
Часть 1
- Numba
- Multiprocessing
- Pandarallel
Часть 2
- Swifter
- Modin
- Dask
Swifter
Swifter — еще одна небольшая, но довольно умная обертка над pandas. В зависимости от ситуации она выбирает наиболее эффективный способ оптимизации из возможных — векторизацию, распараллеливание или средства самого pandas. В отличие от pandarallel для организации параллельных вычислений она использует не голый мультипроцессинг, а Dask, но о нем чуть позже.
Мы проведем два теста все на тех же новостных данных из прошлой части:
- Возьмем векторизуемую функцию (они сами по себе достаточно оптимальны по производительности)
- Наоборот, что-то сложное, и посмотрим, как swifter будет адаптироваться.
Для первого теста я использую простую математическую операцию:
def multiply(x):
return x * 5
# df['publish_date'].apply(multiply)
# df['publish_date'].swifter.apply(multiply)
# df['publish_date'].parallel_apply(multiply)
# multiply(df['publish_date'])
Чтобы было видно, какой именно подход выбрал swifter, я включил в тест обработку самим pandas, векторизованный подход, а также pandarallel:

На графике отлично видно, что за исключением небольшого оверхеда, который swifter тратит на вычисление наилучшего метода, он идет вровень с векторизованной версией, являющийся наиболее эффективной. Это означает, что оптимизация проведена верно.
Теперь посмотрим как он справится с более сложным, невекторизуемым кейсом. Возьмем нашу функцию обработки текста из прошлой части, добавив туда работу с swifter:
# calculate the average word length in the title
def mean_word_len(line):
# this cycle just complicates the task
for i in range(6):
words = [len(i) for i in line.split()]
res = sum(words) / len(words)
return res
# для работы со строками иницируем специальную функцию allow_dask_on_strings()
df['headline_text'].swifter.allow_dask_on_strings().apply(mean_word_len)
Сравним скорость работы:

А тут картина даже более интересная. Пока объем данных небольшой (до 100 000 строк), swifter использует методы самого pandas, что отчетливо видно. Далее, когда pandas уже не так эффективен, включается параллельная обработка, и swifter начинает работать на нескольких ядрах, выравниваясь по скорости с pandarallel.
Итоги
- Функционал позволяет не только распараллеливать, но и векторизовать функции
- Автоматически определяет наилучшую стратегию для оптимизации вычислений, позволяя не задумываться, где стоит его применять, а где нет
- К сожалению пока не умеет применять
applyна группированные данные (groupby)
Modin
Modin занимается распараллеливанием вычислений, в качестве движка используя Dask или же Ray, и по своей сути мало чем отличается от предыдущих проектов. Тем не менее, это довольно мощный инструмент, и я не могу назвать его просто оберткой. В modin реализован свой собственный dataframe класс (хотя под капотом все же используется pandas), в котором на данный момент есть уже ~80% функционала оригинала, а оставшиеся 20% ссылаются на реализации pandas, таким образом полностью повторяя его API.
