Comments 66
Очень толковая статья философско-архитектурного плана, надо будет ещё многое осмыслить, тут одним чтением явно не ограничиться. Пишу на ансибл много, видел и много статей прикладного уровня, но вот такое структурное осмысление пожалуй впервые на хабре вижу.
Очень жаль, что тематика узкая и статья выйдет недооценённой, это явно одна из лучших закладок по теме будет, к которой ещё не раз будут возвращаться желающие осмыслить свой опыт написания плейбуков. (Кстати, да: а почему в женском роде? "плейбука" как "базука", мне вот интуитивно хочется сказать в мужском: "этот плейбук", а не "эта плейбука".)
Жду продолжения, пока буду вертеть в голове и обдумывать уже написанное.
Бук — книга — она.
Интересно, склонения по родам в рунглише — дело вкуса или есть каноничный вариант?
"плейбука" приятнее произносить и склонять, чем "плейбук". Как native speaker, я настаиваю.
В русском языке нет слова "плейбук" или "плейбука", это калька с английского, которая сейчас имеет статус профессионального жаргонизма. Какой при этом у слова образуется род решается носителями языка (к которым я отношусь) в процессе словоупотребления. Вы вольны предлагать свою версию, и лишь практика и время покажет, какой вариант приживётся.
Я использую такие формы, с которыми удобно работать. Это причина, почему я не транслитерирую play, потому что мне его склонения не нравятся.
Если честно, то про сущность play я читаю в первый раз =). Однако то что я в первую очередь админ, а уже во вторую программист, позволило не совершить описанных ошибок. Потому что я давно погружен в эту предметную область =).
Интересно будет почитать остальные части.
Если вы написали хотя бы одну плейбуку в своей жизни и первый раз слышите слово "play", это означает, что документацию вы пролистнули не фокусируясь на написанном. https://docs.ansible.com/ansible/latest/user_guide/playbooks_intro.html#about-playbooks:
Each playbook is composed of one or more ‘plays’ in a list.
The goal of a play is to map a group of hosts to some well defined roles, represented by things ansible calls tasks. At a basic level, a task is nothing more than a call to an ansible module.
By composing a playbook of multiple ‘plays’, it is possible to orchestrate multi-machine deployments, running certain steps on all machines in the webservers group, then certain steps on the database server group, then more commands back on the webservers group, etc.
Насчёт "программистов" вы неправы. Я основываюсь на большом опыте ревью и работы с очень опытными администраторами в команде — ошибки с control flow делают все. Я тоже делал, и мне потребовалось несколько лет, чтобы почувствовать дзен простого Ансибла.
Если вы написали хотя бы одну плейбуку в своей жизни и первый раз слышите слово «play», это означает, что документацию вы пролистнули не фокусируясь на написанном.
Все почти так + плохое знание английского. Я и сейчас не воспринял кавычки как обозначение термина =).
Это не тонны документации, это 101 ansible'а.
что такое 101?
Первый курс института по американской системе нумерации предметов. https://www.urbandictionary.com/define.php?term=101
Он говорил, что пишет на Ансибле и это его основная деятельность на текущем месте работы. Если бы он сказал, что Ансибл знает поверхностно, то я бы просто перешёл к другим вопросам. Доучить Ансибл — не проблема, проблема в том, что человек использует инструмент как основной и не знает его.
Это как если бы программист, который говорил, что пишет на питоне, не мог бы сказать, что такое "модуль", или верстальщик на html не знал, что такое "тег".
