Comments 37
По поводу того что для трейна EfficientDet нужны очень большие батчи — только если трейн с нуля. Если использовать перенос обучения с использованием небольшого датасета — использование небольших батчей не такая уж проблема. Пробовал на нескольких небольших датасетах — вроде неплохо себя EfficientDet показывал.
Есть 2 варианта:
Это справедливо для больших корректных датасетов: Microsoft COCO, Google OpenImages, Stanford ImageNet, Berkeley BDD100k, Toyota Kitti… А на малых датасетах что угодно может быть.
Для точности формулировок Transfer-learning vs Fine-tuning: github.com/AlexeyAB/darknet/issues/2139
- Если делать Transfer-learning / Fine-tuning без заморозки weights/BN, то точность на 0.5 — 1.5 AP ниже с малым mini-batch, чем с большим, т.к. статистика mean/variance будет вычислена заново с малым mini-batch.
- Если заморозить большую часть weights и BN-statistic, то проблем с маленьким mini-batch почти нет, но это подходит только если контекст и объекты обучающего датасета сильно совпадают с pre-trained weights, т.к. в этом случае большая (замороженная) часть сети не обучается. Если контекст/объекты сильно отличаются, то точность может упасть на 10 — 20 AP.
Это справедливо для больших корректных датасетов: Microsoft COCO, Google OpenImages, Stanford ImageNet, Berkeley BDD100k, Toyota Kitti… А на малых датасетах что угодно может быть.
Для точности формулировок Transfer-learning vs Fine-tuning: github.com/AlexeyAB/darknet/issues/2139
- Transfer-learning — перенос весов из одной задачи в другую: классификация -> обнаружение
- Fine-tuning — перенос весов между одинаковыми задачами: обнаружение -> обнаружение
Приветствую автора статьи, почему centermask только в одном графике, как показывает текущие результаты по всем детекторам в разрезе MAP/Fps эта сеть прямой конкурент по данным показателям для Yolov4, я тестировал обе сети (сконвертированный centermask с помощью torch2trt и yolov4 от tkdnn) и для моих задач результат в разрезе качества и скорости практически идентичны
Потому что мы сравниваем данные опубликованные в статьях авторов этих нейронных сетей, за которые они ручаются и вряд ли они занижают свои результаты и достижения. И потому что авторы CetnerMask опубликовали свои результаты только на GPU Pascal и только AP (без AP50).
Все фичи которые применяются при определении точности (ensembles, multiscale/flip, high resolution, ...), должны применяться и при определении скорости.
В отличие от большинства других статей, мы публикуем наши результаты на нескольких архитектурах GPU: Maxwell/Pascal/Volta. И сравниваем точность/скорость только на одинаковых архитектурах.
А не как авторы статей CenterNet, EfficientDet,… запускают свои сети на быстрых GPU, а чужие на старых медленных GPU )
Авторы статьи CenterNet сравнили свой CenterNet на GPU-Pascal с производительность 11 TFlops с Yolov3 на старой GPU-Maxwell с производительностью 6 TFlops.
Screenshot CenterNet: arxiv.org/pdf/1904.07850.pdf

Screenshot Yolov3 (2018): arxiv.org/pdf/1804.02767v1.pdf
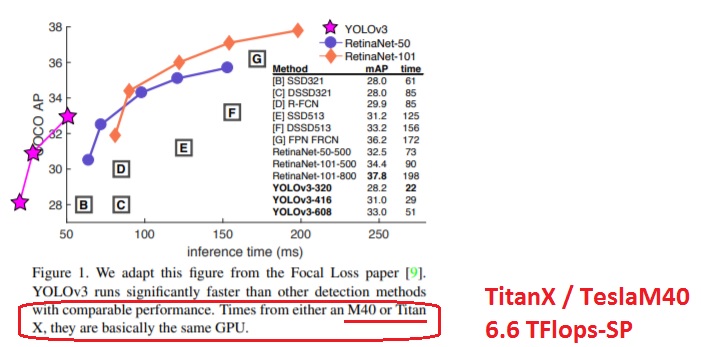
А если сравнить честно на одной и той же GPU, то:
CenterNet-DLA (SS + Flip) — 28 FPS (TitanXP) — 39.2% AP — 57.1% AP50
Darknet YOLOv3 608x608 — ~34 FPS (TitanXP) — 33.0% AP — 57.9% AP50
Авторы EfficientDet из Google Brain пошли ещё дальше, они использовали GPU Volta с Tensor Cores — запустили EfficientDet на GPU не на 1, а на 2 поколения выше, чем Yolov3 :) Но они хотя бы формально поступили чуть более честно – к своему неверному сравнению сделали сноску (что сравнение не верно) – которую увидят только те, кто разбираются: arxiv.org/pdf/1911.09070v4.pdf

Как выглядит честное сравнение Yolov3 и EfficientDet на одинаковом GPU вы видите на наших графиках.
И это им приходится мухлевать, чтобы победить старую YOLOv3, не говоря уже о новой YOLOv4, которая значительно точнее/быстрее.
Чего уж там говорить о горе любителях сравнения из интернета, которые точность проверяют на одном фреймворке с высоким разрешением с multiscale/flip inference-time-data-augmentation и на val5k-датасете, а скорость проверяют на другом фреймворке с низким разрешением без multiscale/flip да ещё с квантованием int8. И сравнивают с другими моделями на test-dev датасете да ещё так же на разных GPU. Вообщем все что только можно смешают и перепутают.
