В личной практике задача разбирать XML средствами PHP возникла еще в 2005. Однако, при попытке разобраться и написать несложный скрипт, загружающий XML-файл в массив, я наткнулся на довольно серьёзную проблему – не существует нормальных программных средств и бинарных библиотек PHP для работы с XML. По мере работы с XML средствами PHP и эволюции PHP применялись различные технологии разбора XML кода, о них далее и пойдет речь.
Сперва приведу сводную таблицу совместимости средств PHP и библиотек XML.
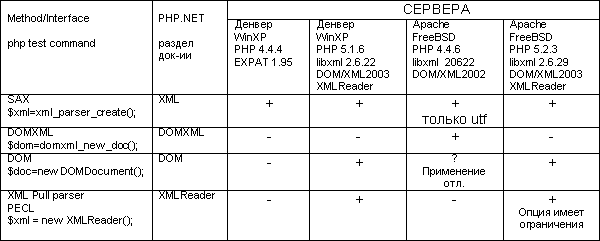
Самым совместимым оказался SAX (Simple API for XML), он поддерживается даже в библиотеке EXPAT имеющейся во всех версиях PHP 4 и выше. Однако его возможности и способы применения вызвали резко негативную реакцию – нет возможности модификации XML, крайне громоздкий и сложный код с большим количеством мест для потенциальных ошибок.
DOMXML ужасная вещь, т.к. существовала в виде дополнительных экспериментальных библиотек для PHP 4. В PHP 5 не включена, т.к. PHP 5 по умолчанию обладает более универсальным средством DOM (Стандарт W3C DOM level 3). DOM наиболее документирован (English PHP & W3C) и завершен, однако не включен в PHP 4, т.к. был разработан только к началу 2006. Если выбор станет DOM или PHP4, однозначно следует сказать DOM, т.к. на сегодняшний день PHP 5 имеется у любого уважающего себя хостинг провайдера. Тем более у разработчика, есть возможность писать PHP 4 совместимый код, т.к. PHP 4 обладает базовой DOM и она поддерживает некоторые основные функции новой DOM.
Существуют ещё дополнительные библиотеки XML-RPC, но они являются экспериментальными, что говорит само за себя – их тестирование и пробы возможны не ранее чем в 2009 году.
В Рунете небыло никакой более-менее полезной литературы на тот момент (осень 2007), все разработчики наповал использовали SAX (часто даже свои библиотеки базирующиеся на SAX) либо DOMXML. О DOM ещё мало кто слышал, а те, кто слышал, отказывались от использования в пользу более старого и менее стандартного, но более привычного DOMXML. Таким образом, имелся крайне низкий уровень реализации и переносимость существующих WEB решений использующих XML. Решение использовать новое, удобное, одобренное W3C средство DOM, было единственно правильным. DOM в PHP по его совместимости и взаимопониманию идентичен DOM'у в JS.
Проведем сравнительный анализ производительности SAX PHP 4 и DOM PHP 5. Будет произведен замер времени разбора следующего XML-файла.

SAX алгоритм разбора
Недостатки этого метода разбора XML очевидны: громоздкость, неудобочитаемость программного кода и необходимость использования глобальных переменных.
Приведем 2 метода разбора того же XML файла, базирующиеся на DOM PHP 5.
Метод 1
Метод использует физическую безадресную навигацию по дереву XML документа.
Метод 2
Метод использует ассоциативно-адресную навигацию по дереву XML документа.
В заключении замечу, что все три алгоритма в результате получают абсолютно идентичные массивы данных:

Тесты производительности алгоритмов производились с учетом следующих условий:
Платформа AMD Athlon(tm) 64 X2 Dual Core Processor 4200+, DDR 2 1024 MB.
Веб-сервер Windows NT 5.1 build 2600, Apache/1.3.33 (Win32) PHP/5.1.6.