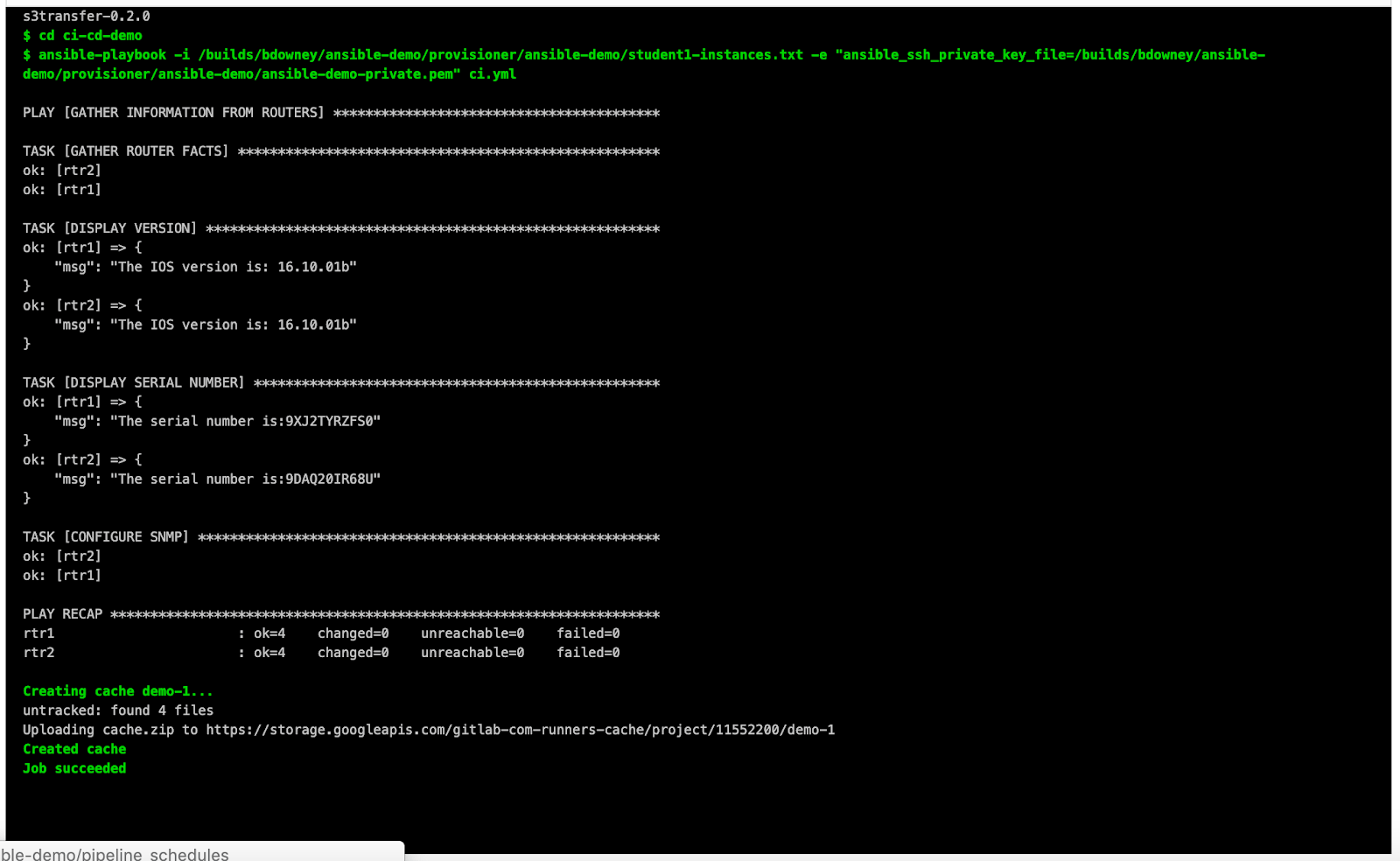
Вот вам типичный лог Ансибла который вы наверное миллион раз видели. Видите там сущность «плей»?
delegate_to имеет несколько очень хороших случаев применения (обычно в отношении гипервизор/vm, хост и "его управляющая машина"). When имеет определённый смысл. Во-первых это двухходовочка для имитации идемпотентности (query, do/when), во-вторых, один из потрясающе полезных трюков, которые я часто использую, это meta: end_host when: nothing else to do. — позволяет исключить тонны skip'ов в выводе.
В целом, и я буду писать отдельный лонгрид про это, Ансибл не всеобъемлющий и надо знать когда остановиться и переходить на модули/скрипты и т.д. Неумение остановиться вовремя (точнее, не знание где остановиться) — это третья критическая ошибка при использовании Ансибла, когда каждется, что "вот сейчас я в этом словаре найду ключ и по нему найду в другом списке словарь и там будет имя по которому я смогу найти IP, и тогда оно заработает". А надо не пытаться дальше, а остановиться и использовать другие инструменты.
Удивительно, но обычная документация ансибла достаточно хороша. Есть такая проблема онбординга, что люди не хотят фокусироваться на простом и сразу прыгают в самое сложное (отношения хостов/переменных, обычно видно в паттерне "настроить СУБД и клиента"). На самом деле, просто начинайте писать простые вещи. Плейбука из одной плей, внутри которой 4 таски — отличное начало.
Например, вы всегда ставите на сервер комплект нужного вам софта и (например) копируете свой bashrc. Вот и напишите плейбуку, которая это делает.
По чуть-чуть, по чуть-чуть. Меньше ролей, больше простых tasks. Дзен Ансибла в том, чтобы сохранять простоту.