PS
YOLOv4 создавалась при поддержке Academia Sinica и MoST (Ministry of Science and Technology) Taiwan в рамках проекта, целью которого изначально было не создать, а выбрать лучшую нейронную сеть по заказу коммерческих корпораций. Поэтому они достаточно тщательно проверяли наши результаты. Собственно Tsung-Yi Lin автор MSCOCO, RetinaNet, FPN,… выходец из Academia Sinica тоже в курсе этих разработок, как и многие другие значимые люди.
Все фичи которые применяются при определении точности (ensembles, multiscale/flip, high resolution, ...), должны применяться и при определении скорости.
В отличие от большинства других статей, мы публикуем наши результаты на нескольких архитектурах GPU: Maxwell/Pascal/Volta. И сравниваем точность/скорость только на одинаковых архитектурах.
А не как авторы статей CenterNet, EfficientDet,… запускают свои сети на быстрых GPU, а чужие на старых медленных GPU )
Авторы статьи CenterNet сравнили свой CenterNet на GPU-Pascal с производительность 11 TFlops с Yolov3 на старой GPU-Maxwell с производительностью 6 TFlops.
Screenshot CenterNet: arxiv.org/pdf/1904.07850.pdf
6.1. Object detection Table 1 shows our results on COCO validation with different backbones and testing options, while Figure 1 compares CenterNet with other real-time detectors. The running time is tested on our local machine, with Intel Core i7-8086K CPU, Titan Xp GPU, Pytorch 0.4.1, CUDA 9.0, and CUDNN 7.1

Screenshot Yolov3 (2018): arxiv.org/pdf/1804.02767v1.pdf

А если сравнить честно на одной и той же GPU, то:
CenterNet-DLA (SS + Flip) — 28 FPS (TitanXP) — 39.2% AP — 57.1% AP50
Darknet YOLOv3 608x608 — ~34 FPS (TitanXP) — 33.0% AP — 57.9% AP50
Авторы EfficientDet из Google Brain пошли ещё дальше, они использовали GPU Volta с Tensor Cores — запустили EfficientDet на GPU не на 1, а на 2 поколения выше, чем Yolov3 :) Но они хотя бы формально поступили чуть более честно – к своему неверному сравнению сделали сноску (что сравнение не верно) – которую увидят только те, кто разбираются: arxiv.org/pdf/1911.09070v4.pdf

Как выглядит честное сравнение Yolov3 и EfficientDet на одинаковом GPU вы видите на наших графиках.
И это им приходится мухлевать, чтобы победить старую YOLOv3, не говоря уже о новой YOLOv4, которая значительно точнее/быстрее.
Чего уж там говорить о горе любителях сравнения из интернета, которые точность проверяют на одном фреймворке с высоким разрешением с multiscale/flip inference-time-data-augmentation и на val5k-датасете, а скорость проверяют на другом фреймворке с низким разрешением без multiscale/flip да ещё с квантованием int8. И сравнивают с другими моделями на test-dev датасете да ещё так же на разных GPU. Вообщем все что только можно смешают и перепутают.
PS
YOLOv4 создавалась при поддержке Academia Sinica и MoST (Ministry of Science and Technology) Taiwan в рамках проекта, целью которого изначально было не создать, а выбрать лучшую нейронную сеть по заказу коммерческих корпораций. Поэтому они достаточно тщательно проверяли наши результаты. Собственно Tsung-Yi Lin автор MSCOCO, RetinaNet, FPN,… выходец из Academia Sinica тоже в курсе этих разработок, как и многие другие значимые люди.
UFO just landed and posted this here
То есть вы берёте цифры конкурентов из их статей и все остальные поступают точно так же — берут цифры конкурентов из их статей, поэтому и получается сравнение новых сетей на новых железках со старыми сетями на старых железках.
Нет, не получается. Прочитайте статью.
У нас новая сеть сравнивается с другими сетями на одинаковых железках.
Новая сеть на старом железе со старой сетью на старом железе.
Новая сеть на новом железе с новой сетью на новом железе.
Вряд ли у ребят из гугл брейн была цель показать какая yolo3 плохая. В конце концов, не весь ресёрч ведётся для того, чтобы показать исключительно практические, немедленно применимые в реальной жизни результаты и уменьшение теоретических флопсов — тоже полезное направление, потому что кто знает, что будущее железо нам принесёт?
Если бы им было все равно, то они бы не кинулись через пол года доделывать сеть и исправлять статью, при этом бросив текущие проекты.
Если бы им не было важно Inference time (ms), то они бы их не указывали.
UFO just landed and posted this here
А то, что они «кинулись» статью исправлять, то тут миллион причин может быть, может быть им ревьюеры на CVPR, куда эта статья прошла, на это указали и попросили уточнить (а это проще сделать, чем спорить)
Все правильно, и я, и авторы CVPR считают, что сравнение EfficientDet на GPU 130 000 TFlops-TC против YOLOv3 на GPU 6 000 TFLops в статье EfficientDet — это фейк, и в первоначальном виде их статью бы не допустили на CVPR. Я это объяснил 99% пользователей, которые это не понимали. Странно почему вы против того, чтобы пользователи это знали.
Если Google указывает Inference time в статье и делает специальную версию EfficientNet-TPUEdge (backbone для EfficientDet) ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html, в которой убирает все фишки (DepthWise-conv, SE, ...) снижающие BFLOPS, чтобы это работало побыстрее, с сильным падением точности обнаружения — хотя бы по точности/скорости как самая древняя YOLO, значит Google важна скорость. И если в результате все равно это не быстрее/точнее — значит просто не могут сделать. Apple их обгоняет в этом плане потому, что они используют что?
Может если бы йоло не была так привязана к маргинальному (будем честны, он такой и есть) даркнету, то авторы не поленились бы и запустили её в сравнение ко всем остальным ретинам.