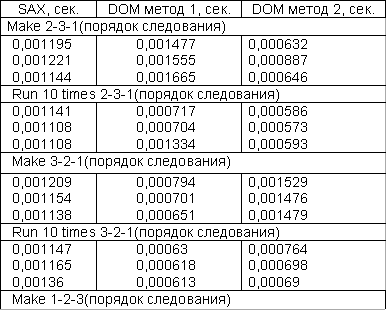
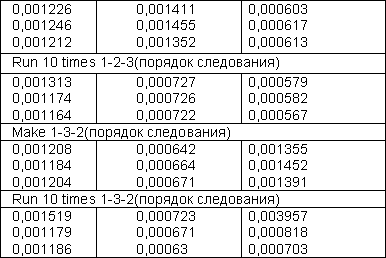

График производительности позволяет сделать следующие заключения: SAX наиболее стабилен и его производительность не зависит ни от положения в теле программы, ни от нагрузки на сервер.
Рассмотрим среднеквадратичные показатели производительности для каждой группы тестов.
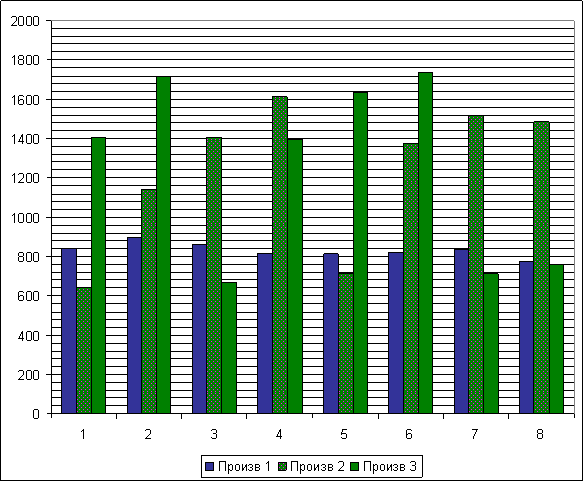
1-SAX Произв 1
2-DOM 1 Произв 2
3-DOM 2 Произв 3
Make — режим сборки, Run 10 times — режим нагрузки.
1)Make 2-3-1(порядок следования)
2)Run 10 times 2-3-1(порядок следования)
3)Make 3-2-1(порядок следования)
4)Run 10 times 3-2-1(порядок следования)
5)Make 1-2-3(порядок следования)
6)Run 10 times 1-2-3(порядок следования)
7)Make 1-3-2(порядок следования)
8)Run 10 times 1-3-2(порядок следования)
Очевидно, что наиболее важным на данном этапе анализа является выявление наиболее производительного метода разбора XML основанного на DOM, SAX не рассматриваем, т.к. его отставание и недостатки очевидны.
Напомню, метод 1 использует физическую безадресную навигацию по дереву XML документа, менее удобочитаем, чем метод 2, который использует ассоциативно-адресную навигацию по дереву XML документа.
Для нас наиболее важны режимы результаты производительности при режимах нагрузки, такими являются четные тесты:

Тесты 2 и 6, тесты в которых метод 1 идет первым, тесты 4 и 8, тесты в которых метод 2 идет первым.
Из графика следует, что при своем удобстве метод 2 достигает наивысших показателей производительности, только при многочисленном использовании XML в программе.
Метод 1, при меньшей лаконичности и пиковой производительности относительно метода 2, является более стабильным в использовании для разбора в единственном месте работы PHP скрипта.
Таким образом, переход на DOM PHP 5, в независимости от способа разбора XML документа, вполне оправдан, как по удобству кода, так и по производительности, тем более, с учетом того, что в настоящее время PHP 4 практически не используется.
Все тесты проводились кустарно, их основной задачей было показать различие а не количественные характеристики производительности того или иного парсера, очевидно, что при грамотной настройке кэширующих механизмов результаты могут отличаться.
Полезная статься о поддержке XML в PHP5 habrahabr.ru/blogs/php/31189
Сперва приведу сводную таблицу совместимости средств PHP и библиотек XML.
Самым совместимым оказался SAX (Simple API for XML), он поддерживается даже в библиотеке EXPAT имеющейся во всех версиях PHP 4 и выше. Однако его возможности и способы применения вызвали резко негативную реакцию – нет возможности модификации XML, крайне громоздкий и сложный код с большим количеством мест для потенциальных ошибок.
