Comments 9
Все выглядит красиво, но как же repmgr, вы даже в слайдах это простое и изящное решение не упомянули, хотя платный продукт BDR от того же разработчика засунули. Вообще, после слайда Postgres High Availability и упоминании Bucardo складывается впечатление, что вы его не пробовали даже, в голом Bucardo HA равно нулю…
Рассказывал А.Клюкин и А.Кукушкин. Но попробую ответить.
По repmgr. Допустим мне нужна синхронная реплика и чтобы, если нода отвалилась, то кластер автоматически сделал синхронную реплику на другой ноде.
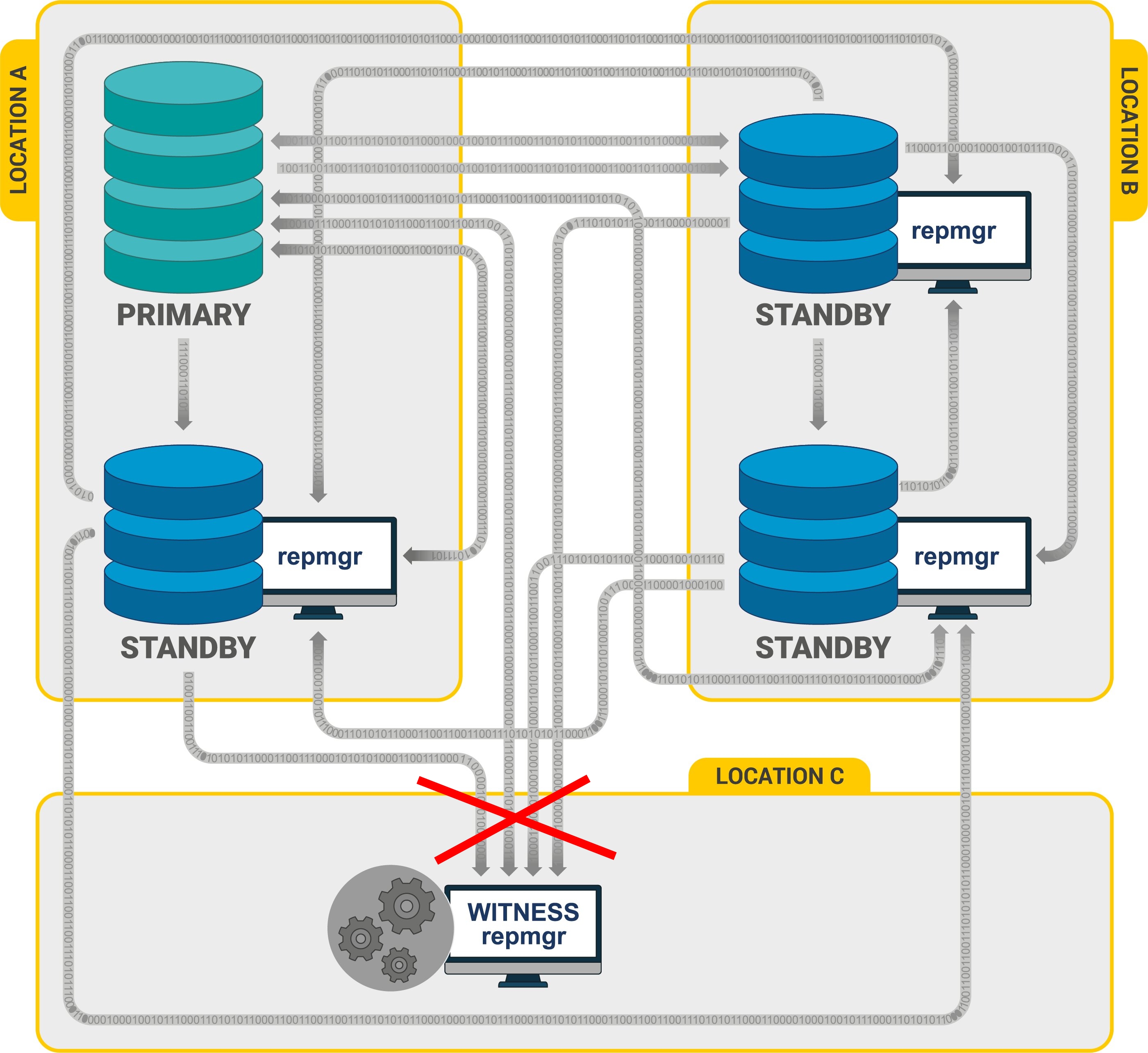
Что случиться если отвалиться сеть до witness ноды (диаграмма ниже)?