YOLO есть на всех фреймворках: Facebook-Pytorch, Google-TensorFlow, Tencent-NCNN, nVidia-TensorRT, Intel-OpenCV, Mxnet, Keras, TVM, Darknet,…
всего 13 000 репозиториев, 4852 на Python: github.com/search?q=yolo
* YOLOv3 Pytorch: github.com/ultralytics/yolov3
* YOLOv3-ASFF Pytorch: github.com/ruinmessi/ASFF
The founders of Xnor.ai, Ali Farhadi and Mohammad Rastegari, are experts in computer vision. Ali is a co-author of the popular object detection technique. YOLO — You Look Only Once. YOLO is one of the most popular techniques used in object detection in real-time.
Приватные разработки в том числе на маргинальном Darknet были куплены компанией Apple за $200 000 000 именно из-за быстроты XNOR-YOLO на ARM-чипах/NPU www.forbes.com/sites/janakirammsv/2020/01/19/apple-acquires-xnorai-to-bolster-ai-at-the-edge/#156e95733975
Думаю вопрос «как сильно пострадала наша репутация от того, что мы в одной из второстепенных строк одной из таблиц указали данные из оригинальной статьи, а потом вычеркнули совсем для единообразия и ясности» вызовет у них в лучшем случае недоумение :)
Если бы Google-brain статью не исправили, и их бы не пустили на CVPR — вот у них было бы недоумение.
Вообще, выглядит так, что они эту йоло туда изначально на отвали запихали — основное внимание в статье уделено большим вариантам и сравниваются они с приличными бейзлайнами.
Т.е. вы считаете, что в статье EfficientDet сравнение писалось на отвали, а вместо точных чисел скорости и точности они использовали термины «приличные»? Я считаю, что Google намного лучше, чем вы о них думаете.
Может если бы йоло не была так привязана к маргинальному (будем честны, он такой и есть) даркнету, то авторы не поленились бы и запустили её в сравнение ко всем остальным ретинам.
Вы считаете, что 10 000 студентов смогли обучить и запустить Yolo, а топовые исследователи из Google не смогли? Какое-то у вас предвзятое и негативное мнение о Google.
Почему тогда CEO ARM рассказывает про XNOR YOLO, и нафига тогда Apple платить $200M за TradeMark на YOLO?
www.patentlyapple.com/patently-apple/2020/06/four-xnorai-trademarks-covering-yolo-tools-for-real-time-object-detection-have-officially-been-transferred-to-apple.html
This week the U.S. Patent and Trademark Office officially published the transfer of four XNOR.AI registered trademarks to Apple that include: YOLOV2; YOLOV3; YOLO9000; and TINY YOLO as presented below. The actual registered trademark certificates have yet to be republished with Apple Inc. shown as owner.
www.forbes.com/sites/janakirammsv/2020/01/19/apple-acquires-xnorai-to-bolster-ai-at-the-edge/#568e22063975
Apple reportedly acquired Xnor.ai, a Seattle-based startup for $200 million
…
The founders of Xnor.ai, Ali Farhadi and Mohammad Rastegari, are experts in computer vision. Ali is a co-author of the popular object detection technique. YOLO — You Look Only Once. YOLO is one of the most popular techniques used in object detection in real-time.
news.crunchbase.com/news/apple-acquires-ai-on-the-edge-startup-xnor-ai-for-around-200m
Researchers at Xnor.ai developed an object detection model they called You Only Look Once (aka YOLO), which the company licensed to enterprise customers including internet-connected home security camera company Wyse.


UFO just landed and posted this here
Под приличными я имел в виду то, что эти бейзлайны были не слабыми, как типично бывает (когда берётся плохо натренированный бейзлайн и сравнивается с сильно тюнингованной своей сетью), а хорошими бейзлайнами, популярными вариантами, хорошо натренированными и известными.
Я понимаю, что для вас это центральная разработка и из-за того, что вы варитесь в нём и среди людей, которые его используют, то может показаться, что это очень популярная и распространённая штука.
Или может быть все знают кроме вас — вот что показывают объективные числа:
Никто не знает и не считает важным детекторы MobileNetv2 / Facebook-RetinaNet / PeleeNet / CornerNet, в отличии от Yolo.
1. Что используют в реальных системах — поиск в гугле по общей фразе «ros object detection» — первая строчка: github.com/leggedrobotics/darknet_ros
2. О чем знают обычные пользователи из ютуб — про какой ещё детектор объектов рассказывали на TED и имеется более 1 млн просмотров на ютуб?
— youtu.be/Cgxsv1riJhI
— youtu.be/4eIBisqx9_g
3. Какие самые популярные детекторы объектов у исследователей:
YOLOv1 (2015) — 7234 раз процитировано: arxiv.org/abs/1506.02640
YOLOv2 (2016) — 3664 раз процитировано: arxiv.org/abs/1612.08242
CornerNet (2017) — 231 раз процитировано: arxiv.org/abs/1808.01244
RetinaNet (2017) — 1796 раз процитировано: arxiv.org/abs/1708.02002 (FaceBook)
YOLOv3 (2018) — 2431 раз процитировано: arxiv.org/abs/1804.02767
MobileNetv2 (2018) — 1862 раз процитировано: arxiv.org/abs/1801.04381
PeleeNet (2018) — 87 раз процитировано: arxiv.org/abs/1804.06882
CenterNet (2019) — 109 раз процитировано: arxiv.org/abs/1904.08189
EfficientDet (2019) — 38 раз процитировано: arxiv.org/abs/1911.09070 (Google)
Сгруппировано по годам, т.к. чем старее статья — тем больше цитат.