DOMXML ужасная вещь, т.к. существовала в виде дополнительных экспериментальных библиотек для PHP 4. В PHP 5 не включена, т.к. PHP 5 по умолчанию обладает более универсальным средством DOM (Стандарт W3C DOM level 3). DOM наиболее документирован (English PHP & W3C) и завершен, однако не включен в PHP 4, т.к. был разработан только к началу 2006. Если выбор станет DOM или PHP4, однозначно следует сказать DOM, т.к. на сегодняшний день PHP 5 имеется у любого уважающего себя хостинг провайдера. Тем более у разработчика, есть возможность писать PHP 4 совместимый код, т.к. PHP 4 обладает базовой DOM и она поддерживает некоторые основные функции новой DOM.
Существуют ещё дополнительные библиотеки XML-RPC, но они являются экспериментальными, что говорит само за себя – их тестирование и пробы возможны не ранее чем в 2009 году.
В Рунете небыло никакой более-менее полезной литературы на тот момент (осень 2007), все разработчики наповал использовали SAX (часто даже свои библиотеки базирующиеся на SAX) либо DOMXML. О DOM ещё мало кто слышал, а те, кто слышал, отказывались от использования в пользу более старого и менее стандартного, но более привычного DOMXML. Таким образом, имелся крайне низкий уровень реализации и переносимость существующих WEB решений использующих XML. Решение использовать новое, удобное, одобренное W3C средство DOM, было единственно правильным. DOM в PHP по его совместимости и взаимопониманию идентичен DOM'у в JS.
Проведем сравнительный анализ производительности SAX PHP 4 и DOM PHP 5. Будет произведен замер времени разбора следующего XML-файла.
SAX алгоритм разбора
// Создаем SAX парсер, который будет использоваться для обработки XML-данных.
$parser = xml_parser_create();
// Регистрируем функции для обработки различных типов
// XML-данных:
// - начальный и конечный тэги XML
xml_set_element_handler($parser,'saxStartElement','saxEndElement');
// - символьные данные
xml_set_character_data_handler($parser,'saxCharacterData');
// Также существуют аналогичные функции для регистрации
// обработчиков других типов XML-данных.
// Убираем case folding, в этом случае имена тэгов будут
// передаваться обработчикам в оригинальном виде. Если case
// folding включен, то все имена тегов будут переведены
// в верхний регистр.
xml_parser_set_option($parser,XML_OPTION_CASE_FOLDING,false);
// Получаем содержимое XML-файла с сылками.
$xml = join('',file($link_file));
// Производим парсинг (разбор) полученного XML-файла.
// В процессе разбора парсер будет вызывать описанные нами
// функции и в результате мы получим массив $news,
// содержащий новости из XML-файла.
$GLOBALS['sax']['links'] = array(); // В этом массиве будут храниться блоки ссылок, полученные из XML файла
$GLOBALS['sax']['current_linksblock']=null;// Текущий блок ссылок. Используется в процессе импорта данных
$GLOBALS['sax']['page_r'] =0;
$GLOBALS['sax']['page_i'] =-1;
$GLOBALS['sax']['link_r'] =0;
$GLOBALS['sax']['link_i'] =-1;
$GLOBALS['sax']['index'] =null;// Текущий индекс в массиве ссылок.
// Используется в процессе импорта данных
if (xml_parse($parser,$xml,true))
// Уничтожаем парсер, освобождая занятые им ресурсы
xml_parser_free($parser);
//else
// Парсер возвращает значение FALSE, если произошла
// какая-либо ошибка. В этом случае мы также прекращаем
// выполнение скрипта и возвращаем ошибку.
// die(sprintf('AOW - Ошибка XML: %s в строке %d',
// xml_error_string(xml_get_error_code($parser)),
// xml_get_current_line_number($parser)));
//Получили массив из XML $GLOBALS['sax']['links']; содержащий полный набор необходимых данных
dbg($GLOBALS['sax']['links'],"results");
//-------------------------------------------------------------------------------------
// Функции, описанные ниже, являются обработчиками различных типов
// XML-данных и будут вызываться парсером в процессе разбора.
