которой перемешаны вредные и полезные советы, под видом очень полезных? Человек, не имеющий хорошего опыта просто не поймет какой совет полезный, а какой вредны и научится херне.
В его книгах очень много здравого.Вот только вредного там не меньше. И я не думаю что вы способны отличить что там здравое, а что нет. Соответственное ваши представления о здравом не сходятся с реальностью.
вот только книги его не были бы так популярны если бы он фигню писалПокекал. Популярность — это как раз таки косвенное свидетельство того что он пишет фигню. Умные штуки редко бывают популярными, потому что их тяжело понять. Поэтому и есть такой большой запрос на гуру, головой думать сложно, разжуйте нам чтобы не надо было думать.
Вероятно, хватит рекомендовать «Чистый код»
В источнике: «It's probably time to stop recommending Clean Code».
Более точный перевод: «Похоже, уже хватит советовать «Чистый код»».
assertEquals(“HBchL”, hw.getState());
Весело будет такими тестами пользоваться, когда в одном из обновлений добавят, например, индикацию средней температуры, и формат станет "HBchLm", особенно если таких тестов — сотни.
И перевод здесь точен. Казалось бы, ерунда. Но в итоге, вместо обсуждения примера, который предназначался в определенном контексте иллюстрировать определенные идеи, получается обсуждение того, как плохо, что данный пример — это не образец Абсолютно Идеального Чистого Кода.
К вопросу о разбиении кода на минимальные по размеру функции/методы.Тут все просто, этот совет изначально дебильный. Странно, что имея опыт и понимание того как функции вызываются, вы вообще такие советы слушаете.
Понимание по какому приницпу разбивать функции, в каких кейсах, и самое главное почему так и не иначе приходит с опытом. Получить такое понимание заучив какието там правила невозможно.
Очевидно что делать функцию на 7к строк — дебилизм (но не удивлюсь если есть редкие кейс где такое оправдано), но разбивать код на функции из максимум 4 строк такая же дебильная крайность.
ПС: иногда, правда, полезно проводить «денормализацию», с целью улучшения читабельности кода.
https://martinfowler.com/bliki/FunctionLength.html
Smalltalk's graphics class had a method for this called 'highlight', whose implementation was just a call to the method 'reverse' [4]. The name of the method was longer than its implementation — but that didn't matter because there was a big distance between the intention of the code and its implementation.
Я понимаю что есть куча компиляторных оптимизаций, да и далеко не везде нужно смотреть на подобные расходы, но все жеЗапустите Windows NT 3.1 на Pentium 200MHz. Запустите Windows 10 на Core i9 4GHz. Сравните скорость реакции. Вы получите ответ на этот вопрос.
И когда сейчас в коде на плюсах вижу подобное дробление меня постоянно мучает сомнение о накладных расходах, и о балансе между читабельностью и производительностью кода.Баланс — где-то между «плохо» и «очень плохо».
Я несколько раз сталкивался с подобным, переписывал код, получал ускорение от 5 до 10 рез.
При этом стоит признать, что «шинкование функций», само по себе, не проблема: современные компиляторы и JIT'ы их отлично инлайнят.
Одна SOLID требует превращать в крошево не только код, но и данные. Забывая про простую истину, как обычно, высказанную Линусом:
Trust me: every problem in computer science may be solved by an
indirection, but those indirections are *expensive*. Pointer chasing
is just about the most expensive thing you can do on modern CPU's.
Обычно это делается, как и весь другой дурдом, под флагом борьбы с «premature optimization»… вот только при этом забывается, что вы можете легко переписмать код, а вот переделка структур данных — это, почти всегда, выкидываение кода и написание его заново.
Потому оптимизация структур данных — это никогда не «premature optimization».
И когда сейчас в коде на плюсах вижу подобное дробление меня постоянно мучает сомнение о накладных расходах, и о балансе между читабельностью и производительностью кода. Разве не приходится производить кучу подготовительной работы чтоб предоставить стек для создаваемой функции, сохранить все нужные состояния регистров и т.п.?
Распространённые современные архитектуры (x86_64, ARM64) (и продвинутые старые, типа Power) имеют достаточно регистров, чтобы не задействовать стек для данных при вызовах простых подпрограмм. Аргументы в основном передаются через регистры (вещественные — в XMM, остальные — в регистрах общего назначения), если аргументов много — то "лишние" передаются через стек.
Выделение памяти на стеке — это не "куча подготовительной работы", это что-то типа '''add rsp, N; mov rbp, rsp''' — пара инструкций. Вершина стека обычно попадет в L1 кэш, и доступ к ней не слишком медленный.
Также выделение подпрограмм может дать результат в виде более компактного кода, который сможет поместиться в L1 instruction cache, в отличие от кода, раздутого от inline подстановок. Но это уже немного другие, специфические частные случаи. В общем случае лучше оставить компилятору выбор inline-не inline.
Распространённые современные архитектуры (x86_64, ARM64) (и продвинутые старые, типа Power) имеют достаточно регистров, чтобы не задействовать стек для данных при вызовах простых подпрограмм.Сам вызов функции и возврат из неё — эквивалентны примерно десятку операций. На Ryzen, например — это 4 тика. Вообще без затрат времени на исполнение содержимого. Плюс, как вы заметили — ещё пару инструкций в вызывающей функции и пара инструкций в вызваемой. Итого — порядка 15-20 простых операций «накладных расходов» на вызов. Дальше вспоминаем Кнута и его «в развитой инжереной дисциплине улучшение в 12%, легко получаемое, никогда не рассматривается как несущественное — и я верю, что подобный же подход должен возобладать и в програмимровании» (это, чисто на всякий случай та статья, откуда кусок про «premature optimizations», с которым дураки носятся как с писанной торбой, выдран) — и получаем что «нормальная» функция должна содержать примеро 200-300 элементарных операций.
И да, конечно одна строка порождает не одну инструкцию на выходе. И да, встраивание и всё такое прочее. Но, извините, средний размер функции в 3-4 строки и эффективность… тут «не вытанцовывается»…
В общем случае лучше оставить компилятору выбор inline-не inline.В общем случае нужно писать программу так, чтобы он мог это сделать. Если у вас виртуальные функции по 2-3 строки и объект передаётся через указатель — то он нифига не может сделать, извините.
А это, блин, рекомендуемый формат кода у фанатов юниттестирования.
Мне кажется, что первична все же читаемость, а не то, сколько тиков тратятся на вызов. В эпоху электрона считать тики это уже не модно. Как правильно писал фаулер: в читаемом коде всегда можно перейти к оптимизированному с профайлером, если чуть-чуть думать при написании кода. Есть буквально пара простых правил, которых стоит придерживаться: не делайте запросы к БД в цикле, не расставляйте thread.sleep, всё в таком духе. А уж тики считать — нужно в единицах случаев, причем нужно сидеть уже с профайлером конкретного процессора и смотреть, что ему больше нравится. У нас кстати таким мы тоже занимались, с vtune'ом.
Да, по возможности нужно выкинуть виртуализацию и писать в стиле параметрического полиморфизма. Да, нужно понимать, где аллокации дешевые на стеке, а где — дорогие в куче. Да, в редких случаях нужно понимать, что вызов функции не бесплатный.