Понятно, что статья вышедшая только месяц назад почти не будет процитирована.
4. О каком ещё детекторе объектов кроме XNOR-YOLO рассказывал CEO ARM?
twitter.com/morastegari/status/1158966293262819328
5. Какой ещё детектор объектов кроме XNOR-YOLO пытались купить сразу Microsoft, Intel, Amazon, Apple (и Apple купила за 200M$)? www.geekwire.com/2020/seattle-ai-startup-drew-interest-amazon-microsoft-intel-selling-apple
Seattle AI startup drew interest from Amazon, Microsoft, Intel before selling to Apple
6. И самое главное, какой детектор самый быстрый и точный? — Об этом эта статья.
Критика о том, что у фреймворка Darknet только 11 000 (my) / 18 000 (official) Stars, про него ничего нет в Wiki, и бывает трудно найти в гугле — принимается. Ну на то он и Darknet.
Под маргинальностью Darknet можно понимать только то, что если я перестану его разрабатывать, то его развитие остановится.
Просто забавно, ходят по конференциям, выпускают кучу статей, а сделать ничего лучше не могут:

—
Могли, но не стали. И я их понимаю — одно дело запустить одной командой условный детектрон и перетренировать, другое дело разбираться с установкой и работой с даркнетом и так далее, особенно, когда тебе это нужно ради добавления одной цифры в статью, которая вообще в целом не об этом.
Конечно, это очень трудно покликать по стрелочкам в Google Colab, чтобы увидеть как компилировать и запускать Yolo на Darknet: https://colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
Скомпилировать Darknet используя Cmake — 2 команды
cmake .
make
Скачать датасет
scripts/get_coco_dataset.shЗатем обучение запускается одной строкой: https://github.com/AlexeyAB/darknet/wiki/Train-Detector-on-MS-COCO-(trainvalno5k-2014)-dataset
./darknet detector train cfg/coco.data cfg/yolov4.cfg csdarknet53-omega.conv.105Вот здесь пробуют запустить обучение «эффективной» Google-EfficientDet-D5 одной командой даже на топовой игровой GPU RTX 2080ti 11GB или на Titan V (3000$) вы столкнетесь с Error: Out of Memory, даже с batch_size=1 (хотя EfficientDet требует batch_size=128 для достижения заявленной точности): github.com/google/automl/issues/85
In my mind, efficientdet is light-weighted and efficient. However, I can only run efficientdet-d4 on a single Nvidia Titan V GPU by setting train_batch_size=1. Training efficientdet-d5 will result in OOM.
UFO just landed and posted this here
И забавно сравнивать популярность детектора по тому, что используют в не менее узкоспециализированной ROS. Одно развёрнутое гуглом приложение на мобильники даст install base в тысячу раз больше, чем все пользователи рос вместе взятые. Причём гугл даже не будет это нигде рекламировать как отдельную фичу (ну разве что где-нибудь в блоге для девелоперов напишут заметку, мимоходом, дескать используем мобайлнет для детекции чего-нибудь на миллиарде устройств).
Ну покажите ссылки и назовите продукты где Google использует какие-либо детекторы массово, кроме своих Pixel-phone тиражом в 2 штуки. Вот Apple купила XNOR-YOLO за 200M$ и уже использует XNOR-YOLO на всех iPhone из-за её быстроты и энергоэффективности — это 200 миллионов iPhone каждый год, да и через 2 года будут использовать на PC, переход PC на ARM уже начался.
Остальные сети вообще нигде не используются, и исследователи их не любят, и точность и скорость у них крайне низкие — объективные числа я привел в предыдущем сообщении.
Компания Tencent (капитализация 500 000 000 000$) считает хорошей сеткой YOLO, а не Facebook-RetineNet/MaskRCNN или Google-EfficientDet: github.com/Tencent/ncnn
Может быть я предвзят из-за своего отрицательного опыта и поэтому так воспринимаю (у меня тоже ограниченное видение), но то, в йоло всё так перемешано и захардкожено (шаг вправо, шаг влево — сегфолт, градиенты всякие вручную прописанные в дебрях Си,
Вы по моему не тот Darknet использовали, надо про нейронные сети, а не где продают запрещенные вещества )
Захардкожено — это в TensorFlow-EfficientDet вся сеть захардкожена в коде на Python, и приходится лазить по всему исходному коду, чтобы хоть чуть-чуть поменять архитектуру
— TF-EfficientDet — backbone в одном месте github.com/google/automl/blob/b26c32ab3062c271eb3a2c2754d633b5572a98c2/efficientdet/backbone/efficientnet_model.py, neck в другом месте github.com/google/automl/blob/b26c32ab3062c271eb3a2c2754d633b5572a98c2/efficientdet/efficientdet_arch.py другие части ещё где-то раскиданы
— в YOLO вообще ничего не зарадкожено, вся сеть целиком в одном простом cfg-файле (читаемый формат INI) github.com/AlexeyAB/darknet/blob/master/cfg/yolov4-tiny.cfg и чтобы поменять архитектуру сети вообще не надо программировать на C/C++/CUDA/Python/…. Авторы CSPNet вообще не правили ни строчки код, а только изменили cfg-файл: arxiv.org/abs/1911.11929
Успешно изменяют YOLO разные люди: и которые вообще не умеют программировать, но знают нейронные сети, и люди которые знают chain-rule/differentiation, могут писать собственные слои и их реализации на CUDA.