Итак, приступим к настройке, для которой нужно только установить env переменную на нужный движок и импортировать класс датафрейма:
# движок Dask на данный момент считается экспериментальным, поэтому я взял ray
%env MODIN_ENGINE=ray
import modin.pandas as mpd
Интересной возможностью modin является оптимизированное чтение файла. Для теста создадим csv файл размером в 1.2 GB:
df = mpd.read_csv('abcnews-date-text.csv', header=0)
df = mpd.concat([df] * 15)
df.to_csv('big_csv.csv')
А теперь прочитаем его с помощью modin и pandas:
In [1]: %timeit mpd.read_csv('big_csv.csv', header=0)
8.61 s ± 176 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
In [2]: %timeit pd.read_csv('big_csv.csv', header=0)
22.9 s ± 1.95 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
Получили ускорение примерно в 3 раза. Конечно, чтение файла не самая частая операция, но все-таки приятно. Посмотрим как поведет себя modin на нашем основном кейсе с текстовой обработкой:
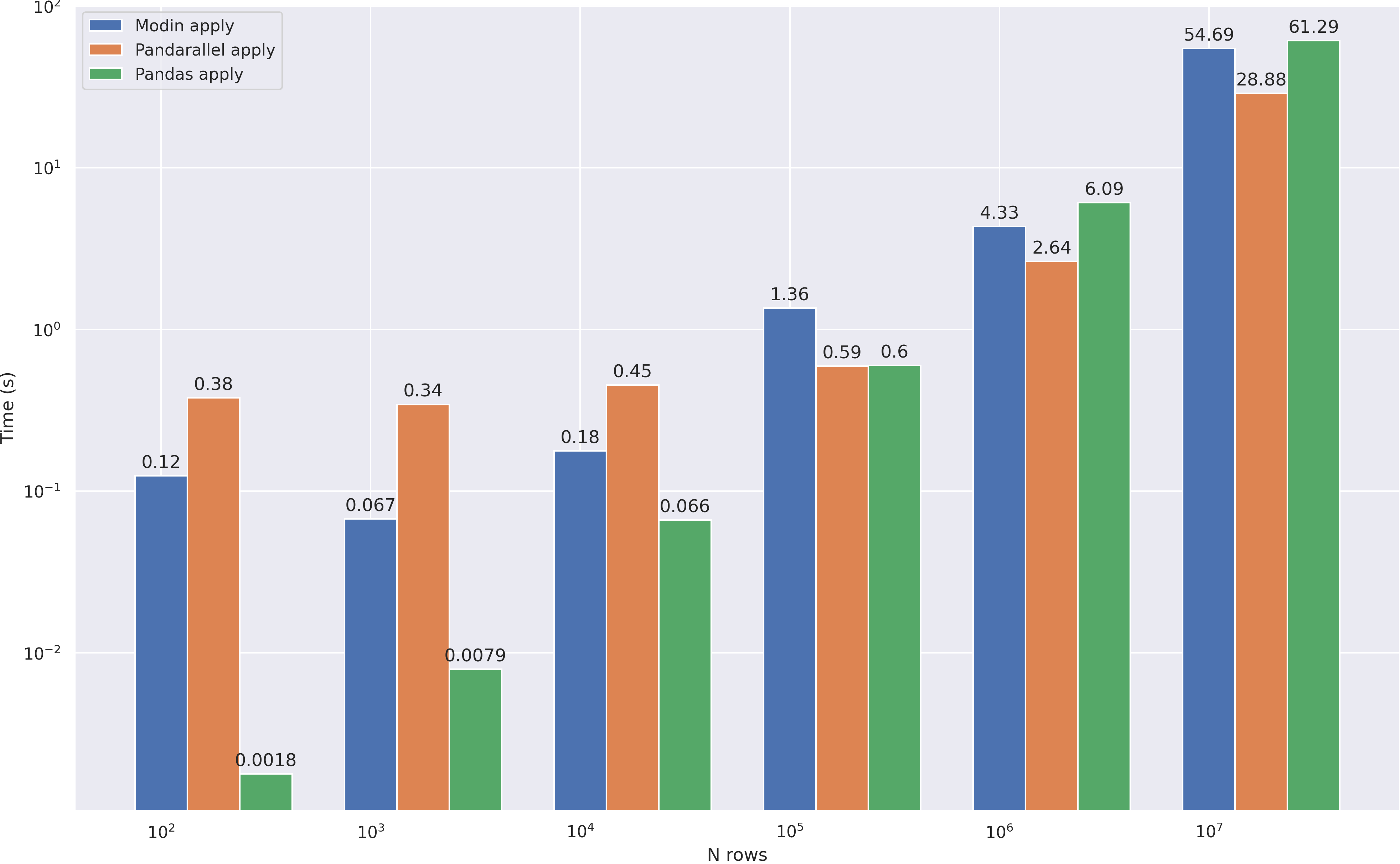
Видим, что применение apply — не самая сильная сторона modin, скорее всего он начнет приносить пользу на данных размера побольше, но у меня не хватило RAM проверить это. Тем не менее, его арсенал на этом не заканчивается, поэтому проверим другие операции:
# в качестве данных выступал вот такой числовой массив
df = pd.DataFrame(np.random.randint(0, 100, size=(10**7, 6)), columns=list('abcdef'))
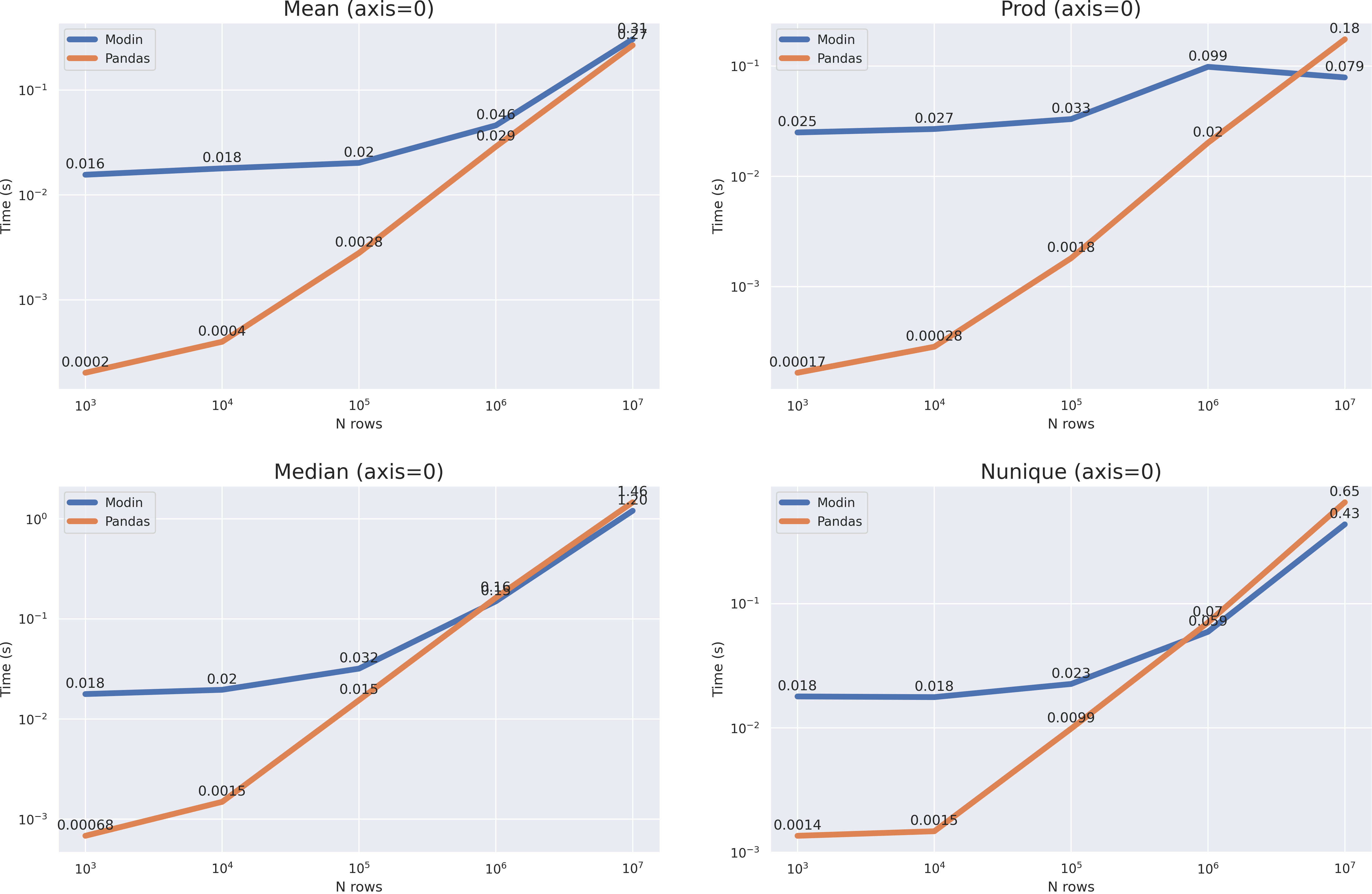
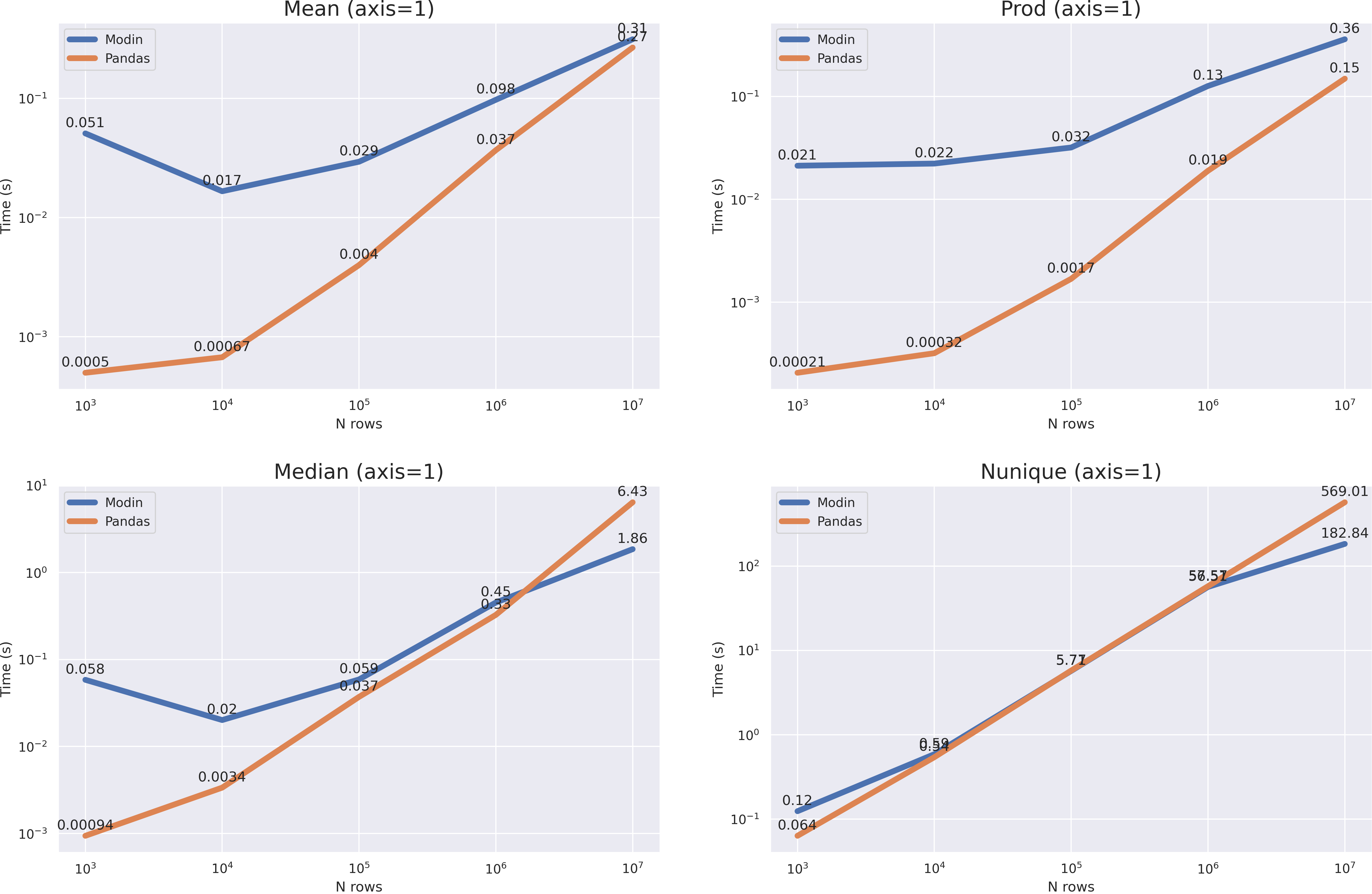
Что мы видим? Очень большой оверхед. В случае с median и nunique мы получили ускорение только когда размер датафрейма вырос до 10**7, в случае же с mean и prod(axis=1) этого не произошло, однако на графиках хорошо видно, что время вычислений pandas растет быстрее и при размере в 10**8 modin уже будет эффективнее во всех случаях.