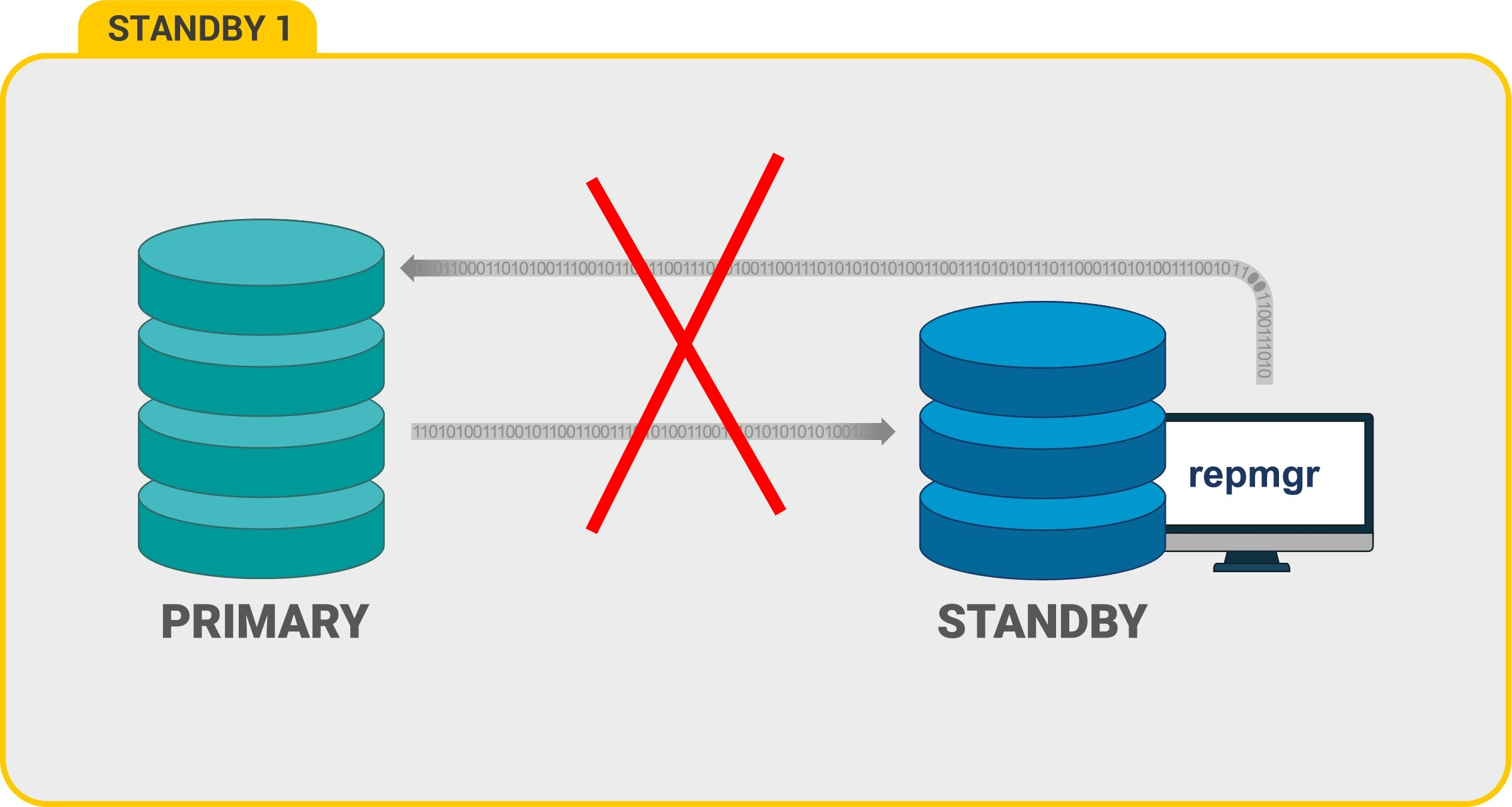
Что случиться если отвалиться сеть между primary и standby (диаграмма ниже)?
Про witness ноду упоминалось в начале tutorial.
Я не пользовался BDR или Bucardo. Может вы напишите пост?
В repmgr настраивается «вес» каждой ноды, который влияет на приоритет становления мастером в случае, когда текущий мастер отваливается. Т.о. если даже связь с witness нодой потеряется, то кластер понимает, как себя вести в случае аварии. В принципе, можно использовать сетап с repmgr и без witness ноды.
Для решения проблем с brain split (вторая диаграмма) используется, так же, witness нода. Но применимы и другие решения, включая скриптовые, которые вполне себе не плохо решают в т.ч. и эту проблему.
BDR, к сожалению, я тоже не пользовался и в тестовой среде поиграться с ним пока не получилось, т.к. даже демо версия у разработчика платная. Про Bucardo уже есть статья на Хабре habr.com/ru/post/327674
Для решения проблем с brain split (вторая диаграмма) используется, так же, witness нода. Но применимы и другие решения, включая скриптовые, которые вполне себе не плохо решают в т.ч. и эту проблему.
BDR, к сожалению, я тоже не пользовался и в тестовой среде поиграться с ним пока не получилось, т.к. даже демо версия у разработчика платная. Про Bucardo уже есть статья на Хабре habr.com/ru/post/327674
Для полноценного HA, нам еще нужен какой-то аналог VIP для клиентов, а repmgr это не решает (это не его задача в целом)
Я пробовал настраивать repmgr через скрипты и тому подобное. Много головной боли и велосипедов на костылях. С patroni всё работает сразу из коробки. Даже кластер из двух postgres нод намного устойчивее. Для etcd нужно всего 3 маломощные машины, плюс можно добавить их на сами сервера с postgres.
Упустили важный момент или я не нашел в тексте вопрос про разворачивание с бэкапа?
Sign up to leave a comment.
Управление высокодоступными PostgreSQL кластерами с помощью Patroni. А.Клюкин, А.Кукушкин