UFO just landed and posted this here
После этого разговора я вообще уже не уверен, что есть свидетельства, что кто-то на самом использует детекцию, а уж тем более определить доли рынка конкретных моделей :)
Как же Apple тогда сейчас сортирует фото по наличию обнаженки, бюстгалтеров, мозаики, цукини… в галерее на iPhone? iz.ru/665343/2017-10-31/iphone-raspoznaet-foto-v-biustgalterakh-v-otdelnuiu-kategoriiu (надо понимать, что на фото может быть 10-20 равноценных мелких предметов, и классификация тут не подходит, нужна детекция)
Т.е. Apple отдала 200M$ за XNOR-YOLO, а вместо него для этой задачи использует ваш любимый медленный и кривой EfficientDet от Google, или там люди руками перебирают фото — как это работает? )
Детекция на смартфонах:
— детекция лиц перед их распознаванием
— сортировка фотографий в галерее по объектам
— поиск фотографий по предметам (забыл где на телефоне валяется фото, но помнишь что на нем была гитара)
— размытие фона при общении по Skype / Zoom /… — уж этим все воспользовались во время карантина
— размытие фона на фотографиях
…
Лучший детектор YOLO можно расширить до лучшего Instance Segmentator YOLACT++, например, чтобы отображать только одного человека, а остальных людей и фон размывать, используя YOLACT++ arxiv.org/pdf/1912.06218.pdf или Poly-YOLO arxiv.org/pdf/2005.13243.pdf

а уж тем более определить доли рынка конкретных моделей :)
Ну то что у Apple доля мирового рынка 32% мирового дохода от продаж телефонов, 66% мирового дохода от мобильных телефонов + сервисов (iCloud, Apple Music, ...), и 15% по количеству проданных iPhone, и продажи 200 миллионов iPhone в год — это по моему не секрет:
— www.forbes.com/sites/johnkoetsier/2019/12/22/global-phone-profits-apple-66-samsung-17-everyone-else-unlucky-13/#37452bf92ff3
— www.ixbt.com/news/2020/01/30/apple-vozglavljaet-rynok-smartfonov-po-itogam-proshlogo-kvartala-.html

UFO just landed and posted this here
Как-то всё смешалось и детекция и сегментация.В лучших real-time алгоритмах Instance Segmentation (YOLACT++, Poly-YOLO) используется модифицированный детектор YOLO.
Then producing a full-image instance segmentation from these two components is simple: for each instance, linearly combine the prototypes using the corresponding predicted coefficients and then crop with a predicted bounding box.
Доля рынка Apple != доля рынка моделей детекторов
Достоверно известно, что Apple использует детекцию в десятке задач (сортировка галереи, поиск в галерее по названию объекта, ...) в любом iPhone -> Apple купила XNOR-YOLO за 200M$ -> Apple заменила все свои детекторы на всех новых iPhone (200М штук в год) на более быстрые и точные XNOR-YOLO.
Но вы утверждаете, что купила за 200M$, но не использует )
Использовал darknet от AlexeyAb для нескольких домашних проектов на yolov3(распознавание дорожных знаков и распознавание эвакуаторов), обучал на RTX2080. В принципе все работало неплохо. Правда, знаки обучались почти неделю. Единственное, что не смог сделать, перенести обученные модели на jetson nano.
1) А что с поддержкой int8? Когда вышла YOLOv3 у нас какие-то были проблемы при попытке всё это перетащить на TensorRT (вроде с tiny там тоже что-то было весьма конкурентное). В результате получалось что какие-то аналоги под int8 были пошустрее без существенной потери качества по сравнению с Yolo.
В статье у вас вижу только int16. С int8 не тестили, или какие-то ограничения архитектуры?
2) Вообще этот проект интересно весьма выглядит — github.com/ceccocats/tkDNN на который вы ссылку приводите. Что-то я нигде на формумах под Jetson ссылок не видел. Хотя он должен массу проблем решать.
Это что-то новое?
3) А сколько fps показывает на Jetson tx2 и Jetson nano? На днях читал что на nano чуть ли не 1 fps у кого-то вышло.
В статье у вас вижу только int16. С int8 не тестили, или какие-то ограничения архитектуры?
2) Вообще этот проект интересно весьма выглядит — github.com/ceccocats/tkDNN на который вы ссылку приводите. Что-то я нигде на формумах под Jetson ссылок не видел. Хотя он должен массу проблем решать.
Это что-то новое?
3) А сколько fps показывает на Jetson tx2 и Jetson nano? На днях читал что на nano чуть ли не 1 fps у кого-то вышло.
1. Проблем с int8 квантованием Yolo в TensorRT не было, были проблемы с производительностью из-за необходимости использовать кастомную активацию leaky, легко решалось заменой на relu: arxiv.org/pdf/1904.02024.pdf
Сейчас Yolov3 нативно поддерживается в nVidia Deepstream 4.0 (TensorRT) поэтому никаких проблем вообще нет: news.developer.nvidia.com/deepstream-sdk-4-now-available
Мало того, Xnor.ai научились обучать Yolo на bit1 весах, собственно основатели и создали Yolo: www.forbes.com/sites/janakirammsv/2020/01/19/apple-acquires-xnorai-to-bolster-ai-at-the-edge/#7727a8913975
2. tkDNN относительно новая библиотека.
3. Я запускал YOLOv4 256x256 async=3 (Leaky вместо Mish) на 1 Watt neurochip Intel Myriad X со скоростью 11 FPS. При этом точность на MSCOCO test-dev такая же как у обычного YOLOv3:
YOLOv4 256x256 (leaky) — 33.3% AP — 53.0% AP50
YOLOv3 416x416 (default) — 31.0% AP — 55.3% AP50.