Я вообще пишу single-play playbooks в основном и только на ролях, никаких тасков, но у меня и задачи соответствующие…
Когда смотришь даже в корпоративных плейбуки — волосы шевелятся. Или груда кода, или все предельно переусложнено и для того, чтобы понять простую роль надо обежать кучу файлов.
Вот как раз корпоративные плейбуки чаще всего и есть самый большой ужас. Как и любой другой код с малым уровнем peer pressure.
Мы в отделе сейчас нарабатываем практики, и у нас есть пара пет-проектов в которых мы стараемся делать так хорошо, как можем. И там всё очень, очень просто. Линейный код, минимум переменных, две с половиной выкрутасы (одна из которых решает проблему группировок, вторая уменьшает скипы).
Когда мы одну из них доведём до совершенства, можно будет поговорить про публикацию. Там нет никаких бизнес-секретов, а вот пример хорошего ансибла — есть.
Я их трогал до появления коллекций и у меня они не взлетели. Но это было очень давно, я не могу оценить своё впечатление тогда как правильную оценку сегодня.
Сейчас я сходу ткнулся — https://github.com/debops/debops/blob/master/ansible/roles/apache/tasks/main.yml
У них могут быть причины, но в целом я не одобряю такой стиль:
- name: Enable/disable configuration snippets
file:
path: '{{ apache__config_path + "/conf-enabled/" + item.key + ".conf" }}'
src: '../conf-available/{{ item.key }}.conf'
force: '{{ ansible_check_mode|d() | bool }}'
state: '{{ (((item.value.enabled|d(True)
if (item.value is mapping)
else item.value|d(True)))
if (item.value.state|d("present") != "absent")
else False) | bool | ternary("link", "absent") }}'
when: (item.value.type|d("default") not in ["divert"])
with_dict: '{{ apache__combined_snippets }}'
notify: [ 'Test apache and reload' ]Требуется невероятная собранность опытного перловода, чтобы такое прочитать. Возможно, у них есть важные причины писать так, проект большой. Но за best practices я это считать не могу.
(А ещё они не пройдут линтер).
Да условия выглядят жутко если уровень вложенности больше 1-го, но это же проблема шаблонизатора.
Хотелось бы авторитетного мнения по поводу структуры, подходов и прочей архитектуры.
По поводу таких сборных переменных тоже хотелось бы услышать
apache__combined_snippets: '{{ apache__dependent_snippets
| combine(apache__role_snippets)
| combine(apache__snippets)
| combine(apache__group_snippets)
| combine(apache__host_snippets) }}'Я увидел 'True' с большой буквы. На такое ругаются (в yaml true пишется с маленькой, а True — это синоним on, yes и т.д.).
Что касается сборки переменных вместе, паттерн со снипеттами у меня вызывает наименьшие вопросы, если нет нормального conf.d, это один из методов написать разумного размера роли.
А вот математику в 'state' (в примере выше) я бы на ревью не принял.
даже в корпоративных плейбукипочему «даже»? Их обычно мало человек пишет и еще меньше в них смотрит, так что там «обычно» всё ужасно, «лишь бы работало». А вот когда от коммьюнити что-то ансибловое — там есть шанс наткнутся на нормально сделанное.
meta: flush_handlers не плохое, но это "затычка". Идеальный вариант, если плейбука структурирована так, что handler'ы отрабатывают сами собой. Например, если роль2 зависит от хэндлера роль1, то можно плей порезать на две, в первой роль1, во второй роль2, и всё отработает само, без flush'ей.
… А handler'ы и ошибки — это вообще тёмные углы Ansible, в которые лучше не ходить. Во-первых хэндлеры — это попытка "спрятать" неидемпотентные рестарты. Что, довольно успешно делается, если всё хорошо. Но если у нас сбой, то возникает проблема: у нас неидемпотентная операция, которая зависит от стейта в памяти у программы. Программа закончилась ошибкой, стейт потерян.
Иногда это ок. Иногда — остро не "ок", потому что процесс (в продакшене) остался со старой версией, а новые прогоны ансибла говорят "ok" с 0 changed.
… И тут начинается проблема распределённых систем, когда нельзя ничего сделать "once". Либо at least once, либо at most once. Хэндлеры работают в режиме at most once.
Если нужно at least once (гарантированный рестарт, но, может быть, больше одного раза), то я такое изобретал (давным-давно). Вот как-то так: https://medium.com/@george.shuklin/handling-handlers-for-ansible-88b0c91515a4 (глава surviving failures). Это было давно, возможно, там у меня грязный Ансибл внутри.