Итоги
- API датафрейма modin идентичен pandas, поэтому чтобы адаптировать код под большие данные, достаточно изменить одну строчку
- Очень большой оверхед, не стоит использовать на маленьких данных. По моим подсчетам, его использование релевантно на данных больше 1GB
- Поддержка большого количества методов — на данный момент больше 80% методов имеют оптимизированную версию
- Умеет не только в параллельные вычисления, но и в кластеризацию — можно настроить кластер Ray/Dask и modin к нему подключится
- Есть очень полезная фича, позволяющая использовать диск, если оперативная память заполнена
- И Ray и Dask поднимают в браузере довольно полезную дашборду. Я использовал Ray:

Dask
Dask — последний в моем списке и самый мощный инструмент. Он обладает огромным количеством возможностей и заслуживает отдельной статьи, а может и нескольких. Помимо работы с numpy и pandas, он также умеет в машинное обучение — в dask есть интеграции с sklearn и xgboost, а также множество своих моделей и инструментов. И все это может работать как на кластере, так и на вашей локальной машине с подключением всех ядер. Однако в этой статье я остановлюсь именно на работе с pandas.
Все что нужно сделать для настройки dask — это поднять кластер воркеров.
from distributed import Client
# разворачиваем локальный кластер
client = Client(n_workers=8)
Dask, как и modin, использует свой dataframe класс, в котором покрыт весь основной функционал:
import dask.dataframe as dd
Теперь можно приступить к тестированию. Сравним скоростью чтения файла:
In [1]: %timeit dd.read_csv('big_csv.csv', header=0)
6.79 s ± 798 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [2]: %timeit pd.read_csv('big_csv.csv', header=0)
19.8 s ± 2.75 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
Dask отработал где-то в 3 раза быстрее. Посмотрим как он справится с нашей главной задачей — ускорением apply. Для сравнения добавил сюда pandarallel и swifter, которые на мой взгляд также неплохо справились с задачей:
# compute() нужен потому что все вычисления в dask ленивые и требуют запуска
# dd.from_pandas - удобный способ конвертировать датафрейм pandas в dask версию
dd.from_pandas(df, npartitions=8).apply(mean_word_len, meta=(float)).compute(),
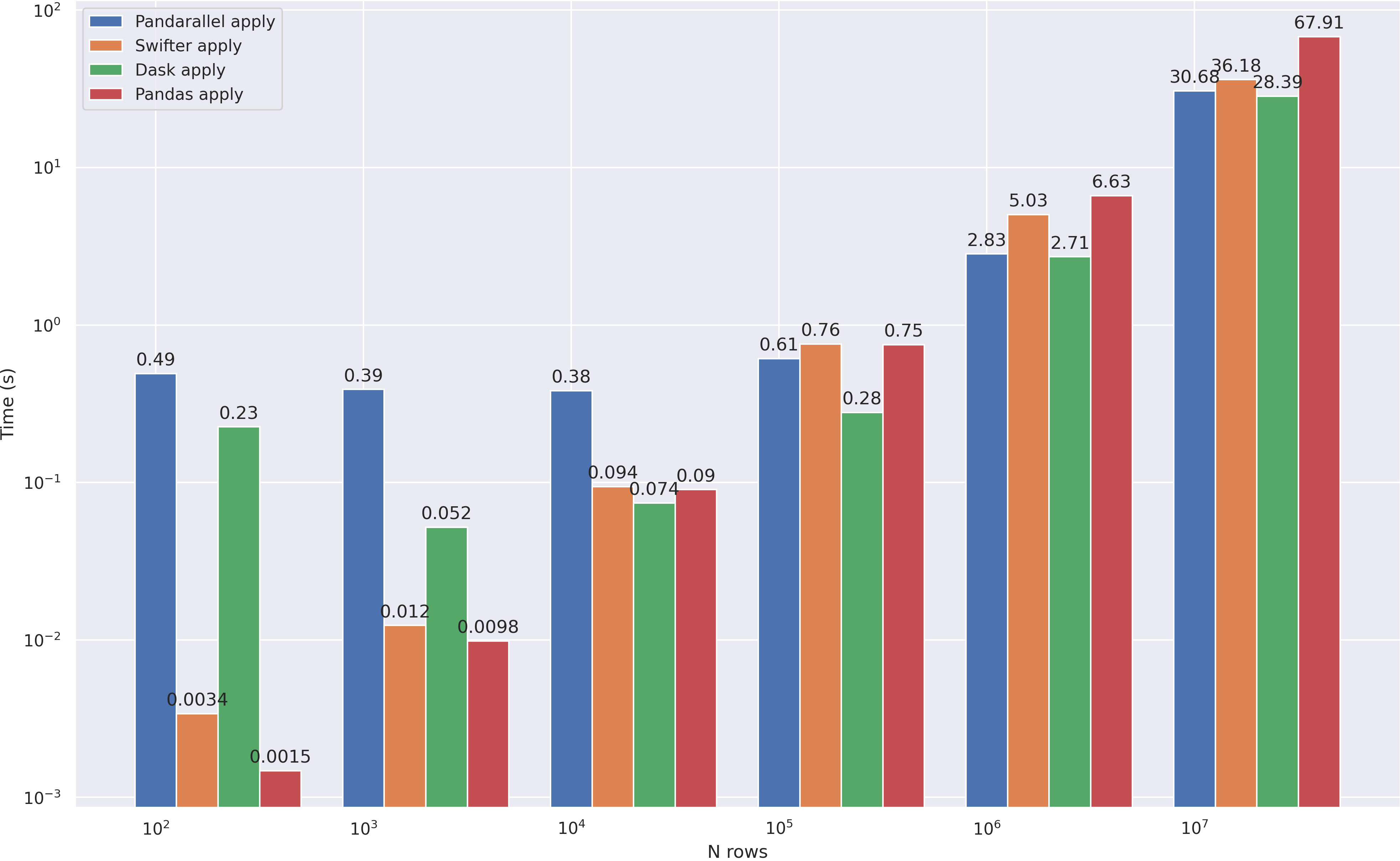
Смело можно сказать, что dask показал лучшие результаты, отрабатывая быстрее всех уже с 10**4 строк. А теперь проверим некоторые другие полезные функции:
# те же числовые данные, что и для modin
df = pd.DataFrame(np.random.randint(0, 100, size=(10**7, 6)), columns=list('abcdef'))

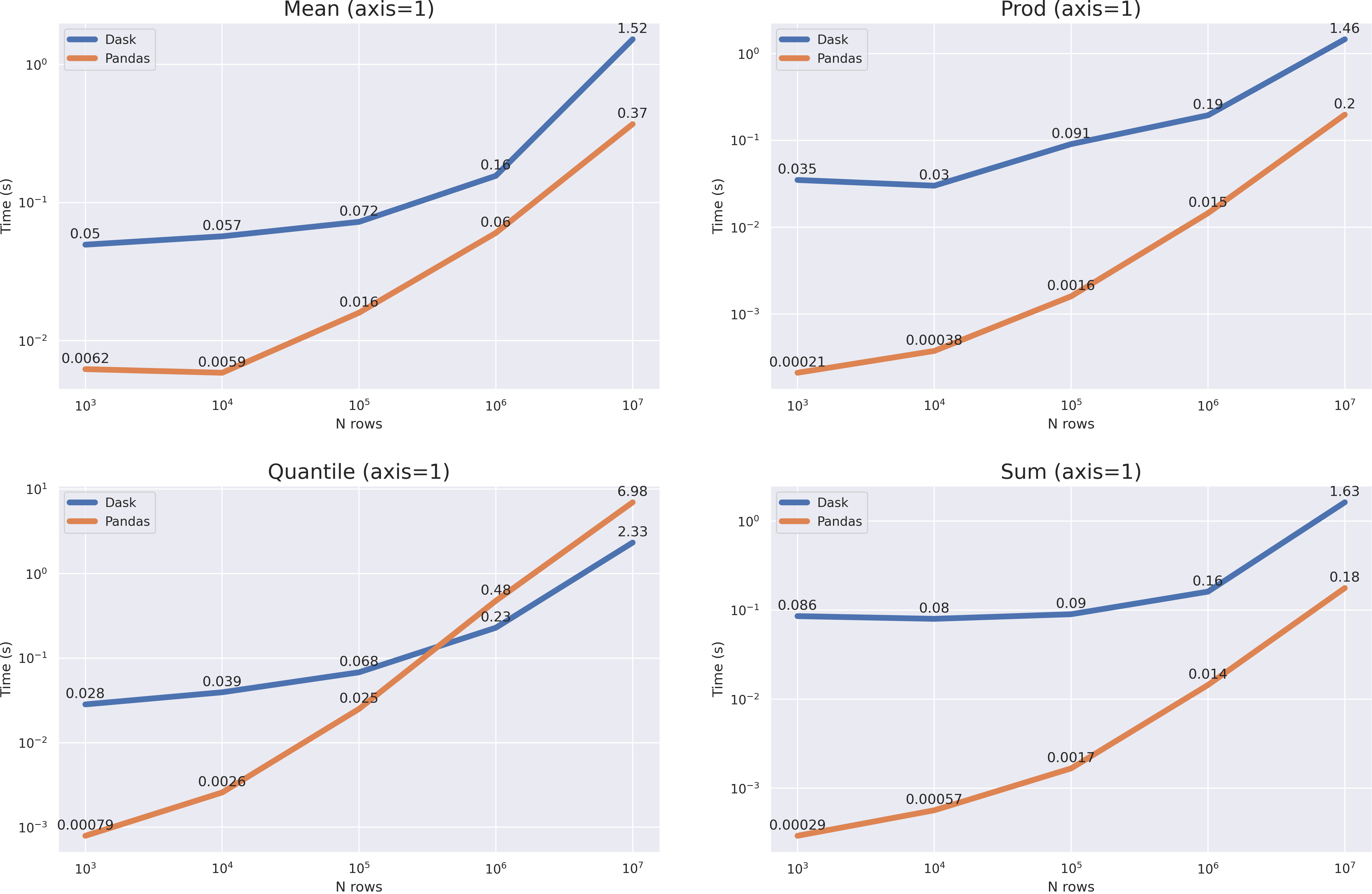
Как и в случае с modin, мы имеем довольно большей оверхед, однако результаты довольно неоднозначные. Для операций с параметром axis=0 мы не получили ускорения, но по скорости роста графиков видно, что при размере данных в >10**8 dask одержит верх. Для операций с axis=1 можно и вовсе сказать что pandas будет работать быстрее (за исключением метода quantile(axis=1)).