Но в основном нужно просто писать понятный код, который легко расширить и заменить наивную реализацию на оптимизированную. Где соблюдается SRP и в итоге оптимизировать можно конкретные места, а не смотреть на размазанную ровным слоем во всей кодовой базе неоптимальность.
Да, по возможности нужно выкинуть виртуализацию и писать в стиле параметрического полиморфизма.
Именно, "по возможности". Иногда выкинуть просто невозможно, часто — можно.
А с другой стороны, есть много языков, где все методы виртуальные, и это мало кого волнует.
Мне кажется, что первична все же читаемость, а не то, сколько тиков тратятся на вызовВ любом коде первична система, которую он описывает, а сам код вторичен. Это как в делать в доме стены потоньше, чтобы в автокаде красивее смотрелось.
Код должен быть в меру понятен, нечитаемое говно это плохо, но и вылизывать код до блеска никакого смысла нет. Извращения на тему «как бы покрасивее написать код» — пустая трата времени.
В эпоху электрона считать тики это уже не модноСамим то нравится говно на электроне использовать? Хотите чтобы весь софт был такой?
Не, я соглашусь с тем что в прикладном софте считать тики с нынешним железом и оптимизациями компиляторов нецелесообразно, но ставить читаемость кода выше характеристик программы это абсурд и идиотизм.
Ну и разбиение кода на микрофункции по 1-2 строки не увеличивает читабельность, а ухудшает. Сами посмотрите на примеры кода в статье, там же ничего сходу не понятно.
Написание понятного кода не поддается алгоритмизации с помощью набора правил (типа «функция должна быть не длиннее 4 строк»), хватит заниматься ерундой.
Код должен быть в меру понятен, нечитаемое говно это плохо, но и вылизывать код до блеска никакого смысла нет. Извращения на тему «как бы покрасивее написать код» — пустая трата времени.
Красивый код — это код, который не имеет багов и который просто расширять. В идеале если он ещё и шустрый.
Как мне кажется, это не пустая трата времени, и чатсо заказчик сможет оценить что время доработки не год, а месяц, и вместо четырёх серваков жрущих по косарю баксов в месяц можно оставить только один.
Самим то нравится говно на электроне использовать? Хотите чтобы весь софт был такой?
Зависит от продукта, VSCode вполне неплох, но в целом да — не нравится. Но нравится мне он или нет это не влияет на то, что это объективная окружающая нас реальность — электрон есть, никуда не денется, и очень популярен. Пользователи хотя лагучее, но быстро сделанное и дешевое решение. Ну что поделать, приоритеты у них такие, у разработчиков и самих такие, когда речь касается не софта.
Ну и разбиение кода на микрофункции по 1-2 строки не увеличивает читабельность, а ухудшает. Сами посмотрите на примеры кода в статье, там же ничего сходу не понятно.
Вот с этим согласен
Красивый код — это код, который не имеет багов и который просто расширять. В идеале если он ещё и шустрый.У кода нет значимого параметра «красота», вообще. Код — это просто описание системы.
который просто расширять
Это все относится не к коду, а к системе. Чем система проще — тем она лучше. Расширяемость — не есть признак качества, порой расширяемую систему сделать дольше и дороже чем такую, которую можно быстро переписать.
Как мне кажется, это не пустая трата времениИменно что пустая, «красота» кода на качество системы влияет мало
Проблема электрона не в пользователях, а в разработчиках. Было бы поменьше js-дебилов, неспособных даже питон выучить, электрон не был бы так популярен. Как только появится вменяемый кроссплатформенный фреймворк, позволяющий делать приложения под win\mac\linux дешево, на современном прикладном языке (а не на плюсах), и не даунским способом — то электрон умрет. Например если флаттер допортируют. Потому что пользователи не хотят лагучее говно.
Хотел ответить, поспрашивать про различие "системы" и "кода", и так далее, но после js-дебилов и тупорылых пользователей которые любят говно как-то расхотелось.
Всего доброго
Хотел ответить, но как-то расхотелосьНечего ответить — докапайся до лексики. Классика. Можете не продолжать, вы упали в моих глазах ниже плинтуса.
пользователей которые любят говноСама придумала — сама обиделась. Тоже классика.
Пользователи хотят лагучее, но быстро сделанное и дешевое решениеЭто ваши слова. Я такого не говорил.
пользователи не хотят лагучее говно.Вот что я говорил, тут смысл абсолютно противоположный
1) Красота понятие субъективное и кому-то и коза красивая. До словно перевод красивый код = код который мне нравится.
2) Расширяемость системы обозначает возможность быстро и бесшовно внести изменения. До словно расширяемый код = код который можно быстро поменять. Ну и иногда лучше сделать просто и плоский код как в Go (писать стену в кода в контроллере) который будет очень быстро меняться путем его банального переписывания а не изменения одной реализации интерфейса на другую (Как например IFormatter с JsonFormatter сменить на XmlFormatter что есть классический пример расширяемости). Опять меня на многабукаф понесло.
1) Используй Интерфейсы вместо реальных объектов везде где это в принципе возможно
2) Используй Коллекции вместо единичного объекта везде где это возможно
Интерфейсы я понимаю. А коллекции то зачем?
И что значит "везде где только возможно"? Вот есть у нас one-to-one отношение и зачем здесь коллекция? Хотя в теории она возможна…
с опытом сформировал 2 правилаА думать правилами — вообще плохой тон. Правила скорее для людей у которых еще нет опыта
А вот мне теперь стало интересно где же это вредна расширяемость кода? То есть что она где-то не нужна я себе могу ещё представить. Но вот чтобы прямо вредна…
Или есть 3 фичи в проекте, одна из них скорее всего потребует расширения, две другие — нет. Вы опять же потратите больше денег и времени на разработку, добавляя расширяемость там где не надо.
Кроме того добавляя расширяемость везде вы усложняете систему. В итоге в определенный момент вы получаете обратный эффект, систему становится сложнее понять, сложнее модифицировать, сложнее фиксить в ней баги, и багов становится намного больше.
что она где-то не нужна я себе могу ещё представитьСочувствую
Надоело уже очевидные вещи расписывать
Так вы просто вред не умеете подсчитывать.
Это скорее вы всё смешиваете в одну кучу.
Вот например нужно сделать MVP — без расширяемости делать неделю, с расшираемостью — две. Например MVP не взлетел, вы потеряли х2 денег, тупо изза расширяемости.
Это не вред от расширяемости, это вред от лишнего потраченного времени. Потому что если у вас скажем ваш MVP с расширямостью или без расширямости будет делаться одинакoво долго, то никаких проблем не будет. А нет никакого всемирного закона, который говорит что с расширямостью всегда и в любой ситуации разработка будет длиться дольше.
Или есть 3 фичи в проекте, одна из них скорее всего потребует расширения, две другие — нет. Вы опять же потратите больше денег и времени на разработку, добавляя расширяемость там где не надо.
И опятъ проблема не в расширяемости, а в потраченных времени и деньгах.
Кроме того добавляя расширяемость везде вы усложняете систему.