Но тотальной функции для рестартов быть не может, увы.
У меня есть пример, где использование flush кажется уместным. Роль (допустим из galaxy) настраивает некий сервис, в ней предусмотрен хэндлер reload при изменении конфига. Хочу прогонять play по одному хосту, делая паузу и ожидания от оператора, что сервис с новым конфигом стартовал и работает ОК. Получается такой плей:
serial: 1
roles:
- setup_service
post_tasks:
- name: Flush handlers (e.g. reload service when needed)
meta: flush_handlers
# FIXME: don't ask for confirmation after last host in batch
- pause:
prompt: "Check that SERVICE is properly running on {{ inventory_hostname }} before we proceed to next host. Type YES when done."
register: prompt_result
failed_when: 'prompt_result.user_input != "YES"'без flush после прогона первого хоста prompt возникает без reload сервиса.
У вас будет flush после выполнения роли и так и так. Перечитайте: flush делается после выполнения каждой секции — pre_tasks, roles и post_tasks.
Т.е. в вашем случае первая post_tasks 'meta: flush_handlers' всегда ничего не делает. А flush делается по факту завершения списка ролей.
(хотя, возможно, с serial: 1 это не так, но я бы счёл это багой).
Ну вот может бага serial:1, но пока я не добавил flush, для сервиса не вызывался reload перед pause.
Аж перепроверил. Неправда, всё выполняется как я написал. (2.9.16)
├── play.yaml
└── role1
├── handlers
│ └── main.yaml
└── tasks
└── main.yamlfind -type f -name "*.yaml"|xargs -n1 --verbose cat
cat ./play.yaml
---
- hosts: localhost,127.0.0.1
gather_facts: false
serial: 1
roles:
- role1
post_tasks:
- pause:
prompt: "Check that SERVICE is properly running on {{ inventory_hostname }} before we proceed to next host. Type YES when done."
register: prompt_result
cat ./role1/tasks/main.yaml
---
- debug:
changed_when: true
notify: h1
cat ./role1/handlers/main.yaml
---
- name: h1
debug: msg=handlerУтащил в закладки. Спасибо большое
Спасибо за статью. Все мои плейбуки односложные
- hosts: nginx
Roles: — nginx
В роли собственно происходит раскатка конфига и поднятие докер контейнера с nginx. Все вроде бы просто. Но так как разные окружения требуют разных портов, разных конфигов того же nginx, то с переменными явно перебор, как красивее организовать хранение переменных? Сейчас это отдельная папка на уровне инвентори. Кстати как проще конфигурить разные окружения? Сейчас это фактически разные инвентори со своими переменными в папке на том же уровне. А про инвентори это yaml или все же ini? Надеюсь в след.статье коснетесь этого. Имхо ini по-приятнее и не надо писать отдельно vars, что придает более табличный вид нежели списочный, сами переменные хостов справа от его объявления.
Переменные должны отражать связь между объектами в плейбуке или с внешним миром (если инвентори вам кто-то другой генерирует). Частично вы можете задавать переменные в play (например, связка nginx+grafana использует одни порты, nginx+apache2 — другие). Частично — выносить в group_vars для плейбук (но надо понимать зачем). Если что-то очень специальное для инсталляции — в инвентори. Если "может быть другим, но кому менять не понятно" — в defaults роли, или даже константами.
Тут есть большое враньё. Ансибл приложил много усилий, чтобы обмануть нас, но враньё всё равно иногда сквозит.
Любой хэндлер — враньё. Если плейбука сломается между выполнением changed и соответствущим handler, то второй прогон идемпотентно не сделает этот handler.
А причина — в том, что restart не может быть идемпотентный.
враньё всё равно иногда сквозит
Для этого есть технический термин: абстракция протекает. :)
Большая ошибка тут в том что вы считаете Ансибл декларативным — декларативна каждая таска в отдельности, плейбук — императивен.
Это зависит от того, как вы его написали. Если у вас нет неявных императивных зависимостей между тасками, то плей будет декларативной. Вот если у вас постоянные when с отсылкой на register от предыдущей таски — вот это да, замаскированное написание модулей для ансибла на ансибле. Такого надо избегать.
-
Спасибо за статью.
А где ещё можно почитать про «вот это лучше делать именно так, потому что …»? Best practices на официальном сайте, увы, не совсем про это.
Статья очень грамотная, но так и не понял одного — почему в одной play не может быть и roles и tasks секций.
В официальной документации есть четкий порядок исполнения секций: сначала roles, потом tasks.
Основы Ansible, без которых ваши плейбуки — комок слипшихся макарон