Можно такую умную камеру+нейрочип использовать shop.luxonis.com — одновременно и объекты обнаруживает и расстояние до них
YOLOv3-spp 192x320 на iPhone (A13 iOS) показывает более 30 FPS apps.apple.com/app/id1452689527
Сейчас Yolov3 нативно поддерживается в nVidia Deepstream 4.0 (TensorRT) поэтому никаких проблем вообще нет: news.developer.nvidia.com/deepstream-sdk-4-now-available
Мало того, Xnor.ai научились обучать Yolo на bit1 весах, собственно основатели и создали Yolo: www.forbes.com/sites/janakirammsv/2020/01/19/apple-acquires-xnorai-to-bolster-ai-at-the-edge/#7727a8913975
2. tkDNN относительно новая библиотека.
3. Я запускал YOLOv4 256x256 async=3 (Leaky вместо Mish) на 1 Watt neurochip Intel Myriad X со скоростью 11 FPS. При этом точность на MSCOCO test-dev такая же как у обычного YOLOv3:
YOLOv4 256x256 (leaky) — 33.3% AP — 53.0% AP50
YOLOv3 416x416 (default) — 31.0% AP — 55.3% AP50.
Можно такую умную камеру+нейрочип использовать shop.luxonis.com — одновременно и объекты обнаруживает и расстояние до них
YOLOv3-spp 192x320 на iPhone (A13 iOS) показывает более 30 FPS apps.apple.com/app/id1452689527
Всё-таки TPU от Intel и Jetson Nano это принципиально разные штуки. Первый сильно энергоэффективнее если сеть на нём работает. Но архитектура там сильно разная, как результат — производительность может рандомно прыгать. Но да, nano под tensorrt должен быть побыстрее в большинстве случаев.
Да не суть. Всё равно хорошо что новые сети появляются и точность растёт.
Да не суть. Всё равно хорошо что новые сети появляются и точность растёт.
Вышла модель YOLOv4-tiny с экстремально высокой скоростью 370 FPS на GPU 1080ti, или 16 FPS на Jetson Nano (max_N, 416x416, batch=1, Darknet-framework): github.com/AlexeyAB/darknet/issues/6067
Дождемся официальной реализации и релиза yolov4-tiny в OpenCV, и там скорее всего будет Real-time 30 FPS на Jetson-Nano и NPU Intel Myriad X (1 Watt), и ещё быстрее при batch=4 / INT8.

Дождемся официальной реализации и релиза yolov4-tiny в OpenCV, и там скорее всего будет Real-time 30 FPS на Jetson-Nano и NPU Intel Myriad X (1 Watt), и ещё быстрее при batch=4 / INT8.
А скажите ещё, на CPU так всё плохо и будет? Там можно как-то хотя бы 30 FPS с батчами по 4 выбить? А то я тут у ZlodeiBaal спрашивал, не лучше ли комбинировать на CPU оптический трекер с yolo, т.к. что-то крайне мало FPS в детекторе получается. Может, действительно, INT8 в OpenCV/OpenVino улучшит ситуацию? Или просто архитектура не оптимизирована под CPU и лучше брать что-то другое?
Моя позиция была всё же, что оптический трекер не нужен когда есть хорошая детекция. И я приводил много примеров когда детекторы дают высокую скорость на процессоре.
Сетей которые быстро детектируют достаточно много. Конечно, их нужно на железо портировать и пробовать максимально его использовать. И круто, что в их семействе появилась ещё одна.
Сетей которые быстро детектируют достаточно много. Конечно, их нужно на железо портировать и пробовать максимально его использовать. И круто, что в их семействе появилась ещё одна.
Можно 46 FPS с batch=1 FP32 на CPU.
Скорость и точность разных YOLO: github.com/AlexeyAB/darknet/issues/5079
На CPU — 90 Watt — FP32 (Intel Core i7-6700K 4GHz 8 Logical Cores) OpenCV-DLIE, FPS
1. github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny-prn.cfg — 46 FPS
2. github.com/AlexeyAB/darknet/blob/master/cfg/yolov4-tiny.cfg — такая же быстрая, но точнее, подождите неделю пока в OpenCV добавят поддержку github.com/opencv/opencv/issues/17666 И затем сразу можете использовать OpenCV-master-branch github.com/opencv/opencv/archive/master.zip
Или дождитесь релиза нового бинарника: opencv.org/releases
Работает быстрее, если скомпилировать OpenCV с бэкэндом OpenVINO: github.com/opencv/opencv/wiki/Intel's-Deep-Learning-Inference-Engine-backend
Скорость и точность разных YOLO: github.com/AlexeyAB/darknet/issues/5079
На CPU — 90 Watt — FP32 (Intel Core i7-6700K 4GHz 8 Logical Cores) OpenCV-DLIE, FPS
1. github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny-prn.cfg — 46 FPS
2. github.com/AlexeyAB/darknet/blob/master/cfg/yolov4-tiny.cfg — такая же быстрая, но точнее, подождите неделю пока в OpenCV добавят поддержку github.com/opencv/opencv/issues/17666 И затем сразу можете использовать OpenCV-master-branch github.com/opencv/opencv/archive/master.zip
Или дождитесь релиза нового бинарника: opencv.org/releases
Работает быстрее, если скомпилировать OpenCV с бэкэндом OpenVINO: github.com/opencv/opencv/wiki/Intel's-Deep-Learning-Inference-Engine-backend
Если на слабых процессорах (ARM, Apple, Qualcomm, ...) думаете делать, то дождитесь реализации yolov4-tiny на github.com/Tencent/ncnn и попробуйте её (YOLOv4-full там уже работает): github.com/Tencent/ncnn/issues/1885
Около 42 FPS работает yolov4-tiny на CPU Intel Core i7 7700HQ используя OpenCV-dnn, если скомпилировано с OpenVINO backend: github.com/opencv/opencv/wiki/Intel's-Deep-Learning-Inference-Engine-backend
Без OpenVINO-backend — 28 FPS.