Ну и получается что проблема в не в расширяемости, а в усложнении системы, которое может сопутствовать расширяемости, а может и не сопутствовать. В расширяемости как таковой проблем в данном случае опять же нет.
это вред от лишнего потраченного времени
в потраченных времени и деньгах.
а в усложнении системыВ следствии расширяемости
Вы несете полную херню и очень тупо передергиваете, как будто расширяемость это святое и всеми силами надо извернуться так чтобы эту святость не опорочить
Расширяемость крайне редко дается бесплатно, вы либо платите за нее усложнением системы, либо большими затратами времени на подумоть\написать.
Вы несете полную херню и очень тупо передергиваете, как будто расширяемость это святое и всеми силами надо извернуться так чтобы эту святость не опорочить
Я не считаю что расширяемость это что-то святое и нигде ничего подобного не утверждал. Я просто не вижу в чём вред именно самой расширяемости как таковой.
Расширяемость крайне редко дается бесплатно
То есть иногда она всё-таки бесплатно даётся? И в чём тогда вред расширяемости именно в таких ситуациях?
вы либо платите за нее усложнением системы, либо большими затратами времени на подумоть\написать.
Банальный пример: у вас есть проект на десятки(а то и сотни) тысяч строк кода. Вы можете запихать все эти строки в один единственный класс, а можете распределить их по разным классам. Расширяемость во втором случае будет однозначно больше. И на мой взгляд ни денег/времени вы во втором случае на разработку больше не потратите, ни модифицировать такую систему сложнее не станет. Скорее как раз наоборот.
То есть иногда она всё-таки бесплатно даётся? И в чём тогда вред расширяемости именно в таких ситуациях?Когда бесплатно — ни в чем. Я нигде не утверждаю что расширяемость всегда вредна. Учитесь читать то что вам отвечают. Я утверждаю что чаще всего за расширяемость надо платить, а платить в тех случаях когда она вам не нужна — очевидно вредно.
Я просто не вижу в чём вред именно самой расширяемости как таковой.Я уже сочувствовал вам по этому поводу
Банальный пример: у вас есть проект на десятки(а то и сотни) тысяч строк кода. Вы можете запихать все эти строки в один единственный классЭто не банальный, а детский и оторванный от реальности до нельзя утрированный пример. Потрудитесь привести чтото более реалистичное и далекое от крайностей
Я нигде не утверждаю что расширяемость всегда вредна.
Ну так где вредна именно расширяемость? Не какие-то побочные эффекты, которые могут или не могут возникнуть, когда вы стремитесь её достигнуть, а именно сама расширяемость?
Я уже сочувствовал вам по этому поводу
Не надо сочуствовать, лучше приведите пример, которые показывает чем вредна расширямость сама по себе.
Это не банальный, а детский и оторванный от реальности до нельзя утрированный пример.
Вы никогда не видели несколько тысяч строк кода запиханные в один класс/файл? Ну могу вас поздравить, вам повезло:
Потрудитесь привести чтото более реалистичное и далекое от крайностей
Ну как только вы приведёте реалистичный и далекий от крайностей пример того что расширяемость вредна сама по себе, то я возможно поищу какие-то другие примеры. А пока хватит и этого.
Я утверждаю что чаще всего за расширяемость надо платить, а платить в тех случаях когда она вам не нужна — очевидно вредно.Любой адекватный человек понимает что написано в этой фразе. Попробуйте несколько раз прочитать, может у вас с этим трудности.
Расширяемый код не самоценность, гдето расширяемость нужна, гдето вредна.
Бывает, что один модуль на десятки тысяч строк кода расширить в смысле смены архитектуры/увеличения функционала проще, чем демонтировать уже существующую архитектуру и пересоздать её заново.
Расширяемость это не только код, это ещё и принципы работы системы, которые необходимо поддерживать при изменении кода системы. Соответственно, если никто ещё задуманные интерфейсы расширяемости не использует, то возрастает цена изменения, так как надо больше факторов проверить на соответствие концепции расширяемости.
Также довольно часто ненужная расширяемость выливается в постоянные затраты времени выполнения: лишние данные занимают место, ненужные события вызываются, выполняются проверки никогда не устанавливаемых условий, неисполняемый код отравляет кэш инструкций и т. д.
Расширяемость это попытка угадать будущие требования, которая в случае неудачи может привести к громоздкой и неподходящей архитектуре, которую просто по определению очень тяжело сменить.
Я за всю свою карьеру видел множество примеров ошибочных прогнозов будущих требований, и всего два примера, когда основатели архитектуры верно угадали, что потребуется. И в этих обоих случаях у них был большой опыт работы в данной конкретной области.
Бывает, что один модуль на десятки тысяч строк кода расширить в смысле смены архитектуры/увеличения функционала проще, чем демонтировать уже существующую архитектуру и пересоздать её заново.
Вы знаете я часто слышал подобные аргументы, но пока ещё ни разу не встречал ни одного конкретного примера. Если у вас такой есть, то я на него с удовольствием посмотрю.
Расширяемость это не только код, это ещё и принципы работы системы, которые необходимо поддерживать при изменении кода системы
Естественно «расширяемость» это много что. Но я привёл конкретный простенький пример, который подтверздхает мой тезис. Если у вас есть конкретный пример, который его опровергает, то я на него с удоволствием посмотрю. Даже если он тоже бдует простенький.
Расширяемость это попытка угадать будущие требования, которая в случае неудачи может привести к громоздкой и неподходящей архитектуре, которую просто по определению очень тяжело сменить.
Как вы уже писали сами: «расширямость это не только ...». То естъ если у вас расширяемость «покупается» за счёт каких-то других минусов, то это может стать проблемой. Но это не значит что плоха расширяемость сама по себе.
Вы не поняли о чем спор вообще. Расширяемый код не самоценность, где-то расширяемость нужна, где-то вредна.
Да и к тому же расширяемый код сложнее и его дольше писать.
Например можно сделать метод User Get(int id) и если понадобиться получать несколько пользователей то придется писать новый метод или в цикле вызывать этот а можно сделать List Get(List ids) который будет работать и с 1 айди и когда кому-то надо будет получить коллекцию не надо будет писать новый код. Метод универсален. Ток написать его будет чуть сложнее. Можно сделать просто int Add(int a, int b) а можно сделать T Add(T a, T b) второй вариант будет более универсальным и расширяемым ток будет сложнее и его дольше делать. Можно сделать просто JsonSerialazer.Serialize(User) а можно ISerializer.Serialize(User) второй вариант будет универсальнее. Его проще расширить но дольше писать и код там будет сложнее. В общем расширяемость это всегда повышение сложности кода и времени его разработки. Иногда проще и выгодней сделать код быстро переписываемым чем расширяемым.
А думать правилами — вообще плохой тон. Правила скорее для людей у которых еще нет опыта
Ага, правила дорожного движения соблюдают только не опытные водители. Вы странный.
val foo = bar().first
Да, Мартин гораздо более публицист, чем программист, его FitNesse — достаточно глючная вещь и не со всеми его рецептами можно согласиться. Но CleanCode подробно отвечает на вопросы новичков о том, чем отличается хороший код от плохого, и однозначно повлияла на моё мировоззрение в лучшую сторону.