//-------------------------------------------------------------------------------------
// Функция для обработки начальных тегов XML
// На входе:
// - указатель на SAX парсер
// - имя XML тега
// - массив аттрибутов
function saxStartElement($parser,$name,$attrs){
switch($name){
case 'links':
// Тег links содержит все блоки ссылок. Мы должны подготовить
// массив $links для приема из XML файла.
$GLOBALS['sax']['links'] = array();
break;
case 'linksblock':
// Каждый блок ссылок находится в теге linksblock. Подготавливаем массив
// $GLOBALS['current_linksblock'] для приема
$GLOBALS['sax']['current_linksblock'] = array("page" => array(), "link" => array());
$GLOBALS['sax']['page_r'] =0;
$GLOBALS['sax']['link_r'] =0;
$GLOBALS['sax']['page_i'] =-1;
$GLOBALS['sax']['link_i'] =-1;
// Если у новости есть random - сохраняем его в массиве
if (isset($attrs))
$GLOBALS['sax']['current_linksblock']['attributes'] = $attrs;
break;
case 'page':
$GLOBALS['sax']['page_r']=1;
$GLOBALS['sax']['page_i']++;
$GLOBALS['sax']['current_linksblock']['page'][$GLOBALS['sax']['page_i']]="";
break;
case 'link':
$GLOBALS['sax']['link_r']=1;
$GLOBALS['sax']['link_i']++;
$GLOBALS['sax']['current_linksblock']['link'][$GLOBALS['sax']['link_i']]="";
break;
};
}
//-------------------------------------------------------------------------------------
// Функция для обработки конечных тегов XML
// На входе:
// - указатель на SAX парсер
// - имя XML тега
function saxEndElement($parser,$name){
if ((is_array($GLOBALS['sax']['current_linksblock'])) && ($name=='linksblock')){
// Если в данный момент у нас есть массив $GLOBALS['current_linksblock']
// что данные для этого блока кончились и мы можем поместить готовый блок в массив ссылок.
$GLOBALS['sax']['links'][] = $GLOBALS['sax']['current_linksblock'];
$GLOBALS['sax']['current_linksblock'] = null;
} elseif($name=='page') {
$GLOBALS['sax']['page_r'] =0;
} elseif($name=='link') {
$GLOBALS['sax']['link_r'] =0;
}
}
// Функция для обработки символьных данных
// На входе:
// - указатель на SAX парсер
// - символьные данные XML
function saxCharacterData($parser,$data){
// Мы принимаем только данные для блоков ссылок, помещенные в
// какой-нибудь тег. Все остальные символьные данные
// (как правило это пустое пространство, использованное
// для форматирования) мы опускаем за ненадобностью.
if (is_array($GLOBALS['sax']['current_linksblock'])){
//Если открыт тег page то пишем в массив строки, склеивая их
if($GLOBALS['sax']['page_r']) {
$GLOBALS['sax']['current_linksblock']['page'][$GLOBALS['sax']['page_i']].= iconv("UTF-8", "windows-1251", $data);
} elseif($GLOBALS['sax']['link_r']) {
//Если открыт тег link то пишем в массив строки, склеивая их
$GLOBALS['sax']['current_linksblock']['link'][$GLOBALS['sax']['link_i']].= iconv("UTF-8", "windows-1251", $data);
}
}
}
//-------------------------------------------------------------------------------------Недостатки этого метода разбора XML очевидны: громоздкость, неудобочитаемость программного кода и необходимость использования глобальных переменных.
Приведем 2 метода разбора того же XML файла, базирующиеся на DOM PHP 5.
Метод 1
/* here we must specify the version of XML : i.e: 1.0 */
$xml = new DomDocument('1.0');
$xml->load($link_file);
$linksblocksa = array();
$i=0;
foreach($xml->documentElement->childNodes as $XMLlinksblock){
if ($XMLlinksblock->nodeType == 1 && $XMLlinksblock->nodeName == "linksblock"){
$linksblocksa[$i]['attributes']=array();
foreach($XMLlinksblock->attributes as $attr)
$linksblocksa[$i]['attributes'][$attr->name]= $attr->value;
foreach($XMLlinksblock->childNodes as $node){
if ($node->nodeType == 1 && $node->nodeName == "page")
$linksblocksa[$i]['page'][]= $node->nodeValue;
elseif($node->nodeType == 1 && $node->nodeName == "link")
$linksblocksa[$i]['link'][]= iconv("UTF-8", $GLOBALS['E_server_encoding'], $node->nodeValue);
}
$i++;
}
}
unset($xml);
dbg($linksblocksa,"linksblocksa");Метод использует физическую безадресную навигацию по дереву XML документа.