Несмотря на то, что pandas показал себя лучше на многих операциях, не стоит забывать, что dask — это в первую очередь кластерное решение, которое может работать там, где pandas не справится (например с большими данными, не влезающими в RAM).
Итоги
- Хорошо справляется с ускорением
apply
- Очень большой оверхед. Предназначен для манипулирования большими датасетами, не помещающимися в память.
- Кластерное решение, но работает и на одной машине
- API dask копирует pandas, но не полность, поэтому адаптировать код под Dask заменой только класса датафрейма может не получится
- Поддержка большого количества методов
- Полезная дашборда:

Conclusion
Стоит понимать, что параллелизация не является решением всех проблем, и начинать всегда нужно с оптимизации своего кода. Перед тем, как параллелить функцию или применять кластерные решения наподобие Dask, спросите себя: Нельзя ли применить векторизацию? Эффективно ли хранятся данные? Правильно ли настроены индексы? И если после ответов на эти вопросы ваше мнение не поменялось, значит описанные инструменты вам действительно нужны, либо вам лень заниматься оптимизацией.
Спасибо всем за внимание! Надеюсь, приведенные инструменты вам помогут!
Предыдущая часть

P.s Trust, but verify — весь код, использованный в статье (бенчмарки и отрисовка графиков), я выложил на github