Поэтому рекомендовал и буду рекомендовать.
Много лет придерживался и до сих придерживаюсь мнения, что многие статьи и книги Боба крайне категоричны и, местами, откровенно опасны для новичков. С другой стороны, опытному разработчику они не сильно и нужны. Куда больше они подходят для инициации обсуждения и холиворов.
Тут рядом упоминали Code Complete — поддержу. Хорошая, обстоятельная книга, перекосов и абсолютизма не припомню.
Одна из причин, почему ООП в целом выглядит хорошо — его часто противопоставляют спагетти на 4000 строчек. Крайне сложно утверждать, что между «красивой иерархией классов» и «монстром на 4000 строк» ты выберешь монстра. Однако, это ложная дихотомия.
Во-первых, существует то же ФП, которое местами показывает очень интересные результаты и вообще функции это классы для бедных и наоборот. Во-вторых, мейнстрим ООП на «сервисах» это по сути glorified процедурное программирование.
Очень хорошее и в некотором смысле inspiring выступление по ООП можно наблюдать у Sandi Metz:
www.youtube.com/watch?v=OMPfEXIlTVE
Что интересно, в процессе разбиения получился набор более мелких классов, каждый из которых старается выполнять одну вещь и при этом не хранить состояния. Что, внезапно, эквивалентно передаче функций без замыканий.
Также отмечу фрагмент про наследование и его опасность, мой личный опыт в целом подтверждает.
В книге нормальные правила и идеи, просто в книге слишком много ООП, который и помешал автору реализовать их.
Дело в том, что книга была написана, когда люди все еще продолжали верить в ООП, как во что-то, что может упростить код.
А потом оказалось что нет.
Не используйте ООП. Никогда. Это ошибка.
На эту тему есть много материалов, к примеру: https://www.youtube.com/watch?v=QM1iUe6IofM
Если ООП все еще кажется вам хорошей идеей, то решите простую задачку:
Есть три объекта: кошка, кормушка и человек. Вам необходимо написать метод, который бы позволял человеку покормить кошку, воспользовавшись кормушкой.
Вопрос: методом какого класса будет являться метод.покормить()?
Просьба привести аргументированный ответ, в соответствии с иерархией классов, и другими лучшими практиками ООП.
Теперь сравните это с функциональной реализацией:
У вас есть функция покормитьКошку() принимающая в качестве аргумента ссылку на кошку и кормушку.
Есть три объекта: кошка, кормушка и человек.
Объекта или класса?
Вопрос: методом какого класса будет являться метод.покормить()?
В зависимости от того какие ещё условия у вас должны выполнятся или могут появится в будущем. Ну а в чём по вашему заключается проблематика варианта с кормушка.покормить(кошка)? И чем такой вариант по вашему принципиально хуже чем покормить(кошка, кормушка)?
Теперь сравните это с функциональной реализацией:
У вас есть функция покормитьКошку() принимающая в качестве аргумента ссылку на кошку и кормушку.
А человек куда внезапно делся? :)
Объекта или класса?
Объекта категории :)
В зависимости от того какие ещё условия у вас должны выполнятся или могут появится в будущем. Ну а в чём по вашему заключается проблематика варианта с кормушка.покормить(кошка)? И чем такой вариант по вашему принципиально хуже чем покормить(кошка, кормушка)?
Второй вариант как раз даже лучше, потому что можно написать
покормитьМоюКошку = покормить мояКошка
...
покормитьМоюКошку кормушка1
покормитьМоюКошку кормушка2
покормитьМоюКошку кормушка3Каррирование — великая вещь
А с первым вариантом можно не менее просто покормить несколько кошек из одной кормушки.
В ООП языках каррирование вообще не распространено, а в ФП — да, можно было бы и так. Ну и да, всегда можно сделать
кокормитьИзКормушки = (flip покормить) мояКормушка
Каррирование — да, не распространено. Но конкретно для нулевого аргумента как минимум в C#, Python и Delphi оно работает.
Если же разрешить не писать "в лоб", а применять трюки вроде flip — то я не вижу проблем написать лямбду, что будет работать для любого частичного применения функции.
Кстати, дарю ещё один вариант для Хаскеля:
покормитьИзКормушки = (`покормить` мояКормушка)Человек имеет метод ПокормитьКормимое, принимающий в качестве аргумента кормушку и кормимое и который внутри, например передает кормушке в такой же метод корм (который берет из шкафчика который, например, ранее передан) и кормимое.
Но вообще пример очень абстрактный. Без уточнения требований вообще непонятно зачем в этой схеме человек.
Ну это же старая задача, из разряда, чьей ответственностью должен быть обсчёт нанесения урона в игре: атауемого, атакованного, какого-нибудь AttackManager'а или ещё кого.
Подобными рассуждениями исписаны тысячи комментов под тысячью таких же статей, от чего я конечно же преисполнился
И вот по такому определению ООП действительно больше вредит, потому что динамический диспатч и для человека, и для машины — очень сложная фигня, которая ещё и оптимизировать и понимать код мешает.
И вот по такому определению ООП действительно больше вредит, потому что динамический диспатч и для человека, и для машины — очень сложная фигня, которая ещё и оптимизировать и понимать код мешает.Оно относительно просто и эффективно реализуется для одного аргумента — и, в результате, выросло уже целое поколение людей, которые свято верят в то, что ООП — только таким и бывает и что мультиметоды — это не ООП.
Хотя CLOS, на них основанный, раньше, чем C++ появился (хотя может быть «C с классами» тогда уже был, не буду спорить, я не настолько хорошо историю знаю).
И да, разумеется, там где вам нужен динамический диспатч — вам нужен ООП (и он, конечно, реализуется в любых языках… в какой-нибудь macOS Classic середины 80х, написанной на необъктном Pascal — оно уже есть ибо как иначе драйвера-то делаеть?). А если не нужен — то не нужен…
Ну вот мне кажется, что ООП как раз создал тенденцию пихать диспатч ВЕЗДЕ. У фаулера емип чуть ли не на каждый иф предлагается писать абстратный класс и пару виртуальных методов. ЕМНИП причем где-то в стандартной библиотеке одного из языков If/Then/Else это и есть объекты с такой реализаций, то ли в окамле, то ли ещё где.
причем где-то в стандартной библиотеке одного из языков If/Then/Else это и есть объекты с такой реализаций, то ли в окамле, то ли ещё где
Это в smalltalk было вроде бы. А еще, внезапно, в лямбда-исчислении.
У фаулера емип чуть ли не на каждый иф предлагается писать абстратный класс и пару виртуальных методов.
Замена сопоставления образца с АДТ реализацией интерфейса несколькими классами (паттерн "стратегия")? Ну, по скорости здесь ни то, ни другое не выигрывает в общем случае. В одном случае куча проверок условий или jmp по вычисляемому адресу, в другом — виртуальный вызов (или call по вычисляемому адресу, если речь например о Си). Не могу понять, почему вы считаете, что именно "виртуальный вызов — это плохо", а не, скажем, "сопоставление с 15 образцами — это плохо". Наверно даже, отличие лишь в том, что при сопоставлении с образцом все возможные ветви кода находятся "локально", а при виртуальном вызове — раскиданы по разным местам (в разных классах). Во втором случае число ветвей кода часто тоже конечно — немного программ имеют создание новых реализаций интерфейсов в рантайме.