— YOLOv4-tiny: accuracy 40.2% AP50 on Microsoft COCO dataset:
1770 FPS — on GPU RTX 2080Ti — (416x416, fp16, batch=4) tkDNN/TensorRT
1353 FPS — on GPU RTX 2080Ti — (416x416, fp16, batch=4) OpenCV
39 FPS — 25ms latency — on Jetson Nano — (416x416, fp16, batch=1) tkDNN/TensorRT
290 FPS — 3.5ms latency — on Jetson AGX — (416x416, fp16, batch=1) tkDNN/TensorRT
42 FPS — on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) — (416x416, fp16, batch=1) OpenCV-dnn (compiled with OpenVINO backend) github.com/AlexeyAB/darknet/issues/6067#issuecomment-656693529
20 FPS on CPU ARM Kirin 990 — Smartphone Huawei P40 (416x416, GPU-disabled, batch=1) Tencent/NCNN
120 FPS on nVidia Jetson AGX Xavier — MAX_N (416x416, fp16, batch=1) — Darknet framework
371 FPS on GPU GTX 1080 Ti — (416x416, fp16, batch=1) Darknet framework
More: github.com/AlexeyAB/darknet/issues/6067
Без OpenVINO-backend — 28 FPS.
— YOLOv4-tiny: accuracy 40.2% AP50 on Microsoft COCO dataset:
1770 FPS — on GPU RTX 2080Ti — (416x416, fp16, batch=4) tkDNN/TensorRT
1353 FPS — on GPU RTX 2080Ti — (416x416, fp16, batch=4) OpenCV
39 FPS — 25ms latency — on Jetson Nano — (416x416, fp16, batch=1) tkDNN/TensorRT
290 FPS — 3.5ms latency — on Jetson AGX — (416x416, fp16, batch=1) tkDNN/TensorRT
42 FPS — on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) — (416x416, fp16, batch=1) OpenCV-dnn (compiled with OpenVINO backend) github.com/AlexeyAB/darknet/issues/6067#issuecomment-656693529
20 FPS on CPU ARM Kirin 990 — Smartphone Huawei P40 (416x416, GPU-disabled, batch=1) Tencent/NCNN
120 FPS on nVidia Jetson AGX Xavier — MAX_N (416x416, fp16, batch=1) — Darknet framework
371 FPS on GPU GTX 1080 Ti — (416x416, fp16, batch=1) Darknet framework
More: github.com/AlexeyAB/darknet/issues/6067
Круто, спасибо!
Обязательно попробую!
Обязательно попробую!
Приветствую автора. Подскажите пожалуйста, есть ли какие либо исследования детальные по neck (FPN,PAN,biFPN,FPN в YOLOv4), интересуют в большей степени case study по поводу количества блоков в пирамиде, оптимального числа fmaps которые нужно отправлять в fpn ( стандарт 256, тестил и 128, но супер сильной разницы не заметил) и по тому как сделать fpn более efficient с точки зрения forward pass затрат времени.Как я вижу вы проводили довольно большей ресерч по поводу комбинаций различных модулей и параметров, возможно вы и об этом знаете.
Количество фильтров/слоев в Neck (FPN, PAN, BiFPN, ASFF, ...) сильно зависит от network resolution, backbone, dataset, BoF/BoS,… чуть что-то изменил, и надо заново подбирать. Это всегда будет поиск компромисса или точнее и медленнее, или быстрее, но точность хуже. Мы же старались добавить фичи, которые увеличивают точность без уменьшения скорости, и которые затем можно использовать в любых других сетях, детекторах или даже задачах.
Единственное, что могу посоветовать, это использовать те же скейл параметры (α = 1.2, β = 1.1, γ = 1.15), как в EfficientNet/Det для compound scaling method, если хотите уменьшить/увеличить сеть и скорость/точность. arxiv.org/abs/1905.11946
Вы можете использовать NAS (как часть AutoML) для подбора оптимальной архитектуры, но если вы не Google, который может тратить миллионы $ на NAS, то больших результатов ждать не стоит. en.wikipedia.org/wiki/Neural_architecture_search
В Google-brain использовали NAS в большей или меньшей степени для: NAS-FPN, MnasNet + NECK, EfficientNet/Det, MixNet,… а все равно не смогли сделать сеть точнее, чем старая Yolov3 при той же скорости, если запускать обе на том же GPU (TitanV/TeslaV100).