Метод 2
/* here we must specify the version of XML : i.e: 1.0 */
$xml = new DomDocument('1.0');
$xml->load($link_file);
$linksblocksb = array();
$i=0;
foreach($xml->getElementsByTagName('linksblock') as $XMLlinksblock){
$linksblocksb[$i]['attributes']=array();
foreach($XMLlinksblock->attributes as $attr)
$linksblocksb[$i]['attributes'][$attr->name]= $attr->value;
foreach($XMLlinksblock->getElementsByTagName('page') as $page)
$linksblocksb[$i]['page'][]= $page->nodeValue;
foreach($XMLlinksblock->getElementsByTagName('link') as $link)
$linksblocksb[$i]['link'][]= iconv("UTF-8", $GLOBALS['E_server_encoding'], $link->nodeValue);
$i++;
}
unset($xml);
dbg($linksblocksb,"linksblocksb");Метод использует ассоциативно-адресную навигацию по дереву XML документа.
В заключении замечу, что все три алгоритма в результате получают абсолютно идентичные массивы данных:
Тесты производительности алгоритмов производились с учетом следующих условий:
Платформа AMD Athlon(tm) 64 X2 Dual Core Processor 4200+, DDR 2 1024 MB.
Веб-сервер Windows NT 5.1 build 2600, Apache/1.3.33 (Win32) PHP/5.1.6.
График производительности позволяет сделать следующие заключения: SAX наиболее стабилен и его производительность не зависит ни от положения в теле программы, ни от нагрузки на сервер.
Рассмотрим среднеквадратичные показатели производительности для каждой группы тестов.
1-SAX Произв 1
2-DOM 1 Произв 2
3-DOM 2 Произв 3
Make — режим сборки, Run 10 times — режим нагрузки.
1)Make 2-3-1(порядок следования)
2)Run 10 times 2-3-1(порядок следования)
3)Make 3-2-1(порядок следования)
4)Run 10 times 3-2-1(порядок следования)
5)Make 1-2-3(порядок следования)
6)Run 10 times 1-2-3(порядок следования)
7)Make 1-3-2(порядок следования)
8)Run 10 times 1-3-2(порядок следования)
Очевидно, что наиболее важным на данном этапе анализа является выявление наиболее производительного метода разбора XML основанного на DOM, SAX не рассматриваем, т.к. его отставание и недостатки очевидны.
Напомню, метод 1 использует физическую безадресную навигацию по дереву XML документа, менее удобочитаем, чем метод 2, который использует ассоциативно-адресную навигацию по дереву XML документа.
Для нас наиболее важны режимы результаты производительности при режимах нагрузки, такими являются четные тесты:
Тесты 2 и 6, тесты в которых метод 1 идет первым, тесты 4 и 8, тесты в которых метод 2 идет первым.
Из графика следует, что при своем удобстве метод 2 достигает наивысших показателей производительности, только при многочисленном использовании XML в программе.
Метод 1, при меньшей лаконичности и пиковой производительности относительно метода 2, является более стабильным в использовании для разбора в единственном месте работы PHP скрипта.
Таким образом, переход на DOM PHP 5, в независимости от способа разбора XML документа, вполне оправдан, как по удобству кода, так и по производительности, тем более, с учетом того, что в настоящее время PHP 4 практически не используется.
Все тесты проводились кустарно, их основной задачей было показать различие а не количественные характеристики производительности того или иного парсера, очевидно, что при грамотной настройке кэширующих механизмов результаты могут отличаться.
Полезная статься о поддержке XML в PHP5 habrahabr.ru/blogs/php/31189