Для нативных языков разница очень существенна — паттерн матчинг по 15 веткам компилятор может соптимизировать, а вызов виртуального метода с 15 версиями — уже нет.
Впрочем, я не противник виртуального диспатча, иногда он сильно облегчает жизнь. Но далеко не так часто, как это продают в книжках по паттернам или на митапах.
Не могу понять, почему вы считаете, что именно «виртуальный вызов — это плохо», а не, скажем, «сопоставление с 15 образцами — это плохо»Виртуальный вызов вместо 15 образцов — это обычно неплохо.
К сожалению в современном мире подавляющее большинство этих виртуальных вызовов — это «один с половиной вариант». То есть формально их два (тест и релиз), а реально, в коде — он один.
Но он всё равно тормозит.
А вот интересно как в ФП стиле решить эту задачу. Только чтобы перечень героев игры был расширяем. Мы делаем движок с человеком, а кошки и разные модели кормушек в аддонах.
Ну мы можем написать какую-то обобщённую атаку которая работает с любыми юнитами, ну что-то в таком духе:
genericAttack : (Unit a, Random r) => a -> a -> r AttackResult
genericAttack a b = do
attackerIndex <- getRandomNumber 0 1
let (first, second) = if attackerIndex == 0 then (a, b) else (b, a)
let newSecond = loseHp (getDamage first) second
let newFirst = if isAlive newSecond then loseHp (getDamage second) first else first
pure $ AttackResult first secondНу и дальше это можно в какие-нибудь трейты/тайпфемили писать, для супер-пупер расширяемости можно взять таглес файнал.
Не используйте ООП. Никогда. Это ошибка.
Почему тогда ООП поддерживается почти всеми современными распространёнными языками?
Если ООП все еще кажется вам хорошей идеей, то решите простую задачку:
Есть три объекта: кошка, кормушка и человек. Вам необходимо написать метод, который бы позволял человеку покормить кошку, воспользовавшись кормушкой.
Вопрос: методом какого класса будет являться метод.покормить()?
Просьба привести аргументированный ответ, в соответствии с иерархией классов, и другими лучшими практиками ООП.
Вы не указали критерии, не привели сценарии использования этого api.
Это как "кто победит — слон или кит". Совершенно нереальный пример задачи. На практике (в реальных задачах, а не выдуманных иерархиях) в 95% случаев выбор очевиден.
Если отвечать на ваш вопрос, не слишком задумываясь о практике, можно предложить отдельный класс ДействиеКормления с полями человек, кошка, кормушка, ссылкой на БД и методом покормить(), который убирает еду из записи кормушки, увеличивает значение сытости у кошки, добавляет плюсик человеку. И ещё огромную иерархию подклассов на все случаи. Хм, а это выглядит неплохо!
Теперь сравните это с функциональной реализацией:
У вас есть функция покормитьКошку() принимающая в качестве аргумента ссылку на кошку и кормушку.
Упрощаете. Представьте, что кормить надо не только кошку, но и собаку, и ещё кучу зверей. ООП не нужно в простых случаях. ООП необходимо, когда у вас есть разнотипные объекты, над которыми нужно производить одинаковые по смыслу действия, не вдаваясь в реализацию действий.
Внезапно в ФП есть тоже не только функции, но и например АДТ (если набор зверей ограничен и редко меняется) и тайпклассы (для обратного сценария).
Чем дальше живу, тем больше вижу, что ООП от не-ООП отличается всего одной вещью: динамическим диспатчем повсюду, где надо и где не надо. Всё остальное давно есть и используется в других языках, и даже не обязательно из ООП пришло, а просто там всегда было, но его не пиарили на конфах миллионам разработчиков.
Всё остальное давно есть и используется в других языках, и даже не обязательно из ООП пришло, а просто там всегда было, но его не пиарили на конфах миллионам разработчиков.
Что значит «из ООП пришло»? ООП это грубо говоря концепт. Вы можете придерживаться его принципов, а можете не придерживаться. Если вы их придерживаетесь, то у вас есть ООП, если не придерживаетесь, то его нет.
У каждого своё понятие что такое ООП, кого ни спрошу — у всех разное определение.
Опа, какие люди)
Ну, лично мне показалось для человека с опытом но не шарящим в ФП хороший вариант — красная книга по скале, которая во-первых объясняет, зачем это всё надо, во-вторых неплохие примеры имеет. А после этого курс по хаскеллю на степике (часть1, часть2), в целом больше ничего и не надо, дальше только в прод.
Внезапно в ФП есть тоже не только функции, но и например АДТ (если набор зверей ограничен и редко меняется) и тайпклассы (для обратного сценария).
Но если обвешаться АДТ и тайпклассами, ФП перестаёт быть таким простым, как пример выше:
Теперь сравните это с функциональной реализацией:
У вас есть функция покормитьКошку() принимающая в качестве аргумента ссылку на кошку и кормушку.
… и начинает напоминать то самое ООП. Тайпклассы — это те же интерфейсы/абстрактные классы. АДТ — хорошая, безопасная реализация union'ов, можно сказать, синтаксический сахар.
Так же, как и выше, можно привести пример, что для hello world на хаскеле обязательно использование каких-то непонятных монад и хвостовой рекурсии, а на java всё "просто и понятно".
Чем дальше живу, тем больше вижу, что ООП от не-ООП отличается всего одной вещью: динамическим диспатчем повсюду, где надо и где не надо.
Виртуальный вызов может преобразовываться компилятором или jit'ом в обычный, если компилятор может вывести конкретный тип, и даже инлайниться.
Вообще любое понятие ФП можно перенести на язык объектов, и наоборот. Имхо, эти парадигмы эквивалентны.
Любое понятие ООП/ФП можно перенести на язык процедрщины, и дальше, в ассемблер (чем и занимается компилятор). Значит ли это, что это одно и то же?
Да, если взять классические ООП языки, действительно окажется, что динамический дисптач это единственное, что уникально отличает ООП от остальных парадигм. И нет, JIT далеко не всегда настолько умён чтобы всегда заинлайнить виртуальный вызов. Не говоря о том, что в он не имеет права инлайнить виртуальный вызов, если например там разные объекты приходят.
Я просто наблюдал физически библиотеку на расте написанную в ООП стиле: тучи забокшенных dyn Trait и прочее, удовольствие ниже среднего. Хотя, казалось бы, тот же язык, которым и я пользуюсь, и на котором многие библиотеки которыми я пользуюсь я написаны.
Извиняюсь, карма позволяет отвечать только раз в день.
Попытаюсь ответить сразу всем.
Почему тогда ООП поддерживается почти всеми современными распространёнными языками?
Даже растом?
Вы не указали критерии, не привели сценарии использования этого api.