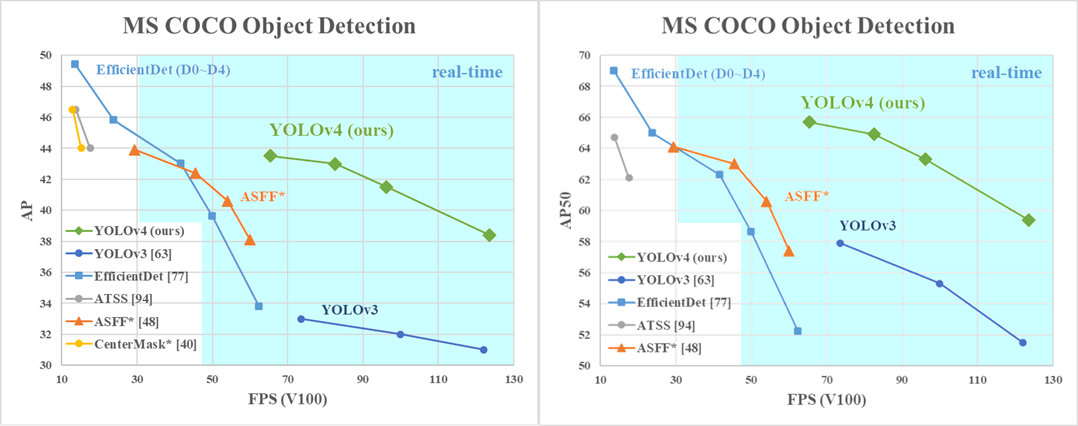
Единственное, что могу посоветовать, это использовать те же скейл параметры (α = 1.2, β = 1.1, γ = 1.15), как в EfficientNet/Det для compound scaling method, если хотите уменьшить/увеличить сеть и скорость/точность. arxiv.org/abs/1905.11946
Вы можете использовать NAS (как часть AutoML) для подбора оптимальной архитектуры, но если вы не Google, который может тратить миллионы $ на NAS, то больших результатов ждать не стоит. en.wikipedia.org/wiki/Neural_architecture_search
В Google-brain использовали NAS в большей или меньшей степени для: NAS-FPN, MnasNet + NECK, EfficientNet/Det, MixNet,… а все равно не смогли сделать сеть точнее, чем старая Yolov3 при той же скорости, если запускать обе на том же GPU (TitanV/TeslaV100).

Добрый день!
AlexeyAB прокомментируете v5?
Что-то он вышел буквально через месяц после вашего, но проработан куда слабее. Нет всей той массы сравнительных графиков, нет примеров под Jetson | OpenVino, нет даже банального сравнения на одном графике с v4.
Я так понимаю он не от вашей команды?
AlexeyAB прокомментируете v5?
Что-то он вышел буквально через месяц после вашего, но проработан куда слабее. Нет всей той массы сравнительных графиков, нет примеров под Jetson | OpenVino, нет даже банального сравнения на одном графике с v4.
Я так понимаю он не от вашей команды?
Привет.
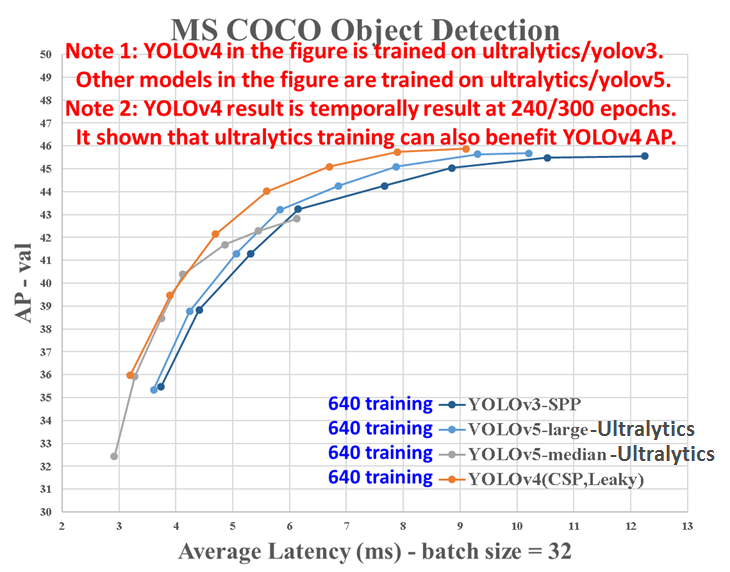
А batch=32 для измерения Latency (ms) не смутило сразу? )
Тут два варианта:
1. Либо один пакет в 32 изображения обрабатывается за 17мс с точностью 47%AP, т.е. скорость ~2000 FPS с точностью 47%AP
2. Либо один пакет в 32 изображения обрабатывается за ~500мс, а затем они зачем то это делят на 32, и получают 17мс. Только задержка 1 сэмпла в пакете не может быть меньше задержки всего пакета 500мс.
То есть чтобы понять, что дурят, даже в нейронных сетях не надо разбираться, надо только знать что такое Latency и Batching.
По факту Ultralytics-YOLOv5 чуть хуже, чем YOLOv4 если честно сравнивать: github.com/AlexeyAB/darknet/issues/5920

А batch=32 для измерения Latency (ms) не смутило сразу? )
Тут два варианта:
1. Либо один пакет в 32 изображения обрабатывается за 17мс с точностью 47%AP, т.е. скорость ~2000 FPS с точностью 47%AP
2. Либо один пакет в 32 изображения обрабатывается за ~500мс, а затем они зачем то это делят на 32, и получают 17мс. Только задержка 1 сэмпла в пакете не может быть меньше задержки всего пакета 500мс.
То есть чтобы понять, что дурят, даже в нейронных сетях не надо разбираться, надо только знать что такое Latency и Batching.
По факту Ultralytics-YOLOv5 чуть хуже, чем YOLOv4 если честно сравнивать: github.com/AlexeyAB/darknet/issues/5920

YOLOv4 github.com/AlexeyAB/darknet и точнее и быстрее, чем YOLOv5-Ultralytics подробнее: github.com/pjreddie/darknet/issues/2198

Алексей, спасибо за поддержку и развитие проекта. Как там с Джо, не общаетесь?
Если кто не в теме, Joseph Redmon месяца четыре назад заявил —
Если кто не в теме, Joseph Redmon месяца четыре назад заявил —
I stopped doing CV research because I saw the impact my work was having. I loved the work but the military applications and privacy concerns eventually became impossible to ignore.
Sign up to leave a comment.
YOLOv4 – самая точная real-time нейронная сеть на датасете Microsoft COCO