Потому что если довести разговор до конкретной реализации, мы начнем спорить, в чьем приватном поле хранить список еды, принимаемой конкретным животным в пищу. Опять же в ФП это место почти всегда однозначно очевидно: это первичная проверки аргументов основной функции покормитьКошку().
А если дальше углубляться в реализацию, представьте, что если вам нужны будут функции/методы, которые бы работали только с сытыми кошками.
Упрощаете. Представьте, что кормить надо не только кошку, но и собаку, и ещё кучу зверей.
Тогда я напишу несколько функций. Или одну — покормитьЖивотное(), в которой один из аргументов будет определять тип животного. За то у меня в худшем случае будет +1 функция, а в лучшем — дополнительное поле в перечисляемом типе (или его аналоге).
А в ООП — в лучшем случае метод, в худшем — наследник класса, со своими реализациями методов и еще небольшим мешком синтаксического мусора.
Я все это к тому, что в обоих случаях код будет примерно одинаковый. Иерархия классов в ООП, никогда не уходит, а скорее превращяется в иерархию типов в ФП.
Но все это в итоге помогает находить ошибки еще на этапе компиляции, даже в таких языках, как Си.
А с ООП часть ошибок станет возможно отловить только тестами, которые не все пишут и умеют писать.
Плюс не забудьте вычеркнуть время, потраченное на обсуждение командой всякого бреда из серии "чьим методом должно являться кормление".
ФП больше о дисциплине и сознательном отказе от синтаксического сахара.
В Расте, конечно, сахар вернули: можно деласть структуры с трейтами и методами, поэтому простая синтаксическая конструкция Объект.действие(чем) мелькает чаще, плюс после точки автодополнение экономит время (как и подсказки типов).
человеку покормить кошку, воспользовавшись кормушкой
Некорректная формулировка. Это два разных действия — насыпать корм из человека в кормушку, пересыпать корм из кормушки в кошку.
Если ООП все еще кажется вам хорошей идеей, то решите простую задачку:Легко. Вот вообще не проблема. Это будет мультиверсионный метод, полиморфный по трём параметрам. CLOS, 80е годы, в 1991м году вышла соотвествующая книжка.
Есть три объекта: кошка, кормушка и человек. Вам необходимо написать метод, который бы позволял человеку покормить кошку, воспользовавшись кормушкой.
Вопрос: методом какого класса будет являться метод.покормить()?
ООП — это не только кастрированная версия из C++/Java. Есть и другие, более грамотные, версии.
Любой современный язык мультипарадигменный, там есть элементы процедуного, ооп и функциональных подходов. В разных кейсах удобны разные подходы. Адекватные люди выбирают подход под задачу.
Писать реальные проекты на чистой функциональщине надо сильно упороться. Это редко в каких кейсах преимущества дает.
Вас еще не замонали споры на тему ОПП vs функциональщина?
Как раз таки замонали. Поэтому ФП и больше нравится, так как сам подход генерирует меньше споров.
Поясню полушуточной картинкой:

А при чем тут SRP? Речь не про одну функцию, а функции.
Чтобы мем был понятен, замените FP -> OOP, Functions -> Classes
Я скорее склоняюсь к версии, что без паттернов ни в ооп, ни без ооп написать ничего не получится. В низкоуровневом коде нужно знать всякие sfinae и raii и как свои примитивы проектировать учитывая их, в ФП без понимания таглес файнала не получится переиспользовать один коннект к БД между запросами, ну и так далее.
То, что причиной и разговоров про паттерны, SOLID, GRASP и т.п., и тотального использования ООП является сложность тематики, и это всё следствия одной причины, а не причина и следствие — таким людям не докажешь. А особенно когда это не единственные варианты следствий, но другие резко более маргинальны и имеют свой фольклор, который перекрывает собой и отменяет всю известную паттернщину.
Предлагайте в комментариях, если только я их не закрыл.
Мартин Фаулер Рефакторинг, по мне, оказалась годной, когда впервые прочел 5 лет назад
В книге Мартин не говорит, что это чистый код. Он лишь переписал чужой код избавившись от дублирования, чтобы на примере показать зло дублирования.
Все-таки речь о книге, срок жизни этих примеров огромен, а времени на их написание вполне достаточно. Код в таких примерах должен быть корректен во всех отношениях. Это не рабочий код, который нужно сделать «здесь и сейчас», и при этом он будет выброшен через неделю.
И догадываться не нужно, в книге ясно написано, что этот код из себя представляет.
В конце книги приведен большой листинг программного кода по всем правилам, вот на его примере и нужно делать критику, иначе — это пустословие и подмена понятий. Это первое, второе — даже в окончательном коде можно сделать улучшения, об этом и говорит автор, что код нужно обновлять периодически. Ну и третье — это не конкретная технология, где есть правильно и неправильно. Это всего навсего рекомендации автора, опытного автора, ОЧЕНЬ опытного, к мнению которого, как минимум, нужно прислушиваться. Ну и напоследок — если критикуешь кого-то, то предложи лучше, а не то какой смысл, возьми его окончательный код — перепиши на свой лад и залей на голосовалку.
P.S. Складывается впечатление, что вы не читали эту книгу. Если не читали, настоятельно рекомендую )
рекомендации автора, опытного автора, ОЧЕНЬ опытного, к мнению которого, как минимум, нужно прислушиватьсяО нет, ктото обидел Гуру в коментах! Надо срочно его защитить
опытного автора, ОЧЕНЬ опытного
А вот можно поподробнее, что автор написал? Вот, Кармак, например, для меня авторитет, я знаю что он сделал, и его заметки о программировании читать очень интересно. А что такого сделал Мартин?
Идеального не существует, поэтому и «идеально чистого кода» тоже. Но это не значит что к нему не надо стремиться.
Однозначно рекомендую книгу к прочтению (но не в секто-подобной ситуации). Поищу что ли в комментариях нормальную критику самой книги.
Чистый Код — это не точка, а вектор. Рекомендовать эту книгу начинающим разработчикам по моему бесперспективно. Настоящую пользу она принесла лично мне, когда я вдоволь успел сам нарефакториться и вот свежие мысли из книги, дали мне новый вектор для рассуждений и улучшений собственного кода. Критерием чистоты стало то, насколько просто читать и изменять мне свой собственный код спустя неделю и месяцы.
Чистый Код не даёт чётких ответов и инструкций о том как нужно всё написать, чтобы было всё чинно благородно и без оговорок. Он лишь задаёт вектор в этом направлении, полном компромиссов, граблей, костылей и прочих соглашений с совестью. Книга не устанавливает чёткие правила, следуя которым всё точно будет идеально, а лишь расширяет мышление по этому поводу. А главное эта книга — кладезь чужого многолетнего опыта с обширной практикой — это просто интересно само по себе.
Рекомендую именно эту книгу, но не раньше чем читатель сам получит опыт рефакторинга и вдоволь намучается с пониманием своего собственного кода. Иначе последствия чтения могут вылиться в подобную статью или культ карго.
Автору поста желаю и дальше совершенствовать свой навык рефакторинга, получать новый опыт и написать свою книгу с примерами на любом удобном языке, который не потеряет актуальность через года. Надеюсь к своей книге вы отнесётесь с аналогичной критичностью и выпустите в свет только идеальную книгу которая всё учитывает. (в последнем я сомневаюсь, но а вдруг?)
ЗЫ Совершенный Код рекомендую тем кто любит диаграммы, графики, стрелочки и прочие схемы. В чистом коде их практически нет. Лично мне не зашёл.
Код до моих правок (плохой код):
if FPriceSet.CurrentOverrideSPOID > 0 then
i := cont.IndexOverrideSPOByID(FPriceSet.CurrentOverrideSPOID)
else
i := 0;
if i > 0 then
begin
Delta := cont.Price - cont.OverrideContainers[i].Price;
if Delta > 0 Then
Font_Color := clRed
else
if Delta < 0 Then
Font_Color := clBlue
else
Font_Color := clOlive;
end;Код после моих правок (хороший код):
if FPriceSet.CurrentOverrideSPOID > 0 then
begin
i := cont.IndexOvrSPOByID(FPriceSet.CurrentOverrideSPOID,IsY);
if i > 0 then
begin
Delta := cont.Price - cont.OvrContainers(i,IsY).Price;
Font_Color := clOlive;
if Delta > 0 Then Font_Color := clRed;
if Delta < 0 Then Font_Color := clBlue;
end;
end;Значение переменной i ниже данного фрагмента не используется, Font_Color и i — локальные переменные.
Что касается ООП-баталий в комментариях к этой теме.
Помните! Производительность программиста в день, и количество ошибок на количество строк, от языка программирования не зависит! Умножая объём текста, вы умножаете количество багов.
Чем этот код хорош? В сравнениях delta c нулём у вас на 1 присваивание больше, и в некоторых случаях на 1 сравнение больше. Потом, компилятор (вроде бы уже) проверяет присваивания в переменную по всем ветвям выполнения, и безусловное присваивание clOlive может спровоцировать ошибку далее, которую отловил бы компилятор (ругнулся бы warning'ом) в первом случае.
if. Если же от них отказаться, то вот такой вот код будет иметь то же количество строк и, как мне кажется, будет понятнее:if FPriceSet.CurrentOverrideSPOID > 0 then begin
i := cont.IndexOvrSPOByID(FPriceSet.CurrentOverrideSPOID,IsY);
if i > - then begin
Delta := cont.Price - cont.OvrContainers(i,IsY).Price;
if Delta > 0 then begin
Font_Color := clRed;
else if Delta < 0 then begin
Font_Color := clBlue;
else begin
Font_Color := clOlive;
end;
end;
end;
Вот и вы внесли две ошибки — забыли написать два end.
А для чего здесь лишние else?
else не лишние. Когда вы проверяете 1й раз Delta>0 и получаете true, то 2я проверка Delta<0 бессмысленна и лишняя, и программа в идеале должна вторую проверку пропустить. Код выше отражает эту логику 1-в-1.
Вот и вы внесли две ошибки — забыли написать два end.
Не все помнят синтаксис не самого распространённого языка. Но суть верна. Последние 'begin','end' в условии тоже не обязательны.
Почему тогда не использовать:
case Sign(Delta) of
-1: Font_Color := clBlue;
0: Font_Color := clOlive;
1: Font_Color := clRed;
end;По моим сведениям 10-летней давности, case выигрывает по скорости у if, если вариантов много и аргумент это byte либо перечисляемый с <=256 вариантов. Для размеров exe, case не полезен.
Если у вас такие проблемы с перфомансом, взяли бы тот же раст. Уверен, что llvm на порядок лучше оптимизирует чем паскаль компилятор. Про удобство тоже молчу, match всегда по скорости такой же как if потому что компилятор не будет компилировать в дорогостоящие джампы матч с малым количеством вариантов, а сгенерирует ифы.
Уверен, что llvm на порядок лучше оптимизирует чем паскаль компилятор.LLVM лучше оптимизирует, чем LLVM? Это, я извиняюсь, как?
Ну да, Delphi использует чуть более старую версию. Но разница невелика. И не всегда в пользу более новой, кстати…
Не рассказывайте сказок… или ссылку на godbolt, пожалуйста. Не сворачивает это clang пока, не сворачивает.
Хотя может в Rust по-другому, более эффективно
sign можно написать? Или match? Полный пример можно?В clang действительно полный швах со
switchом. В GCC, кстати, большой разницы нету, но и Delphi и Rust используют LLVM, не GCC.LLVM лучше оптимизирует, чем LLVM? Это, я извиняюсь, как?
ХМ, любопытно. Ну тогда могу посоветовать сменить бекенд, не думаю, что ребята им пользуются.
Не рассказывайте сказок… или ссылку на godbolt, пожалуйста. Не сворачивает это clang пока, не сворачивает.
А вы с чем сравниваете? Какой паскаль компилятор аткой код сварачивает?
Хотя может в Rust по-другому, более эффективно sign можно написать? Или match? Полный пример можно?
Пример мог бы, если бы понимал, Как функция работает. Потому что я думал что Font_Color это имя функции и тогда она не определена если i == 0. Если это какой-то объект мутируется, тогда понятнее уже.
Какой паскаль компилятор аткой код сварачивает?Никакой, как я понимаю. Вернее GPC умеет — но пользоваться сегодня продуктом, последняя версия которого вышла более 10 лет назад… я бы не рекомендовал.
Если это какой-то объект мутируется, тогда понятнее уже.Автор сего творения явно написал, что там локальная переменная. Но я придерживаюсь мнения, что мы код не на выставку каллиграфии посылаем, а с ошибками боремся (это, по опыту, всегда занимает больше времени чем исходное написание кода). А потому если есть два похожих варианта, один «красивый (с точки зрения каллиграфии), но иногда медленный», а другой «не слишком красивый (с точки зрения каллиграфии), но всегда быстрый», то я предпочту всегда использовать второй, чтобы не напрягать ни себя, ни ревьюера лишними размышлениями. К примеру
for (i = A; i < B; ++i) я пишу именно так, хотя многим i++ нравится, чисто эстетически, больше — и для простых переменных разницы нету.Пример мог бы, если бы понимал, Как функция работает.Хотя бы банальную функцию, которую я написал — из числа в число — изобразите.
Хотя бы банальную функцию, которую я написал — из числа в число — изобразите.
Что-то такое? https://rust.godbolt.org/z/ik9cxw
А потому если есть два похожих варианта, один «красивый (с точки зрения каллиграфии), но иногда медленный», а другой «не слишком красивый (с точки зрения каллиграфии), но всегда быстрый», то я предпочту всегда использовать второй, чтобы не напрягать ни себя, ни ревьюера лишними размышлениями.
А я предпочту тот, который лучше передаёт намерения. И я напишу i = x % 2 а не i = x & 1, когда мне нужно проверить факт чётности числа.
LLVM лучше оптимизирует, чем LLVM? Это, я извиняюсь, как?
Delphi при компиляции под винду, увы, не использует LLVM, и оптимизации в нём так себе. По вашей ссылке:
LLVM-based Delphi compilers are DCCIOSARM (32-bit iOS), DCCIOSARM64 (64-bit iOS), DCCAARM (Android), DCCAARM64 (64-bit Android), and DCCLINUX64 (Linux).
В расте будет точно так же как в LLVM, чудес же не бывает :)
switch плохо работает в Clang — LLVM или, собственно, сам Clang.Знаю только что это у него застарелая беда — просто если лет 5 назад это был просто кошмар, то сегодня результат «чуть хуже, чем серия из 2-3
ifов». Если вариантов больше 5-6 — то тут серия ifов уже стабильно проигрывает.В GCC этой проблемы почему-то нет (хотя может в прошлом веке была, я не знаю).
Вы что на делфи под суровый ембеддед пишите?
так у вас же память в таком случае занимают в основном данные а не код.
Про размер exe. Есть конторы, которые начали с простого exe с четыремя формами, а затем 15 лет не меняли архитектуры. У таких фирм exe файл уже >100мб весит, его запаковывают перед тем как отдавать пользователям. Это пример когда важен размер exe.
- а чем помогла бы переделка архитектуры?
- Щас проверил, JetBrains Rider 2020.1.3 весит 2 340 908 716 байт, и не слышал чтобы кто-то жаловался. Студия в полной установке — 120гб что ли, хотя её в таком виде никто не ставит конечно
2) Пример 1. Крупнейший негосударственный банк. Проблема: из-за обилия функционала, exe чрезмерно разросся. Решение: exe оставили маленьким, весь функционал перенесли в .bpl, каждый сотрудник подгружает только нужные ему .bpl в процессе работы.
Пример 2. Крупнейшая российская туркомпания. exe разросся до >100мб. Решение: перед выпуском, упаковывают его специальным архиватором. Всё равно, те офисы которые сидят на 3G интернете, тратят на апдейт существенное время. Это простой и потеря клиентов.
Задача апдейта по сети решается легче патчами. Когда качается не вся новая версия, а только измененные куски. Например, для двухгигабайтного райдера патч составляет 5-50 мегабайт.
- есть инструменты
- линковать всё приложение в гигантский 100мегабайтный экзешник не всегда хорошая идея. А заменять отдельные dll куда проще.
Price у вас целое число или с плавающей точкой? Если второе, то разница будет совершенно незаметной (вот бенчмарк на скорую руку).
Вот и вы внесли две ошибки — забыли написать два end.И что характерно — на исправление обоих уйдёт несколько секунд. А вот сколько времени уйдёт у вас не то, чтобы исправить проблему с пропущенным
else в первом варианте?До эффектов, которых, в деле «улучшения» кода достигла Apple я не дорос, но мне хватило одного, примерно недельного, расследования для того, чтобы понять: экономия на фигурных скобках (
begin/end в Pascal) — себя не оправдывает. Они должны ставиться во всех структурных операторах. Без исключения. Без вариантов. Всегда.И да, иногда я теряю одну из скобочек. Ещё ни разу, за много лет, такая ошибка не выживала дольше, чем до запуска компилятора. И ни разу не приводила к многочасовым сеансам отладки.
А для чего здесь лишние else?Потому что SSA упрощает понимание кода не только компилятором. В вашем случае переменная меняет своё значение два раза, а если были бы другие условия — моглы бы и три раза это сделать. В моём случае гарантируется, что это произойдёт один раз. И да, в данном конкретном случае это не так важно, но, опять-таки следование одному простому правили всегда (вместо того, чтобы «художественно выбирать» как именно, данном, конкретном случае, стоит сделать) — в конечном итоге упрощает жизнь.
P.S. Это немного похоже на внедрение в команде
clang-format (кстати у Delphi уже есть аналог?): пока его нет — вопросы как лучше записать перечисление 42 элементов (в несколько строк или в столбик?) могут вылиться буквально в часы дискуссий. Если clang-format есть — то всё, дискуссии окончены: как он расставит, так и будет. Пусть даже и, по мнению кого-то (часто даже, кстати, меня) — он это делает некрасиво. Зато всегда одинаково — и спорить не о чем.Очевидно, что действия по жарке стейка из морозилки и из живой коровы — это разные действия. Плох тот повар, который в обоих случаях действует одинаково.
P.S. Не знаю что такое clang-format, в Delphi есть Ctrl+D — автоформатирование.
Потому что SSA упрощает понимание кода не только компилятором.Кстати, а компилятору не нравятся, когда default выносят перед циклом? Т.е.вариант
ret = 0;
if cmp_val < 8, ret = 8;
else if cmp_val > 15, ret = 99;
end
return ret;
оптимизируется хуже, чемif cmp_val < 8, ret = 8;
else if cmp_val > 15, ret = 99;
else ret = 0;
end
return ret;
?Если ret — локальная переменная, то компилятору должно быть не важно (хотя в том же LLVM для достижения этого самого "не важно" требуется отдельный проход).
А вот мне как программисту второй вариант воспринимать проще.
Но в сложных случаях (проперти, сложные конструкции «слева» и прочее), конечно, одно присваивание лучше, а потому, чтобы не умножать сущности, этот вариант и нужно применять.
Оставьте микрооптимизации компилятору где можно!
В идеале конечно это должен быть какой-то матчинг с проверкой полноты. Но нам бы хоть от языков 70х уйти до конца.
Но это всё крайней субъективно, на самом деле.
Да, это субъективно. Мне, например, наоборот, значительно легче читать текст с программы с однострочными if, если в if — один оператор, а не c многострочными конструкции с операторными скобками (особенно — с такими тяжеловесными, как begin/end в Pascal): во-первых, в поле зрения помещается больше имеющего смысловую значимость текста программы, во-вторых, при перемещении по тексту глаз легче находит реперные точки — нет этих однообразных begin и end.
Но, опять-таки — это всё субъективно.
PS А вообще мне кажется, что и исходный, и учлучшенный варианты одинаково хороши (ну, или для критиков — одинаково плохи). Я бы пожалел тратить время на такую переделку — если это единственная переделка и если она не вызвана внешней причиной вроде руководства по стилю программирования, принятому в проекте.
1) Количеством машинных команд, которые добавляются в exe файл.
2) Количеством строк исходника
2) Количеством строк исходникаВот только тот факт, что строк стало меньше не означает, автоматически, что код стало читать проще.
Посмотрите на код на каких-нибудь конкурсах. Вот тут, недавно, статья была.
Прошёл по вашей ссылке, там такие строки:
var mat_product_symbolic = B => `(a,b)=>[${reshape(range(16),4).map(c=>B[0].map((_,i)=> B.reduce((s,d,j)=>`${s}+b[${d[i]}]*a[${c[j]}]`,0))).flat()}]`;У автора этих строк, очевидно, не стояло задачи, чтобы их было легко читать.
Первый проект подозреваю спасли 3 месяца осмысленной работы а не книжка )
Ну я лично читал чистый код на 2-3 курсе универа, ещё до того как на работу пошёл. И именно тогда он мне показался максимально полезным, а для студента менторский ультимативный тон выходит не такой раздражительный. А через 3 года, то есть к концу универа и второй работы, уже казалось весьма капитанским, да.
Вероятно, хватит рекомендовать «Чистый код»